






CANDLES: 用于低能耗稀疏神经网络加速的通道感知的新型数据流-微架构协同设计
摘要:目前最先进的稀疏加速器可以描述为Pixel - first或Channel - first加速器,每个加速器都有其独特的数据流和压缩格式来辅助其数据流。前者在更新神经元部分和消耗大量能量,而后者在处理索引元数据时消耗大量能量。这项工作引入了一种新的微体系结构和数据流,通过采用像素优先压缩和通道优先数据流来协调这些权衡。所提出的微体系结构具有更简单的索引生成逻辑,并结合了累加器缓冲层次结构和具有低布线开销的交叉开关。压缩格式和数据流促进了神经元更新的高时间局部性,进一步降低了能量。最后,我们引入跨处理元素的工作分区,无需离线分析,自然地实现负载平衡。与四个最先进的基线相比,所提出的体系结构CANDLES显著优于三个,并与第四个基线的性能相匹配。在能量方面,CANDLES比这4个基线节能2.5 × ~ 5.6 ×。
INTRODUCTION
提高加速器能量效率的两个机会:
1、双边稀疏:激活函数+权重的稀疏性–>结构复杂和/或未充分利用的体系结构
–>催生了多个DNN加速器
(压缩输入激活和权重来提高功率、吞吐量和面积,然后使用不同的数据流策略对压缩后的数据进行计算。)
2、数据流:确定一个循环排序、平铺和分区,以最大化数据重用和最小化数据移动
本文提出了新的微架构数据流协同设计:
捕获了先验稀疏加速器的最佳元素,并定义了一个导致高重用和高利用率的数据流。
双边稀疏加速器的分类:
-
Pixel-first
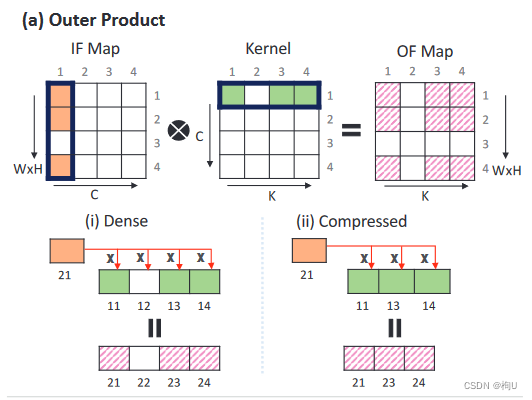
采用外积策略用于计算,对稀疏数据进行压缩,使得每个通道(( ii )中的核表示)的非零激活函数和核在像素维度中有序。

算法1展示了Pixel - first架构使用的简化伪代码。读取一个通道对应的非零激活向量和非零权重向量,执行笛卡尔积。
优点:任何激活都可以与任意权重相乘,从而得到若干输出神经元对应的部分和。
部分和的地址仅通过将行索引替换为激活的行索引和将列索引替换为内核的列索引来获得。
因此,Pixel - first架构具有较高的激活/内核复用率和简单的索引机制。
缺点:
1)高能耗:这些数据流在写回之前很少甚至没有部分和的减少/重用,从而导致高能耗。
2)逻辑复杂:笛卡尔乘积导致部分和会有不相关的输出神经元,需要大的累加器缓冲区和路由逻辑。
例如,SCNN和STICKER是在访问交叉开关和/或多进制累加器缓冲区时消耗了超过80 %的片上总能量。
这种高能量大部分是由于频繁地遍历 直接联系到每个库和进入相关的库的长导线造成的。
3)PE内和PE间利用率不足:
PE内利用率不足是由于权重或激活向量没有完全填充时,在特征图和核边界处造成的。
PE间利用率不足是由稀疏度和分配给每个PE的工作不同导致的负载不均衡造成的。
4)边界处不存在的乘法 浪费计算比例大:外积模型人为地在特征图边界处会导致不存在的乘法,即使使用padding也无法避免。对于双边稀疏模型,这些结构上浪费的计算可以贡献到总计算量的6.5 %。 -
Channel-first
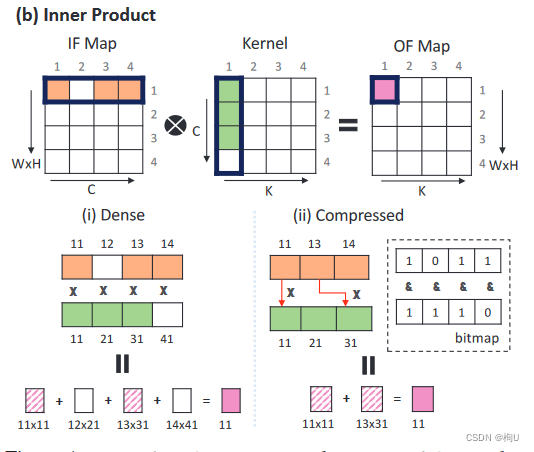
采用内积策略。它压缩了稀疏的数据结构,使得每个像素(见激活函数(橙色))和权重(绿色)的非零激活和权重在通道维度上有序(图1b的( ii ) )。

算法2给出了Channel - first架构使用的简化伪代码。读取一个非零激活向量和一个像素对应的非零核向量进行内积运算。
例子:包括SparTen [ 16 ],SNAP [ 58 ],[ 59 ]和StitchX [ 29 ]。
优点:1)开销小:在每个处理单元( PE )中,通道优先架构使用输出稳定的数据流来辅助内积操作。
因此,在写回累加器缓冲区之前,可以在本地减少输出神经元对应的大量部分和,从而避免了Pixel - first架构中普遍存在的交叉开关和多进制累加器缓冲区的开销。
缺点:1)需要额外辅助:由于数据结构在通道维度上被压缩,因此需要一个辅助条件来寻找匹配激活和内核索引对对应于同一个通道(算法2中的if -条件)。
2)时间长 :if条件的失效增加了额外的循执行时间,导致PE内部利用率不足。
3)匹配逻辑复杂:为了防止这些循环的浪费和提高PE内的利用率,典型的Channel - first架构使用辅助的参数匹配逻辑只预取满足if条件的操作数。这种if条件使得Channel - first索引生成/匹配逻辑比Pixel - first架构更加复杂。
例如,SparTen中的索引匹配逻辑消耗了近46%的片上功耗和63 %的片上面积。
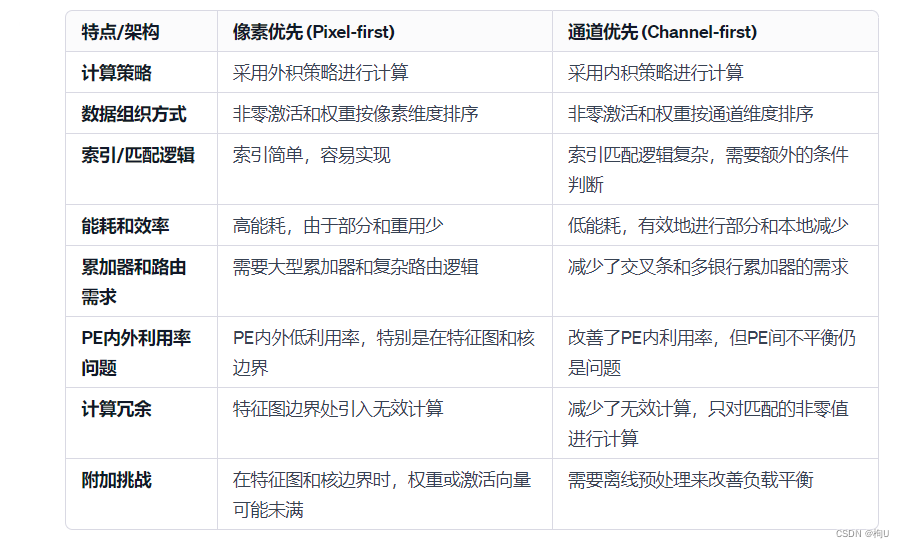
综上:P可以实现更简单的参数匹配逻辑,C可以实现有效的聚合。
CANDLES, a microarchitecture and dataflow co-design that combines the best of these two approaches.
