







全图层面的特征工程:将整张图反映为D维的向量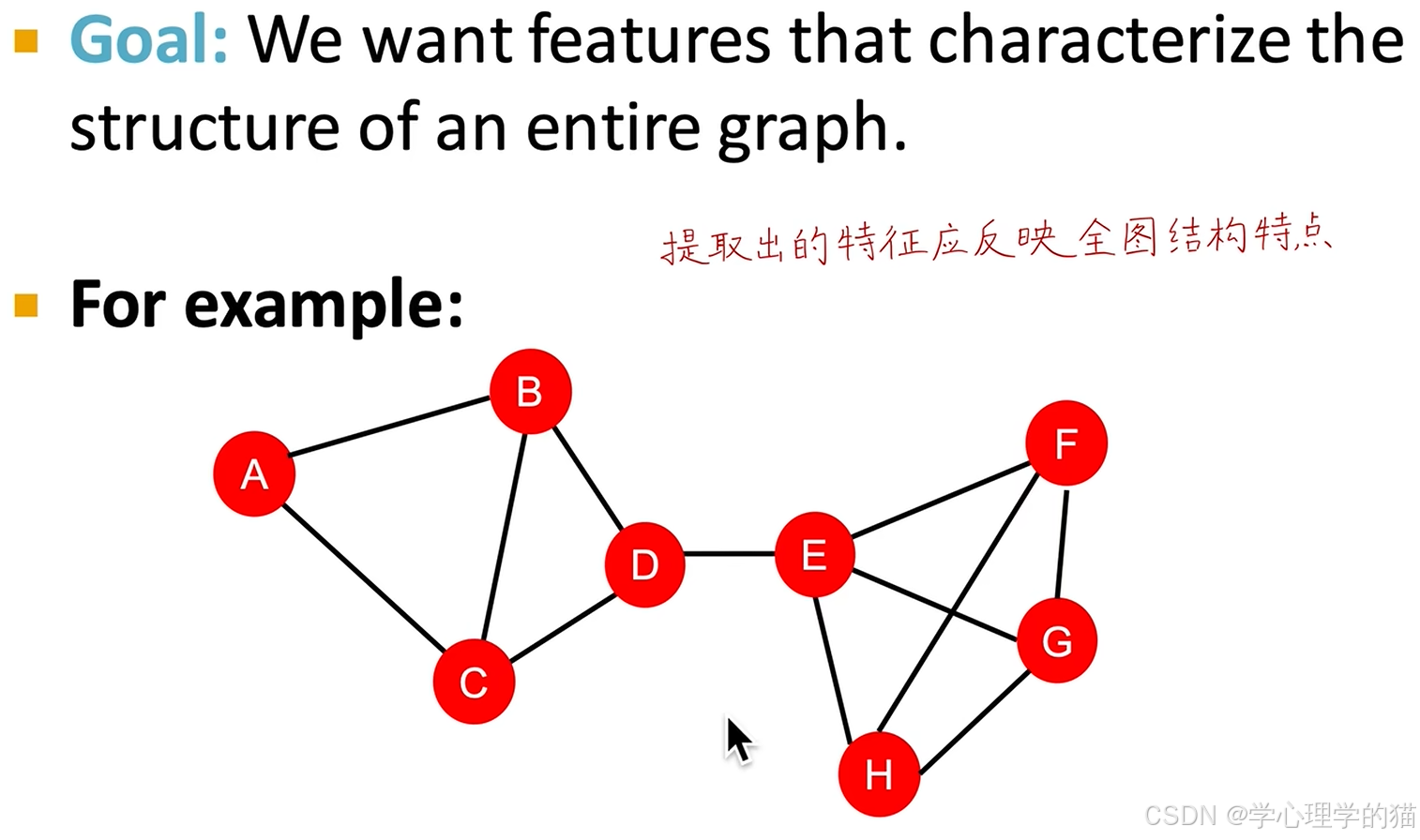
BoW方法:将文章的词语抽出来,然后分别计数总结为一个D维向量这样计算机就可以识别。
但是如下图所示两个不同的图抽象出来的D维向量却是一样的,所以只靠BoW方法不可靠。

