







K均值(K-Means)
是聚类算法中最为简单、高效的,属于无监督学习算法。
公式

K 簇类数
u_k 质心
k 簇类中心索引
第i个样本到质心距离的平方
c^(i) 第i个簇类,c^(i)=2 样本分给了第2簇类
模型算法核心
始中心的选择->k-leans++就是一种选择方式,有以随机点的,或者以数据源的
簇类数->不会超过源数据数目,有轮廓函数作为选择
距离类型->欧式距离,曼哈夫距离,取决于p
类均值迭代次数->大部分到达一定程度的迭代就会大大降低效率,肘部定律可知,
存在轮廓函数验证
样例
超市积分与顾客信息分析
特征选择
这个一般取决于数据分析,要拥有正确的数据特征
可视化(各种表)
多数据柱形表
plt.rcParams['figure.figsize'] = (18, 8) # 创建画布大小
plt.subplot(1, 1, 1) # 选取1行1列1号位置图操作
sns.set(style='whitegrid') # 格式位置
sns.displot(data['Annual Income (k$)']) # 数据展示
plt.title('Annual Income', fontsize=20)
plt.xlabel('range of Annual Income')
plt.ylabel('count')
plt.show()
单数据柱形图
plt.rcParams['figure.figsize'] = (15, 8)
sns.countplot(data['Age'], palette='hsv') # 以柱形图显示每个类别的数量
plt.title("Age", fontsize=20)
plt.show()
饼状图
以数据的性别为例
labels = ['Female', 'Male'] # 给标签
size = data['Gender'].value_counts() # 性别统计
colors = ['lightgreen', 'orange'] # 配置颜色
explode = [0, 0.1] # 饼图参数
plt.rcParams['figure.figsize'] = (9, 9) # 创建画布并大小
plt.pie(size, colors=colors, explode=explode, labels=labels, shadow=True, autopct="%.2f%%")
plt.title('Gender', fontsize=20) # 标题
plt.axis('off') # 关闭坐标轴
plt.legend() # 显示标签解析
plt.show()
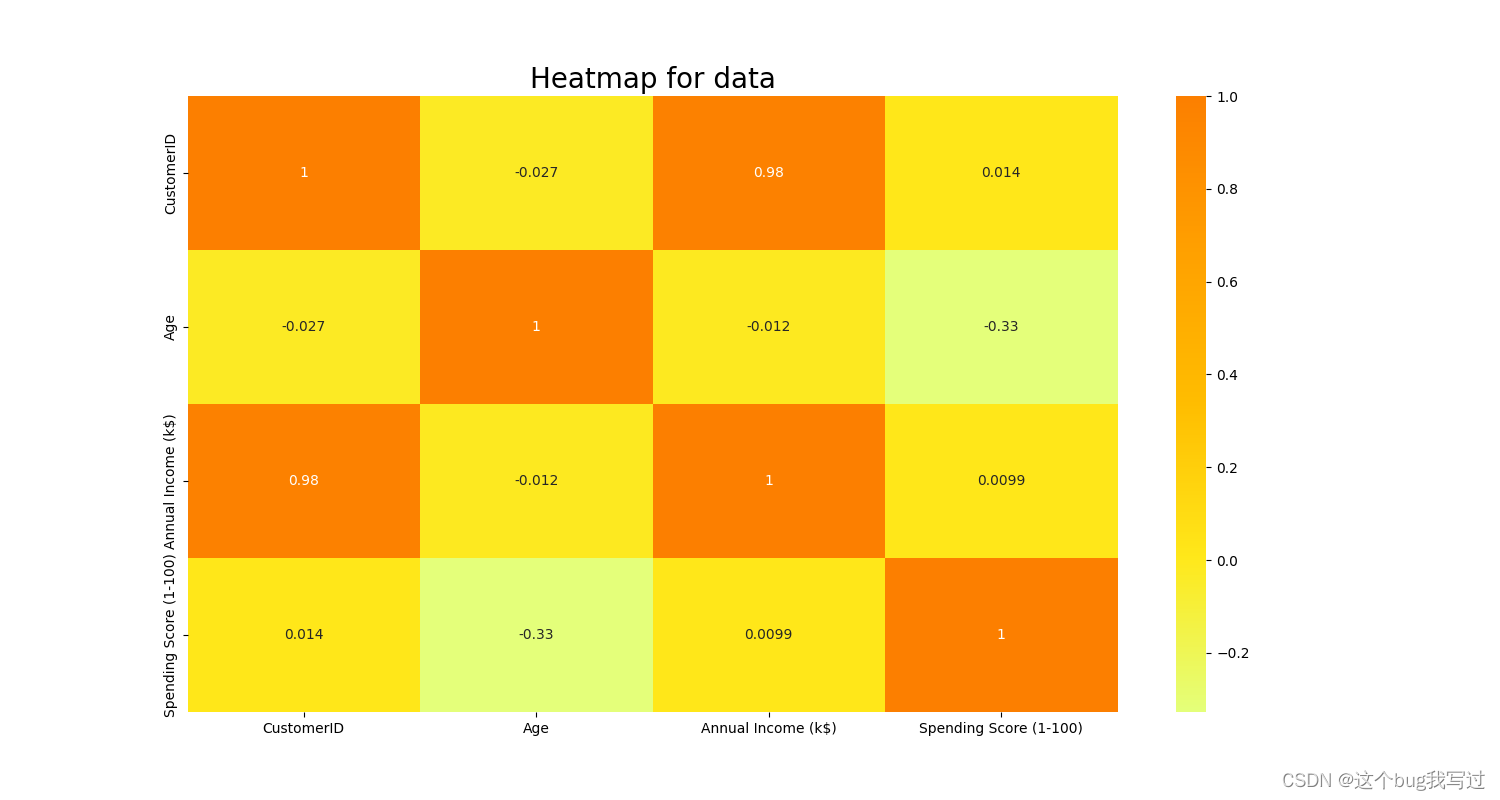
相关系数,热图heatMap
plt.rcParams['figure.figsize'] = (15, 8)
sns.heatmap(data.corr(), cmap='Wistia', annot=True)
plt.title('Heatmap for data', fontsize=20) # 标题
plt.show()
哑铃图
