







😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文讲解24考研860软件工程佛系上岸经验分享【丰富简历、初复试攻略、导师志愿、资料汇总】,期待与你一同探索、学习、进步,一起卷起来叭!

目录
前言
电子科技大学的信软院的电子信息专业初试为政治、英一、数一、860专业课(软件工程+计算机网络),考研难度中等,本人是24考研应届生,初试成绩:政治:71、英语:63、数学:123、专业课:133、总分:390分,以下是我在备考过程中的经验总结,希望能帮到正在备考这所学校的同学。💡其他科目考生 也可 以此做参考

大一
如果你当前是大一看到这个贴子,我给的建议是请不要搭理“考研“,为时甚早,建议认真学习学校课程、提升专业硬实力以及好好体验大学生活,以下是我本科期间有关专业知识的高质量文章,希望能帮到你更好的掌握专业知识:
🔗C语言题库-基础
🔗C语言题库-进阶
🔗Linux科普
🔗计算机网路科普
🔗编程练习:剪刀石头布
🔗Java基础知识汇总,巩固期末必看
🔗CCF-CSP打怪装备
🔗Java-OJ常用
🔗JavaWeb科普
🔗Git科普
🔗Nginx科普
🔗可视化大屏全栈教学,可以拿来做课设哦!
🔗Docker科普
🔗设计模式:女娲造人
🔗PDF生成原理
🔗MySQL二十万字总结
🔗Vue十万字总结
🔗带上ES一起寻找理想的另一半
🔗喜迎国庆,居家五黑,自己写个组队匹配叭
🔗拥抱云原生,Java与Python基于gRPC通信
🔗迎接2023,用JAVA演奏“新年”
🔗人工智能入门十二讲
🔗CI/CD科普
🔗大学刷了千道力扣,留下了什么(待更新)
🔗使用Anki挑战半月背完老九门
大二至大三上
如果你当前是大二或者大三上看到这个贴子,我给你的建议请不要现在开始备战考研,有点为时过早,建议开始好好丰富自己的简历(不论是保研、考研、就业均有好处)
比赛 && 科研 && 项目
如果你之前有接触过一些编程语言如Java、Python、JavaScrpit,且熟悉一些框架的使用,或者对一些领域的算法比较熟悉,那么我推荐你这一年可以参加一些大学生比赛。如:互联网+、挑战杯、全国机器人大赛、数学建模、蓝桥杯、CCF-CCSP、ACM、三创赛、全国大学生节能减排社会实践与科技竞赛、市调赛、微信小程序大赛等,这里面有的是团队赛,有的是个人赛,建议找一个团队并有老师的指导下参赛,这样更容易拿到国奖。【学习的技能、参与的比赛没有鄙视链这一说法,如果身边有人说学Java的都只会CRUD,参加互联网+、挑战杯比赛都是PPT大赛,也请不要搭理这些人!】
💡PS:如果有和我一个学校的同学,也欢迎加入我们实验室:IPBD公共安全大数据研究所
🚩 你在参赛过程中,一般这个项目都会参与到科研、项目,甚至你还可以申请到专利、软件著作。特别是进入国赛的项目,你可能需要付出更多的努力,我仍记得我在提交比赛作品的前一天熬到凌晨4点多,早上6.00多起床改PPT改到下午6.30提交了作品,中间只吃了几口泡面,提交完作品的那一瞬间,就像躺下来睡觉,很饿就是吃不进去,痛苦确实是挺痛苦,不过经过一步步的努力,我也顺利的获得了几个国奖,拿到了一些该得到的荣誉奖项,很艰辛但也很快乐。
🚩在参加这些比赛过程中,令我感受最深刻的莫过于性格的变化,我刚上大学特别的内向,不敢和别人对视,更不敢和别人说话,甚至见到熟人都要躲着走,后来我接触了一群有着共同理想的小伙伴和几位优秀且热心的老师,我们一块参加比赛。期间我有硬着头皮上台演讲,懵懵懂懂的组织团建,声音支支吾吾地和客户沟通需求等等,渐渐地,自己开始变得外向了,不再因为第二天要怎么怎么前几天晚上就开始睡不着觉,也不再因为很多事堆到一块就不知所措,开始懂得去社交,渐渐的认识了越来越多的优秀的人…直到考研复试,我自我感觉,我从头到尾没怎么紧张过,像极了我日常生活和老师们、客户们的对话,整个复试也是很愉快的结束。
实习经历
如果你的专业技能过关,推荐你在大二下的暑假去实习一段时间,这段实习经历能提升你的很多软实力,如人与人、人与知识、人与问题等。
创作经历
如果你喜欢分享知识,我非常推荐你在网上发布自己的博客,以此来鼓励自己不断地学习,并推荐你每天坚持刷力扣算法,训练自己的算法思维。也能后期参加蓝桥杯比赛、CCF-CCSP比赛奠定良好的基础。
以下是我本科推荐的课程,黑马程序员、尚硅谷的前后端课程、李沐老师的Pytorch课程、程序员鱼皮的项目实战课程、B站Up主小满zs的前端课程、极客时间的一些技术专题、ACWing的算法课等等。
大三下至大四
初试篇
我们这一年疫情原因,期末推迟到了寒假,所以在这个假期,我认真准备了期末考试和学习机器学习、深度学习相关的事情。我过年后2月份多算是开始正式备战考研,也开始确定自己备考的学校【建议最好在3-4月确定好,特别是考408的同学】。因为我的个人情况比较特殊,大三下我一直再纠结选择保研还是考研,所以我在大三下这一学期在备战考研的同时也在认真的准备学校的课程,当然最后也成功稳住了保研的资格,又在9月份又果断地放弃了。
💡大三上的这个学期,11月份会有一次软考,12月份会有四六级考试,也非常推荐大家参加,软考考试内容有软件工程、数据库、408相关的知识,有助于预热你的专业课
数学
高数
我数学高数部分跟的是“武忠祥”老师,刷题遇到武钟祥老师没讲到的,我会通过B站Up主的视频进行适当补充,如没咋了,吃尽天下面、考研竞赛凯哥等
因为我们大三下课程少,我一天可以听1-2甚至3节高数课(倍速播放),听完课刷一刷讲义,每学完一个大的章节我会先做一个数学思维导图进行复盘一下做题思路(我这里使用的是GoogleNotes,GoogleNotes可以手写公式,更能加强印象),大约3月份初就能听完基础课。
💡PS:我身边有同学刷过三大计算、1998-2009年的数学历年真题,因为我那会需要抽出一部分时间学习学校课程以及偶尔搞搞身边的项目,时间并不是很充裕,我没有刷这些题,所以不作评价。如果大家这学期有比较综合的课设,也非常推荐大家认真准备一下,这样不仅可以提升自己课程成绩以及专业课技能,甚至还可以申请一项软著、专利、期刊等为自己的简历加分!
我听完了高数基础课,然后我直接开始看的“武忠祥”老师的强化课程,并开始配套做880基础部分,我非常建议将 “武忠祥”老师的强化讲义 做到滚瓜烂熟,因为这本讲义总结真的非常到位,建议至少对某个知识点对应讲义上的哪几种常见题型以及对应解法要了如指掌。880题也是我心中的No.1,考研前我只做了2遍,感觉还是有的题目没有吃透,如果有时间,我一定还会再多刷几遍。

我大约4月上旬听完了武老师的高数强化部分,开始每天早上10min默写记不住的数学公式,如泰勒、曲率半径等,然后陆续慢慢补充了考研竞赛凯哥的定积分计算、不定积分计算、无穷级数等专题。4月份开始,郭伟老师会开始在每个月份的下旬开始模考,我感觉这个挺不错的,能够及时的反映自己目前的学习情况。
这里880基础篇刷题时,一章刷完记得复盘一下这一章的错题,一些特别好的题是可以打个标记,后续多刷。880基础篇刷完,就可以刷880强化篇、660高数部分等,依旧是错题标记,反复刷,滚瓜烂熟为止。【660不推荐刷线性代数部分,我只刷了高数部分,个人感觉高数部分最好,有余力者再刷其他部分,武忠祥老师的严选题、凯哥的高数讲义也是非常不错的题集,可以针对性刷一刷】
880强化部分是有一定的难度的,如果有个别题目被卡住进度可以适当跳过,后边可以慢慢修补,指不定哪天吃饭的时候就想明白了,保证在学习线代和概率论的同时也在刷着高数就行
线性代数
高数强化部分结束,可以稍休息一周(我这里直接出去旅游耍去了),做做总结后就可以开始线性代数了。我本科线性代数基础不错,所以先看了看自己的学习笔记,然后花了一周时间学完李永乐老师的线代课,开始反复刷李永乐老师的强化班讲义。不得不说“永乐大帝”的线代讲义是真的好,这本书我刷了大概3遍左右,也是非常建议多刷,特别是基础差的同学,至少这本书要滚瓜烂熟。李永乐老师的普通话不标准,我这里想推荐一个更好的线性代数课程:考研竞赛凯哥的线性代数解题班,这个课程是我在假期遇到的,非常推荐线性代数课程听他的,凯哥的线代讲义+李永乐老师的讲义+880刷到滚瓜烂熟,线代大概差不多了。如果大家数学基础不错的话,可以再买本李正元老师的考研数学复习全书,我后来又把这本书上面的例题针对性的刷了一遍,这本书上面的题也是非常的经典。还是坚持每天早上第一件事:默写一遍线性代数的二级结论,滚瓜烂熟为止。