这里若考NodeDegree进行判断则可以区别出来,所以将Bag-of-*推广到其他情况。

回想之前的Graphlets,将全图的Graphlets抽取出来作为一个向量
第i个元素就是第i个graphlet在图中的个数。

将两个图的Graphlet进行数量积可以得到两张图的Kernel,这个Kernel就可以反映两张图的相似程度,若两张图不一样大的话则会对每一个向量做一个归一化。

但是为什么我们不经常用这个方法呢?因为消耗的算力太大。

更高效的算法

例子:初始化都为1。后面一次迭代若邻居有两个则写为1,11。若邻居有三个则写为1,111。其他以此类推。
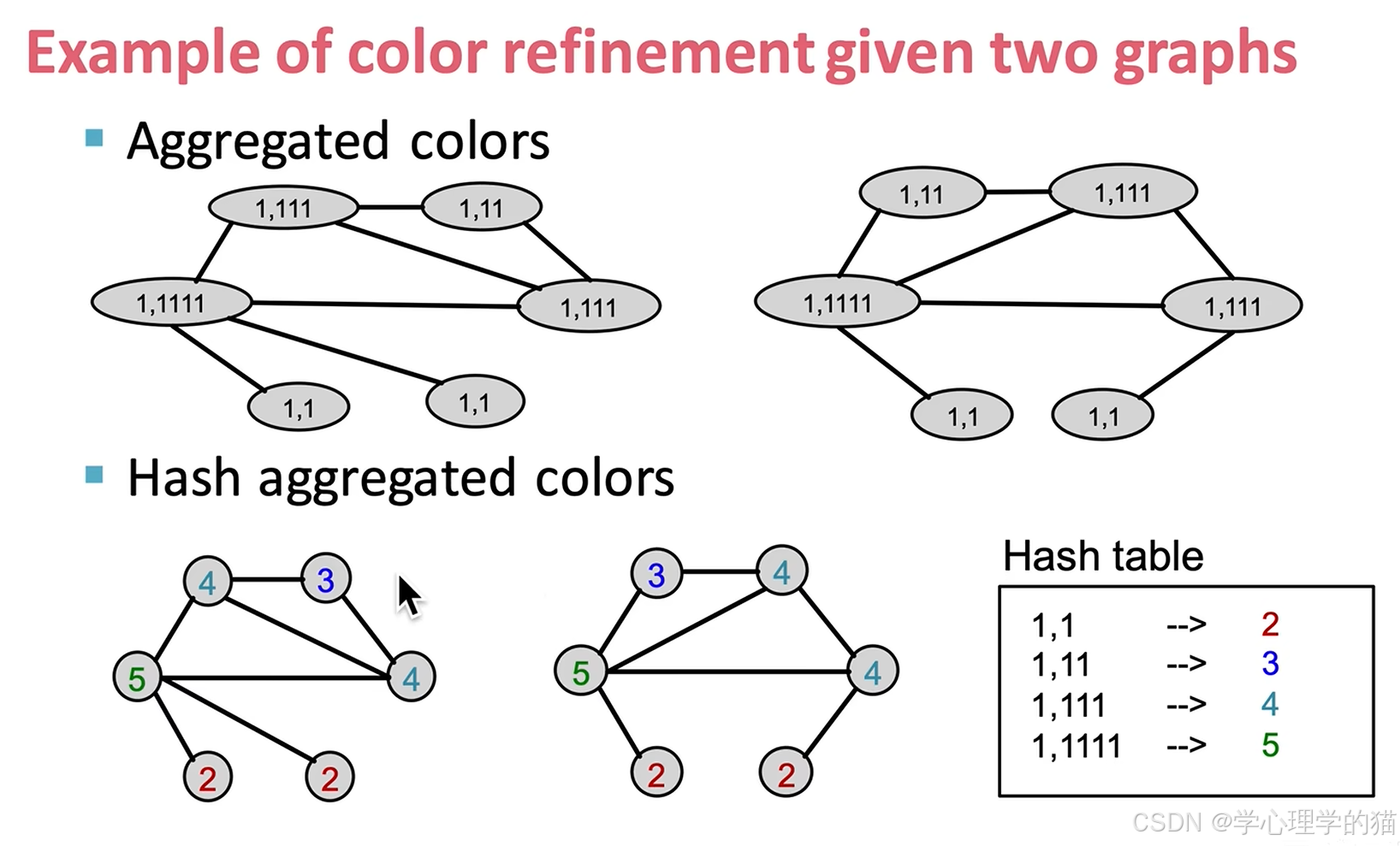
在进一步迭代,也和上面一样将邻居的点“拿”过来形成下图样子。
