







打开终端的方法:ctrl + alt + t
放大: ctrl + shif +
缩小 :ctrl -

文件管理指令
常规指令
注意事项:命令区分大小写
1. ls命令查看文件列表
# 1. 查看文件列表
ls [-参数1参数2] [目标文件夹]
# 查看当前目录下的文件列表
ls
# 查看指定目录下的文件
ls /
# 查看详细信息,元数据信息(用户、组、大小、创建时间、权限信息、文件类型)
# 查看最长信息
ls -l
# 查看隐藏文件,所有文件
ls -a
# 查看最大大小的文件顺序排序
ls -S
# 参数并用
ls -la == ll //可以读取所以隐藏文件和详细信息


drwxrwxr-x 1 liudengfeng liudengfeng 4096 7月 21 16.44
d:文件类型,Linux里面不以后缀名作为文件类型的区分
linux里一共有其中文件类型bcd-lsp

2. cd命令–切换目录
# 2. 切换目录
cd 目标文件夹
# 绝对路径切换
cd 绝对路径
# 绝对路径切换
cd 相对路径
# 例子:切换到/etc/sysconfig/networks-scripts 目录下
cd ~ #直接进入home目录
cd . #当前目录
cd .. #上一级目录
cd - #回到上一次的路径
./ # 当前路径
../ # 上一级路径
3. pwd指令 – 查看当前命令所在的目录
pwd #查看当前路径
[root@centos7 network-scripts]# pwd
/etc/sysconfig/network-scripts
# 特殊目录符号
~ 当前用户的home目录
. 当前目录
.. 上一级目录
4. mkdir/rmdir指令 – 新建文件夹和文件/删除文件夹
# 在当前位置新建文件夹
mkdir 文件夹名
# 在指定目录位置,创建文件夹,并创建父文件夹
mkdir -p /a/b/文件夹名 //创建子文件夹
# 在当前目录下新建文件
touch 文件名


5. cp – 拷贝文件
# 拷贝文件
cp 原文件 新文件
# 拷贝文件夹
cp -r 源文件夹 新文件夹
cp 文件名1 文件名2 #直接将文件1的内容复制到文件2



6. rm – 删除文件
# 删除文件
rm 文件
# 删除文件夹
rm -r 文件夹
# 强制删除不询问
rm -rf 文件

7. mv指令 – 移动文件或修改文件名
# 移动源文件到目标文件夹中
mv 文件 文件夹
# 修改文件A的名字为文件B,重命名文件名
mv 文件A 文件B


8. md5sum指令 – 获取文件的md5指纹(数字签名)
md5sum 文件名
# 简介
1. 数字签名,又称数字指纹
2. 可以验证文件是否被修改
3. 一个文件通过计算得到的一串字符串,文件内容的唯一标记(文件内容不变,指纹不会变)
文件被修改后,签名也会发生改变
9.sort指令 – 文件排序
sort 文件名 # 对文件的内容进行排序
sort -r 文件名 # 对文件的内容进行反排序

tree指令 – 以树形呈现目录
sudo apt install tree
sudo apt-get install tree #安装tree
tree -L 层数



清屏命令 – **clear 或者快捷键 ctrl + l **
man指令 – 帮助手册


man man

- 可执行程序
- 系统调用
- 库调用
- 特殊文件
- File formats and conventions
- 游戏
- 杂项
- 系统管理命令
- 内核例程

检查一些C中的头文件
man stdio


文件处理指令 – 三剑客
sed 命令 – 利用脚本来处理文本文件
- sed 可依照脚本的指令来处理、编辑文本文件。
- sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
- **-e
动作说明:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何东东;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正则表达式!例如 1,20s/old/new/g 就是啦!

新增内容
在 testfile 文件的第四行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令:
sed -e 4a\newLine testfile
使用 sed 命令后,输出结果如下:
在第2行之前添加内容
$ nl testfile | sed '2i drink tea'
1 HELLO LINUX!
drink tea
2 Linux is a free unix-type opterating system.
3 This is a linux testfile!
4 Linux test
5 Google
6 Taobao
7 Runoob
8 Tesetfile
9 Wiki
如果是要增加两行以上,在第二行后面加入两行字,例如 Drink tea or … 与 drink beer?每一行之间都必须要以反斜杠 \ 来进行新行标记。
$ nl testfile | sed '2a Drink tea or ......\
drink beer ?'
1 HELLO LINUX!
2 Linux is a free unix-type opterating system.
Drink tea or ......
drink beer ?
3 This is a linux testfile!
4 Linux test
5 Google
6 Taobao
7 Runoob
8 Tesetfile
9 Wiki
以行为单位的新增/删除
将 testfile 的内容列出并且列印行号,同时,请将第 2~5 行删除!
$ nl testfile | sed '2,5d'
1 HELLO LINUX!
6 Taobao
7 Runoob
8 Tesetfile
9 Wiki
sed 的动作为 2,5d,那个 d 是删除的意思,因为删除了 2-5 行,所以显示的数据就没有 2-5 行了, 另外,原本应该是要下达 sed -e 才对,但没有 -e 也是可以的,同时也要注意的是, sed 后面接的动作,请务必以 ‘…’ 两个单引号括住喔!
要删除第 3 到最后一行:
$ nl testfile | sed '3,$d'
1 HELLO LINUX!
2 Linux is a free unix-type opterating system.
$ 代表的是最后一行
以行为单位的替换与显示
将第 **2-5 **行的内容取代成为 No 2-5 number 呢?
$ nl testfile | sed '2,5c No 2-5 number'
1 HELLO LINUX!
No 2-5 number
6 Taobao
7 Runoob
8 Tesetfile
9 Wiki
仅列出 testfile 文件内的第 5-7 行:
$ nl testfile | sed -n '5,7p'
5 Google
6 Taobao
7 Runoob
数据的搜寻并显示
搜索 testfile 有 oo 关键字的行:
$ nl testfile | sed -n '/oo/p'
5 Google
7 Runoob
数据的搜寻并删除

删除 testfile 所有包含 oo 的行,其他行输出
$ nl testfile | sed '/oo/d'
1 HELLO LINUX!
2 Linux is a free unix-type opterating system.
3 This is a linux testfile!
4 Linux test
6 Taobao
8 Tesetfile
9 Wiki
数据的搜寻并执行命令
搜索 testfile,找到 oo 对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把 oo 替换为 kk,再输出这行:
$ nl testfile | sed -n '/oo/{s/oo/kk/;p;q}'
5 Gkkgle
# q是推出
数据的查找与替换
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的查找与替换<。
sed 的查找与替换的与 vi 命令类似,语法格式如下:
sed 's/要被取代的字串/新的字串/g'
将 testfile 文件中每行第一次出现的 oo 用字符串 kk 替换,然后将该文件内容输出到标准输出:
sed -e 's/oo/kk/' testfile
g 标识符表示全局查找替换,使 sed 对文件中所有符合的字符串都被替换,修改后内容会到标准输出,不会修改原文件:
sed -e 's/oo/kk/g' testfile
选项 i 使 sed 修改文件:
sed -i 's/oo/kk/g' testfile
批量操作当前目录下以 test 开头的文件:
sed -i 's/oo/kk/g' ./test*
多点编辑
一条 sed 命令,删除 testfile 第三行到末尾的数据,并把 HELLO 替换为 RUNOOB :
$ nl testfile | sed -e '3,$d' -e 's/HELLO/RUNOOB/'
1 RUNOOB LINUX!
2 Linux is a free unix-type opterating system.
awk命令 – 处理文本 格式化
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符
linux中有三剑客之称:
三剑客之首就是 AWK
三剑客功能:
grep : 过滤文本
sed : 修改文本
awk : 处理文本
awk的作用: awk主要是用来格式化
awk [参数] [处理内容] [操作对象]
主要参数:
-F : 指定文本分隔符 (本身默认是以空格作为分隔符)
awd -F'f' '{print $NF}' 1.txt
-F’f’ : 指定f为分隔符
常用指令
$0 : 代表当前行(相当于匹配所有)
awk -F: '{print $0, "---"}' /etc/passwd

$n : 代表第n列
案例1:(以:为分隔符)
awk -F: '{print $1}' /etc/passwd
# 输出第一列的内容

案例2:(默认空格为分隔符)
awk '{print $1}' /etc/passwd
NF : 记录当前统计总字段数
案例1:(以:为分隔符 统计文件内每行内的行数)
awk -F: '{print NF}' /etc/passwd

案例2:(以:为分隔符 统计文件内每行总字段 并打印每行统计行数)
awk -F: '{print $NF}' /etc/passwd

NR : 用来记录行号
案例1:
awk -F: '{print NR}' /etc/passwd

FS : 指定文本内容分隔符(默认是空格)
案例1:
awk 'BEGIN{FS=":"}{print $NF, $1}' /etc/passwd


解析:
BEGIN{FS=“:”} : 相当于指定以 : 为分隔符
$NF : 存储以 : 分隔符的最后一列
$1 : 存储以 : 分隔符的第一列
print : 打印
OFS : 指定打印分隔符(默认空格)
案例1:(输出的意思 分隔符会打印出来)
awk -F: 'BEGIN{OFS=" >>> "}{print $NF, $1}' /etc/passwd
**FS 的优先级要高于 -F **
解析:
BEGIN{OFS=" >>> "} : 指定打印分隔符
$NF : 存储以 >>> 分隔符的最后一列
1
:
存储以
>
>
>
分隔符的第一列
∗
∗
<
b
r
/
>
∗
∗
p
r
i
n
t
:
打印
∗
∗
<
b
r
/
>
∗
∗
N
F
:
统计总字段数
∗
∗
<
b
r
/
>
∗
∗
1 : 存储以 >>> 分隔符的第一列**<br />**print : 打印**<br />**NF : 统计总字段数**<br />**
1:存储以>>>分隔符的第一列∗∗<br/>∗∗print:打印∗∗<br/>∗∗NF:统计总字段数∗∗<br/>∗∗ : 取值
结合作用:
配合
N
F
使用
:
N
F
内存储统计文件内每行的总字段,
配合NF使用 : NF内存储统计文件内每行的总字段,
配合NF使用:NF内存储统计文件内每行的总字段,存储NF内的值
NF :相当于 变量值 $ :相当于 变量名
print相当于打印 $ 内的内容



awk的生命周期
grep,sed和awk都是读一行处理一行,直到处理完成。
接收一行作为输入
把刚刚读入进来得到文本进行分解
使用处理规则处理文本
输入一行,赋值给$0,直至处理完成
把处理完成之后的所有数据交给END{}来再次处理
三:awk运行处理规则的执行流程
- BEGIN{} : 最开始执行
- // : 正则
- {} : 循环体
- END{} : 最后执行
这里面最少有一个,最多有四个!
四:awk中的函数
print : 打印
printf : 格式化打印
%s : 字符串
%d : 数字
- : 左对齐
+ : 右对齐
15 : 至少占用15字符
awk中函数(格式化打印)
案例1:
awk -F: 'BEGIN{OFS=" | "}{printf "|%+15s|%-15s|\n", $NF, $1}' /etc/passwd