如果你对线代代数感兴趣,我非常推荐你看B站Up主:3Blue1Brown的线性代数课程,里面的动画做的十分出色,可以增加自己对线代的理解。🔗参考链接
概率论
我概率论基础强化全部跟的方浩的课程,书使用的是余炳森的讲义,讲义我做了两遍,方浩老师的课上的题大概刷了3遍,至少滚瓜烂熟了,880也是做了两遍。因为概率论比较套路固定化,所以给的时间并不多。

暑假
我觉得暑假期间,至少要保持一天8小时的有效学习时长,个人感觉这个假期对于考研的成功与否至关重要。我是这样分配的:早上8:00起床吃饭,9:00-12:30刷高数、线代题并听一节概率论课,2.00-3:30看徐涛老师的政治课醒醒脑子并刷对应肖1000,3:30-5:30看专业课书,8:00-11:00刷一篇阅读、刷数学题、复盘数学题。
开学前,只剩下概率论强化课部分,我觉得就进度一切正常,880有的题会比较难,遇到不懂的思路,这个时间点没咋了会在B站发布880的题解,大家有不会的题可以去看没咋了讲解。
💡 如果你这个阶段听的凯哥线代解题班,已经可以开始刷近几年的模拟卷的线代题,如张宇4+8、李林4+6等,他的课程里面也有对应的讲解,如果都有大致思路,且能做出来,线代可以说是过关了。
真题
我是在10月刷完了数学880、英语阅读(除近三年)、小三门完型方法学的差不多、政治强化课全部听完。这个时候可以抽一周时间复盘做过的题,880依旧继续反复刷错题,然后就可以开始做数学真题了,数学真题我只做了近十年,且一天一套,使用的是李艳芳老师的,如果大家资金允许建议使用纸质版做,购买答题卡练习,感觉这样可以对眼睛好点,毕竟听了一年网课。
💡如果大家目标分数在130+,时间还算充裕,推荐大家可以再刷一本《李林108》,我数学并没有追求很高的分数,所以从这之后就每天巩固之前的错题,然后刷真题和模拟卷
模拟卷
真题做完复盘结束,就可以开做模拟卷了,我做过的模拟卷有:余炳森5套卷、张宇8套卷、张宇4套卷、李林4、李林6。这几个试卷质量都不差,有时间拿到卷子,每天早上一套,可以一周做五天卷子,两天用来复盘总结休息。持续到考前就行。这个时候每天的任务就是:刷题、复盘、总结、默写公式。模拟卷的分数不要纠结多少,没有任何意义【这个时候有人会在群里秀自己模拟卷的成绩啥的,甭理他们,大部分的人成绩这个阶段都是很不符合预期的,找到自己的不足就行】,模拟卷有的老师可能出错比较多,可以刷之前先找找勘误。【李艳芳、合工大、李永乐的卷子我只推荐做选填,大题有点搞人,周洋鑫、王谱的模拟卷也可以做做,什么真题讲解课真的没必要听,模拟卷的讲解课也尽量少听,可以针对性的听听,总之:每天有题可刷就行,保持手感】
💡 少听课,多刷题,多总结!
💡热点问题
Q:数学目标100+,需要刷多少模拟题呢?
A:认真总结好基础题型,选择题务必稳稳拿下,计算部分不要算错,闭眼100+
💡热点问题
Q:之前学的数二,想转数一来的及吗?
A:暑假之前能学完高数(基础 + 强化)并刷了一定量的题,总结了一定的题型,就可以转。
💡热点问题
Q:数学公式经常忘,经常自己做不会,一看答案就会
A:每天去教室前默写/推导几个公式,做题时不要上来就看答案秒了,刷每日一题视频时不要直接就看讲解,关闭弹幕先自己做一遍。
专业课
计算机网络
我之前计网学过几遍,所以没咋听课。我从4月份开始看的计网书,每天晚上阅读30分钟到1小时,遇到不懂的知识点选择性的看B站老师中科大计网视频,在假期看完了一轮,就开学直接开始了二轮。
第一轮黑书学习,我建议学习的深入一点,最好把每个知识点全部弄懂,不会的可以咨询ChatGpt。第二轮我把重点知识点全部在电脑上手敲了一遍做好了分类归纳,有的知识点做了记忆背诵的一些口诀,方便后期快速记忆。只要第一轮扎实,第二轮是特别快的,大概一个月多就学完了,然后就是三轮,四轮,我大概看了五六轮,最后就是每天背我自己整理的记忆手册。
我建议计网最迟在国庆假期后开始背诵,我在9月下旬开始了计网背诵,11月前专业课重点知识点已经背的很熟练了,11月份可以适当做做其他机构的模拟卷或者历年题啥的(熟悉题型即可,重点还是多看课本,机构讲义题库真的一点用也没有)以及MOOC上面的电科计算机网络课程的课后题,我11月份还做了王道书上的部分练习题,过了一遍王道对应的思维导图,总之后期就是查漏补缺反复记忆。
💡PS:第一轮中,如果时间充裕非常建议把每个知识点全部吃透,最好形成自己的框架体系,遇到不会的就理解咨询ChatGPT,或者看网课进行补充,理解的越到位,后期二轮、三轮复习越轻松。
💡热点问题
Q:最近才开始确定860,黑书第一轮怎么过比较好呢?我感觉我抓不住重点
A:
1.请查看资料:初试/860/860大纲+重点,根据重点内容学习
2.对照本人的背诵笔记:初试/860/笔记/个人笔记,再看书学习,效率会大大提升
💡热点问题
Q:之前学的408,现在想转860来的及吗?
A:如果以前学过计网和软工,6月之前换完全来得及,然后直接对照背诵笔记+课本/PPT猛猛学即可
软件工程
软件工程我是在暑假结束后开始的,软件工程比较简单,推荐大家直接看MOOC电子科技大学的PPT,课程就不要看了,大概一周就能看完,把里面的课后题一定也要刷一刷。然后就是整理软工的画图总结,第二轮软工也可以像我那样整理一个记忆手册,方便后期背诵,我看到过别人整理的,个人认为短期内背诵这么多简答题,最后先搞一个万能的套话框架,然后每次回答问题都用这个框架回答,复试也特别有效,不至于无话可说。例如:什么是软件测试?你就可以说软件测试是什么,目的是什么,为什么出现软件测试,软件测试有哪些等等。可以扩展写满答卷,我印象我考试的时候,整个答题卡写的都是满满的。
💡后期我会把我当时候整理的软工画图总结附上【少听课,多背】
💡热点问题
Q:软件工程简答题和选择题如何备考,需要看网课吗?
A:
1.软件工程不需要看网课,直接看PPT即可(位置:初试/860/PPT/软件工程/MOOC PPT)大概一周就能学完,不要自己做笔记,也不要看黑书或者别的网上的资料,对应考纲学习即可
2.看PPT的过程中,打开我的笔记二次修改,重新整理背诵即可(初试/860/笔记/个人笔记)
3.软件工程选择题很简单,花一周时间刷完这个PDF上的所有选择即可(初试/860/PPT/MOOC习题.pdf)
4.软件工程画图题不用自己找教程,直接看对应文件(初试/860/PPT/软件工程画图题汇总.pdf)
5.860对应模拟题和真题在文件夹(初试/860/真题+模拟卷),只做题型参考,不用太在意多少年的题,对于应付考研足够了
💡热点问题
Q:学长做1对1答疑吗?
A:暂时不做,使用资料后,后台私信我或者文章底部评论即可,看到就会回复,如果对您有帮助,欢迎赞助。
💡热点问题
Q:学长,软件工程跨考该怎么学?
A:先看PPT,根据我的笔记(初试/860/笔记/个人笔记)整理一个大的框架图,想象成造一个工程,需要每一步要干嘛,每一步会遇到什么问题,为了解决这个问题采用了什么手段…
补充
💡电科的专业课不是很难,都是偏记忆性的科目,多刷刷课后题、多背、多总结课本知识即可,市场上的模拟题、练习题真的很没必要花太多经历去做。
英语
英语其实是我最意难平的一个部分,我英语单词开始的最早,使用的软件是扇贝单词APP【背单词软件适合自己的才是最好的,不要受周围人乱推荐,我使用扇贝单词的原因是因为里面有个同桌的功能,我找了一个学习搭子每天和我一块背,这样能监督自己】,大概大三上开学前就已经每天100个单词背开了,因为准备六级考试嘛,就每天哐哐背,我个人比较喜欢英语,阅读理解我跟的是唐迟老师的课,我觉得大家单词背到4月份、5月份就可以开始看阅读理解课了,两三天一节就可以,学学做题方法,听完阅读方法课就可以认真的一天一篇阅读理解刷了,单词依旧每天背诵就行。
💡我身边有同学跟过田静老师的每日长难句练习,貌似效果不错,这里推荐一下,我没有跟 (没坚持下来)
暑假中旬可以开始小三门学习,我听的是刘琦老师的课,方法学会就行,没必要都听的,节约时间。完型填空我听的易熙人老师的课,我感觉这个老师讲的完型特别好,强力推荐,真的逻辑非常到位。翻译我跟的唐静老师,也是一位非常好的老师,我很喜欢这位老师的一句话:选择了就不会害怕,努力了就不会后悔,这里也想送给大家。
大约9月份底,我开始了作文,这里我走了一些弯路,我听了好多好多课,因为英语一直是我的一个强项,我对作文下的功夫挺大的,听了石雷朋老师的课、潘越老师的课、王江涛老师的书,最后看了一本见山学长的书,才恍然大悟。我这里只推荐大家作文少听课,直接看见山学长的书就可,看完模板,直接背完,然后就拿历年真题套一遍就成,不用花太多的时间。

