







Paper: Mou L, Chen J K, Wang Y X. Instruct 4D-to-4D: Editing 4D Scenes as Pseudo-3D Scenes Using 2D Diffusion[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 20176-20185.
Introduction: https://immortalco.github.io/Instruct-4D-to-4D/
Code: https://github.com/Friedrich-M/Instruct-4D-to-4D/

\quad 光流 (Optical Flow) 指的是在连续时间帧之间物体表面上像素的运动,可以用来描述图像中每个点的移动速度和方向,通常用于视频分析、运动检测、目标跟踪等任务。
\quad 光流的基本假设是:在小的时间间隔内,场景中的物体不会发生大的变化,且亮度保持不变。通过分析相邻帧之间的像素变化,光流算法可以估计出物体的运动。常用的光流算法包括:
- Lucas-Kanade 方法:假设在一个小的邻域内,运动是恒定的,适合于处理小范围的运动。
- Horn-Schunck 方法:通过全局优化的方式,考虑到图像的平滑性,适合于处理大范围的运动。
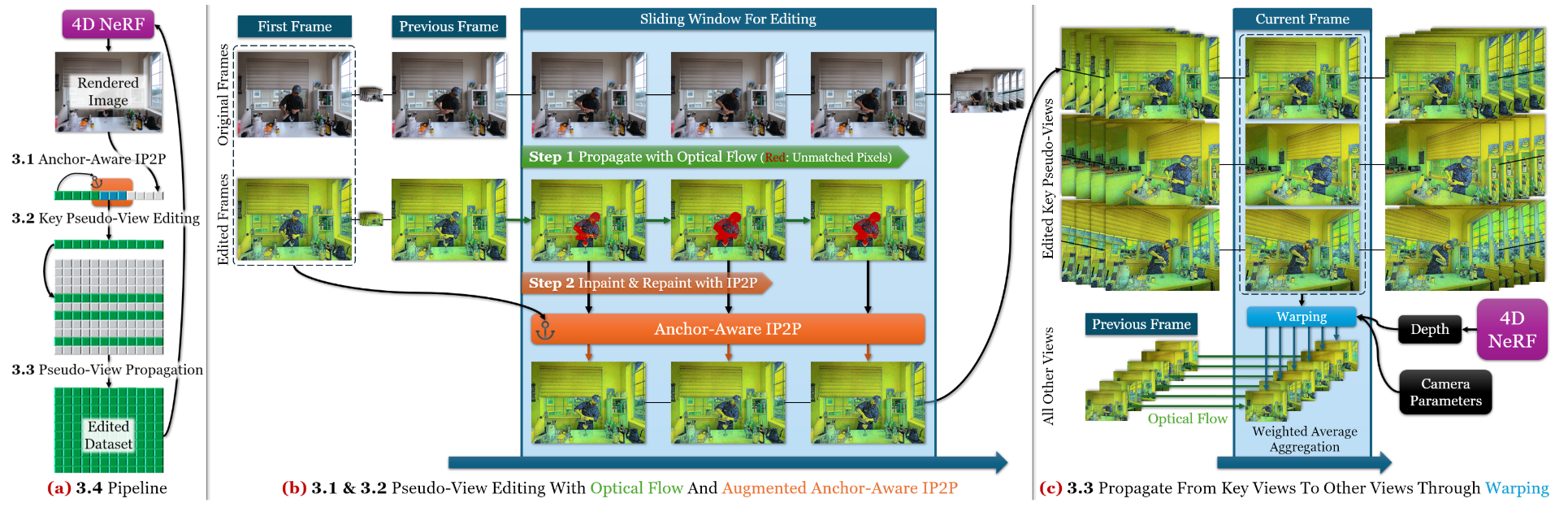
Instruct 4D-to-4D 将 4D 场景视为伪 3D 场景,并将 4D 场景编辑解耦为两个子问题:一是确保视频编辑的时间一致性,二是将这些编辑应用到伪 3D 场景。Instruct 4D-to-4D 为 Instruct-Pix2Pix 模型增加一个锚点感知注意力模块,以支持批量处理和一致性编辑。然后引入光流引导的外观传播方法,采用滑动窗口方式进行更精确的帧间编辑,并结合基于深度的投影来处理伪3D场景中的大量数据,最后通过迭代编辑实现收敛。Instruct 4D-to-4D 为 2D Diffusion 引入了 4D 感知和时空一致性,能够生成高质量的指令引导动态场景编辑结果。
复现
- 平台:本地服务器
- 显卡:RTX 3090 24G * 2
- 镜像:----
- 源码:https://github.com/Friedrich-M/Instruct-4D-to-4D
实验过程:
-
克隆仓库后,按照 README 创建虚拟环境
instruct4d并安装依赖。随后安装编辑过程中需要用到的diffusers:pip install --upgrade diffusers accelerate transformers; -
下载数据集后,使用
tools/prepare_video.py处理数据集:python tools/prepare_video.py data/neural_3d/coffee_martini;
如果遇到sh: 1: ffmpeg: not found报错,需要先更新apt-get然后安装ffmpeg1:sudo apt-get update sudo apt-get install ffmpeg -
因为服务器上有好几张卡,训练过程中总是因为
RuntimeError: Expected all tensors to be on the same device, but found at least two devices而中断:
