






之前使用的是chatGLM2中自带的ptuner进行的大模型微调,但是效果并不理想。分析原因:我们的大模型需要同时做两种不同的任务,一种是病历自动生成(相当于实体属性抽取任务)和健康建议(医疗问答任务),在使用ptuner进行微调的时候,两个不同的任务会互相影响,使得模型出现灾难性遗忘。我们重新使用开源微调工具LLaMA factory(hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs (github.com)),对chatglm2进行LoRA微调。
低秩适配(LoRA)是一种非常高效的微调方法,它不会改变预训练模型的原始权重参数。相反,LoRA在需要微调的层上引入了一对小的可训练矩阵,称为低秩矩阵。在前向过程中,模型会对原始权重张量和LoRA低秩矩阵进行相乘运算,得到改变后的权重用于计算。而在反向传播时,只需要计算和更新这对小矩阵的梯度。
LLaMA-Factory是一个统一的框架,集成了一套先进的高效训练方法。它允许用户通过内置的可视化界面灵活定制100多个LLMs的微调,而无需编写代码.LLaMA Factory支持的大模型列表如下,可在github查到: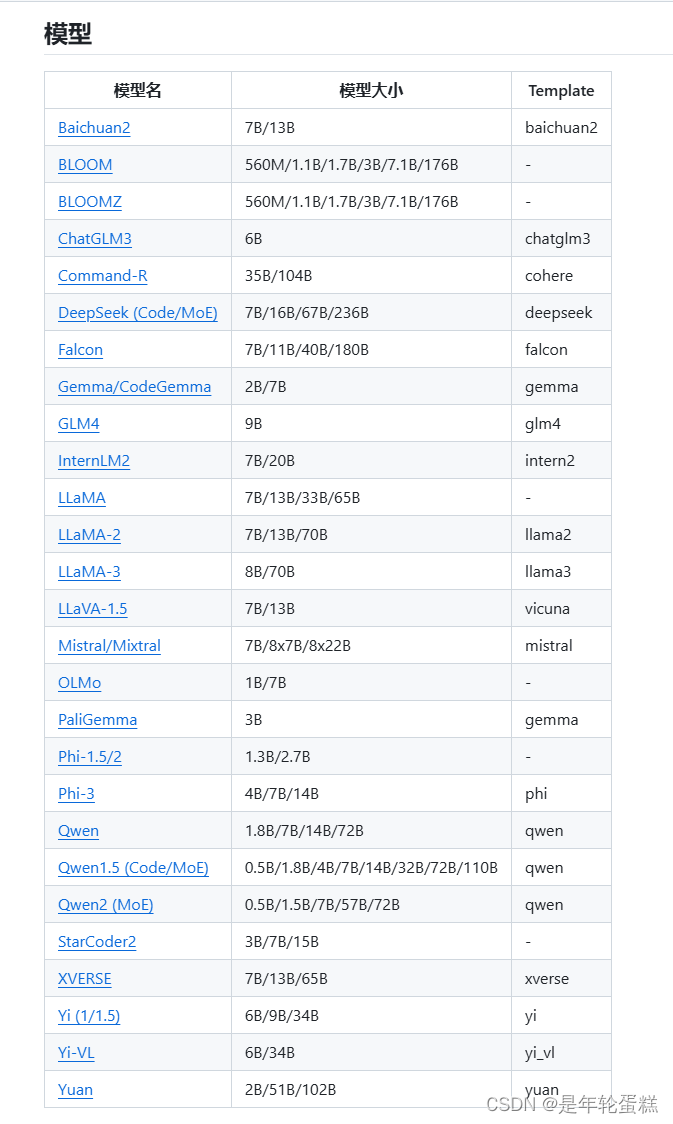
首先通过git安装LLaMA-Factory,并安装相应依赖:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]" pip