最后就是英语后期最好测试一下自己的做阅读题的维持度,我个人一次性刷四篇阅读理解后面几篇效果很差,我考研在这吃过很大亏,前几篇还好,后几篇就大脑有点疲惫了,直接一大片全错,很痛心,至少要丢失很多分在这里。
💡 单词是前提,单词是前提,单词是前提!
💡热点问题
Q:学长,英二阅读、模拟题需要做吗?
A:不需要,做好英一真题即可,弄好每一题选项为什么对、错即可,至少要二刷、三刷,真题讲解可以看唐迟老师的课程或者考研真相PDF。
Q:作文最迟几月开始?
A:国庆结束开始就行,作文模板文件在(初试/英语/个人作文模板/作文模板.docx),大作文前两个模板几乎万能无敌了,小作文模板都背一下,建议每天背一小段,每次去了教室先默写一下,不追求很高的分数,套用没有任何问题。
政治
政治课我觉得是少投入多回报,暑假开始每天一节徐涛老师的课,一节对应肖1000题,可以配个小程序没事刷一刷,主打一个休息大脑。肖4到手之前只研究选择题就行,肖4到手立马背大题就政治问题不大。这里我没有太多的建议,关注B站Up主有山学长、空卡空卡空空卡等Up主跟着他们的步骤来就没啥问题。肖1000我只刷了1.3遍、腿姐技巧版只看了马原部分,手册买的腿姐的小册子,没花太多时间,就是背肖4,背肖8,背小册子。
在进入11月份的时候,我在小程序上刷了一遍市场上主流老师的政治模拟卷上的选择题,我个人感觉多刷刷模拟卷上的选择题还是挺有必要的,如徐涛模拟卷、腿姐四套卷、米鹏卷等等。
12月份专业课、数学、英语应该背诵任务全部结束,肖四PDF一出立马开始背就行,可以按科目进行背诵,建议不要偷懒只背前1-2套,我4套是都背了的,考试都写上了,可以侧重点放在前几套,但是后面的卷子也要至少有个大概印象,比如关键的采分点一定要答出来,细节不会了可以抄抄材料。背肖4的过程会很痛苦,建议大家备好金嗓子和水,从早背到晚,一直持续到考前一小时。(不要因为旱区而放弃,不要因为水区而大意,认准肖四)
💡政治学习秘诀:多刷B站Up主的学习指南视频
寄语
老师的选择个人感觉对学习没太多影响,跟哪个老师都差不多,我感觉还是多刷题,多总结,不要和身边的人比进度,有的人可能比你快个5、6轮不要打理他们,他们纯纯在感动自己,其实没什么用,保持好自己的节奏,就问题不大。考研群也不用每天水群,看别人群里发一些网红题、吹进度,学累了跑跑步、听听歌就挺好,如果有一天突然发现学不进去了,可以适当的休息半天或者一天,我一般会打会游戏或者出去旅游,总之不会在群里寻找焦虑。
资源汇总
优质UP主推荐:没咋了、吃尽天下面、空卡空卡空空卡、考研竞赛凯哥、夜雨教你考研竞赛、鸟山学长、学长小谭、蝶澈学姐、苏一说了、Ele实验室、3Blue1Brown、线帒杨、雅拉A梦、当年线代、小崔说数、中科大-郑烇老师、Roy大表哥、JavaEE之Spring框架
💡其他汇总请见文末
复试篇
寒假
春节前,我做了一个当地政府的项目并培训了22级本科生前后端学习,虽然假期过的比较累,但给自己的简历也增加了一些项目,还可以重拾自己以前学到的技术,方便后期做毕设,也是挺开心的。所以我挺推荐大家这个假期去接触一些项目,方便后期简历做准备。
春节后,我开始查阅学院老师信息,了解各个实验室研究方向,确定自己未来的读研规划。出成绩前,推荐大家制定好复试学习计划(需要用的学习资料、题库等)、自己的简历、自荐信、相关证明材料(方便出来成绩立即联系导师)、准备英语自我介绍、阅读喜欢的导师近几篇论文等。
💡可能会用到的资源:
- 信软实验室:🔗https://sise.uestc.edu.cn/kxyj/xykytd.htm
- 导师评价信息爬虫汇总附文末
💡这里分享一下我用到的自荐信模板:【其他文件(如英文自我介绍、论文阅读技巧总结、科研学习路线总结、项目包装教程)附文末】
XXX-软件工程专业硕士自荐信邮件
尊敬的X老师:
您好,非常感谢您能百忙之中抽出时间阅读我的邮件。
我叫XXX,是XX大学XX学院XX专业20级本科生,我的初试成绩是XXX分,其中政治XX分、英语XX分、数学XXX分、软件工程学科基础综合XXX分。根据往年复试线可以进入复试,希望有机会成为您的学生,所以冒昧写了这封邮件。
本科期间,我加权学分成绩为XX,绩点为XX,专业排名前X%并通过了英语四六级考试。我大XXX加入了我校XXX,担任XXX,期间XXX并参加了XXX大赛。我还热爱写作,从大二至今已在CSDN等社区共创作129篇文章,阅读量21W,粉丝2000多位。
XX期间,我参与了《XXX》科研命题,深入了解XXXX,并提升了自己在文献资料阅读与整理的能力。我通过查询学校官网,对您的科研方向非常感兴趣,并希望能够在您的指导下完成自己的研究生学业。
以上是我的自荐信,附件中有我的简历,以供您参考。冒昧打扰老师还望海涵,期待您的回信,祝老师万事顺心!
💡这个假期我读了两本书受益匪浅,想分享给大家:《学术“咸鱼”自救指南:论文写作发稿一本通》、《平面国》


还有两个计算机科普视频、机器学习与深度学习科普视频:
开学后
成绩查询
- 研招网:🔗https://yz.chsi.com.cn/apply/cjcx/
- 四川省教育考试院:🔗https://www.sceea.cn/
- 电子科技大学官网: 🔗http://zsgl.uestc.edu.cn/ksxt/login.aspx
- 复试通知查询:🔗https://yz.uestc.edu.cn/info/1081/4815.htm
- 信软官网:🔗https://sise.uestc.edu.cn/info/1026/11945.htm
- 成电地图:🔗https://gis.uestc.edu.cn
- 电子科技大学研究生招生管理系统:🔗https://zsgl.uestc.edu.cn/ksxt/login.aspx
💡可能会用到的资源:文末我会附上PDF编辑神器,方便大家PDF签名、PDF整合、PDF编辑等操作
笔试

电科的笔试比较简单,如果你之前有刷过力扣,或者接触过算法竞赛,只需要翻看自己的算法笔记(基础部分即可) -> 过一遍菜鸟教程 -> 稍微刷刷题库即可
🔗C语言题库-基础
🔗C语言题库-进阶
🔗大学刷了千道力扣,留下了什么(待更新)
老九门
如果你本科看过王道相关408视频,可以直接过一遍王道408笔记(网上一搜大把笔记) + 自己的计网、软工背诵手册 + 数据库、编译原理看看PPT即可。软件我使用的是Anki,背诵速度特别快,非常推荐使用。💡文末会附上我的Anki卡牌组,供大家参考使用
综合面试
关于综合面试,只需要根据自己的简历把可能用到的知识点进行专项突破一下就问题不大,总之做到有备而来就好。
💡如果对人工智能相关知识实在没有接触过,推荐先阅读书籍:白话机器学习的数学

