







内容摘要
对源文件进行词法分析,语法分析每需要一个单词时调用词法分析程序,分析当前单词,回送给语法分析程序同时产生相应的二元式文件和符号表。在此过程中,应用SLR(1)文法。同时设计3个和结果相关的栈,观察每一步操作所产生的结果,在进行语法分析时,也伴随着语义的分析,根据算数表达式和赋值语句的文法及相应的语义子程序,最后生成一个四元式文件,存放结果。
关键字
SLR(1) 符号栈 状态栈 语义栈 词法、语法、语义分析

一、课程设计目的
《编译原理》课程设计是编译原理课程必不可少的一个环节,通过课程设计,加深对编译原理的教学内容的了解,以及实现编译原理各部分知识的融合。进而提高学生分析问题、解决问题,从而运用所学知识解决实际问题的能力。
二、课程设计要求
1.明确课设任务,复习与查阅有关资料
2.按要求完成课设内容,课设报告要求文字和图工整、思路清楚、正确。
3.注意增强程序界面的友好性。凡用户输入时,给出足够的提示信息使用户感到方便使用。
4.注意提高程序的可读性和可理解性:程序中应有适当的注释,变量命名应符合实际含义,程序结构清晰,易于阅读和理解。
三、课程设计内容
1.题目
编译程序构造
2.内容
涉及词法分析、自下而上语法分析程序的实现:SLR(1)分析器的实现以及生成中间代码
3.具体要求
根据LR分析算法构造SLR(1)分析程序,并完成语法分析动作(当需要一个单词时,调用词法分析程序获取),同时完成语义分析生成四元式输出。要求程序具有通用性,改变文法时只需改变程序的数据初值,无需改变程序主体;
要求完成算数表达式和赋值语句的翻译,生成中间代码。
算数表达式和赋值语句的文法及相应的语义子程序。
(
1
)
A
→
i
d
=
E
p
=
l
o
o
k
u
p
(
i
d
.
n
a
m
e
)
;
e
m
i
t
(
E
.
P
A
L
C
E
,
,
p
)
;
(1)A→id=E {p=lookup(id.name);emit(E.PALCE, , p);}
(1)A→id=Ep=lookup(id.name);emit(E.PALCE,,p);
(
2
)
E
→
E
(
1
)
+
T
E
.
P
A
L
C
E
=
n
e
w
t
e
m
p
(
)
;
e
m
i
t
(
+
,
E
(
1
)
.
P
A
L
C
E
,
T
.
P
A
L
C
E
,
E
.
P
A
L
C
E
)
(2)E→E(1)+T {E.PALCE=newtemp(); emit(+,E(1).PALCE,T.PALCE,E.PALCE)}
(2)E→E(1)+TE.PALCE=newtemp();emit(+,E(1).PALCE,T.PALCE,E.PALCE)
(
3
)
E
→
T
E
.
P
A
L
C
E
=
T
.
P
A
L
C
E
;
(3)E→T {E.PALCE=T.PALCE;}
(3)E→TE.PALCE=T.PALCE;
(
4
)
T
→
T
(
1
)
∗
F
T
.
P
A
L
C
E
=
n
e
w
t
e
m
p
(
)
;
e
m
i
t
(
+
,
T
(
1
)
.
P
A
L
C
E
,
F
.
P
A
L
C
E
,
T
.
P
A
L
C
E
)
(4)T→T(1)*F {T.PALCE=newtemp(); emit(+,T(1).PALCE,F.PALCE,T.PALCE)}
(4)T→T(1)∗FT.PALCE=newtemp();emit(+,T(1).PALCE,F.PALCE,T.PALCE)
(
5
)
T
→
F
T
.
P
A
L
C
E
=
F
.
P
A
L
C
E
;
(5)T→F {T.PALCE=F.PALCE;}
(5)T→FT.PALCE=F.PALCE;
(
6
)
F
→
(
E
)
F
.
P
A
L
C
E
=
E
.
