










ZeroEA论文翻译
ZeroEA: A Zero-Training Entity Alignment Framework via Pre-Trained Language Model
ZeroEA:通过预训练语言模型的零训练实体对齐框架
ABSTRACT
实体对齐(EA)是知识图(KG)研究中的一项关键任务,旨在识别不同知识图谱中的等效实体,以支持知识图谱集成、文本到 SQL 和问答系统等下游任务。考虑到 KG 中丰富的语义信息,预训练语言模型 (PLM) 因其卓越的上下文感知编码能力而在 EA 任务中显示出前景。然而,当前基于 PLM 的解决方案遇到了一些障碍,例如需要大量培训、昂贵的数据注释以及结构信息的结合不足。在本研究中,我们引入了一种新颖的零训练 EA 框架 ZeroEA,它可以有效地捕获 PLM 的语义和结构信息。具体来说,Graph2Prompt模块通过将KG拓扑转换为适合PLM输入的文本上下文,充当图结构和纯文本之间的桥梁。此外,为了向 PLM 提供简洁、清晰、长度合理的输入文本,我们设计了一个基于基序的邻域过滤器来消除嘈杂的邻域。对 5 个基准数据集的综合实验和分析证明了 ZeroEA 的有效性,超越了所有领先的竞争对手,并在实体对齐方面实现了最先进的性能。值得注意的是,我们的研究强调了 EA 技术在提高下游任务性能方面的巨大潜力,从而使更广泛的研究领域受益。
1 INTRODUCTION
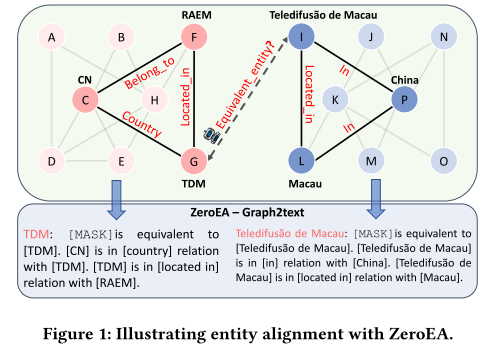
知识图(KG)是一种流行的知识库格式,已成为存储大规模结构和语义信息的关键技术。知识图谱在通过基于知识的推理为智能系统提供动力方面发挥着关键作用。实体对齐(EA)是知识图谱的关键任务之一,旨在识别和链接不同知识图谱之间的等效实体。如图 1 中的玩具示例所示,EA 旨在确定实体“TDM”和“Teledifusão deMacau”在现实世界中是否等效,并可以将它们连接在一起以形成更全面的社区。因此,EA 可以使下游任务受益,例如知识图谱集成、推荐系统和文本到 SQL。
大多数现有的 EA 解决方案通过强化训练将来自不同 KG 的实体和关系编码到同一向量空间中,然后根据相似性测量进行预测。成功的 EA 关键是正确编码结构信息和语义信息。这两个维度构成了现有 EA 方法的两大类。大多数现有的 EA 方法属于基于结构的组,该组精心设计了图拓扑编码器,例如 TransE 和图神经网络(GNN),如图 2(a)所示。
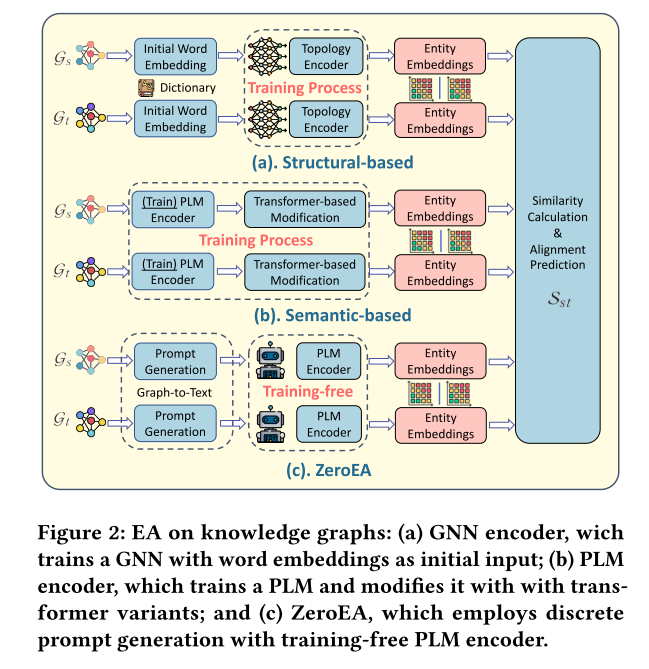
另一方面,基于语义的组利用 PLM(例如 BERT)来捕获 KG 的文本语义信息,如图 2(b)所示。该小组在现有解决方案中实现了最先进的性能。例如,BERT-INT对 KG 语义信息上的 PLM 进行微调(在第 2 节中定义),但无法组合结构信息。 SDEA 利用 PLM 对实体属性信息进行编码,并训练基于变压器的神经网络来捕获邻居的语义信息。
经过对流行的基于语义的方法的详细调查和比较,我们得到了以下关键观察结果。(a) 它们高度依赖于 PLM 上的强化训练或微调,并依赖于大量数据标签注释,这在网络规模的 KG 中成本高昂,甚至有时在现实世界中无法实现。(b) 他们对邻居的定义是基于边缘连接的。然而,流行的实体节点在大规模 KG 中具有太多边连接的邻居,这会分散 EA 模型的注意力并引入噪声,导致性能较差。此外,鉴于不同的邻居对目标节点的贡献不同,它们应该被分配不同程度的关注,正如最近的研究所建议的。
© 在现有文献中,尚未研究 EA 对下游任务的影响。在这项工作中,我们将文本到 SQL 作为我们的主要下游任务,目标是弥合这一研究差距,并为 EA 增强型下游应用程序的开发提供有价值的见解。
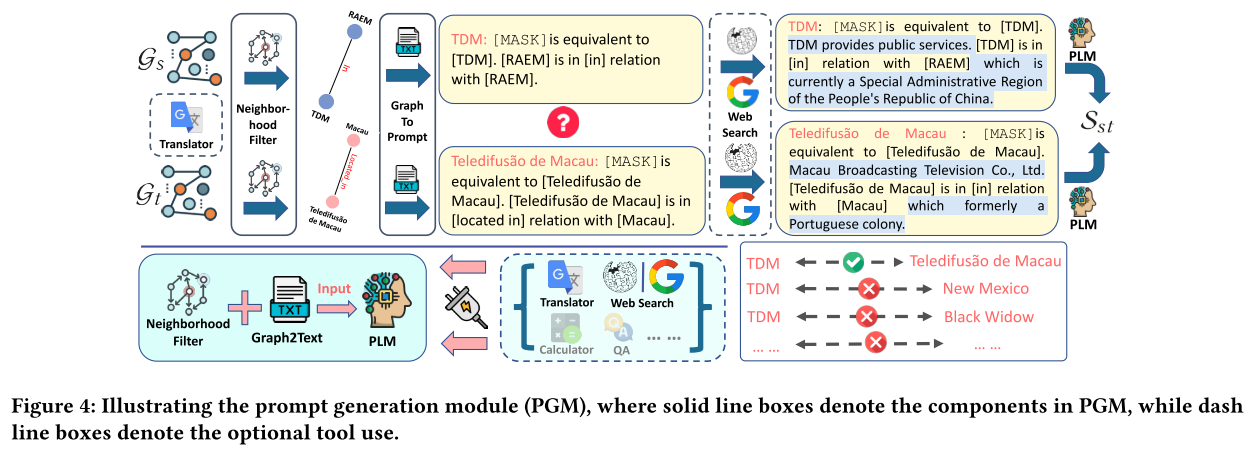
在这项工作中,我们提出了 ZeroEA,一种使用 PLM 的新型零训练 EA 框架,如图2© 所示,它通过提供高质量的离散提示(即输入 PLM 的文本序列)来唤起 PLM 中固有的知识。ZeroEA采用Graph2Prompt模块将KG拓扑信息转换为具有大量上下文的离散提示。如图1所示,目标实体“TDM”及其两条边被转换为离散提示“TDM”。Graph2Prompt 模块使 PLM 能够理解和使用图形技术(例如,频繁的小的子图或基序)。由于基序可以识别抗噪声的稳定结构(或高阶结构),因此我们提出的基于基序的邻域滤波器可以与 PLM 一起使用,以消除噪声并精确捕获信息。因此,与其他基于语义的监督方法相比,ZeroEA 无需微调,可以捕获更丰富的结构信息,同时不会丢失语义信息。此外,我们还观察到,准确的 EA 可以有利于下游任务,例如文本到 SQL。 总而言之,我们的贡献是:
