






注意:此文档给mmcv初时者供读比较合适!!!
mmcv是什么?
简单理解,mmcv就是pytorch的封装版本,他无外乎还是继承pytorch的,所以懂pytorch后读懂mmcv也不是太难的事。
怎么读mmcv代码?
首先得大概了解mmcv代码存放的习惯(也可以叫规定,因为这是github上大哥整出来的)

上图是我随便下载的一个项目源码,其中有几个非常重要,也是每个项目都有的:
1.configs文件夹:里面放了参数的存放,类似于pytorch的edit configuration(这个不知道的话说明pytorch还得再学学)
configs文件夹打开有一堆乱七八糟的东西,不重要,记住一点,_base_文件夹里面存放的文件夹会被其他文件夹里的py文件调用,例如:ann文件夹里会有一个py,你可以打开看,里面会这么写

这个路径就是_base_文件夹内的py文件,说明调用的是_base_文件夹内py文件的参数
再说_base_存放的是什么
显而易见,里面的datasets肯定存放的是数据的信息,比如路径啊、有什么预处理等乱七八糟的东西。
# dataset settings
dataset_type = 'ADE20KDataset'
#数据名字叫ADE20KDataset,别小看这个名字,
这个名字最后要被下文所写的datasets文件夹中的
builder.py调用的,怎么调用这一问题我后续发文再写。
data_root = 'data/ade/ADEChallengeData2016' #数据路径
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) #均值方差,以便归一化
crop_size = (512, 512) #图片尺寸变化值
### 接下来有两个pipeline,分别是训练和测试的,写法是固定的,
这里说一下pipline的意义,就是现在想象一个场景,你开始训练了,
ok,此时开始把你数据路径中的数据文件全部加载进来了,那此时应该干点啥,
很对,就是解析文件啊,比如把jpg文件变成array,然开始预处理,那么就要用到pipeline,
第一个dict(type='LoadImageFromFile'),这就是加载数据,也就是把数据文件(假如叫cat.png)用cv.imread读成一个矩阵,LoadAnnotations就是读标签,后面的我就不多解释了,大家自己进函数看看就行了,我觉得最后这个Collect可以自行去网上查查,感觉得好好理解一下
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', reduce_zero_label=True),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
###至此pipeline书写完了,也就是数据处理这一config写完了,底下写的就是什么batch_size,然后训练验证测试时候的数据具体路径,不要惊讶,上面虽然写了数据路径,但有的数据输入和标签不在一起放着,甚至train和test都不在一起放着,当然要进一步具体写好啊。
data = dict(
samples_per_gpu=4, ##每个GPU的batch_size
workers_per_gpu=4, ##每个GPU的线程数
train=dict(
type=dataset_type, #这句话也是因为会被builder.py调用,目前可以先不管
data_root=data_root, #这句话也是因为会被builder.py调用,目前可以先不管
img_dir='images/training', #输入路径
ann_dir='annotations/training', 标签路径
pipeline=train_pipeline), 这句话有意思,就是train过程中数据调用的pipeline,看到了没 这就相当于把上面写的train_pipeline调用了。
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=test_pipeline))
上面的代码是我打开datasets中的一个py文件,重要语句我都给了注释了,大家自行阅读,有不懂的可以自行scdn。
该models文件夹的py文件了,
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True) #BN层用哪个函数,要不要更新
model = dict(
type='EncoderDecoder', #这句话很关键,会被mmseg/models/builder.py调用,请大家记住这个EncoderDecoder名字,记住!!!
pretrained='open-mmlab://resnet50_v1c', #预训练模型文件
backbone=dict(
type='ResNetV1c', #每一个type都对应了一个类,这个类怎么找,后续会说,这ResNetV1c就和EncoderDecoder一样
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='ANNHead',
