






学习知识整理
(以下为转载内容,方便学习,随时更改)
1.memset()函数
memset:char型初始化函数
头文件:<string.h> 或 <memory.h>
函数原型:*void *memset(void s , int ch , size_t n )
# include <string.h>
void *memset(void *s, int c, unsigned long n);
memset(结构体/数组名 , 用于替换的ASCII码对应字符 , 前n个字符 );
memset(结构体/数组名 , "用于替换的字符“ , 前n个字符 );
函数解释:将s中的前n个字节用ch替换并且返回s
函数的功能是:将指针变量 s 所指向的前 n 字节的内存单元用一个“整数” c 替换,注意 c 是 int 型。s 是 void* 型的指针变量,所以它可以为任何类型的数据进行初始化。memset() 的作用是在一段内存块中填充某个给定的值。因为它只能填充一个值,所以该函数的初始化为原始初始化,无法将变量初始化为程序中需要的数据。用memset初始化完后,后面程序中再向该内存空间中存放需要的数据。
memset 是对较大的数组或结构体进行清零初始化的最快方法,因为它是直接对内存进行操作的
memset 函数的第三个参数 n 的值一般用 sizeof() 获取。注意,如果是对 指针变量 所指向的内存单元进行清零初始化,那么一定要先对这个指针变量进行初始化,即一定要先 让它指向某个有效的地址 。而且用memset给指针变量如p所指向的内存单元进行初始化时,n 千万别写成 sizeof§。因为 p 是指针变量,不管 p 指向什么类型的变量,sizeof§ 的值都是 4。
//1.
#include<cstring>//#include<string.h>
#include<iostream>
using namespace std;
int main()
{
char str[10];
str[9] = ‘w’;
memset(str,97,9);
for(int i=0;i<10;i++){
cout<<str[i]<<" ";
}
return 0;
}
//输出:a a a a a a a a a w
//2.
#include<cstring>//#include<string.h>
#include<iostream>
using namespace std;
int main()
{
char str[10];
str[9] = ‘w’;
memset(str,97,sizeof(char)*10);
for(int i=0;i<10;i++){
cout<<str[i]<<" ";
}
return 0;
}
//输出:a a a a a a a a a a
//3.
#include<cstring>//#include<string.h>
#include<iostream>
using namespace std;
int main()
{
char str[10];
memset(str,65,sizeof(str)-3);
for(int i=0;i<10;i++){
cout<<str[i]<<" ";
}
return 0;
}
//输出:A A A A A A A
2.EOF
用于连续输入多组测试数据,以EOF结束。
c语言:while(scanf("% ",& )!=EOF)
头函数:#include<stdio.h>
c++:while(scanf("% “,& )!=EOF)/whiile(~scanf(”% ",& ))
头函数:#include #include
#include<cstdio>//#include<stdio.h>
#include<iosteraam>
int main()
{
int n;
while(~scanf("%d",&n))//while(scanf("%d",&n)!=EOF)
{
printf("%d",n+1);//可循环计算n-1,直到EOF结束
}
}
3.bool函数




4.tolower/toupper
一个一个字符处理,将大小写转换,除字母外原样输出
#include <iostream>
#include <string>
#include <cctype>
using namespace std;
int main()
{
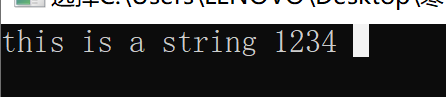
string str= "this IS A STRING 1234";
for (int i=0; i <str.size(); i++) // string类的长度不用strlen()函数,直接str.size()或str.lenth()
str[i] = tolower(str[i]); // 小写不会变,大写转小写
cout<<str<<endl;
return 0;
} // toupper 同理
5.定义有序对
define cord std::pair<int,int>
#include<cstdio>
#include<cmath>
#include<algorithm>
#define cord std::pair<int,int>
#define x first
#define y second
using namespace std;
const int N=1007;
cord loc[N];
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;++i)
scanf("%d%d",&loc[i].x,&loc[i].y);
std::sort(loc+1,loc+n+1);//loc+n+1为空地址
for(int i=1;i<=n;++i)