(1) 我们提出了 ZeroEA,一种通过 PLM 的新型零训练实体对齐框架,它通过使用高质量的离散提示来唤起 PLM 固有的知识,从而摆脱了广泛的 PLM 微调和数据注释。
(2)为了捕获更丰富的结构信息,我们提出了一种基于基序的邻域过滤器,它过滤掉嘈杂的邻居并通过基序捕获高阶KG结构信息。
(3) 我们对五个基准数据集进行了全面的实验,这表明 ZeroEA 优于最先进的监督方法,并显着优于其他无监督解决方案。
(4) 最后,我们还在文本到 SQL 领域最先进的解决方案之一中采用了 ZeroEA,并取得了令人印象深刻的改进。为此,我们重新定义了模式链接,这是文本到 SQL 中的关键中间步骤 过程,作为一个 EA 问题。 我们的实验结果还表明,提高 EA 的准确性可以提高文本到 SQL 的性能。
其余部分的组织如下。第2节正式定义了实体对齐问题。第3节描述了我们用于EA任务的ZeroEA框架。第4节提供了基准数据集和下游任务的实验结果。第五节讨论了相关工作。第6节总结了本文。
2 PRELIMINARIES
问题表述。 我们首先介绍一些必要的符号。一个KG由一个三元组 T \mathcal{T} T的集合组成,其格式为(头实体,关系,尾实体),一个实体集 E \mathcal{E} E和一个关系集 R \mathcal{R} R。在 R = { r 1 , . . . , r n } \mathcal{R} = \{r_{1},...,r_{n}\} R={r1,...,rn}中,任何 r i r_i ri 都指的是节点之间的一跳关系和具有 l l l 跳数的多跳关系定义为 r m u l = r 1 ∘ r 2 ∘ . . . ∘ r l r^{mul}=r_{1}\circ r_{2}\circ...\circ r_{l} rmul=r1∘r2∘...∘rl,这是一跳关系的组合。KG的正式定义为 G = { E , R , T } \mathcal{G}=\{\mathcal{E},\mathcal{R},\mathcal{T}\} G={E,R,T}。
按照[32]中的问题定义,在 EA 任务中,给出了两个不同的 KG: G s = { E s , R s , T s } \mathcal{G}_{s}=\{\mathcal{E}_{s},\mathcal{R}_{s},\mathcal{T}_{s}\} Gs={Es,Rs,Ts} 和 G t = { E t , R t , T t } \mathcal{G}_{t}=\{\mathcal{E}_{t},\mathcal{R}_{t},\mathcal{T}_{t}\} Gt={Et,Rt,Tt}。EA 旨在找到从 E s \mathcal{E}_{s} Es 到 E t \mathcal{E}_{t} Et 的等效实体,反之亦然。最后,生成并定义两个 KG 的实体之间的对齐集 S s t \mathcal{S}_{st} Sst:
S s t = { ( e i , e j ) ∣ e i ∈ E s , e j ∈ E t , e i ⇔ e j } ( 1 ) S_{st}=\left\{(e_i,e_j)\big|e_i\in\mathcal{E}_s,e_j\in\mathcal{E}_t,e_i\Leftrightarrow e_j\right\}\quad(1) Sst={(ei,ej) ei∈Es,ej∈Et,ei⇔ej}(1)
其中 ⇔ \Leftrightarrow ⇔表示现实世界中的等效实体,例如图1中所示的“Teledifusão deMacau”和“TDM”。
标记的预训练语言模型。 标记语言模型 (MLM),例如 BERT 和 RoBERTa,采用的训练策略包括屏蔽输入序列中的特定标记并将其替换为 [MASK] 标记。MLM 的主要目标是预测屏蔽位置的原始标记,从而最大化正确标记的可能性。给定文本输入 X = x 1 , x 2 , … , x n X = x_{1},x_{2},\ldots,x_{n} X=x1,x2,…,xn,其中第 i i i 个标记被屏蔽,目标函数可以表示为:
− log exp ( c ( [ MASK ] ) ⋅ E x i ) ∑ v ∈ V exp ( c ( [ MASK ] ) ⋅ E v ) , ( 2 ) -\log\frac{\exp(c([\text{MASK}])\cdot\mathbf{E}_{x_i})}{\sum_{v\in V}\exp(c([\text{MASK}])\cdot\mathbf{E}_v)},\quad\quad(2) −log∑v∈Vexp(c([MASK])⋅Ev)exp(c([MASK])⋅Exi),(2)