 设置环境变量
设置环境变量 CUDA_VISIBLE_DEVICES指定可用的 GPU 即可:export CUDA_VISIBLE_DEVICES=4,5; -
然后就可以训练场景:
python stream_train.py --config configs/n3dv/train_coffee_50_2.txt --datadir data/neural_3d/coffee_martini --basedir log/neural_3d --render_test 1 --render_path 1;
训练完成后会自动评估指标,如果因为网络问题下载节点失败,可以手动下载:wget -P /path/to/cache https://download.pytorch.org/models/alexnet-owt-7be5be79.pth; -
编辑场景时需要 2 块 GPU,否则会出现
RuntimeError: CUDA error: invalid device ordinal报错。如果遇到Missing Stable Diffusion packages报错,应该是diffusers安装错误,可以在 python 交互终端中import diffusers寻找问题出处。然后又遇到module 'torch' has no attribute 'float8_e4m3fn'报错:
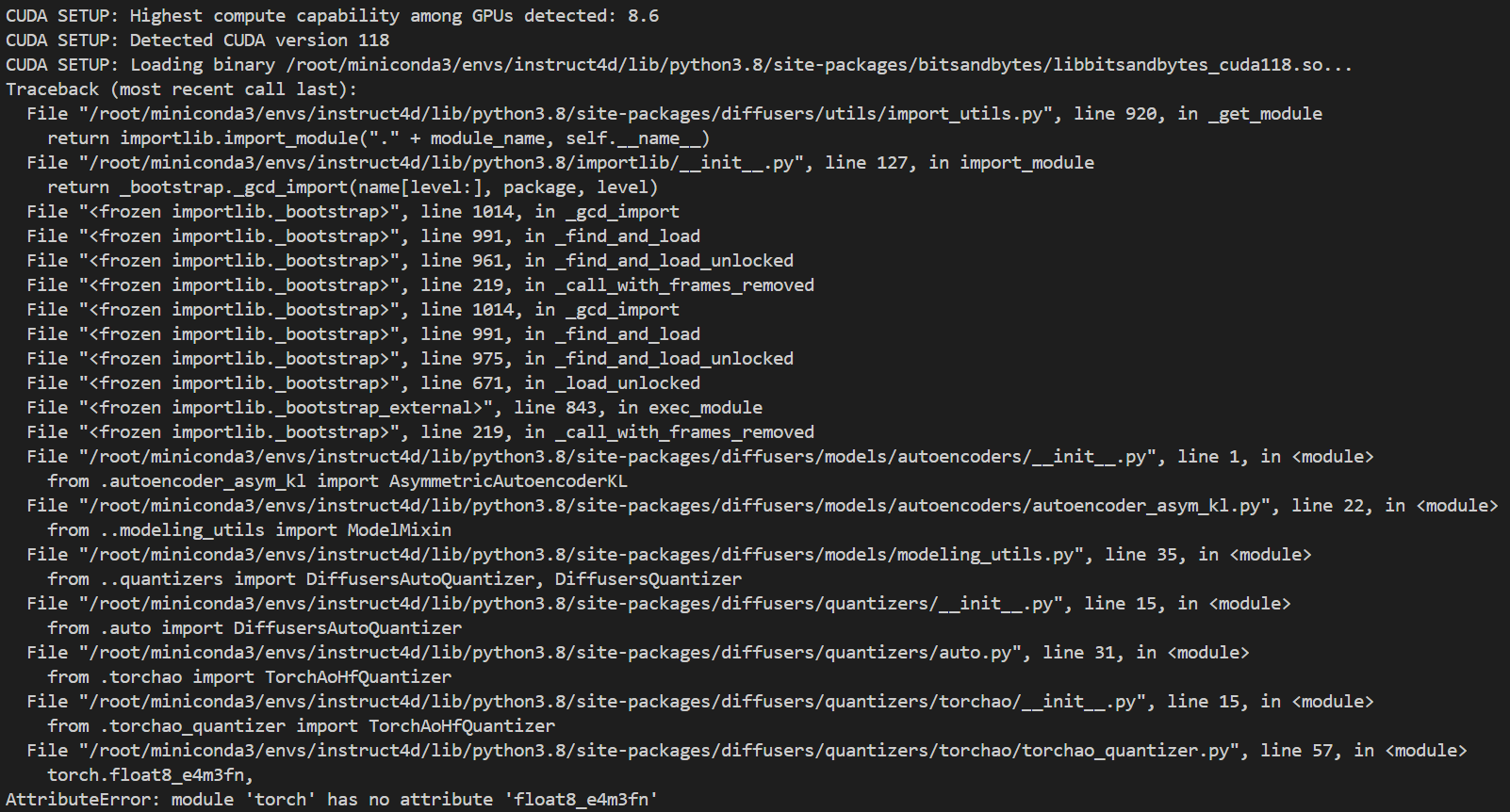
更新 pytorch 即可 2:pip install --upgrade torch torchvision torchaudio -r requirements.txt; -
此前已经设置了环境变量
CUDA_VISIBLE_DEVICES,现在可以直接编辑场景:python stream_edit.py --config configs/n3dv/edit_coffee_50_2.txt --datadir data/neural_3d/coffee_martini --basedir log/neural_3d --expname edit_coffee_50_2 --ckpt log/neural_3d/train_coffee_50_2-20240902-102206/ckpt-99999.th --prompt 'What if it was painted by Van Gogh?' --guidance_scale 9.5 --image_guidance_scale 1.5 --diffusion_steps 20 --refine_num_steps 600 --refine_diffusion_steps 4 --restview_refine_num_steps 700 --restview_refine_diffusion_steps 6;
实验结果:
原始场景:
Instruct-4D-to-4D原始场景
Turn the man into spiderman.
Instruct-4D-to-4D编辑场景1
What if it was painted by Van Gogh?
Instruct-4D-to-4D编辑场景2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