P
A
L
C
E
;
(6)F→(E) { F.PALCE=E.PALCE;}
(6)F→(E)F.PALCE=E.PALCE;
(
7
)
F
→
i
d
P
=
L
O
O
K
U
P
(
i
d
.
n
a
m
e
)
;
F
.
P
A
L
C
E
=
P
;
(7)F→id {P=LOOKUP(id.name);F.PALCE=P;}
(7)F→idP=LOOKUP(id.name);F.PALCE=P;
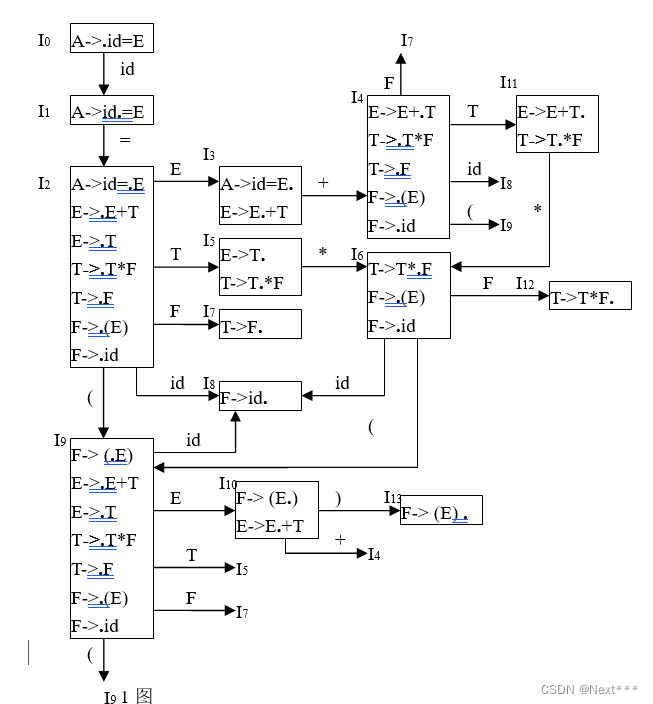
构造其用于SLR(1)分析的识别活前缀的DFA以及action表和goto表。然后编程实现。
4.程序设计提示
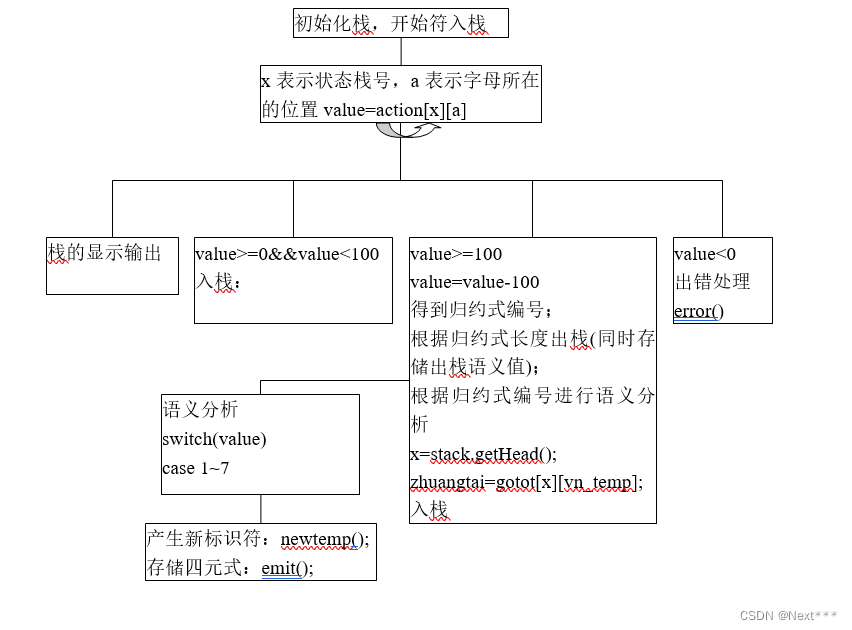
(1)分析栈设计时可以用一个栈完成,也可以设计三个栈:一个符号栈,一个状态栈,一个语义栈,则归约时,则需要在符号栈中退掉n个符号,在状态栈中退掉n个符号(n为产生式符号个数),语义栈中退掉n个符号对应的语义;
(2)终结符表和非终结符表的组织和预测分析程序中相同(将符号对应到一个数字,表示在分析表中对应的下标)。
(3)action表中的错误处理:简化的错误处理:当查找action表出现空白时,则当前单词无法移进和规约,可简单的认为当前单词为多余的单词,则抛弃当前单词,读下一单词继续分析。
四、课程设计解决方案
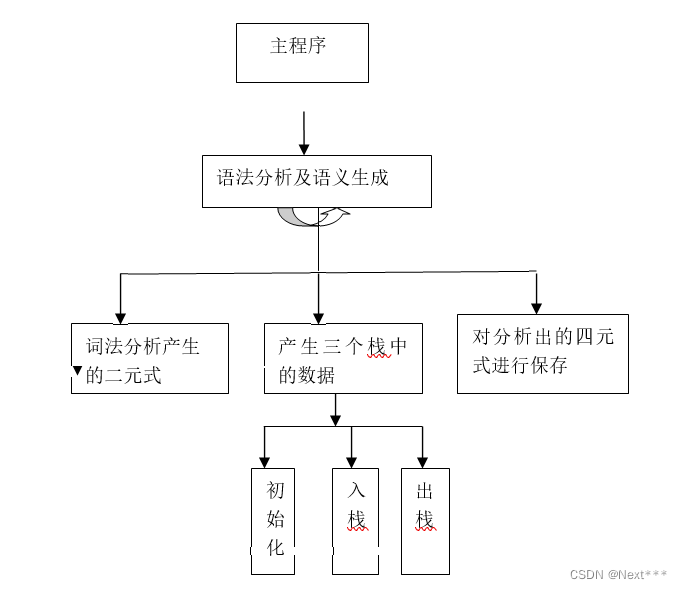
主要程序图
语法分析+语义分析方法中关于三个栈设计的程序结构图:
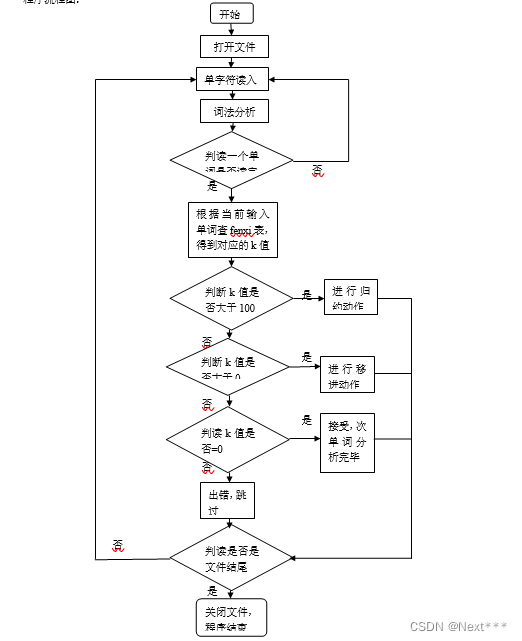
程序流程图:
五、主要程序源代码
import javax.swing.*;
import java.awt.*;
import java.awt.event.*;
import java.io.*;
import java.util.*;
import java.lang.String.*;
class AA extends JFrame
{ int a=0;
int ii=-1;//状态栈的栈顶指针
int e=1;//记录错误数
int u=-1;//符号栈的栈顶指针
int h=-1;//控制中间变量的数组下表;
int y=-1;//语义栈的栈顶指针
int weizhi=-1;//符号表中符号的总数;
int i=0;//当把输入的表达式映射为数组,i为数组下标;
int ll=0;//如果输入的字符是不可识别,ll=1;如果是可识别的ll=0;
String s=" ";
String kk="";
String id;//记录识别出来的字符是标示符还是符号,值为i,或*,=,...;
String iweizhi;//记录所识别出来的字在符号表里的位置。
String pp="";//将符号表里的所有内容,全部取出付给pp,便于查询;
String Eplace,Tplace,Fplace,Aplace;//记录E,T,F,A的实际值,可以为a,b,x,或中间变量;
char lookhead;
int state_stack[]=new int[ 40];//状态栈
char symbol_stack[]=new char[40];//符号栈
String grammer_stack[]=new String[100];//语义栈
String name[]={"A","B","C","D","F","G","H","J","K","L","Q","T1","T2","T3","T4","T5","T6","T7","T8","T9","A1","A2","A3","A4","A5","A6"};//中间变量的值
char N[] ={'+','*','i','=','(',')','#','E','F','T','A'};//这个文法所能识别出的符号,相当于slr表里的行坐标
char grammer_right[][] ={{'i','=','E'} , {'E','+','T'}, {'T'}, {'T','*','F'}, {'F'}, {'(','E',')'},{'i'} };
//每个产生式右边对应的符号
String iii;
JTextArea text1=new JTextArea();
