







注:本篇博客为 MySql 表操作指令2 ,若要学习 MySql 基本指令,可通过作者 博客 进行学习;若要进一步练习,可结合 操作1 后,根据 博客 MySql 实例 进行练习!
增删查改–进阶
本篇博客主要从四个部分,即 键值约束与扩展属性、分组查询、ER关系图+三大范式、多表联查 进行展开!
键值约束与扩展属性
键值约束:约束表中指定字段的数据必须符合某种规则
种类:
- 非空约束:
NOT NULL– 约束指定字段的数据不能为NULL - 唯一约束:
UNIQUE– 约束指定字段的数据不能出现重复 - 主键约束:
primary key– 约束字段数据 非空且唯一,一张表只有一个主键
注:not null unique约束在某种程度上相当于primary key约束 - 外键约束:
foreign key– 约束指定字段数据受父表数据约束。其格式为
foreign key (字段名) references 主表(列)
如
foreign key (class_id) references class(id)
- 默认值:
default– 为指定字段设置默认值
此处若要用默认值,插入时需得 不给对应字段插入数据 - 自增属性:
AUTO_INCREMENT– 整形字段数据自动+1 ,只能用于主键 - CHECK约束:使用时不报错,但也没用
案例:建立一个班级表与学生表,并将班级表中的 id 与学生表中的 class_id 相关联。
程序如下
create table if not exists class(
id int primary key comment '序号', -- primary key 要求非空且唯一,所以插入时不能将其设为空,同时因为其没有默认值所以必须输入
name varchar(32) comment '姓名' -- 默认为空,可以在输入时不输入该处的值
);
create table if not exists student(
id int primary key auto_increment comment '序号', -- 虽然为主键,但其有自增属性,所以输入时可以为空
snum int not null unique comment '学号', -- 非空且唯一,即输入时不能为空
name varchar(32) comment '姓名', -- 可以为空
class_id int comment '班级号',
sex varchar(1) default '男', -- 此处默认为 男,即若有输入则为输入值,若未输入则为默认值
foreign key (class_id) references class(id) -- 外键约束,简单说 class_id 受 class表 中 id 数据的约束
);
结果显示如下:

分组查询
分组查询:以表中某一字段作为分段依据进行数据统计的分组查询。所用关键字为 group by 字段 having 条件,字段为表中包含的字段,后面的 having 条件 则实现的是根据条件对表中数据进行筛选。
分组查询的字段只能是 分组依据字段 以及 聚合函数
如:select role, sum(salary) from emp group by role; -- 以角色进行分组查询
分组查询中不能使用 where 字段,在分组查询若要进行条件过滤可以用 having 进行查看
聚合函数:
sum(field) 统计指定字段的和,
max(field) 统计指定字段的最大值,
min(field) 统计指定字段的最小值,
avg(field) 统计指定字段的平均值,
count(*) 统计数据条数....
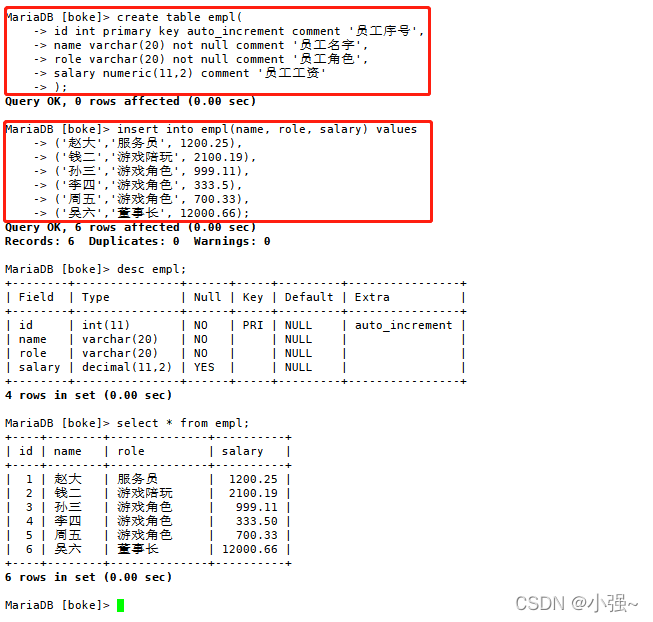
案例:创建一个员工薪资表,具体代码如下
create table empl(
id int primary key auto_increment comment '员工序号',
name varchar(20) not null comment '员工名字',
role varchar(20) not null comment '员工角色',
salary numeric(11,2) comment '员工工资'
);
insert into empl(name, role, salary) values
('赵大','服务员', 1200.25),
('钱二','游戏陪玩', 2100.19),
('孙三','游戏角色', 999.11),
('李四','游戏角色', 333.5),
('周五','游戏角色', 700.33),
('吴六','董事长', 12000.66);
创建结果如下
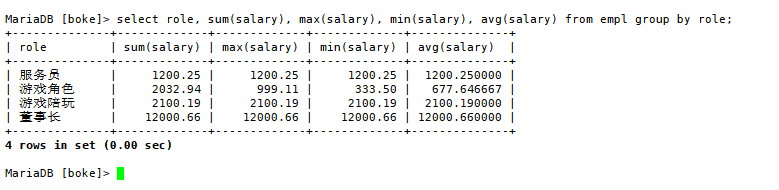
问题1:以员工角色进行薪资的和、最大值、最小值和平均值分类,代码为
select role, sum(salary), max(salary), min(salary), avg(salary) from empl group by role;
结果如下
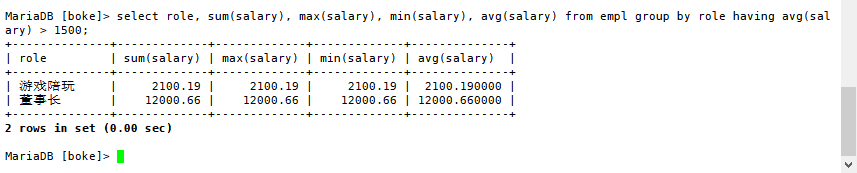
问题2:查找员工平均薪资大于1500的员工角色,并输出他的相关值,代码如下
select role, sum(salary), max(salary), min(salary), avg(salary) from empl group by role having avg(salary) > 1500;
结果如下
问题3:求解员工个数
select count(*) from empl;
结果如下