贡献:
1)CANDLES采用Pixel - first压缩和Channel - first数据流,利用简单的交叉开关实现高效的内部连接,同时避免了辅助的参数匹配逻辑;
2 ) 提出了一种两级累加缓存结构,第一级( L1 )采用一组低能耗的寄存器文件,第二级( L2 )采用6KB的多分组累加器缓存;
3 ) 引入了Tiled Pixel-first ( TP )压缩算法,提高了部分和更新的时间局部性,从而提高了L1的命中率;
4 ) 我们在PE上对不同的工作分区进行了实验,并确定了规则分区,在没有离线预处理的情况下实现了高水平的负载均衡;
5 ) 探索设计空间,以确定最佳匹配的网络和缓冲区层次结构。
效果:评估该架构,并通过模拟一组不同的基于图像的DNN的执行来评估该架构。
比目前最先进的架构高达5.6倍的能量效率,同时达到峰值吞吐量的86 - 99 %。
BACKGROUND
基线:像素优先架构SCNN,STICKER 和通道优先架构SparTen,SNAP 。
A. Pixel-first
- SCNN:SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks
SCNN 有64个PE与邻居连接。每个PE有一个4 × 4的乘法器单元网格。一个输入激活缓冲器和一个权重缓冲器。每次提供四个非零激活来执行笛卡尔积。相应地,这些产物通过一个16 × 32的交叉开关引导到32个块中的16个银行块,形成累积缓冲区。
每次在每个PE的输入激活子集tile上使用激活函数平稳数据流。其中累加缓冲器每次处理对16个部分和的读写操作,每个部分都被分配到一个独立的384字节的存储单元,因此占用了大量的电路资源。累加缓冲器是主要的能量贡献者,占加速器总能量的80 %以上。交叉开关和MAC操作是其他非平凡且大致相等的贡献者。
此外,SCNN通过为每个PE分配不同的Planar Tiles来选择数据流和并行化,表现出很高的PE负载不平衡。由于每个PE在其Planar Tiles中可能表现出不同的激活稀疏性,因此分配给每个PE的负载存在显著差异。这种负载不均衡导致了较高的PE利用率和较高的延迟。 - STICKER STICKER: An Energy-Efficient Multi-Sparsity Compatible Accelerator for Convolutional Neural Networks in 65-nm CMOS
STICKER 使用了九种不同的操作模式来处理跨层激活和内核的不同稀疏度。其次,由于STICKER的Pixel - first性质,没有利用部分和的短期重用。相反,所有的部分和都指向一个大的累加器缓冲区。
STICKER没有使用类似SCNN的多分组累加器缓冲区,而是使用2 - way集合关联PE来处理不规则数据。它对输入激活进行预处理和重组,以减少对累加器缓存资源的冲突。STICKER通过避免SCNN中的多进制累加器缓冲区,节省了显著的存储面积。然而,大型蓄能器缓冲器仍然是主要的能量贡献者。进一步地,由于蓄能器缓冲资源的冲突,pe下降了8 %。
B. Channel-first
- Spar Ten:SparTen: A Sparse Tensor Accelerator for Convolutional Neural Networks
Spar Ten由多个PE组成,每个PE执行一个Inner Join操作。内核被划分并预分配给PE,而激活则广播给所有PE。在PE内部执行的内部连接对应于单个输出神经元,从而避免了PE内部的交叉开关和多个部分和更新。
然而,对于内部连接,需要一个non-trivial电路来识别匹配的非零元素。
SparTen的主要优点是它比SCNN大约多4 ×,具有更好的负载均衡。
SparTen依赖离线分析,通过稀疏性对内核进行排序,并使用贪心算法将其映射到PE,以平衡每个PE的负载。由于核函数在PE间进行了置换,输出神经元在被表示为压缩之前经历了一次洗牌。 - SNAP:SNAP: A 1.67 – 21.55TOPS/W Sparse Neural Acceleration Processor for Unstructured Sparse Deep Neural Network Inference in 16nm CMOS
SNAP有4个核,每个核有一个7 × 3的PE阵列,每个PE有3个MAC单元。
SNAP在bundle中处理激活和内核。关联索引匹配( AIM )电路处理激活和核的束,以找到匹配的非零激活核对。与Spar Ten不同,一个PE执行的计算可以对应多个输出神经元。
SNAP使用两级部分和约减( PE层和核心层)来处理所有的输出神经元。第一层PE水平(或PE内)通道降维。第二层精简是通过在互连网络上移动数据来实现核心级的(或PE间)像素维度精简。这种两级归约技术减少了回写流量。
AIM单元是一个折衷方案- - AIM单元中较大的比较器尺寸会对面积和功耗产生负面影响,但会导致有效的参数匹配,从而提高PE内的利用率。然而,SNAP并没有像SparTen那样解决PE间的未充分利用开销。
CANDLES
A. Motivation
三个挑战:
1 ) 高效的PSUM聚合
2 ) 简单的索引逻辑
3 ) 负载均衡
在Channel - first架构中,通过使用软件和硬件相结合的技术来解决负载均衡问题。
在Pixel-first架构中,以低效率的PSUM聚合为代价便于简单的参数匹配逻辑,而通道优先架构则相反。
