







系列文章目录
第十七章 Python 机器学习入门之基于内容过滤算法
目录
一、协同过滤与基于内容过滤对比
协同过滤与基于内容过滤对比
Collaborative filtering vs content-based filtering
对于协同过滤,一般时我们根据用户给出的评分,算法会根据用户的评分,给用户推荐新的东西。(对于缺少信息的时候,比如一个用户只对很少电影进行评分,该给他推荐什么电影;或者有一部新电影没有人评分过,该向哪些用户推荐它。对于这些问题,使用协同过滤可能会出现预测不准的情况。)
对于基于内容过滤,它是基于内容的过滤需要来决定向我们推荐什么东西的算法,它会根据用户的特征给用户推荐东西。
换句话说,它需要每个用户都有一些特征,以及每个项目的一些特征,它使用这些特征来尝试决定哪些项目和用户可能是很好的匹配。
使用基于内容过滤算法,它仍然有用户对某些项目进行评分的数据,所以它会像协同过滤一样,使用r(i ,j)表示用户j是否对项目i进行评分;y(i,j)用户j对项目i的评分是多少。不同的是基于内容过滤算法可以很好的利用用户和项目的特征来进行匹配。
比如用户有年龄、性别、国家等特征;电影有上映年份、类型、平均评分等特征。
用户特征和电影特征的大小可能有很大差别,那么我们如何将用户和项目的特征进行匹配呢?
基于内容过滤算法中,我们可以利用算法来学习匹配用户和项目,这里是用户和电影。
下面是预测用户j 对电影 i的评分: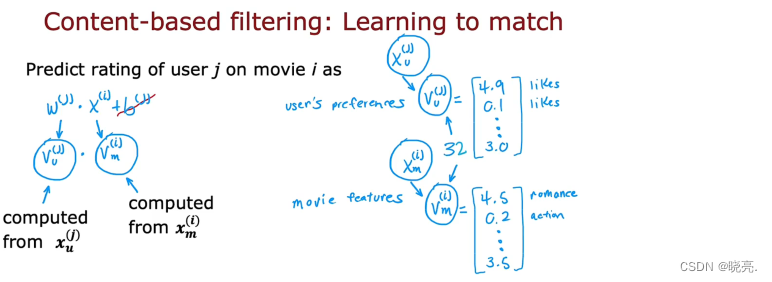
基于内容过滤算法的预测公式不需要b(j) , 这并不会影响算法的性能。
然后将w(j) 改为了v_u(j) 表示用户 ;将 x(i) 改为了 v_m(i) 表示电影中的项目
其中 v_u(j)、v_m(i) 向量都是根据用户的特征和电影的特征计算过来的。
前面说了用户特征和电影特征大小可能有很大差别,于是我们计算处理v_u(j)、v_m(i) 这两个大小是一样的大的,然后进行点乘。
二、 基于内容过滤的深度学习方法
基于内容的过滤算法就是使用深度学习
回到前面,我们有用户的许多特征年龄、性别、国家等x_u, 我们要利用这些特征计算向量v_u
我们有电影的许多特征上映年份、类型等x_m, 我们要利用这些特征计算向量v_m
我们怎么去计算v_u 和 v_m 呢?
可以使用神经网络。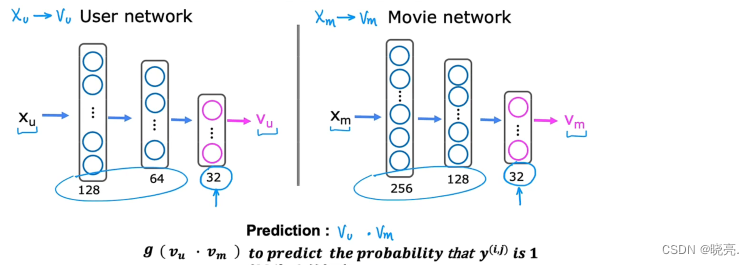
使用两个神经网络将计算出来v_u 和 v_m,再进行 点乘就可以进行预测。
我们现在是对电影评分进行预测,如果有二进制标签,标签y对用户来说是是否喜欢一个项目,我们也可以修改算法来输出,使用sigmiod 函数来进行预测y(i,j)为1 的概率。
这个网络模型每一层都有一组神经网络参数,如何去训练用户网络和电影网络的这些参数?