plt.rcParams['figure.figsize'] = (18, 7)
sns.boxenplot(data['Gender'], data['Spending Score (1-100)'], palette='hsv')
plt.title('Gender vs Spending Score', fontsize=20) # 标题
plt.show()
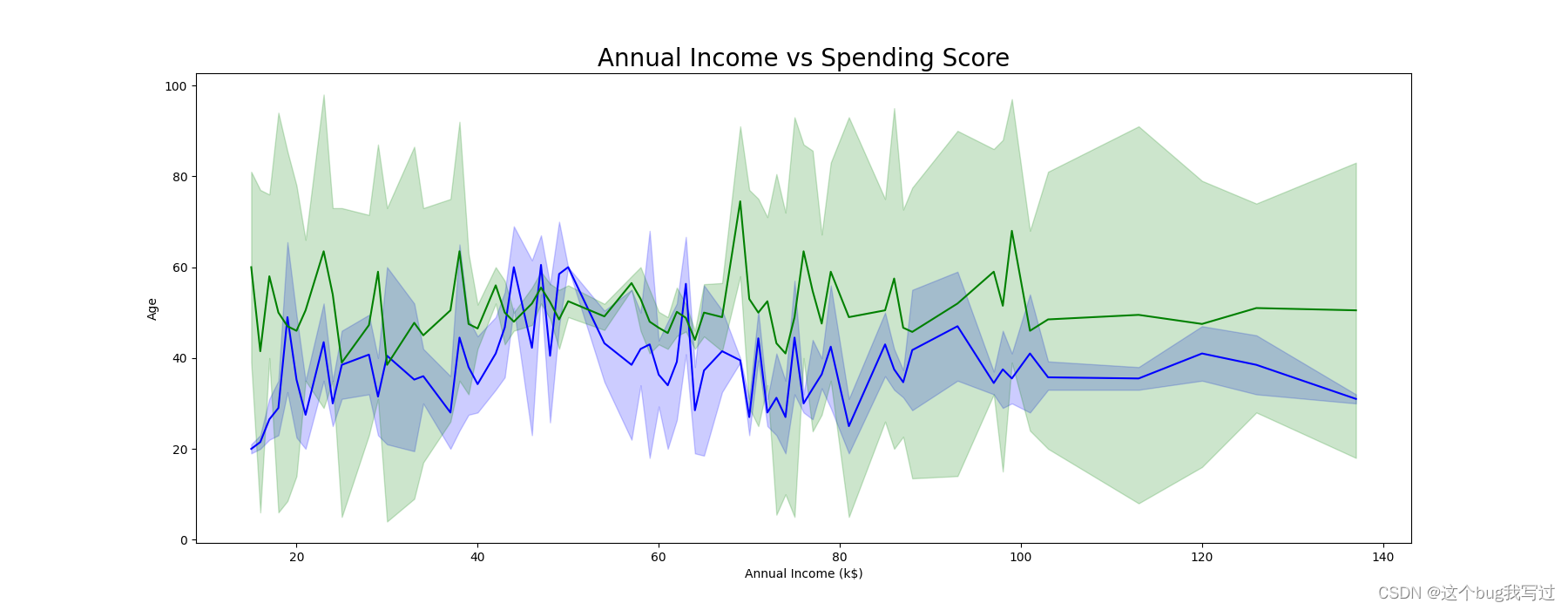
曲线对比图/也可以单线曲线
x = data['Annual Income (k$)']
y = data['Age']
z = data['Spending Score (1-100)']
sns.lineplot(x, y, color='blue')
sns.lineplot(x, z, color='green')
plt.title('Annual Income vs Spending Score', fontsize=20) #
plt.show()
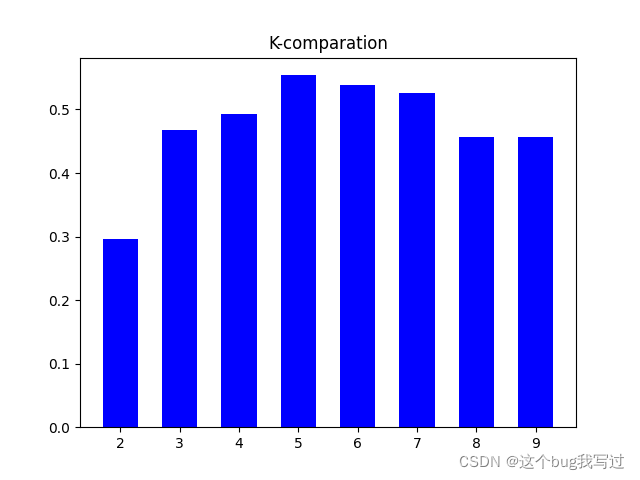
簇类数K
根据轮廓函数选择
不过感觉取决于实质问题的本身
range_values = np.arange(2, 10) # 初始化聚类个数
for i in range_values:
kmeans = KMeans(init='k-means++', n_clusters=i, max_iter=300, n_init=10, random_state=0)
'''
n_clusters: 即我们的k值,一般需要多试一些值以获得较好的聚类效果。
max_iter:最大的迭代次数,一般如果是凸数据集的话可以不管这个值,
如果数据集不是凸的,可能很难收敛,
此时可以指定最大的迭代次数让算法可以及时退出循环。
n_init:用不同的初始化质心运行算法的次数。
由于K-Means是结果受初始值影响的局部最优的迭代算法,
因此需要多跑几次以选择一个较好的聚类效果,默认是10,一般不需要改。
如果你的k值较大,则可以适当增大这个值。
init: 即初始值选择的方式,可以为完全随机选择’random’,
优化过的’k-means++‘或者自己指定初始化的k个质心。
一般建议使用默认的’k-means++’。
algorithm:有“auto”, “full” or “elkan”三种选择。
“full"就是我们传统的K-Means算法, “elkan”是elkan K-Means算法。
默认的"auto"则会根据数据值是否是稀疏的,来决定如何选择"full"和“elkan”。
一般数据是稠密的,那么就是 “elkan”,否则就是"full”。一般来说建议直接用默认的"auto"
'''
kmeans.fit(X)
score = silhouette_score(X, kmeans.labels_, metric='euclidean', sample_size=len(X))
'''
metric为欧式距离的选择
samplesize 为样本数量
'''
# 计算得分
scores.append(score)