解析:
| : 以 | 为分隔符
|%+15s| : 以 | 为分隔符 %s 配合 printf 使用 代替当前字符串 右对齐 占用15字符
|%-15s| : 以 | 为分隔符 %s 配合 printf 使用 代替当前字符串 左对齐 占用15字符
\n : 换行符
$NF : 存储以 | 为分隔符的最后一列
$1 : 存储以 | 为分隔符的第一列
五:awk中的定位
1.正则表达式
案例1:(awk中匹配有root内容的行)
awk -F: '/root/{print $0}' /etc/passwd
解析:
/root/{print $0} : awk中先执行正则 在执行循环 匹配文件内有root的每一行。
$0 :代表所有
案例2:(awk中匹配root开头的行)
awk -F '/^root/{print $0}' /etc/passwd
六:比较表达式(匹配文本之内的内容)
> : 小于
< : 大于
>= : 小于等于
<= : 大于等于
~ : 正则匹配(包含)
!~ : 正则匹配(不包含)
# 要求打印属组ID大于属主ID的行
awk -F: '$4 > $3{print $0}' /etc/passwd
解析:
$4 : 代表属组所在列
$3 : 代表属主所在列
$0 : 所有行
# 打印结尾包含bash
awk -F: '$NF ~ /bash/{print $0}' /etc/passwd
解析:
$NF ~ /bash/ :尾部最后一列 包含 bash 的行
~ : 包含
# 打印结尾不包含bash
awk -F '$NF !~ /bash/{print $0}' /etc/passwd
解析:
!~ : 不包含 (将打印其他内容)
七:条件表达式(文本之外的内容)
==
>
<
>=
<=
# 要求打印第三行
awk -F: 'NR == 3{print $0}' /etc/passwd
解析:
NR : 行号
NR == 3 : 行号等于3
注意:
$1 : 是列
NR == 3 : 是行

八:逻辑表达式
&& : 逻辑与
|| : 逻辑或
! : 逻辑非
awk -F: '$3 + $4 > 2000 && $3 * $4 > 2000{print $0}' /etc/passwd
awk -F: '$3 + $4 > 2000 || $3 * $4 > 2000{print $0}' /etc/passwdawk -F: '!($3 + $4 > 2000){print $0}' /etc/passwd
awk -F: '!($3 + $4 > 2000){print $0}' /etc/passwd
九:算数表达式
+ :加
- :减
* :乘
/ :除
% :求余
1.要求匹配打印出属组 + 属主的ID 大于 2000 的
awk -F: '$3 + $4 > 2000{print $0}' /etc/passwd
2.要求属组 * 属主的ID 大于 2000
awk -F: '$3 * $4 > 2000{print $0}' /etc/passwd
3.要求打印偶数行
awk -F: 'NR % 2 == 0{print $0}' /etc/passwd
解析:
NR :全部行号 除以 2 == 零的 零等于余数
4.要求打印奇数行
awk -F: 'NR % 2 == 1{print $0}' /etc/passwd
NR :全部行号 除以 2 == 1的 零等于奇数
NR :全部行号 除以 2 == 1的 零等于奇数

十:流程控制
if:
awk -F: '{if($3>$4){print "大于"}else{print "小于或等于"}}' /etc/passwd
解析:
判断文件 第三列大于第四列的话打印(大于) 不大于 else
if 使用格式:
if(){} : 但分支
if(){}else{} : 双分支
if(){}else if(){}else{} : 多分支
for每一行打印10次
for 使用格式
awk -F: '{for(i=10;i>0;i--){print $0}}' /etc/passwd
解析:
i-- 相当于python中的 i-=1 : i=i-1
减到条件不成立为止
格式:
fro(i="初始值":条件判断:游标){}
while每一行打印10次
while 使用格式
awk -F: '{i=1; while(i<10){print $0, i++}}' /etc/passwd
解析:
i++ 相当于python中的 i+=1
加到条件不成立为止
格式:
while(条件判断){}
每隔5行,打印一行横线
1.使用if判断
awk -F: '{if(NR%5==0){print "----------"}print $0}' /etc/passwd
解析:
1. NR : 每一行的行号
2. 行号 除以 5 ==0
3. 打印一行
以此类推 4%5=0.8

4. 查看文件内容
cat指令 – 文本内容查看命令
- cat命令 : 查看文件中的全部信息(适合查看小文档)
- tac命令: 从文件的最后一行开始显示(tac是cat的倒着写)
- more命令:以一页一页的形式显示,更方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示
- less命令 : 以分页的方式浏览文件信息(适合查看大文档),进入浏览模式
- tail命令 : 可以选择看文件的倒数几行
- head命令 :可以选择看文件的开头几行内容
- nl命令: 在显示内容的时候同时还会显示行数
可以使用 man [命令]来查看命令的使用文档
# 查看文件中的全部信息(适合查看小文档)
cat 文件名
cat [-AbEnTv]
选项与参数:
- -A :相当于 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
- -b :列出行号,仅针对非空白行做行号显示,空白行不标行号!
- -E :将结尾的断行字节 $ 显示出来;
- -n :列印出行号,连同空白行也会有行号,与 -b 的选项不同;
- -T :将 [tab] 按键以 ^I 显示出来;
- -v :列出一些看不出来的特殊字符

more 指令–以一行一行形式呈现文件内容
more [-dlfpcsu] [-num] [+/pattern] [+linenum] [fileNames..]
more -s testfile # 逐页显示 testfile 文档内容,如有连续两行以上空白行则以一行空白行显示。
more +20 testfile # 从第 20 行开始显示 testfile 之文档内容。
- -num 一次显示的行数
- -d 提示使用者,在画面下方显示 [Press space to continue, ‘q’ to quit.] ,如果使用者按错键,则会显示 [Press ‘h’ for instructions.]
- -l 取消遇见特殊字元 ^L(送纸字元)时会暂停的功能
- -f 计算行数时,以实际上的行数,而非自动换行过后的行数(有些单行字数太长的会被扩展为两行或两行以上)
- -p 不以卷动的方式显示每一页,而是先清除萤幕后再显示内容
- -c 跟 -p 相似,不同的是先显示内容再清除其他旧资料
- -u 不显示下引号 (根据环境变数 TERM 指定的 terminal 而有所不同)
- +/pattern 在每个文档显示前搜寻该字串(pattern),然后从该字串之后开始显示
- +num 从第 num 行开始显示
- fileNames 欲显示内容的文档,可为复数个数

nl 指令 – 显示行数
nl 文件名

显示行数
less指令–以分页的方式浏览文件信息(适合查看大文档),进入浏览模式
# 以分页的方式浏览文件信息(适合查看大文档),进入浏览模式
less 文件名
# 浏览模式快捷键
↑ #上一行
↓ #下一行
G #最后一页
g #第一页
空格 #下一页
/关键词 #搜索关键词
# 退出浏览模式,回到Linux命令行模式
q #退出
head命令 – 显示文件开头几行的信息
# 显示文件的开头20行信息
head -n 20 文件名
head -n -20 文件名
head file #默认打开前10行
tail指令 – 实时滚动显示文件的最后10行信息(默认10行)
tail file #默认最后10行
# 实时滚动显示文件的最后10行信息(默认10行)
tail -f 文件名
# 显示文件的最后20行信息
tail -n 20 文件名
tail -n -20 文件名
# 显示文件信息从第20行至文件末尾
tail -n +20 文件名


5. 文件查找
1. find 指令 – 文件名查找
需要管理员root权限才能查找
# 语法
find 搜索路径 -name "文件名关键词"
# 例子
find / -name "passwd"
find / -name "ifcfg-*"
find . -name mydir2 #会从制定目录下寻找包括子目录中的文件

find . -name "*.c" # 查找当前路径下的所有.c文件

2.locate命令 – 查找文件或者目录
locate(locate) 命令用来查找文件或目录。
locate命令要比find -name快得多,原因在于它不搜索具体目录,而是搜索一个数据库/var/lib/mlocate/mlocate.db 。
这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次,因此,我们在用whereis和locate查找文件时,有时会找到已经被删除的数据,或者刚刚建立文件,却无法查找到,原因就是因为数据库文件没有被更新。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。整个locate工作其实是由四部分组成的。
- /usr/bin/updatedb 主要用来更新数据库,通过crontab自动完成的
- /usr/bin/locate 查询文件位置
- /etc/updatedb.conf updatedb的配置文件
- /var/lib/mlocate/mlocate.db 存放文件信息的文件
locate [OPTION]... [PATTERN]...
-e 将排除在寻找的范围之外。
-1 如果 是 1.则启动安全模式。在安全模式下,使用者不会看到权限无法看到 的档案。这会使速度减慢,因为 locate 必须至实际的档案系统中取得档案的 权限资料。
-f 将特定的档案系统排除在外,例如我们没有必要把 proc 档案系统中的档案 放在资料库中。
-q 安静模式,不会显示任何错误讯息。
-n 至多显示 n个输出。
-r 使用正规运算式 做寻找的条件。
-o 指定资料库存的名称。
-d 指定资料库的路径
-h 显示辅助讯息
-V 显示程式的版本讯息
查找与pwd相关的文件
locate pwd
# 先安装 sudo apt install mlocate


搜索etc目录下所有以sh开头的文件
locate /etc/sh


3. grep指令 – 文件内容查找
grep 是 Linux/Unix 系统中的一个命令行工具,用于从文件中搜索文本或字符串。grep 代表全局正则表达式打印。当我们使用指定字符串运行 grep 命令时,如果匹配,则它将显示包含该字符串的所在行,而不修改现有文件的内容。
grep 查找信息 文件名
# 语法
$ grep <Options> <Search String> <File-Name>
grep -参数 要查找的目录范围
# 参数
-n 显示查找结果所在行号
-R 递归查找目录下的所有文件
-r
-l 打印匹配的单词存在的文件
-v 反转,匹配文件中不存在“”后的结果
-B n 匹配前n行
-A n 匹配后n行
-c 计算匹配的行数
-e 连接多个指令
-E 使用|来连接多条指令
# 例子
grep aries /etc
grep aries /etc/passwd


(1) 在文件中搜索单词或字符串
$ grep nobody /etc/passwd
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
$

(2) 多文件中的搜索模式
可以使用 grep 命令在多个文件中搜索单词或模式。
例如:在 /etc/passwd,/etc/shadow, /etc/gshadow 文件中搜索 linuxtechi
sudo grep linuxtechi /etc/passwd /etc/shadow /etc/gshadow

(3) 打印与模式匹配的文件名
假设我们想列出包含单词“root”的文件名,可以在 grep 命令中使用“-l”选项,后跟单词(模式)和文件。
$ grep -l 'root' /etc/fstab /etc/passwd /etc/mtab
/etc/passwd
$
(4) 显示带有行号的输出行
使用 “-n” 选项显示与模式或单词匹配的行及其编号。
$ grep -n 'nobody' /etc/passwd
18:nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
$
(5) 反转模式匹配
使用 grep 命令中的选项 “-v”,我们可以显示与模式不匹配的行
$ grep -v 'nobody' /etc/passwd
6) 打印以特定字符开头的所有行
Bash Shell 将插入符号 “^” 视为特殊字符,用于标记行或单词的开头。
让我们显示文件 /etc/passwd 中以 “backup” 开头的行
$ grep ^backup /etc/passwd
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
$

(7) 打印以特定字符结尾的所有行
Bash Shell 将美元符号 “$” 视为一个特殊字符,用于标记行或字的结尾。
让我们列出 /etc/passwd 中以 “bash” 结尾的所有行
$ grep bash$ /etc/passwd
root:x:0:0:root:/root:/bin/bash
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
$

(8) 递归搜索模式
“-r” 选项用于在文件夹和子文件夹中递归搜索模式。
假设我们想递归地搜索 /etc 文件夹中的模式 “nologin”
$ sudo grep -r nobody /etc
/etc/shadow:nobody:*:19101:0:99999:7:::
/etc/shadow-:nobody:*:19101:0:99999:7:::
/etc/passwd:nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
/etc/ssh/sshd_config:#AuthorizedKeysCommandUser nobody
/etc/passwd-:nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
$

