






 本文介绍了一种名为TeAAL的语言和生成器,它将稀疏张量加速器设计简化为映射Einsum的级联形式,通过FiberTree操作来表达内容保留变换。TeAAL提供了一种通用框架,用于精确评估稀疏加速器的性能和内存需求,对比了与现有工作的优缺点。
本文介绍了一种名为TeAAL的语言和生成器,它将稀疏张量加速器设计简化为映射Einsum的级联形式,通过FiberTree操作来表达内容保留变换。TeAAL提供了一种通用框架,用于精确评估稀疏加速器的性能和内存需求,对比了与现有工作的优缺点。
TeAAL: 一种语言和模拟器生成器,用于稀疏张量代数加速器的简洁和精确的规范和评估。
1 INTRODUCTION
RTL: verbose and often difficult to comprehend
a block diagram and an accompanying natural language description :imprecise and often incomplete
TOOLS: 遵循Halide【39】提出的模型 目标算法和映射
Halide: A Language and Compiler for Optimizing Parallelism,Locality, and Recomputation in Image Processing Pipelines
密集张量加速器建模技术无法支持稀疏情况:对不规则稀疏数据进行有效编排和计算时出现了新的复杂性。
稀疏加速器:
**OuterSPACE ** 稀疏-稀疏矩阵乘法 (SpMSpM)分成生成、排序和消耗表示部分乘积的链表数组;
Gamma 两个阶段的相同内核,这两个阶段与高基数硬件合并器连接以有效地处理数据;
SIGMA 不规则地仅用非零数据填充 PE 数组
Sparseloop [52] 可以对可在单个深循环嵌套中描述的加速器进行建模,使用抽象分布函数来建模稀疏性,而不是精确建模实际输入集的行为。
本文贡献为制定稀疏张量代数加速器:设计如何表示为映射 Einsum 的级联(有向无环图或 DAG)以及这些 Einsum 中组成张量的内容保留变换
e.g. OuterSPACE 和 Gamma 都可以通过将矩阵乘法的 Einsum 重写为几个相关的 Einsum 来描述:
相同点:重新排序中间张量的维度以改善局部性
不同点: 每个Einsum的映射方式
TeAAL(张量代数加速器语言)
采用被描述为映射 Einsum 级联的加速器,并生成命令式中间表示 (IR),将张量变换描述为对表示为 Fibertree 的张量的原始操作;
使用实现级规范(例如,描述张量格式)来增强 IR,以生成处理真实张量的准确、经过验证的性能模型。
本文贡献概括为:
- TEAAL 规范语言
- Simulator 生成器 Teaal–>IR
- 结果验证准确性 memory traffic/performance/energy
- 加速潜力 accelerators for vertex-centric programming
2 BACKGROUND
稀疏张量代数的关键属性&通用设计决策
MOTIVATION: 非正式比较的困难性
2.1 稀疏张量和纤维树
秩:行+列
点 :包含标量值的张量中的逻辑位置
数学上,张量没有稀疏性/CSR压缩格式,
纤维树 张量=一棵树 每个层次=一个标记秩
纤维每个层次含有多个纤维,共享坐标的元素集合
元素 坐标/有效负载对 叶子处:标量 中间节点:引用
模型纤维的(整数形状表示从零到该整数的开区间);
秩的(该秩中所有纤维shape的集合);
张量的(每个秩的shape的列表 按秩的顺序排列。)
纤维树的一个优点是它们稠密和稀疏张量均可处理。
稠密张量的纤维树的每个坐标都存在于树上。
稀疏张量的纤维树 可以省略所有具有空有效负载的元素(零值或空纤维)
为了对特定的设计进行建模,所有的纤维树都被简化为具体的表示,如CSR或COO
秩的扁平
秩的重组
秩的调配 swizzle
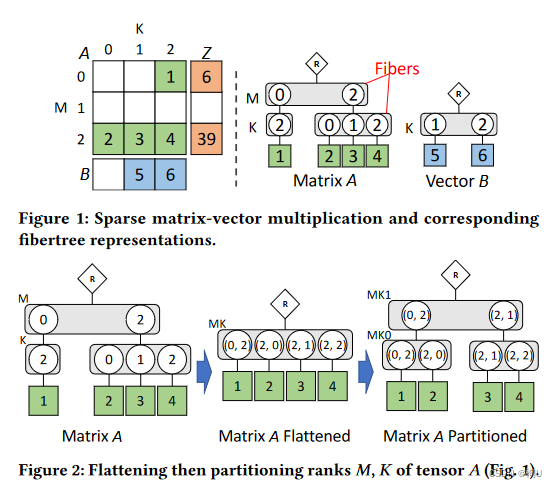
2.2 带扩展Einsums的张量代数
Einsum 使用以扩展爱因斯坦求和符号编写的方程来表达加速器执行的各个计算
1、输入、输出及秩
2、每个计算的点的迭代空间
3、特定空间