printf("(%d,%d)\n",loc[i].x,loc[i].y);
return 0;
}
定义结构体排序
#include<cstdio>
#include<cmath>
#include<algorithm>
const int N=1007;
struct Cord{
int x,y;
}loc[N];
bool cmp(Cord a,Cord b){
return a.x<b.x || a.x==b.x && a.y<b.y;
}
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;++i)
scanf("%d%d",&loc[i].x,&loc[i].y);
std::sort(loc+1,loc+n+1,cmp);
for(int i=1;i<=n;++i)
printf("(%d,%d)\n",loc[i].x,loc[i].y);
return 0;
}
/*
输入:
5
-1 2
-1 3
-3 2
2 4
5 2
输出:
(-3,2)
(-1,2)
(-1,3)
(2,4)
(5,2)
*/
6.sort快速排序
sort(起始位置,结束位置+1,排序方法(升序/降序))
#include <iostream>
#include <algorithm> //用sort必须加入的头文件
using namespace std ;
struct text {
int a;
int b;
};
bool cmp1(int a,int b) {
return a>b;
}
bool cmp2(char a,char b) {
return a>b;
}
bool cmp3(text a,text b) {
return a.a>b.a;
}
bool cmp4(text a,text b) {
return a.b<b.b;
}
int main() {
int a[5]={3,4,1,2,5};
sort(a,a+5,cmp1); //cmp,降序排序 5,4,3,2,1
sort(a,a+5); //默认升序排序,1,2,3,4,5
char b[6]={'s','j','d','e','a','t'};
sort(b,b+6,cmp2); //按ASCII码降序排序
sort(b,b+6); //默认按ASCII码升序排序
text c[5]={5,9,7,3,1,6,4,8,2,0};
sort(c,c+5,cmp3); //按结构体中a的值降序排序
sort(c,c+5,cmp4); //按结构体中b的值升序排序
return 0;
}
7.初始化问题
转载——C++初始化问题1
转载——C++初始化问题2
转载——C++初始化问题3
转载——C++指针初始化问题
8.π的表达方式
π=acos(-1)//较为准确的表达方式,主要看题目和代码要求
9.getline()
在C++中本质上有两种getline函数:
第一种:在头文件istream中,是iostream类的成员函数。
第二种:在头文件string中,是普通函数。
第一种: 在istream中的getline()函数有两种重载形式:
istream& getline (char* s, streamsize n );
istream& getline (char* s, streamsize n, char delim );
作用是: 从istream中读取至多n个字符(包含结束标记符)保存在s对应的数组(用于数组)中。即使还没读够n个字符,
如果遇到delim 或 字数达到限制,则读取终止,delim都不会被保存进s对应的数组中。
例如:
char s[11];
cin.getline(s, 10);
第二种: 在string中的getline函数有四种重载形式:
istream& getline (istream& is, string& str, char delim);
istream& getline (istream&& is, string& str, char delim);
istream& getline (istream& is, string& str);
istream& getline (istream&& is, string& str);
用法和上第一种类似,但是读取的istream是作为参数is传进函数的。读取的字符串保存在string类型(用于string类型)的str中。
函数的变量:
is :表示一个输入流,例如 cin。
str :string类型的引用,用来存储输入流中的流信息。
delim :char类型的变量,所设置的截断字符;在不自定义设置的情况下,遇到’\n’,则终止输入。
例如:
string s;
getline(cin, s);
getline函数在遇到换行符“/n”时停止读入
eg:string line;
cout<<”Enter a line of input:/n”;
getline( cin, line );
2、 允许程序员指定不同的停止读入标志。
eg:string line;
cout<<”Enter some input:/n”;
getline( cin, line, ‘?’ ); // 在第一个问号处停止读入
3、 getline函数的返回值是一个输入流对象(一般就是cin)的引用,因此可以如下使用:
eg:string s1, s2;
getline( cin, s1 ) >> s2; // 先读入一行到s1,再读入一个不包含空白字符的字符串到s2
10.swap函数
C++中的swap函数
交换两个变量的值很简单。
比如 int a = 1; b = 2; 交换a b的值
这个很简单 很容易想到的是找个中间变量比如 int temp = a; a = b; b = temp;
不需要中间变量可不可以?
