






Loss Functions的使用大概有两点:
1.可以计算我们实际输出和目标之间的差距;2.为我们更新输出提供一定的依据(反向传播)我们可以通过loss来不断的训练神经网络,提高精度。
目录
一、理解Loss Functions
Loss functions是用来干什么的呢。
比如我们考试的目标target是30,20,50.但是我们实际output才10,10,10.
这时候loss=(31-10)+(20-10)+(50-10)=70,
loss的意思就是target与output的差距,然后根据差距,来指导output去靠近target,
loss是越小越好的。
要根据loss去提高output,也就是通过loss来不断的训练,提高精度。
作用:
1.可以计算我们实际输出和目标之间的差距
2.为我们更新输出提供一定的依据(反向传播)
二、常用的函数
1.L1Loss
1.1 L1Loss的官方文档
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
含义:创建一个标准,用于测量输入 xx 和目标 yy 中每个元素之间的平均绝对误差 (MAE)。
xx 和 yy 是任意形状的张量,每个都有 nn 个元素。
求和运算仍然对所有元素进行运算,并除以 nn。
如果设置 reduction = 'sum',则可以避免除以 nn。
支持实值和复值输入。
计算公式:

Shape:
input:(*)(∗),其中 *∗ 表示任意数量的维度。
target:(*)(*),与输入的形状相同。
output:标量。 如果减少是“无”,则 (*)(*),与输入的形状相同。
1.2 L1Loss实例练习
代码如下:
import torch
from torch.nn import L1Loss
input = torch.tensor([1, 2, 3], dtype=torch.float32)
target = torch.tensor([1, 2, 5], dtype=torch.float32)
L1loss = L1Loss()
output = L1loss(input, target)
print(output)
L1loss2 = L1Loss(reduction = 'sum') #求和,不求平均值
output = L1loss2(input, target)
print(output)
输出结果:
tensor(0.6667)
tensor(2.)
2.MSELoss
2.1 MSELoss官方文档
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
Creates a criterion that measures the mean squared error (squared L2 norm) between each element in the input xx and target yy.(平方差)
XX和YY是任意形状的张量,每个NN元素总计。
平均操作仍在所有元素上运行,并除以NN。
如果一个设置reduction='sum',则可以避免NN的划分。
计算公式:
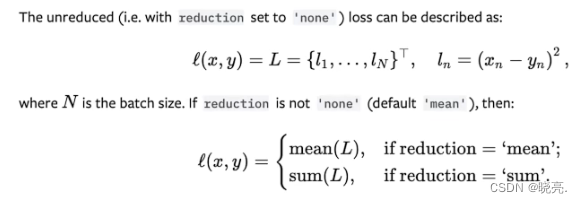
Shape:
input:( *)( *),其中 * *表示任何数量的尺寸。
target:(*)(*),与输入相同。
2.2 MSELoss实例练习
代码如下:
import torch
from torch.nn import L1Loss, MSELoss
input = torch.tensor([1, 2, 3], dtype=torch.float32)
target = torch.tensor([1, 2, 5], dtype=torch.float32)
#MSELoss的用法
mseloss = MSELoss()
output = mseloss(input, target)
print(output)
mseloss2 = MSELoss(reduction='sum')
output = mseloss2(input, target)
print(output)
输出结果:
tensor(1.3333)
tensor(4.)3. CrossEntropyLoss
3.1 CrossEntropyLoss官方文档
torch.nn.CrossEntropyLoss(weight=None,
size_average=None,
ignore_index=- 100,
reduce=None,
reduction='mean',
label_smoothing=0.0)
This criterion computes the cross entropy loss between input and target.计算输入和目标之间的交叉熵损失。
It is useful when training a classification problem with C classes. If provided, the optional argument weight should be a 1D Tensor assigning weight to each of the classes. This is particularly useful when you have an unbalanced training s
计算公式:

exp(x)表示的是e的x次方,x可以是一个函数
Shape:
Input: Shape (C)(C), (N, C)(N,C) or (N, C, d_1, d_2, ..., d_K)(N,C,d1,d2,...,dK) with K \geq 1K≥1 in the case of K-dimensional loss.
Target: If containing class indices, shape ()(), (N)(N) or (N, d_1, d_2, ..., d_K)(N,d1,d2,...,dK) with K \geq 1K≥1 in the case of K-dimensional loss where each value should be between [0, C)[0,C). If containing class probabilities, same shape as the input and each value should be between [0, 1][0,1].
Output: If reduction is ‘none’, same shape as the target. Otherwise, scalar.
3.2 CrossEntropyLoss实例练习
代码如下:
import torch
from torch import nn
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3)) #batch size为1,通道为3
loss_cross = nn.CrossEntropyLoss()
output = loss_cross(x, y)
print(output)
输出结果:
tensor(1.1019)
output=-0.2+ln(exp(0.1)+exp(0.2)+(exp(0.3)) = 1.1019

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