install -r requirements.txt
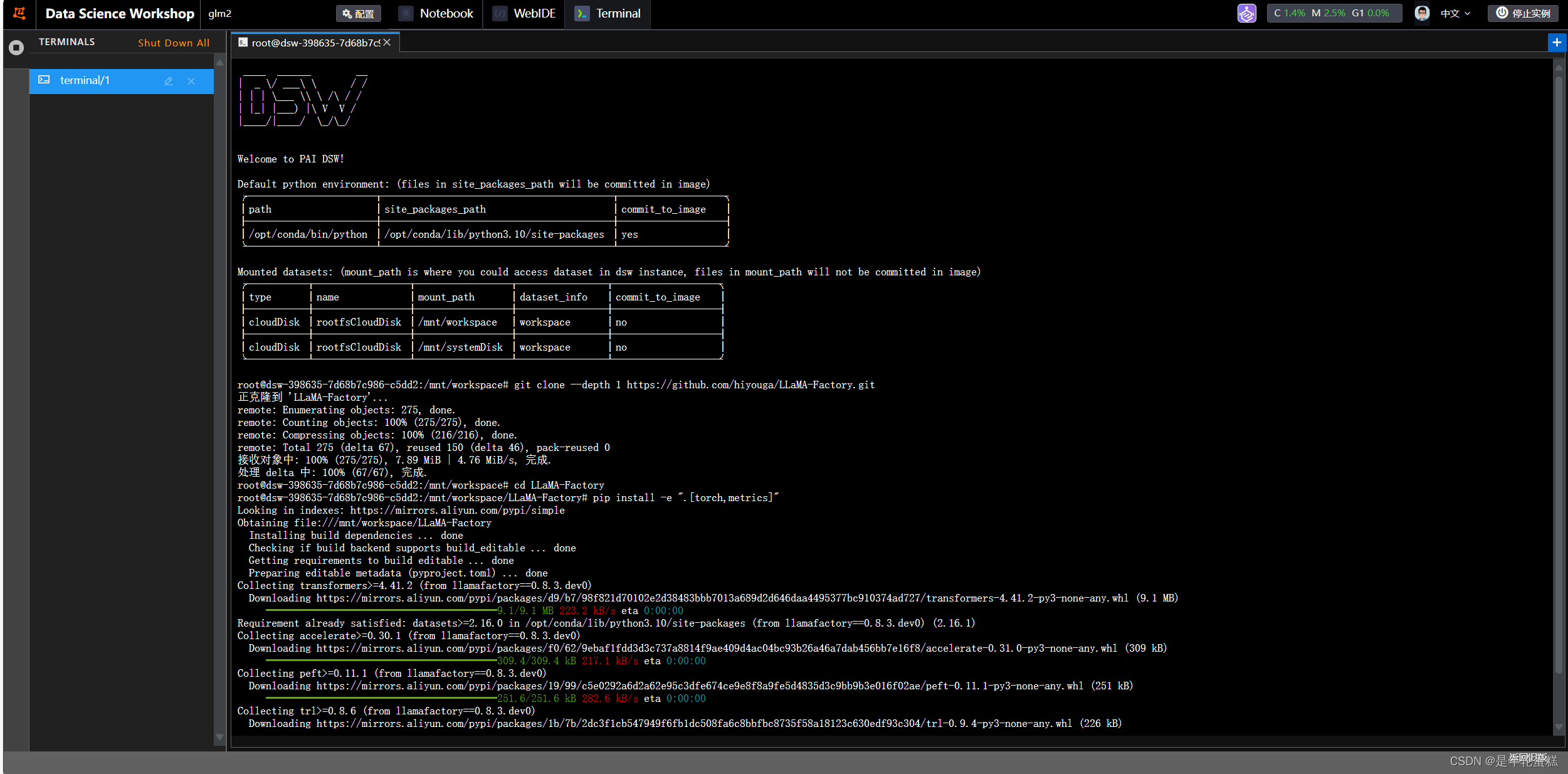
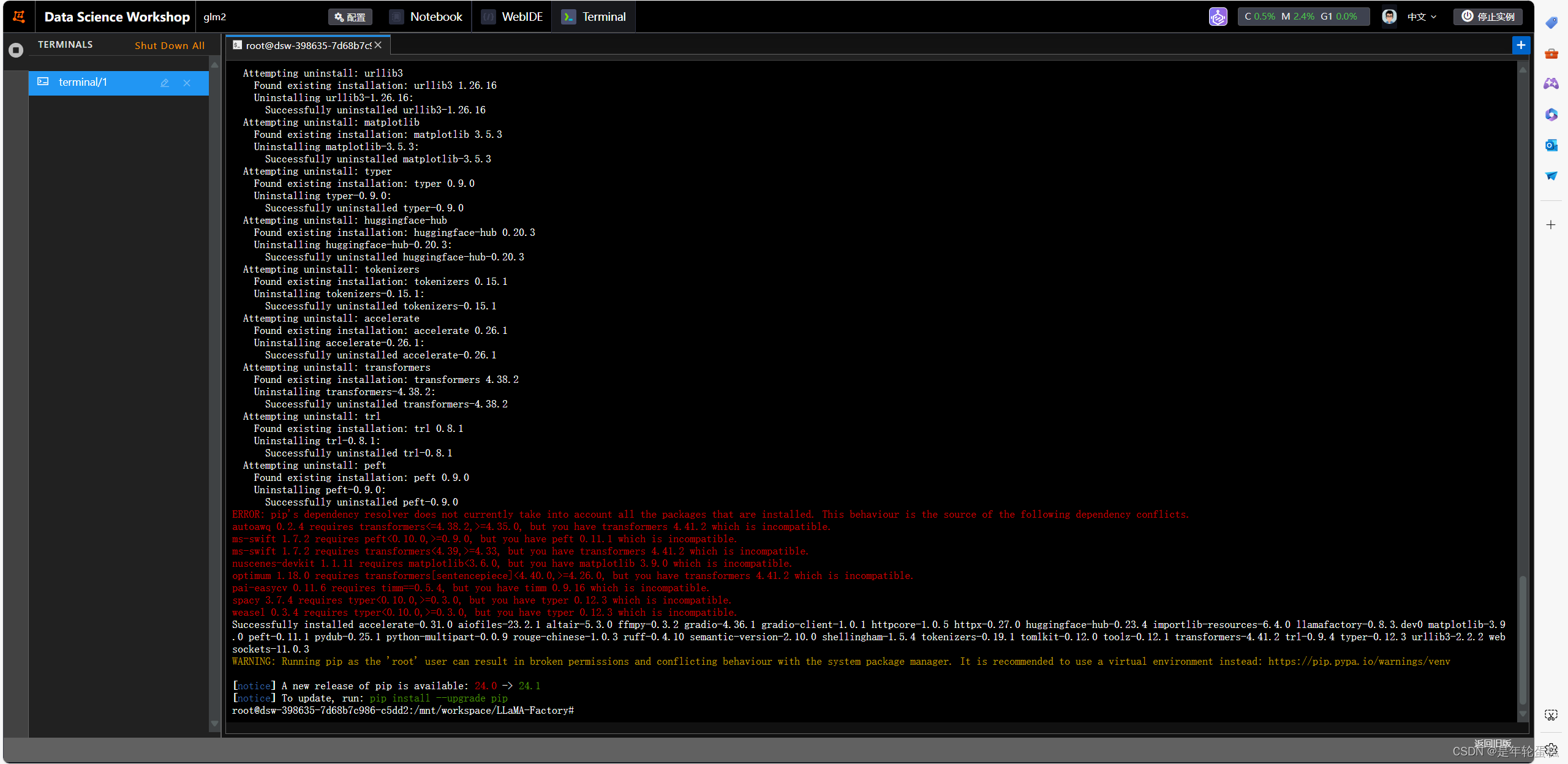
遇到了包冲突,先执行requirements.txt,再执行pip install -e ".[torch,metrics]",依然报错。
改成使用anaconda虚拟环境进行包管理:
# 创建虚拟环境
conda create -n llama_factory python=3.10