当然是可以的。
比如
【加减法】
a = a + b; b = a - b; a = a - b;
该方法可以交换整型和浮点型数值的变量,但在处理浮点型的时候有可能出现精度的损失,例如对数据:
a = 3.123456
b = 1234567.000000
交换后各变量值变为:
a = 1234567.000000
b = 3.125000
很明显,原来a的值在交换给b的过程中发生了精度损失。
【乘除法】
a = a * b; b = a / b; a = a / b;
乘除法更像是加减法向乘除运算的映射,它与加减法类似:可以处理整型和浮点型变量,但在处理浮点型变量时也存
在精度损失问题。而且乘除法比加减法要多一条约束:b必不为0。
可能经验上的某种直觉告诉我们:加减法和乘除法可能会溢出,而且乘除的溢出会特别严重。其实不然,采用这两种
方法都不会溢出。以加减法为例,第一步的加运算可能会造成溢出,但它所造成的溢出会在后边的减运算中被溢出回来。
【异或法】
a ^= b; //a=a^b
b ^= a; //b=b(ab)=bab=bba=0^a=a
a ^= b; //a=(ab)a=aba=aab=0^b=b
异或法可以完成对整型变量的交换,对于浮点型变量它无法完成交换。
第二类方法更像是玩了一个文字游戏,此种方法采用了在代码中嵌入汇编代码的方法避免了临时变量的引入,但究其
本质还是会使用额外的存储空间。此种方法可以有很多种,下边列出几种:
等等…
但是对结构体这种交换就不太实用了应为结构体需要对每个数据都进行交换,这个时候用函数就是最简单的了。
C++提供了一个swap函数用于交换,用法如下
#include<iostream>
#include<string>
#include<algorithm>//sort函数包含的头文件
using namespace std;
//定义一个学生类型的结构体
typedef struct student
{
string name; //学生姓名
int achievement; //学生成绩
} student;
//用来显示学生信息的函数
void show(student *stu,int n)
{
for(int i = 0; i < n; i++)
{
cout<<"姓名:"<<stu[i].name<<'\t'<<"成绩:"<<stu[i].achievement<<endl;
}
}
int main()
{
student stu[] = { {"张三",99},{"李四",87},{"王二",100} ,{"麻子",60}};
cout<<"交换前:"<<endl;
show(stu,4);
swap(stu[0],stu[3]);
cout<<"交换后:"<<endl;
show(stu,4);
return 0;
}
用函数不用担心精度的损失
#include<iostream>
using namespace std;
int main()
{
float a = 3.123456,b = 1234567.000000;
swap(a,b);
cout<<fixed;
cout<<a<<"->"<<b<<endl;
return 0;
}
#include<iostream>
#include<string>
using namespace std;
int main()
{
string a ="666",b = "999";
swap(a,b);
cout<<a<<"->"<<b<<endl;
return 0;
}
11.scanf("%*s%d")
当写入时会跳过%s直接读取%d的内容
%s:取决于在scanf中使用还是在printf中使用。
1.在scanf中使用,则添加了的部分会被忽略,不会被参数获取。
int a,b;
char b[10];
scanf("%d%*s",&a,b);
//输入为:12 abc那么12将会读取到变量a中,但是后面的abc将在读取之后抛弃,不赋予任何变量(例如这里的字符数组b)
2.在printf中使用,表示用后面的形参替代的位置,实现动态格式输出。
例如:
printf("%*s", 10, s);
//意思是输出字符串s,但至少占10个位置,不足的在字符串s左边补空格,这里等同于printf("%10s", s);
%.*s: *用来指定宽度,对应一个整数。.(点)与后面的数合起来 是指定必须输出这个宽度,如果所输出的字符串长度大于这个数,则按此宽度输出,如果小于,则输出实际长度
int i;
for(i=0;i<3;i++)
printf("%.*s%s\n", i, " ", "########");
return 0;
//循环三次
第一次不输出空格,直接输出########
第二次输出一个空格,再输出########
第三次输出两个空格,再输出########
//大家可以自行验证
12.setiosflags(ios::fixed)
使用setprecision(n)可控制输出流显示浮点数的数字个数。C++默认的流输出数值有效位是6。
如果setprecision(n)与setiosflags(ios::fixed)合用,可以控制小数点右边的数字个数。setiosflags(ios::fixed)是用定点方式表示实数。
如果与setiosnags(ios::scientific)合用, 可以控制指数表示法的小数位数。setiosflags(ios::scientific)是用指数方式表示实数。
例如,下面的代码分别用浮点、定点和指数方式表示一个实数:
#include<iostream>
#include<iomanip> //要用到格式控制符
int main()
{
double amount = 22.0/7;
cout <<amount <<endl;
cout <<setprecision(0) <<amount <<endl
<<setprecision(1) <<amount <<endl
<<setprecision(2) <<amount <<endl
<<setprecision(3) <<amount <<endl
