







目录
四、《Mobility-Aware Cluster Federated Learning in Hierarchical Wireless Networks》
Part 1.Mobility
一、《Mobility-Aware Cooperative Caching in Vehicular Edge Computing Based on Asynchronous Federated and Deep Reinforcement Learning》——问题场景:车辆移动性、异步联邦、边缘缓存内容预测
从车辆移动性考虑,采用异步FL提升聚合模型的精度,将车辆位置、传输速率作为权重融入聚合公式;从传输延迟的角度,预测热门内容,基于DRL将其存储到本地或邻居RSU上,减少与MBS、云服务器的通信。
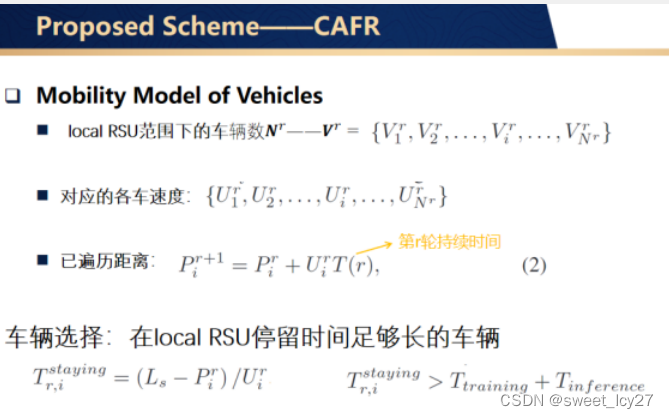
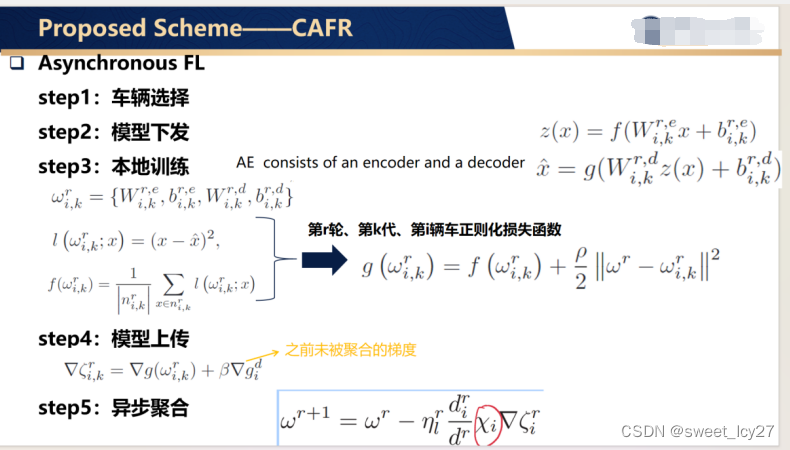
节点选择:在RSU覆盖范围中停留的时间>训练时间+介入时间;AE(auto encoder)提取content的潜在特征,训练AE中的权重和偏置项。异步联邦聚合方式,融入车辆移动性相关权重。
热门内容预测:评分矩阵—AE—>提取潜在特征后的重构矩阵,结合各车节点的个人信息形成个人信息+重构评分矩阵——>计算余弦相似度,选出最大的K个作为该车邻居车节点,组合各邻居车节点的评分矩阵作为该车的interested content;传输给RSU,RSU将自己覆盖范围下的车节点interested content整理得到popular content:Fc个
基于DRL的联合缓存方案:state、action、reward、nextstate(s(t), a(t), r(t), s(t + 1))判断各RSU中、及其邻居RSU中的缓存内容是否需要置换。
缺点:1、增加数据质量融入车辆选择策略中;
2、没有考虑恶意节点带来的隐私问题,可引入相关的隐私保护机制。
优点:多方面考虑了车辆的移动性对FL模型的影响:
1、将车辆的位置、速度作为车节点选择的依据
2、将车辆的移动性融入聚合权重
二、《Blockchain Empowered Asynchronous Federated Learning for Secure Data Sharing in Internet of Vehicles》——分散型FL;BC+FL架构双重验证机制;车辆移动性;声誉机制;异步联邦
混合区块链的双重验证机制保障联邦过程的鲁棒性和隐私性,基于深度强化学习的节点选择保障所选节点的质量对全局模型的贡献最大。总体上仍然采用联邦学习的框架,但在DAG(车节点运行)中采取了异步的本地聚合,减少了传统FL同步聚合方式具有的延迟较高问题。

在节点移动性上,采用深度学习模型

1、双重验证机制,保障了联邦学习模型更新参数的合法性,增强了联邦过程的鲁棒性
2、异步联邦学习,减少了等待本地训练参数上传在同步聚合的时延,符合车联网对实时性的高要求。
3、基于DDPG的节点选择算法,不仅更全面地(通信状态、计算资源、本地训练效果)考虑了节点的质量,同时融入了声誉机制,对于恶意节点的防御性更强。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