ER关系图+三大范式
ER关系图
ER关系图:
-
一对一:如一个学生只有一个学生证(各项信息),能够唯一标识学生的字段就是主键;
-
一对多:向多的一方添加一个少的一方的某信息作为外键,可将两方联系起来;
-
多对多:双方并不能直接关联,通常创建一个第三方实体进行中转,比如创建一个中间表包含两个实体的ID,通过中间表将两个实体关联。
如 学生可以学很多课程,一个课程有很多学生上,所以可以建立第三方实体 学生课程表,其将学生与课程放在一起,避免了直接相关联。
三大范式
三大范式:数据库表设计的三大范式
1nf:表中每个字段都必须具有不可分割原子特性;
第一范式是其他范式的前提,并且若不遵循第一范式会导致按照某个非原子字段进行查询时降低效率
2nf:表中每个字段都应该与主键完全关联,而不是部分关联;
若不遵循第二范式,则表中有可能会存在大量冗余数据
3nf:表中每个字段都应该与主键直接关联,而不是间接关联
注意:删除关联表时,需要先删除子表,才可删除父表!!! drop table tbname;
多表联查
多表联查:将多张表合在一起进行查询。将多张表合在一起,常利用 笛卡尔积
一般合在一起后,须先进行条件过滤,防止过多内容影响效率
连接方式:内连接 + 外连接(左连接,右连接)
内连接
内连接:取数据交集 inner join – inner可忽略
此处条件过滤可以用 on, 此处这个on是联系两个表的数据的条件过滤符
将两张表连起来取交集,如
select test2.name , test1.name from test2 inner join test1 on test2.class_id=test1.id;
上述语句是寻找 test2 与 test1 中 test2.class_id 与 test1.id相等时对应的 name。
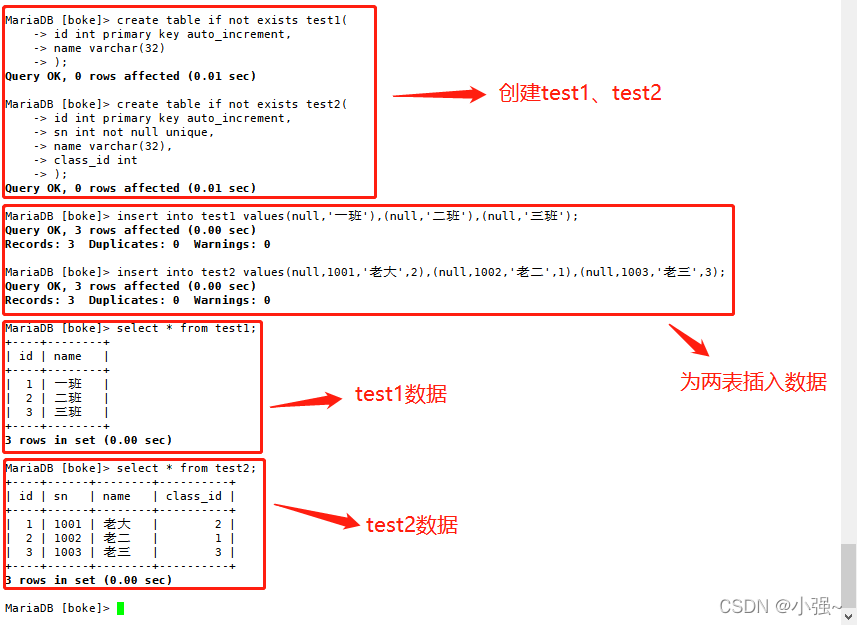
案例:创建 test1 与 test2 表,然后完成一些要求。
创建表格代码如下
create table if not exists test1(
id int primary key auto_increment,
name varchar(32)
);
create table if not exists test2(
id int primary key auto_increment,
sn int not null unique,
name varchar(32),
class_id int
);
为每个表格插入一些数据,
insert into test1 values(null,'一班'),(null,'二班'),(null,'三班'); --为test1插入数据
insert into test2 values(null,1001,'老大',2),(null,1002,'老二',1),(null,1003,'老三',3); --为test2插入数据
结果如下
问题1:两表进行 内连接
select test2.name , test1.name from test2 inner join test1;
结果为