其中本研究中的术语 E v \mathbf{E}_v Ev表示 v v v的词嵌入,属于词汇集𝑉。
MLM免调整提示。 MLM 的免调整提示方法通过冻结 MLM 的所有参数来直接生成答案或嵌入。这是简单地基于给定的离散提示来实现的,如 4 中所述。在我们的方法中,我们直接提取 c ( [ M A S K ] ) c([MASK]) c([MASK]) 作为实体的上下文表示。
文本到 SQL 和模式链接。Text-to-SQL 旨在将自然语言查询转换为 SQL,从而为数据科学应用程序自动返回关系数据库的结果。文本到 SQL 过程的一个关键方面是架构链接,这需要将问题标记映射到其相应的架构元素(表或列),从而产生更准确的 SQL 查询。
考虑一个自然语言问题 Q = { q 1 , … , q ∣ Q ∣ } \mathcal Q=\{q_{1},\ldots,q_{|\mathcal Q|}\} Q={q1,…,q∣Q∣} 和数据库模式 S = ⟨ C , T ⟩ \mathcal{S}=\langle\mathcal{C},\mathcal{T}\rangle S=⟨C,T⟩ ,其中 C = { c 1 , … , c ∣ C ∣ } \mathcal C=\{c_{1},\ldots,c_{|\mathcal C|}\} C={c1,…,c∣C∣}且 T = { t 1 , … , t ∣ T ∣ } \mathcal T=\{t_{1},\ldots,t_{|\mathcal T|}\} T={t1,…,t∣T∣} 分别表示列和表。text-to-SQL 任务旨在为模式 S \mathcal S S 的上下文中给定的问题 Q \mathcal Q Q 生成相应的 SQL 查询 y y y。
模式链接是文本到 SQL 生成的一项关键技术,因为它可以区分任意对的问题标记和模式项的关系。我们将模式链接对表示如下:
S l = { ( q i , s j ) ∣ q i ∈ Q , s j ∈ ⟨ C , T ⟩ , q i ⇔ s j } . ( 3 ) \mathcal S_l=\{(q_i,s_j)\mid q_i\in Q,s_j\in\langle C,\mathcal{T}\rangle,q_i\Leftrightarrow s_j\}.\quad\quad(3) Sl={(qi,sj)∣qi∈Q,sj∈⟨C,T⟩,qi⇔sj}.(3)
在我们的实验中,我们观察到模式链接准确性的提高可以生成更准确的 SQL 查询。
3 METHODOLOGY
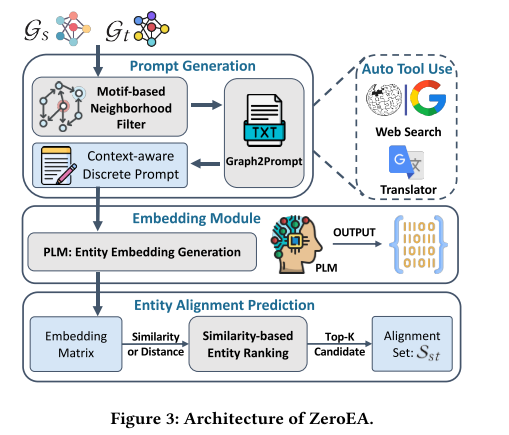
该 ZeroEA 框架由三个主要组件组成:(i)提示生成模块(PGM),它将 KG 拓扑转换为文本离散提示,其中包含来自过滤邻域的大量上下文信息。 (ii) 嵌入模块 (EM) 将 PGM 生成的离散提示作为所选 PLM 的输入,并输出每个目标实体的上下文感知嵌入。(iii) EA预测模块,计算候选实体之间的相似度并据此进行对齐预测。我们提出的 ZeroEA 的总体概述如图 3 所示。在这项工作中,我们使用 BERT 作为编码器。
3.1 Prompt Generation Module (PGM)
如图 3 所示,PGM 的主要组件包括基于基序的邻域过滤器、Graph2Prompt 和可选的自动工具使用,这些部分将在以下部分中进行说明。
3.1.1 基于基序的邻域过滤器。 邻域过滤器旨在滤除目标节点的嘈杂邻居。捕获结构信息最流行的方法是聚合来自邻居的信息。然而,“哪些邻居应该被覆盖?” 仍存在争议。最近,许多作品声称利用多跳邻居是有益的;然而,其他研究发现一跳邻居可以提供足够的信息。正如 SelfKG和 BERT-INT中所述,包含多跳邻居会因邻居噪音而损害 EA 性能。此外,PLM 还具有输入长度限制。例如,BERT 只能接受长度最多为 512 个 token 的输入序列,这意味着如果有太多邻居,输入提示将超出输入限制并损害 EA 性能。为了控制输入长度,BERT-INT 在 BERT 嵌入中选择具有高相似性的邻居,如果仅考虑邻居之间的语义相似性,这是不够的。