# 激活虚拟环境
conda activate llama_factory
# 安装依赖
cd LLaMA-Factory
pip install -r requirements.txt
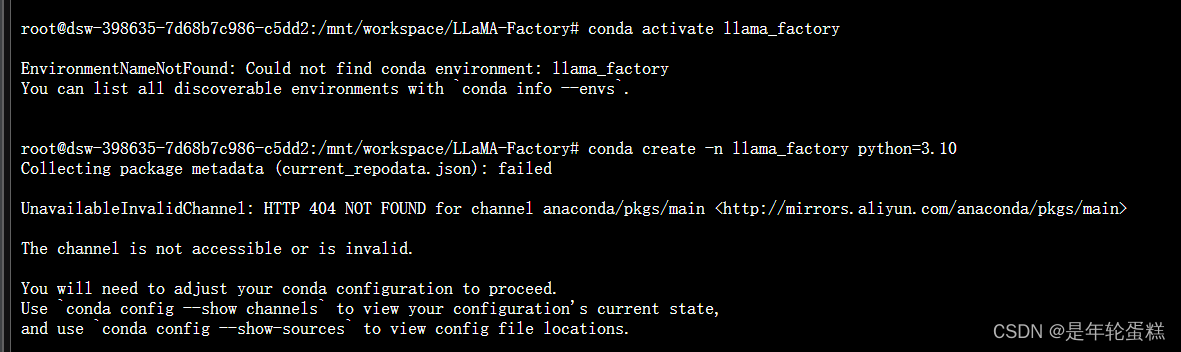
阿里云服务器连不上阿里云的镜像站···
conda无法创建新隔离环境。
之后改为在Windows运行。
先创建虚拟环境:conda create -n llama_factory python=3.10
再按readme.md安装相应依赖:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
pip install -e .[torch,metrics]