简历参考
💡经验:写满 、无废话、科研+项目+奖项+实习+其他特殊经历 【模板文件附文末】

如果大家简历有用到MySQL、SpringBoot等领域知识,推荐一位厦门大学老师的课程,我在备考期末那会听了他的课受益匪浅,顿悟了好多知识:🔗跳转链接【有助于加深对底层的理解】
如果真的没有项目,那就好好做毕设:【若有余力我会逐渐开源我的一些项目实战教程】
英文面试
我这里沿用的英文写作的思路,采用固定的模板和万能套话进行记忆的。
步骤:1.收集常见问题 + 根据简历推测老师可能要问的问题;2.提取共性组织成万能模板;3.总结回答提问框架 + 反复套用模板练习
思路参考:
介绍生活相关类:【family、hobbies、college life】
family:
There are four people in my family: my parents, my younger sister and me.
In my spare time, I usually enjoy having a walk with my family after dinner,because there is a lovely park just very close to my home. And I believe it’s good for both my physical and mental health.
hobbies:
I have a lot of hobbies,such as running、listening to music and reading books.
In my spare time, I usually enjoy running with my friends after dinner,because there is a playground just very close to classrooms. And I believe it’s good for both my physical and mental health.
Xx is one of my favorite season/songs.In my spare time, I usually enjoy the season/song with my friends after dinner.And I believe it’s good for both my physical and mental health.
college life:
So, in my spare time, I usually enjoy having a walk with my friends after dinner,because there is a playground just very close to classrooms. And I believe it’s good for both my physical and mental health.
介绍专业知识类【常见名词解释汇总】、人生规划类【研究生、职业】等模板汇总附文末
体检 && 政审
清水河校医院体检攻略:【仅供参考,帮助大家节约时间】
0)复试结束过几天官网就会发体检报告(每年好像都一样),可以在学校附近租房字住几天顺便把体检做了
1)早上携带身份证来校医院,先去一楼体检部登记,登记完了之后去大厅缴费处缴费,然后你需要跑三个地方
2)先去二楼北侧血检,有两个窗口,检查后记得拿条形码。上午11点前完成,可以在下午5点前在大厅打印机根据条形码取体检报告
3)二楼放射科拍胸片,在DR一号诊室那里
4)去一楼体检中心的内外科,在体检部登记台左手边,应该会有两个窗口,可以排队前先问问
5)下午取到报告后,到一楼体检中心的内外科找医生签字
政审表攻略:【仅供参考,帮助大家节约时间】
个人信息部分打字即可:
1)出生年月,不是出生年月日。示例:2024年4月
2)学习工作单位:XX大学(应届生)、无(往届生无工作)、xx工作单位(往届生有工作)
3)最后学历:本科
4)免冠照贴一张,手写签字时间,然后交给学院导员或者当地社区即可
调档函 && 通知书
1)调档函随通知书一起一般在六月中旬发放,期间会5.1之前填写邮寄地址(不变动不需要填写,留意官网通知即可)
2)调档函接收地址查询 :🔗https://yz.uestc.edu.cn/info/1081/4475.htm
学信网身份证有效期问题
学信网 - 查看个人信息 - 编辑身份证 - 身份证是否长期有效选择否 - 重新填写身份证有效期

研0启动
恭喜你成功被电科拟录取,如果你本科没有参与过科研,推荐你参考以下学习路线(根据本人本科在实验室相关生活及身边研究生、研究生毕业生建议汇总),用于弥补和其他人的差距。
四月份
小白入门科研
💡涉及到的资料均在文末
开始书籍阅读,了解科研日常:《学术“咸鱼”自救指南:论文写作发稿一本通》(建议两周看完 + 一周复盘)
小白入门人工智能
第一周:
编辑器推荐:Prcharm、Vscode
🔗Python入门:菜鸟教程Python(一周) || 廖雪峰Python(一周)【学至内置模块即可】
🔗机器学习数学入门:《白话机器学习的数学》书籍(一周)【最后一章编程觉得困难可不看】
💡 Python历史版本大全,建议3.8+
💡 pip修改国内源:
# 临时换源:
# 清华源
pip install markdown -i https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
pip install markdown -i https://mirrors.aliyun.com/pypi/simple/
# 腾讯源
pip install markdown -i http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
pip install markdown -i http://pypi.douban.com/simple/
# 永久换源:
# 清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 腾讯源
pip config set global.index-url http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
pip config set global.index-url http://pypi.douban.com/simple/
# 换回默认源
pip config unset global.index-url
第二周:
🔗数据分析三件套:numpy、pandas、matplotlib(一周)【基础用法跟着敲一遍即可】
🔗数据分析三件套:配套CSV文件,提取码:fbaz
💭 1、2、42节不听
💭 18集完了之后请跳到21集和22集,再返回19集
💭 听不懂就跟着敲代码,只掌握三件套即可,中间涉及到的爬虫、数据库不需要纠结
🔗数据分析三件套,现用现查:菜鸟教程Numpy、菜鸟教程Pandas、菜鸟教程Matplotlib
💡复盘:




第三周:
🚩支线任务:🔗Numpy进阶练习:Numpy题库
🚩主线任务:
🔗人工智能原理速学(用于确定科研方向):小白也能听懂的人工智能原理
第四周:
🚩主线任务:Pytorch【小白推荐】 || Tenserflow
🔗PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
🔗Pytorch 下载官网:链接
🔗Pytorch 离线下载:链接
📜 注意事项:
1、使用国内源下载更快:anaconda 清华源

2、安装路径,这里不建议装在C盘,安装完大概3个G左右

3、Conda常用命令
#查询cuda版本
nvidia-smi
#查看当前环境的信息
conda info
#查看已经创建的所有虚拟环境
conda info -e
#切换到xx虚拟环境
conda activate xx
#切换环境
set CONDA_FORCE_32BIT=1 # 切换到32位
set CONDA_FORCE_32BIT=0 # 切换到64位
#创建一个python2.7 名为xxx的虚拟环境
conda create -n xxx python=2.7
#移除环境
conda remove -n env_name --all
#切换root环境
activate root
#删除环境钟的某个包
conda remove --name $your_env_name $package_name
#设置搜索时显示通道地址
conda config --set show_channel_urls yes
#恢复默认镜像
conda config --remove-key channels
#查找某包是否已经安装
conda list xxx #包的名称
#查询已安装包
pip list
4、Conda 虚拟环境envs目录为空
envs 在C:\Users\用户\.conda\envs

5、conda install nb_conda 安装失败
nb_conda -> python[version='>=2.7,<2.8.0a0|>=3.5,<3.6.0a0|>=3.8,<3.9.0a0|>=3.6,<3.7.0a0|>=3.7,<3.8.0a0']
# 如果python版本 >= 3.9
conda install nb_conda_kernels
# 启动命令
jupyter notebook
6、Pytroch(GPU版本)安装检查
python
>>> import torch
>>> torch.cuda.is_available()
>>> True
如果为Fasle,请检查下载版本(可能下载的是CPU版本)是否正确
五月份
组会PPT && 论文阅读工具汇总(第一周)
PPT常用素材:
电子科技大学Logo:

色系:RGB(0,64,152)
常用模板【文件已附文末】:

示例大语言模型综述介绍:

机器学习(第二周)
推荐书籍:李航《统计学习方法》(第二版)、周志华《机器学习》【文件已附文末】

只需要掌握基础知识+对应方向前置知识即可
深度学习(第三、四周)
李沐-动手学深度学习(花书)【文件已附文末】

读研规划(第四周)
就业攻略:【文件已附文末】
读博攻略:【文件已附文末】
竞赛汇总:Kaggle、ACM ICPC、阿里云天池大赛等【攻略已附文末】
入门测试
机器学习:是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。简单的说,就是“从样本中学习的智能程序”。
深度学习:深度学习的概念源于人工神经网络的研究,是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。不论是机器学习还是深度学习,都是通过对大量数据的学习,掌握数据背后的分布规律,进而对符合该分布的其他数据进行准确预测。

机器学习中典型任务类型:分类任务(Classification)和回归任务(Regression)。
- 分类任务:对
离散值进行预测,根据每个样本的值/特征预测该样本属于类型A、类型B还是类型C,例如情感分类、内容审核,相当于学习了一个分类边界(决策边界),用分类边界把不同类别的数据区分开来。 - 回归任务:对
连续值进行预测,根据每个样本的值/特征预测该样本的具体数值,例如房价预测,股票预测等,相当于学习到了这一组数据背后的分布,能够根据数据的输入预测该数据的取值。

分类任务 VS 回归任务:分类与回归的根本区别在于输出空间是否为一个度量空间。

- 对于分类问题,目的是
寻找决策边界,其输出空间B不是度量空间,即“定性”。也就是说,在分类问题中,只有分类“正确”与“错误”之分,至于分类到了类别A还是类别B,没有分别,都是错误数量+1。 - 对于回归问题,目的是
寻找最优拟合,其输出空间B是一个度量空间,即“定量”,通过度量空间衡量预测值与真实值之间的“误差大小”。当真实值为10,预测值为5时,误差为5,预测值为8时,误差为2。

