







· 交互效应模型——定性与定量变量的交互效应
· Example8. 在example.6的模型中,female组与male组的回归函数是两条平行的直线,即它们的斜率——教育程度
e
d
u
c
educ
educ对薪资
w
a
g
e
wage
wage的偏效应是恒定的,这意味着性别不会对教育的边际回报产生影响。而如果我们想在模型体现或验证两者会相互影响,则可以在原模型中加入交互项
f
e
m
a
l
e
∗
e
d
u
c
female*educ
female∗educ
wage
=
β
0
+
δ
0
female
+
β
1
educ
+
δ
1
female
∗
educ
+
u
\text { wage }=\beta_{0}+\delta_{0} \text { female }+\beta_{1} \text { educ }+\delta_{1} \text { female } * \text { educ }+u
wage =β0+δ0 female +β1 educ +δ1 female ∗ educ +u
E
(
wage|male
,
e
d
u
c
)
=
β
0
+
β
1
e
d
u
c
E(\text { wage|male }, e d u c)=\beta_{0}+\beta_{1} e d u c
E( wage|male ,educ)=β0+β1educ
E
(
wage|female
,
e
d
u
c
)
=
β
0
+
δ
0
+
(
β
1
+
δ
1
)
e
d
u
c
E(\text { wage|female }, e d u c)=\beta_{0}+\delta_{0}+\left(\beta_{1}+\delta_{1}\right) e d u c
E( wage|female ,educ)=β0+δ0+(β1+δ1)educ
对于这个模型,我们可以做两种假设检验:
1、检验男性与女性的边际教育回报是否相同。这等价于检验假设
H
0
:
δ
1
=
0
↔
H
1
:
δ
1
≠
0
H_{0}: \delta_{1}=0 \leftrightarrow H_{1}: \delta_{1} \neq 0
H0:δ1=0↔H1:δ1=0
2、检验男性与女性的平均工资是否存在性别差异。这等价于检验假设
H
0
:
δ
0
=
δ
1
=
0
↔
H
1
:
∃
δ
j
≠
0
,
j
=
0
,
1
H_{0}: \delta_{0}=\delta_{1}=0 \leftrightarrow H_{1}: \exists \delta_{j} \neq 0, j=0,1
H0:δ0=δ1=0↔H1:∃δj=0,j=0,1
显然,对于第一个问题,我们可以使用t检验;对于第二个问题,我们可以使用F检验
直接根据报告表做t检验
wage1_lm3=sm.formula.ols('lwage~female+educ+I(female*educ)+exper+I(exper**2)+tenure+I(tenure**2)',data=wage1).fit()
print(wage1_lm3.summary())
# 使用anova函数做F检验
wage1_lm3_r=sm.formula.ols('lwage~educ+exper+I(exper**2)+tenure+I(tenure**2)',data=wage1).fit()
anova_lm(wage1_lm3_r,wage1_lm3)
t检验结果表明,两性之间教育边际回报相等的假设是不能被拒绝,即两性边际回报可以认为是相等的;但是F检验结果是非常显著的,即两性存在薪资差异。这可能能说明引起两性收入不平等的原因并非来自教育程度。
多分类变量
多分类变量相比于二分类变量也更难处理,我们不能用一个变量的多个取值来定义多分类虚拟变量。如,我们不可以定义季节变量 s e a s o n season season的取值1/2/3/4为春/夏/秋/冬,因为这意味着不同分类之间的差异完全取决于取值之间的差!
正确做法是,用多个二值虚拟变量来表示多分类定性变量。具体的,如果一个变量有n个类别,则需要定义n-1个虚拟变量表示它。以季节变量为例,我们定义三个虚拟变量:spring/summer/fall,当它们其中之一等于1时,代表季节为它们本身;而如果它们全都为0,则代表季节为winter。
· 虚拟变量陷阱——完全共线性
之所以需要这样定义多分类定性变量,是因为如果我们如果将winter也纳入模型中时,这四个变量会满足一个恒等关系式
s
p
r
i
n
g
+
s
u
m
m
e
r
+
f
a
l
l
+
w
i
n
t
e
r
=
1
spring+summer+fall+winter=1
spring+summer+fall+winter=1
这说明这四个自变量存在完全共线性,违背了CLM假设中的MLR.4,使得模型完全失效。
- 如何将一个多分类变量“分解”为多个0-1虚拟变量
- 分解成多个虚拟0-1变量后,如何用这些变量进行回归而不踩雷。
· Example9. 我们对某大公司的计算机专业人员进行薪水调查,调查的目的是识别和量化哪些影响薪水差异的因素,数据中的变量描述如下:
S:年薪,单位是美元;
X:工作经验,单位是年;
E:教育,1表示高中毕业,2表示获得学士学位,3表示更高学位;
M:1表示为管理人员,0表示非管理人员;
我们以S为因变量,以X/E/M为自变量进行多元回归。其中:X为定量变量,M为二分类变量(且已经0-1化),它们已经可以直接进行回归处理了。但是E则需要进行0-1处理。
现在我们对E进行虚拟变量编码,这也叫One-hot编码。我们使用pandas包的get_dummies函数进行重编码。
在对E进行重编码前,我们先花一点时间介绍一下get_dummies这一函数,让大家明白这个函数的工作原理。该函数会自动变换所有具有对象类型(如字符串)的列,但是如果某列的变量是数值型变量(哪怕它实际上是分类变量),它将不会为该列创建虚拟变量,除非我们将该列的数据类型从数值转化为字符串。