(9) 打印文件中的所有空行
使用特殊字符组合 “^$” 打印文件中的所有空行
$ grep '^$' /etc/sysctl.conf
打印空行的行号
$ grep -n '^$' /etc/sysctl.conf


(10) 搜索时忽略字母大小写
“-i” 选项忽略模式和数据中的字母大小写
假设我们希望在 sysctl.conf 文件中搜索 “IP_Forward” 字符串
$ grep IP_Forward /etc/sysctl.conf
$
$ grep -i IP_Forward /etc/sysctl.conf
#net.ipv4.ip_forward=1
$

使用 “-w” 选项仅匹配整个单词
$ sudo sysctl -a | grep -w 'vm.swappiness'
vm.swappiness = 60
$
(11) 匹配多个模式
借助 grep 命令中的 “-e” 选项,我们可以在单个命令中搜索多个模式。
$ grep -e nobody -e mail /etc/passwd
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
$


$ grep -E "nobody|mail" /etc/passwd
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
$

(12) 从文件中获取模式
grep 命令中的 “-f” 选项允许从文件中获取模式。示例如下所示:
首先在当前工作目录中创建名为 “grep_pattern” 的搜索模式文件,我已事先将以下内容放入其中。
现在尝试使用 “grep_pattern” 文件进行搜索
$ grep -f grep_pattern /etc/passwd

(13) 计算与模式匹配的行数
“-c” 选项用于计算与搜索模式匹配的行数。
假设我们要计算 /etc/password 文件中以 “false” 结尾的行数
$ grep -c false$ /etc/passwd
7
$

(14) 打印模式匹配前后的 N 行
(a) 打印在模式匹配之前的四行,使用 “-B” 选项
$ grep -B 4 "games" /etc/passwd

(b) 打印在模式匹配之后的四行,使用 “-A” 选项
$ grep -A 4 "games" /etc/passwd

6. ln指令 – 创建文件链接
它的功能是为某一个文件在另外一个位置建立一个同步的链接。当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在 其它的目录下**用ln命令链接(link)**它就可以,不必重复的占用磁盘空间。
1. Linux文件管理
- 模型图

- 说明
# 文件名
该文件的名字
# inode
该文件的元数据
# datablock
该文件真正保存的数据
文件名 -> 链接到 -> inode【元数据】->数据块【databolcks】(真正保存的数据)
注意:
1、inode中保存的是文件的元数据
2、ls命令查看的都是linux的元数据信息
3、数据块中才是文件的真正数据

ln [参数][源文件或目录][目标文件或目录]
[-bdfinsvF] [-S backup-suffix] [-V {numbered,existing,simple}]
[--help] [--version] [--]
Linux文件系统中,有所谓的链接(link),我们可以将其视为档案的别名,而链接又可分为两种 : 硬链接(hard link)与软链接(symbolic link),
硬链接的意思是一个档案可以有多个名称,而软链接的方式则是产生一个特殊的档案,该档案的内容是指向另一个档案的位置。硬链接是存在同一个文件系统中,而软链接却可以跨越不同的文件系统。
不论是硬链接或软链接都不会将原本的档案复制一份,只会占用非常少量的磁碟空间。
必要参数:
- –backup[=CONTROL] 备份已存在的目标文件
- -b 类似 –backup ,但不接受参数
- -d 允许超级用户制作目录的硬链接
- -f 强制执行
- -i 交互模式,文件存在则提示用户是否覆盖
- -n 把符号链接视为一般目录
- -s 软链接(符号链接)
- -v 显示详细的处理过程
选择参数:
- -S "-S<字尾备份字符串> "或 “–suffix=<字尾备份字符串>”
- -V “-V<备份方式>“或”–version-control=<备份方式>”
- –help 显示帮助信息
- –version 显示版本信息
2. 硬链接 ln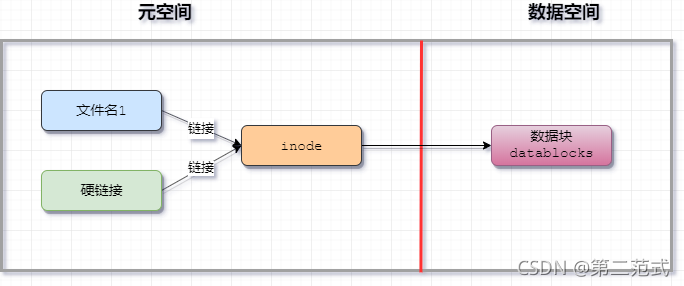
- 硬链接,以文件副本的形式存在。但不占用实际空间。
- 不允许给目录创建硬链接
- 硬链接只有在同一个文件系统中才能创建
- 源文件如果失效,硬链接不受影响
命令
ln 源文件 硬链接文件
3. 软连接 ln -s

- 软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
- 软链接可以 跨文件系统 ,硬链接不可以
- 软链接可以对一个不存在的文件名进行链接
- 软链接可以对目录进行链接
- 源文件如果失效,则软链接也会失效
ln -s 目标文件或文件夹 软连接名字
ln -s 1.c link1 # 为1.c文件创建link1的软链接,
# 1.c文件如果失效,则软链接也会失效

给文件创建硬链接
ln 1.c link2


8. tee/< – 输入/输出指令
tee指令 – 用于读取标准输入的数据
tee命令用于读取标准输入的数据,并将其内容输出成文件。
tee [-ai][--help][--version][文件...]
参数:
- -a或–append 附加到既有文件的后面,而非覆盖它
- -i或–ignore-interrupts 忽略中断信号
- –help 在线帮助
- –version 显示版本信息
使用指令"tee"将用户输入的数据同时保存到文件"file1"和"file2"中,输入如下命令:
tee file1 file2
以上命令执行后,将提示用户输入需要保存到文件的数据,如下所示:
My Linux #提示用户输入数据
My Linux #输出数据,进行输出反馈
此时,可以分别打开文件"file1"和"file2",查看其内容是否均是"My Linux"即可判断指令"tee"是否执行成功。
重定向
>和>>
**覆盖输出 > **
# 将命令1的执行结果,输出到后面的文件中。
`覆盖写入`
命令1 > 文件
# 例子
date > date.log

将日期加入到文件中,覆盖掉之前的内容
追加输出 >>
# 将命令1的执行结果,输出到后面的文件中。
`追加写入`
命令1 >> 文件
# 例子
date >> date.log

追加写入数据
1> 和 2>
他们两个用于将一个文件正确的输出,和错误的输出分开保存。
1> 将正确的输出重定向到某个文件
2> 将错误的输出重定向到某个文件
将错误输出和正确输出保存到同一个文件:
command 1> a.txt 2>&1
或者写作:command > a.txt 2>&1
2>&1表明将文件描述2(标准错误输出)的内容重定向到文件描述符1(标准输出),为什么1前面需要&?当没有&时,1会被认为是一个普通的文件,有&表示重定向的目标不是一个文件,而是一个文件描述符。
1>> 和 2>>
同理1>> 2>>其实也就是追加数据到文件中,和前面介绍的>>没有什么不同,需要提到的一点是,如果我们想将错误的和正确的信息重定向追加到同一个文件应该怎么做呢?你可能会想到2>>&1。。。然而现实是,并没有这个语法。
然而我们却可以使用1 >> a.txt 2>&1的语法实现这个功能,比如:
command 1>> a.txt 2>&1
看似1> 1>> 2> 2>>是相一一对应的,但是其实不是,他们可以混用,比方说正确的结果想追加,错误的结果我想覆盖。
command 1>> right.txt 2> wrong.txt
如果我们想保存正确的结果,错误的结果直接丢向垃圾站,既不保存为文件,也不在标准输出打印又该怎么做呢?
command 1>> right.txt 2> /dev/null
直接将错误输出重定向到/dev/null就好了,他好像就是一个无底洞,丢进去的东西就不见了。
<
< 可以将原本由标准输入改为由指定地方输入,比如下面。
首先创建一个hh文件,里面写入hello world
然后执行 >> txt.py < hh
就可以把hh里面的内容写入到txt.py
9. 管道
一个程序的输出作为|后面的第二个程序的输入
# 语法,将命令1的输出结果,作为命令2的输入
命令1 | 命令2

# 例子
查找aries用户:cat /etc/passwd | grep -n “baizhi”
查找aries组:cat /etc/group | grep -n “baizhi”
查找sshd进程:ps -aux | grep sshd

11.yes指令 – 重复输出一个字符串,直到被杀死
命令简介 yes 重复输出一个字符串,直到被杀死。 yes 不带任何参数运行时默认输出的字符串是 y。
yes [STRING]...
yes OPTION
--help
显示此帮助并退出。
--version
输出版本信息并退出。

12.dd 命令 – 用于读取、转换并输出数据
dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
参数说明:
- if=文件名:输入文件名,默认为标准输入。即指定源文件。
- of=文件名:输出文件名,默认为标准输出。即指定目的文件。
- ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
- obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
- bs=bytes:同时设置读入/输出的块大小为bytes个字节。
- cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
- skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
- seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
- count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
- conv=<关键字>,关键字可以有以下11种:
- conversion:用指定的参数转换文件。
- ascii:转换ebcdic为ascii
- ebcdic:转换ascii为ebcdic
- ibm:转换ascii为alternate ebcdic
- block:把每一行转换为长度为cbs,不足部分用空格填充
- unblock:使每一行的长度都为cbs,不足部分用空格填充
- lcase:把大写字符转换为小写字符
- ucase:把小写字符转换为大写字符
- swap:交换输入的每对字节
- noerror:出错时不停止
- notrunc:不截短输出文件
- sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
将testfile文件中的所有英文字母转换为大写,然后转成为testfile_1文件,在命令提示符中使用如下命令:
dd if=testfile_2 of=testfile_1 conv=ucase
$ cat testfile_2 #testfile_2的内容
HELLO LINUX!
Linux is a free unix-type opterating system.
This is a linux testfile!
Linux test
$ dd if=testfile_2 of=testfile_1 conv=ucase #使用dd 命令,大小写转换记录了0+1 的读入
记录了0+1 的写出
95字节(95 B)已复制,0.000131446 秒,723 KB/s
cmd@hdd-desktop:~$ cat testfile_1 #查看转换后的testfile_1文件内容
HELLO LINUX!
LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM.
THIS IS A LINUX TESTFILE!
LINUX TEST #testfile_2中的所有字符都变成了大写字母
由标准输入设备读入字符串,并将字符串转换成大写后,再输出到标准输出设备,使用的命令为:
dd conv=ucase
输入以上命令后按回车键,输入字符串,再按回车键,按组合键Ctrl+D 退出,出现以下结果:
$ dd conv=ucase
Hello Linux! #输入字符串后按回车键
HELLO LINUX! #按组合键Ctrl+D退出,转换成大写结果
记录了0+1 的读入
记录了0+1 的写出
13字节(13 B)已复制,12.1558 秒,0.0 KB/s

