






(四)泛型与集合类
走进泛型
为了统计学生成绩,要求设计一个Score对象,包括课程名称、课程号、课程成绩,但是成绩分为两种,一种是以优秀、良好、合格 来作为结果,还有一种就是 60.0、75.5、92.5 这样的数字分数,那么现在该如何去设计这样的一个Score类呢?现在的问题就是,成绩可能是String类型,也可能是Integer类型,如何才能很好的去存可能出现的两种类型呢?
public class Score {
String name;
String id;
Object score; // 因为Object是所有类型的父类,因此既可以存放Integer(不是int)也能存放String
public Score(String name, String id, Object score) {
this.name = name;
this.id = id;
this.score = score;
}
}
以上的方法虽然很好地解决了多种类型存储问题,但是Object类型在编译阶段并不具有良好的类型判断能力,很容易出现以下的情况:
public class Main {
public static void main(String[] args) {
Score score = new Score("数据结构", "EP123456", "优秀");
// ...
Integer number = (Integer) score.score; // 获取成绩需要强制类型转换,虽然并不是一开始的类型,但是编译不会报错
}
}
// 运行时出现异常
Exception in thread "main" java.lang.ClassCastException: class java.lang.String cannot be cast to class java.lang.Integer (java.lang.String and java.lang.Integer are in module java.base of loader 'bootstrap')
at Main.main(Main.java:7)
使用Object类型作为引用,取值只能进行强制类型转换,显然无法在编译期确定类型是否安全,项目中代码量非常之大,进行类型比较又会导致额外的开销和增加代码量,如果不经比较就很容易出现类型转换异常,代码的健壮性有所欠缺!(此方法虽然可行,但并不是最好的方法)
为了解决以上问题,JDK1.5新增了泛型,它能够在编译阶段就检查类型安全,大大提升开发效率。
public class Score<T> {
String name;
String id;
T score; // T为泛型,根据用户提供的类型自动变成对应类型
public Score(String name, String id, T score) { // 提供的score类型即为T代表的类型
this.name = name;
this.id = id;
this.score = score;
}
}
public class Main {
public static void main(String[] args) {
Score<String> score1 = new Score<String>("数据结构", "EP123456", "优秀");
Integer i = (Integer) score1.score; // 编译不通过,因为成员变量score类型被定为String
}
}
泛型将数据类型的确定控制在了编译阶段,在编写代码的时候就能明确泛型的类型!如果类型不符合,将无法通过编译!
泛型本质上也是一个语法糖(并不是JVM所支持的语法,编译后会转成编译器支持的语法,比如之前的foreach就是),在编译后会被擦除,变回上面的Object类型调用,但是类型转换由编译器帮我们完成,而不是我们自己进行转换(安全)
// 反编译后的代码
public static void main(String[] args) {
Score<String> score1 = new Score("数据结构", "EP123456", "优秀");
String i = (String)score1.score; // 其实依然会变成强制类型转化,但这是编译器帮我门完成的
}
将out中的class文件 打开于 终端
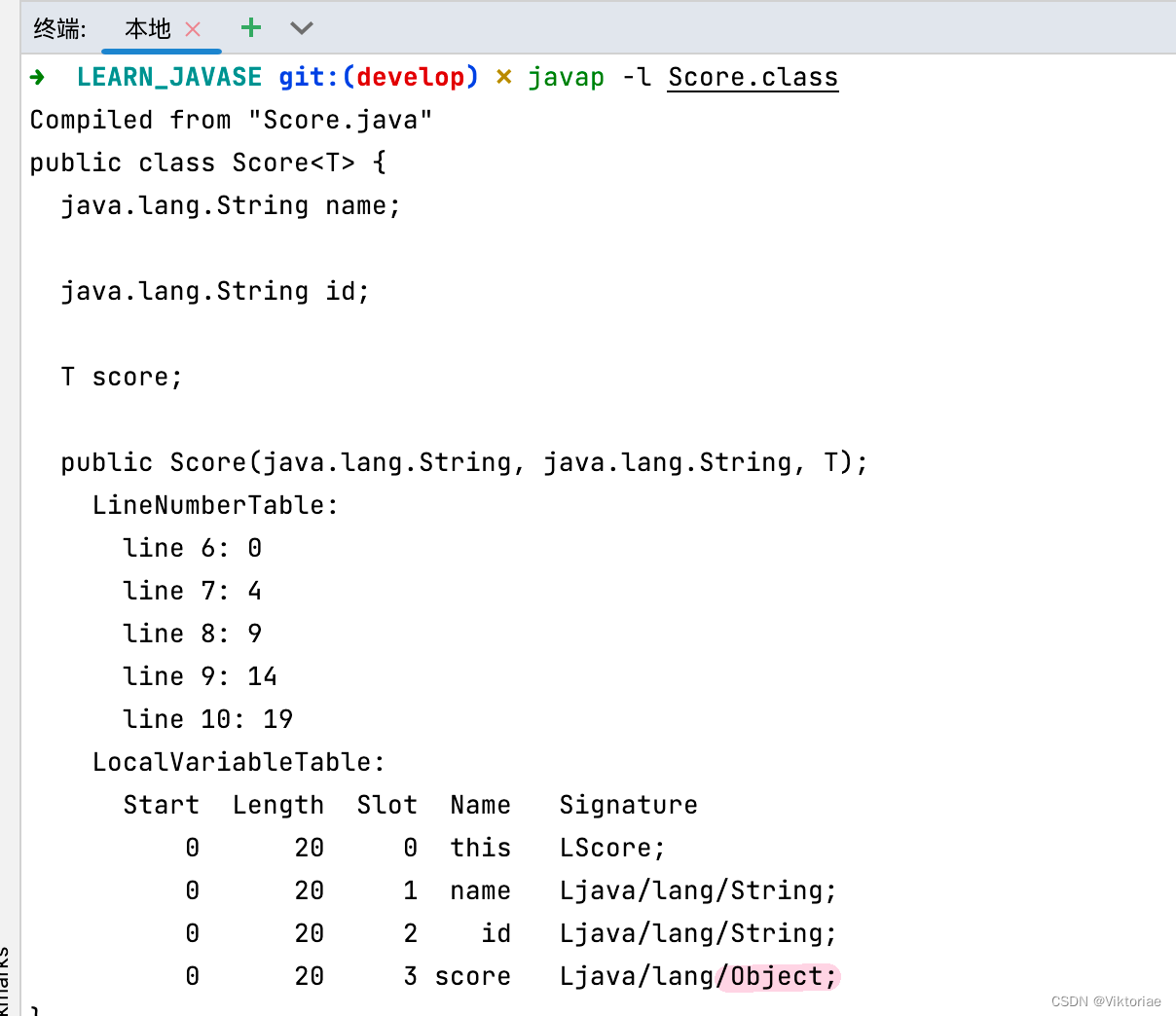
发现这个score本质就是Object类型
像这样在编译后泛型的内容消失转变为Object的情况称为类型擦除(重要,需要完全理解),所以泛型只是为了方便我们在编译阶段确定类型的一种语法而已,并不是JVM所支持的。
综上,泛型其实就是一种类型参数,用于指定类型。
泛型的使用
泛型类
上一节我们已经提到泛型类的定义,实际上就是普通的类多了一个类型参数,也就是在使用时需要指定具体的泛型类型。泛型的名称一般取单个大写字母,比如T代表Type,也就是类型的英文单词首字母,当然也可以添加数字和其他的字符。
在一个普通类型中定义泛型,泛型T称为参数化类型,在定义泛型类的引用时,需要明确指出类型:
Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");
此时类中的泛型T已经被替换为String了,在我们获取此对象的泛型属性时,编译器会直接告诉我们类型:
Integer i = score.score; //编译不通过,因为成员变量score明确为String类型
注意,泛型只能用于对象属性,也就是非静态的成员变量才能使用:
static T score; //错误,不能在静态成员上定义
由此可见,泛型是只有在创建对象后编译器才能明确泛型类型,而静态类型是类所具有的属性,不足以使得编译器完成类型推断。
泛型无法使用基本类型,如果需要基本类型,只能使用基本类型的包装类进行替换!