int fenxi[][] ={ {-1, -1, 2, -1,-1, -1, -1, -1, -1,-1,1}, { -1, -1, -1, -1, -1,-1,0, -1, -1, -1,-1 }, { -1, -1, -1, 3,-1, -1, -1, -1,-1,-1,-1}, { -1, -1, 12, -1, 9, -1, -1, 4,10,11, -1}, { 5, -1, -1, -1, -1 ,-1 ,101,-1,-1,-1,-1},{-1,-1,12,-1,9,-1,-1,-1,10,6,-1},{102,7,-1,-1,-1,102,102,-1,-1,-1,-1},{-1,-1,12,-1,9,-1,-1,-1,8,-1,-1},{104,104,-1,-1,-1,104,104,-1,-1,-1,-1},{-1,-1,12,-1,9,-1,-1,13,10,11,-1},{105,105,-1,-1,-1,105,105,-1,-1,-1,-1},{103,7,-1,-1,-1,103,103,-1,-1,-1,-1},{107,107,-1,-1,-1,107,107,-1,-1,-1,-1},{5,-1,-1,-1,-1,14,-1,-1,-1,-1,-1},{106,106,-1,-1,-1,106,106,-1,-1,-1,-1}};
//************************************
AA(JTextArea a)
{text1=a;}
//****************输出结构************
int jianyan(char b)//寻找分析表的列坐标
{
int k=N.length;
for (int j = 0; j < k; j++)
{
if (b == N[j])
return j;
}
return -2;
}
void printz()//输出状态栈
{
for(int p=0;p<=ii;p++)
{
String pp=state_stack[p]+" ";
text1.append(pp);
}
}
void printf()//输出符号栈
{
String h=" ";
text1.append(h);
for(int p=0;p<=u;p++)
{
String pp=symbol_stack[p]+" ";
text1.append(pp);
}
}
void printy()//输出语义栈
{
String h=" ";
text1.append(h);
for(int p=0;p<=u;p++)
{
String pp=grammer_stack[p]+" ";
text1.append(pp);
}
}
void print_grammer_right(int pv,int bv)
//输出每个产生式右边;
{
for(int p=0;p<bv;p++)
{
String pp=grammer_right[pv][p]+" ";
text1.append(pp);
}
}
void emit(String a,String b,String c,String d)
//四元式 输出
{
String dd=" 四原式输出是:("+a+","+b+","+c+","+d+")";
text1.append(dd + '\n');
}
//**************栈的结构**************
void state_push(int a)
{
if(ii<39 )
{ii++;state_stack[ii] = a;}
}
void symbol_push(char a)
{
if(u<39)
{
u++;symbol_stack[u] = a;
}
}
void grammer_push(char a)
{
if(y<40)
{
y++;
symbol_stack[y] = a;
if(a=='i') grammer_stack[y]=chaxun(iweizhi);
else if(a=='E')grammer_stack[y]=Eplace;
else if(a=='F')grammer_stack[y]=Fplace;
else if(a=='T')grammer_stack[y]=Tplace;
else if(a=='A')grammer_stack[y]=Aplace;
else grammer_stack[y]="_";
}
}
//***************出栈结构*************
void state_pop(int zhan[])
{ ii--; }
char symbol_pop(char zhan[])
{
char p=symbol_stack[u];
symbol_stack[u]=' ' ;
u--;
return p;
}
void grammer_pop(String zhan[])
{ y--; }
//************************************
String chaxun(String iwei)//输入标识符的在符号表里边的位置,找到相应的符号;
{