因为在Windows运行,还需要:
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
之后就可以启动了:
Set CUDA_VISIBLE_DEVICES=0
Set GRADIO_SHARE=1
llamafactory-cli webui
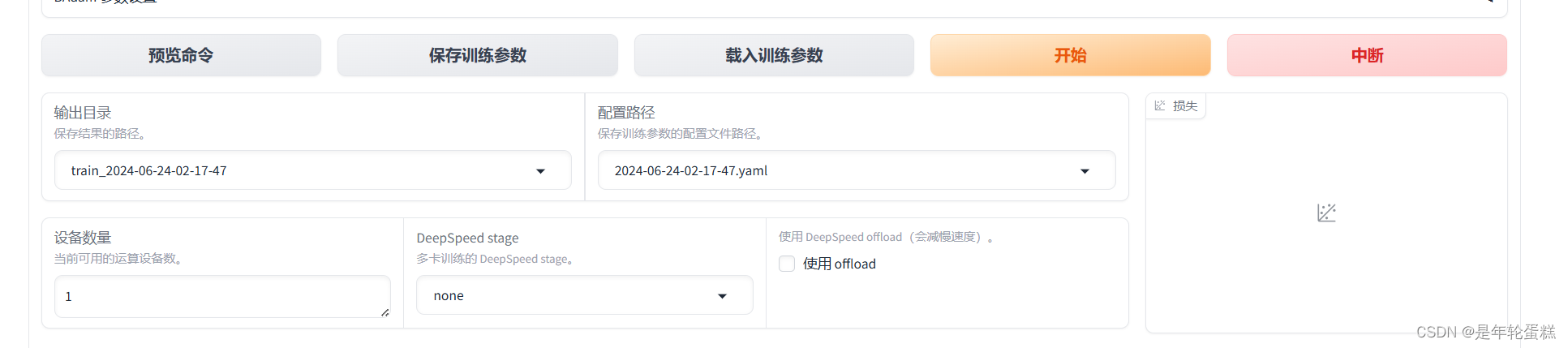
启动后,出现如下图所示界面,成功
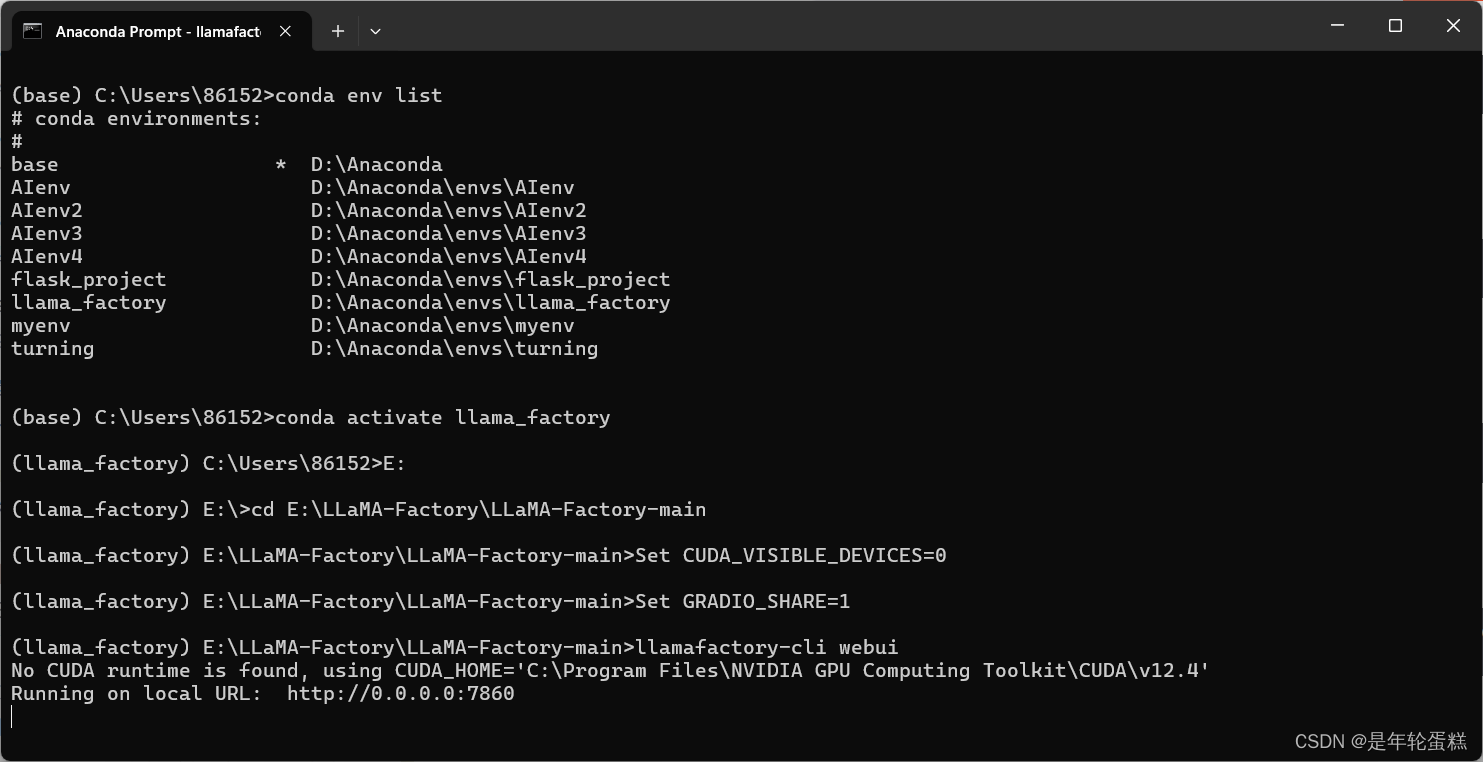
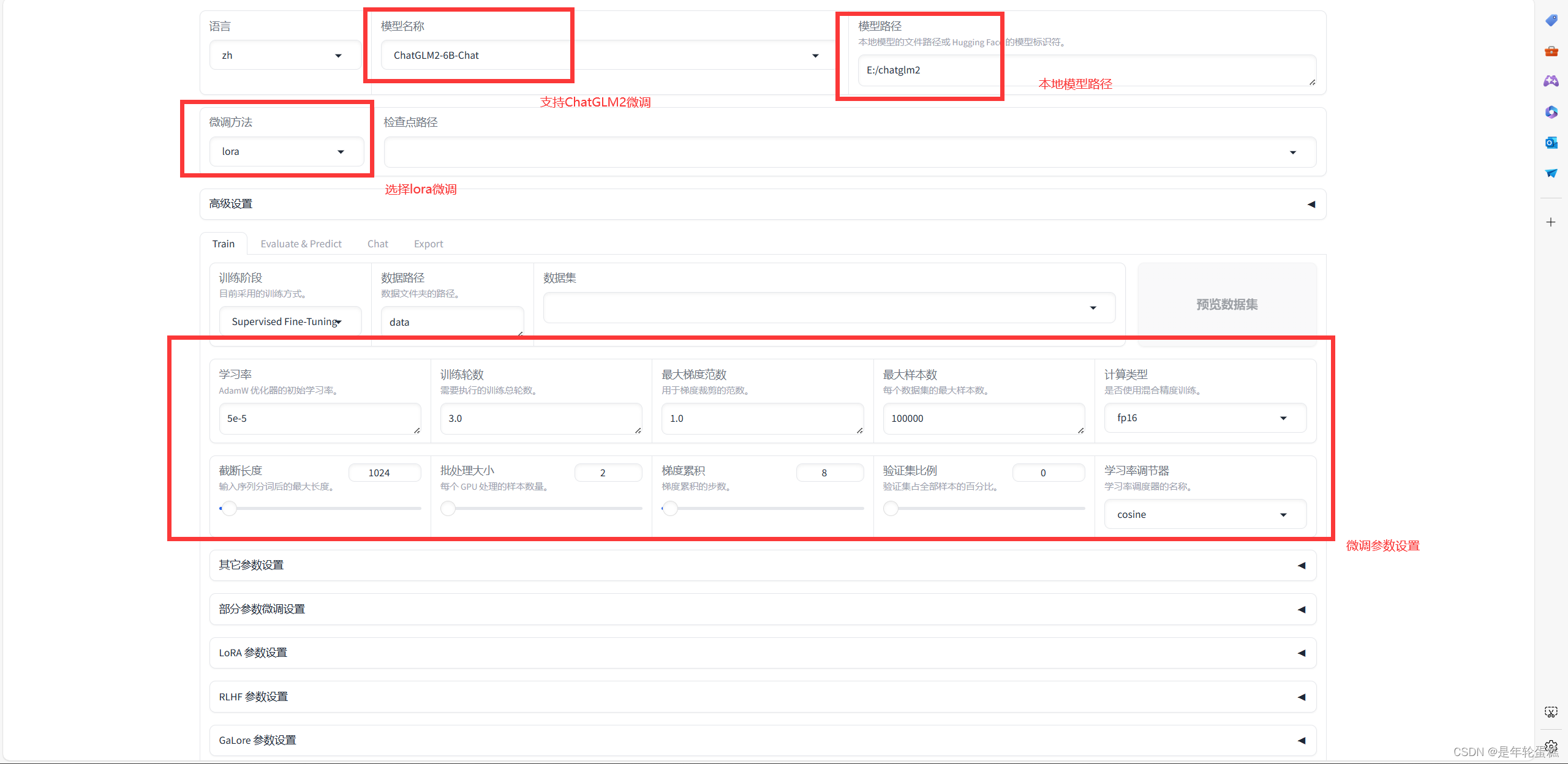
如上图所示设置各参数