Score<double> score = new Score<double>("数据结构与算法基础", "EP074512", 90.5); //编译不通过
那么为什么泛型无法使用基本类型呢?回想上一节提到的类型擦除,其实就很好理解了。由于JVM没有泛型概念,因此泛型最后还是会被编译器编译为Object,并采用强制类型转换的形式进行类型匹配,而我们的基本数据类型和引用类型之间无法进行类型转换,所以只能使用基本类型的包装类来处理。
类的泛型方法
泛型方法的使用也很简单,我们只需要把它当做一个未知的类型来使用即可:
public T getScore() { //若方法的返回值类型为泛型,那么编译器会自动进行推断
return score;
}
public void setScore(T score) { //若方法的形式参数为泛型,那么实参只能是定义时的类型
this.score = score;
}
Score<String> score1 = new Score<String>("数据结构", "EP123456", "优秀");
score1.setScore(10); //编译不通过,因为只接受String类型
同样地,静态方法无法直接使用类定义的泛型(注意是无法直接使用,静态方法可以使用泛型)
自定义泛型方法
那么如果我想在静态方法中使用泛型呢?首先我们要明确之前为什么无法使用泛型,因为之前我们的泛型定义是在类上的,只有明确具体的类型才能开始使用,也就是创建对象时完成类型确定,但是静态方法不需要依附于对象,那么只能在使用时再来确定了,所以静态方法可以使用泛型,但是需要单独定义:
public static <E> void test(E e) { //在方法定义前声明泛型
System.out.println(e);
}
public class Score<T> {
String name;
String id;
T score; // T为泛型,根据用户提供的类型自动变成对应类型
public Score(String name, String id, T score) { // 提供的score类型即为T代表的类型
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() { //若方法的返回值类型为泛型,那么编译器会自动进行推断
return score;
}
public void setScore(T score) { //若方法的形式参数为泛型,那么实参只能是定义时的类型
this.score = score;
}
public static <E> void test(E e) { //在方法定义前声明泛型
System.out.println(e);
}
}
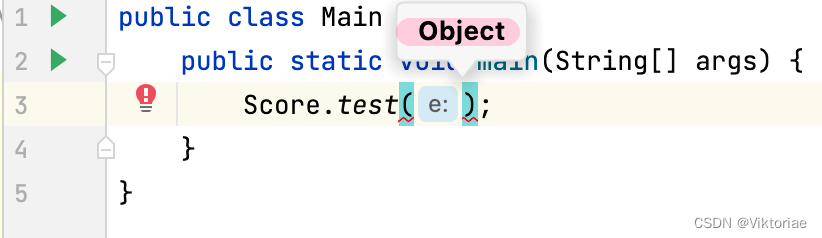
public class Main {
public static void main(String[] args) {
Score.test("lbwnb");
}
}
同理,成员方法也能自行定义泛型,在实际使用时再进行类型确定:
public <E> void test(E e) { //在方法定义前声明泛型
System.out.println(e);
}
其实,无论是泛型类还是泛型方法,再使用时一定要能够进行类型推断,明确类型才行。
注意一定要区分类定义的泛型和方法前定义的泛型!
泛型引用
可以看到我们在定义一个泛型类的引用时,需要在后面指出此类型:
Score<Integer> score; //声明泛型为Integer类型
如果不希望指定类型,或是希望此引用类型可以引用任意泛型的Score类对象,可以使用?通配符,来表示自动匹配任意的可用类型:
Score<?> score; //score可以引用任意的Score类型对象了!
那么使用通配符之后,得到的泛型成员变量会是什么类型呢?
Object o = score.getScore(); //只能变为Object
因为使用了通配符,编译器就无法进行类型推断,所以只能使用原始类型。
在学习了泛型的界限后,我们还会继续了解通配符的使用。
泛型的界限
现在有一个新的需求,现在没有String类型的成绩了,但是成绩依然可能是整数,也可能是小数,这时我们不希望用户将泛型指定为除数字类型外的其他类型,我们就需要使用到泛型的上界定义:
public class Score<T extends Number> { // 设定泛型上界,必须是Number的子类
private final String name;
private final String id;
private T score;
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() {
return score;
}
}
通过extends关键字进行上界限定,只有指定类型或指定类型的子类才能作为类型参数。
同样的,泛型通配符也支持泛型的界限:
Score<? extends Number> score; //限定为匹配Number及其子类的类型
同理,既然泛型有上限,那么也有下限:
Score<? super Integer> score; //限定为匹配Integer及其父类
通过super关键字进行下界限定,只有指定类型或指定类型的父类才能作为类型参数。
那么限定了上界后,我们再来使用这个对象的泛型成员,会变成什么类型呢?
Score<? extends Number> score = new Score<>("数据结构与算法基础", "EP074512", 10);
Number o = score.getScore(); //得到的结果为上界类型
也就是说,一旦我们指定了上界后,编译器就将范围从原始类型Object提升到我们指定的上界Number,但是依然无法明确具体类型。思考:那如果定义下限呢?(得到的结果还是上界)
public static void main(String[] args) {
Score<? super Integer> score = new Score<Integer>("123", "456", 789);
// Integer score1 = score.getScore(); // 报错
// Integer score1 = score.getScore(); // 报错
Object score1 = score.getScore(); // 限定下界,得到的还是上界(默认是Object)
}
那么既然我们可以给泛型类限定上界,现在我们来看编译后结果呢:
因此,一旦确立上限后,编译器会自动将类型提升到上限类型;如果确立的是下限,上限不变还是Object
钻石运算符
我们发现,每次创建泛型对象都需要在前后都标明类型,但是实际上后面的类型声明是可以去掉的,因为我们在传入参数时或定义泛型类的引用时,就已经明确了类型,因此JDK1.7提供了钻石运算符来简化代码:
Score<Integer> score = new Score<Integer>("数据结构与算法基础", "EP074512", 10); //1.7之前
Score<Integer> score = new Score<>("数据结构与算法基础", "EP074512", 10); //1.7之后
泛型与多态
泛型不仅仅可以可以定义在类上,同时也能定义在接口上:
public interface ScoreInterface<T> {
T getScore();
void setScore(T t);
}
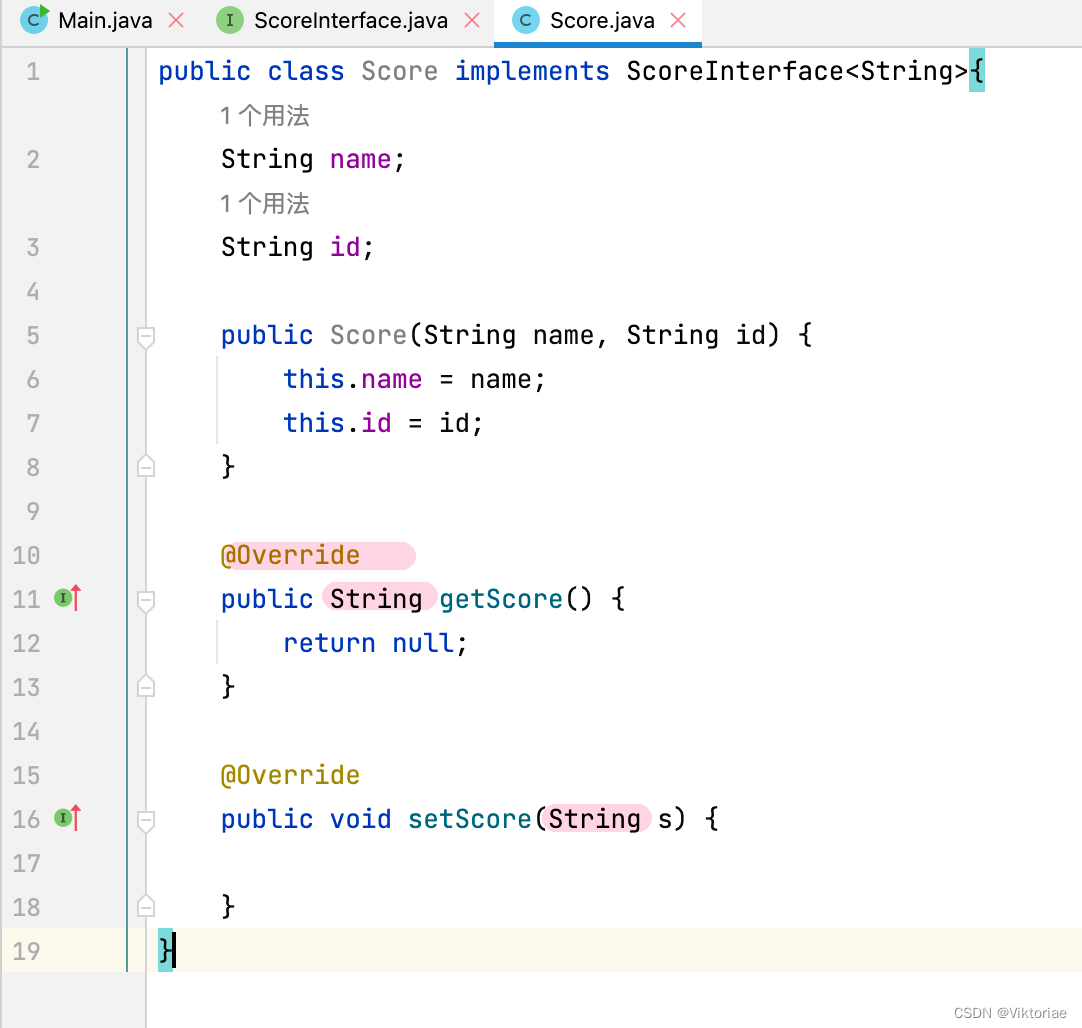
当实现此接口时,我们可以选择在实现类明确泛型类型或是继续使用此泛型,让具体创建的对象来确定类型。
public class Score<T> implements ScoreInterface<T>{
String name;
String id;
public Score(String name, String id) {
this.name = name;
this.id = id;
}
@Override
public T getScore() {
return null;
}
@Override
public void setScore(T t) {
}
}
抽象类同理,这里就不多做演示了。
多态类型擦除
思考一个问题,既然继承后明确了泛型类型,那么为什么@Override不会出现错误呢,重写的条件是需要和父类的返回值类型、形式参数一致,而泛型默认的原始类型是Object类型,子类明确后变为Number类型,这显然不满足重写的条件,但是为什么依然能编译通过呢?