问题2:寻找 test2 与 test1 中 test2.class_id 与 test1.id相等时对应的 name
select test2.name , test1.name from test2 inner join test1 on test2.class_id=test1.id;
结果为

外连接
外连接:左连接 + 右连接
- 左连接:以左表作为基表在右表中查询符合条件的数据进行连接
left join,如
select test2.name , test1.name from test2 left join test1 on test2.class_id=test1.id;
是以程序中的左表与右表进行连接,比如上述程序是以 test2 为基表在 test1 中查询符号要求的数据
结合上面的表,其结果为

- 右连接:以右表作为基表在左表中查询符合条件的数据进行连接
right join,如
select test2.name , test1.name from test2 right join test1 on test2.class_id=test1.id;
是以程序中的右表与左表进行连接,比如上述程序是以 test1 为基表在 test2 中查询符号要求的数据
结合上面的表,其结果为

子查询
在子查询中,常见的是多条 sql 语句嵌套查询,如一条 sql 的查询条件是另一条 sql 的执行结果。
子条件in:用于对一个集合进行判断,如
select name from student where classes_id in (select classes_id from student where name='不想毕业');
上述程序,是先获取 name='不想毕业' 在 student 中的 classes_id 结果集,然后逐条在结果集中进行判断。
子条件 in常使用于匹配结果较少的情况
(注意:嵌套时,如果被嵌套内容求出的值为一个时可以用 = 也可以用 in, 但如果是多个值时只能用 in !!!)
子条件exists:用于判断后面的语句是否为真,为真则执行前面的语句;或者说先取出前面的信息在后面的信息中判断是否为真,为真则继续处理。如
select * from score where exists (select score.id from course where (name='语文' or name='英文') and course.id = score.course_id);
上面语句即是取出一条成绩信息,然后表中再次查询是否具有后面条件的结果。
子条件exists常适用于匹配结果很多的情况
合并查询
合并查询:将多条 sql 语句的执行结果合并在一起,会默认去重。其所用关键字为 union 。
union all:全部合并,将多个结果直接合在一起,不进行去重
如
简单求解:
select * from course where id < 3 or name = '英文';
合并求解:
select * from course where id < 3
union
select * from course where name = '英文';
虽然上述语句效果大致一致,但相比之下,or 会忽略索引,而索引可有效提高系统查询效率!
以上为本篇博客内容,内容有点多!
侵权删~















 2033
2033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