机器学习分类:
- 有监督学习:监督学习
利用大量的标注数据来训练模型,对模型的预测值和数据的真实标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。【每条数据都有正确答案,通过模型预测结果与正确答案的误差不断优化模型参数】 - 无监督学习:无监督学习
不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。【只有数据没有答案,常见的是聚类算法,通过衡量样本之间的距离来划分类别】 - 半监督学习:利用
有标签数据和无标签数据来训练模型。一般假设无标签数据远多于有标签数据。例如使用有标签数据训练模型,然后对无标签数据进行分类,再使用正确分类的无标签数据训练模型。【利用大量的无标注数据和少量有标注数据进行模型训练】 - 自监督学习:机器学习的
标注数据源于数据本身,而不是由人工标注。目前主流大模型的预训练过程都是采用自监督学习,将数据构建成完型填空形式,让模型预测对应内容,实现自监督学习。【通过对数据进行处理,让数据的一部分成为标签,由此构成大规模数据进行模型训练】 - 远程监督学习:主要用于关系抽取任务,
采用bootstrap的思想通过已知三元组在文本中寻找共现句,自动构成有标签数据,进行有监督学习。【基于现有的三元组收集训练数据,进行有监督学习】 - 强化学习:强化学习是智能体根据已有的经验,采取系统或随机的方式,去尝试各种可能答案的方式进行学习,并且智能体会
通过环境反馈的奖赏来决定下一步的行为,并为了获得更好的奖赏来进一步强化学习。【以获取更高的环境奖励为目标优化模型】
模型:一个包含了大量未知参数的函数。

训练:通过大量的数据去迭代逼近这些未知参数的最优解。

- 样本:一条数据;
- 特征:被观测对象的可测量特性,例如西瓜的颜色、瓜蒂、纹路、敲击声等;
- 特征向量:用一个d维向量表征一个样本的所有或部分特征;
- 标签(label)/真实值:样本特征对应的真实类型或者真实取值,即正确答案;
- 数据集(dataset):多条样本组成的集合;
- 训练集(train):用于训练模型的数据集合;
- 评估集(eval):用于在训练过程中周期性评估模型效果的数据集合;
- 测试集(test):用于在训练完成后评估最终模型效果的数据集合;
- 误差/损失:样本真实值与预测值之间的误差;
- 预测值:样本输入模型后输出的结果;
- 模型训练:使用训练数据集对模型参数进行迭代更新的过程;
- 模型收敛:任意输入样本对应的预测结果与真实标签之间的误差稳定;
- 模型评估:使用测试数据和评估指标对训练完成的模型的效果进行评估的过程;
- 模型推理/预测:使用训练好的模型对数据进行预测的过程;
- 模型部署:使用服务加载训练好的模型,对外提供推理服务;
梯度:梯度是一个向量(矢量),函数在一点处沿着该点的梯度方向变化最快,变化率最大。换而言之,自变量沿着梯度方向变化,能够使因变量(函数值)变化最大。

学习率(LearningRate,LR):学习率决定了模型参数的更新幅度,学习率越高,模型参数更新越激进,即相同Loss对模型参数产生的调整幅度越大,反之越越小。
- 如果学习率太小,会导致网络loss下降非常慢;
- 如果学习率太大,那么参数更新的幅度就非常大,产生振荡,导致网络收敛到局部最优点,或者loss不降反增。

Batch size:Batch size是一次向模型输入的数据数量,Batch size越大,模型一次处理的数据量越大,能够更快的运行完一个Epoch,反之运行完一个Epoch越慢。
使用Batch size的原因:由于模型一次是根据一个Batch size的数据计算Loss,然后更新模型参数,如果Batch size过小,单个Batch可能与整个数据的分布有较大差异,会带来较大的噪声,导致模型难以收敛。与此同时,Batch size越大,模型单个Step加载的数据量越大,对于GPU显存的占用也越大,当GPU显存不够充足的情况下,较大的Batch size会导致OOM,因此,需要针对实际的硬件情况,设置合理的Batch size取值。
使用Batch size的好处:
- 提高内存利用率,提高
并行化效率; - 一个Epoch所需的
迭代次数变少,减少训练时间; - 梯度计算更加
稳定,训练曲线更平滑,下降方向更准,能够取得更好的效果;

Batchsize需要在合理的范围内设置,如果超出合理范围,Batchsize的增大会导致模型性能下降,泛化能力变差。(https://arxiv.org/pdf/1706.02677.pdf)

大的Batchsize容易收敛到sharpminimum,而小的Batchsize容易收敛到flatminimum,后者具有更好的泛化能力(https://arxiv.org/pdf/1609.04836.pdf)。

Batchsize过大并不是性能下降的直接原因,直接原因是迭代次数过少,因为Batchsize越大,每个epoch执行的迭代次数越少,参数更新次数减少,因此需要更长的迭代次数(https://arxiv.org/pdf/1705.08741.pdf)。

learningrate与batch_size:
- 传统模型在训练过程中更容易过拟合,所以需要设置合理的Batchsize,更多情况下
较小的Batchsize会取得更好的效果; 大模型不易过拟合,所以大模型建议设置更大的Batchsize;- 调整Batchsize与lr的一个常用思路是:调整batch_size时learningrate要进行
等比例的调整,保证收敛稳定性,但是在新的研究中表明这种方式不一定有效(还是得炼丹); - 可以通过增加Batchsize来达到与衰减学习率类似的效果,由于learningrate对收敛影响很大,所以
可以通过增加Batchsize代替衰减(https://arxiv.org/pdf/1711.00489.pdf); - 对于一个
固定的learningrate,存在一个最优Batchsize使得性能最优;
Learning rate scheduler:
合适的学习率对于模型的快速收敛非常重要,学习率下降策略是模型训练过程中一个非常常用且有效的方法。在训练初期,可以使用较大的LR来以较大幅度更新参数,然后逐渐降低LR,使网络更容易收敛到最优解。

Warm up:
- 在训练开始阶段,模型的权重(weights)是随机初始化或者与当前训练数据分布差异较大,此时若
选择一个较大的学习率,模型权重迅速改变,可能带来模型的不稳定(振荡)。 - 选择Warmup预热学习率的方式,可以使得在
训练开始阶段学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
好处:
- 有助于
减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳。 - 有助于保持
模型深层的稳定性。
Warm up && LR decay:
下图为在微调LLaMA-7B初始阶段的LR变化情况。首先通过Warm up策略,从一个非常小的学习率开始,逐步增大,完成warm up过程后,从预设LR开始,进行基于LR decay策略的模型训练。

Step:一次梯度更新的过程。
Epoch:模型完成一次完整训练集的训练。
线性函数:一次函数的别称。
非线性函数:函数图像不是一条直线的函数,如指数函数、幂函数、对数函数、多项式函数等,以及它们组成的复合函数。
激活函数:激活函数是多层神经网络的基础,保证多层网络不退化成线性网络,这样可以使得神经网络应用到更多非线性模型中。

常见激活函数:
sigmoid:

- sigmoid函数具有
软饱和特性,在正负饱和区的梯度都接近于0,只在0附近有比较好的激活特性; - sigmoid导数值最大0.25,也就是反向传播过程中,每层至少有75%的损失,这使得当sigmoid被用在隐藏层的时候,会导致
梯度消失(一般5层之内就会产生); - 函数输出不以0为中心,也就是
输出均值不为0,会导致参数更新效率降低; - sigmoid函数涉及
指数运算,导致计算速度较慢。
为什么希望激活函数输出均值为0?