为了滤除噪声并控制 PLM 的输入长度,我们提出了一种基于基序的邻域过滤器。图 G G G的基序或“基本构建块”是 G G G的重复出现且重要的子图模式。在文献中,据说基序可以表达节点之间的高阶关系,并减少图分析中的噪音。基序和基序实例在 Def 中定义。分别如图 1 和 2 所示,图 1 显示了基序的一个简单示例,即粗体颜色的三角形和线条。注意,二元矩阵 M M M表示邻接矩阵,其中每个元素 M i , j M_{i,j} Mi,j表示边 ( i , j ) (i,j) (i,j)的存在。因此,除了通过边连接的常规邻居之外,知识图谱中的每个节点还有其通过基序实例连接的基序邻居。如图 1 所示,当基序是三角形时,节点 C C C 和 F F F都是边邻居和基序邻居。然而,节点 C C C 和 B B B 是边缘邻居,但不是基序邻居,因为它们之间没有共享的三角形基序。与节点对 C C C 和 B B B 相比,节点对 C C C 和 F F F 从噪声中上升的机会更小,因为 C C C 和 F F F 构成了一个基序实例,这意味着 C C C 和 F F F 参与了由基序决定的高阶关系,这种关系发生反复在 G G G。因此, F F F 成为 C C C 的邻居的置信度更高。
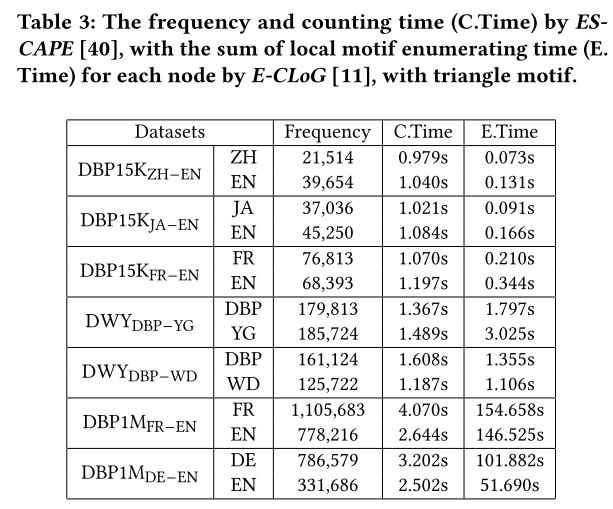
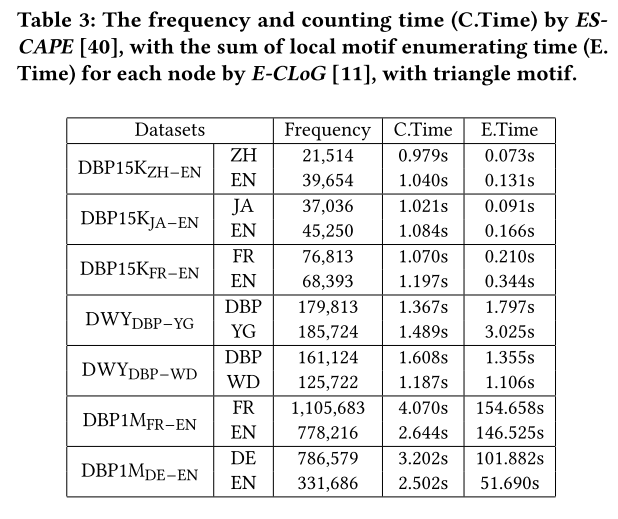
对于基于基序的邻居过滤器,我们通过以下方式计算每个图节点的嵌入:(1)找到其基序邻居及其边缘;(2) 将这些边翻译成一个句子;(3) 将句子组合成段落;(4) 将段落传递到 PLM 模型以生成节点的嵌入。为了枚举基序实例,我们使用了 E-CLoG,这是一种最先进的局部子图枚举算法,可以有效地找到大型子图的实例,例如,在数百万个数据集上的所有 p p p 节点基序只需几分钟, p = 3 , 4 , 5 p = 3, 4, 5 p=3,4,5。该算法也常用于大图分析。表 3 显示了我们实验中使用的数据集的基序枚举的开销。可以看到,所需时间并不长,仅占ZeroEA总运行时间的0.5%。
定义1(Motif) 一个 i i i节点的基序 H H H被定义为一个元组 ( M , V ) (\mathbf M, V) (M,V),其中 V ⊂ { 1 , 2 , 3 , . . . , i } V\subset\{1,2,3,...,i\} V⊂{1,2,3,...,i}表示一组锚节点,即感兴趣的节点集。 M \mathbf M M 是一个大小为 i ⋅ i i\cdot i i⋅i 的二进制矩阵,表示 H H H 的边缘模式。
定义 2(Motif-instance) 给定图 G = ( V , E ) G=(V, E) G=(V,E) 和基序 H = ( V H , E H ) H=(V_{H},E_{H}) H=(VH,EH), H H H的基序实例 m = ( V m , E m ) m=(V_{m},E_{m}) m=(Vm,Em)是 G G G的子图,与 H H H同构,表示为 m ≃ H m\simeq H m≃H。
为了维持具有合理大小的高质量邻域,我们为邻域分配不同的重要性值并选择最重要的邻域。我们采用 IND 作为该模块的基线之一,其中较高的节点度意味着较高的重要性值。
如前所述,与基于边缘的关系相比,图案能够减少噪声并捕获高阶关系。在本模块中,为了充分利用基序,我们探索了使用基序的不同方法来帮助我们选择最重要的邻居,其中 k k k是由用户决定的整数。我们有以下基线方法来选择邻域过滤器模块中的邻居:
(1)n跳邻居:选择所有n跳邻居,其中n是用户决定的整数。
(2)n-hop基序邻居:选择所有 n-hop 基序邻居(即具有到目标节点的n-hop 基序路径的所有邻居,其中基序路径是一个或多个基序实例的串联)。
(3) IND:基于边的邻居根据节点度进行排序。
(4) M-IND:基序邻居根据基序度(即包括给定节点的基序实例的数量)值进行排序。
然而,IND和M-IND关注的是每个邻居的受欢迎程度,而忽略了测量邻居与目标节点之间的互连程度。为了捕获不同邻居和目标节点之间的不同互连级别,我们提出了一种基序相关邻域过滤器,其中每个邻居的重要性值通过与目标节点共享基序的数量来衡量。之后,根据重要性值对所有邻居进行排名,我们选择最重要的邻居。 KG G a \mathcal G_a Ga 中给定节点 e i e_i ei 的 k k k 邻居的选定邻居集 S n e \mathcal S_{ne} Sne 定义为: S n e = N e i g h b o r h o o d − F i l t e r ( e i , G a ) = { ( e i , r 1 , e 1 ) , ( e i , r 2 , e 2 ) , . . . , ( e i , r n , e n ) } . S_{ne} = \mathrm{Neighborhood-Filter}(e_{i},G_{a}) = \{(e_i,r_1,e_1),(e_i,r_2,e_2),...,(e_i,r_n,e_n)\}. Sne=Neighborhood−Filter(ei,Ga)={(ei,r1,e1),(ei,r2,e2),...,(ei,rn,en)}.