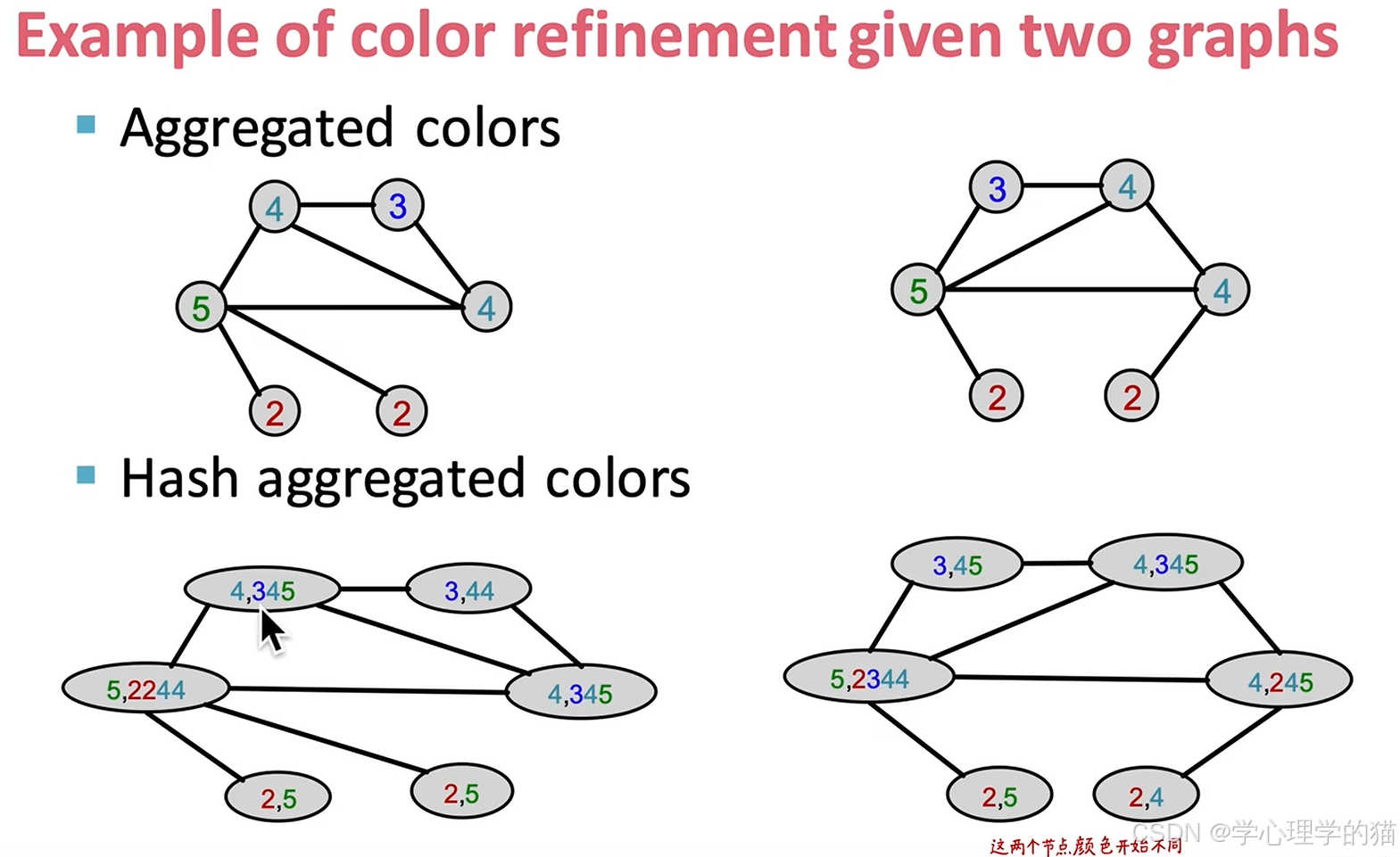
在进一步迭代,将图中节点的个数计算出来如下图所示。
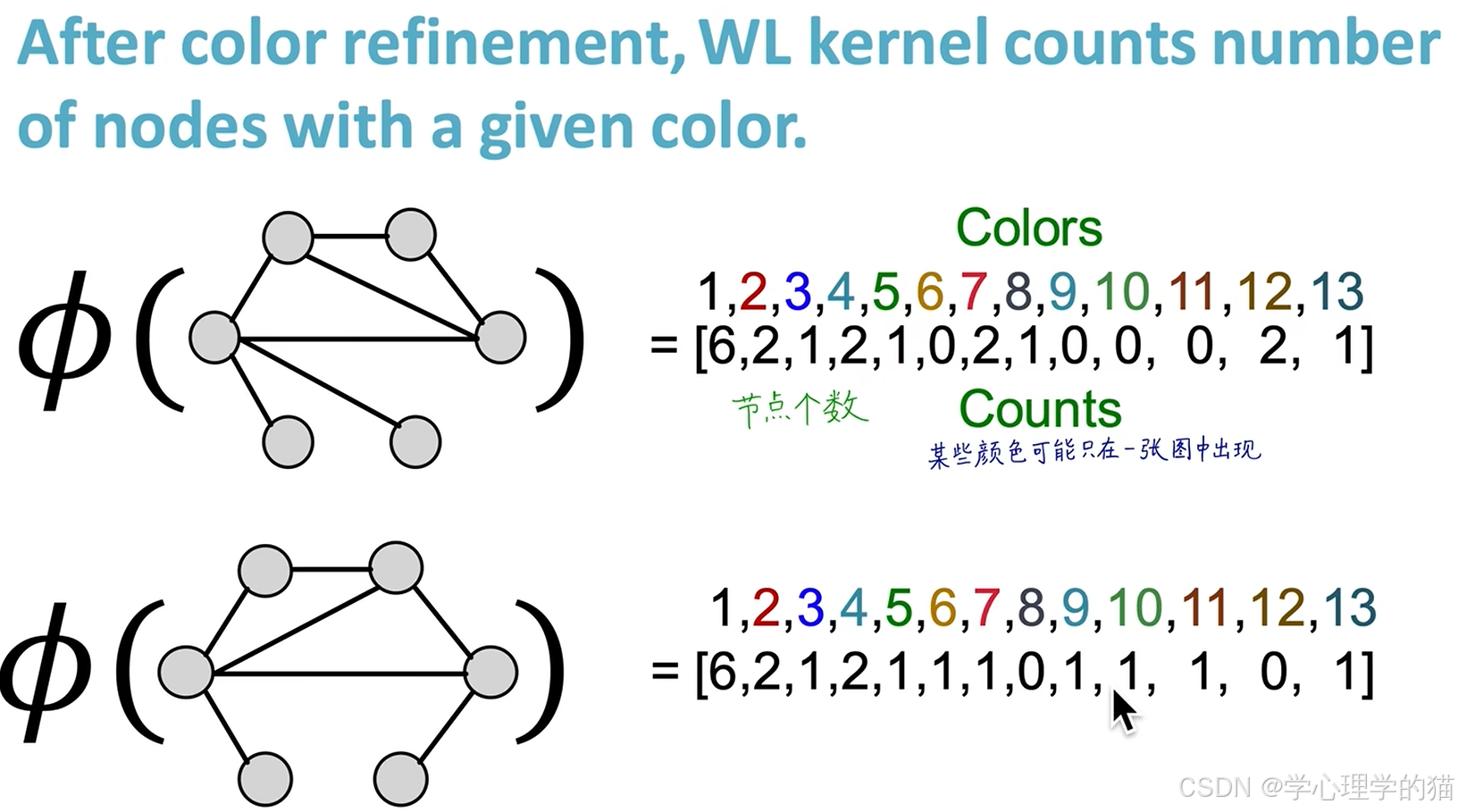
最后将两个图的Kernel点乘计算出来。
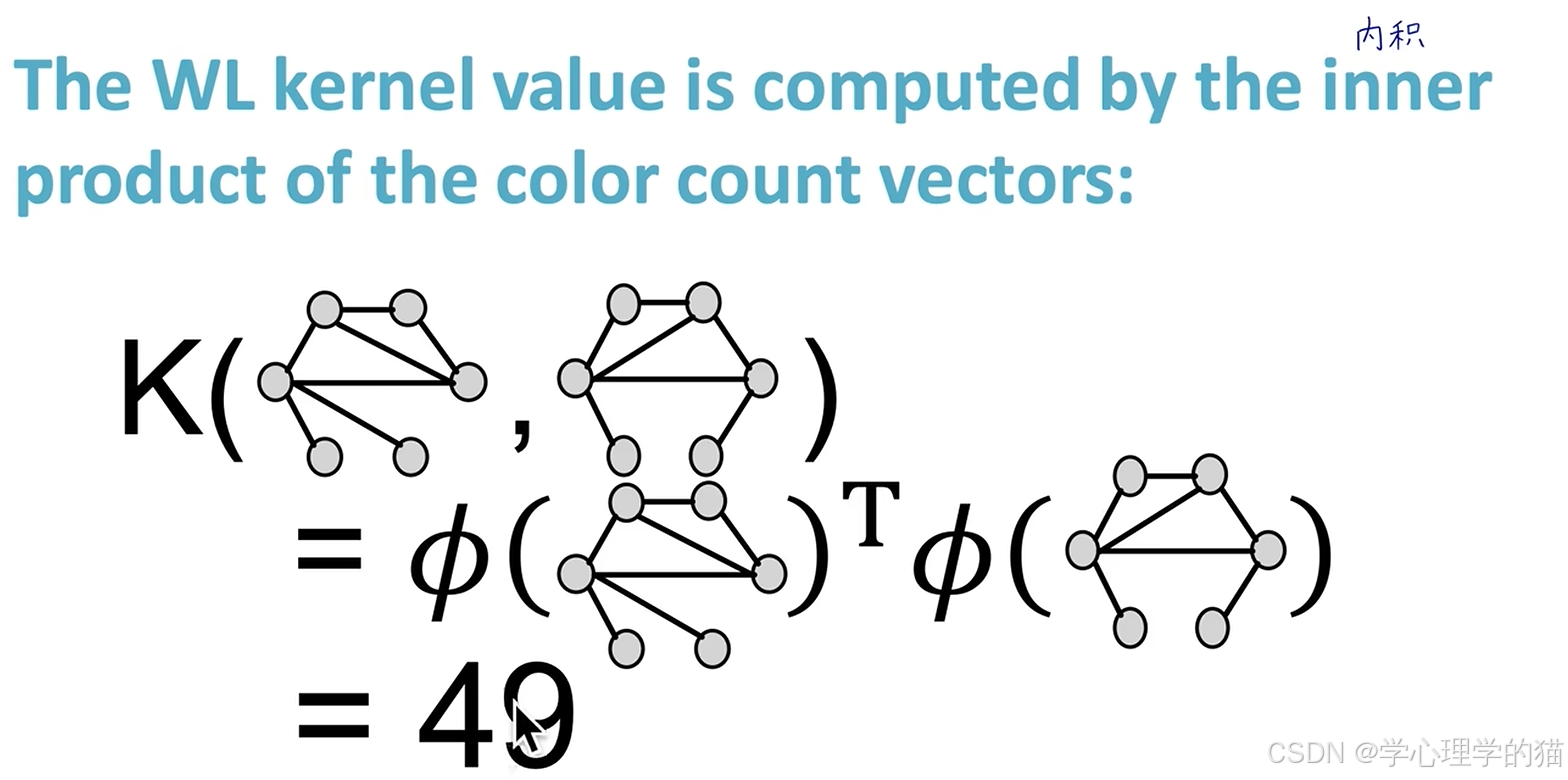
总结:
Graphlet Kernel: 是一种基于图的子图结构来衡量两个图相似度的方法。它的核心思想是将图分解为更小的子图结构,称为 graphlets,然后计算这些 graphlets 在两个图中出现的频率,以此来估计图之间的相似度。Graphlet Kernel 的计算复杂度较高,因为它需要枚举图中的所有可能的子图结构,这在大型图中尤其耗时。