







前言:
本系列是为了总结相关的一些论文中相关内容的笔记,绝大部分都是参考文末论文中的内容,博文仅用于自己之后对自己模型进行相应的优化,记录一部分相关的CSLR的知识,并提出一部分自己的问题,深知本人水平有限,所写之处如有错误,欢迎指出。
1、关于CTC对应的尖峰现象如何处理以及对于CSL数据集为什么会出现这种现象。
2、LSTM的机制是什么,在哪些地方可以用到。
⊙ denotes the Hadamard product,可以将LSTM用如下的公式表示:
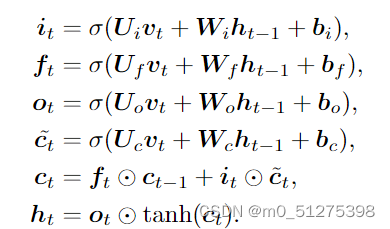
The it、ft and ot are corresponding to input, for-get and output gate,ht and ct are hidden and cell states.U· and W· are the input-to-hidden and hidden-to-hidden weight matrices.
ft对应公式为隐层与输入词同时进行σ的相关运算,并加上偏置;
it对应的公式与ft类似,只是偏置上可能会有区别;
为临时细胞状态,tanh中的公式与ft、it类似;
Ct为当前细胞状态,为遗忘层与上一个细胞状态的乘积加上输入层与临时细胞状态对应乘积;
ot输出层类似于ft;
ht隐藏层为输出与tanh的乘积;
- 利用LSTM进行CSLR训练的时候会出现局部最优;
- 输入与输出的数值会变得很大而且会很平滑,但是层与层之间相关性会很差;原因在于:
输入特征的大小 - 利用LSTM很容易出现稳定收敛,但是问题是这类模型中很可能Visual feature没有得到有效的利用,进而而言的话可能会导致模型泛化能力很差
3、如何减少过拟合。
采用pseudo labels;
采用visual alignment constraint;
采用distillation loss;
采用辅助损失,例如Visual Enhancement (VE) loss即基本的CTCloss、the Visual Alignment (VA) loss即计算上下文的KL散度,先对上下文进行SOFTMAX处理之后求KL散度即可.
采用一些数据增强的方法:All frames are resized to 256x256, and the training set is augmented with random crop (224x224), horizontal flip (50%), and random temporal scaling (±20%).
transforms.Compose([
torchvision.transforms.Resize([256,256]),
torchvision.transforms.RandomCrop([224,224]),
torchvision.transforms.RandomHorizontalFlip(p=0.5),
])4、评估手语测试能力的量度。
Word Error Rate(WER):这里参考了这个项目WER,代码测试如下:
import numpy
def wer(r, h):
d = numpy.zeros((len(r) + 1) * (len(h) + 1), dtype=numpy.uint16)
d = d.reshape((len(r) + 1, len(h) + 1))
for i in range(len(r) + 1):
for j in range(len(h) + 1):
if i == 0:
d[0][j] = j
elif j == 0:
d[i][0] = i
for i in range(1, len(r) + 1):
for j in range(1, len(h) + 1):
if r[i - 1] == h[j - 1]:
d[i][j] = d[i - 1][j - 1]
else:
substitution = d[i - 1][j - 1] + 1
insertion = d[i][j - 1] + 1
deletion = d[i - 1][j] + 1
d[i][j] = min(substitution, insertion, deletion)
result = float(d[len(r)][len(h)]) / len(r) * 100
print(result)
return result
if __name__=='__main__':
wer(list('abcd'),list('abdc'))5、具体网络设计:
VGG11或Resnet18来获取Visual feature,两个网络可以利用torch里面的预训练模型来得到,具体调用可以如下所示:
import torchvision.models as models
model = models.resnet18()在提取完视觉特征后,可以采用BiLSTM也可以用Transformer,也可以用Seq2Seq模型,Transformer与Seq2Seq都是基于Encoder和Decoder的模型。
6、优化器该如何设计。
7、利用Batch Normalization进行模型优化。
参考文献:















 2434
2434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