StringTokenizer fenxi1=new StringTokenizer(pp);
String token="";
while(fenxi1.hasMoreTokens())
{
String xx=fenxi1.nextToken();
if( xx.compareTo(iwei)==0)
{ token=fenxi1.nextToken();}
}
return token;//返回标识符的真值,比如a,b,c;
}
//***********进行规约的函数**********
void guiyue(int m)
{
String a="",b="",c="",d="";//四元式输出所需要 的参数 T1;
int k=m-10 ;//k为规约到哪一状态
int j=0;//j为产生式右边字符的个数
int jj=0;//jj为产生式左边字符的个数
char q='*';//q为产生式左边的字符
switch(k)
//看规约到哪个产生式,j为产生式右边字符的个数;jj为产生式左边;q为产生式左边的字符;进行四元式值得初始化;
{
case 1:
jj=0;j=3;q='A';a="=";
b=grammer_stack[u];c="";
d=grammer_stack[u-2];
Aplace=Eplace;break;
case 2:
jj=1;j=3;q='E';
if(h==name.length)h=0;
else h++;
//取中间变量,当数组中的中间变量都用完时循环取用; a="+";b=grammer_stack[y-2];
c=grammer_stack[y];
Eplace=name[h];d=Eplace; break;
case 3:
jj=2;j=1;q='E';
Eplace=grammer_stack[u];break;
case 4:
jj=3;j=3;q='T';
if(h==name.length)h=0;
else h++;a="*";
b=grammer_stack[y-2];
c=grammer_stack[y];
Tplace=name[h];
d=Tplace;break;
case 5:
jj=4;j=1;q='T';
Tplace=Fplace;break;
case 6:
jj=5;j=3;q='F';
Fplace=Eplace;break;
case 7:
jj=6;j=1;q='F';
Fplace=grammer_stack[y];break;
}
String ppp=" 用"+q+"-->";
text1.append(ppp);
//写到文本中
print_grammer_right(jj,j);
//打印字符串右边的部分;
for(int p1=0;p1<j;p1++)
//将规约好的产生式出栈,对应的语义,状态分别出栈
{
char kk=symbol_pop(symbol_stack);
grammer_pop(grammer_stack);
state_pop(state_stack);
}
ppp="进行归约";
text1.append(ppp);
symbol_push(q);
//将规约式左边的符号入符号栈;
grammer_push(q);
//入语义栈
int l=jianyan(q);
//调用函数,查询slr表对应的列坐标
int g=state_stack[ii];
//取出状态栈的栈顶元素
int ru=fenxi[g][l];
//查询slr表找出所对应的状态,
pp="且将状态"+ru+"入栈";text1.append(pp);
state_push(ru);
//蒋新状态入栈;
if(a!="")
//如果需要四元式输出的话,将其输出;
emit(a,b,c,d);
else text1.append( " "+'\n');
}
//***********输出函数**************
void Output(String a,FileWriter out)//向文件里写东西;
{
try{ out.append(a+"\n"); }
catch(IOException e)
{ System.out.println(e); }
}
//************************************
void error(FileWriter file,int t,String d)
{
String ss= " 第"+t+" 出错"+d+"是多余的";
text1.append(ss+'\n');
Output(ss,file);
}
//**********词法分析函数**************
//**********建字符表整数表************