为了解决这个问题,研究者们提出了一种高效的方法,只考虑大小为3、4和5的连接图lets,因为这些较小的图lets可以有效地捕捉图的结构特征,并且计算成本较低。
Weisfeiler-Lehman Kernel(WL Kernel):是基于 Weisfeiler-Lehman 同构测试算法的图核方法。这个算法通过迭代地为图中的节点分配新标签来捕捉图的结构信息。在每次迭代中,节点的标签会被更新为其邻居节点的标签的某种组合。这个过程重复进行,直到无法进一步更新或达到预定的迭代次数。WL Kernel 通过比较两个图在不同迭代步骤中的标签分布来衡量它们的相似度。WL Kernel 的一个关键优势是它可以处理带有离散标签的大规模图,并且计算效率较高。
两种方法都试图通过捕捉图的结构特征来衡量图之间的相似度,但它们在实现和效率上有所不同。Graphlet Kernel 更注重于子图的结构,而 Weisfeiler-Lehman Kernel 则侧重于节点标签的迭代更新过程。在实际应用中,选择哪种方法取决于具体任务的需求和图的大小。对于大规模图数据,WL Kernel 通常更受欢迎,因为它的计算效率更高

把两张图的向量做数量积得到一个标量这种方法称为Kernel methods

这集讲的是Graphlet Kernel和Weisfeiler-Lehman Kernel方法,另外可以了解的方法如下Random-walk kernel、Shortest-path graph kernel等等。


















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









