









Knowledge Graph Embedding Methods for Entity Alignment: An Experimental Review
1 Intro
基于关系的方法:基于关系三元组或路径等实体结构学习嵌入;
基于属性的方法:基于实体名称/标识或文本属性等事实特征学习嵌入。
- 问题1:影响基于关系的方法(如负采样、邻域范围)和基于属性的方法(如文字和文本描述的使用)有效性的关键因素是什么?这些方法的调参敏感性如何?
- 问题2:如何提升同时考虑实体结构关系和属性值的方法的效果?
- 问题3:效果与效率的权衡
- 问题4:数据集的哪些特征(例如,稀疏性、种子对齐中实体对的数量、文本、谓词名称和实体名称方面的异质性)对监督、半监督和非监督方法敏感?
OpenEA和EAE只使用的数据集,具有文本描述和文字值的实体数量较少。
对比方法:
- 有监督:MTransE[6]、MTransE+RotatE[7]、MultiKE[10]、RDGCN[8]、RREA(basic)[9]
- 无监督:AttrE[11]
- 半监督:KDCoE[12]、RREA(semi)[9]
2 KG嵌入实体对齐 Entity Alignment With KG Embeddings
2.1 实体对齐问题
在实践中,所有评估的实体对齐方法都依赖于许多假设/约束:
- 每个实体至少是一个关系三元组的头节点
- 1对1约束:E1中的每个实体都与E2中的一个实体匹配
2.2 KG嵌入实体对齐
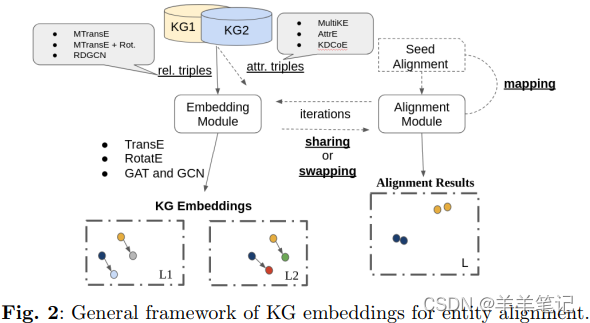
嵌入模块:根据关系(即实体结构邻域)和/或事实部分(即实体名称/标识、文字/文本),学习每个KG的实体的嵌入。
对齐模块:使用种子对齐(监督)或属性值相似性(无监督)或两者(半监督)对齐生成的实体嵌入。它为两个KG的实体生成一个公共嵌入空间,以便使用三种不同的技术(共享、交换和映射)根据距离度量(例如,欧几里德)生成对齐结果。共享和交换,根据实体的可用相似性证据直接更新嵌入模块生成的实体嵌入,而映射本质上学习对齐KG的两个嵌入空间之间的线性变换。
2.2.1 嵌入模块 Embedding Module
翻译模型:TransE、RotatE
图神经网络:处理复杂图结构 GCN、GAN
2.2.2 对齐模块 Alignment Module
共享 sharing:更新两个KGs的实体嵌入,使种子对齐的嵌入距离最小化;