3.1.2 Graph2Prompt 应用 Graph2Prompt 操作后,从邻域过滤器中选择的前 k k k 个 邻居被连接在一起成为离散提示,然后可以输入到 PLM。离散提示定义为:
P r o m p t e i = C o n c a t ( [ [MASK]is equivalent to [ e i ] , [ e i ] i s i n [ r 1 ] r e l a t i o n w i t h [ e 1 ] , . . . . . . [ e i ] i s i n [ r n ] r e l a t i o n w i t h [ e n ] ] ) ( 4 ) \begin{aligned}Prompt_{e_{i}}&=\mathrm{Concat}([\text{[MASK]is equivalent to }[e_{i}],\\&[e_{i}] \mathrm{is~in~}[r_{1}] \mathrm{relation~with~}[e_{1}],\\&......\\&[e_{i}] \mathrm{is~in~}[r_{n}] \mathrm{relation~with~}[e_{n}]] )\end{aligned}\quad\quad(4) Promptei=Concat([[MASK]is equivalent to [ei],[ei]is in [r1]relation with [e1],......[ei]is in [rn]relation with [en]])(4)
其中“[MASK]”是BERT中的特殊标记,“Concat(·)”表示连接操作。 r n r_n rn是目标实体 e i e_i ei 和第 n n n 个选定邻居 e n e_n en之间的关系。
如果基于第3.1.5节中定义的感知策略应用网络搜索工具,则会注入关于 e i e_i ei的简短外部知识,如公式5所示。
P r o m p t e i = C o n c a t ( W e b S e a r c h ( e i ) , P r o m p t e i ) ( 5 ) Prompt_{e_i}=\mathrm{Concat}(\mathrm{~WebSearch}(e_i),Prompt_{e_i})\quad\quad(5) Promptei=Concat( WebSearch(ei),Promptei)(5)
图 4 展示了该过程。
3.1.3 嵌入模块(EM) 输入标记列表 T T T的嵌入(即语义表示)首先由多层双向 Transformer 进行编码。每个 Transformer 层都有两个子层,即多头自注意力网络(MHA)和全连接前向网络(FFN)。 综上所述,可以获取实体 e i e_i ei的最后一层BERT语义隐藏状态,如式6所示。
E e i = E n c Θ ( P r o m p t e i ) ( 6 ) \mathbf{E}_{e_i}=\mathrm{Enc}_\Theta(Prompt_{e_i})\quad\quad(6) Eei=EncΘ(Promptei)(6)
其中 E n c Enc Enc表示PLM编码器,即本工作中的BERT。 Θ \Theta Θ为PLM编码器的原始参数。
给定实体 e i e_i ei 的最终实体嵌入是特殊标记“[MASK]”的隐藏状态,它代表 e i e_i ei 的上下文感知嵌入,而“[CLS]”通常被认为是整个输入提示的嵌入,如方程7所示。
c ( [ MASK ] ) = E e i ( [ MASK ] ) + E e i ( [ CLS ] ) 2 ( 7 ) \mathbf{c}([\text{MASK}])=\frac{\mathbf{E}_{ei}([\text{MASK}])+\mathbf{E}_{ei}([\text{CLS}])}{2}\quad\quad(7) c([MASK])=2Eei([MASK])+Eei([CLS])(7)
3.1.4 实体对齐预测。 获取所有实体嵌入后,目标实体嵌入 E t E_t Et 和候选实体嵌入 E c E_c Ec 之间的相似度得分可以通过余弦相似度来测量,如下所示:
cos ( E t , E c ) = E t ⋅ E c ∥ E t ∥ ∥ E c ∥ ( 8 ) \cos(\mathbf{E}_t,\mathbf{E}_c)=\frac{\mathbf{E}_t\cdot\mathbf{E}_c}{\|\mathbf{E}_t\|\|\mathbf{E}_c\|}\quad\quad(8) cos(Et,Ec)=∥Et∥∥Ec∥Et⋅Ec(8)
相似度分数越高意味着目标实体和候选实体更有可能对齐。
3.1.5 自动工具使用策略:感知。 与[32,53,54]中使用语言翻译工具类似,为了解决PLM的局限性,例如无法访问最新知识,我们提出了一种基于工具的新颖框架,在该框架下ZeroEA可以自动 使用工具来扩展其能力。在这项工作中,我们提出了使用应满足以下要求的工具的感知策略:(1)工具的使用应以自动方式进行,无需任何人工监督注释。(2)工具的使用应该是按需使用,决定何时使用、如何使用工具,而不是到处使用所有工具。