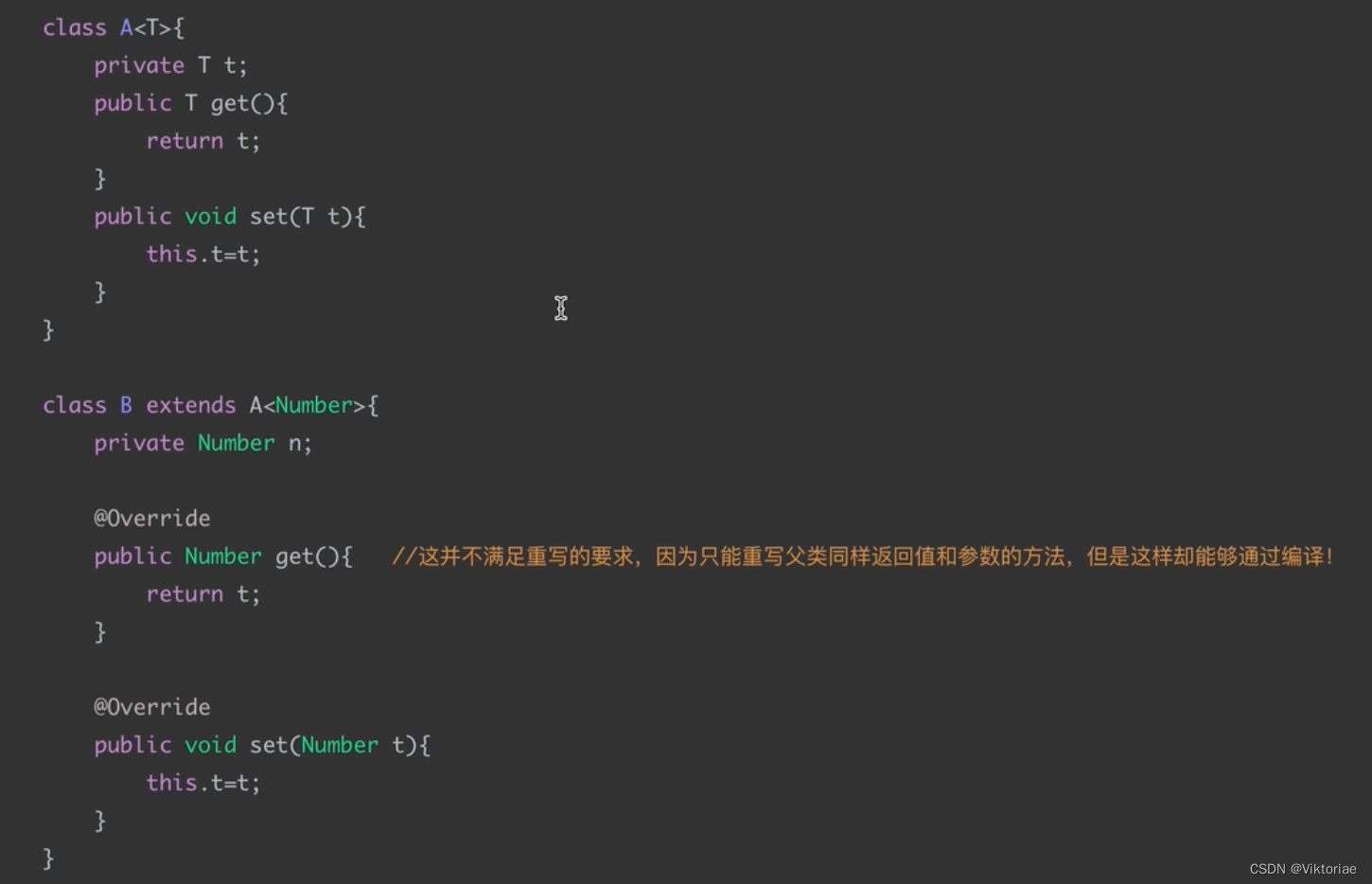
通过反编译进行观察,实际上是编译器帮助我们生成了两个桥接方法用于支持重写:

数据结构基础
线性表
线性表是最基本的一种数据结构,它是表示一组相同类型数据的有限序列,你可以把它与数组进行参考,但是它并不是数组,线性表是一种表结构,它能够支持数据的插入、删除、更新、查询等,同时数组可以随意存放在数组中任意位置,而线性表只能依次有序排列,不能出现空隙,因此,我们需要进一步的设计。
顺序表
将数据依次存储在连续的整块物理空间中,这种存储结构称为顺序存储结构,而以这种方式实现的线性表,我们称为顺序表。
同样的,表中的每一个个体都被称为元素,元素左边的元素(上一个元素),称为前驱,同理,右边的元素(后一个元素)称为后驱。
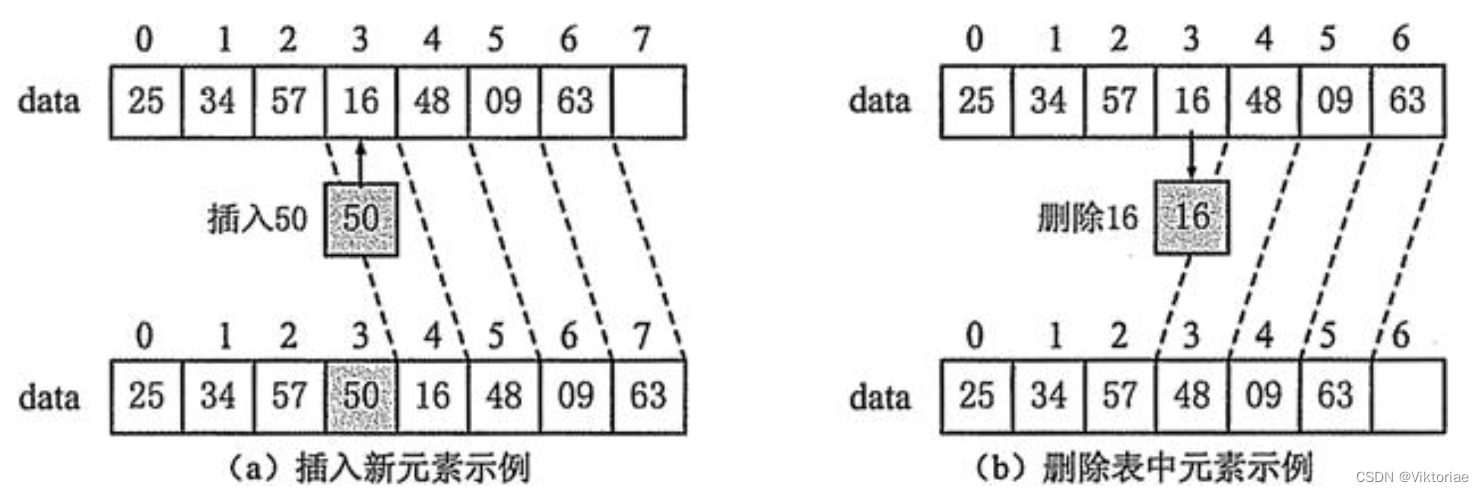
我们设计线性表的目标就是为了去更好地管理我们的数据,也就是说,我们可以基于数组,来进行封装,实现增删改查!既然要存储一组数据,那么很容易联想到我们之前学过的数组,数组就能够容纳一组同类型的数据。
目标:以数组为底层,编写以下抽象类的具体实现
/**
* 线性表抽象类
* @param <E> 存储的元素Element类型
*/
public abstract class AbstractList<E> {
/**
* 获取表的长度
* @return 顺序表的长度
*/
public abstract int size();
/**
*
* @param e 元素
* @param index 要添加的位置(索引)
*/
public abstract void add(E e, int index);
/**
*
* @param index 位置
* @return 移除的元素
*/
public abstract E remove(int index);
/**
*
* @param index 位置
* @return 元素
*/
public abstract E get(int index);
}
public class ArrayList<E> extends AbstractList<E> {
// 底层数组
private Object[] arr = new Object[1];
// 长度
private int size = 0;
@Override
public int size() {
return size;
}
@Override
public void add(E e, int index) {
if (index > size) throw new IllegalArgumentException("非法的插入位置"); // 位置是否异常
if (size >= arr.length) { // 扩容
Object[] arr = new Object[this.arr.length + 10];
for (int i = 0; i < this.arr.length; ++ i) arr[i] = this.arr[i];
this.arr = arr;
}
int i = size - 1;
while (i >= index) {
arr[i + 1] = arr[i];
i -- ;
}
arr[index] = e;
size ++ ;
}
@Override
public E remove(int index) {
return null;
}
@Override
public E get(int index) {
return null;
}
}
链表
数据分散的存储在物理空间中,通过一根线保存着它们之间的逻辑关系,这种存储结构称为链式存储结构
实际上,就是每一个结点存放一个元素和一个指向下一个结点的引用(C语言里面是指针,Java中就是对象的引用,代表下一个结点对象)
栈
其实,我们的JVM在处理方法调用时,也是一个栈操作:
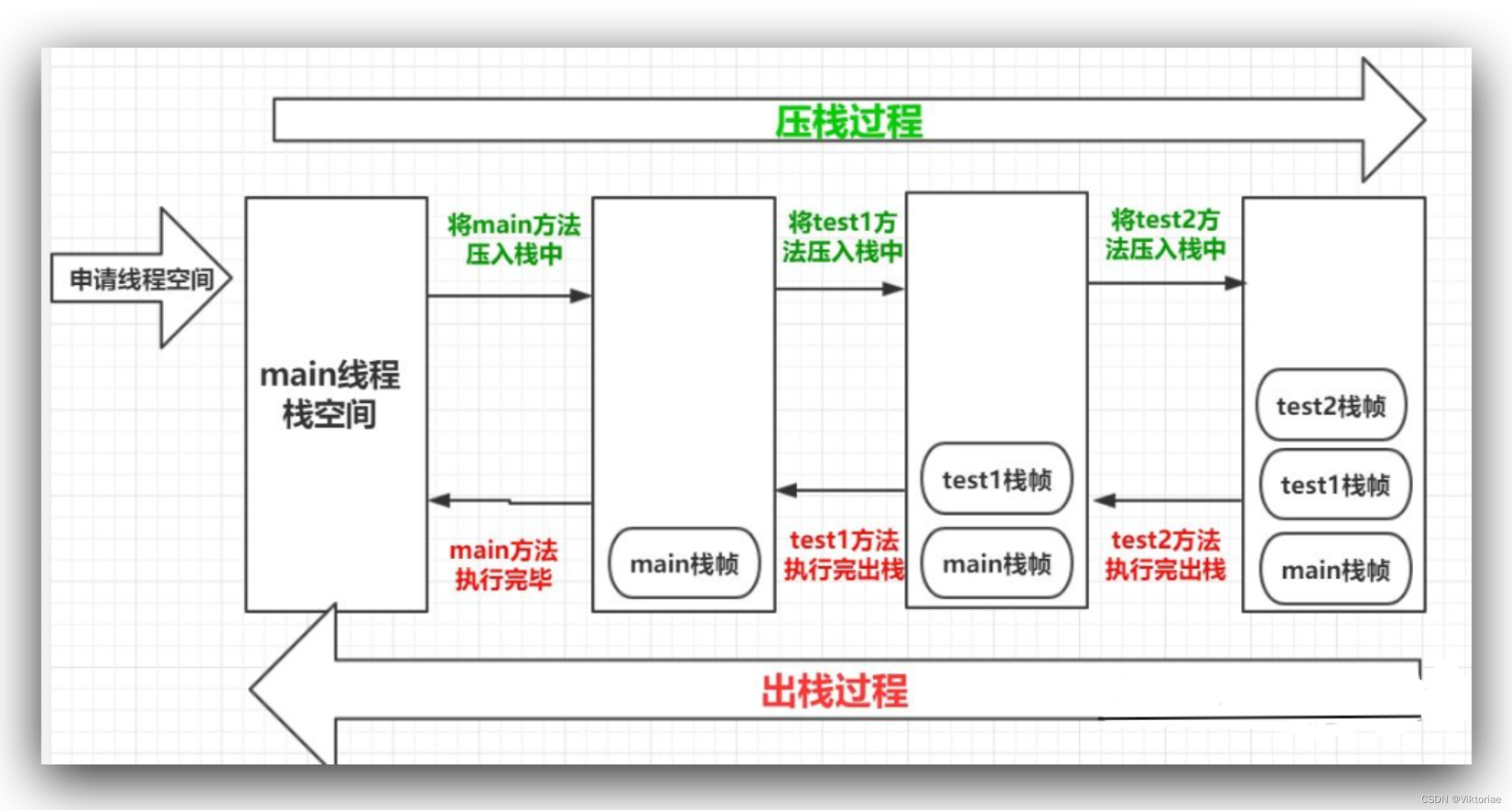
栈的深度是有限制的,如果达到限制,将会出现StackOverflowError错误(注意是错误!说明是JVM出现了问题)
队列
队列同样也是受限制的线性表
二叉树
树
我们前面已经学习过链表了,我们知道链表是单个结点之间相连,也就是一种一对一的关系,而树则是一个结点连接多个结点,也就是一对多的关系。
快速查找
我们之前提到的这些数据结构,很好地帮我们管理了数据,但是,如果需要查找某一个元素是否存在于数据结构中,如何才能更加高效的去完成呢?
哈希表
通过前面的学习,我们发现,顺序表虽然查询效率高,但是插入删除有严重表更新的问题,而链表虽然弥补了更新问题,但是查询效率实在是太低了,能否有一种折中方案?哈希表!
不知大家在之前的学习中是否发现,我们的Object类中,定义了一个叫做hashcode()的方法?而这个方法呢,就是为了更好地支持哈希表的实现。hashcode()默认得到的是对象的内存地址,也就是说,每个对象的hashCode都不一样。
哈希表,其实本质上就是一个存放链表的数组,那么它是如何去存储数据的呢?
数组中每一个元素都是一个头结点,用于保存数据,那我们怎么确定数据应该放在哪一个位置呢?通过hash算法,我们能够瞬间得到元素应该放置的位置。
设想这样一个问题,如果计算出来的hash值和之前已经存在的元素相同了呢?这种情况我们称为hash碰撞,这也是为什么要将每一个表元素设置为一个链表的头结点的原因,一旦发现重复,我们可以往后继续添加节点。
当然,以上的hash表结构只是一种设计方案,在面对大额数据时,是不够用的,在JDK1.8中,集合类使用的是数组+二叉树的形式解决的(这里的二叉树是经过加强的二叉树,不是前面讲得简单二叉树,我们下一节就会开始讲)
二叉排序树
我们前面学习的二叉树效率是不够的,我们需要的是一种效率更高的二叉树,因此,基于二叉树的改进,提出了二叉查找树。
利用二分搜索的思想,我们就可以快速查找某个节点!
平衡二叉树
现在我们对二叉排序树加以约束,要求每个结点的左右两个子树的高度差的绝对值不超过1,这样的二叉树称为平衡二叉树,同时要求每个结点的左右子树都是平衡二叉树,这样,就不会因为一边的疯狂增加导致失衡。
红黑树
红黑树也是二叉排序树的一种改进,同平衡二叉树一样,红黑树也是一种维护平衡的二叉排序树,但是没有平衡二叉树那样严格(平衡二叉树每次插入新结点时,可能会出现大量的旋转,而红黑树保证不超过三次),红黑树降低了对于旋转的要求,因此效率有一定的提升同时实现起来也更加简单。但是红黑树的效率却高于平衡二叉树,红黑树也是JDK1.8中使用的数据结构!