在上面的参数wi更新公式中,
∂
L
∂
y
∂
y
∂
z
\frac{\partial L}{\partial y}\frac{\partial y}{\partial z}
∂y∂L∂z∂y对于所有wi都是一样的,xi是i-1层的激活函数的输出,如果像sigmoid一样,输出值只有正值,那么对于第i层的所有wi,其更新方向完全一致,模型为了收敛,会走Z字形来逼近最优解。
softmax:

tanh:

ReLU:

- ReLU是一个
分段线性函数,因此是非线性函数; - ReLU的发明是深度学习领域最重要的突破之一;
- ReLU
不存在梯度消失问题; - ReLU
计算成本低,收敛速度比sigmoid快6倍; - 函数输出不以0为中心,也就是
输出均值不为0,会导致参数更新效率降低; - 存在
deadReLU问题(输入ReLU有负值时,ReLU输出为0,梯度在反向传播期间无法流动,导致权重不会更新);
为了解决deadReLU问题:
LeakyReLU:

ELU:

Swish:

- 参数不变情况下,将模型中ReLU替换为Swish,
模型性能提升; - Swish
无上界,不会出现梯度饱和; - Swish
有下界,不会出现deadReLU问题; - Swish
处处连续可导。
损失函数(lossfunction):用来度量模型的预测值f(x)与真实值Y的差异程度(损失值)的运算函数,它是一个非负实值函数。损失函数仅用于模型训练阶段,得到损失值后,通过反向传播来更新参数,从而降低预测值与真实值之间的损失值,从而提升模型性能。整个模型训练的过程,就是在通过不断更新参数,使得损失函数不断逼近全局最优点(全局最小值)。
常见损失函数:回归任务中的MAE、MSE,分类任务中的交叉熵损失等。

均方误差(meansquarederror,MSE),也叫平方损失或L2损失,常用在最小二乘法中,它的思想是使得各个训练点到最优拟合线的距离最小(平方和最小)。

平均绝对误差(MeanAbsoluteError,MAE)是所有单个观测值与算术平均值的绝对值的平均,也被称为L1loss,常用于回归问题中。
交叉熵损失:
二分类:

其中,yi为样本i的真实标签,正类为1,负类为0;pi表示样本i预测为正类的概率。
多分类:

其中,M为类别数量;yic符号函数,样本i真实类别等于c则为1,否则为0;预测样本i属于类别c的预测概率。
对于不同的分类任务,交叉熵损失函数使用不同的激活函数(sigmoid/softmax)获得概率输出:
【二分类】
使用sigmoid和softmax均可,注意在二分类中,Sigmoid函数,我们可以当作成它是对一个类别的“建模”,另一个相对的类别就直接通过1减去得到。而softmax函数,是对两个类别建模,同样的,得到两个类别的概率之和是1。
【单标签多分类】
交叉熵损失函数使用softmax获取概率输出(互斥输出)。
【多标签多分类】
交叉熵损失函数使用sigmoid获取概率输出。
优化器(Optimizer):优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。如果损失函数是一座山峰,优化器会通过梯度下降,帮助我们以最快的方式,从高山下降到谷底。

梯度下降算法:
- BGD:批量梯度下降法在全部训练集上计算精确的梯度。为了获取准确的梯度,批量梯度下降法的每一步都把整个训练集载入进来进行计算,
时间花费和内存开销都非常大,无法应用于大数据集、大模型的场景。 - SGD:随机梯度下降法则采样单个样本来估计的当前梯度。随机梯度下降法放弃了对梯度准确性的追求,每步仅仅随机采样一个样本来估计当前梯度,
计算速度快,内存开销小。但由于每步接受的信息量有限,随机梯度下降法对梯度的估计常常出现偏差,造成目标函数曲线收敛得很不稳定,伴有剧烈波动,有时甚至出现不收敛的情况。 - mini-batchGD:mini-batch梯度下降法
使用batch的一个子集来计算梯度。

- Momentum(动量):Momentum优化算法是对梯度下降法的一种优化, 它在原理上模拟了物理学中的动量。
 vt由两部分组成:一是学习速率η乘以当前估计的梯度gt;二是带衰减的前一次步伐vt−1。vt直接依赖于vt−1和gt,而不仅仅是gt。另外,衰减系数γ扮演了阻力的作用。
vt由两部分组成:一是学习速率η乘以当前估计的梯度gt;二是带衰减的前一次步伐vt−1。vt直接依赖于vt−1和gt,而不仅仅是gt。另外,衰减系数γ扮演了阻力的作用。

- AdaGrad:引入
自适应思想,训练过程中,学习速率逐渐衰减,经常更新的参数其学习速率衰减更快。AdaGrad方法采用所有历史梯度平方和的平方根做分母,分母随时间单调递增,产生的自适应学习速率随时间衰减的速度过于激进。

- RMSprop:RMSprop是Hinton在课程中提到的一种方法,是对Adagrad算法的改进,主要是
解决学习速率过快衰减的问题。采用梯度平方的指数加权移动平均值,其中一般取值0.9,有助于避免学习速率很快下降的问题,学习率建议取值为0.001。

- Adam:Adam方法将
惯性保持(动量)和自适应这两个优点集于一身。- Adam记录梯度的
一阶矩(firstmoment),即过往梯度与当前梯度的平均,这体现了惯性保持: 
- Adam还记录梯度的
二阶矩(secondmoment),即过往梯度平方与当前梯度平方的平均,这类似AdaGrad方法,体现了自适应能力,为不同参数产生自适应的学习速率: 
- 一阶矩和二阶矩采用类似于滑动窗口内求平均的思想进行融合,即
当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均值的贡献呈指数衰减。 
- 其中,β1,β2为衰减系数,β1通常取值0.9,β2通常取值0.999,mt是一阶矩,vt是二阶矩。

- 其中,mt^ 和 vt^ 是mt、vt偏差矫正之后的结果。
- Adam记录梯度的
模型评估指标:
分类模型:
-
准确率(Accuracy):准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,
当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。

其中,ncorrect为被正确分类的样本个数,ntotal为总样本个数。 -
混淆矩阵:混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。

- TruePositive(TP):真正类。正类被预测为正类。
- FalseNegative(FN):假负类。正类被预测为负类。
- FalsePositive(FP):假正类。负类被预测为正类。
- TrueNegative(TN):真负类。负类被预测为负类。
-
精准率(Precision):精准率,表示预测结果中,
预测为正样本的样本中,正确预测的概率。

-
召回率(Recall):召回率,表示在
原始样本的正样本中,被正确预测为正样本的概率。

Precision值和Recall值是既矛盾又统一的两个指标,为了提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall值降低。 -
F1-score是Precision和Recall两者的综合,是一个综合性的评估指标。

-
Micro-F1:不区分类别,直接使用总体样本的准召计算f1score。
-
Macro-F1:先计算出每一个类别的准召及其f1score,然后通过求均值得到在整个样本上的f1score。
数据均衡,两者均可;样本不均衡,相差很大,使用Macro-F1;样本不均衡,相差不大,优先选择Micro-F1。
回归模型:
-
MSE(Mean Squared Error):均方误差,yi-y^i为真实值-预测值。
MSE中有平方计算,会导致量纲与数据不一致。

-
RMSE(Root Mean Squared Error):均方根误差,yi-y^i为真实值-预测值。
解决量纲不一致的问题。

-
MAE(Mean Absolute Error):平均绝对误差,yi-y^i为真实值-预测值。

问题:RMSE与MAE的量纲相同,但求出结果后为什么RMSE比MAE的要大一些。
原因:这是因为RMSE是先对误差进行平方的累加后再开方,它其实是放大了较大误差之间的差距。而MAE反应的是真实误差。因此在衡量中使RMSE的值越小其意义越大,因为它的值能反映其最大误差也是比较小的。 -
决定系数(R2):决定系数,分子部分表示真实值与预测值的平方差之和,类似于均方差MSE;分母部分表示真实值与均值的平方差之和,类似于方差Var。

- 根据R2的取值,来判断模型的好坏,其
取值范围为[0,1]: R^2^越大,表示模型拟合效果越好。R2反映的是大概的准确性,因为随着样本数量的增加,R2必然增加,无法真正定量说明准确程度,只能大概定量。
- 根据R2的取值,来判断模型的好坏,其
GSB:常用于两个模型之间的对比,而非单个模型的评测,可以用GSB指标评估两个模型在某类数据中的性能差异。

数据精度:
- FP32是
单精度浮点数,用8bit表示指数,23bit表示小数; - FP16是
半精度浮点数,用5bit表示指数,10bit表示小数; - BF16是对FP32单精度浮点数截断数据,即用8bit表示指数,7bit表示小数。

为什么聚焦半精度?
原因:
(1)内存占用更少
fp16模型占用的内存只需fp32模型的一半:
- 模型训练时,可以用更大的batchsize;
- 模型训练时,GPU并行时的通信量大幅减少,大幅减少等待时间,加快数据的流通;
(2)计算更快
主流GPU都有针对fp16的计算进行优化(如英伟达),在这些GPU中,半精度的计算吞吐量可以是单精度的2-8倍;
常用估计模型尺寸大小:
| 模型尺寸 | FP16 类型大小 | FP32 类型大小 |
|---|---|---|
| 6B | 6000000000 * 2byte ≈ 11.18GB | 6000000000 * 4byte ≈ 22.35GB |
| 7B | 7000000000 * 2byte ≈ 13.04GB | 6000000000 * 4byte ≈ 26.08GB |
| 13B | 13000000000 * 2byte ≈ 24.21GB | 6000000000 * 4byte ≈ 48.42GB |
| 175B | 175000000000 * 2byte ≈ 325.96GB | 175000000000 * 4byte ≈ 651.93GB |
当然半精度也会带来一定的问题:
(1)下溢出
- FP32 的表示范围:1.4 * 10-45 ~ 1.7 * 1038
- FP16 的表示范围:6 * 10-8 ~ 65504
由于 fp16 的值区间比 fp32 的值区间小很多,所以在训练过程中很容易出现下溢出(Underflow,<6x10-8)的错误。
(2)舍入误差
对于fp16:
- Weight = 2-3(0.125), Gradient = 2-14(约为0.000061)
- Weightnew= Weight + Gradient = 2-3 + 2-14 = 2-3
在 [2-3, 2-2] 区间,fp16 表示的固定间隔为2-13,也就是说,在fp16表示下,比2-3大的下一个数为 2-3 + 2-13,因此,当梯度小于2^-13^时,会出现舍入误差,梯度被忽略。
解决方案:
(1)保存fp32备份(混合精度训练)
weights, activations, gradients 等数据在训练中都利用FP16来存储,同时拷贝一份FP32的 weights,用于更新。
在前向传播过程中,模型各个层的参数w和层的输入输出都是fp16,但是fp16的精度不够,无法表示特别小的数值,这会导致在进行梯度更新的时候,梯度值下溢,导致被调整参数没有变化。
因此,在参数梯度更新的时候,会使用fp32来进行运算,也就是优化器为每一个训练参数保存一个额外的fp32类型的拷贝,计算完成之后再转成fp16,参与训练过程。
【极大消耗显存】

