






optimizer.step()是大多数优化器支持的简化版本。 一旦使用例如计算梯度,就可以调用该函数。 backward()反向传播。
2. How to use an optimizer(如何使用优化器)
2.2 Per-parameter options(每个参数选项)
2.3 Taking an optimization step(采取优化步骤)
一、 官方文档
1. 什么是torch.optim?
torch.optim 是一个实现各种优化算法的包。 最常用的方法都已经支持了,接口也足够通用,以后也可以轻松集成更复杂的方法。
2. How to use an optimizer(如何使用优化器)
要使用 torch.optim,必须构造一个优化器对象,该对象将保持当前状态并根据计算的梯度更新参数。
2.1 Constructing it(构建它)
要构造一个优化器,你必须给它一个包含要优化的参数(都应该是变量)的迭代。 然后,您可以指定优化器特定的选项,例如学习率、权重衰减等。
Note:
如果您需要通过 .cuda() 将模型移动到 GPU,请在为其构建优化器之前执行此操作。 .cuda() 之后的模型参数将与调用之前的对象不同。
通常,在构建和使用优化器时,应该确保优化的参数位于一致的位置。
2.2 Per-parameter options(每个参数选项)
不会,后面补充。
2.3 Taking an optimization step(采取优化步骤)
所有优化器都实现了一个更新参数的 step() 方法。 它可以通过两种方式使用:
第一种是optimizer.step()
这是大多数优化器支持的简化版本。 一旦使用例如计算梯度,就可以调用该函数。 backward()反向传播。
for input, target in dataset:
optimizer.zero_grad() #这是将上一步求得每个参数对应的梯度进行清0,以防上一步的梯度造成影响
output = model(input) #数据经过神经网络得到一个输出
loss = loss_fn(output, target) #计算出losss,得到输出与目标之间的误差
loss.backward() #反向传播,得到每一个要更新的参数的梯度
optimizer.step() #调用optimizer.step,每一个参数都会根据反向传播得到的梯度进行优化
第二种是optimizer.step(closure)
一些优化算法,如 Conjugate Gradient 和 LBFGS 需要多次重新评估函数,因此您必须传入一个允许它们重新计算模型的闭包。 闭包应该清除梯度,计算损失并返回它。
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)
二、torch.optim的算法
2.1 torch.optim.Optimizer(params, defaults)
这是优化器的基本结构,每个优化器类都有着两个参数。
参数:
params (iterable) – an iterable of torch.Tensor s or dict s. Specifies what Tensors should be optimized.
( 可迭代的 torch.Tensor 或 dict 。 指定应该优化哪些张量。)
defaults – (dict): a dict containing default values of optimization options (used when a parameter group doesn’t specify them).
(包含优化选项默认值的字典(在参数组未指定它们时使用)。)
2.2 Adadelta
torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
params:参数,需要将模型的参数输入
lr:学习速率,即learning rate
不同的优化器,只有params和lr前面两个参数是一样的,其他的参数是不一样的。
2.3 使用torch.optim.SGD进行学习
代码如下:
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
#调用CIFAR10数据集
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
#使用dataloader数据迭代器
dataloader = DataLoader(dataset, batch_size=1)
#搭建神经网络,这个Test网络就是CIFAR10数据集的网络
class Test(nn.Module):
def __init__(self): #初始化
super(Test, self).__init__()
self.seq = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.seq(x)
return x
#创建网络
test = Test()
#使用nn.CrossEntropyLoss
loss_cross = nn.CrossEntropyLoss()
optim = torch.optim.SGD(test.parameters(), lr=0.01)
for data in dataloader:
imgs, targets = data
optim.zero_grad() #上一步求得的参数归零
output = test(imgs)
result_loss = loss_cross(output, targets)
result_loss.backward()
optim.step()
print(result_loss)

运行一次backward,grad梯度值就计算出来了

运行optim.step().会发现grad梯度改变了
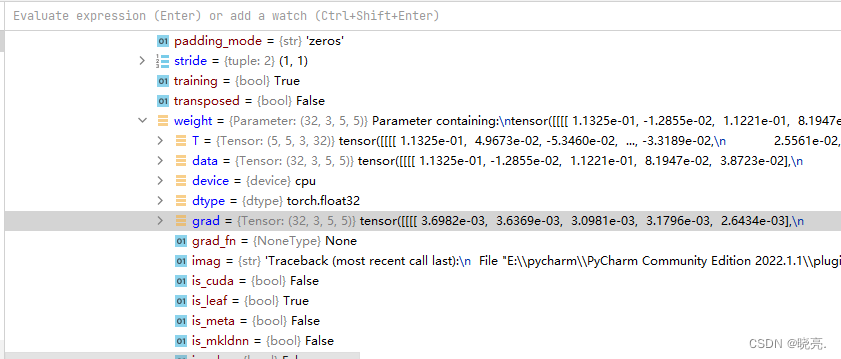
运行optim.zero_grad(),grad梯度又清零了

如此往复。让我们的Loss变小。
输入print(result_loss),来查看一下代码运行的结果
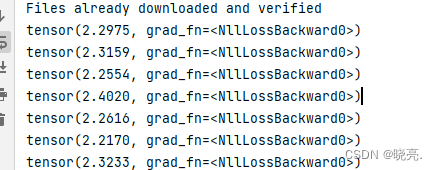
在每一个节点上,loss值好像并没有减小,那是因为dataloder的数据在这个神经网络中都只看了一遍,
一般情况下,我们需要对数据进行很多轮的学习,这里才学习了一次
故,可以使用for循环,来进行多轮学习
代码如下:
loss_cross = nn.CrossEntropyLoss()
optim = torch.optim.SGD(test.parameters(), lr=0.01)
for epoch in range(20): #epoch就是一轮一轮的意思
running_loss = 0.0 #为了方便观察,用这个查看每一轮中loss值为多少
for data in dataloader:
imgs, targets = data
optim.zero_grad() #上一步求得的参数归零
output = test(imgs)
result_loss = loss_cross(output, targets)
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print(running_loss)输出结果:
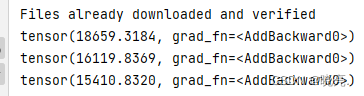
可以看见,Loss值在变小。

















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