PSUM 聚合效率 归因于部分和中存在时间局部性。
(PSUM聚合:它指的是在执行卷积操作时,将多个乘法运算的结果(即部分和)累积或聚合起来,以得到最终的输出值。在CNN中,这通常涉及到多个输入特征图(输入数据)与多个卷积核(权重)之间的乘法,其结果被累加以形成输出特征图的一个元素。高效的PSUM聚合可以显著提高计算效率和降低能耗。)
CANDLES使用微架构数据流协同设计来采用两种架构风格中的最佳,并解决所有三个挑战。
时间局部性:
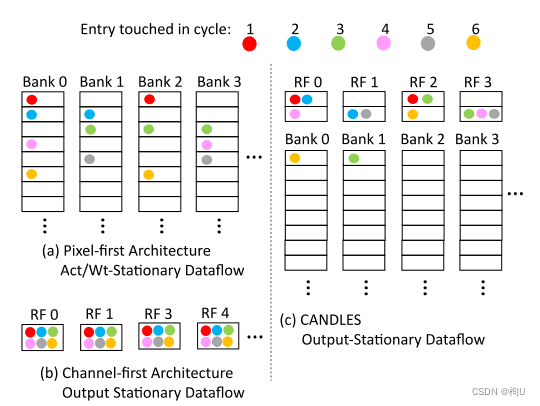
着色点显示了累积缓冲区中每个项被更新时的周期。每个块和注册表文件( RF )中的block表示部分和项。
1)Pixel - first中,在一个周期内,更新被分散到多个累积缓冲区中。
连续循环中更新的部分和不同–> 需要较大的累加器缓冲区–> 导致较高的每次访问能量
这种具有很少时间局部性的部分和更新模式在图2a中显示,并且是累加器缓冲区占主导地位的能量贡献的关键因素。
2)Channel - first中,首先遍历通道维度,
连续循环中的部分和对应于同一个输出神经元,只需要一个小的项累加器(一个寄存器文件)来捕获这个模式(见图2b)。
通道(Channel):指的是输入数据的一个维度,通常用于表示颜色通道(如RGB图像中的红、绿、蓝)或特征图的不同层。在卷积神经网络中,每个卷积层都会产生多个通道的输出,这些输出称为特征图,每个通道捕捉输入数据的不同特征。
像素(Pixel):指图像中的最小数据单元,通常代表图像中的一个点。在处理图像数据时,每个像素包含了特定的颜色信息,对于彩色图像,这通常是通过多个通道(如RGB)来表示的。
3)CANDLES中,我们保留Pixel - first压缩策略。
然而,数据流被修改为更接近Channel-first输出稳定型,
由于首先遍历激活和权重,连续周期中的部分和更新表现出更高的时间局部性。
–>一个2级结构的累加缓冲器 其中,L1具有高命中率
如图2c所示,前6个周期的更新大部分被本地化到每个块/缓冲区少量条目的L1寄存器文件中。
??、??其实有点不懂
B. High-level 综述
四个关键创新的协同组合:
1)实现了Pixel-first compression and Channel-first dataflow ( PFCF ),以实现高效的内部连接,而不需要复杂的索引匹配逻辑。
2)两级累加缓冲区捕获了部分和的重用;
3)新的压缩算法保证了连续部分和之间的高局部性;
4)内存分区方案可以在不需要软件优化的情况下保证负载均衡。
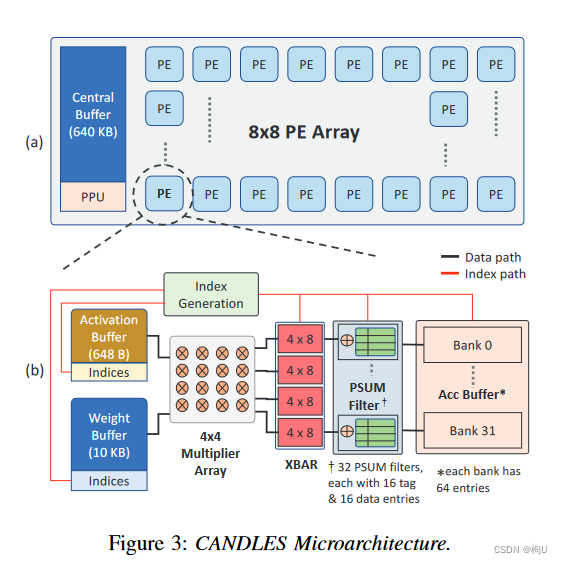
由一个Central Buffer和一个8 × 8的PE网格通过mesh网络连接而成。
1)Central Buffer:负责将每一层的激活分布到网状网络中的各个PE上。配备了Pool和ReLU模块。
2)PE:每个PE由3个缓冲区组成,用于存储激活函数、权重、部分和、4x4乘法器阵列、PSUM滤波器、简单的交叉开关结构和索引生成逻辑。
核心是PSUM滤波器,它捕获了部分和的重用,以实现能量有效的累积。
为了减少回写流量,我们还支持跨PE减少。
在一个循环中,激活和权重缓冲区为4x4乘法器提供输入数据结构,生成16个部分和。
索引生成逻辑通过笛卡尔积并行地计算这些部分和的输出神经元地址。
得到的部分和存储在PSUM滤波器或累加器缓冲区中。
单个PE由片外DRAM 填充 权重。
一旦加载,在取下一个集合之前,用所有可用的激活完全耗尽加粗样式一组权重(高层的的权重平稳数据流)。相反,激活函数被访问/被送入中央缓冲区。
C. Pixel-first Compression and Channel-first Dataflow
数据流对时间局部性的影响:
提出的数据流是专门为具有分级累加器缓冲区的微体系结构量身定做的。
为了减少common-case的重用距离,我们在CANDLES中引入了以下的数据流。
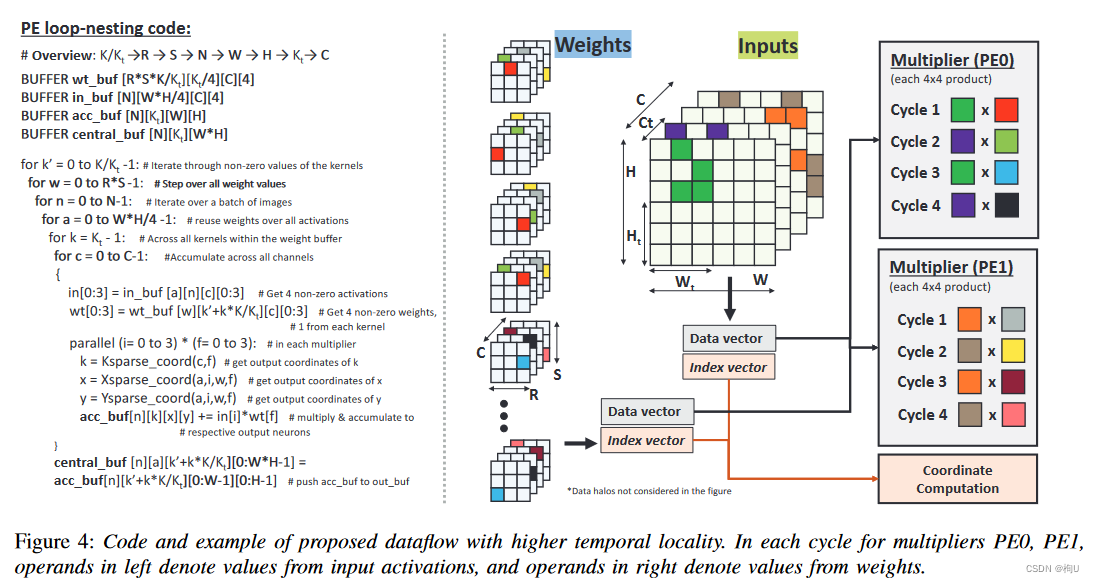
每个PE在连续的循环中处理四个对应于C_{t}通道的非零激活。
PE0从第一个Ct通道(绿色和紫色)分配4个非零激活,PE1从下一个Ct通道(橙色和浅褐色)分配4个非零激活。
在第一个循环中,乘法器阵列(如PE0 )由前4个(绿色)激活函数和前4个内核的(红色)第一个权重(同样,均来自一个input channel)馈送。
在下一个循环中,我们切换到不同的输入通道,同样从前4个内核中获取前4个(紫色)激活和第一个(浅绿色)权重。因此,前两个循环触及的部分和属于相同的4个输出通道。
多次处理之后,将大多数更新集中到累加缓冲区中的一组小元素上。
每个周期从它们的缓冲区中获取一组新的激活和权重,增加了激活和权重缓冲区中消耗的(低)能量。
当所有PE完成对Ct通道的局部缩减后,每个备用PE通过网格网络将其部分和转移到相邻PE进行PE间缩减。接收方PE利用加法器将接收到的部分和与其累加缓冲区中的部分和相加。在PE间归约过程中,接收PE不执行乘法操作。
可缓存性:连续周期内部分和之间存在显著的重叠
–>少量的部分和缓存–>每个块的单个条目中产生非常高的命中率。(图2c)
“高命中率”指的是在使用缓存时,所需的数据已经存在于缓存中的频率。具体来说,在CANDLES数据流中,连续周期产生的部分和(PSUMs)有很大的重叠,这意味着多次访问相同的数据。因此,当这些数据存储在缓存中时,处理单元(PE)在访问这些数据时能够频繁地在缓存中找到它们,而不是从主存中重新获取,从而提高了效率和性能。