# 可视化得分
plt.figure()
plt.bar(range_values, scores, width=0.6, color='b', align='center')
plt.title('K-comparation')
plt.show()
k-means简单实现
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import plotting
import seaborn as sns
from scipy.spatial.distance import cdist
import warnings
warnings.filterwarnings('ignore')
# 默认欧式距离
# 重点在簇类的变换,k的取值
# 初始质心选择原始数据点,不作随机的讨论
class KMeans(object):
# K簇类数目,最大迭代,初始质心
def __init__(self, n_clusters, max_iter, centroids):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = np.array(centroids, dtype=np.float)
# 簇类变换
def fit(self, data):
if self.centroids.shape == (0, ): # 0行矩阵
# random.randint(a,b,c)方法随机生成一个整数,从a到b,生成c个
self.centroids = data[np.random.randint(0, data.shape[0], self.n_clusters), :]
# data.shape[0]为data行数,
# 如果大于数据数的簇类过于奇怪了
# 生成self.n_clusters个即K
# 迭代次数循环,也是簇类质心移动关键
for i in range(self.max_iter):
distances = cdist(data, self.centroids)
# 对距离按由近到远排序,选取最近的质心点的类别作为当前点的分类
c_index = np.argmin(distances, axis=1)
# axis=1每一行取最小值,最后结果保存为一列(100*1的矩阵)
# 对每一类数据进行均值计算,更新质心点坐标
for j in range(self.n_clusters):
# 首先排除掉没有出现在c_index里的类别(即所有的点都没有离这个质心最近)
if j in c_index: # j为0-K
# 选出所有类别是j的点,取data里面坐标的均值,更新第j个质心
self.centroids[j] = np.mean(data[c_index == j], axis=0)
# 布尔索引。axis=0得到一行的数据,将每一列做均值计算,列数不变














 6265
6265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