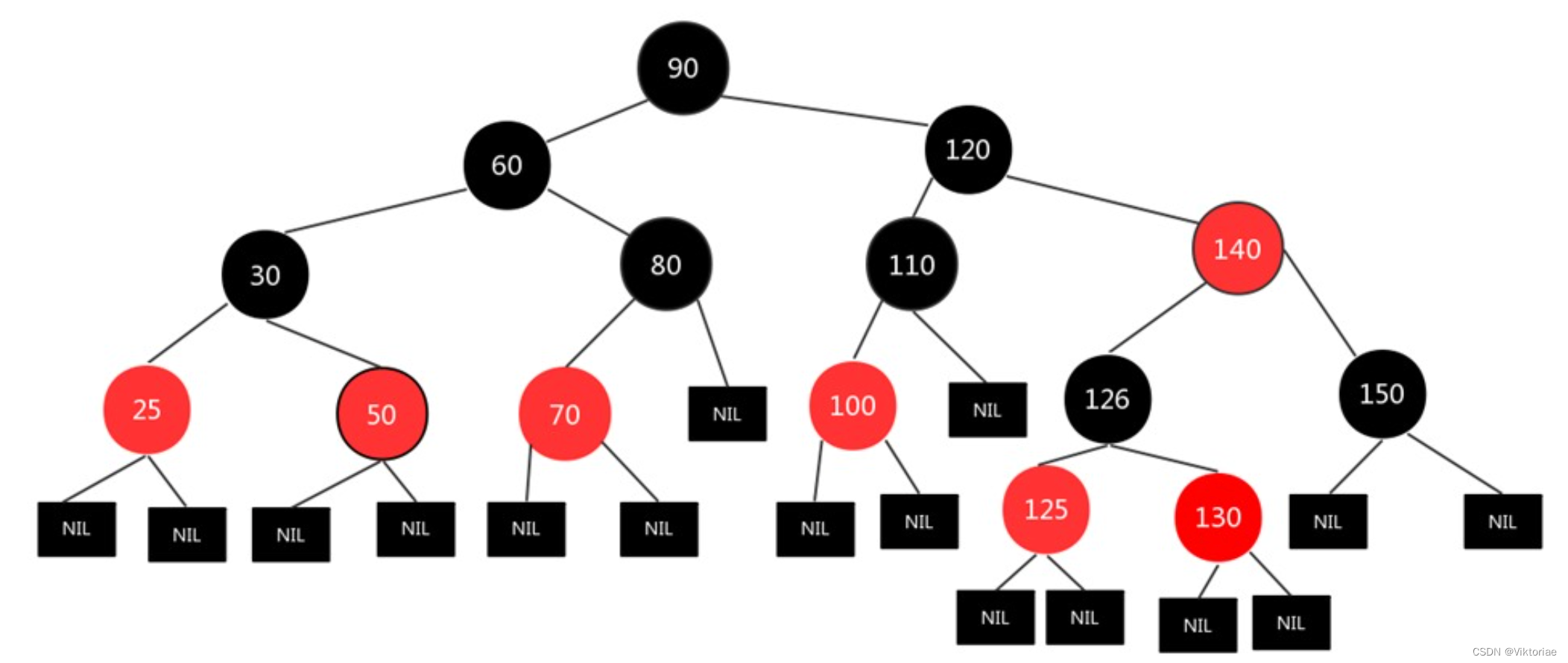
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点的两边也需要表示(虽然没有,但是null也需要表示出来)是黑色。
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
我们来看看一个节点,是如何插入到红黑树中的:
基本的 插入规则和平衡二叉树一样,但是在插入后:
- 将新插入的节点标记为红色
- 如果 X 是根结点(root),则标记为黑色
- 如果 X 的 parent 不是黑色,同时 X 也不是 root:
-
3.1 如果 X 的 uncle (叔叔) 是红色
-
- 3.1.1 将 parent 和 uncle 标记为黑色
-
- 3.1.2 将 grand parent (祖父) 标记为红色
-
- 3.1.3 让 X 节点的颜色与 X 祖父的颜色相同,然后重复步骤 2、3
-
3.2 如果 X 的 uncle (叔叔) 是黑色,我们要分四种情况处理
-
- 3.2.1 左左 (P 是 G 的左孩子,并且 X 是 P 的左孩子)
-
- 3.2.2 左右 (P 是 G 的左孩子,并且 X 是 P 的右孩子)
-
- 3.2.3 右右 (P 是 G 的右孩子,并且 X 是 P 的右孩子)
-
- 3.2.4 右左 (P 是 G 的右孩子,并且 X 是 P 的左孩子)
-
- 其实这种情况下处理就和我们的平衡二叉树一样了
认识集合类
集合表示一组对象,称为其元素。一些集合允许重复的元素,而另一些则不允许。一些集合是有序的,而其他则是无序的。
集合类其实就是为了更好地组织、管理和操作我们的数据而存在的,包括列表、集合、队列、映射等数据结构。从这一块开始,我们会从源码角度给大家讲解(数据结构很重要!),不仅仅是教会大家如何去使用。
集合类最顶层不是抽象类而是接口,因为接口代表的是某个功能,而抽象类是已经快要成形的类型,不同的集合类的底层实现是不相同的,同时一个集合类可能会同时具有两种及以上功能(既能做队列也能做列表),所以采用接口会更加合适,接口只需定义支持的功能即可。

数组与集合
相同之处:
- 它们都是容器,都能够容纳一组元素。
不同之处:
- 数组的大小是固定的,集合的大小是可变的。
- 数组可以存放基本数据类型,但集合只能存放对象。
- 数组存放的类型只能是一种,但集合可以有不同种类的元素。
集合根接口Collection
本接口中定义了全部的集合基本操作,我们可以在源码中看看。
我们再来看看List和Set以及Queue接口。
集合类的使用
List列表
首先介绍ArrayList,它的底层是用数组实现的,内部维护的是一个可改变大小的数组,也就是我们之前所说的线性表!跟我们之前自己写的ArrayList相比,它更加的规范,同时继承自List接口。
先看看ArrayList的源码!
基本操作
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
List<String> list2 = new ArrayList<>(200); // 这是一种优化。如果没有数字,源码中显示默认就是空的list,那么下次插入元素就会增长,而前期增长是非常频繁的
list.add("A");
list.add("B");
System.out.println(list); // 与数组不同,List可以直接打印 // [A, B]
System.out.println(list.contains("A")); // 是否包含某个元素 // true // 这里是String的equals,已经重载
// 一定要注意,这个contains方法调用的是equals
// equals方法在没有重载(String,Integer都重载了)时,和 == 一样,比较的是对象的地址
}
}
public class Student {
String name;
public Student(String name) {
this.name = name;
}
}
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
list.add(new Student("A"));
list.add(new Student("B"));
System.out.println(list.contains(new Student("A"))); // false
}
}
或者 重载equals方法;就可以变成true了

import java.util.Objects;
public class Student {
String name;
public Student(String name) {
this.name = name;
}
// 重载equals;先打出eq然后就会弹出可以重载(通过向导生成)
@Override
public boolean equals(Object o) {
return this.name.equals(((Student)o).name); //注意这里是两个字符串比较值,不能用 ==
}
}
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
list.add(new Student("A"));
list.add(new Student("B"));
System.out.println(list.contains(new Student("A"))); // true
}
}
// 移除元素
list.remove(0); // 移除下标为0的元素
list.remove("yyds"); // 移除内容为 yyds 的元素
// 批量操作
ArrayList<String> list = new ArrayList<>();
list.addAll(new ArrayList<>()); // 在尾部批量添加元素
list.removeAll(new ArrayList<>()); // 批量移除元素(只有给定集合中存在的元素才会被移除)
list.retainAll(new ArrayList<>()); // 只保留某些元素
我们再来看LinkedList,其实本质就是一个链表!我们来看看源码。