实际应用中,非零激活函数的位置在每个通道中不会完美排列–>产生更多的misses或需要更多的条目以获得较高的命中率。当包含权重稀疏性–>部分和更新更加分散,再次要求每个块有多个条目,以产生高命中率。
解决:我们提出tiled-compression techniques,将部分和的散射限制在一个很小的集合。
D. PSUM 滤波器
通过重新访问连续循环中相同输出神经元的部分和,上述数据流输出最平稳。–>提供了一个将累加缓冲区划分为两个级别的机会。
-
最近访问的部分和被移动到一个小的标记缓存( PSUM Filter )中,以服务于期望的高时间局部性;
-
其他具有较长重用距离的部分和被放置在一个6 KB的二级缓冲区中,类似于基线SCNN (见图3)中的累加缓冲区。
Section V中指出:即使每个存储体有 16 个或更少的条目,PSUM 过滤器也能产生很高的命中率。
它实现的方式为一组带有标签的寄存器。我们将 PSUM 滤波器布置在交叉开关的输出端口附近(图 3)。这减少了 PSUM 过滤器访问的长互连遍历。
实现细节:每个存储体的 PSUM 过滤器是完全关联的。
每个条目都与一个 6 位标签关联,该标签指向 L2 组中的 64 个条目之一。
索引生成逻辑为每个生成的产品生成一个 11 位标签 - 其中 5 位标识存储体,6 位标识存储体中的条目。标签检查与输出神经元索引生成一起执行。索引生成是与较长延迟的笛卡尔积 并行执行的。
因此,当产物出现时,命中/未命中信息就可得到了。部分和通过访问过滤器或 L2 继续执行。这两个结构都可以在一个周期内访问,因此一次过滤器的失误不会影响性能。
当过滤器未命中时,过滤器和 L2 都执行并行读取-修改-写入,同时交换过滤器和 L2 中的条目。
命中率对替换策略参数不敏感。
E. Tiled Pixel-first Compression
传统的像素优先压缩方法可以显著影响 PSUM 过滤器的命中率。????
典型的内核或特征图中–>零点分布不均匀–>可能会导致非零异常值–>严重影响 PSUM 过滤器命中率
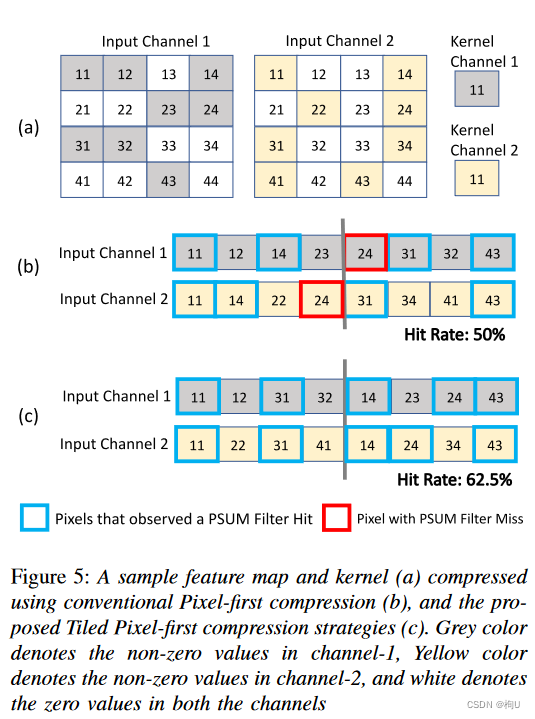
图 5a :在最先进的架构中使用像素优先压缩的传统方法(图 5b)
非零值与编码元数据的索引向量(图中未显示)一起存储在数组中。
每个单元格中的数字表示像素维度的坐标,而颜色表示不同的通道。
假设我们有一个密集的 1×1 内核,其通道数与示例输入特征图相同。
CANDLES 数据流一次穿过通道维度的四个非零值。
在两个周期中,处理来自两个通道的四个非零值。
当我们遍历通道维度时,像素 11 和 14 在两个周期中都有涉及。
存储在第一次迭代时 PSUM 中的像素 在第二次迭代开始之前被逐出。
原因:在典型的部署场景中,我们第一次遍历 64 个通道,观察到的双峰重用距离,该值保留在缓存中的概率非常低。
在第二次迭代期间,像素 31 和 43 被导通,导致总 PSUM 过滤器命中率为 50%,完全执行特征图。
虽然 Pixel-24 在两个通道中也具有匹配的非零值,但此压缩策略并未捕获其局部性。这是第一个通道的Pixel-23 中的非零值导致的结果。
虽然两个通道具有相同数量的非零值,但它们在像素维度上的分布并不均匀。
由于我们一次只取四个非零值,不均匀的密度分布会导致数据流无法捕获Pixel 24 的局部性。–>导致命中率低于 40%。
解决办法:在压缩前对像素进行分组可以显著降低分布的不均匀性–>获得更高的PSUM Filter命中率( > 85 % )。
Tiled Pixel-first (TP) compression
将特征图平铺成多组–>非零值每次存储一个tile
将先前讨论的示例特征图平铺成两个相等的部分,每个部分只有四个列中的两个。
图5c展示了使用TP压缩策略仅使用非零值的压缩数据结构,命中率高达62.5%。
原因:在像素上放置边界框限制了压缩数据结构中非零值的散射。
优点:PSUM过滤器的命中率与瓦片分区的数量成正比。
缺点:瓦片尺寸过小会导致PE内部利用率过低。
事实:瓦片大小为7 × 4可以在不牺牲大量PE内部利用率的情况下保证较高的命中率。
备注:空的特征图或核–>为特征图和内核的每个通道分配一个有效位–>完全跳过 各自通道的计算
F. PE间的负载平衡 讨论如何在多个PE之间进行工作划分
CANDLES为每个PE分配相同数量的非零激活(在一般情况下)和一个N × N的权重划分。
负载不平衡:由各个PE的核分区的稀疏度变化决定的。
与Pixelfirst架构对比:其中每个PE都有一个重复的权重副本,负载不平衡由激活分区的稀疏度变化决定的。
区别:
- 激活的稀疏度:对于每幅图像,在网络的不同层中动态变化–> 在运行期间很难确定激活在PE间的理想分布
2)权重的稀疏性:在推理过程中不会发生变化,允许我们进行离线分析。
分区设计空间:
卷积层所需的计算量可以表示为 输入通道×核× A × W,A为2D输入通道中非零激活的集合,W为2D核通道中非零权重的集合。
图4为例:PE0和PE1都只分配了2个(输入)通道和8个内核,表示成’“2×8”。
在CANDLES中,总的计算量必须在64个PE之间进行拆分。我们认为一个核的一个通道中的权重没有跨PE进行划分,即我们没有对W进行划分。
在一个典型的具有多个通道和多个核的卷积层中,
1)采用" 2 × 8 "的划分意味着每个PE接收到的通道和核的份额很小,但是每个输入特征图通道的份额很大。