交换 swapping:将三元组中实体替换成与之对齐的实体,形成新的三元组,扩充种子对齐训练集;
映射 Mapping:学习线性变换矩阵,进行对齐实体嵌入映射。
2.2.3 基于关系的KG嵌入
MTransE:多语言KG实体嵌入模型,也适用于常规KG
Loss function:J = SK + αSA,
- 嵌入模块:无负采样的TransE,损失函数SK;
- 对齐模块:映射对齐。
MTransE+RotatE:MTransE变体
- SK使用RotatE损失函数;
- SA使用共享参数对齐方式。
RDGCN
- 嵌入模块:GCN。
- 对齐模块:映射,带负采样
RREA
- 有监督:GCN + GAN 基于路径学习实体嵌入,共享参数对齐(带负采样)
- 半监督:自训练
2.2.4 基于属性的KG嵌入
MultiKE(有监督)
- 嵌入模块:从实体名称、关系结构、属性三个角度进行实体嵌入表示
实体名称:基于词向量进行实体名称文本特征表示
关系:基于TransE(负采样)进行实体关系特征表示
属性:基于TransE进行实体属性特征表示,其中属性嵌入使用CNN结合属性文本特征与属性结构特征获得 - 对齐模块:参数交换
KDCoE(半监督)
联合训练基于关系结构和文本特征的两个嵌入对齐模型,迭代交替由两个模型提出一组新的种子对齐(距离在特定阈值内的实体对),丰富训练集。
- 基于关系结构的嵌入对齐模型:MTransE
- 基于文本特征的嵌入对齐模型:Attention GRU获取文本嵌入,对齐目标P(e|e’)
AttrE(无监督)
最小化基于关系结构的嵌入模型中具有相似文本描述的实体对的嵌入距离。
- 谓词融合:融合两个KG的关系,合并形成一个KG。
- 关系结构嵌入:用TransE作为关系结构嵌入模型,得到实体嵌入es
- 属性嵌入模型:TransE属性结构+n-gram属性文本编码,得到实体嵌入ec
- 结合es和ec,是es和ec相近
2.3 方法分类比较

3 实验设置
数据集:共9个数据集,其中4个OpenEA数据集,5个自建。
- BBC-DB:1)稀疏数据集;2)实体平均属性数最高;3)具有文本描述的实体数最多;4)KG遵循类似的谓词命名规则,适用于模式对齐的方法。
- imdb tmdb、imdb tvdb和tmdb tvdb:1)实体数较少;2)实体的平均属性数较低;3)文字和谓词名称方面的同质性较高。