String jianbiao(String s,String bj,FileWriter file,FileWriter file1)
//查询符号表看新识别出的标示符是不使已经存在;
{
int n=0;
//如果已存在n为1;如果不存在为零;
int vvv=-1;//
String token=" ";
//用来记录所识别处的标示符
String v="";
StringTokenizer fenxi=new StringTokenizer(s);
while(fenxi.hasMoreTokens())
//循环查询看是否有存在;
{
vvv++;
String xx=fenxi.nextToken();
if( xx.compareTo(bj)==0)
{
n++;
String p=String.valueOf( (vvv-1)/2);
//计算此标识符在符号表里的位置
iweizhi=p;
//将位置赋值给全变量iweizhi;
token="(i,"+p+") ";
Output(token ,file);
//调用函数写入二元式表
break;
}
}
if(n==0)
//如果在符号表里不存在
{
weizhi++;
//符号表共有的符号数加一;
v=weizhi+" "+bj+" ";
pp=pp+v;
//将记录符号的字符串更新;
s=s+v;
Output(v ,file1);
//调用函数将新的符号写入符号表
token="(i,"+weizhi+") ";
iweizhi=""+weizhi;
Output(token ,file);
//将符号写入二元式表
}
id="i";
//给全局变量id 赋值,以便语法分析器对其进行分析;
return s;
}
//**********识别标识符函数************
int Isalpha(char ch[],FileWriter file,FileWriter file1,int f,int t,FileWriter file2)
{
String biaoliu=" int 1 char 2 float 3 void 4 const 5 for 6 if 7 else 8 then 9 while 10 switch 11 break 12 begin 13 end 14 ";
StringTokenizer fenxi=new StringTokenizer(biaoliu);
int i=f,tt=0;String token="";
for(int j=f;j<ch.length;j++) {
if(((int)ch[j]>47&&(int)ch[j]<58)||((int)ch[j]>64&&(int)ch[j]<123))
//用ASC值判断输入的是不是字母或数字
{
token=token+ch[j];
i++;
}//i加一表明当前的符号串由两个字符或多个字符组成
else break;
}
while(fenxi.hasMoreTokens())
//查看此字符串是不是保留字
{
String xx=fenxi.nextToken();
if( xx.compareTo(token)==0)
{
token="("+token+","+fenxi.nextToken()+") ";
tt=1;
}
}
if(tt==0)
//如果不是的话,调用函数进行写入
{
kk=this.jianbiao(kk,token,file,file1);
token="(i,"+weizhi+") ";
}
return i;
}
//*********特殊字符识别函数 + * *******
int Isother(char ch[],FileWriter file,int i,int t,FileWriter file1)
{
int p=0;
String a="+ 19 * 21 ( 24 ) = rlop # 44";
StringTokenizer fenxi1=new StringTokenizer(a);
String token="";
//如果输入的字符是可以识别的标示符时,
for(int f=i;f<ch.length;f++)
{
token="";token=token+ch[i];
while(fenxi1.hasMoreTokens())
{ String xx=fenxi1.nextToken(); if( xx.compareTo(token)==0)
{ id=token;token="("+token+",) ";
p=1;
i++;
}
f++;
}
}
if(p==0)
{
token="";
ll++;
String n="第" + t+"行 "+ch[i] +"无法识别的特殊符号 ";
Output(n,file1);