13.文件比较
diff命令 – 比较文件差异
Linux diff命令用于比较文件的差异,检查两个文件内容是否相同,将不同的内容输出到屏幕
- diff以逐行的方式,比较文本文件的异同处
- 如果指定要比较目录,则diff会比较目录中相同文件名的文件,但不会比较其中子目录
- diff命令可以同时输出成补丁文件,并且Linux中还有一个patch命令,可以依据diff生成的.patch补丁文件,将a.c与b.c两个文件差异部分更新到需要修改的文件
- diff在SVN 、GIT、CVS等版本控制工具中也是不可或缺的一部分
diff[参数][文件1或目录1][文件2或目录2]
diff file1 file2 # 比较两个文件之间的差异
diff dir1/ dir2/ # 比较当前目录下的文件,不包括子目录
<行数>:指定要显示多少行的文本。此参数必须与-c或-u参数一并使用;
-a或--text:diff预设只会逐行比较文本文件;
-b或--ignore-space-change:不检查空格字符的不同;
-B或--ignore-blank-lines:不检查空白行;
-c:显示全部内容,并标出不同之处;
-C<行数>或--context<行数>:与执行“-c-<行数>”指令相同;
-d或——minimal:使用不同的演算法,以小的单位来做比较;
-D<巨集名称>或ifdef<巨集名称>:此参数的输出格式可用于前置处理器巨集;
-e或——ed:此参数的输出格式可用于ed的script文件;
-f或-forward-ed:输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处;
-H或--speed-large-files:比较大文件时,可加快速度;
-l<字符或字符串>或--ignore-matching-lines<字符或字符串>:若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异;
-i或--ignore-case:不检查大小写的不同;
-l或——paginate:将结果交由pr程序来分页;
-n或——rcs:将比较结果以RCS的格式来显示;
-N或--new-file:在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录,文件A 若使用-N参数,则diff会将文件A 与一个空白的文件比较;
-p:若比较的文件为C语言的程序码文件时,显示差异所在的函数名称;
-P或--unidirectional-new-file:与-N类似,但只有当第二个目录包含了第一个目录所没有的文件时,才会将这个文件与空白的文件做比较;
-q或--brief:仅显示有无差异,不显示详细的信息;
-r或——recursive:比较子目录中的文件;
-s或--report-identical-files:若没有发现任何差异,仍然显示信息;
-S<文件>或--starting-file<文件>:在比较目录时,从指定的文件开始比较;
-t或--expand-tabs:在输出时,将tab字符展开;
-T或--initial-tab:在每行前面加上tab字符以便对齐;
-u,-U<列数>或--unified=<列数>:以合并的方式来显示文件内容的不同;
-v或——version:显示版本信息;

Linux内核diff自定义的补丁
diff -ruN linux-4.19-rc3_lyn linux-4.19-rc3 > linux-4.19-rc3_lyn.patch

tkdiff命令: 并排查看两个输入文件之间差异
# 初次使用tkdiff会显示没有安装包
# 安装包
sudo apt install tkcvs
tkdiff file1 file2


Special Devices


/dev/null – 空设备

/dev/null 是一个特殊的设备文件,它丢弃一切写入其中的数据 .可以将它 视为一个黑洞, 它等效于只写文件, 写入其中的所有内容都会消失, 尝试从中读取或输出不会有任何结果,同样,/dev/null 在命令行和脚本中都非常有用
用途:
/dev/null 通常被用于丢弃不需要的输出流,或作为用于输入流的空文件,这些操作通常由重定向完成,任何你想丢弃的数据都可以写入其中
丢弃标准输出
在写shell脚本的时候,只想通过命令的结果执行后面的逻辑,而不想命令执行过程中有一大堆中间结果输出,这时候可以把命令执行过程中的输入全部写入 /dev/null
现有 a.sh 脚本,它的功能是判断传入的系统命令是否存在,脚本内容如下
1 #!/bin/bash
2 #判断命令是否存在,存在则返回该命令存在的日志
3 command -v $1
4
5 if [[ $? -eq 0 ]]; then
6 echo "command $1 exist..."
7 else
8 echo "command $1 not exist..."
9 fi
执行 ./a.sh top 命令,输出如下
[tt@ecs-centos-7 dev_test]$ ./a.sh top
/bin/top
command top exist...
说明: command -v 命令名 是查找指定命令名的命令是否存在,如果存在,输出指定命令名的路径,否则,不做任何输出
$? 表示前一条命令的执行结果, 0 表示成功,其他表示失败
脚本的执行结果中先输出了 top 命令的路径,紧接着输出了top命令存在的日志
把 command -v $1的结果重定向到 /dev/null 可以屏蔽掉 top命令路径的输出,调整之后的a.sh 内容如下
1 #!/bin/bash
2
# 把结果重定向到/dev/null屏蔽掉top的输出
3 command -v $1 >/dev/null
4
5 if [[ $? -eq 0 ]]; then
6 echo "command $1 exist..."
7 else
8 echo "command $1 not exist..."
9 fi
再次执行 ./a.sh top,结果如下
[tt@ecs-centos-7 dev_test]$ ./a.sh top
command top exist...
[tt@ecs-centos-7 dev_test]$
丢弃标准错误输出
在shell脚本中,删除一个文件的时候,需要先判断文件是否存在,然后才能执行删除操作,否则删除的时候会输出错误, 一般的删除文件脚本内容如下:
1 #!/bin/bash
2
3 if [ -f $1 ]; then
4 rm $1
5 fi
可以通过把删除命令的输出重定向到 /dev/null 来避免输出错误信息, 同时也不用判断文件是否存在了, 调整之后的删除脚本内容如下:
1 #!/bin/bash
2
3 rm $1 >/dev/null 2>$1
分别执行命令 ./d.sh t1.txt、./d.sh t2.txt ,结果如下:
[tt@ecs-centos-7 dev_test]$ ls t*.txt
t1.txt
[tt@ecs-centos-7 dev_test]$ ./d.sh t1.txt
[tt@ecs-centos-7 dev_test]$ ./d.sh t2.txt
[tt@ecs-centos-7 dev_test]$ ls t*.txt
ls: 无法访问t*.txt: 没有那个文件或目录
t1.txt 文件位于当前目录下,t2.txt 不存在,从执行结果可以看出,不管是删除存在的文件还是不存在的文件都不会有错误输出信息了
清空文件内容
清空文件内容有很多种方法,这里介绍一种利用 /dev/null 清空文件内容的方法,具体的示例如下:
[tt@ecs-centos-7 dev_test]$ cat t.txt
123456
[tt@ecs-centos-7 dev_test]$ cat /dev/null > t.txt
[tt@ecs-centos-7 dev_test]$ cat t.txt
/dev/zero – 零流源


提示:从文件属性可以看出这两个文件都是字符设备文件。
和/dev/null类似,/dev/zero也是一个特殊的字符设备文件,当我们使用或读取它的时候,它会提供无限连续不断的空的数据流(特殊的数据格式流)。
a./dev/zero文件覆盖其他文件信息
#<==生成一个新文件写入sztech字符串
echo sztech > new.txt
#<==用空的字符流覆盖存在的new.txt文件
dd if=/dev/zero of=new.txt bs=1M count=10

b.产生指定大小的空文件,例如:交换文件、模拟虚拟文件系统等
dd if= /dev/zero of=test.data bs=1M count=2
#<==生成块大小1M,含有2个块的文件。
ls -lh test.data
-rw-r--r--. 1 root root 2.0MJul 15 20:20 test.data
#<==一共2M大小。

提示:在使用dd命令产生空文件时常用/dev/zero作为字符流的源。
随机数
为了尽可能的做到随机,随机数生成器会收集系统环境中各种数据,比如:鼠标的移动,键盘的输入, 终端的连接以及断开,音视频的播放,系统中断,内存 CPU 的使用等等。
生成器把收集到的各种环境数据放入一个池子 ( 熵池 ) 中,然后将这些数据进行去偏、漂白,主要目的也是使得数据更加无序,更加难以猜测或者预料得到
有了大量的环境数据之后,每次获取随机数时,从池子中读取指定的字节序列,这些字节序列就是生成器生成的随机数
随机数生成器的结构
整个生成器的结构分成 收集器、主熵池、次熵池、urandom熵池、计数器 几部分
- 收集器
收集器收集系统中的环境噪音,比如:鼠标、键盘、中断事件、内存、CPU等,收集之后进行批量去偏、漂白之后进入主熵池中
- 主熵池
主熵池接收收集器传递过来的环境数据,大小为 512字节( 4098二进制位) , 它为 次熵池 和 urandom 熵池提供随机数。
- 次熵池
/dev/random 设备关连的,大小为128字节,它是阻塞的
- urandom 熵池
和 /dev/urandom 设备关连的,大小为128字节,它是非阻塞的
- 计数器
主熵池 、次熵池 以及 urandom熵池各自都有一个计数器,用一个整数值来记录,表示当前熵池中可用随机数的数量,这是一个预估的值,它是生成器根据熵池中的环境数据估算出来的。
当熵池中有新的随机数加入时,对应熵池的计数器计数会增加,当熵池中随机数被取出时,熵池计数器计数减少
输出接口
生成器主要有 /dev/random、/dev/urandom get_random_bytes() 这三个接口
- /dev/random、/dev/urandom
可以从用户空间去访问这两设备文件,即使是普通用户也有访问权限,它们返回指定请求数量的随机数
- get_random_bytes()
只供内核使用的接口, 返回指定请求数量的随机数,暂时不讨论这个接口
请求随机数流程
/dev/random和/dev/urandom是Linux系统中提供的随机伪设备,这两个设备的任务,是提供永不为空的随机字节数据流。很多解密程序与安全应用程序(如SSH Keys,SSL Keys等)需要它们提供的随机数据流。
/dev/random – 真随机数发生器
次熵池计数器减去 N, 如果结果大于等于0,直接从 次熵池中取出 N 个随机二进制位并返回
如果结果小于 0, 先从主熵池提取剩余所需的随机二进制位,主熵池计数器减去相应的值,同时返回 N 个随机二进制位
如果这时主熵池和次熵池两者计数器之和都不够 N 的话, 则读取随机二进制位的动作会被阻塞,直到次熵池中有足够的随机二进制位
/dev/urandom – 伪随机数发生器
urandom 熵池计数器计数会减去 N ,如果结果大于等于0 ,直接从urandom熵池中取出 N 个随机二进制位并返回,如果结果小于0,请求不会阻塞,只不过返回的是 N 个伪随机二进制位,这里的伪随机二进制位是通过算法计算出来的,它的质量没有 urandom 熵池中提取出的随机二进制位高
区别:
- /dev/random的random pool依赖于系统中断,因此在系统的中断数不足时,/dev/random设备会一直封锁,尝试读取的进程就会进入等待状态,直到系统的中断数充分够用, /dev/random设备可以保证数据的随机性。/dev/urandom不依赖系统的中断,也就不会造成进程忙等待,但是数据的随机性也不高。
- 在cat的过程中发现,/dev/random产生的速度比较慢,有时候还会出现较大的停顿,而/dev/urandom的产生速度很快,基本没有任何停顿。
- 而使用dd命令从这些设备中copy数据流,发现速度差异很大:通过程序测试也发现:/dev/random设备被读取的越多,它的响应越慢.
- /dev/urandom 它返回指定请求数量的随机数,如果请求的数量非常庞大的话,返回的随机数可能是伪随机数,随机数质量稍差些,即使如此,它们对大多数应用来说已经足够了
- /dev/random 也是返回指定请求数量的随机数,但是它产生的随机数质量很高, 是属于真随机数, 主要用于需要高质量的随机数的地方,比如:生成加密密钥等。
- 为了保证随机数的质量,/dev/random 只能返回熵池当前最大可用的随机二进制位,当请求超过这个值,就会阻塞,直到熵池中有足够的随机二进制位
首先要明确一点,/dev/random 和 /dev/urandom 产生的随机数都是从同一个熵池 ( 主熵池 ) 中提取的,只有当各自的熵池耗尽了,它们的行为才有所不同: /dev/random 阻塞,而 /dev/urandom 没有,但是此时它返回的是用算法计算出来的伪随机数
- 一般有个规则,/dev/random 产生的随机数质量高,主要用于一些安全方面,而且,它是阻塞的,对于大部分应用来说,这是不能接受的
- 对于 /dev/urandom ,当熵池计数器足够的时候,产生真随机数,计数不够的时候,产生伪随机数,最重要的是 它不会阻塞,而且,对于绝大多数的应用来说,伪随机数也能很好的满足需求了
/dev/full – 满设备
/dev/full 满设备。任何写入都将失败,并把errno设为ENOSPC(没有剩余空间);任何读取都将得到无限多的二进制零流。
这个设备通常被用来测试程序在遇到磁盘无剩余空间错误时的行为。
echo命令 – 打印到标准输出中
echo 通常用于 shell 脚本中,用于显示消息或输出其他命令的结果。
echo [-neE] [ARGUMENTS]
当-n 选项,则取消尾随换行符
如果-e 选项,则将解释以下反斜杠转义字符:
\ 显示反斜杠字符
\a 警报(BEL)
\b 显示退格字符
\c 禁止任何进一步的输出
\e 显示转义字符
\f 显示窗体提要字符
\n 显示新行
\r 显示回车
\t 显示水平标签
\v 显示垂直标签
这个-E 项禁用转义字符的解释。这是默认值
echo "Hello, World!"
Hello, World!
若要打印双引号,请将其包含在单引号内,或用反斜杠字符进行转义。
模式匹配字符
echo 命令可以与模式匹配字符一起使用,比如通配符。 例如,下面的命令将返回所有。 工作目录中的 php 文件。
echo The PHP files are: *.php
The PHP files are: index.php contact.php functions.php2