<<setprecision(4) <<amount <<endl;
cout <<setiosflags(ios::fixed);
cout <<setprecision(8) <<amount <<endl;
cout <<setiosflags(ios::scientific)
<<amount <<endl;
cout <<setprecision(6); //重新设置成原默认设置
return 0;
}
运行结果为:
3.14286
3
3
3.1
3.14
3.143
3.14285714
3.14285714e+00
该程序在32位机器上运行通过。
在用浮点表示的输出中,setprecision(n)表示有效位数。
第1行输出数值之前没有设置有效位数,所以用流的有效位数默认设置值6:第2个输出设置了有效位数0,C++最小的有效位数为1,所以作为有效位数设置为1来看待:第3~6行输出按设置的有效位数输出。
在用定点表示的输出中,setprecision(n)表示小数位数。
第7行输出是与setiosflags(ios::fixed)合用。所以setprecision(8)设置的是小数点后面的位数,而非全部数字个数。
在用指数形式输出时,setprecision(n)表示小数位数。
第8行输出用setiosflags(ios::scientific)来表示指数表示的输出形式。其有效位数沿用上次的设置值8
13.mid=(left+right)>>1
右移运算符>>,运算结果正好能对应一个整数的二分之一值,这就正好能代替数学上的除2运算,但是比除2运算要快。
mid=(left+right)>>1 与 mid=(left+right)/2 意义相同
14.freopen
通常在设计好算法和程序后,要在调试环境(例如VC等)中运行程序,输入测试数据,当能得到正确运行结果后,才将程序提交到oj中。但由于调试往往不能一次成功,每次运行时,都要重新输入一遍测试数据,对于有大量输入数据的题目,输入数据需要花费大量时间。使用freopen函数可以解决测试数据输入问题,避免重复输入,不失为一种简单而有效的解决方法。
函数名:freopen
声明:FILE *freopen( const char *path, const char *mode, FILE *stream );
所在文件: stdio.h
参数说明:
path: 文件名,用于存储输入输出的自定义文件名。
mode: 文件打开的模式。和fopen中的模式(如r-只读, w-写)相同。
stream: 一个文件,通常使用标准流文件。
返回值:成功,则返回一个path所指定文件的指针;失败,返回NULL。(一般可以不使用它的返回值)
功能:实现重定向,把预定义的标准流文件定向到由path指定的文件中。标准流文件具体是指stdin、stdout和stderr。其中stdin是标准输入流,默认为键盘;stdout是标准输出流,默认为屏幕;stderr是标准错误流,一般把屏幕设为默认。
freopen 用法
函数原形 FILE *freopen(char *filename, char *type, FILE *stream);
第一个参数 filename 是文件名
第二个参数一般是 “r” 或 “w”, “r” 代表是从文件读入,"w"代表是写
入到文件
第三个参数一般是 stdin 代表文件读入, 和第二个参数 “r” 连用
stdout 代表写入到文件,和 第二个参数 “w” 连用
用法举例
freopen(“a.txt”,“r”,stdin ); 执行这条语句后, 程序中下面所有的
读入将从文件 “a.txt” 中读入
如:
#include <stdio.h>
#include <stdlib.h>
int main()
{
char ch;
freopen("a.txt","r",stdin);
while( ch= getchar()!= '/n' )
putchar(ch);
return 0 ;
}
对于这个程序, 那么在控制台下的读入都无效, 他只会从文件
"a.txt"中读入. 运行这个程序前你得先建一个文件 a.txt , 与你的代码
生成的 .exe 文件在同一文件夹中。大家可以试试看。
如果再加一个语句, 程序变为
#include <stdio.h>
#include <stdlib.h>
int main()
{
char ch;
freopen("a.txt","r",stdin);
freopen("b.txt","w",stdout);
while( ch= getchar()!= '/n' )
putchar(ch);
return 0 ;
}
程序不会输出任何东西在控制台下, 而把所有输出输出到文件 “b.txt” 中
这个 b.txt 文件可以先不建, 程序会自动在与 .exe 文件相同目录下建立
另外还有两个问题
- 如何判断文件是否打开了
可以直接
if( freopen("a.txt","r",stdin)== NULL ) return false;
if( freopen("b.txt","w",stdout)== NULL ) return false;
表示没有打开
- 如何使流重新回到控制台上
如果你不想输入或输出到文件了,就加上一句
freopen("CON","r",stdin ); 对应输入
freopen("CON","w",stdout); 对应输出
注意的问题, 因为参数都是 c_字符串, 故不能把 c++ 里面的 string 类对
象作为参数传进去
比如 string str= “a.txt”;
你不能这样写 freopen( str, “r”, stdin );
可以先把 string 类对像化成 c_字符串, 就用 c_str() 函数
上面的可以这样写 freopen( str.c_str(), “r”, stdin );















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