其实与我们之前编写的LinkedList不同之处在于,它内部使用的是一个双向链表:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
当然,我们发现它还实现了Queue接口,所以LinkedList也能被当做一个队列或是栈来使用。
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.offer("A"); // 入队
System.out.println(list.poll()); // 出队
list.push("A");
list.push("B"); // 进栈
list.push("C");
System.out.println(list.pop()); // 出栈
}
}
利用代码块来快速添加内容
前面我们学习了匿名内部类,我们就可以利用代码块,来快速生成一个自带元素的List
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>() {
{
this.add("A");
this.add("B");
}
};
System.out.println(list); // [A, B]
}
}
如果是需要快速生成一个只读的List,后面我们会讲解Arrays工具类。
public class Main {
public static void main(String[] args) {
List<String> list = Arrays.asList("A", "B");
// list.add("C"); // 报错
System.out.println(list);
}
}
集合的排序
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>() {
{
this.add("A");
this.add("B");
}
};
list.sort(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return 0;
}
});
}
如果接口中只有一个抽象方法的话,可以用lambda表达式来替代
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>() {
{
this.add("A");
this.add("B");
}
};
list.sort((o1, o2) -> 0);
}
}
public class Main {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<Integer>() {
{
this.add(2);
this.add(1);
this.add(3);
}
};
// 返回值小于0,表示o1应该在o2前面,大于0反之;等于0则不进行交换
list.sort((o1, o2) -> {
return o1 - o2;
});
System.out.println(list); // [1, 2, 3]
}
}
迭代器
集合的遍历
如果直接用for循环,LinkedList中每次取get效率很低
为了解决这个问题,java专门提供了 迭代器
所有的集合类,都支持foreach循环!
public class Main {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<Integer>() {
{
this.add(2);
this.add(1);
this.add(3);
}
};
// for (Integer i : list) {
// System.out.println(i);
// }
// 两种都可以
// JDK1.8新增的forEach方法,它接受一个Consumer接口实现:
list.forEach(i -> {
System.out.println(i);
});
// 这是第二种的简写
list.forEach(System.out::println);
}
}
从JDK1.8开始,lambda表达式开始逐渐成为主流,我们需要去适应函数式编程的这种语法,包括批量替换,也是用到了函数式接口来完成的。
list.replaceAll((i) -> {
if (i == 2) return 3; // 将所有的2替换成3
else return i; // 不是2就不变
});
public class Main {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<Integer>() {
{
this.add(2);
this.add(1);
this.add(3);
}
};
list.replaceAll(new UnaryOperator<Integer>() {
@Override
public Integer apply(Integer integer) {
return integer + 1;
}
});
list.forEach(System.out::println); // 3 2 4
}
}
public class Main {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<Integer>() {
{
this.add(2);
this.add(1);
this.add(3);
}
};
// 替换为lambda
list.replaceAll(integer -> integer + 1);
list.forEach(System.out::println); // 3 2 4
}
}
Iterable和Iterator接口
我们之前学习数据结构时,已经得知,不同的线性表实现,在获取元素时的效率也不同,因此我们需要一种更好地方式来统一不同数据结构的遍历。
由于ArrayList对于随机访问的速度更快,而LinkedList对于顺序访问的速度更快,因此在上述的传统for循环遍历操作中,ArrayList的效率更胜一筹,因此我们要使得LinkedList遍历效率提升,就需要采用顺序访问的方式进行遍历,如果没有迭代器帮助我们统一标准,那么我们在应对多种集合类型的时候,就需要对应编写不同的遍历算法,很显然这样会降低我们的开发效率,而迭代器的出现就帮助我们解决了这个问题。
我们先来看看迭代器里面方法:
public interface Iterator<E> {
//...
