






线性回归算法
一、概念介绍
1、线性回归
线性回归是一种广泛使用的统计分析方法,用于建立自变量(输入数据)和因变量(输出数据)之间的线性关系模型。它基于假设该关系可以通过一个线性方程来描述,即
Y
=
a
X
+
b
Y = aX + b
Y=aX+b
,其中Y表示因变量,X表示自变量,a和b表示模型的系数。线性回归的目标是找到最佳的系数a和b,使得模型对观测数据的拟合误差最小化。
线性回归可以用来分析两个或多个变量之间的关系,并进一步进行预测和推断。通过计算实际观测值和回归模型的残差(即观测值与模型预测值之间的差异)来评估模型的拟合程度。常见的评估指标包括均方误差(MSE)、**决定系数(R-squared)**等。
线性回归适用于数据具有线性关系的情况,但在实际应用中可能存在非线性关系。此时,可以尝试对数据进行变换,如对自变量或因变量进行平方、对数等操作,来拟合更复杂的非线性模型。
2、平均绝对误差(MAE)
在线性回归中,MAE代表均值绝对误差(Mean Absolute Error)。它是用来衡量预测值和实际值之间差异程度的一种指标。MAE的计算方法是将每个数据点的绝对误差相加并求平均。
具体地,给定一组预测值和相应的实际值,MAE通过以下公式计算:
M
A
E
=
(
1
/
n
)
∗
Σ
∣
预测值
−
实际值
∣
MAE = (1/n) * Σ|预测值 - 实际值|
MAE=(1/n)∗Σ∣预测值−实际值∣
其中,n表示样本数量,Σ表示求和运算。MAE表示平均每个样本的预测误差的大小。
与均方误差(Mean Squared Error, MSE)相比,MAE不会将误差进行平方处理,因此更加注重误差的绝对值。这使得 MAE 对于异常值(outliers)更加鲁棒。此外,MAE的值在实际情况下更容易直观解释。
在线性回归中,我们通过最小化MAE来优化模型,以尽量减少预测值和实际值之间的差异。较小的MAE值表示模型的预测效果更好。
3、均方误差(MSE)
在线性回归中,MSE代表均方误差(Mean Squared Error)。它是用来衡量预测值和实际值之间差异程度的一种指标。MSE的计算方法是将每个数据点的误差平方相加并求平均。
具体地,给定一组预测值和相应的实际值,MSE通过以下公式计算:
M
S
E
=
(
1
/
n
)
∗
Σ
(
预测值
−
实际值
)
2
MSE = (1/n) * Σ(预测值 - 实际值)^2
MSE=(1/n)∗Σ(预测值−实际值)2
其中,n表示样本数量,Σ表示求和运算。MSE表示平均每个样本的预测误差的平方大小。
MSE相比于MAE,将误差平方处理,因此对于较大的预测误差更加敏感。这意味着MSE会受到异常值的影响,因为异常值的误差平方较大。
在线性回归中,我们通过最小化MSE来优化模型,以尽量减少预测值和实际值之间的差异。较小的MSE值表示模型的预测效果更好。
4、决定系数(R²)
在线性回归中,决定系数(Coefficient of Determination)用于评估线性回归模型对目标变量的解释能力。它表示模型能够解释实际数据中变异的程度。
决定系数的取值范围在0到1之间。当决定系数接近1时,表明模型能够很好地解释目标变量的变异,预测效果较好。当决定系数接近0时,说明模型无法有效解释目标变量的变异,预测效果较差。
决定系数的计算方法是通过将模型预测值与目标变量的实际值的离差平方和(SSR)除以总离差平方和(SST)来得到:
决定系数
=
1
−
(
S
S
R
/
S
S
T
)
决定系数 = 1 - (SSR / SST)
决定系数=1−(SSR/SST)
其中,SSR表示回归平方和,模型预测值与目标变量平均值的离差平方和;SST表示总平方和,目标变量与其平均值的离差平方和。
决定系数的值越接近1,表示模型能够很好地解释目标变量的变异,预测效果较好。然而,如果决定系数过高,可能会出现过拟合的情况。因此,在使用决定系数时,需要结合其他指标进行综合评估,并根据具体问题进行解释和判断。
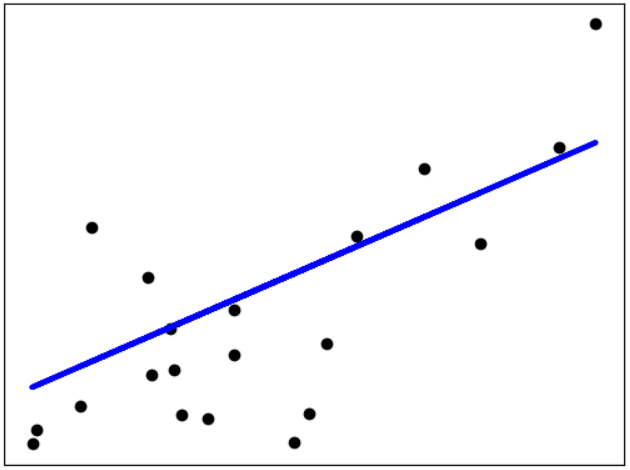
二、sklearn的线性回归示例
# Code source: Jaques Grobler
# License: BSD 3 clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients
print("Coefficients: \n", regr.coef_)
# The mean squared error
print("Mean squared error: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred))
# The coefficient of determination: 1 is perfect prediction
print("Coefficient of determination: %.2f" % r2_score(diabetes_y_test, diabetes_y_pred))
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color="black")
plt.plot(diabetes_X_test, diabetes_y_pred, color="blue", linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
Out:
Coefficients:
[938.23786125]
Mean squared error: 2548.07
Coefficient of determination: 0.47















 8544
8544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