Einsum的一个实现必须遍历这个空间中的每个点。对于每个点,使用输入操作数( A、B)中的指定点计算右边的操作( × )。然后取结果,填充左手边指定的位置( Z )。由于K秩不出现在输出张量中,Einsum会试图重复填充同一点( Zm )。Einsum语义通过将该点的多个值依次归约为一个值来解决这个问题。
在B中增加了一个新的秩N -> MKN的空间
2.3 映射硬件加速器
映射将 Einsum 的计算调度到有限的硬件资源上的任务,以联合优化吞吐量、延迟(执行时间)、功耗等所需的组合。
1、循环顺序 数据局部性->内存访问成本
2、分组 纤维树通过根据分割迭代空间划分纤维来对这些子集进行建模。
3、工作预设 指定如何遍历 时间&串行/空间&并行
2.4 加速稀疏张量代数
稀疏张量代数通常被压缩,去除Zero元素–>纤维树缺少有效负载pair
压缩的好处:
yield significant savings in storage and data transfers and avoid ineffectual compute operations that have no impact on the result and can be safely skipped
实现好处的前提:移除无效计算,增加设计复杂度、对内存延迟/带宽的敏感性提高、负载不平衡
TABLE I custom hardware solutions but 不好使!
3 OVERVIEW
1、实现稀疏张量代数加速器的简明规格说明
2、在实际稀疏张量上计算该加速器的效率
映射Einsums的级联(有向无环图; DAGs)+张量的保留内容变换
3.1 Einsum级联可以代表多相加速器设计
看似单一的张量代数核(例如,矩阵相乘)常常被实现为一个DAG的操作,而这些操作中的每一个都可以表示为一个产生和消耗中间张量的Einsum。
1)直接卷积
2)Toeplitz展开:将卷积转换为矩阵向量或矩阵矩阵相乘,在脉动阵列和数据并行处理机(如GPU )上很常见。
生成T的Einsum的RHS反映了I在Einsum中如何被索引以进行直接卷积。
放松了对I的访问和对F的访问同时发生的要求。
独立映射,从而为构建和使用中间张量提供了新的自由度。
ps. Einsums的这一序列并没有说明这两个阶段是如何重叠的。
3)卷积之外级联可以表示的实现方式。
目前支持 take(.)将交集从计算中解耦出来 Table ii列了别的

3.2 张量上的保留内容变换
(sparse accelerator behaviors e.g., work scheduling, splitting, sorting/merging),可以表示为纤维树上的核心操作,为稀疏张量数据编排提供策略。
content-preserving如果它不改变张量的内容,即纤维树叶子处的值的集合,但改变了用于访问每个值的坐标系。
OuterSpace running: 以外积的方式输入;部分积写入链表;排序化简;约简结果
- Sparse Tensor Splitting and Work Scheduling
适应不规则的稀疏性:在边界出现的时候,改变划分标准
fibertree rank swizzles -->efficient concordant traversal
1)稀疏恢复策略将纤维树中某一层的每根纤维进行拆分,使得每根新纤维具有相等的元素个数(模余数)。
基于占有率划分后的每根光纤的坐标范围是不规则的。
为了确保多个张量的分区具有匹配的坐标范围用于协同迭代,基于占有率的分区使用a leader-follower paradigm:分区的坐标范围被选择,使得领导者张量的分区具有相等的占有率,所有跟随者张量采用这些范围。
2) 缺点:may still result in partitions with varying occupancies because a partition must end where its parent fiber ends.
改善:flattening 通过先合并扁平化的行列,然后重新分配元素来缓解这种不平衡
以Fig.3举例 partition和flattning在并行的work scheduling的用途
矩阵A : 256 非空元素
Processing Tile:16组,每组16个
Flattening and Partitioning(见18/19行代码)
TeAAL规范描述了 KM1和KM0的空间并行性
- Transposition, Sorting, and Merging.