}
每个集合类都有自己的迭代器,通过iterator()方法来获取:
public class Main {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<Integer>() {
{
this.add(2);
this.add(1);
this.add(3);
}
};
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
Integer i = iterator.next();
System.out.println(i);
}
}
}
foreach 本质 就是迭代器调用
public class Main {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<Integer>() {
{
this.add(2);
this.add(1);
this.add(3);
}
};
ListIterator<Integer> iterator = list.listIterator(); //List还有一个更好地迭代器实现ListIterator(比Iterator有更多针对List的方法
while (iterator.hasNext()) {
Integer i = iterator.next();
System.out.println(i);
}
while (iterator.hasPrevious()) {
Integer i = iterator.previous();
System.out.println(i);
}
}
}
迭代器生成后,默认指向第一个元素,每次调用next()方法,都会将指针后移,当指针移动到最后一个元素之后,调用hasNext()将会返回false,迭代器是一次性的,用完即止,如果需要再次使用,需要调用iterator()方法。
ListIterator是List中独有的迭代器,在原有迭代器基础上新增了一些额外的操作。
Set集合
我们之前已经看过Set接口的定义了,我们发现接口中定义的方法都是Collection中直接继承的,因此,Set支持的功能其实也就和Collection中定义的差不多,只不过使用方法上稍有不同。
Set集合特点:
- 不允许出现重复元素
- 不支持随机访问(不允许通过下标访问)
首先认识一下HashSet,它的底层就是采用哈希表实现的(我们在这里先不去探讨实现原理,因为底层实质上维护的是一个HashMap,我们学习了Map之后再来讨论)
public class Main {
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<>();
set.add(120); // 不指定位置插入(不一定是在集合尾部
set.add(13);
// set.fot
for (Integer integer : set) {
System.out.println(integer);
}
}
}
运行上面代码发现,最后Set集合中存在的元素顺序,并不是我们的插入顺序,这是因为HashSet底层是采用哈希表来实现的,实际的存放顺序是由Hash算法决定的。
那么我们希望数据按照我们插入的顺序进行保存该怎么办呢?我们可以使用LinkedHashSet:
public class Main {
public static void main(String[] args) {
HashSet<Integer> set = new LinkedHashSet<>();
set.add(120);
set.add(13);
// set.fot
for (Integer integer : set) {
System.out.println(integer);
}
}
}
LinkedHashSet底层维护的不再是一个HashMap,而是LinkedHashMap,它能够在插入数据时利用链表自动维护顺序,因此这样就能够保证我们插入顺序和最后的迭代顺序一致了。
还有一种Set叫做TreeSet,它会在元素插入时进行排序(红黑树):
public class Main {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(1);
set.add(3);
set.add(2);
System.out.println(set); // 1 2 3
}
}
可以看到最后得到的结果并不是我们插入顺序,而是按照数字的大小进行排列。当然,我们也可以自定义排序规则:
public class Main {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>((a, b) -> b - a); // 在创建时制定规则即可
set.add(1);
set.add(3);
set.add(2);
System.out.println(set); // 3 2 1
}
}
Map映射
什么是映射
我们在高中阶段其实已经学习过映射了,映射指两个元素的之间相互“对应”的关系,也就是说,我们的元素之间是两两对应的,是以键值对的形式存在。
Map接口
Map就是为了实现这种数据结构而存在的,我们通过保存键值对的形式来存储映射关系。
我们先来看看Map接口中定义了哪些操作。
HashMap和LinkedHashMap
HashMap的实现过程,相比List,就非常地复杂了,它并不是简简单单的表结构,而是利用哈希表存放映射关系,我们来看看HashMap是如何实现的,首先回顾我们之前学习的哈希表,它长这样:
哈希表的本质其实就是一个用于存放后续节点的头结点的数组,数组里面的每一个元素都是一个头结点(也可以说就是一个链表),当要新插入一个数据时,会先计算该数据的哈希值,找到数组下标,然后创建一个新的节点,添加到对应的链表后面。
而HashMap就是采用的这种方式,我们可以看到源码中同样定义了这样的一个结构:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
这个表会在第一次使用时初始化,同时在必要时进行扩容,并且它的大小永远是2的倍数!
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
我们可以看到默认的大小为2的4次方,每次都需要是2的倍数,也就是说,下一次增长之后,大小会变成2的5次方。
我们现在需要思考一个问题,当我们表中的数据不断增加之后,链表会变得越来越长,这样会严重导致查询速度变慢,首先想到办法就是,我们可以对数组的长度进行扩容,来存放更多的链表,那么什么情况下会进行扩容呢?
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
我们还发现HashMap源码中有这样一个变量,也就是负载因子,那么它是干嘛的呢?
负载因子其实就是用来衡量当前情况是否需要进行扩容的标准。我们可以看到默认的负载因子是0.75
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
那么负载因子是怎么控制扩容的呢?0.75的意思是,在插入新的结点后,如果当前数组的占用率达到75%则进行扩容。在扩容时,会将所有的数据,重新计算哈希值,得到一个新的下标,组成新的哈希表。
但是这样依然有一个问题,链表过长的情况还是有可能发生,所以,为了从根源上解决这个问题,在JDK1.8时,引入了红黑树这个数据结构。
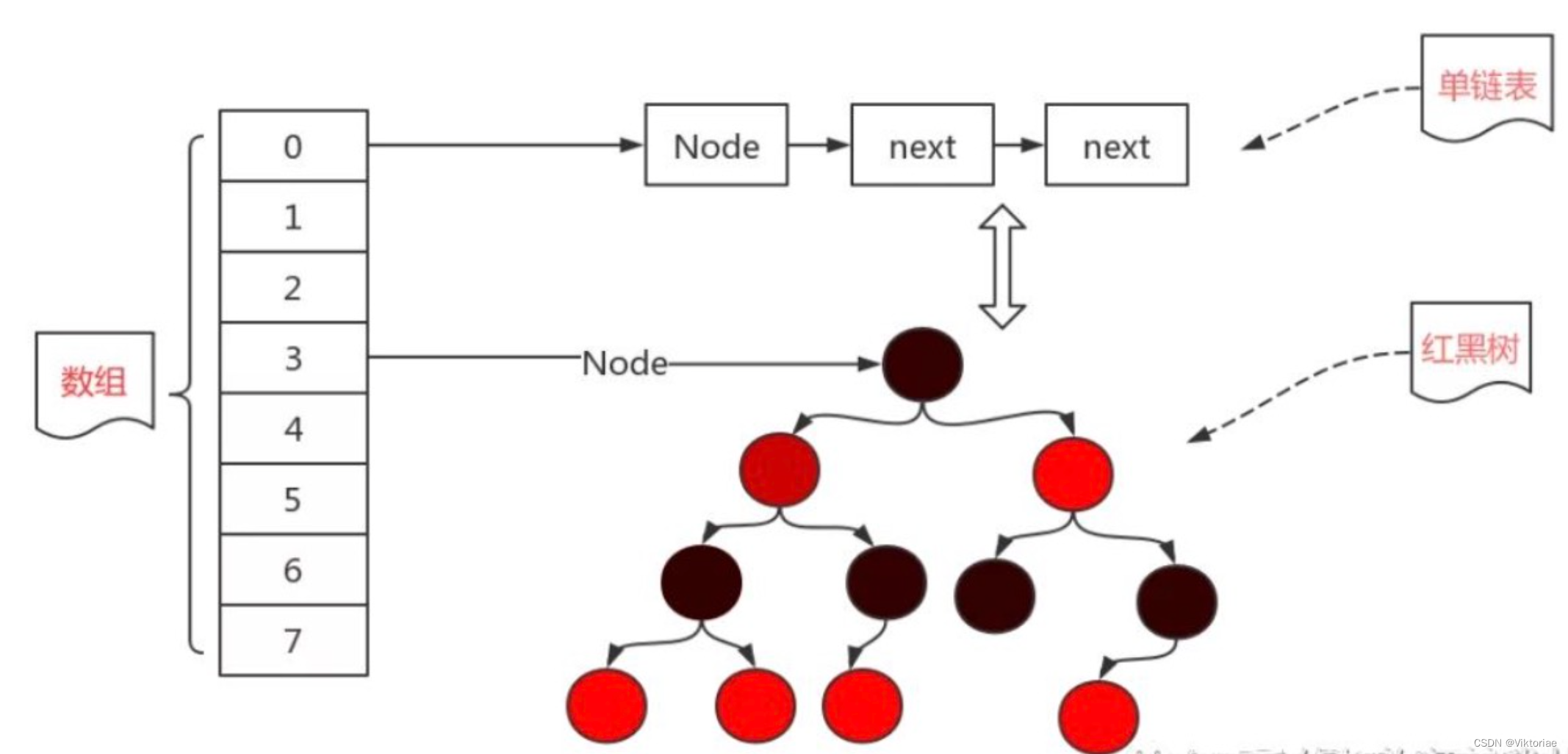
当链表的长度达到8时,会自动将链表转换为红黑树,这样能使得原有的查询效率大幅度降低!当使用红黑树之后,我们就可以利用二分搜索的思想,快速地去寻找我们想要的结果,而不是像链表一样挨个去看。
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
除了Node以外,HashMap还有TreeNode,很明显这就是为了实现红黑树而设计的内部类。不过我们发现,TreeNode并不是直接继承Node,而是使用了LinkedHashMap中的Entry实现,它保存了前后节点的顺序(也就是我们的插入顺序)。
LinkedHashMap是直接继承自HashMap,具有HashMap的全部性质,同时得益于每一个节点都是一个双向链表,保存了插入顺序,这样我们在遍历LinkedHashMap时,顺序就同我们的插入顺序一致。当然,也可以使用访问顺序,也就是说对于刚访问过的元素,会被排到最后一位。
TreeMap
TreeMap其实就是自动维护顺序的一种Map,就和我们前面提到的TreeSet一样:
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
@SuppressWarnings("serial") // Conditionally serializable
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
/**
* Node in the Tree. Doubles as a means to pass key-value pairs back to
* user (see Map.Entry).