本节我们以网页搜索工具为例。直观上,当翻译质量不理想或者特定实体的节点度较低时,应该使用该工具。 为了衡量翻译质量,我们采用 Rouge-L 评分,这是机器翻译领域最广泛使用的指标之一。
对于翻译质量测量过程,当给定长度为 m m m的源文本序列 S S S和长度为 n n n的目标文本序列 T T T时,Rouge-L分数测量如下:其中 L C S ( S , T ) LCS(S, T) LCS(S,T)表示公共子序列 S S S 和 T T T 的最大长度,并且 β = P l c s / R l c s \beta=P_{lcs}/R_{lcs} β=Plcs/Rlcs。
令 F l c s F_{lcs} Flcs表示Rouge-L分数, α \alpha α表示Rouge-L阈值, γ \gamma γ表示用户设置的实体度阈值。如果 F l c s F_{lcs} Flcs低于 α \alpha α或实体度小于 γ \gamma γ,则应用网络搜索工具。在这种情况下,Web搜索工具会输出附加信息以增强实体表示。 在数学上,目标函数可以表示为等式9:
WebSearch ( e i ) = { K E , if F l c s < α or degree ( e i ) < γ None , otherwise ( 9 ) \text{WebSearch}(e_i)=\begin{cases}K_E,&\text{if}F_{lcs}<\alpha\text{or degree}(e_i)<\gamma\\\text{None},&\text{otherwise}\end{cases}\quad\quad(9) WebSearch(ei)={KE,None,ifFlcs<αor degree(ei)<γotherwise(9)
其中: WebSearch ( e i ) \text{WebSearch}(e_i) WebSearch(ei)是实体 e i e_i ei 的 Web 搜索工具的输出。 K E K_E KE表示通过 Web Search 工具检索到的外部知识,包括正确的英文实体名称和简短的介绍或定义,如图 4 中突出显示的文本。 degree ( e i ) \text{degree}(e_i) degree(ei)是实体 e i e_i ei 在知识图谱中的程度,表示其在图中的连通性。 α \alpha α是用户设定的Rouge-L阈值,表示可接受的最低翻译质量。 γ \gamma γ是用户设定的实体度阈值,表示最小可接受的实体度。限于篇幅,我们将防止工具使用过程中信息泄露的策略报告在我们的 GitHub 存储库中,这种情况很少发生。
4 EXPERIMENTS
4.1 Experimental Setup
数据集 (1) DBP15K 数据集是公认的实体对齐基准,包含三个较小的跨语言 EA 子集,每个子集有 15,000 个对齐实体对。(2) DWY100K 数据集包含两个中等规模的单语言 EA 子集,每个子集包括 100,000 个对齐实体对和大约 100 万个三元组。(3) DBP1M 数据集是迄今为止最大的 EA 基准之一,具有两个跨语言子集,每个子集都有超过一百万个实体和近千万个三元组。(4) SPIDER:在我们的工作中,我们将文本到SQL作为我们研究的主要下游任务,旨在研究实体对齐对下游应用程序性能的影响。SPIDER 是一个大规模、复杂、跨域的文本到 SQL 数据集。 它包含 10,181 个问题、5,693 个独特的 SQL 查询、跨 138 个领域的 200 多个数据库。
评估指标: 与基准工作一致,我们采用两种评估指标:hits@K 和平均倒数排名(MRR)。更高的 hits@K 和 MRR 意味着更好的性能。
在 SPIDER 中,精确匹配 (EM) 和执行准确性 (EX) 是用于评估最终文本到 SQL 性能的两个主要指标。 此外,我们使用精度、召回率和 f1 分数来衡量实体对齐 (EA) 模型支持的模式链接的有效性。实体对齐 EA 增强的架构链接及其后续文本到 SQL 性能之间的相关性可以揭示更准确的 EA 可以使下游任务受益。
实验设置: 我们遵循原始的数据集分割,其中70%的种子对齐数据用作测试数据,另外30%用作监督方法的训练数据和验证数据。 在我们的文本到 SQL 实现中,我们采用了中概述的技术。Graphix-T5 是一种最先进的模型,将问题标记和模式项视为两个小 KG,并通过字符串匹配技术执行模式链接。 在 Graphix-base 构建的默认图中,通过 EA 新添加的关系被标记为语义匹配。由于文本转 SQL 的计算成本较高,我们将 EA 方法与 Graphix-T5 的基础版本进行比较分析。
