






作者遵循第二种方法,研究了一个可靠的技术解决方案,在 Mask 分类框架内重新思考双流架构。以此为目标,在流行的双流语义分割架构的基础上,作者提出了BiSeNetFormer。它保持了高效的双流设计:空间路径从图像中提取高分辨率低级细节,而上下文路径生成高度语义化的视觉特征。为了执行 Mask 分类,作者采用了一个 Transformer 解码器组件,该组件有效地利用低分辨率上下文路径特征计算一组分割嵌入。这些嵌入随后被用于计算一组由二进制 Mask 及其相应类别概率组成的配对,这些配对构成了分割输出。得益于其设计,BiSeNetFormer无缝支持多种任务,如语义分割和全景分割。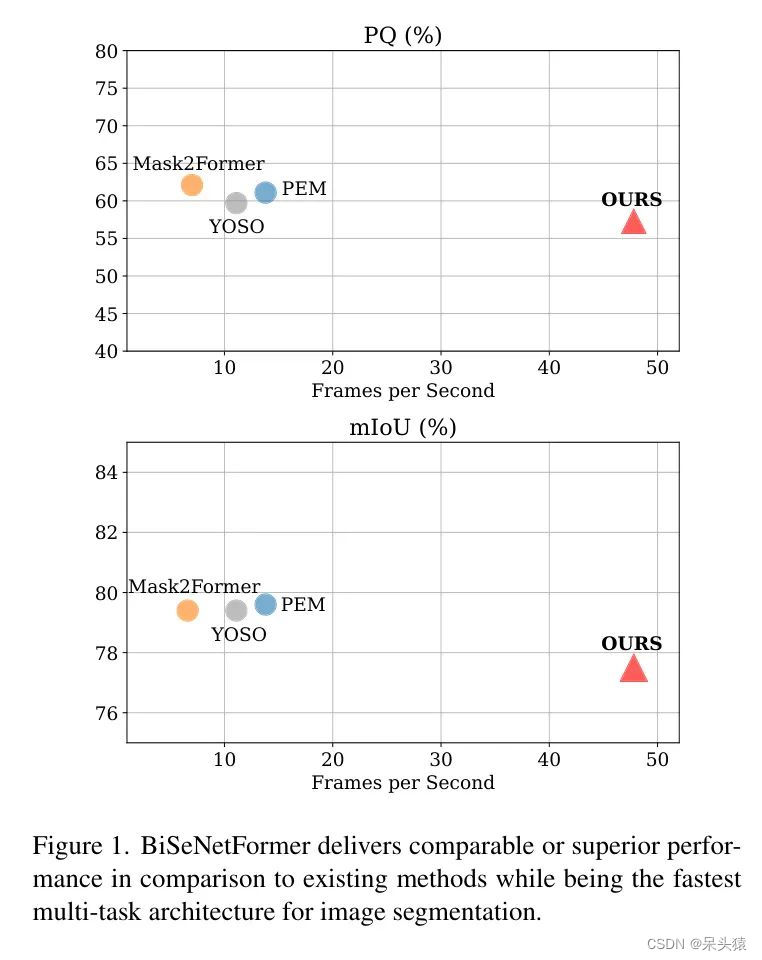
作者讨论了两种截然不同的策略。第一种是优化 Mask 分类网络的效率。通过采用定制化的架构改进,即使直接从 Mask 分类方法出发,也能实现实时性能,正如YOSO [17] 和 PEM [2] 所展示的成功,它们显著加快了MaskFormer [6] 的速度,同时在其准确度上也有所提高。
第二种策略则从相反的方向着手问题,寻求在基于 Mask 的框架内重新设计本质上高效的双流语义分割模型。作者认为,由于这些架构本质上比原始的MaskFormer [6] 更加注重效率,按照第一种直觉工作将提升模型的准确度而非效率;而第二种策略则更多地提升了效率,正如图1中清晰所示。
为了提供最快的用于图像分割的多任务架构,在本文中,作者遵循第二种方法,研究了一个可靠的技术解决方案,在 Mask 分类框架内重新思考双流架构。以此为目标,在流行的双流语义分割架构的基础上,作者提出了BiSeNetFormer。它保持了高效的双流设计:空间路径从图像中提取高分辨率低级细节,而上下文路径生成高度语义化的视觉特征。为了执行 Mask 分类,作者采用了一个 Transformer 解码器组件,该组件有效地利用低分辨率上下文路径特征计算一组分割嵌入。这些嵌入随后被用于计算一组由二进制 Mask 及其相应类别概率组成的配对,这些配对构成了分割输出。得益于其设计,BiSeNetFormer无缝支持多种任务,如语义分割和全景分割。
作者评估了BiSeNetFormer在两项任务上的表现,这两个任务是基于两个流行数据集:Cityscapes [8] 和 ADE20K [30]。在比较推理速度和准确度时,作者将作者的架构与最先进的多任务和特定任务模型进行了对比。BiSeNetFormer在所有基准测试中均实现了令人印象深刻的速度,同时其表现与特定任务网络以及速度较慢的多任务架构相比拟。此外,作者还使用低端GPU(NVIDIA T4)和边缘设备(NVIDIA Jetson Orin)进行了测试。值得注意的是,即便在资源受限的硬件上,作者的方法也能保持一致的推理速度,这证实了其适合于现实世界的部署。
作者的论文贡献如下:
-
作者提出了BiSeNetFormer,它重新设计了高效的双分支语义分割架构,以执行多个分割任务。
-
作者通过广泛的实验验证表明,BiSeNetFormer在展现出卓越的推理速度(高达100 FPS)的同时,还能获得与现有较慢的多任务架构接近的性能
Mask-classification Framework