e++;
i++; }
//如果是不可识别的 写入错误表,错误个数加一;
this.Output( token,file);
return i;
}
//*********词法分析总函数******
void Initscanner(char ch[],FileWriter out,FileWriter ouf,FileWriter ouc,int t)
{
int n=0;int p=0;int g=0;int hh=0;int x=0;
if(i<ch.length)
{
if(((int)ch[i]>64)&&((int)ch[i]<123))
{
i= this.Isalpha(ch,out,ouf,i,t,ouc);
}
//调用的是符号判别函数
else
{ i= this.Isother(ch,out,i,t,ouc);}
//调用特殊字符判别函数
}
}
//************************************
void fenxi(String s)//分析总过程
{
int t=0;
File file = new File(s);
//要分析的文件名称
try
{
String ys="danciliubiao.doc ";
//三个 输出表,二元式输出,符号表输出,错误输出
String fh="symbol_stackbiao.doc";
String cw="错误分析表.doc";
File yu=new File(ys);
File yu1=new File(fh);
File yu2=new File(cw);
int d=0;
FileWriter out=new FileWriter(yu);
FileWriter ouf=new FileWriter(yu1);
FileWriter ouc=new FileWriter(yu2);
FileReader in = new FileReader(file);
BufferedReader in2 = new BufferedReader(in);
String str = "";
while ((str = in2.readLine()) != null)
//逐行进行分析
{ t++;
StringTokenizer fenxi1 = new StringTokenizer(str);
while (fenxi1.hasMoreTokens())
//每一行中逐词进行分析
{ String BB="---------------------------语法分析过程----------------------------";
text1.append( BB+ '\n');
ii=-1;u=-1;y=-1;i=0;
//每分析一个表达式各个变量重新初始化;ii为状态栈栈顶指针,u符号栈,y语义栈
state_push(0);
symbol_push('#');
grammer_push('#');
//开始将开始符号入栈
String ss = fenxi1.nextToken();
ss=ss+'#';
//给表达式加结束符
char x='0';int f=0;
String SS="状态栈 符号栈 语义栈 动作说明";
text1.append(SS+ '\n');
char zxl[]=ss.toCharArray();
lookhead=zxl[0];
int p=zxl.length;
Initscanner(zxl,out,ouf,ouc,t);
//进行词法分析,out
//二元式文件,符号文件,错误输出文件
do
{
if(ll==0)
//当单词是可以识别时,进行循环语法分析
{
if(f<p&&ii>=0)
//f是已经识别的字符个数,p为表达式的总个数;当ii>0即符号栈不为空时;
{
printz();
//将三个栈打印输出
printf();
printy();
int g=-1;
char aaa[]=id.toCharArray();
//将词法分析识别出的单词i,或+,*。(,)..赋值给数组
lookhead=aaa[0];
//取第一个元素赋值给lookhead调用查询函数得到slr表的列坐标
int m=jianyan(lookhead);
int k=state_stack[ii];
//取状态栈的栈顶元素; if(k<15&&m<11)
//一共有十五个状态,十一个列元素,当不越界时
{ g=fenxi[k][m];
if(g<100&&g>0&&ll==0)
//进行移进动作
{ state_push(g);symbol_push(lookhead); grammer_push(lookhead);
//分别入栈
f++;
Initscanner(zxl,out,ouf,ouc,t);