in_channels=[1024, 2048],
in_index=[2, 3],
channels=512,
project_channels=256,
query_scales=(1, ),
key_pool_scales=(1, 3, 6, 8),
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole')) #这个我不想多解释了,mode这一变量会在测试时进行判断,如果是"whole那就因为判断进入另一块代码,没什么神秘的,具体看代码哪块进行mode变量的判断就行了。
其实看完models中的py文件,大家心里是不是有种感觉,这不就是pytorch的configuration吗,装什么神秘,写的那么复杂,还非要分开写这么多文件,搞得乱七八糟,对了,我刚开始也是这种感觉,但是真的读懂了后发现,假如你说你要修改个预处理操作,直接在这改就行,方便,而且,而且,而且,每次训练都会自动保存你的config文件中的所有设置到你设置的日志路径中,这样多次实验也不怕忘了这个实验当时设置啥东西了(不信你训训你看,就会出现一个.py文件,你打开就发现你设置的所有东西都自动写进去了,一目了然)
再看schedules文件夹中的py文件
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
# learning policy
lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False) #poly就是逐降方式
# runtime settings
runner = dict(type='IterBasedRunner', max_iters=20000) #这里的runner是啥呢,大概就是咱们pytorch训练的时候写训练是不是这样的:
while epoch < 10000:
epoch += 1
for i, (f_img, labels,local_index) in enumerate(trainloader):
model.train()
optimizer.zero_grad()
loss, outputs = model(f_img, labels,Training=True)
loss.backward()
optimizer.step()
是不是很熟悉,就相当要开始训10000轮次,对不对?
ok,那mmcv就直接人家给你把这段省了,人家直接构建一个runner,这个runner就相当于上面代码的封装版本(当然肯定没那么简单,可以简单这么理解),你只需要给runner里面填参数,他直接给你训,参数有啥呢,我来简单讲讲,比如type='IterBasedRunner',什么意思,就是你要循环的轮次方式按照iteration还是epoch,
也可以type='EpochBasedRunner',后面就变成max_epoch就行。
checkpoint_config = dict(by_epoch=False, interval=2000)
#这句话也很重要,就是告诉runner你要多久保存一次模型, by_epoch可以选,True了就相当于按epoch进行保存,False了就是按iteration保存
evaluation = dict(interval=2000, metric='mIoU')
#这个就是问你多久验证一回,咱们也知道,训个几轮验证一次是合理的,这也是一个意思,至于metric,那是因为这个项目代码中会判断精度计算方式,你的项目没有就算了。
至此configs文件夹内大概都搞明白了,当然你要对py文件内的每句话搞清楚是干啥的,还得看具体的代码调用其中的参数后是干啥的。(这个我如果有时间还会继续写下去)
2.mmseg文件夹:这个文件夹太重要了,这是整个项目的灵魂,打开会看到
version一般都说的mmcv的版本要求,__init__是将这个文件夹当成模块包可以调用
2.1 apis文件夹存放的接口文件
这里的train.py、test.py可不是训练主代码,这是训练主代码后面接的代码,就是主代码后面就进这个py文件,所以叫个接口文件,类似于你大领导把任务布置了,小领导就是接口,作用就是再细化一下任务细节,然后就到组长了,组长代表啥我一会说,最后到你就是实实在在模型代码了。主代码一般是tools文件夹下的train.py或test.py,备注一下interface.py是demo.py的接口。这玩意我就不一个一个注释了,自己debug看看就知道了,无非训练测试数据的加载,然后优化器加载,lr加载,当然这些加载其实就是把上面说的configs文件夹中base文件夹中的py文件给加进来,所以我说那玩意就是configuration,变高级了而已。

2.2 datasets文件夹
pipeline文件夹就是数据的加载(loader.py)、数据预处理方式加载(compose.py)、数据格式转化(formating.py)、旋转剪切等处理(transforms.py),测试数据预处理(test_time_aug.py)