比较方法: 我们将 ZeroEA 与: 1. 需要使用 100% EA 训练集数据的监督方法。监督方法进一步分为 (1) 基于翻译的方法(表 1 中的“Trans”,它是 TransE 的变体)。(2) 基于 GNN 的方法(表 1 中的“GNN”),它是变体 (3)基于PLM的方法(表1中的“PLM”),使用PLM作为编码器。组(1)、(2)是基于结构的方法,组(3)是基于语义的方法。 2. 无监督和自监督,不需要利用 EA 的任何训练集数据。它们的分组方式与上面的监督组类似,在文本到 SQL 设置中,我们选择 Graphix-T5-base。我们通过这些 EA 方法和具有不同阈值的 ZeroEA 增强模式链接。
4.2 Experimental Results
4.2.1 总体结果。 多语言数据集的结果:如表 1 所示,ZeroEA 的表现显着优于监督基线组、无监督基线组和自监督基线组。
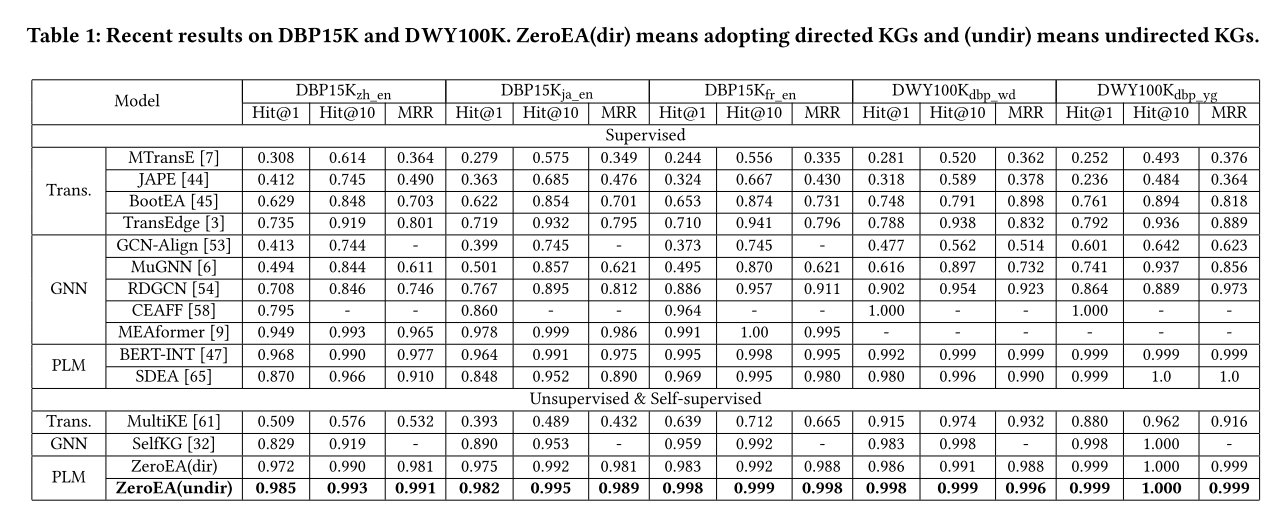
(1) 与监督组相比,ZeroEA 在 ZH-EN、JA-EN 和 FR-EN 上分别优于最佳基线 1.9%、2.1% 和 0.5%(ZeroEA 已达到 99.9%),这表明强化训练是有效的 不是必需的,并且通过适当的上下文信息,PLM 处理结构化 KG 数据的能力非常出色。 正如 BERT-INT(EA 中最先进的监督模型)所述,语义信息甚至比 KG 的结构信息更重要[47],我们的 ZeroEA 的性能也证明了这一点。 它表明,基于语义信息的嵌入方法,尤其是基于 PLM 的嵌入方法,在 EA 任务中是一种很有前途的方法,但与众多基于 GNN 的方法相比,这并不是一个经过充分探索的解决方案。
(2) 在无监督和自监督组中,ZeroEA 在 ZHEN、JA-EN 和 FR 上的表现优于基于 GNN 的新颖无监督解决方案 SelfKG 16.2%、7.7% 和 3.8%(ZeroEA 已达到 99.9%) 分别为EN,这表明ZeroEA可以在相同的低资源条件下以更有效的方式对知识图谱的结构和语义信息进行编码。 并且ZeroEA成为EA中新的最先进模型,甚至没有训练过程,展示了ZeroEA在零样本条件下强大的泛化能力。
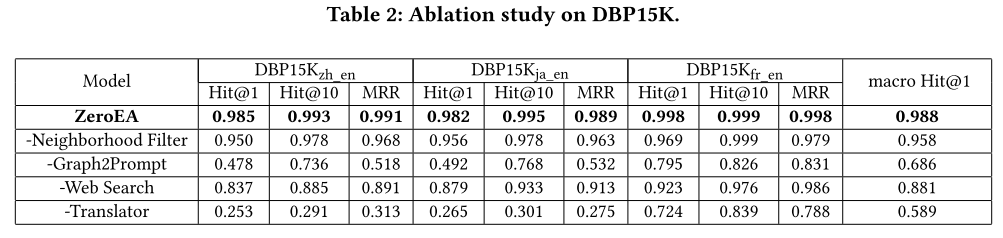
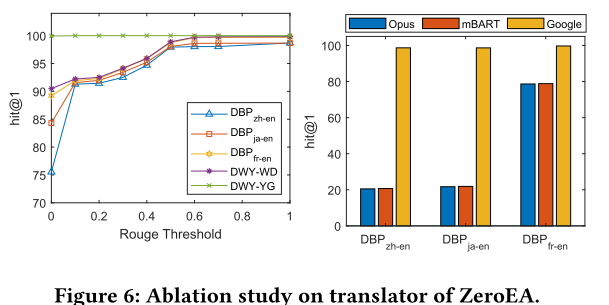
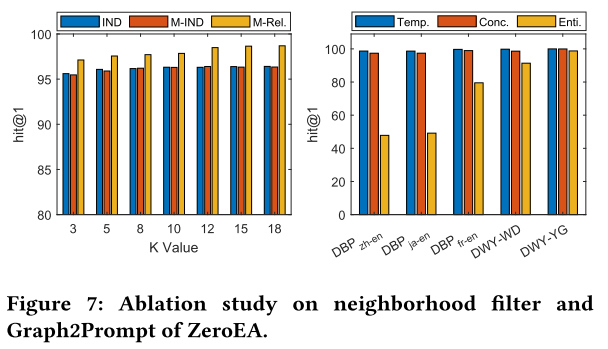
4.2.2 消融研究。 (1) 如果没有我们提出的模型的基础 Graph2Prompt,性能会急剧下降约 50%。这表明预训练语言模型 (PLM) 擅长处理文本数据而不是结构化图形数据。如果没有 Graph2Prompt,我们的模型在实体对齐任务中将表现不佳。(2)当去除邻域过滤模块时,性能从2.7%降低到3.8%,表明motif带来的高阶信息对于EA任务非常有利。(3) 网络搜索工具的性能下降了 4.6% 至 15%,这表明其处理低质量翻译噪音的强大能力以及拥有有限结构和语义信息的实体比例相当大。正如中所指出的,DBP15k 中大约 40% 的实体的度数小于5,因此拥有有限的结构信息。这一观察结果强调了利用外部知识来补充单个知识图(KG)中不完整信息的重要性,最终有利于依赖这些知识的任务。(4)去掉Translator工具后,性能下降很大,甚至下降70%以上。这种减少与两种语言之间的相似性相关。它表明 BERT 处理低资源(即非英语)语言的能力有限。
4.2.3 自动工具的使用。(1) 如前所述,我们采用 Rouge 评分来衡量翻译质量。图6显示了随着Rouge阈值增加的性能趋势,转折点在0.5,这意味着当在较少实体上应用Web搜索但性能相似时,将Rouge阈值设置为0.5是最有效的。 (2)如图6所示,当使用小型基于Transformer的机器翻译时,性能极低,因为它可以翻译大多数实体; 然而,当采用谷歌翻译时,它可以生成任何文本的翻译,性能变得合理。
4.2.4 误差分析。我们使用具有挑战性的 ZH-EN DBP15K 数据集对 ZeroEA 的错误进行了详细调查。在 136 个错误中,确定了三种主要类型。大多数错误翻译(68.5%)会导致嵌入的显着偏差和错误的预测。例如,“Divas in Distress”被误译为“wanna mama…”,“Sukhoi PAK FA”被误译为“KAI T50 Golden Eagle”。第二种类型是低度实体(18%),由于网络搜索差异和稀疏结构信息而难以进行编码。一个例子是“Teledifusão deMacau S.A.”,其实体名称为“TDM”,需要更多的结构上下文才能准确识别。第三种错误类型是错误的标签(6%),例如“Kvitrafn”和“Einar Selvik”的错位。 最后,错误的 WebSearch 调用 (11%) 可能会引入不相关的数据,增加模型的不确定性。最后一种类型是糟糕的 WebSearch 调用 (11%)。不良的 WebSearch 调用可能会注入不相关的知识,从而增加实体对模型的不确定性。
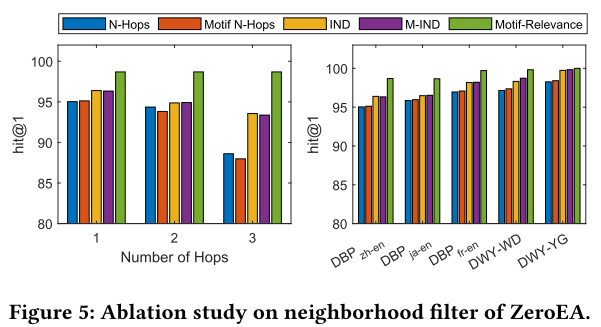