2)采用**" 64 × 64 "分区意味着每个PE接收大量的通道和内核,但每个输入特征映射通道的份额很小。
较小的输入特征通道可能意味着每个PE需要处理更多的通道和核,但每个通道的数据量较小。这可以导致负载更均匀地分布在PEs之间,提高整体计算效率。
实证分析:最小化负载不平衡
为了简化控制逻辑和避免任何离线分析,我们试图通过定期绘制线来进行分区。
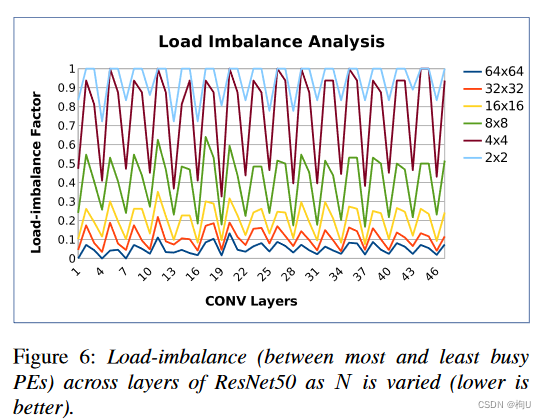
图6量化了多个" N × N "分区的这种负荷不平衡。
分析图6:
1)使用大的N显然是有益的;对于N = 64,负荷不平衡度在10 %以下。
这种划分在不同的层之间是一致平衡的,不像SCNN在后期特征图收缩时看到更高的负载不平衡。
2)多重因素在这一实证观察中发挥作用。各个核通道的稀疏度确实存在较大差异。
假设一个卷积层有3 × 3 × 128 × 128的权重。在这种情况下,每个核中每个通道的非零权重的数量将是16384个整数的列表,范围从0到9。
如果每个PE被分配这个列表的小部分连续子集**,则PE之间的负载变化会比分配大部分子集时更大。换句话说,大样本平均了核通道间的高变化,从而大的N较好。通过使用大的N,每个PE被分配到输入特征图的较小部分。
较小的特征图样本可能导致每个PE中非零激活元组的变化量更大—>将激活分布在N个通道上,使得样本比来自少数通道的激活更多样化。
G. 微架构设计的选择
新的PFCF数据流和新的工作分区对所提出的微体系结构的影响。
- 权重和激活缓冲器:
每个周期读取一个新的权重和激活元组,并随着重用距离的变化显示激活和权重重用。
我们调整权重和激活缓冲区的大小,以捕获产生的重用模式。
考虑到我们对大多数层选择了" 64 × 64 "的划分,一个PE在每层一次分配4K个权重。包括索引元数据,我们分配了一个10 KB的缓冲区来存储这些权重。
这些权重从DRAM中取出,完全重用,然后从DRAM中移除,为后续的4K权重腾出空间。
循环了PE的64个不同通道后,激活函数被重新访问–>需要激活缓冲区足够大,可以存储256个激活( 648B ,包括索引元数据)。 - 累加缓冲区:
累加缓冲区大小的设计:从最坏情况下的部分和散射场景入手
由于我们在权重缓冲区中使用了7x4 ( = 28 )的瓦片大小和64个唯一的内核,最坏情况下的场景容纳了1792个部分和( 28x64 )的最大散射。对于24位的PSUM,需要一个5.25 KB的累加器缓冲区,由于内存编译器的限制,将其舍入到6 KB。 - 中心缓冲区:
一旦一组权重被带入权重缓冲区,它必须被分配给该PE的所有激活消耗。
由于激活缓冲器每次只能处理256个条目,所以它必须定期重新填充。为了适应这种激活重用模式,激活缓冲区被组织为一个两级层次结构。
第一级640B 捕获了大部分的重用。
第二级是所有PE共享的640 KB中央缓冲区:它负责第一级的周期性二次填充,并在激活中捕获更长距离的重用模式。
中心缓冲区之前有一个预处理单元( PPU ),负责应用激活函数和创建压缩输出特征图。
当跨通道聚合发生在PE级别时,跨卷积滤波器( ex:3 × 3 )的聚合通常在Central Buffer中执行。由于最终聚合的PSUM只存在于中央缓冲区中,因此我们只在其旁边放置pool / ReLU单元。
在不修改PE微体系结构的情况下,只需增加中央缓冲区的大小就可以实现对更大批量的支持。 - 更简单的交叉开关
数据流:一个周期内产生的16个部分和,被拆分为4个部分,每个部分对应一个不同的输出通道。每部分中的四个PSUMs被分配到8个PSUM过滤器中,通过一个小型的4×8交叉开关(crossbar)。明显小于SCNN实现的16 × 32交叉开关。
进入每个4×8交叉开关的四个PSUMs对应于四个不同输入像素与单个核条目之间的乘法,结果形成了4个唯一指标对应的PSUM。–>在同一个周期内计算的两个PSUM不会有相同的输出指标。 - 激活元数据:
由于初始层的特征图较大,使用存储w和h 索引的朴素方法,元数据开销可以十分巨大。
改善:使用混合RLE方法,对于每4个非零激活,我们使用绝对指数和RLE风格零指数的组合。1)第一个激活的指数存储其w和h指数;2)其余三个存储自最后一个非零激活以来的零出现次数。
每个瓦片只有7x4,使用一个5-bit的值来存储瓦片中每4个非零激活中的一个绝对索引。瓦片中其余的非零激活使用类似于RLE的4位零索引。
由于PE每次处理一个瓦片,我们需要在索引生成逻辑中存储一个2-byte的瓦片索引来计算瓦片的偏移量。 - 核元数据:
典型的核通常是较小的( 1 × 1或3 × 3)–>存储所有非零权重的绝对指标。
每个非零权重的4位元数据足以存储我们所有基准的绝对指标。 - 浪费的计算量:
在执行外积运算时,一些涉及特征图边界元素的乘法运算对输出神经元没有贡献–>降低了有效吞吐量,浪费了包括CANDLES在内的所有Pixel - first架构的能量。
(影响相对较小,特别是考虑到最近向小核维度发展的趋势。)
METHODOLOGY
相同资源/MAC单元数比较:CANDLES、SCNN、STICKER、SparTen和SNAP
- 能量和面积建模
Pixel-first architectures in Verilog
the multi-banked accumulator buffers’ overheads
the mesh interconnect