转置
1)使得更有效的一致(相对于不和谐)遍历成为可能。
Concordant traversal
2)中间张量的计算中:
根据顺序或非顺序存储,并在多大程度上建立中间张量后再被使用决定是否使用
Fig.4
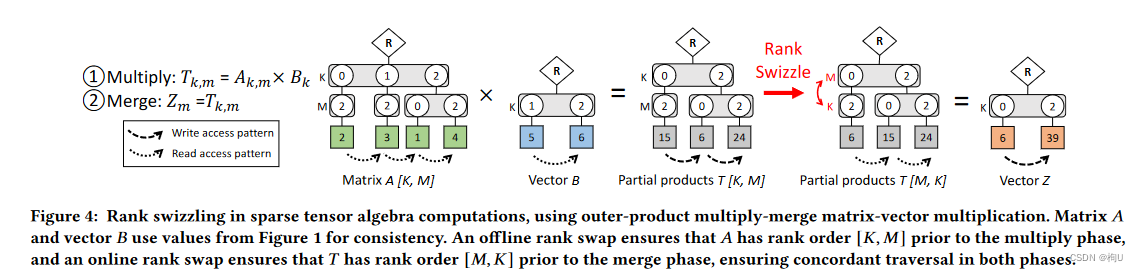
默认情况下,TeAAL会自动推断秩转义以保持一致遍历
4 GENERATING THE MODEL
Section 3证明generality;Section4证明 lower down to具体的表示和特定的硬件
额外的规范format, architecture, and binding及其与Einsum、mapping的结合来生成可执行的模型。
4.1 映射Einsum到硬件层面
- Format
TACO[9]??先阐释了现有的,再说TeAAL(a more modular specification)的具体种类,再说好处
纤维的种类:
a format type
a layout
cbits/pbits/fhbits coordinates/payloads/fiber headers
纤维具体化为 坐标数组、有效负载数组//结构数组
TeAAL支持三种类型:
Uncompressed 不需要存储坐标,根据有效负载推断(设0)
Compressed C
Combination B:the coordinates are uncompressed and the payloads are compressed
好处:支持很多通用格式+支持多个格式的联合+(补充说明)小范围修改制定特定功能格式
-
Architecture(inspired by Timeloop)
在Timeloop支持的组件基础之上,定义了more: Table 3

-
Binding
1)每个 Einsum 必须绑定到单个加速器拓扑。
2)每个存储组件,其绑定描述了其中的数据。
张量、配置、等级、类型、是否延迟访问元素或急切地访问元素(加载/存储访问时元素下方的整个子树),以及数据缓冲多长时间
3)一个存储组件可以有多个这样的绑定。 -
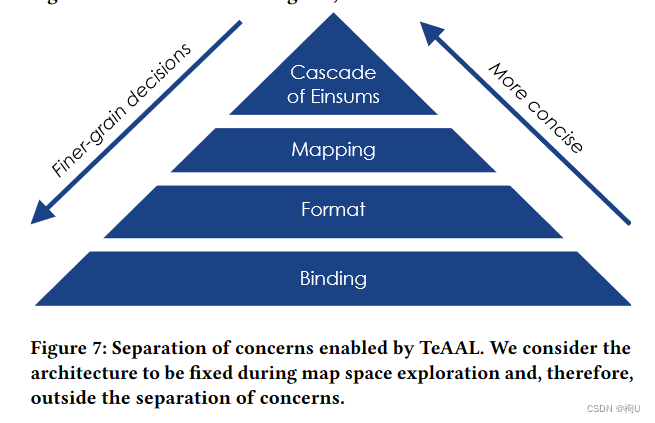
表达性和可拓展性 Fig.7
4.2 Specifying OuterSpace
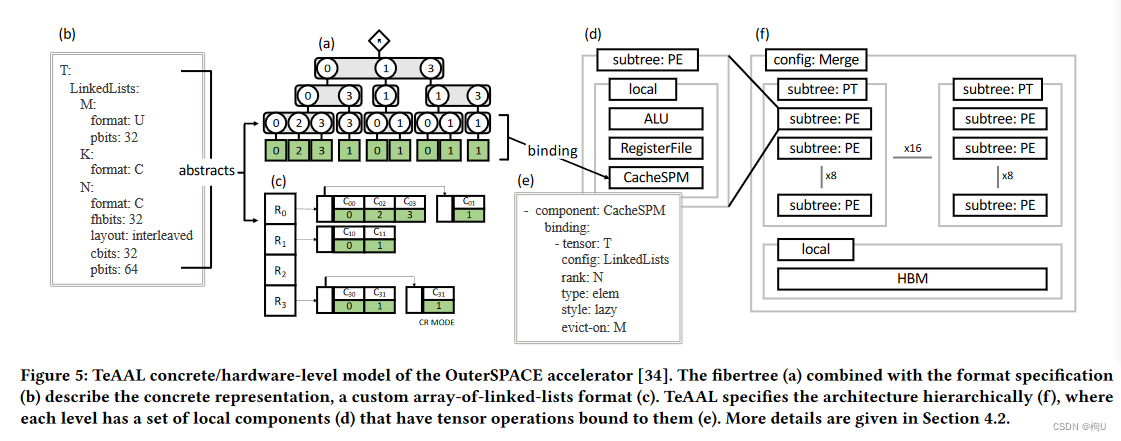
从通用到具体示例说明:OuterSpace
(a)fibertree T (b)张量的格式规范
(c)OS的自定义链表数组格式 Mrank指针数组由未压缩的有效负载数组给出;Nrank fhbits描述链表指针;layout坐标和有效数组对的相邻;cbits和pbits描述了数据位数 (d)PE=ALU+register file+L0 scratchpad (e)binding (f)entire accelerator topology.