//重新调用词法分析,识别下一个字符
SS=" 状态"+g+"进栈";
text1.append(SS + '\n');
}
else if(g>100&&ll==0)
{guiyue(g);}
//规约,ll=0,可以分析
else
if(g==0&&ll==0)
//当分析成功时:
{
SS="分析成功";text1.append(SS + '\n');
x='#';
}
else
{
if(lookhead=='#')
{
state_pop(state_stack);
symbol_pop(symbol_stack);
grammer_pop(grammer_stack);
}
//当输入字符串是a=a+b+#时,将最后一字符调过,返回去分析前面的
else//当在中间出错时,直接调过,不回调分析
{ f++;
Initscanner(zxl,out,ouf,ouc,t);
//调用词法分析分析下个单词
}
error(ouc,t,id);
}
}
}
else
//识别a+n#这种情况;
{
SS="分析 不成功,表达式错误";
text1.append(SS + '\n');
break;
}
}
else { //当不能识别的时候
SS=zxl[i-1]+"单词不能识别,跳过";
text1.append(SS + '\n');
Initscanner(zxl,out,ouf,ouc,t);
ll=0;
}
}while(x!='#');
//次表达式分析完毕
}
}
out.close();
ouf.close();
ouc.close();
}
catch (IOException e)
{ System.out.println(e); }
}
}
class JieMian extends JFrame implements ActionListener
{
JButton bCompile=new JButton("编译");
JButton bOut1=new JButton("保存");
JButton bOut2=new JButton("二元式输出");
JButton bOut3=new JButton("错误处理");
JButton bOut4=new JButton("符号表输出");
JTextArea bText1=new JTextArea();
JTextArea bText2=new JTextArea();
JieMian(String s){
super(s);
bCompile.addActionListener(this);
bOut1.addActionListener(this);
bOut2.addActionListener(this);
bOut3.addActionListener(this);
bOut4.addActionListener(this);
Container pane=getContentPane();
pane.add(new JScrollPane (bText2));
pane.setLayout(null);
bText1.setBounds(0,0,2000,40);
pane.add(bText1);
bText2.setBounds(0,50,2000,400);
pane.add(bText2);
bCompile.setBounds(50,500,150,40);
pane.add(bCompile);
bOut1.setBounds(250,500,150,40);
pane.add(bOut1);
bOut2.setBounds(450,500,150,40);
pane.add(bOut2);
bOut3.setBounds(650,500,150,40);
pane.add(bOut3);
bOut4.setBounds(850,500,150,40);
pane.add(bOut4);
setVisible(true);
setBounds(0,0,2000,2000);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
validate();
}
public void actionPerformed(ActionEvent e)
{
if(e.getSource()==bOut1)
{
File file = new File("hello.txt");
try
{
FileWriter out=new FileWriter(file);
String ss=bText1.getText();
out.write(ss);
out.close();
}
catch (Exception ee)
{ ee.printStackTrace(); }