退出pipeline文件夹剩余的有builder.py文件和其他的(builder.py是雷打不动的,其余的都是自己定义的):builder.py作用比较复杂:大概就是mmcv通过builder来调用其他py文件中的函数,至于到底调用哪个,还得看你configs文件夹中选取的参数是哪个
2.3 models文件夹
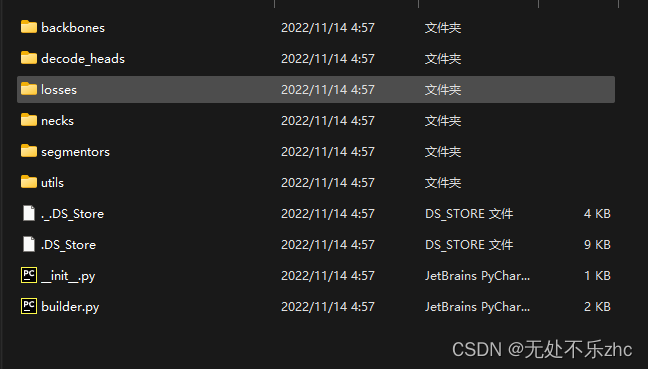
里面有很多子文件夹,都是自己定义的,含义我觉得不用多解释,看文件夹名称就知道里面放的啥,这里值得注意的有2点:1)组长来了,刚才没说的组长,这就是组长,就是segmentors文件夹里的base.py和encoder_decoder.py或者decede_heads,里面放着调用模型的总体说明,你可以看看里面写的东西,它里面绝对写着数据进来后第一步进哪个backbone,然后进neck还是decede_head,这不就是组长更细化任务吗 2)builder.py和datasets文件夹中的builder.py文件作用是一样的
看看组长的segmentors文件夹:
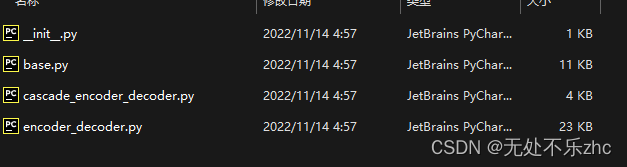
里面encoder_decoder.py就是相当于我刚才说的模型总体说明(cascade_encoder_decoder.py是多卡分布用的,一样的道理),base.py写着如何调用encoder_decoder.py,例如base写着训练时如何进入模型,测试时如何进入模型,也就是进入到encoder_decoder.py里面,然后encoder_decoder.py里面写着先进入哪个backbone然后进入哪个neck或decede_heads,然后每训练一个iteration后又进入base,base又告诉模型训完一个iteration该干啥了,计算精度啦、计算loss啦啥的,循环往复,(至于什么时候训练完一个epoch后进行验证,那就是configs文件夹中schedule文件还记得吗,往上翻翻就知道了,对于用户来说其实就是configs里面定义就好了,而且代码都是固定的,无特殊需要只需要改变数值就行了)
读到这里还记的我让大家记住的type=EncoderDecoder(就是configs/models/xx.py 给的代码注释让大家记住的那个),我在注释中写道会被builder.py调用,builder.py最后就调到encoder_decoder.py中的EncoderDecoder类了,发现每,config里面写的type的名字竟然和类名一样,确实是这样的,每个type其实都对应了一个类,至于代码怎么根据type名找同名的类,后续再说。这是一个例子,这个例子也就同理说明了config中其他type的含义了
3.tools文件夹
这个里面大部分也是固定的,也有很多其实平时也用不到

3.1 convert_datasets文件夹:
其实就是数据的存放方式转换文件夹,比如你下载的数据格式不符合代码要求,你一运行直接自动调好存放格式了就,当然这部分我的理解还是得自己去写?,有待考证吧,因为我直接用自己的数据,相当于直接在mmseg/datsets/loader.py那直接修改了。
剩余的文件只有train.py和test.py重要,一个就是模型训练主文件,一个就是模型测试主文件了,剩余的都是一些辅助性文件,我反正感觉用的不太多,有需要的可以直接自己把名字复制到百度查就行了,一查就出来含义了,毕竟人家写的都比较规范。















 1829
1829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