- Restaurants:最小的数据集。它没有涵盖所有基于嵌入的实体对齐方法的假设(1对1假设),即并非所有KG1实体都与所有KG2实体匹配,反之亦然。选择这个数据集来检验评估的方法是否可以推广到不满足1对1假设的数据集。
交叉验证:5项交叉验证取平均。
评估指标:
- HIT@K:前K个实体对齐中正确的比例,衡量模型在可接受范围内的准确率
- MR:正确实体对齐的平均排序,对模型的质量比较敏感
- MRR:排名的调和平均数的倒数,受排名靠前的值的影响更大
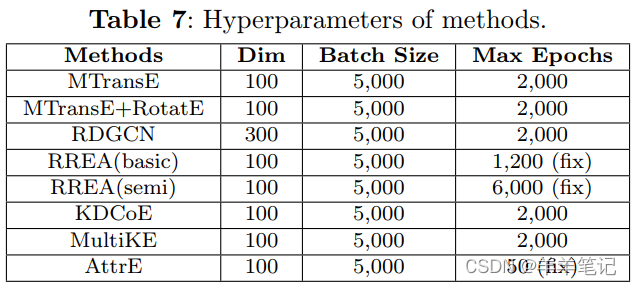
参数设置:
4 实验结果分析
4.1 结果对比
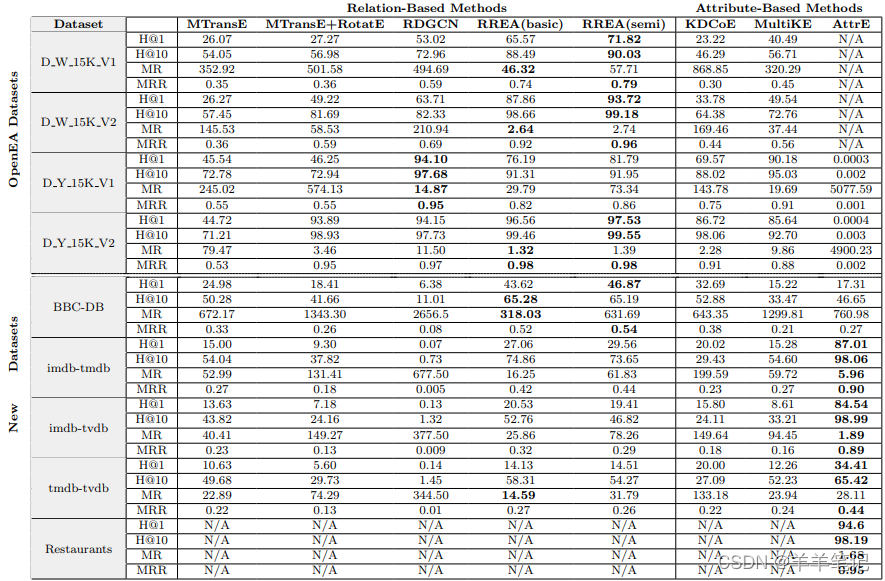
MTransE:
- OpenEA数据集:在密集型数据集上的效果并没有明显优于稀疏性数据集。这是因为缺少负采样导致的过拟合训练。
- 自建数据集:效果更差,因为自建数据集数据规模和用于训练的种子对齐都很少。
MTransE+RotatE:
- OpenEA数据集:稀疏数据集上的效果与MTransE类似,由于采用负采样,其在密集数据集上的效果优于MTransE。
- 自建数据集:效果均不如MTransE,在三元组数和训练集规模(种子对齐数量)较小的数据集上,高维空间中相似实体的距离很远,负采样会加剧这种问题。
RDGCN:利用多跳关系结构,且嵌入维数和负采样数都是最大的。
- OpenEA数据集:效果优于上面两个方法,体现出引入多跳关系结构的作用。但多跳关系也会引入噪声,因此采用了更高维的嵌入和更多的负采样来应对这些噪声。
- 自建数据集:效果不如上面两个方法,因为更多的负采样和更高维的嵌入加剧了上述问题。
RREA(basic):利用多跳关系结构,且利用Attention机制排除多跳关系结构中噪声。
- OpenEA数据集:在DY15K V1上效果不如RDCGCN,其余数据集上效果优于上述方法。可能在DY15K V1上Attention机制没能有效除噪。
- 自建数据集:效果优于上述方法。多跳关系提升了嵌入对实体的描述能力,同时Attention除噪机制避免了高维、高负采样的副作用。
RREA(semi) :比RREA(basic)增加了4轮自训练。
- 在DY15K V1上效果不如RDCGCN(原因同上),其余数据集上的HIT@k和MMR指标优于上述方法,MR指标不如上述方法。自训练增加了可用于训练的种子对齐数,但也会引入错误的种子对齐。
KDCoE:三元组关系结构+负采样+实体的文本描述。