导入自定义数据集:
经过清洗后的数据集样式如下(alpaca样式)
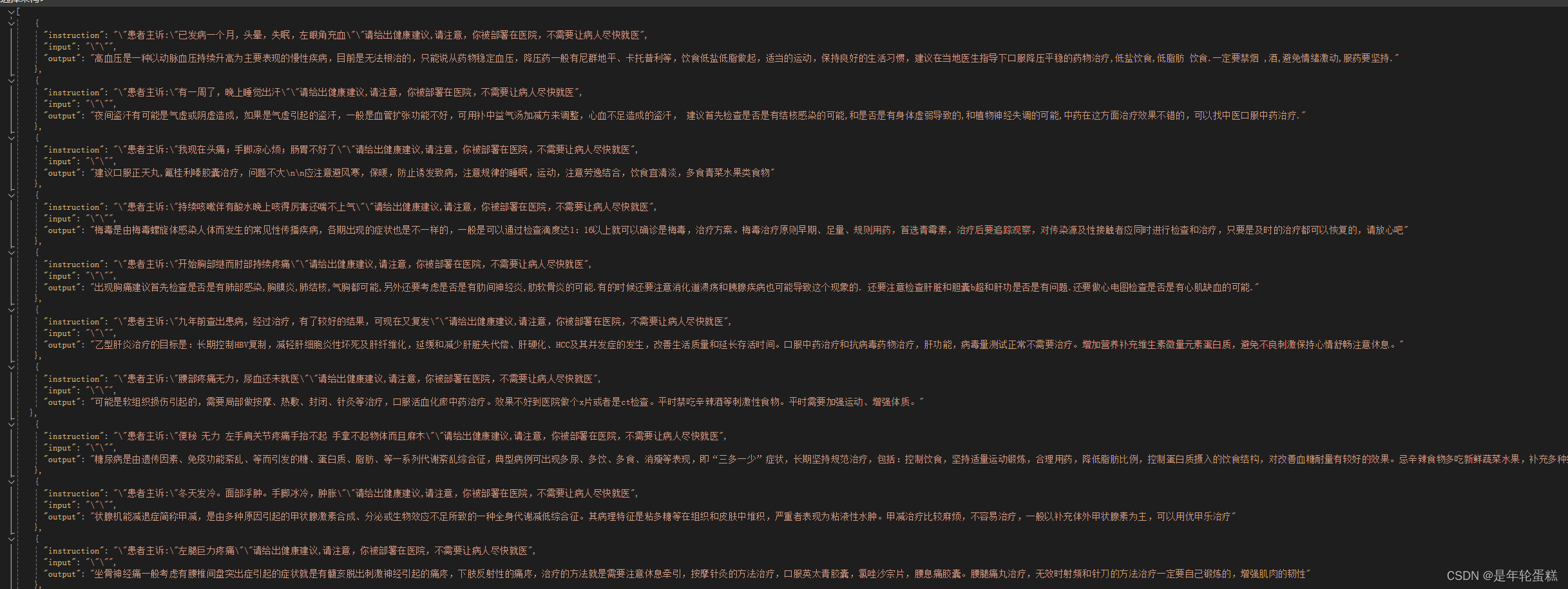
将数据集json文件放到LLaMA-Factory\data目录下,然后打开dataset_info.json文件,增加这个文件名记录:

然后就能在LLaMA界面下拉框选择这个数据集
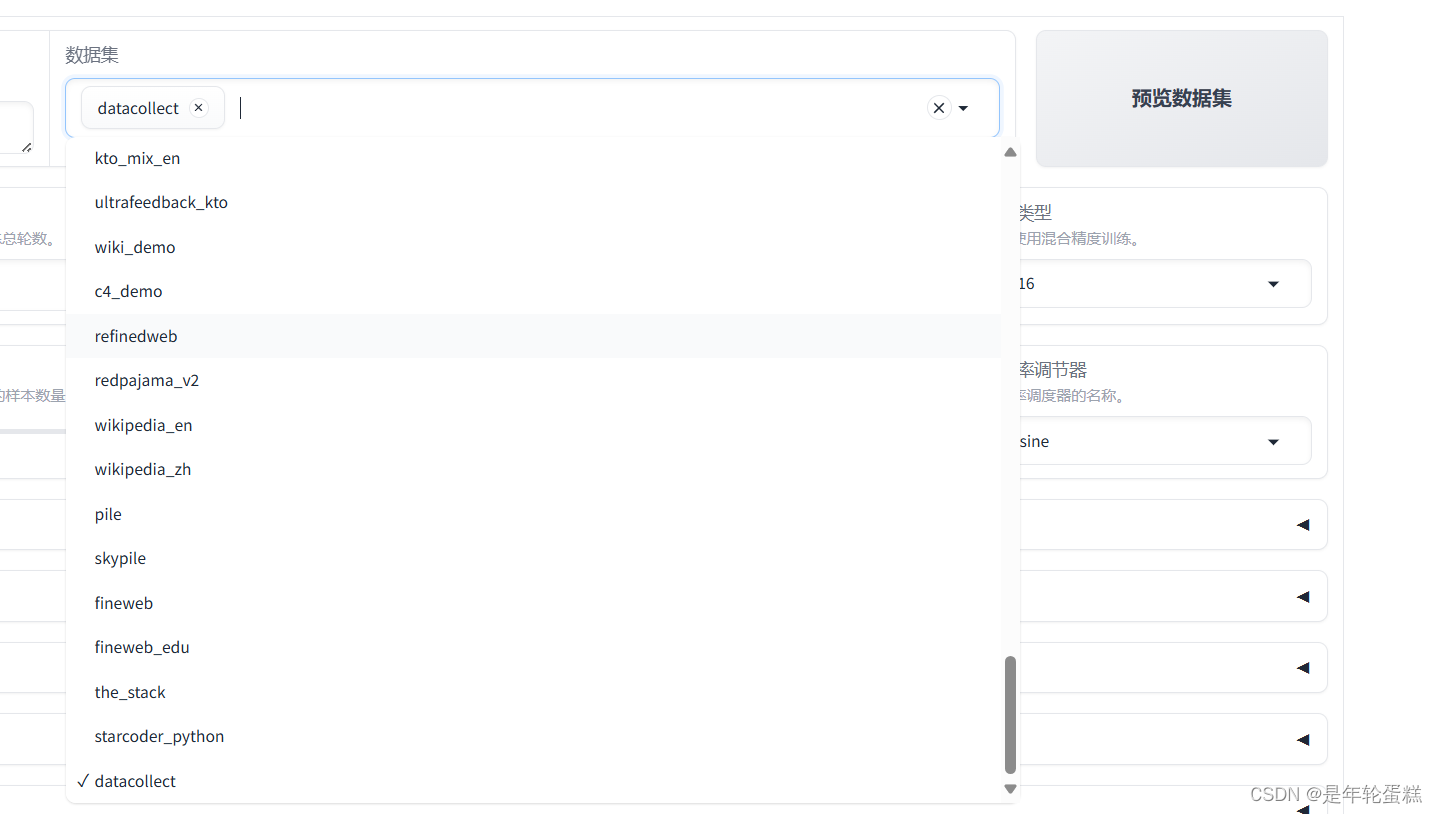
预览命令,可以发现其实执行的是:
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path E:/chatglm2 \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template chatglm2 \
--flash_attn auto \
--dataset_dir data \
--dataset datacollect \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves\ChatGLM2-6B-Chat\lora\train_2024-06-24-02-17-47 \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all 这样的一个sh脚本
点击开始,就正式开始微调。
打开任务管理器,可以看到GPU的占用率飞速上涨
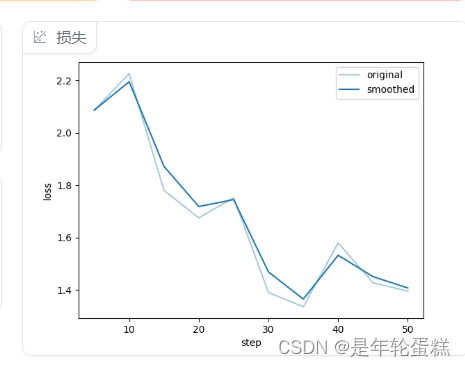
右下角的图会显示微调过程种的loss
运行完成后,点击保存训练参数,设置导出路径然后点击导出(耗时较长,这个时间应该是训练层和原大模型结合的过程),导出完毕后,结果如下:
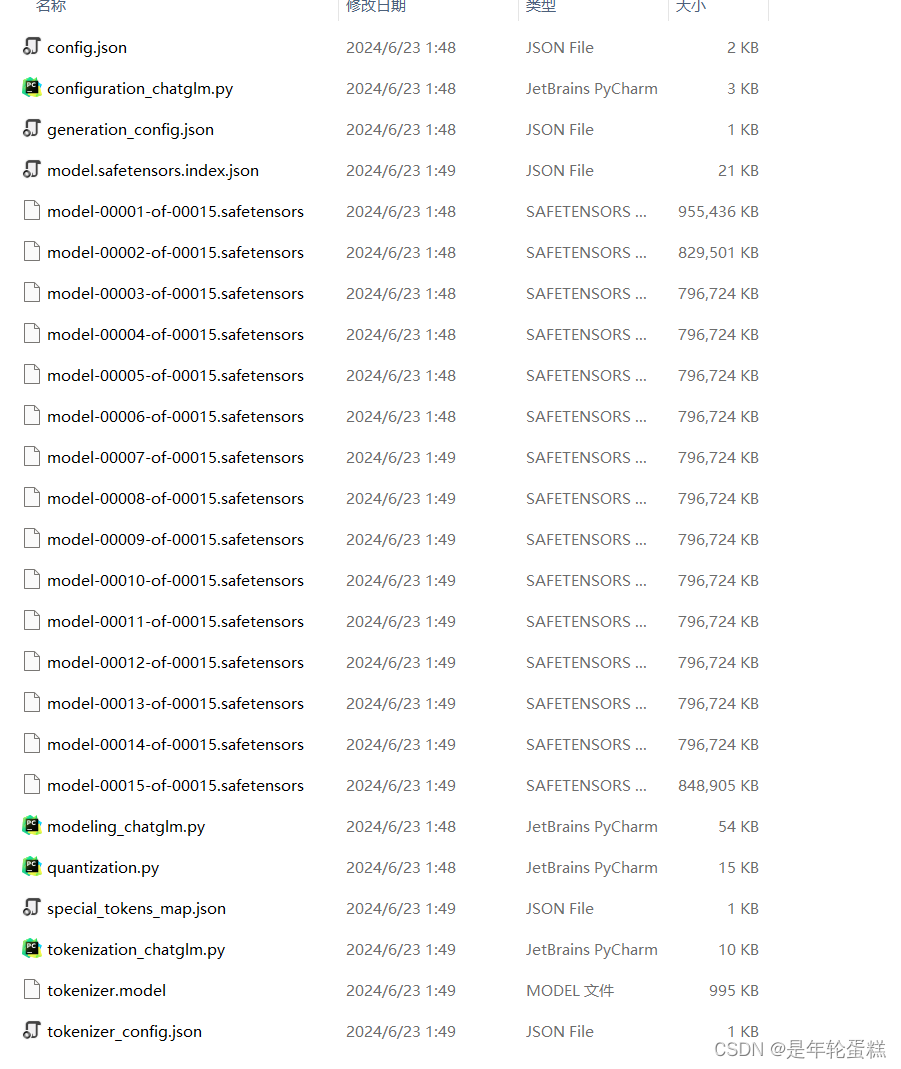
打开我们的项目文件,将大模型的路径改为微调后输出的路径,微调完成。















 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