(2)Loss Scaling
- 前向传播后,反向传播前,
将损失变化(Loss)增大 2^k^倍,确保反向传播时得到的中间变量(激活函数梯度)则不会溢出; - 反向传播过程中,
使用放大的梯度对模型参数进行更新; - 反向传播后,
将权重梯度缩小 2^k^倍,恢复正常值。
如果缩放因子选择得太小,仍然可能会出现小梯度的问题;而如果缩放因子选择得太大,可能会导致梯度爆炸等数值稳定性问题。因此,合理选择缩放因子和监测训练过程中梯度的变化是非常重要的。

(3)Dynamic Loss Scaling
- 动态损失缩放的算法会
从比较高的缩放因子开始(如2^24^),然后开始进行训练迭代中检查数是否会溢出(Infs/Nans); - 如果
没有梯度溢出,则不进行缩放,继续进行迭代;如果检测到梯度溢出,则缩放因子会减半,重新确认梯度更新情况,直到数不产生溢出的范围内; - 在训练的后期,
loss已经趋近收敛稳定,梯度更新的幅度往往小了,这个时候可以允许更高的损失缩放因子来再次防止数据下溢。 - 因此,动态损失缩放算法会尝试
在每N(N=2000)次迭代将损失缩放增加F倍数,然后执行步骤2检查是否溢出。
模型计算练习:【参考文献:https://arxiv.org/pdf/1910.02054.pdf】
对于一个φ个参数的模型,fp16类型:
- 参数:2φ
- 梯度:2φ
- 优化器:12φ(混合精度训练,
每个参数fp32类型的值、momentum值和variance值,各4φ) - 总计:16φ
一个1.6B参数的GPT-2,训练过程就需要24GB的显存。这24GB中,参数和梯度只占了3GB,其余21GB只在模型更新的时候用到,但是在DP的时候,要存在里面。
当使用1.6B模型,序列长度1024,batch_size=32的时候,需要60GB的内存,大概15GB存储中间变量,24GB存储上述训练相关数据。
pytorch在进行模型训练的时候,如果发现没有用到的内存,会释放掉,等用的时候再开出来,反复的析构,会导致碎片内存的出现。
CUDA:CUDA中线程也可以分成三个层次:线程、线程块和线程网络。
- 线程(Thread):CUDA中基本执行单元,由硬件支持、开销很小,每个线程执行相同代码;
- 线程块(Block):若干线程的分组,Block内一个块至多512个线程、或1024个线程(根据不同的GPU规格),线程块可以是一维、二维或者三维的;
- 线程网络(Grid):若干线程块Block的网格,Grid是一维和二维的。
GPU有很多线程,在CUDA里被称为Thread,同时我们会把一组Thread归为一个Block,而Block又会被组织成一个Grid。

SM(StreamingMultiprocessor):GPU上有很多计算核心也就是SM,SM是一块硬件,包含了固定数量的运算单元,寄存器和缓存。在具体的硬件执行中,一个SM会同时执行一组线程,在CUDA里叫warp,直接可以理解这组硬件线程warp会在这个SM上同时执行一部分指令,这一组的数量一般为32或者64个线程。一个Block会被绑定到一个SM上,即使这个Block内部可能有1024个线程,但这些线程组会被相应的调度器来进行调度,在逻辑层面上我们可以认为1024个线程同时执行,但实际上在硬件上是一组线程同时执行,这一点其实就和操作系统的线程调度一样。意思就是假如一个SM同时能执行64个线程,但一个Block有1024个线程,那这1024个线程是分1024/64=16次执行。
GPU在管理线程的时候是以block为单元调度到SM上执行。每个block中以warp(一般32个线程或64线程)作为一次执行的单位(真正的同时执行)。
- 一个GPU包含多个SM,而每个SM又包含多个Core,SM支持并发执行多达几百的Thread。
- 一个Block只能调度到一个SM上运行,直到ThreadBlock运行完毕。一个SM可以同时运行多个Block(因为有多个Core)。
- 写CUDAkernel的时候,跟SM对应的概念是Block,每一个Block会被调度到某个SM执行,一个SM可以执行多个block。CUDA程序就是很多的Blocks均匀的喂给若干SM来调度执行。
再看一张图,加深一下理解,CUDA软件和硬件结构:

规格参数:不同的GPU规格参数不一样,执行参数不同,比如Fermi架构:
- 每一个SM上最多同时执行8个Block。(不管Block大小)
- 每一个SM上最多同时执行48个warp。
- 每一个SM上最多同时执行48*32=1536个线程。
内存:一个Block会绑定在一个SM上,同时一个Block内的Thread是共享一块ShareMemory(一般就是SM的一级缓存,越靠近SM的内存就越快)。GPU和CPU也一样有着多级Cache还有寄存器的架构,把全局内存的数据加载到共享内存上再去处理可以有效的加速。

CPU&GPU训练时间对比,直观感受一下差距:
- 模型:BERT-base
- 训练数据集:180000
- batch_size:32
- CPU(Xeon®Gold51182CPU24Core):40:30:00
- CPU(Xeon®Platinum8255C1CPU40Core):16:25:00
- GPU(P40):3:00:00
- GPU(V100):1:17:00
GPU并行方式:
- 数据并行(DataParallelism):在不同的GPU上运行同一批数据的不同子集;
- 流水并行(PipelineParallelism):在不同的GPU上运行模型的不同层;
- 张量并行(TensorParallelism):将单个数学运算(如矩阵乘法)拆分到不同的GPU上运行;
- 混合专家系统(Mixture-of-Experts):只用模型每一层中的一小部分来处理数据。

数据并行:
将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播,相当于加大了batch_size。
每个GPU都加载模型参数,被称为“工作节点(workers)”,为每个GPU分配分配不同的数据子集同时进行处理,分别求解梯度,然后求解所有节点的平均梯度,每个节点各自进行反向传播。
各节点的同步更新策略:
①单独计算每个节点上的梯度;
②计算节点之间的平均梯度(阻塞,涉及大量数据传输,影响训练速度);
③单独计算每个节点相同的新参数。
Pytorch对于数据并行有很好的支持,数据并行也是最常用的GPU并行加速方法之一。
模型分层:
将模型按层分割,不同的层被分发到不同的GPU上运行。每个GPU上只有部分参数,因此每个部分的模型消耗GPU的显存成比例减少,常用于GPU显存不够,无法将一整个模型放在GPU上。

layer的输入和输出之间存在顺序依赖关系,因此在一个GPU等待其前一个GPU的输出作为其输入时,朴素的实现会导致出现大量空闲时间。这些空闲时间被称作“气泡”,而在这些等待的过程中,空闲的机器本可以继续进行计算。
张量并行:
如果在一个layer内“水平”拆分数据,这就是张量并行。许多现代模型(如Transformer)的计算瓶颈是将激活值与权重相乘。
矩阵乘法可以看作是若干对行和列的点积:可以在不同的GPU上计算独立的点积,也可以在不同的GPU上计算每个点积的一部分,然后相加得到结果。
无论采用哪种策略,都可以将权重矩阵切分为大小均匀的“shards”,不同的GPU负责不同的部分,要得到完整矩阵的结果,需要进行通信将不同部分的结果进行整合。
混合专家系统:
混合专家系统(MoE)是指,对于任意输入只用一小部分网络用于计算其输出。在拥有多组权重的情况下,网络可以在推理时通过门控机制选择要使用的一组权重,这可以在不增加计算成本的情况下获得更多参数。
每组权重都被称为“专家(experts)”,理想情况是,网络能够学会为每个专家分配专门的计算任务。不同的专家可以托管在不同的GPU上,这也为扩大模型使用的GPU数量提供了一种明确的方法。

