







论文地址:https://arxiv.org/pdf/2005.12872
代码地址:https://github.com/facebookresearch/detr
摘要
本研究提出了一种新的方法,该方法将目标检测视为一个直接的集合预测问题。本研究的方法简化了检测流程,有效地消除了对许多手工设计的组件的需求,例如非极大值抑制程序或显式编码本研究对任务的先验知识的锚框生成。新框架(称为DEtection TRansformer或DETR)的主要组成部分是:一个基于集合的全局损失,它通过二分匹配强制产生独特的预测;以及一个transformer编码器-解码器架构。给定一组固定的、小的、学习到的目标查询,DETR推理目标之间的关系和全局图像上下文,以并行方式直接输出最终的预测集合。与许多其他现代检测器不同,本研究的新模型在概念上很简单,不需要专门的库。在具有挑战性的COCO目标检测数据集上,DETR展示了与已建立且高度优化的Faster R-CNN基线相当的准确性和运行时间性能。此外,DETR可以很容易地推广以统一的方式生成全景分割。本研究表明,它显著优于有竞争力的基线。

引言
目标检测旨在为每个感兴趣的对象预测一组边界框和类别标签。目前的目标检测方法通过在一大堆提议区域、锚框或窗口中心上定义替代回归和分类问题来间接解决这一问题。本研究提出了一种直接集合预测方法来绕过这些替代任务,旨在简化这些流程。这种端到端的理念已经在机器翻译或语音识别等复杂的结构化预测任务中取得了显著进展,但在目标检测中尚未实现。以往的尝试或者增加了其他形式的先验知识,或者在具有挑战性的基准测试中,未能证明其竞争力。本研究旨在弥合这一差距。
本研究通过将目标检测视为一个直接的集合预测问题来简化训练流程。本研究采用了一种基于Transformer的编码器-解码器架构,Transformer是一种流行的序列预测架构。Transformer的自注意力机制能够显式地建模序列中元素之间的所有成对交互,这使得这些架构特别适合于集合预测的特定约束,例如消除重复预测。
本研究提出的DETR(DEtection TRansformer)模型可以一次性预测所有对象,并通过一个集合损失函数进行端到端训练,该损失函数在预测对象和真实对象之间执行二分匹配。DETR通过放弃多个编码先验知识的手工设计的组件,例如空间锚点或非极大值抑制,从而简化了检测流程。与大多数现有的检测方法不同,DETR不需要任何定制的层,因此可以在任何包含标准CNN和Transformer类的框架中轻松重现。