synthesized implementation of Channel-first architectures/ directly use the numbers
从多个带宽方面确保变量单一性 - 模拟器建模
考虑SCNN及其变体;
Sticker的CSR压缩;
… - 基准测试
1)4个CNN工作负载:VGG16 [44], ResNet-50 [19] (ResNet50-A), Inceptionv1 [47], and MobileNet-v1 [23]
2)第五种稀疏核的工作负载:在ImageNet [ 22 ]上训练的ResNet - 50 ( ResNet50网络-AW )的一个公开可用的剪枝检查点。
3)评估双边稀疏性,我们对MobileNet ( MobileNet-v1-AW * )的前50 %接近零的权重进行了综合剪枝。
RESULTS
A. Energy
表1.。。。。,,,,
-
综合设计的重要性
考虑了具有一个或多个基元的CANDLES的几种变体- -数据流、PSUM Filter和TP - Compression。
图7a 以SparTen的能量为标准,绘制了每种变化对能量消耗的影响。
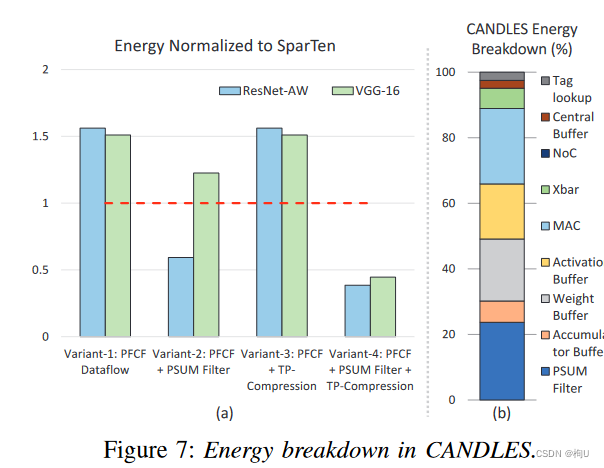
Variant-1:
现象:仅考虑PFCF的CANDLES 能耗比SparTen高达57 %
原因1)在没有TP压缩的情况下,大部分层的PSUM复用率在40 %以下。
2)由于没有PSUM Filter来捕获可用的重用,所有的部分和被重定向到大的累加器缓冲区,从而导致每次访问的高能量。
现象:在执行基准测试程序时,该变体比SCNN - E节能1.2倍,比SCNN - EP节能1.45倍。
原因:CANDLES具有更好的交叉开关结构、更高的MAC利用率和更高效的数据流。
Variant-2:
PFCF数据流+PSUM滤波器,但没有TP压缩
这限制了PSUM Filter的重用性,因为初始层具有较低的命中率(见图10b)。
V- 2介于1.3 - 2.6 ×比变式- 1节能。
Varient-3:
PFCF数据流+TP压缩,但没有PSUM
当使用TP压缩将PSUM复用提高到> 85 %时,由于没有PSUM滤波器来捕获这种复用,所消耗的能量与变体- 1相似。
Varient-4:全部考虑
现象:比SparTen节能2.6倍。
原因:PSUM Filter现在捕获了TP压缩所启用的所有部分和复用。由于PSUM - Filter的能量比访问累积缓冲区小8.7 ×,高复用率导致能耗降低。 -
能耗分析 图7b
图7b:每个组件在双边稀疏的ResNet50网络基准测试中的能耗的组成。其余的基准也观察到类似的能量分解。
新的数据流–>体积较小,但在其激活缓冲区耗能更多–>被累加缓冲器和交叉开关中较低的能量抵消。
CANDLES中更紧凑的交叉开关相比于基准SCNN交叉开关消耗了近3倍的能量。
互连线和PPU的能耗均小于总能耗(图7b中No C)的1 %
原因:1)除了执行深度卷积外,PPU的唯一目的是在处理下一层之前对输出神经元进行压缩。每个神经元只读取一次。由于计算次数比激活次数高一个数量级,因此PPU的能量占有率较低。
2)适用于互连到中心缓冲器;它只用于PE和中央缓冲区之间的单次数据交换,而由该交换发起的PE操作的数量要高几个数量级。
浪费计算:CANDLES由于其像素优先的压缩,与其他像素优先的架构一样,会导致架构上的浪费计算。然而,这些浪费的计算对CAN总能耗的贡献不足6.5 %。具有1x1维核的基准测试程序不存在浪费的计算。
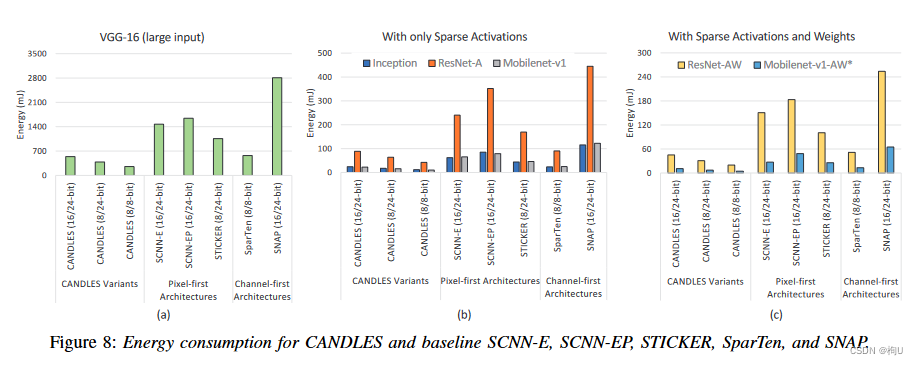
图8 CANDLES和基准架构( SCNN-E , SCNN-EP , STICKER , SparTen和SNAP)在执行基准应用程序时消耗的能量。(MAC&部分和的数据宽度)在SCNN中,每生成一个新的部分和都要访问交叉开关和累加缓冲区。这种对这些大型结构的频繁访问是SCNN能量的一个重要贡献。
SCNN - EP通过选择合适的瓦片大小来分配负载,保证了较好的并行性。这导致数据结构的写次数增加,因此与SCNN - E相比有更多的能量。
STICKER通过用组相联PE替换交叉开关和使用更小的累加缓冲区来减少面积。然而,与SCNN相比,这并不能节省大量的能量。在SCNN的累加缓冲区中,仍将部分和写入与单个块大小相似的累加缓冲区。此外,与SCNN类似,部分和是分散的,在MAC单元的旁边没有捕获重用。所有这些因素都对STICKER中的能量做出了贡献。SparTen使用Channel - first数据流,因此完全捕获了部分和在MAC单元附近的小寄存器中的重用。此外,它用一个简单的置换器代替SCNN中的大交叉开关,节约能源。然而,这种好处被使用复杂的折射率匹配逻辑所抵消。在SparTen中,将近46 %的片上功耗被优先编码器和前缀和电路所消耗。
SNAP类似于SparTen,是一种Channel first架构,其功耗和面积占折射率匹配逻辑的比例很高。此外,SNAP并没有像SparTen那样有效地捕获部分和的重用。这是因为PE内部的利用效率取决于参数匹配逻辑(关联指标匹配单元)中比较器的大小。增大比较器的尺寸会使面积和功率成二次方增加,不可取。或者,如果不在本地捕获部分和的重用,将导致访问下一级层次结构中较大的缓冲区。这些因素共同导致了SNAP的高能耗。CANDLES比SCNN - E,SCNN-EP,STICKER,Spar Ten和SNAP结构节能3.3 ×,4 ×,3.2 ×,2.5 ×和5.6 ×。