最近,MaskFormer [6] 提出了一种在图像分割领域的范式转变,将所有不同的分割任务统一在一种单一的方法下,这种方法被称为 Mask 分类。这个想法是将分割分为两个步骤:(1)将图像划分为N个不同的片段(其中可能不同于类别的数量),(2)为每个片段关联一个类别标签。基于 Mask 方法的主要优点之一是它们的灵活性,允许它们无缝地解决不同的分割任务,因为相同的类别可以与可变数量的 Mask 相关联。形式上,对于一个图像, Mask 分类头输出一组个二进制 Mask ,每个 Mask 都关联有一个概率分布,其中是图像的高度和宽度,是类别的数量,加上一个额外的“无目标”类别。
BiSeNetFormer architecture
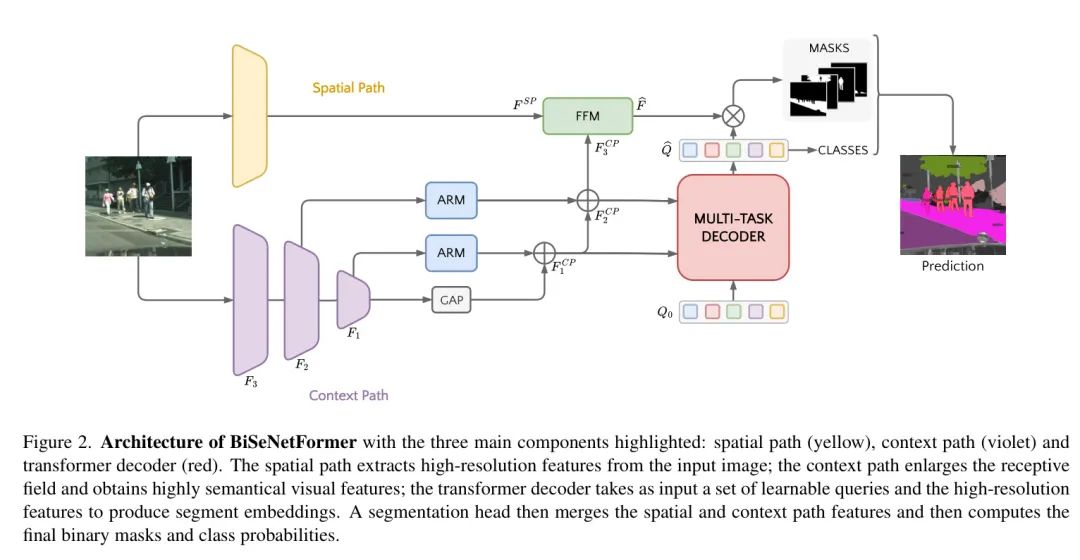
图2:展示了BiSeNetFormer的架构,其中突出了三个主要组成部分:空间路径(黄色)、上下文路径(紫色)和 Transformer 解码器(红色)。空间路径从输入图像中提取高分辨率特征;上下文路径扩大了感受野并获得了高度语义化的视觉特征; Transformer 解码器以一组可学习的 Query 和高分辨率特征作为输入,生成片段嵌入。然后,分割头合并空间路径和上下文路径特征,并计算最终的二值 Mask 和类别概率。
虽然最初的面部遮挡分类模型实现提供了令人印象深刻的性能,但它们的结构设计往往依赖于计算密集型模块。这种设计选择强烈限制了它们适用于实时应用以及在资源受限的边缘设备上部署的适宜性,在这些环境中处理速度至关重要。更近期的作品[2, 17]试图解决这个效率瓶颈,实现了性能的提升和效率的增加。然而,用于在[2, 17]中提高模型效率的设计选择仍然倾向于提高准确性而非计算需求,这在实验上导致推理速度受限。
相比之下,作者提出了一种双流架构,该架构在优先考虑推理速度的同时融合了 Mask 分类能力,将多任务架构的效率推向了前所未有的水平。作者的解决方案由一个受BiSeNet [27]启发的_Spatial Path_(空间路径)和一个_Context Path_(上下文路径)组成,随后是一个基于 Transformer 的分割头[7]来计算输出的二值 Mask 和类别概率。整体架构如图2所示。
空间路径。_空间路径_负责保留图像的空间信息,从而实现精确的分割 Mask 。输入图像按顺序进行处理,逐渐将空间分辨率降低到初始图像尺寸的。如先前的研究所确认,在模型准确性和速度之间提供了很好的权衡。从形式上讲,空间路径接收一个图像 作为输入,并生成一个高分辨率特征 。
上下文路径。相反,上下文路径 通过提供更广泛的上下文信息来丰富每个像素的表示。为此,这个模块旨在扩大感受野,同时避免计算需求的过度增加。特别是,它首先提取两个低分辨率特征 和 ,分别是原始图像的 和 。这样的特征编码了高级语义信息,这对于正确地上下文化每个像素至关重要。随后在 上应用全局平均池化来提取编码全局场景理解的特征。然后,将这些特征重新组合并上采样,以获得具有相关语义信息的高分辨率表示。
正式地,上下文路径输出三个特征 ,其分辨率分别等于原始图像的1/32 ,1/16 ,1/8 和。它们计算如下:
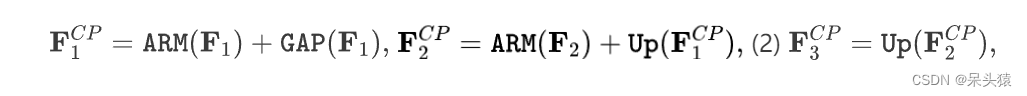
(2)
其中GAP表示全局平均池化层,Up表示上采样操作,而ARM指的是在[27]中提出的注意力细化模块。