与之前关于直接集合预测的大多数工作相比,DETR的主要特点是二分匹配损失和带有(非自回归)并行解码的Transformer的结合。相比之下,之前的工作主要集中在使用RNN的自回归解码上。本研究的匹配损失函数将一个预测唯一地分配给一个真实对象,并且对于预测对象的排列是不变的,因此本研究可以并行地发出它们。DETR在COCO数据集上进行了评估,并与Faster R-CNN基线进行了比较。实验结果表明,本研究的新模型取得了可比的性能。更准确地说,DETR在大型对象上表现出明显更好的性能,这可能是由于Transformer的非局部计算实现的。然而,它在小型对象上的性能较低。本研究期望未来的工作能够改进这方面,就像FPN的开发对Faster R-CNN所做的那样。
论文创新点
本研究的核心创新点在于它将目标检测问题视为一个直接的集合预测问题,从而简化了传统目标检测的流程。具体来说,本研究的创新点体现在以下几个方面:
-
✨ 端到端的目标检测框架: ✨
- 本研究提出了一个名为DETR(DEtection TRansformer)的全新框架,该框架采用端到端的方式进行目标检测,无需像传统方法那样依赖于手工设计的组件,例如非极大值抑制(NMS)或先验框生成。
- 这种端到端的训练方式简化了目标检测流程,减少了人为干预,并允许模型直接学习目标之间的关系。
-
⚙️ 基于Transformer的编码器-解码器结构: ⚙️
- 本研究利用Transformer的编码器-解码器结构来处理目标检测任务。
- Transformer的自注意力机制能够有效地捕捉图像中目标之间的全局关系,从而更好地进行目标检测。
- 与传统的卷积神经网络相比,Transformer能够更好地处理长距离依赖关系,这对于检测图像中的复杂场景非常重要。
-
🎯 集合预测损失函数: 🎯
- 本研究设计了一种基于二分图匹配的集合预测损失函数,该损失函数能够强制模型生成唯一的预测结果,避免重复检测。
- 通过二分图匹配,可以将预测的目标与真实目标进行一一对应,从而优化模型的性能。
- 这种损失函数的设计使得DETR能够直接预测目标集合,而无需像传统方法那样进行后处理。
-
🏆 泛化能力强: 🏆
- 实验结果表明,DETR在具有挑战性的COCO目标检测数据集上取得了与Faster R-CNN相当甚至更好的性能。
- 尤其是在检测大尺寸目标时,DETR的性能明显优于Faster R-CNN。
- 此外,DETR还能够很容易地扩展到全景分割任务,并且取得了优于现有基线的性能。这表明DETR具有很强的泛化能力,可以应用于不同的视觉任务。
-
⚡ 计算复杂度与效率的平衡: ⚡
- 尽管DETR使用了Transformer这种计算量较大的结构,但本研究在模型设计和训练策略上进行了优化,使得DETR在保持高性能的同时,也具有较高的计算效率。
- 这使得DETR在实际应用中具有一定的可行性。
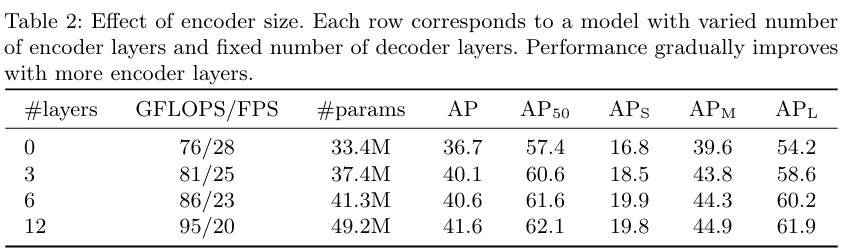
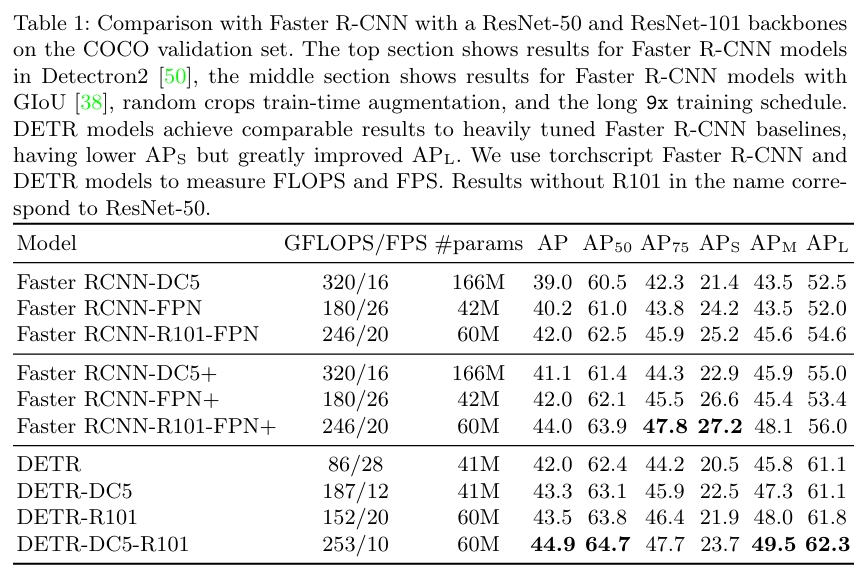
论文实验



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