4.2.5 邻域过滤器。 正如第 3.1.1 节中提到的,我们有四个基线和我们提出的邻域过滤方法。在这项研究中,我们将我们的基序相关邻域过滤器与五个基准数据集上的四个基线进行比较。我们的研究结果表明,基于基序的 n-hop 邻居和选择 n-hop 邻居表现出相当的性能。IND 和 M-IND 的卓越性能可归因于它们通过选择具有最高重要性值的 k 邻居来处理冗长的 PLM 输入的能力。我们的基序相关性策略始终优于基线,支持贡献值应由两个节点之间的相关性确定的假设。 在我们所有的数据集中,我们使用“三角形”作为我们的 m o t i f ( Δ ) \mathrm{motif}\left(\Delta\right) motif(Δ)。 这是因为 Δ \Delta Δ的实例非常丰富,如表3所示。而且,基于[40]中的算法,计算 Δ \Delta Δ实例的开销很小,只需要1到4秒(表3)。 我们还指出, Δ \Delta Δ常用于基于基序的分析。
4.2.6 可扩展性和效率。 ZeroEA 的主要贡献之一来自于它的模型可扩展性。为了令人信服地证明 ZeroEA 的可扩展性,我们在不同大小的数据集上进行了广泛的实验,其中包括最大的 EA 数据集之一,即 DBP1M。 该数据集比其他使用的数据集大十到一百倍。这些实验涵盖了三个不同级别的数据集大小。
通过使用小、中、大范围以及单语言和跨语言环境的数据集,我们能够彻底评估 ZeroEA 在扩展到不同数据量时的稳健性。所有其他 EA 基线要么由于超出 GPU 内存限制 (12G) 而无法运行,要么需要超过三天的计算时间。此外,这些方法通常无法处理大型知识图(KG),因为它们的训练过程必须将整个图加载到内存中。相比之下,ZeroEA 旨在通过完全避免训练阶段并每次仅加载与一个目标实体所选的一跳邻域相对应的小子图来绕过这些限制。这种方法有效地将 ZeroEA 的性能与 KG 的大小解耦,从而确认其可扩展至非常大的 KG,而不会遇到其他模型所面临的常见约束。此外,ZeroEA 在这些大型数据集上的准确性评估方面表现良好。在 DBP1M FR−EN 上,ZeroEA 获得 Hit@1= 0.594,Hit@10=0.635,MRR=0.400;在 DBP1M DE−EN 上,ZeroEA 获得 Hit@1= 0.616、Hit@10=0.648 和 MRR=0.395,这也是最先进的。这些结果表明,ZeroEA 不仅可以有效扩展,而且可以在各种数据集类别(包括跨语言、单语言和超大规模子集)中保持最先进的性能。
4.3 Downstream Task Application: Text-to-SQL
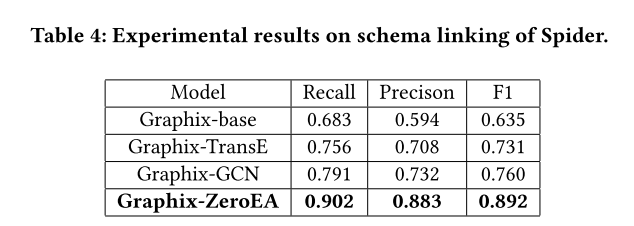
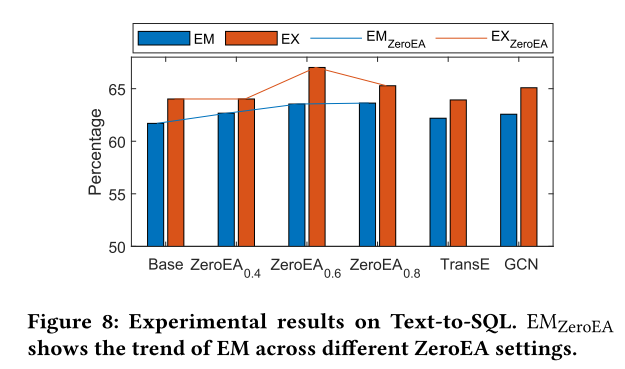
图 8 显示了 SPIDER 数据集上的文本到 SQL 性能,配备了各种 EA 增强模式链接。Base 表示称为 Graphix-base 的普通模型,而 ZeroEA_𝛼 表示带有用于包含新关系的 𝛼 阈值的 Graphix-base 模型。我们的结果表明:(a) 使用 ZeroEA 的 Graphix-base 模型在下游任务中优于标准 Graphix-base 模型,当阈值设置为 0.6 时实现最佳性能。 (b) 此外,表 4 显示 EA 为基于 Graphix 的模型的模式链接提供了最显着的增强。© 值得注意的是,模式链接 F1 与最终文本到 SQL 的性能之间存在明显的正相关性,如图 8 所示。这表明 EA 可以使下游任务受益,从而激发对其进行进一步探索。 对下游各项任务的影响。
5 RELATEDWORKS
近几十年来的实体对齐研究可以分为基于规则的、基于众包的、深度学习(DL)和基于PLM的方法。基于深度学习的方法,特别是基于嵌入的策略,已经表现出优越的性能。这些方法通常使用 TransE 来训练 KG嵌入,但较新的方法考虑 KG 结构并使用图神经网络或基于注意力的机制。最近的一些工作侧重于多模式 EA,例如 MEAformer。有些还结合了语义信息或属性值以提高性能。然而,PLM 培训成本高昂且耗时,因此我们的工作旨在使用 KG 中的结构和语义信息,而无需进行大量培训。
尽管实体对齐 (EA) 任务取得了进展,但它们对下游任务(例如文本到 SQL 中的模式链接和基于知识图的问答 (KGQA) )的影响尚未得到充分研究。 EA 对于这些复杂的任务至关重要,通过精确的实体对齐可以显着改善这些任务。 我们是第一个研究 EA 对下游任务影响的人。
6 CONCLUSION
我们介绍 ZeroEA,这是一种新颖的实体对齐 (EA) 零训练框架,它巧妙地利用了预训练语言模型的上下文编码功能。ZeroEA 可以通过 Graph2Prompt 模块和基于基序的邻域过滤器熟练地合并来自知识图谱的语义和结构信息。在五个基准数据集上取得的实验结果不仅将 ZeroEA 定位为前沿解决方案,而且凸显了其增强复杂下游任务的潜力,并为知识图谱研究的持续进展做出贡献。未来,我们计划开发ZeroEA的训练版本,它可以以更长的训练时间为代价获得更高的性能。我们在 GitHub 存储库中报告了初步结果,并计划在未来进一步开发它。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