Transformer解码器。Transformer解码器的目标是生成 个片段嵌入 ,这些嵌入被用于计算最终的二进制 Mask 和概率分布。为了获得有利的分割结果,片段嵌入应当适当地编码图像中存在的类(或实例)的表示。因此,它们是通过用来自上下文路径的多尺度特征 和 来细化一组 个可学习 Query 来计算的。
为了迭代地细化 Query ,作者使用了一系列Mask2Former [7] 变换块。这个块策略性地集成了 Mask 的交叉注意力(MCAs)、自注意力(SAs)和前馈网络(FFNs)。 Mask 的交叉注意力选择性地将每个 Query 与从上下文路径提取的相关图像特征对齐。自注意力允许 Query 之间进行交互并学习彼此之间的上下文关系,从而提高学习到的表示。最后,FFN是一个2层的前馈网络,用于引入额外的非线性,以识别复杂的模式。形式上,给定前一个阶段的 Query 和一个上下文路径特征 ,变换块计算以下操作:
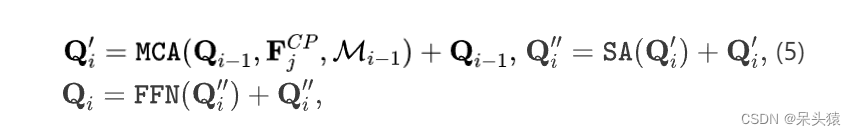 (5)
(5) 其中 是从上一解码层的二值化输出获得的二值 Mask ,类似于[7]中的方法。
作者依次将这个 Transformer 块在多尺度特征 和 上应用 次。作者将 视为最后一个 Transformer 块的输出 Query 。请注意,为了优先考虑计算效率,作者将 Mask 交叉关注限制在 和 上,避免使用最高分辨率特征 ,这会引起持续更大的计算开销。
分割头。分割头的目标是生成最终的预测,即一系列与每个类别概率相关联的二值 Mask 。
类别的概率 是通过应用一个分类层直接获得的,该分类层用参数 对每个段嵌入 进行处理,并接着使用softmax激活函数。正式地,将第 个嵌入表示为 ,作者计算如下:
为了获得最终的二值分割 Mask ,需要采用两步过程。首先,融合来自空间()和上下文()路径的高分辨率特征;然后,作者将得到的特征图与片段嵌入相乘以生成最终预测。来自空间和上下文路径的特征融合是一个关键点,因为前者关注低级视觉细节,而后者提取高级语义概念。融合操作遵循[27]并采用特征融合模块(FFM)。它首先将和进行拼接,以获得同时保留空间和上下文信息的特征。然后,为了得到最终的输出特征,采用了类似于SENet [16]的重新加权策略来促进特征选择和组合。正式地,作者计算
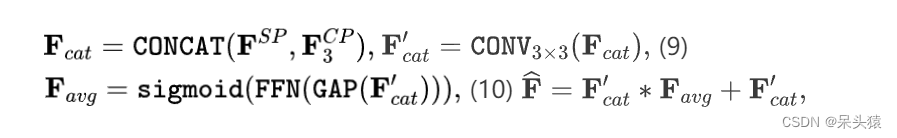
其中CONCAT是一个拼接操作,CONV是一个卷积,之后接ReLU和批量归一化,GAP是一个全局平均池化算子,FFN是一个两层ReLU前馈网络,之后接一个sigmoid函数,而表示广播逐元素乘法。
最后,将特征 与段嵌入 结合起来以获得最终的二值 Mask 。首先,一个具有两层隐藏层的前馈网络将段嵌入转换为 个 Mask 嵌入 ,它们具有与 相同的通道维度 。然后,通过特征与嵌入之间的点积得到二值 Mask ,之后使用sigmoid激活函数。形式上,输出 Mask 中由 标识的像素计算如下:
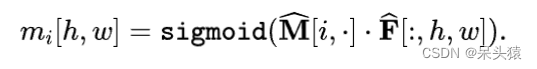















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