- 在文本描述丰富的数据集中可以优于基于关系结构的方法,但仍不如RREA。虚假的相似性描述会影响对齐效果。
MultiKE:三元组关系结构+实体名称+属性结构&属性文字。
- 对三元组规模变化不敏感。负采样数的增加影响了它在小数据集上的效果。
AttrE:无监督+少量负采样+文本相似性
- OpenEA数据集:无效,因为AttrE仅在可以进行谓词对齐的方法可用
- 自建数据集:效果最佳,在相似谓词和相似文本描述丰富的数据集有效
- 唯一一个在不满足1对1假设的数据集上生效的方法。
4.2 效果与效率的权衡
效果排序:RREA效果最好(semi好于basic),MultiKE第二。
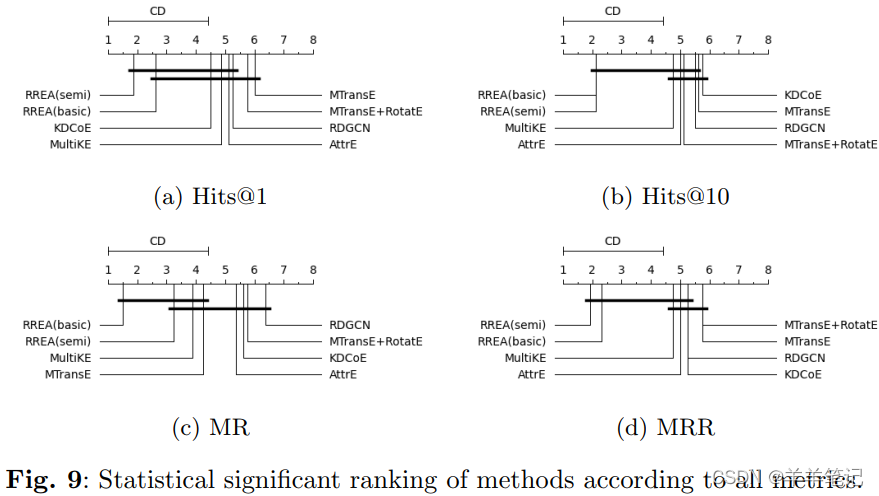
效率排序:前三名MTransE、RDGCN、MultiKE
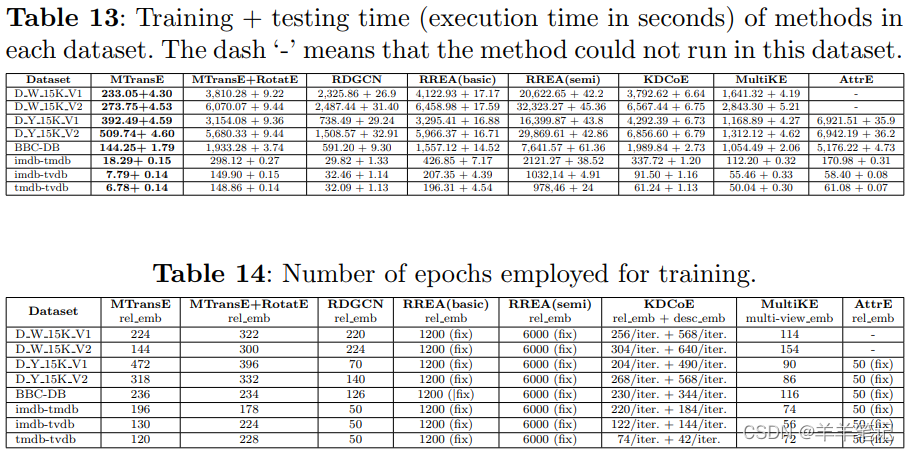
- MTransE:轻量级,两层网络,目标函数简单,无负采样;
- RDGCN & MultiKE:收敛快;
- RREA:固定训练轮次,不采用早停;
- AttrE:无监督,利用所有可能的文本描述参与训练
效果与效率综合考虑:

- 红:比baseline快又好
- 绿:比baseline慢且差
- 左下灰:比baseline快但差
- 右上灰:比baseline慢但好
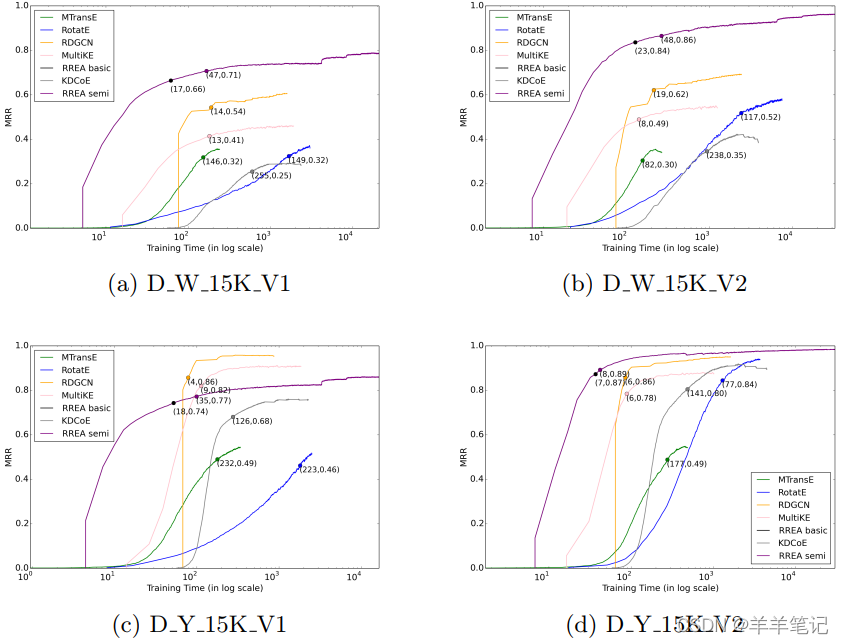
MRR随训练时间的变化,圆点标注出MRR达到最佳的90%时的训练时间。
4.3 数据集特征与方法效果的关系
- 种子对齐数量:种子对齐的数量与有监督和半监督方法的效果呈正相关。
- 数据集密度:实体的平均关系三元组数与所有方法(除AttrE以外)的效果呈正相关,AttrE的效果与实体的平均属性数呈负相关。可能因为更多的属性引入了更多的噪声,而AttrE没有很好的处理属性文本噪声的策略。
总结
1)负采样:负采样有助于在密集型数据集中提升方法的效果,在特别稀疏的数据集会起反效果
2)使用的领域范围:使用多跳关系可以丰富嵌入的语义,但也会引入噪声,需要设置相应的除噪机制(增加负采样和嵌入维度或Attention)
3)属性附加信息:在稀疏数据集中,对基于属性的方法的增益更明显














 4101
4101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