B. Performance
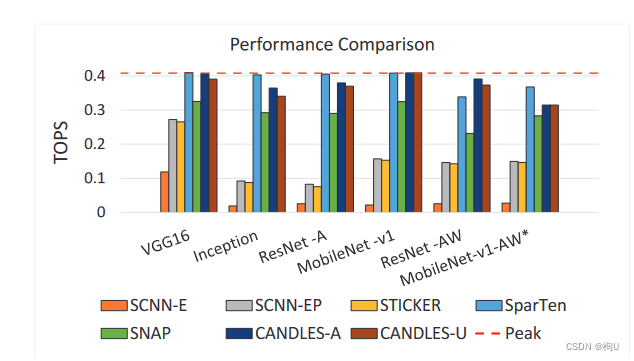
图9:吞吐量( Tera每秒操作次数)
两个变体:
CANDLES - A显示了CANDLES执行的所有计算的绝对TOPS,其中包括结构上浪费的计算。
CANDLES - U只考虑测量TOPS的有用计算。
现象:架构浪费的计算量占总计算量的比例在0 ~ 6.5 %之间。
在仅有稀疏激活的基准应用上,CANDLES的两个变体比SCNN - EP快4倍以上,
在同时具有稀疏激活和权重的ResNet - AW和MobileNet - AW *上分别快2.5倍和2倍以上。
原因:SCNN中PE内和PE间的利用率不足。SCNN - E比SCNN - EP慢了8 %。
现象:STICKER比CANDLES慢了5倍。
原因:CANDLES由于其高效的工作划分和缓冲区大小选择,实现了较高的负载均衡。
STICKER使用2 - way组相联PE进行部分求和累加。当发生冲突时,需要两个周期来更新部分和。虽然STICKER提出对数据进行洗牌以避免冲突,但并不能完全解决问题。STICKER分析表明,在基准应用程序的各层之间,冲突率可以在1 - 15 %之间。
SNAP
1)channel-first数据流保证了部分和在写回输出激活缓冲区之前被减少–>拥塞回写流量和输出激活缓冲区竞争的显著下降2)消除了PE内部的利用率不足,
3)广播总线施加的隐式障碍–>导致的PE之间的负载不平衡–>SparTen使用贪婪平衡技术和硬件协同优化解决了PE间
现象:CANDLES比SNAP和SparTen分别快68 %和15 %。
原因:CANDLES 不受隐式栅栏的限制,通过使用足够大的权重缓冲区来实现负载均衡。
现象:当考虑稠密核的稀疏激活时,SparTen可以比CANDLES快1.1倍。
原因:SparTen广播了允许所有PE同时完成计算的激活。
现象:1)对于单独的稀疏激活,Spar Ten的性能非常接近理想的峰值吞吐量。2)但CANDLES比SparTen少消耗10 %的面积。CANDLES在等面积比较(针对iso - MAC)上优于SparTen。
CANDLES在所有基准应用程序中运行在 峰值吞吐量的86 - 99 %。
微架构和分块优化共同作用总结:
通过更好的负载均衡(依赖于权重缓冲区的大小),提高了PE间的利用率;
通过高效的分块(取决于瓦片的尺寸),提高了PE内或计算的利用率。
较大的权重缓冲区导致每个PE的权重样本较大,这平均了内核之间的高差异,促进了PE间的负载平衡( F)。
理想的瓦片大小保证了每个PE中MAC的高利用率,促进了PE内部的负载均衡。
通过使用网格网络,CANDLES避免了基线中广播网络施加的隐式障碍。
瓦片大小对基线SCNN的影响 图9
SCNN - E代表基线SCNN的性能,SCNN - EP的瓦片大小由我们提出的方法获得。
现象:SCNN的性能比基线SCNN提高了2.5 - 7 ×。
原因:较好的平铺提高了PE的利用率。
虽然平铺有助于提高基线中PE内的利用率,但微架构的选择限制了它们在PE间获得更好的负载平衡。
CANDLES由于其微体系结构和平铺,比SCNN - EP至少快2倍。
C. PSUM-filter的灵敏性分析
PSUM滤波器的命中率随着各种参数的变化。
- 替换策略:忽略不计
包括LRU、Second Opportunity、LRU插入策略( LIP )和Bimode插入策略( ε范围为1 / 2 ~ 1 / 64的BIP) [ 36 ]。
由于部分和的双峰复用距离性质,替换策略对命中率的影响可以忽略不计:
非常短的重用距离总是被捕获,而非常长的重用距离不被PSUM过滤器捕获,无论替换策略如何。
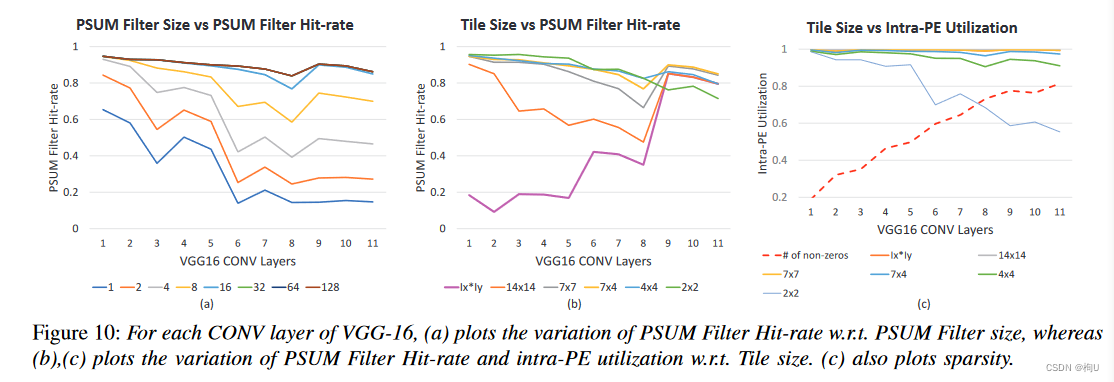
- PSUM Filter Size:
图10 (a) 给出了VGG16的每个CONV层在不同PSUM滤波器大小下的平均命中率。
层数越深,命中率越低。
命中率的提高在每个块超过16个条目时达到饱和。 - TP - Compression的瓦片(tile)大小:与PSUM Filter命中率之间存在反相关关系,但过小的瓦片大小会导致PE内部利用率不足。
图10 (b)显示了PSUM过滤器的命中率随瓦片大小的变化。
瓦片大小为Ix * Iy,表示无瓦片Pixel-first压缩的CANDLES。
优点:1)较小的瓦片将部分和的离散限制在较小的范围内,从而保证了部分和较好的局部性。
2)在压缩前对像素进行分组,可以降低输出神经元分布的不均匀性,进一步提高部分和的局部性。
图10 ( c )显示了瓦片尺寸的变化对PE内利用率的影响。
缺点:减少瓦片的大小会导致每个瓦片中出现的非零值更少。
减小到一个阈值–>将导致每个循环没有4个非零的激活来供给笛卡尔产物–>PE内的利用率不足。
结论:7 × 4的瓦片在保证较高的PSUM Filter命中率( > 85 % )的同时,对PE内利用率的影响最小。
- 循环tiling的空间性和复杂性:
每一层的PSUM滤波器命中率与该层激活的零点个数有直接的关系。
假设:瓦片大小与激活中的零点个数成反比关系。
tile size:PE内利用率最大化所需的最小非零值个数与该层中非零值所占比例的比值。
由于我们每个周期读取4个激活,因此我们至少需要每个tile有4个非零值来保证PE内利用率最大化。