显示变量
echo 还可以显示变量。在下面的示例中,我们将输出当前登录用户的名称:
echo $USER #$USER 是一个保存用户名的 shell 变量。
admin

显示命令的输出
使用 $(command)表达式将命令输出包含在 echo 的参数中。
echo "The date is: $(date +%D)"
The date is: 04/01/20
echo "Today is : $(date +%D)"
Today is : 07/13/23
echo "Today is : $(date +%Y%m%d-%H%M%S)"
Today is : 20230713-145600
echo "Today is : $(date +%Y-%m-%d-%H:%M:%S)"
Today is : 2023-07-13-14:56:17

time命令 – 统计给定命令所花费的总时间
time [参数]
指令:指定需要运行的额指令及其参数。
> time ls
real 0m0.001s
user 0m0.000s
sys 0m0.002s

- real时间是指挂钟时间,也就是命令开始执行到结束的时间。这个短时间包括其他进程所占用的时间片,和进程被阻塞时所花费的时间。
- user时间是指进程花费在用户模式中的CPU时间,这是唯一真正用于执行进程所花费的时间,其他进程和花费阻塞状态中的时间没有计算在内。
- sys时间是指花费在内核模式中的CPU时间,代表在内核中执系统调用所花费的时间,这也是真正由进程使用的CPU时间。

env命令 – 显示系统中已存在的环境变量,以及在定义的环境中执行指令
env命令用于显示系统中已存在的环境变量,以及在定义的环境中执行指令。该命令只使用”-“作为参数选项时,隐藏了选项”-i”的功能。若没有设置任何选项和参数时,则直接显示当前的环境变量。
如果使用env命令在新环境中执行指令时,会因为没有定义环境变量”PATH”而提示错误信息”such file or directory”。此时,用户可以重新定义一个新的”PATH”或者使用绝对路径。
env # 显示系统的环境变量
env -u LOGNAME # 从当前环境中删除指定的变量
env LOGNAME=root # 定义指定的环境变量



alias 命令 – 命令行上的工作更加顺畅
通常情况下alias命令适合下面场景:
- 简化过长且过于复杂的命令
- 记住复杂名称的命令
- 使用你经常使用的命令节省时间
创建alias
设置一个别名列出所有文件包括隐藏文件,别名为la:
alias la='ls -al'
# 执行别名
la
total 68
dr-xr-x---. 3 root root 216 May 25 13:13 .
drwxr-xr-x. 19 root root 271 May 7 15:12 ..
-rw-------. 1 root root 1178 Dec 29 2019 anaconda-ks.cfg
-rw-------. 1 root root 14798 May 20 01:48 .bash_history
-rw-r--r--. 1 root root 18 May 11 2019 .bash_logout
-rw-r--r--. 1 root root 176 May 11 2019 .bash_profile

如果要永久使用,可以将该命令写入~/.bashrc文件里面。
echo "alias la='ls -al'" >> ~/.bashrc

如何列出alias
使用alias命令列出系统中已设置的所有别名:
alias

检查命令类型是否是别名
要检查命令是否为别名,请使用which命令。如下实例显示的内容就是别名。
[root@server1 ~]# which la
alias la='ls -al'
/usr/bin/ls
如何删除alias
如果需要停用别名,则可以使用unalias命令。要使更改永久生效,就需要在~/.bashrc文件中删掉对应的别名。
unalias la
对常用命令使用alias
[root@server1 ~]# alias c='clear'
[root@server1 ~]# alias ll='ls -al'
[root@server1 ~]# alias new='ls -1tr | tail -5'
使用alias避免长字符串的选项
别名对于记住较长的命令选项非常有用。例如,要解压文件可以使用如下别名:
alias untar='tar -xvf'
使用alias查看命令的历史记录
要使用搜索字词查看历史记录,请执行以下操作
alias rec='history | grep'
这可以看到在历史记录中保留的相关记录,例如:
rec alias
显示你的IP地址
alias myip='hostname -I'

history 命令 – 列出全部历史命令

注:~/.bash_history文件会自动保存当前用户使用过的历史命令
列出最近的5条记录
history -w——将本次登录的命令写入命令历史文件中, 默认写入~/.bash_history
linux命令行使用打印机

lpq --查看打印队列
lpq指令用来显示当前打印队列的状态。如果命令行中没有指定打印机或类,则将显示默认目标上排队的作业。
lpq [ -E ] [ -U username ] [ -h server[:port] ] [ -P destination[/instance] ] [ -a ] [ -l ] [ +interval ]


cancel --取消打印任务
cancel指令用来取消已经存在的打印任务。
cancel [ -E ] [ -U 'HR ] [ -a ] [ -h hostname[:port] ] [ -u 'HR ] [id ] [ destination ] [ destination-id ]

lprm --删除打印任务
lprm指令用来删除当前打印队列上的任务,如果没有指定,那么就删除当前打印任务。您可以指定一个或多个职务ID编号来取消这些职务,或者使用选项”-”取消所有作业。
lpstat --查看打印任务

ps2pdf命令 – 将ps文件转换成pdf文件

ps2pdf .ps文件 xpdf pdf文件名
pdf2ps 命令 – pdf转换成ps
pdf2ps .pdf文件 lpr .ps文件

wget命令 – 从指定网址下载网络文件

其功能是用于从指定网址下载网络文件。wget命令非常稳定,一般即便网络波动也不会导致下载失败,而是不断地尝试重连,直至整个文件下载完毕。
- wget命令支持如HTTP、HTTPS、FTP等常见协议,可以在命令行中直接下载网络文件。



直接从网上下载文件
wget https://www.linuxprobe.com/docs/LinuxProbe.pdf
--2023-05-11 18:36:42-- https://www.linuxprobe.com/docs/LinuxProbe.pdf
Resolving www.linuxprobe.com (www.linuxprobe.com)... 58.218.215.124
Connecting to www.linuxprobe.com (www.linuxprobe.com)|58.218.215.124|:443... connected.
HTTP request sent, awaiting response... 200 OK Length: 17676281 (17M) [application/pdf]
Saving to: ‘LinuxProbe.pdf’ LinuxProbe.pdf 100%[=================================>] 16.86M 30.0MB/s in 0.6s
2023-05-11 18:36:42 (30.0 MB/s) - ‘LinuxProbe.pdf’ saved [17676281/17676281]

网上下载文件并在本地重命名文件
wget -O Book.pdf https://www.linuxprobe.com/docs/LinuxProbe.pdf
启用断点续传技术下载指定的网络文件:
wget -c https://www.linuxprobe.com/docs/LinuxProbe.pdf
下载指定的网络文件,将任务放至后台执行
wget -b https://www.linuxprobe.com/docs/LinuxProbe.pdf
Continuing in background, pid 237616.
Output will be written to ‘wget-log’.
sleep 命令 – 休眠

wc命令 – 统计文件中的行数、单词数或字节数
wc 命令用来统计文件中的行数、单词数或字节数,然后将结果输出在终端上。我们可以使用 wc 命令来计算文件的Byte数、字数或是列数。
wc [选项] [文件]
wc [OPTION] [FILE]
行数 单词数 字节数
-c #统计字节数
-l #统计行数
-m #统计字符数
-w #统计字数
-L #显示最长行的长度
-help #显示帮助信息
--version #显示版本信息


bc命令 – 计算器
bc 命令是任意精度计算器语言,通常在linux下当计算器使用,可以做基本的数学运算。
在终端输入 bc 命令,即可进入 bc 进行交互式的数学计算,如下图所示。



bc 也支持以下函数:
- 求平方根:sqrt(n)
- 求数值的长度:length(n)
- 设置小数的有效位:scale
- 设置输入进制格式:ibase
- 设置输出进制格式:obase
date命令 – 系统日期
date "+今天是%Y-%m-%d,现在是%H:%M:%S"
%n : 下一行
%t : 跳格
%H : 小时(00-23)
%I : 小时(01-12)
%k : 小时(0-23)
%l : 小时(1-12)
%M : 分钟(00-59)
%p : 显示本地 AM 或 PM
%r : 直接显示时间 (12 小时制,格式为 hh:mm:ss [AP]M)
%s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数
%S : 秒(00-60)
%T : 直接显示时间 (24 小时制)
%X : 相当于 %H:%M:%S
%Z : 显示时区
%a : 星期几 (Sun-Sat)
%A : 星期几 (Sunday-Saturday)
%b : 月份 (Jan-Dec)
%B : 月份 (January-December)
%c : 直接显示日期与时间
%d : 日 (01-31)
%D : 直接显示日期 (mm/dd/yy)
%h : 同 %b
%j : 一年中的第几天 (001-366)
%m : 月份 (01-12)
%U : 一年中的第几周 (00-53) (以 Sunday 为一周的第一天的情形)
%w : 一周中的第几天 (0-6)
%W : 一年中的第几周 (00-53) (以 Monday 为一周的第一天的情形)
%x : 直接显示日期 (mm/dd/yy)
%y : 年份的最后两位数字 (00.99)
%Y : 完整年份 (0000-9999)