4.3 Simulator Generation 看图说话!
how to put everything together: 1)对于级联中的每个Einsum,Te AAL将Einsum方程与其映射信息相结合,产生一个可执行的循环嵌套。2)确定了所需的每张纤维树操作(例如rank swizzling )和每秩纤维协同迭代器。3)Te AAL利用这些信息构建一个循环嵌套的数据流图,并将其归结为Python中的一个嵌入式DSL作为纤维树操作执行计算。4)得到的编码是Einsum级联(即,一系列的循环,每个Einsum一个)的命令式表示,它可以直接评估表示为fibertree的真实张量。5)见后文
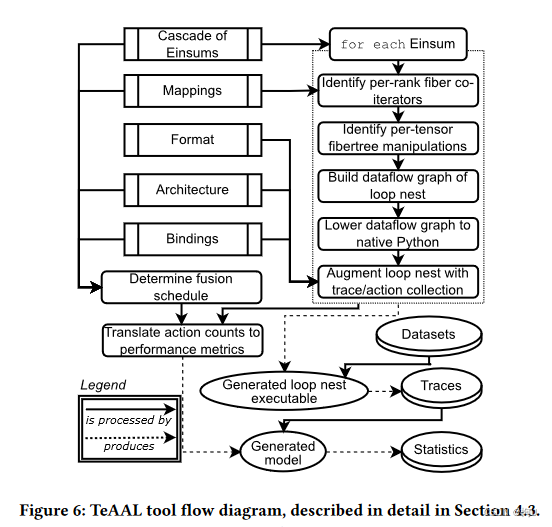
TeAAL处理加速器三阶段:
1)产生traces 哪些坐标和负载对被接入
TeAAL结合三个信息,决定
执行时,映射后的循环嵌套在纤维树(存储真实的张量数据)上执行计算,并生成每个坐标和每个载荷被访问时的轨迹。
–>充分捕捉每个真实张量的特定稀疏模式对核性能的影响,显著提高了TeAAL的保真度。
2)计算动作数 TeAAL提供了单部件动作计数模型库,调用并传递属性,得到相应计数
3)计算总的 得到运行时间和耗能
Accelergy【51】? 将动作计数转化为能量
当满足三个条件时,Einsum 可以融合在一起
①Einsum使用相同的加速器配置
②在第一个空间秩之前所有循环顺序中 时间秩相同
③非存储组件的不相交子集中
融合Einsum到单个块中;
所有动作数量相加 并计算每个
bottleneck分析 块的执行时间是最长组件的执行时间,级联的执行时间是所有块的执行时间之和。
5 ACCELERATOR SPECIFICATION
除了OuterSpace之外,其他三个较先进的加速器,以及Graphicionado [14] and GraphDynS [53] (Section 8), Eyeriss [8], Tensaurus [43], Flexagon [30], and DSTC [47]
Gamma行式加速器,使用紧密流水线的多重合并式架构
ExTensor在最内层采用内积式的混合数据流。
SIGMA深度学习加速器,使用基于占用的分区,仅将固定矩阵的非零元素分配给 PE,从而减少无效计算。
结合FIG.8代码 有点不懂???