*/
static final class Entry<K,V> implements Map.Entry<K,V> {
我们发现它的内部直接维护了一个红黑树,就像它的名字一样,就是一个Tree,因为它默认就是有序的,所以说直接采用红黑树会更好。我们在创建时,直接给予一个比较规则即可。
public class Main {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
map.put(1, "A");
map.put(3, "C");
map.put(2, "B");
System.out.println(map); // {1=A, 2=B, 3=C}
}
}
public class Main {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>((a, b) -> b - a);
map.put(1, "A");
map.put(3, "C");
map.put(2, "B");
System.out.println(map); // {3=C, 2=B, 1=A}
}
}
Map的使用
我们首先来看看Map的一些基本操作:
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.get(1)); // 获取Key为1的值
System.out.println(map.getOrDefault(0, "K")); // 不存在就返回K
map.remove(1); // 移除这个Key的键值对
}
}
由于Map并未实现迭代器接口,因此不支持foreach,但是JDK1.8为我们提供了forEach方法使用:
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.forEach((k, v) -> System.out.println(k + "->" + v));
}
}
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
for (Map.Entry<Integer, String> entry : map.entrySet()) { // 也可以获取所有的Entry来foreach
int key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " -> " + value);
}
}
}
我们也可以单独获取所有的值或者是键:
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.keySet()); // [1, 2, 3]
}
}
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "B");
System.out.println(map.keySet()); // [1, 2, 3]
System.out.println(map.values().getClass()); // class java.util.HashMap$Values // HashMap$Values 说明是一个内部类
System.out.println(map.values()); // [A, B, B] // 可以出现重复的值
}
}
再谈Set原理
通过观察HashSet的源码发现,HashSet几乎都在操作内部维护的一个HashMap,也就是说,HashSet只是一个表壳,而内部维护的HashMap才是灵魂!
我们发现,在添加元素时,其实添加的是一个键为我们插入的元素,而值就是PRESENT常量:
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element {@code e} to this set if
* this set contains no element {@code e2} such that
* {@code Objects.equals(e, e2)}.
* If this set already contains the element, the call leaves the set
* unchanged and returns {@code false}.
*
* @param e element to be added to this set
* @return {@code true} if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
观察其他的方法,也几乎都是在用HashMap做事,所以说,HashSet利用了HashMap内部的数据结构,轻松地就实现了Set定义的全部功能!
再来看TreeSet,实际上用的就是我们的TreeMap:
/** * The backing map. */
private transient NavigableMap<E,Object> m;
JDK1.8新增方法使用
最后,我们再来看看JDK1.8中集合类新增的一些操作(之前没有提及的)首先来看看compute方法:
也可以使用computeIfAbsent,当不存在Key时,计算并将键值对放入Map
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.compute(1,(k, v) -> { // compute会将指定的Key的值进行重新计算,若Key不存在,v会返回null
return v + "M"; //这里返回原来的value+M
});
map.computeIfPresent(1, (k, v) -> { //当Key存在时存在则计算并赋予新的值
return v + "M"; //这里返回原来的value+M
});
System.out.println(map);
}
}
merge方法用于处理数据:
import java.util.*;
public class Main {
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("zhangsan", "english",80),
new Student("zhangsan", "chinese",70),
new Student("zhangsan", "math",90),
new Student("lisi", "english",82),
new Student("lisi", "chinese",72),
new Student("lisi", "math",92)
);
Map<String, Integer> scoreMap = new HashMap<>();
students.forEach(student -> scoreMap.merge(student.getName(), student.getScore(), (a, b) -> a + b));
scoreMap.forEach((k, v) -> System.out.println("key: " + k + "总分" + "value: " + v));
}
static class Student {
private final String name;
private final String type;
private final int score;
public Student(String name, String type, int score) {
this.name = name;
this.type = type;
this.score = score;
}
public String getName() {
return name;
}
public String getType() {
return type;
}
public int getScore() {
return score;
}
}
}
集合的嵌套
既然集合类型中的元素类型是泛型,那么能否嵌套存储呢?
public class Main {
public static void main(String[] args) {
Map<String, List<Integer>> map = new HashMap<>();
map.put("abc", new LinkedList<>());
map.put("cde", new LinkedList<>());
System.out.println(map.keySet()); // [abc, cde]
System.out.println(map.values()); // [[], []]
}
}
通过Key获取到对应的值后,就是一个列表:
public class Main {
public static void main(String[] args) {
Map<String, List<Integer>> map = new HashMap<>();
map.put("abc", new LinkedList<>());
map.put("cde", new LinkedList<>());
map.get("abc").add(10);
System.out.println(map.get("abc").get(0));
}
}
流Stream和Optional的使用
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
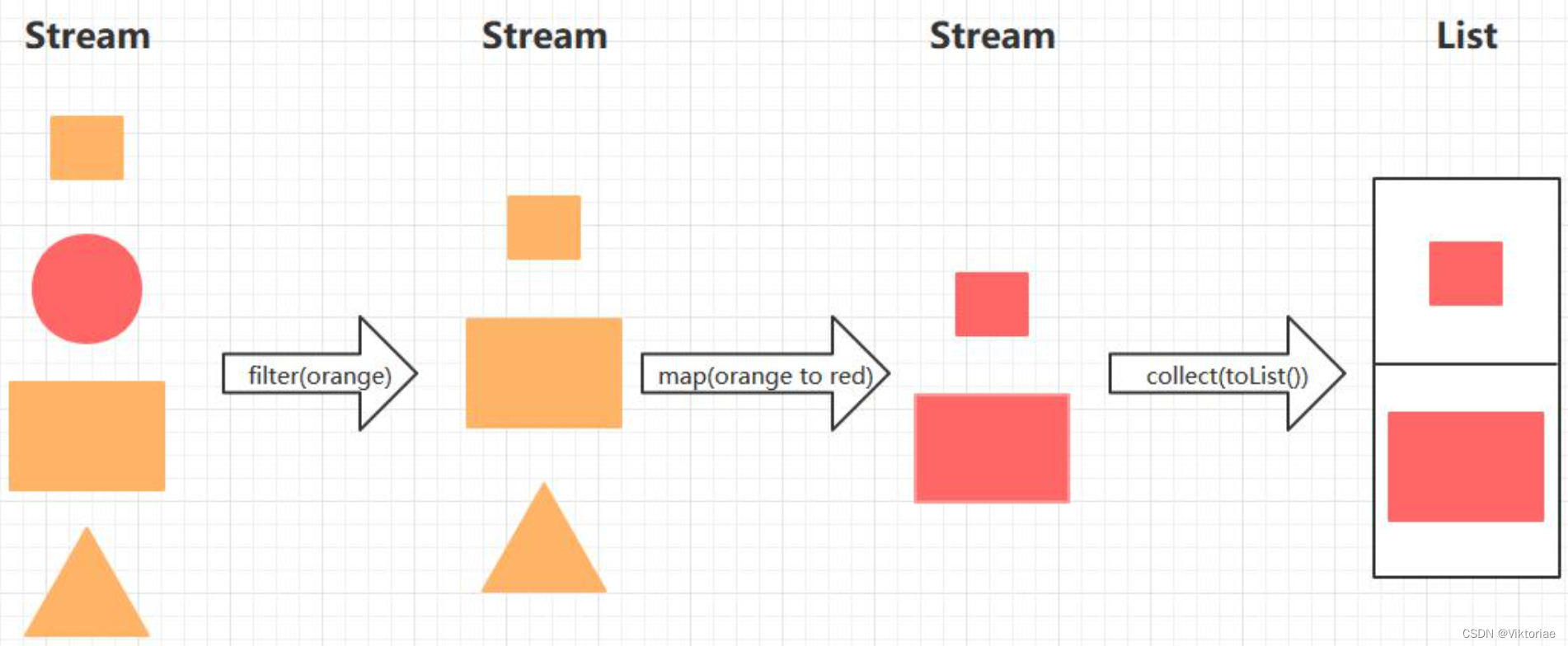
它看起来就像一个工厂的流水线一样!我们就可以把一个Stream当做流水线处理:
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
// 移除为B的元素
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
if (iterator.next().equals("B")) iterator.remove();
}
System.out.println(list);
}
}
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
// 移除为B的元素
list = list // 链式调用
.stream() // 获取流
.filter(e -> !e.equals("B")) // 只允许所有不是B的元素通过流水线
.collect(Collectors.toList()); // 将流水线中的元素重新收集起来,变成List
System.out.println(list);
}
}
可能从上述例子中还不能感受到流处理带来的便捷,我们通过下面这个例子来感受一下:
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() // 去重(使用equals判断
.sorted((a, b) -> b - a) // 进行倒序排序
.map(e -> e + 1) // 每个元素都要执行+1操作
.limit(2) // 只放行前两个元素
.collect(Collectors.toList());
System.out.println(list); // [4, 3]
}
}
当遇到大量的复杂操作时,我们就可以使用Stream来快速编写代码,这样不仅代码量大幅度减少,而且逻辑也更加清晰明了(如果你学习过SQL的话,你会发现它更像一个Sql语句)
注意:不能认为每一步是直接依次执行的!
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() // 断点
.sorted((a, b) -> b - a)
.map(e -> {
System.out.println(">>> " + e); // 断点
return e + 1;
})
.limit(2) // 断点
.collect(Collectors.toList());
// 实际上,stream会先记录每一步操作,而不是直接开始执行内容,当整个链式调用完成后,才会依次进行
}
}
接下来,我们用一堆随机数来进行更多流操作的演示:
public class Main {
public static void main(String[] args) {
Random random = new Random(); // Random是一个随机数工具类
random
.ints(-100, 100) // 生成-100~100之间的,随机int型数字(本质上是一个IntStream)
.limit(10) // 只获取前10个数字(这是一个无限制的流,如果不加以限制,将会无限进行下去!