info指令 – 帮助指令
命令概述
- info命令是Linux下info格式的帮助指令。阅读 info 格式的文档。
- 就内容来说,info页面比man page编写得要更好、更容易理解,也更友好,但man page使用起来确实要更容易得多。一个man page只有一页,而info页面几乎总是将它们的内容组织成多个区段(称为节点),每个区段也可能包含子区段(称为子节点)。理解这个命令的窍门就是不仅要学习如何在单独的Info页面中浏览导航,还要学习如何在节点和子节点之间切换。可能刚开始会一时很难在info页面的节点之间移动和找到你要的东西,真是具有讽刺意味:原本以为对于新手来说,某个东西比man命令会更好些,但实际上学习和使用起来更困难。
- 总之:不推荐大家使用该命令。
```bash -d:添加包含info格式帮助文档的目录; -f:指定要读取的info格式的帮助文档; -n:指定首先访问的info帮助文件的节点; -o:输出被选择的节点内容到指定文件。 ``` 
passwd指令 – 更改密码
passwd

系统软件管理
gzip指令 – 压缩文件
Linux gzip命令用于压缩文件。gzip是个使用广泛的压缩程序,文件经它压缩过后,其名称后面会多出".gz"的扩展名。
-a或--ascii 使用ASCII文字模式。
-c或--stdout或--to-stdout 把压缩后的文件输出到标准输出设备,不去更动原始文件。
-d或--decompress或----uncompress 解开压缩文件。
-f或--force 强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接。
-h或--help 在线帮助。
-l或--list 列出压缩文件的相关信息。
-L或--license 显示版本与版权信息。
-n或--no-name 压缩文件时,不保存原来的文件名称及时间戳记。
-N或--name 压缩文件时,保存原来的文件名称及时间戳记。
-q或--quiet 不显示警告信息。
-r或--recursive 递归处理,将指定目录下的所有文件及子目录一并处理。
-S<压缩字尾字符串>或----suffix<压缩字尾字符串> 更改压缩字尾字符串。
-t或--test 测试压缩文件是否正确无误。
-v或--verbose 显示指令执行过程。
-V或--version 显示版本信息。
-<压缩效率> 压缩效率是一个介于1-9的数值,预设值为"6",指定愈大的数值,压缩效率就会愈高。
--best 此参数的效果和指定"-9"参数相同。
--fast 此参数的效果和指定"-1"参数相同。
gzip file #压缩文件
gzip -dv file #解压文件
gzip -l file #显示详细信息

gzip是个使用广泛的压缩程序,文件经它压缩过后,其名称后面会多出".gz"的扩展名。
tar 指令 – 压缩解压缩
gzip格式
压缩语法:tar -zcvf 压缩后文件名 被压缩文件
解压缩语法 tar -zxvf 压缩文件名 -C 解压后文件所在目录

参数2:-C 指定解压后的文件存放的位置

bzp2格式
#压缩
tar jcvf 压缩包名 文件1 文件2 ...
tar jcvf test.tar.bz2 test.txt ...
#解压
tar jxvf 压缩包名 -c 制定解压的路径

gunzip指令 – 解压文件
Linux gunzip 命令用于解压文件。
gunzip 是个使用广泛的解压缩程序,它用于解开被 gzip 压缩过的文件,这些压缩文件预设最后的扩展名为** .gz**。事实上 gunzip 就是 gzip 的硬连接,因此不论是压缩或解压缩,都可通过 gzip 指令单独完成。
-c:将解压缩后的文件内容输出到标准输出(而不是写入文件)。
-d:解压缩文件。这是默认的行为,可以省略。
-f:强制解压缩,即使已存在同名的解压缩文件。
-h:显示帮助信息。
-k:保留原始的压缩文件。解压缩后的文件会保留在同一目录下,而不会删除原始文件。
-l:显示压缩文件的详细信息,包括压缩前后的文件大小、压缩比等。
-n:不覆盖已存在的解压缩文件。如果已存在同名文件,则不会进行解压缩操作。
-q:静默模式,不显示解压缩进度和错误信息。
-r:递归地解压缩指定目录下的所有文件。
-t:测试压缩文件的完整性,而不进行实际的解压缩操作。
-v:显示详细的解压缩信息,包括解压缩的文件名、压缩比等。
--help:显示帮助信息。
--version:显示 gunzip 命令的版本信息。
gunzip example.txt.gz #解压
gunzip -k example.txt.gz #解压缩文件并保留原始文件
gunzip -c example.txt.gz #解压缩文件并将内容输出到标准输出:
gunzip -r directory #递归地解压缩目录下的所有文件:
系统权限指令
配置MobaXterm的默认文本编辑器
免去vim命令的麻烦
Linux 系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。
为了保护系统的安全性,Linux 系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定。
在 Linux 中我们通常使用以下两个命令来修改文件或目录的所属用户与权限:
- chown (change owner) : 修改所属用户与组。
- **chmod (change mode) : **修改用户的权限。
在 Linux 中我们可以使用 ll 或者 ls –l 命令来显示一个文件的属性以及文件所属的用户和组,如:
[root@www /]# ls -l
total 64
dr-xr-xr-x 2 root root 4096 Dec 14 2012 bin
dr-xr-xr-x 4 root root 4096 Apr 19 2012 boot
……
实例中,bin 文件的第一个属性用 d 表示。d 在 Linux 中代表该文件是一个目录文件。
在 Linux 中第一个字符代表这个文件是目录、文件或链接文件等等。
- 当为 d 则是目录;
- 当为 - 则是文件;
- 若是 l 则表示为链接文档(link file);
- 若是 b 则表示为装置文件里面的可供储存的接口设备(可随机存取装置);
- 若是 c 则表示为装置文件里面的串行端口设备,例如键盘、鼠标(一次性读取装置)。
接下来的字符中,以三个为一组,且均为 rwx 的三个参数的组合。其中, r 代表可读(read)、 w 代表可写(write)、 x 代表可执行(execute)。 要注意的是,这三个权限的位置不会改变,如果没有权限,就会出现减号 - 而已。
每个文件的属性由左边第一部分的 10 个字符来确定(如下图)。
从左至右用 0-9 这些数字来表示。
第 0 位确定文件类型,第 1-3 位确定属主(该文件的所有者)拥有该文件的权限。
第4-6位确定属组(所有者的同组用户)拥有该文件的权限,第7-9位确定其他用户拥有该文件的权限。
其中,第 1、4、7 位表示读权限,如果用 r 字符表示,则有读权限,如果用 - 字符表示,则没有读权限;
第 2、5、8 位表示写权限,如果用 w 字符表示,则有写权限,如果用 - 字符表示没有写权限;第 3、6、9 位表示可执行权限,如果用 x 字符表示,则有执行权限,如果用 - 字符表示,则没有执行权限。
1、chgrp:更改文件属组
chgrp [-R] 属组名 文件名
chgrp group file或者dir 改变文件或者目录的用户组
chgrp -R group dir 递归改变目录的用户组
chgrp groupname file|dir ##更改文件或者目录的所有组
chgrp -R groupname dir ##更改目录本身及里面所有内容的所有组
- -R:递归更改文件属组,就是在更改某个目录文件的属组时,如果加上-R的参数,那么该目录下的所有文件的属组都会更改。
2、chown:更改文件属主,也可以同时更改文件属组
chown [–R] 属主名 文件名
chown [-R] 属主名:属组名 文件名
chown username file或者dir 更改文件或者目录的拥有者
chown user-group file或者dir
#user-group不是命令表示的是username.groupname 更改文件或者目录的用户和用户组
chown -R user-group dir 递归更改目录的用户和用户组
3、chmod:更改文件属性
文件的权限: r w x
身份的权限: u g o a
Linux文件属性有两种设置方法,一种是数字,一种是符号。
Linux 文件的基本权限就有九个,分别是 owner/group/others(拥有者/组/其他) 三种身份各有自己的 read/write/execute 权限。
先复习一下刚刚上面提到的数据:文件的权限字符为: -rwxrwxrwx , 这九个权限是三个三个一组的!其中,我们可以使用数字来代表各个权限,各权限的分数对照表如下:
- r:4
- w:2
- x:1
符号类型改变文件权限
还有一个改变权限的方法,从之前的介绍中我们可以发现,基本上就九个权限分别是:
- user:用户
- group:组
- others:其他
那么我们就可以使用 u, g, o 来代表三种身份的权限。
此外, a 则代表 all,即全部的身份。读写的权限可以写成 r, w, x,也就是可以使用下表的方式来看:
| chmod | u g o a | +(加入) -(除去) =(设定) | r w x | 文件或目录 |
|---|
(1)chmod [-R] <u|g|o><+|-|=><r|w|x> file|dir 总的格式
(2)chmod u-x file1 file1拥有者去掉x权限
(3)chmod g+w file1 file1拥有组添加w权限
(4)chmod u+x,g-w file1 file1拥有者去掉x权,file1拥有组添加w权限
(5)chmod ugo-r file2 file2的用户、组、其他人去掉r权限
(6)chmod ug+x,o-r file3 file3用户和组添加x权限,其他人去掉r权限
chmod 777 filename #修改文件权限rwx




进程系统地址指令
top 指令 – 实时查看进程情况
top命令经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。
top [-d number] | top [-bnp]
# 实时查看系统进程
top
# 快捷键
↑ 下翻
↓ 上翻
q 退出


top - 14:49:28 up 1:33, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 80 total, 2 running, 78 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1922488k total, 406936k used, 1515552k free, 11940k buffers
Swap: 835576k total, 0k used, 835576k free, 111596k cached
进程信息 默认进入top时,各进程是按照CPU的占用量来排序的
默认进入top时,各进程是按照CPU的占用量来排序的
ps指令 – 输出在系统上的所有程序的许多信息
# 静态查看所有系统进程
ps -aux
-A 显示所有进程(同-e)
-a 显示当前终端的所有进程
-u 显示进程的用户信息
-o 以用户自定义形式显示进程信息
-f 显示程序间的关系
USER 进程所有者的用户名
PID 进程ID(Process ID)
START 进程激活时间
%CPU 进程的cpu占用率
%MEM 进程使用内存的百分比
VSZ 进程使用的虚拟内存大小,以K为单位
RSS 驻留空间的大小。显示当前常驻内存的程序的K字节数。
TTY 与进程关联的终端(tty)
STAT 进程状态,包括下面的状态:
D 不可中断 Uninterruptible sleep (usually IO)
R 正在运行,或在队列中的进程
S 处于休眠状态
T 停止或被追踪
Z 僵尸进程
W 进入内存交换(从内核2.6开始无效)
X 死掉的进程
< 高优先级
N 低优先级
L 有些页被锁进内存
s 包含子进程
\+ 位于后台的进程组;
l 多线程,克隆线程
TIME 进程使用的总CPU时间
COMMAND 被执行的命令行
NI 进程的优先级值,较小的数字意味着占用较少的CPU时间
PRI 进程优先级。
PPID 父进程ID
WCHAN 进程等待的内核事件名
ps -A / ps -aux # 查看所有进程的信息
ps -ef | grep ssh # 查看特定信息
ps -aux | grep ssh

kill指令 – 杀死进程
在Linux系统中有时想中止一些命令的执行,或者清理一些僵尸进程,kill命令是个不错的选择。
kill [OPTIONS] [PID]..
kill pid #杀死进程
kill -KILL 123456 强制杀死进程
kill -HUP pid 发送信号
kill -9 123456 彻底杀死进程
kill -l 显示所有可用的信号
该kill命令将信号发送到指定的进程或进程组,使它们根据该信号进行操作。未指定信号时,默认为-15(-TERM)。
最常用的信号是:
- 1(HUP)-重新加载进程。
- 9(KILL)-终止进程。
- 15(TERM)-正常停止进程。
要获取所有可用信号的列表,请使用以下-l选项调用命令:
kill -l #查看所有可以用的信号

可以用三种不同的方式指定信号:
- 使用数字(例如-1或-s 1)。
- 使用“ SIG”前缀(例如-SIGHUP或-s SIGHUP)。
- 没有“ SIG”前缀(例如-HUP或-s HUP)。
以下命令彼此等效:
kill -1 PID_NUMBER
kill -SIGHUP PID_NUMBER
kill -HUP PID_NUMBER
提供给kill命令的PID 可以是以下之一:
- 如果PID大于零,则将信号发送到ID等于的进程PID。
- 如果PID等于零,则将信号发送到当前过程组中的所有过程。换句话说,该信号将发送到属于调用kill命令的外壳程序的GID的所有进程。使用ps -efj命令查看进程组ID(GID)。
- 如果PID等于-1,则信号以与用户调用命令相同的UID发送到所有进程。如果调用用户是root用户,则信号将发送到除init和kill进程本身之外的所有进程。
- 如果PID小于-1,则将信号发送到GID等于的绝对值的进程组eq中的所有进程PID。
普通用户可以将信号发送到自己的进程,但不能发送信号给其他用户,而根用户可以将信号发送到其他用户的进程。
使用kill命令终止进程
要使用kill命令终止或终止进程,首先需要找到进程ID号(PID)。为此,您可以使用不同的命令,例如top,ps,pidof和pgrep。
假设Firefox浏览器已无响应,并且您需要终止Firefox进程。要查找浏览器的PID,请使用以下pidof命令:
pidof firefox
该命令将打印所有Firefox进程的ID:
6263 6199 6142 6076
一旦知道了进程号,就可以通过发送TERM信号来终止所有进程号:
kill -9 2551 2514 1963 1856 1771
您可以将上述命令组合为一个命令,而不是先搜索PID然后终止进程。
kill -9 $(pidof firefox)
使用kill命令重新加载进程
另一个常见用例kill是发送HUP信号,该信号告诉进程重新加载其设置。
例如,要重新加载Nginx,您需要向主进程发送一个信号。Nginx主进程的进程ID可以在nginx.pid文件中找到,该文件通常位于/var/run目录中。
使用cat命令查找主PID:
cat /var/run/nginx.pid
30251
一旦找到主PID,请输入以下内容重新加载Nginx设置:
sudo kill -1 30251
上面的命令必须以root用户或具有sudo特权的用户身份运行。
killall指令 – 杀死指定名字的所有进程
Linux killall 用于杀死一个进程,与 kill 不同的是它会杀死指定名字的所有进程。
killall [选项] name
- name : 进程名
选项包含如下几个参数:
- -e | --exact : 进程需要和名字完全相符
- -I | --ignore-case :忽略大小写
- -g | --process-group :结束进程组
- -i | --interactive :结束之前询问
- -l | --list :列出所有的信号名称
- -q | --quite :进程没有结束时,不输出任何信息
- -r | --regexp :将进程名模式解释为扩展的正则表达式。
- -s | --signal :发送指定信号
- -u | --user :结束指定用户的进程
- -v | --verbose :显示详细执行过程
- -w | --wait :等待所有的进程都结束
- -V |–version :显示版本信息
- –help :显示帮助信息
killall -9 php-fpm //结束所有的 php-fpm 进程
ip指令 –
ip route – 管理静态路由表
linux 系统中,可以自定义从 1-252个路由表。其中,linux系统维护了4个路由表:
- 0#表: 系统保留表
- 253#表: defulte table 没特别指定的默认路由都放在改表
- 254#表: main table 没指明路由表的所有路由放在该表
- 255#表: local table 保存本地接口地址,广播地址、NAT地址 由系统维护,用户不得更改
查找路由表可以通过**ip route show table table_number[table name]**命令,路由表和表明的对应关系记录在/etc/iproute2/rt_tables中
查看路由表信息
ip route show table 表号[表名]

# 第一行是默认路由,表示在路由表上查不到数据时时,报文都从 enp0s3 网卡出去,去 IP 为 10.0.0.2 的另一台主机。
# 第二行是网络路由,表示去 10.0.0.0/24 网络的报文都从 enp0s3 网卡出去,报文中携带的源地址(本机地址)为 10.0.0.128。
# 第三行也是网络路由,表示去 172.17.0.0/16 网络的报文都从 docker0 网卡出去,报文中携带的源地址(本机地址)为 172.17.0.1。
# 由第二行可知,走默认路由时,报文中携带的源地址(本机地址)为 10.0.0.128。
ip route add – 增加路由
- ip route add default via 192.168.1.1
增加默认网关(在main路由表中)
- ip route add 192.168.4.0/24 via 192.168.166.1 dev wlan0
设置192.168.4.0网段的网关为192.168.166.1,数据走wlan0接口
- ip route add 192.168.1.9 via 192.168.166.1 dev wlan0
增加目的地址192.168.1.9的网关为192.168.166.1,数据走wlan0接口
- ip route add default via 192.168.1.1 table 1
在1号路由表中增加默认网管
- ip route add 192.168.0.0/24 via 192.168.166.1 table 1
在1号路由表中增加192.168.0.0网段的网关为192.168.166.1
ip route show – 显示系统路由
- ip route 或:ip route show
- 显示系统路由
- ip route show table local
- 查看本地路由表
ip route get – 获取单目标路由
- ip route get 169.254.0.0/16
- 获取到目标的单个路由,并按照内核所看到的方式打印其内容
ip route delete – 删除路由
- ip route del 192.168.4.0/24
- 删除192.168.4.0网段的网关
- ip route del default
- 删除默认网关
ip route flush – 输出特定路由
- ip route flush 10.38.0.0/16
- 删除特定路由
- ip route flush table main
- 清空路由表
ip route是route命令的升级版本,但route命令仍在大量使用
ip address – 查看所有Ip地址
ip a:查看所有 IP 地址(以网卡分组)。
ip a show lo:查看 本地 网卡上的 IP 地址。
ip a add 192.168.10.10/24 dev ens33:向 ens33 网卡上添加一个临时 IP 地址 192.168.10.10/24 (dev 是 device 的简写)。
ip a del 192.168.10.10/24 dev ens33:从 ens33 网卡上删除一个临时 IP 地址 192.168.10.10/24。
iptables指令 – 实现对网络数据包进出设备及转发的控制
iptables 是 Linux 防火墙系统的重要组成部分,iptables 的主要功能是实现对网络数据包进出设备及转发的控制。当数据包需要进入设备、从设备中流出或者由该设备转发、路由时,都可以使用 iptables 进行控制。
iptables 是集成在 Linux 内核中的包过滤防火墙系统。使用 iptables 可以添加、删除具体的过滤规则,iptables 默认维护着 4 个表和 5 个链,所有的防火墙策略规则都被分别写入这些表与链中。
“四表”是指 iptables 的功能,默认的 iptable s规则表有 filter 表(过滤规则表)、nat 表(地址转换规则表)、mangle(修改数据标记位规则表)、raw(跟踪数据表规则表):
- filter 表:控制数据包是否允许进出及转发,可以控制的链路有 INPUT、FORWARD 和 OUTPUT。
- nat 表:控制数据包中地址转换,可以控制的链路有 PREROUTING、INPUT、OUTPUT 和 POSTROUTING。
- mangle:修改数据包中的原数据,可以控制的链路有 PREROUTING、INPUT、OUTPUT、FORWARD 和 POSTROUTING。
- raw:控制 nat 表中连接追踪机制的启用状况,可以控制的链路有 PREROUTING、OUTPUT。
“五链”是指内核中控制网络的 NetFilter 定义的 5 个规则链。每个规则表中包含多个数据链:
INPUT(入站数据过滤)、
OUTPUT(出站数据过滤)、
FORWARD(转发数据过滤)、
PREROUTING(路由前过滤)
POSTROUTING(路由后过滤),
防火墙规则需要写入到这些具体的数据链中。
Linux 防火墙的过滤框架,如图所示:
可以看出,
- 如果是外部主机发送数据包给防火墙本机,数据将会经过 PREROUTING 链与 INPUT 链;
- 如果是防火墙本机发送数据包到外部主机,数据将会经过 OUTPUT 链与 POSTROUTING 链;
- 如果防火墙作为路由负责转发数据,则数据将经过 PREROUTING 链、FORWARD 链以及 POSTROUTING 链。
iptables语法格式
iptables 命令的基本语法格式如下:
iptables [-t table] COMMAND [chain] CRETIRIA -j ACTION
各参数的含义为:
- -t:指定需要维护的防火墙规则表** filter、nat、mangle或raw**。在不使用 -t 时则默认使用 filter 表。
- COMMAND:子命令,定义对规则的管理。
- chain:指明链表。
- CRETIRIA:匹配参数。cretiria
- ACTION:触发动作。action
iptables 命令常用的选项及各自的功能:
选 项 功 能
-A 添加防火墙规则
-D 删除防火墙规则
-I 插入防火墙规则
-F 清空防火墙规则
-L 列出添加防火墙规则
-R 替换防火墙规则
-Z 清空防火墙数据表统计信息
-P 设置链默认规则
iptables 命令常用匹配参数及各自的功能:
参 数 功 能
[!]-p 匹配协议,! 表示取反
[!]-s 匹配源地址
[!]-d 匹配目标地址
[!]-i 匹配入站网卡接口
[!]-o 匹配出站网卡接口
[!]--sport 匹配源端口
[!]--dport 匹配目标端口
[!]--src-range 匹配源地址范围
[!]--dst-range 匹配目标地址范围
[!]--limit 四配数据表速率
[!]--mac-source 匹配源MAC地址
[!]--sports 匹配源端口
[!]--dports 匹配目标端口
[!]--stste 匹配状态(INVALID、ESTABLISHED、NEW、RELATED)
[!]--string 匹配应用层字串
iptables 命令触发动作及各自的功能:
触发动作 功 能
ACCEPT 允许数据包通过
DROP 丢弃数据包
REJECT 拒绝数据包通过
LOG 将数据包信息记录 syslog 曰志
DNAT 目标地址转换
SNAT 源地址转换
MASQUERADE 地址欺骗
REDIRECT 重定向
内核会按照顺序依次检查 iptables 防火墙规则,如果发现有匹配的规则目录,则立刻执行相关动作,停止继续向下查找规则目录;如果所有的防火墙规则都未能匹配成功,则按照默认策略处理。使用 -A 选项添加防火墙规则会将该规则追加到整个链的最后,而使用 -I 选项添加的防火墙规则则会默认插入到链中作为第一条规则。
注意:在 Linux CentOS 系统中,iptables 是默认安装的,如果系统中没有 iptables 工具,可以先进行安装。
规则的查看与清除
使用 iptables 命令可以对具体的规则进行查看、添加、修改和删除。
查看规则
iptables -nvL
各参数的含义为:
- -L 表示查看当前表的所有规则,默认查看的是 filter 表,如果要查看 nat 表,可以加上 -t nat 参数。
- -n 表示不对 IP 地址进行反查,加上这个参数显示速度将会加快。
- -v 表示输出详细信息,包含通过该规则的数据包数量、总字节数以及相应的网络接口。
【例 1】查看规则。首先需要使用 su 命令,切换当前用户到 root 用户。然后在终端页面输入命令如下:
添加规则
添加规则有两个参数分别是 -A 和 -I。其中 -A 是添加到规则的末尾;-I 可以插入到指定位置,没有指定位置的话默认插入到规则的首部。
【例 2】查看当前规则。首先需要使用 su 命令,切换当前用户到 root 用户,然后在终端页面输入命令如下:
添加一条规则到尾部。首先需要使用 su 命令,切换当前用户到 root 用户,然后在终端页面输入如下命令:
iptables -A INPUT -s 192.168.1.5 -j DROP
iptables -nL --line-number

修改规则
在修改规则时需要使用-R参数。
【例 4】把添加在第1 行规则的 DROP 修改为 ACCEPT。首先需要使用 su 命令,切换当前用户到 root 用户,然后在终端页面输入如下命令:
iptables -R INPUT 1 -s 192.168.1.5 -j ACCEPT
iptables -nL --line-number

对比发现,第 1 行规则的 target 已修改为 ACCEPT。
删除规则
删除规则有两种方法,但都必须使用 -D 参数。