6 EXPERIMENTAL SETUP
介绍张量 矩阵数据 硬件配置 及 比较标准
SIMULATOR VALIDATION
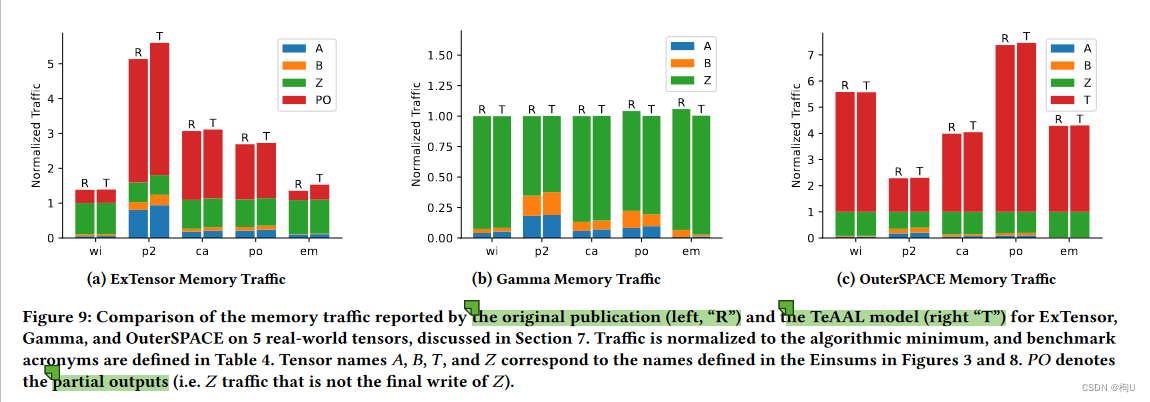
-
Memory Traffic Fig.9
low error
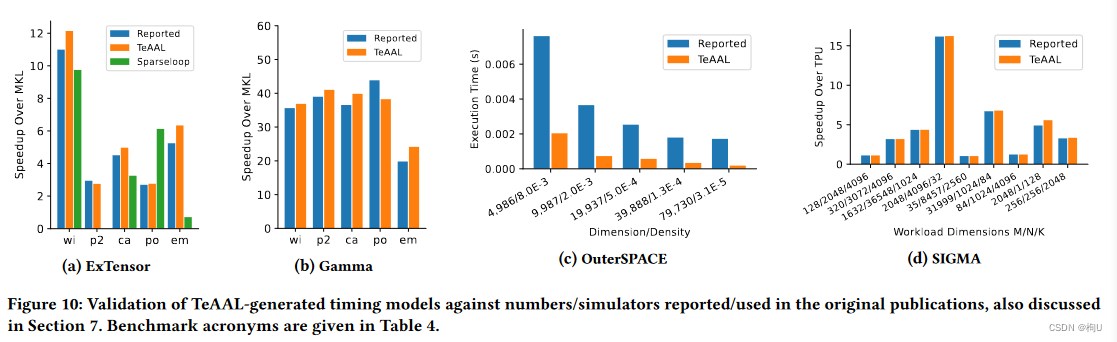
-
Performance Fig.10
(a)Sparseloop相关 有用
(a)(b)speedup Extensor/Gamma 还有error rate
(c) 这个error在哪里看啊????