.filter(i -> i < 0) // 只保留小于0的数字
.sorted() // 默认从小到大排序
.forEach(System.out::println); // 依次打印
}
}
我们可以生成一个统计实例来帮助我们快速进行统计:
public class Main {
public static void main(String[] args) {
Random random = new Random(); // Random是一个随机数工具类
IntSummaryStatistics statistics = random
.ints(0,100)
.limit(100)
.summaryStatistics(); // 获取语法统计实例
System.out.println(statistics.getMax()); // 快速获取最大值
System.out.println(statistics.getCount()); // 获取数量
System.out.println(statistics.getAverage()); // 获取平均值
}
}
普通的List只需要一个方法就可以直接转换到方便好用的IntStream了:

public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.stream()
.mapToInt(i -> i) // 将每一个元素映射为Integer类型(这里因为这里的流元素本来就是Integer)
.summaryStatistics();
System.out.println(list);
}
}
我们还可以通过flat来对整个流进行进一步细分:
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A,B");
list.add("C,D");
list.add("E,F"); // 我们想让每一个元素通过,进行分割,变成独立的6个元素
list = list
.stream() // 生成流
.flatMap(e -> Arrays.stream(e.split(","))) // 分割字符串并生成新的流
.collect(Collectors.toList()); // 汇成新的list
System.out.println(list);
}
}
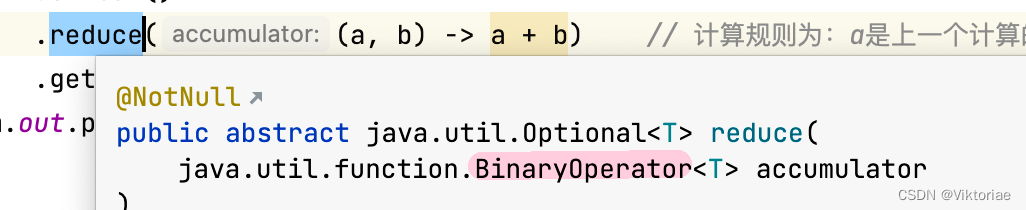
我们也可以只通过Stream来完成所有数字的和,使用reduce方法:

public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
int sum = list
.stream()
.reduce((a, b) -> a + b) // 计算规则为:a是上一个计算的值,b是当前要计算的参数,这里是求和
.get(); // 我们发现得到的是一个Optional类实例,不是我们返回的类型,通过get方法返回得到的值
System.out.println(sum); // 6
}
}
通过上面的例子,我们发现,Stream不喜欢直接给我们返回一个结果,而是通过Optinal的方式,那么什么是Optional呢?
Optional类是Java8为了解决null值判断问题,使用Optional类可以避免显式的null值判断(null的防御性检查),避免null导致的NPE(NullPointerException)。总而言之,就是对控制的一个判断,为了避免空指针异常。
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
String str = null;
if(str != null){ //当str不为空时添加元素到List中
list.add(str);
}
}
}
有了Optional之后,我们就可以这样写:
public class Main {
public static void main(String[] args) {
String str = null;
Optional<String> optional = Optional.ofNullable(str); // 转换为Optional
optional.ifPresent(System.out::println); // 当存在时再执行方法
}
}
就类似于Kotlin中的:
? 相当于 Optional
var str : String? = null
str?.upperCase()
我们可以选择直接get或是当值为null时,获取备选值:
public class Main {
public static void main(String[] args) {
String str = null;
Optional optional = Optional.ofNullable(str); // 转换成Optional(可空)
System.out.println(optional.orElse("lbwnb")); // 如果optional是空的话会给另外一个值 lbwnb
// System.out.println(optional.get()); // 这样会直接抛异常 No value present
}
}
同样的,Optional也支持过滤操作和映射操作,不过是对于单对象而言:
public class Main {
public static void main(String[] args) {
String str = "A";
Optional optional = Optional.ofNullable(str); // 转换为Optional(可空)
System.out.println(optional.filter(s -> s.equals("B")).get()); // 被过滤了,此时元素为null,获取时报错
}
}
public class Main {
public static void main(String[] args) {
String str = "A";
Optional optional = Optional.ofNullable(str); // 转换为Optional(可空)
System.out.println(optional.map(s -> s + "A").get()); // 在尾部追加一个A // AA
}
}
Arrays和Collections的使用
Arrays是一个用于操作数组的工具类,它给我们提供了大量的工具方法:

而且 工具 一般都是 static ,不需要new就能用方法啦
由于操作数组并不像集合那样方便,因此JDK提供了Arrays类来增强对数组操作,比如:
- 排序
- 直接打印数组是打印不出来的,需要用Arrays的toString
public class Main {
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array); // 直接进行排序(底层原理:进行判断,元素少使用插入排序,大量元素使用双轴快速/归并排序)
System.out.println(array); // 由于int[]是一个对象类型,而数组默认是没有重写toString()方法,因此无法打印到想要的结果
System.out.println(Arrays.toString(array)); // 我们可以使用Arrays.toString()来像集合一样直接打印每一个元素出来
// [I@2133c8f8
// [1, 2, 3, 4, 5, 6, 7]
}
}
public class Main {
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array);
System.out.println("排序后的结果:" + Arrays.toString(array));
System.out.println("目标元素3位置为:" + Arrays.binarySearch(array,3)); // 二分搜索,必须是已经排序好的数组
}
}
public class Main {
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays
.stream(array) // 将数组转换为流进行操作
.sorted()
.forEach(System.out::println);
}
}
public class Main {
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
int[] array2 = Arrays.copyOf(array, array.length); // 复制一个一摸一样的数组
System.out.println(Arrays.toString(array2));
// true
System.out.println(Arrays.equals(array,array2)); // 比较两个数组是否 值 相同
Arrays.fill(array, 0); // 将数组的所有值全部填充为指定值
System.out.println(Arrays.toString(array)); // [0, 0, 0, 0, 0, 0, 0]
Arrays.setAll(array2, i -> array2[i] + 2); // 依次计算每一个元素(注意i是下标位置)
System.out.println(Arrays.toString(array2)); // 这里计算让每个元素值+2
System.out.println(array.equals(array2)); // false // 数组是一个Object对象,因此直接使用数组的equals方法调用的是Object的equals方法,实际上使用的是Object类的equals方法
}
}
思考:当二维数组使用**Arrays.equals()进行比较以及Arrays.toString()**进行打印时,还会得到我们想要的结果吗?
public class Main {
public static void main(String[] args) {
// 这里用包装类型和基本类型一样的
Integer[][] array = {{1, 5}, {2, 4}, {7, 3}, {6}};
Integer[][] array2 = {{1, 5}, {2, 4}, {7, 3}, {6}};
System.out.println(Arrays.toString(array)); // [[Ljava.lang.Integer;@49e4cb85, [Ljava.lang.Integer;@2133c8f8, [Ljava.lang.Integer;@43a25848, [Ljava.lang.Integer;@3ac3fd8b]
System.out.println(Arrays.equals(array2, array)); // false
System.out.println(Arrays.deepToString(array)); // 使用deepToString就能打印多维数组 // [[1, 5], [2, 4], [7, 3], [6]]
System.out.println(Arrays.deepEquals(array2, array)); // 使用deepEquals几句能比较多维数组 // true
}
}
那么,一开始提到的当做List进行操作呢?我们可以使用**Arrays.asList()**来将数组转换为一个 固定长度的List
public class Main {
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = Arrays.asList(array); // 不支持基本类型数组,必须是对象类型数组
Arrays.asList("A", "B", "C"); // 也可以逐个添加,因为是可变参数
// list.add(1); // 此list实现是长度固定的,是Arrays内部单独实现的一个类型,因此不支持添加操作 // 报错
// list.remove(0); // 同理,也不支持移除 // 报错
list.set(0, 8); // 直接设置指定下标的值就可以
list.sort(Comparator.reverseOrder()); // 也可以执行排序操作
System.out.println(list); // 也可以像List那样直接打印 // [8, 7, 6, 5, 4, 3, 2]
}
}

文字游戏:allows arrays to be viewed as lists,实际上只是当做List使用,本质还是数组,因此数组的属性依然存在!因此如果要将数组快速转换为实际的List,可以像这样:
public class Main {
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = new ArrayList<>(Arrays.asList(array));
// 因为真正的ArrayList可以接受一个Collection类型的参数(又,所有的集合都继承自Collection,所以所有集合都可以当作这里的参数
// 这个假的ArrayList也是继承Collection的
}
}
通过自行创建一个真正的ArrayList并在构造时将Arrays的List值传递。
既然数组操作都这么方便了,集合操作能不能也安排点高级的玩法呢?那必须的,JDK为我们准备的Collocations类就是专用于集合的工具类:
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
Collections.max(list);
Collections.min(list);
}
}
当然,Collections提供的内容相比Arrays会更多,希望大家下去自行了解,这里就不多做介绍了。















 3508
3508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