我们可以构造一个代价函数J, 它非常类似于协同过滤中的代价函数,
有了这个代价函数就可以使用梯度下降或者一些其他的优化算的来调整所有的参数,来使得代价函数尽可能的小,如果想要对这个模型进行正则化,我们也可以添加 神经网络正则化项,来使得所有的参数都很小。
在我们有了这个模型后,还可以使用它来寻找类似的物品,这类似于协同过滤特征,帮助找到类似的项目。
例如我们想找到其他类似的电影该怎么做?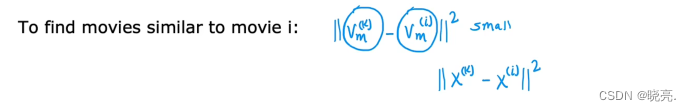
向量v_m(i) 描述了电影 i,如果要找到类似的电影,可以寻找其他电影的k的向量,然后计算平方距离。
当平方差较小时,说明两者较为相近。使用这个方法可以找到与给定项目相似的项目。
三、从大型目录中推荐
今天的推荐系统可能需要从数千或数百万甚至更多的目录中挑选少数物品进行推荐,如何有效地做到这一点?
一般都分为两个步骤,检索步骤和排名步骤。
就是在检索步骤期间生成大量的候选项目列表,这些候选项目试图涵盖很多我们试图向用户推荐的内容。
在检索的过程中,如果包含了很多用户可能不喜欢的项目,在排名步骤中将微调 并选择最好的项目推荐给用户。
检索步骤的目的是确保广泛的覆盖范围,拥有足够多的电影,
然后我们将获取检索步骤中检索到的所有项目,并将它们组合成一个列表,删除重复项和删除用户已经完成的物品(看过的电影项)和我们不想再次推荐给他们的物品。
第二步是排名步骤,在排名步骤中,我们将获得检索步骤中检索到的列表,
这可能是数百部电影,然后使用学习模型对它们进行排名,也就是将用户特征向量和电影特征向量输入到图中的神经网络中,对于每个用户电影对进行预测评分。基于此,我们现在拥有所有100多部电影(用户最有可能给予高评价的电影)。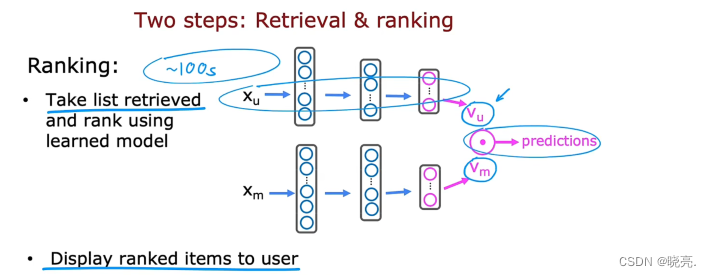
然后,我们可以根据自己认为用户将给予最高评价的内容向用户显示项目的排名列表。
一项额外的优化,如果我们所有电影都计算了v_m, 我们需要做的就是进行图中在上部分神经网络上单次计算v_u,
然后将v_u 和 v_m 点乘得到结果,作为我们在检索步骤中检索到的电影。
如果检索步骤 检索出100部电影,我们需要做的决定之一是在这100部电影的检索步骤中我们要检索多少项,以便进入更准确的排名步骤。
在检索步骤中,检索更多项目 往往会导致更好的性能,但是该算法最终会在分析或优化检索多项之间的权衡时变得更慢。
总结
基于内容过滤算法的使用比协同过滤算法使用的更频繁,多用于推荐系统中,基于内容过滤算法用到了神经网络,其中检索步骤和排名步骤两个步骤非常重要。检索物品组成列表,然后使用算法进行排名,最后再推荐给用户。

















 1980
1980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