在阐释图片的时候 相关联图片说明了/同时解释了不能够比较一些参数的原因! -
Energy Fig.11
IMPROVING GRAPHICIONADO
Grapicionado以顶点为中心的编程范式图算法加速器 Optimizer:GraphDynS
Fig 12(a)
processing phase
使用活动顶点A0选择需要处理的边SO ( Line 2 ),这些边的权重结合源顶点属性( Line 3 ),并减少为R (隐含于第3行)。
apply phase
更新顶点属性P0 / P1 (第6行),并使用更新顶点(第7 ~ 8行)的掩码M创建新的活动顶点集合A1。
Fig 12(b) 利用 R 的稀疏性,向级联添加新的 Einsum;
增加MP+可调的P0+Mmask --> 缩减了内存流量
保留256位图
进一步将图的格式从边-列表表示更改为 CSR–>去除了源顶点 ID 的不必要重载,并去除了不使用的边权重加载算法(例如 BFS)
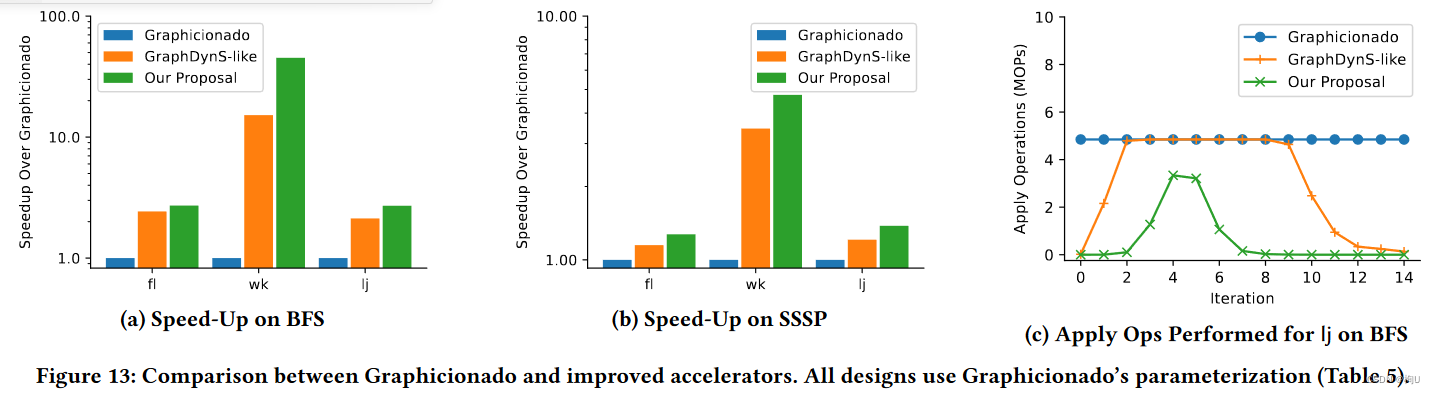
Fig 13 迭代次数相关
(a)本文方案在BFS上比GraphDynS平均提高了1.9倍
(b)方案在SSSP上比GraphDynS平均提高了1.2倍
(c)解释原因
虽然GraphDynS的位图方法减少了当活动顶点集较小时所需的应用操作的数量,但本文方案也能在活动顶点集较大时跳过应用操作。
小小的综上:TeAAL 可以表达稀疏张量代数之外的领域中的设计。
9 RELATED WORK
Table 6 在稀疏张量上进行计算建模的框架 用途效果的比较
1、STONNE [31] 是 DNN 加速器的循环级建模框架 数据驱动 支持的唯一稀疏工作负载是 SpMSpM。
2、Sparseloop [52] 和稀疏抽象机 (SAM) 对用 Einsum 语言表达的稀疏工作负载进行建模,但保真度低于 TeAAL。
优缺点比较:
| SparseLoop | TeAAL |
|---|---|
| 具有灵活的硬件后端,并将架构规范、数据统计模型、稀疏优化(例如交集 [16])和用户指定的映射作为输入。它返回性能和能耗的估计值。 | 直接对实张量进行评估。这使得 TeAAL 能够实现更高保真度的建模 |
| 不支持许多对稀疏计算很重要的功能,例如级联 Einsum、缓存、转秩。 | 增加了模拟器运行时间。 |
SAM 受众:由类似于 TeAAL 支持的硬件模块组成的体系结构,在 SAM 硬件上对加速器数据流进行建模。
3、CIN-P一种映射器语言,当与渐近成本模型和自动调度器结合使用时,会生成可以使用 TACO [23] 进行编译的映射。由于它使用渐近分析,映射器仅考虑映射决策空间的一小部分,包括循环顺序和融合。
4、为现有的可编程设备编译内核
| Mosaic | TeAAL |
|---|---|
| 支持对通用内核进行建模 | |
| 不支持 TeAAL 所支持的一些习惯用法,例如,允许仿射表达式作为张量索引并且仅支持一维中间体 | 不允许用户将现有的库调用与用户定义的内核混合 |
10 CONCLUSION
TeAAL:
如何将最先进的稀疏加速器表示为映射 Einsum 的级联以及 Einsum 组成张量上的内容保留变换。
使用组合这些概念+生成器(从语言到模拟 FiberTree 操作的可执行的生成器)+用于比较和讨论设计的通用语言的社区
未来工作:
1、支持更多的工作负载和加速器 增加迭代算法或非线性函数
2、将TeAAL设计空间探索:分层,低保真度模型探索整个设计空间,promising部分精细探索
高保真度 高效率 但自动探索:将加速器描述为Einsums 的级联
3、支持其他后端
APPENDIX
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