Pytorch DDP:
- 在DDP模式下,会有N个进程被启动(一般N=GPU数量),
每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。 - 在模型训练时,
各个进程通过Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度; - 各个进程
用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
Ring all-reduce 算法:
定义 GPU 集群的拓扑结构:
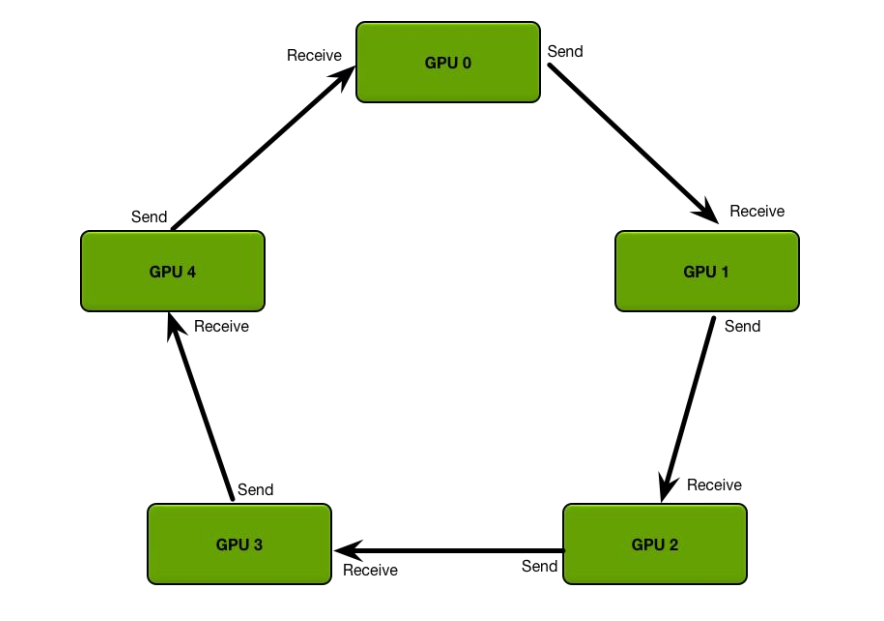
每个 GPU 只从左邻居接受数据、并发送数据给右邻居。
算法主要分两步:(举例:数组求和)
- scatter-reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。
- allgather:GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
Step1:将数组在每个GPU上都分块

Step2:N-1轮的scatter-reduce,每一轮中,每个GPU将自己的一个chunk发给右邻居,并接收左邻居发来的chunk,并累加。


Allgather:和scatter-reduce操作类似,只不过将每个chunk里面的操作由累加值变为替换。



在上面的过程中,N个GPU中的每一个将分别发送和接收N-1次scatter reduce值和N-1次all gather的值。每次,GPU将发送K/N个值,其中K是在不同GPU之间求和的数组中值的总数。
因此,往返每个GPU的数据传输总量为

由于所有传输都是同步发生的,因此减少的速度受到环中相邻GPU之间最慢(最低带宽)连接的限制。如果为每个GPU选择了正确的邻居,则该算法是带宽最佳的,并且是减少带宽的最快算法(假设与带宽相比,延迟成本可以忽略不计)。
通常,如果一个节点上的所有GPU在环中彼此相邻,则该算法的效果最佳。这样可以最大程度地减少网络争用的数量,否则可能会大大降低GPU-GPU连接的有效带宽。
学生党如何购卡
🔗购卡攻略:AutoDL

根据合适的任务选择GPU,以大模型训练为例:
| 任务类型 | 推荐GPU | 备注 |
|---|---|---|
| BERT训练 | RTX3090/RTX3080/RTX2080TI | 可以选择便宜的2080 |
| ⼤模型LoRA微调 | V100 32GB/V100 SXM2 32GB | V100 32GB 起步 |
| ⼤模型FT微调 | A100 40GB PCIE /A100 SXM 80GB | A100 40GB PCIE 起步 |
注意,SXM2/SXM4版本的GPU使⽤NVLINK,多卡性能优于PCIE版本。
GPU性能对⽐⽹址:🔗https://topcpu.net/cpu-c
注意,默认提供50GB硬盘,选择GPU⼀定选择可以扩容更多硬盘的服务器,不同任务的硬盘需求:
| 任务类型 | 推荐拓展硬盘 | 备注 |
|---|---|---|
| BERT训练 | 不需要拓展 | |
| ⼤模型LoRA微调 | 150GB及以上(理想300GB) | 500GB以内即可 |
| ⼤模型FT微调 | 300GB及以上(理想500GB) | 多多益善,不设限 |


选定后选择拓展硬盘、镜像:

配置SSH密钥登录,将⾃⼰电脑的ssh公钥复制到⾥⾯,配置ssh后,所有云服务器可以⽆密登录::

打开cmd终端,输入命令生成公私钥对:
ssh-keygen
我这里之前创建过:


打开git bash,执行cat命令:

添加SSH公钥:

将ssh命令复制到命令行中:

配置服务器网盘:


将模型下载到服务器中:

长时间关注显然使用情况命令:
watch -n -1 nvidia-smi

配置中文编码,防止中文乱码:
vim /etc/profile
#LANG=en_US.UTF-8
#LANGUAGE=en_US:en
#LC_ALL=en_US.UTF-8
export LANG=zh_CN.UTF-8
PATH=/root/miniconda3/bin:/usr/local/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
source /etc/profile
HuggingFace缓存配置:
如果不进⾏HuggingFace缓存配置,在⼤模型加载过程中的临时数据就会存放到系统盘,系统盘只有
25GB,会导致训练过程OOM。
mkdir /root/autodl-tmp/artboy && mkdir /root/autodl-tmp/tmp
vim ~/.bashrc
# enable programmable completion features (you don't need to enable
# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
#if [ -f /etc/bash_completion ] && ! shopt -oq posix; then
# . /etc/bash_completion
#fi
export HF_HOME=/root/autodl-tmp/artboy/.cache
export TEMP=/root/autodl-tmp/tmp
source /etc/profile
source /etc/autodl-motd
source ~/.bashrc
创建常用目录:
cd /root/autodl-tmp/artboy
mkdir finetune_code && mkdir data && mkdir base_model
ls
# 移动代码
cd finetune_code
mv ~/autodl-tmp/BertClassifier/ .
ls
配置虚拟环境:
conda create -n bert_env python=3.8.5
source activate bert_env
cd BertClassifier
bash install_req.sh
# cat install_req.sh
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# pip list
Package Version
------------------------ ----------
certifi 2024.6.2
charset-normalizer 3.3.2
cmake 3.29.3
filelock 3.14.0
fsspec 2024.6.0
huggingface-hub 0.23.3
idna 3.7
Jinja2 3.1.4
joblib 1.4.2
lit 18.1.6
MarkupSafe 2.1.5
mpmath 1.3.0
networkx 3.1
numpy 1.24.4
nvidia-cublas-cu11 11.10.3.66
nvidia-cuda-cupti-cu11 11.7.101
nvidia-cuda-nvrtc-cu11 11.7.99
nvidia-cuda-runtime-cu11 11.7.99
nvidia-cudnn-cu11 8.5.0.96
nvidia-cufft-cu11 10.9.0.58
nvidia-curand-cu11 10.2.10.91
nvidia-cusolver-cu11 11.4.0.1
nvidia-cusparse-cu11 11.7.4.91
nvidia-nccl-cu11 2.14.3
nvidia-nvtx-cu11 11.7.91
packaging 24.0
pip 24.0
PyYAML 6.0.1
regex 2024.5.15
requests 2.32.3
safetensors 0.4.3
scikit-learn 1.3.2
scipy 1.10.1
setuptools 69.5.1
sympy 1.12.1
threadpoolctl 3.5.0
tokenizers 0.19.1
torch 2.0.0
tqdm 4.66.4
transformers 4.41.2
triton 2.0.0
typing_extensions 4.12.1
urllib3 2.2.1
wheel 0.43.0
模型训练:
nohup bash multi_gpu.sh > 20240605_1800.log &
tail -f 20240605_1800.log
loading data from: data/cnew.train_debug.txt
100%|██████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 167.75it/s]
loading data from: data/cnew.val_debug.txt
100%|████████████████████████████████████████████████████████████| 500/500 [00:03<00:00, 129.41it/s]
Epoch 1 train: 11%|███▏ | 27/250 [00:41<05:41, 1.53s/it, acc=0, loss=2.08]
寄语
考研是一场持久战,它考验的不仅是我们的知识储备,更是我们的意志和毅力。只有真正踏上考研征途的人,方能深切体会考研人的心声与不易。用最少的时间做最多的事,希望我的分享能对大家有帮助。最后,祝愿所有正在备考的准研究生们都能取得优异的成绩,实现自己的梦想。“道阻且长、行则将至”,让我们一起共勉!
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2024.4.4
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!



















 2620
2620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