【例 5】删除添加的第 1 行的规则。首先需要使用su命令,切换当前用户到 root 用户,然后在终端页面输入如下命令:
iptables -D INPUT 1 -s 192.168.1.5 -j ACCEPT
或
iptables -D INPUT 1

已经删除第一行的规则
注意:有时需要删除的规则较长,删除时需要写一大串的代码,这样比较容易写错,这时可以先使用 -line-number 找出该条规则的行号,再通过行号删除规则。
防火墙的备份与还原
默认的 iptables 防火墙规则会立刻生效,但如果不保存,当计算机重启后所有的规则都会丢失,所以对防火墙规则进行及时保存的操作是非常必要的。
iptables 软件包提供了两个非常有用的工具,我们可以使用这两个工具处理大量的防火墙规则。这两个工具分别是** iptables-save 和 iptables-restore**,使用该工具可以实现防火墙规则的保存与还原。这两个工具的最大优势是处理庞大的规则集时速度非常快。
CentOS 7 系统中防火墙规则默认保存在 /etc/sysconfig/iptables 文件中,使用 iptables-save 将规则保存至该文件中可以实现保存防火墙规则的作用,计算机重启后会自动加载该文件中的规则。如果使用 iptables-save 将规则保存至其他位置,可以实现备份防火墙规则的作用。当防火墙规则需要做还原操作时,可以使用 iptables-restore 将备份文件直接导入当前防火墙规则。
iptables-save命令
iptables-save 命令用来批量导出 Linux 防火墙规则,语法介绍如下:
保存在默认文件夹中(保存防火墙规则):iptables-save > /etc/sysconfig/iptables
保存在其他位置(备份防火墙规则):iptables-save > 文件名称
直接执行 iptables-save 命令:显示出当前启用的所有规则,按照 raw、mangle、nat、filter 表的顺序依次列出,如下所示:
“#”号开头的表示注释;
“filter”表示所在的表;
“:链名默认策略”表示相应的链及默认策略,具体的规则部分省略了命令名“iptables”;
在末尾处*“COMMIT”表示提交前面的规则设置。**
列出nat表的规则内容,命令如下:
iptables-save -t nat

“-t表名”:表示列出某一个表。
iptables-restore命令
iptables-restore 命令可以批量导入Linux防火墙规则,同时也需要结合重定向输入来指定备份文件的位置。命令如下:
iptables-restore < 文件名称
注意,导入的文件必须是使用 iptables-save工具导出来的才可以。
先使用 iptables-restore 命令还原 text 文件,然后使用 iptables -t nat -nvL 命令查看清空的规则是否已经还原,如下所示:
iptables-restore < test
iptables -t nat -nvL

Linux Task Control
jobs命令 – 查看当前终端放入后台的工作
jobs 命令可以用来查看当前终端放入后台的工作,工作管理的名字也来源于 jobs 命令。
查看当前有多少在后台运行的命令
jobs [选项]

[root@localhost ~]#jobs -l
[1]- 2023 Stopped top
[2]+ 2034 Stopped tar -zcf etc.tar.gz /etc
可以看到,当前终端有两个后台工作:一个是 top 命令,工作号为 1,状态是暂停,标志是"-“;另一个是 tar 命令,工作号为 2,状态是暂停,标志是”+"。"+"号代表最近一个放入后台的工作,也是工作恢复时默认恢复的工作。"-"号代表倒数第二个放入后台的工作,而第三个以后的工作就没有"±"标志了。
一旦当前的默认工作处理完成,则带减号的工作就会自动成为新的默认工作,换句话说,不管此时有多少正在运行的工作,任何时间都会有且仅有一个带加号的工作和一个带减号的工作。
fg指令 – 将后台运行的或挂起的任务(或作业)切换到前台运行
将后台中的命令调至前台继续运行
如果后台有多个命令,可以用fg %jobnumber将选中的命令调出,%jobnumber是通过jobs命令查到的后台正在执行的命令的序号(不是pid)
假如你发现前天运行的一个程序需要很长的时间,但是需要干前天的事情,你就可以用ctrl-z挂起这个程序,然后可以看到系统的提示:
[1]+ Stopped /root/bin/rsync.sh
然后我们可以下·
bg 1 #把程序调度到后台执行:(bg 作业号)
[1]+ /root/bin/rsync.sh &
jobs #用jobs命令查看任务
[1]+ Running /root/bin/rsync.sh &
fg 1 #把它调回到控制台运行
/root/bin/rsync.sh
这样,你这控制台上就只有等待这个任务完成了。
bg指令 – 将在后台暂停的命令,变成继续执行
将一个在后台暂停的命令,变成继续执行
如果后台有多个命令,可以用bg %jobnumber将选中的命令调出,%jobnumber是通过jobs命令查到的后台正在执行的命令的序号(不是pid)
& – 用在命令的最后,可以把这个命令放到后台执行
ctrl + z – 将正在前台执行的命令放到后台,并且暂停
服务(service)管理
服务(service) 本质就是进程,但是是运行在后台的,通常都会监听某个端口,等待其它程序的请求,比如(mysqld , sshd、防火墙等),因此我们又称为守护进程,是 Linux 中非常重要的知识点。
service管理指令
service 服务名 [start | stop | restart | reload | status]
# 检查某个进程的(开始/结束/重启/重载/状态)
service 指令管理的服务在 /etc/init.d 查看
检查某个进程的(开始/结束/重启/重载/状态)
service 管理指令案例
请使用 service 指令,查看,关闭,启动 network [注意:在虚拟系统演示,因为网络连接会关闭]
指令:
service network status
service network stop
service network start

检查ssh的状态
查看服务名的方式
方式 1:使用 setup -> 系统服务 就可以看到全部。
在虚拟机的终端中使用
setup
带 * 号说明是守护进程,和系统的是一起启动的。选中输入空格键也可以把 * 号去掉,下次启动的时候就不会随着系统一起启动了,需要手动启动

方式 2: /etc/init.d 看到 service 指令管理的服务
ls -l /etc/init.d
网络诊断指令
ping 指令 –
ping命令是个使用频率极高的网络诊断工具,在Windows、Unix和Linux系统下均适用。它是TCP/IP协议的一部分,用于确定本地主机是否能与另一台主机交换数据报。根据返回的信息,我们可以推断TCP/IP参数设置是否正确以及运行是否正常。需要注意的是,成功与另一台主机进行一次或两次数据报交换并不表示TCP/IP配置就是正确的,必须成功执行大量的数据报交换,才能确信TCP/IP的正确性。下面就以Windows系统为例,介绍一下ping命令的基本使用方法。
ping命令的应用格式
①ping+IP地址或主机域名;
②ping+IP地址或主机域名+命令参数;
③ ping+命令参数+IP地址或主机域名 。
注意,“+”要换成空格!
当我们使用第①种格式时,默认只发送四个数据包。例如,我们来ping一下http://www.baidu.com这个地址,如下图所示。119.75.217.109便是百度的其中一台主机的地址;bytes表示发送数据包的大小,默认为32字节;time表示从发出数据包到接受到返回数据包所用的时间;TTL表示生存时间值,该字段指定IP包被路由器丢弃之前允许通过的最大网段数量。

参数:
-t : 表示不间断向目标地址发送数据包,直到我们强迫其停止,
-a :
-n : 定义向目标地址发送数据包的次数
-l : 定义发送数据包的大小,默认情况下是32字节
如果-t和-n两个参数一起使用,ping命令将以放在后面的参数为准,比如“ping IP -t -n 10”,虽然使用了-t参数,但并不是一直ping下去,而是只ping 10次。
tracert指令 –
tracert是一个简单的网络诊断工具命令,可以列出分组经过的路由节点,以及它在IP网络中每一跳的延迟。(这里的延迟是指:分组从信息源发送到目的地所需的时间,延迟也分为许多种——传播延迟、传输延迟、处理延迟、排队延迟等,是大多数网站性能的瓶颈之一。)
tracert的使用方法可以使用tracert-?来查看
tracert [-d] [-h maximum_hops] [-j host-list] [-w timeout] [-R] [-S srcaddr] [-4] [-6] target_name
下面是参数说明:
- -d:表示不让 tracert 根据节点主机名查找路由的 IP 地址,直接进行路由跟踪。当路由器不支持 ICMP/UDP/ICMPv6 数据包时,建议使用该选项。
- -h maximum_hops:指定最多经过多少个节点进行路由跟踪,默认值为 30。使用该选项可以更改该值。
- -j host-list:枚举一个节点列表,并在路由跟踪过程中只走该列表中的节点。
- -w timeout:设置等待每个回复消息的超时时间,默认值为 4000 毫秒。使用该选项可以更改该值。
- -R:指示 tracert 跟踪路由时,使用“参考路由”而不是“严格源路由”。如果启用了该选项,则可以跨越某些无法到达的能够到达目标的路由器。
- -S srcaddr:指定源地址。如果在单个计算机上安装了多个网络适配器,则使用该选项可以指定从哪个适配器发出路由跟踪请求。
- -4:强制使用 IPv4 进行路由跟踪。
- -6:强制使用 IPv6 进行路由跟踪。
- target_name:表示要查询的目标 IP 地址或主机名。
使用tracert命令来追踪www.sina.com.cn网站。
- tracert命令用于确定IP数据包访问目标所采取的路径,显示从本地到目标网站所在网络服务器的一系列网络节点的访问速度,最多支持显示30个网络节点。
- 最左侧的1~11,表明在作者使用的网络上,经过10(不算自己本地的)个路由节点,可以到达新浪网站;如果网络不同,则到达的站点可能不同;其他的IP,也有可能不同。可以自行测试一下。
- 访问单位是ms,表示连接到每个路由节点的速度、返回速度和多次。连接反馈的平均值。
- 后面的IP,就是每个路由节点对应的IP。
- 如果返回消息是超时,则表示这个路由节点和作者使用的宽带,是无法连通的,至于原因,就有很多种了。比如,作者特意在路由上做了过滤限制,或者确实是路由的问题等,需要具体问题具体分析。
- 如果在测试的时候,返回大量*和超时信息,则说明这个IP在各个路由节点都有问题。
- 一般10个节点以内可以完成跟踪的网站,访问速度都是不错的;10~15个节点之内才完成跟踪的网站,访问速度则比较慢;如果超过30个节点都没有完成跟踪,则可以认为目标网站是无法访问的。
磁盘管理指令
Linux 磁盘管理好坏直接关系到整个系统的性能问题。
Linux 磁盘管理常用三个命令为 df、du 和 fdisk。
- df(英文全称:disk free):列出文件系统的整体磁盘使用量
- du(英文全称:disk used):检查磁盘空间使用量
- fdisk:用于磁盘分区
df指令 – 检查文件系统的磁盘空间占用情况
df命令参数功能:检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法:
df [-ahikHTm] [目录或文件名]
选项与参数:
- -a :列出所有的文件系统,包括系统特有的 /proc 等文件系统;
- -k :以 KBytes 的容量显示各文件系统;
- -m :以 MBytes 的容量显示各文件系统;
- -h :以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示;
- -H :以 M=1000K 取代 M=1024K 的进位方式;
- -T :显示文件系统类型, 连同该 partition 的 filesystem 名称 (例如 ext3) 也列出;
- -i :不用硬盘容量,而以 inode 的数量来显示



du指令 – 对文件和目录磁盘使用的空间的查看
Linux du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的,这里介绍 Linux du 命令。
语法:
du [-ahskm] 文件或目录名称
du -h file
// 13M file
du -sh dir # 返回路径下所有文件的总量
选项与参数:
-a :列出所有的文件与目录容量,因为默认仅统计目录底下的文件量而已。
-h :以人们较易读的容量格式 (G/M) 显示;
-s :列出总量而已,而不列出每个各别的目录占用容量;
-S :不包括子目录下的总计,与 -s 有点差别。
-k :以 KBytes 列出容量显示;
-m :以 MBytes 列出容量显示;


fdisk指令 – 磁盘分区表操作工具
fdisk 是 Linux 的磁盘分区表操作工具。
fdisk [-l] 装置名称
选项与参数:
- -l :输出后面接的装置所有的分区内容。若仅有 fdisk -l 时, 则系统将会把整个系统内能够搜寻到的装置的分区均列出来。
free指令 – 显示系统内存的使用情况
free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
















 3292
3292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