选择tile size为7x4原因:超过99%的图像在每层中都有至少14 %的非零值。由于每个瓦片至少需要4个非零值,因此最小瓦片大小为4 / 0.14 = 28。
未来的设计可以根据稀疏度分布为每一层提供动态的瓦片尺寸。
例如,有50 %非零值的图层很可能分配给每幅图幅4 / 0.5 = 8个条目。
D. 更多讨论
密集&量化密集加速器:
虽然元数据是一个不小的开销,但CANDLES的好处远远超过了额外元数据的成本。
通过只访问非零操作数和执行非零计算,CANDLES与密集加速器相比,大大减少了计算量和数据移动开销。
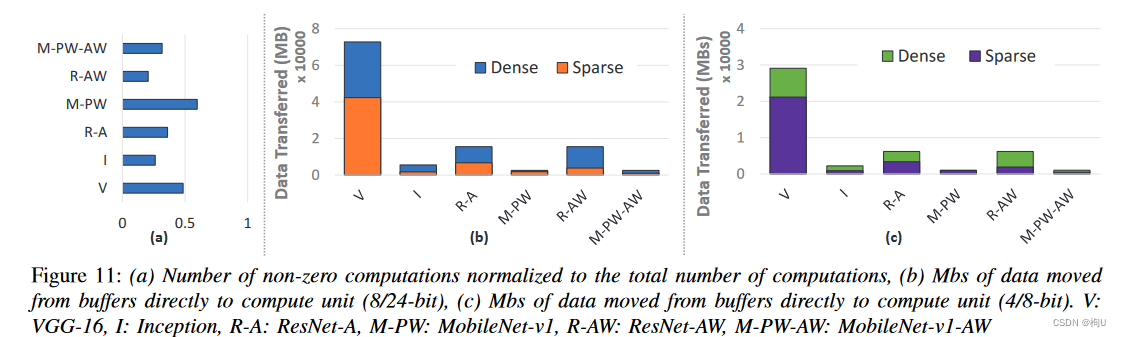
图11 (a)
现象:CANDLES在只有稀疏激活的情况下执行的稠密计算仅占总稠密计算的26 %,
而在稀疏激活和权重都存在的情况下执行的稠密计算高达总稠密计算的20 %。
好处:1)跳过具有零激活或权重的MAC的处理周期–>显著提高吞吐量。
2)节省执行MAC所消耗的能量,跨缓冲区移动数据中的大量能量份额也显著减少。
图11(b)(c)显示了从缓冲区直接传输到MAC的数据MBs,以执行密集和稀疏情况下的基准测试。
对于CANDLES,考虑了数据移动中额外的索引元数据.
在8 / 24位精度下,CANDLES最多可减少4倍的数据移动。
当元数据大小保持不变时,相对于稠密模型,稀疏模型的数据移动MBs随着精度的降低而增加。
MAC数量的减少–>与稠密模型相比,CANDLES在4位量化精度下可减少多达3倍的数据移动。
2 - bit量化的稠密架构可能会进一步缩小这种差距,但稠密架构在吞吐量和准确性等其他相关指标上可能与稀疏不匹配。
随着密集、量化和稀疏平台设计空间的不断发展,稀疏平台已经被证明足以构成Cerebras等商业设计的基础.
RELATED WORK
A. 和Baseline的相似性 要看SCNN/SNAP论文
1)与SCNN
使用了笛卡尔积,相似的总SRAM缓冲区大小,用于路由部分和的交叉开关。
2)与SNAP 一种通道优先的架构
采用的PE内部和PE之间的缩减也与SNAP中的两级PE缩减相似
3)比baseline牛的关键
数据流,交叉开关,缓冲区的层次结构和大小,以及工作分区。
引入网格网络、符合元数据格式的索引生成逻辑、PSUM过滤器等微体系结构组件。
B. 其他相关工作
OuterSPACE(Pixel - first架构)
它使用基于外积的矩阵乘法技术,通过解耦乘法和合并相位来消除对非零操作数的冗余内存访问。
由于PSUM没有减少,使用了较大的共享缓存,因此消耗的能量显著较高。
虽然由于通道索引不匹配(算法2中的if -条件)导致性能优于基于内积的矩阵乘法,但现代通道优先架构通过实现额外的参数匹配逻辑很容易避免这一点。
Eyeriss - v2(Pixel - first架构)
与其他Pixel - first结构不同的是,行平稳数据流执行压缩,
外积策略,与SCNN类似,每个激活都以多个权重顺序重用,导致部分和分散到一个大的32项板块–>访问部分和需要消耗大量的能量。
CANDLES
在写回之前有效地减少了部分和,从而减少了对大缓冲区的访问。
Ex Tensor(Channel - first架构)
寻找非零元素坐标交点的架构。
使用并行的比较器来寻找匹配的交叉点。
与其他通道优先架构一样,这种辅助索引匹配电路对片上功耗和面积影响巨大。
CANDLES通过使用像素优先压缩和通道优先数据流避免了这种比较器开销。
Ex Tensor中提出的无用信息的分层消除与我们的贡献是互不影响互不依赖的,可以进一步提高CANDLES。
1)Stitch-X [29]:一种类似于SNAP的“通道优先”架构,采用一种新型数据流,利用空间和时间缩减来平衡能效和数据流控制的复杂性。
2)Bit-Tactical [28]:旨在通过使用轻量级稀疏互连和一种新型的静态调度方案来减少稀疏DNN加速器中内存访问的带宽和能源成本。
3)Cambricon-S [61]、PermDNN [14] 和 Packed Systolic [27]:旨在有效地处理稀疏神经网络的不规则性。
4)Scalpel [55]:提出了粗粒度剪枝技术来维持规律性。
5)UCNN [20]:通过重用点积运算来利用稀疏性和权重重复。
6)Laconic [42]、Bit-Pragmatic [3] 和 Bit-Tactical [28]:针对DNN网络中的比特稀疏性,通过利用Booth编码来省略零值。
7)Eyeriss v2 [9]:使用专门的网络来处理稀疏性,但主要针对小型移动模型进行了优化。
8)Sparse ReRAM Engine [ 53 ]和SNrram [ 51 ]探索了基于ReRAM的DNN加速器。虽然内存加速器为模拟逻辑提供了巨大的好处,但利用它们的稀疏性是困难的。
9)在GPU上加速稀疏神经网络的技术[62][37].
CONCLUSION
稀疏加速器面临的权衡:
像素优先架构需要复杂的神经元更新,而通道优先架构需要复杂的索引逻辑。
通过采用像素优先压缩和通道优先数据流,可以调和这种权衡:简化了索引,并在神经元更新中实现了高时间局部性,可以进一步利用二级累加缓冲。
提出一种工作分区策略,无需离线分析即可匹配最快的稀疏加速器(SparTen)的性能。
CANDLES在索引和神经元更新方面实现了低能耗,比四种最先进的基准低耗能2.5倍到5.6倍。















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