}
else
if(e.getSource()==bOut2)
{
File file = new File("danciliubiao.doc");
try
{
bText2.setText("");
String s = null;
FileReader in = new FileReader(file);
BufferedReader intwo = new BufferedReader(in);
int n = 0;
if (e.getSource() == bOut2)
{
while ((s = intwo.readLine()) != null)
{
bText2.append(s + '\n');
}
in.close();
intwo.close();
}
}
catch (Exception ee)
{ ee.printStackTrace(); }
}
else
if(e.getSource()==bOut3)
{
File file = new File("错误分析表.doc");
try
{
bText2.setText("");
String s = null;
FileReader in = new FileReader(file);
BufferedReader intwo = new BufferedReader(in);
int n = 0;
if (e.getSource() == bOut3)
{
while ((s = intwo.readLine()) != null)
{
bText2.append(s + '\n');
}
in.close();
intwo.close();
}
}
catch (Exception ee)
{ ee.printStackTrace(); }
}
else
if(e.getSource()==bCompile)
{
try{
bText2.setText("");
AA a=new AA(bText2 );
a.fenxi("hello.txt");
}
catch (Exception ee)
{ ee.printStackTrace(); }
}
else
{
File file = new File("符号表.doc");
try
{
bText2.setText("");
String s = null;
FileReader in = new FileReader(file);
BufferedReader intwo = new BufferedReader(in);
int n = 0;
if (e.getSource() == bOut4)
{
while ((s = intwo.readLine()) != null)
{ bText2.append(s + '\n'); }
in.close();
intwo.close();
}
}
catch (Exception ee)
{ ee.printStackTrace(); }
} }
}
class meng
{ public static void main(String args[])
{ JieMian j=new JieMian("语法分析"); }
**测试文档**
```c
a+b*(a+c)
b*a
**程序测试数据和结果:**

**二元式输出、错误处理及符号表输出如下:**

### 六、课设总结
  在这次课程设计过程中,由于时间有限,对于词法分析方面采用的方法不是很容易扩展,在语法分析的过程中嵌套了语义分析的操作。本程序实现了对输入内容进行词法分析,产生二元式,符号表,再根据二元式及符号表进行语法和语义分析,生成四元式及输出动作过程的功能,实现此次课程设计的基本功能。
  在编写程序的过程中,经过仔细分析我明白了分析表的构造和分析原理。本以为不是很难,但当我把写好的程序敲到电脑上并运行时才发现,在程序中我遇到了很多实际的小问题,比如程序中三个栈的输出问题,因为是三个栈分别定义的,所以经常会出现输出结果正确但位置不正确的问题。用数组模拟栈,又出现了比如数组越界,输出的分析过程移进或者规约滞后一个状态等问题,但经过和老师同学的交流,这些都一一解决。同时在此次编程的过程中,也让我学到了一些常用的小技巧。比如,用输出语句测试程序哪块出错。
  和老师、同学的交流也使得我更深入的理解了课本上的有关知识。正向别人所说的,“实践出真知”,没有实践的过程,就不可能完全理解课本的知识。因此,在以后的学习过程中,要努力把理论和实践相结合来学习,这样自己的专业基础才会越来越扎实。
















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