# 使用get_dummies函数
display(pd.get_dummies(demo_df))
print(type(demo_df.Interger_Feature[0]))
demo_df['Interger_Feature']=demo_df['Interger_Feature'].astype(str)
pd.get_dummies(demo_df,columns=['Interger_Feature']) # 指定columns参数,就可以对我们想要虚拟变量化的列进行精准转换
#重编码
data['E']=data['E'].astype(str)
data_dummies=pd.get_dummies(data,columns=['E'])
data_dummies.head()
我们已经将变量E转化为了三个虚拟变量,现在可以进行回归了。注意:不可以直接将三个虚拟变量同时纳入回归当中,我们可以选取一个虚拟变量作为“基组”,然后将其他非基组的虚拟变量纳入回归。这里我们选取高中教育水平
E
=
1
E=1
E=1作为基组,则方程可以这样构建
S
=
β
0
+
β
1
X
+
γ
2
E
2
+
γ
3
E
3
+
δ
1
M
+
u
S=\beta_{0}+\beta_{1} X+\gamma_{2} E_{2}+\gamma_{3} E_{3}+\delta_{1} M+u
S=β0+β1X+γ2E2+γ3E3+δ1M+u
data_lm=sm.formula.ols('S~X+E_2+E_3+M',data=data_dummies).fit()
print(data_lm.summary())
带有自变量函数的回归分析
所谓自变量函数,其实就是将原自变量进行一种变换。变换后的变量一方面可能使模型对数据的拟合效果更佳;另一方面也可以满足一些我们实际的数据分析需求。在这一章节,我们简单介绍三种常见的自变量函数:对数化、二次项化、交互项化。
对数化
我们考虑一般地模型
log
(
y
)
=
β
0
+
β
1
log
(
x
1
)
+
β
2
x
2
+
u
\log (y)=\beta_{0}+\beta_{1} \log \left(x_{1}\right)+\beta_{2} x_{2}+u
log(y)=β0+β1log(x1)+β2x2+u
对于因变量与自变量同为对数的系数,其满足如下公式
β
1
≈
Δ
y
/
y
Δ
x
1
/
x
1
⇒
Δ
y
y
≈
β
1
Δ
x
1
x
1
\beta _1\approx \frac{\Delta y/y}{\Delta x_1/x_1}\Rightarrow \frac{\Delta y}{y}\approx \beta _1\frac{\Delta x_1}{x_1}
β1≈Δx1/x1Δy/y⇒yΔy≈β1x1Δx1
约等号两边都以增量比例的形式代表增量,于是我们可以将之解读为:在其他因素不变的条件下,
x
1
x_1
x1每增加1%,
y
y
y会增加
β
1
%
\beta_1\%
β1%。
而对于因变量与自变量一个为对数一个不为对数的系数,以上述模型
β
2
\beta_2
β2为例,其满足如下公式
β
2
≈
Δ
y
/
y
Δ
x
2
⇒
Δ
y
y
≈
β
2
Δ
x
2
\beta _2\approx \frac{\Delta y/y}{\Delta x_2}\Rightarrow \frac{\Delta y}{y}\approx \beta _2\Delta x_2
β2≈Δx2Δy/y⇒yΔy≈β2Δx2
约等号一边为纯增量,一边为增量比例的形式,对于该模型我们可以将之解读为:在其他因素不变的条件下,
x
2
x_2
x2每增加1个单位,
y
y
y会增加
β
2
%
\beta_2\%
β2%。
严格地说,对数化变量系数的解读并没有上面这么简单,上面的解读方法只是一种近似,但是一般情况下我们不用考虑得那么严格。
它的作用非常明显:
- 正如上面的例子所示,对数变换可以方便地计算变换百分比,于“价格”型变量而言,百分比解释比绝对值解释更有经济意义。
- 当因变量为严格取正的变量,它的分布一般存在异方差性或偏态性,这容易违背CLM假设的同方差/正态性假设。而对数变换可以缓和这种情况。
然而,对数变换并不能滥用,因为在一些情况下对数变换会产生极端值。首先,存在负值的变量不可以对数变换;其次,当原变量 y y y有部分取值位于[0,1]区间时, l o g ( y ) log(y) log(y)的负数值会非常大!而线性模型对极端值是非常敏感的,这会影响模型的效果。
- 对于大数值大区间变量(价格类变量、人口变量等),可取对数变换,如:工资、薪水、销售额、企业市值、人口数量、雇员数量等。
- 对于小数值小区间变量(时间类变量等),一般不取对数变换,如:受教育年限、工作年限、年龄等。
# 对数化对正态化的作用
## 以hprice1的price为例
### 未经对数化的直方图
hprice1.hist(column='price',figsize=(8,6))
### 对数化后的直方图
hprice1.hist(column='lprice',figsize=(8,6))
二次项
· Example10. 直觉上看,职场里资历越老的人工资水平就越高,于是我们想知道某公司内员工工资水平与单位工作年限之前的关系。很自然地,我们会把模型简单地假设为
w
a
g
e
=
β
0
+
β
1
e
x
p
e
r
+
u
wage=\beta _0+\beta _1exper+u
wage=β0+β1exper+u
经验告诉我们,随着工作年限的上升,工资提升会逐渐变缓。也就是说,工作年限对工资水平的影响可能不是线性的,而是有一个“弧度”。如何让模型具备这个“弧度”呢?最简单也是最直观的方法就是,在原模型的基础上加入二次项
w
a
g
e
=
β
0
+
β
1
e
x
p
e
r
+
β
2
e
x
p
e
r
2
+
u
wage=\beta _0+\beta _1exper+\beta _2exper^2+u
wage=β0+β1exper+β2exper2+u
假设经过OLS估计后,模型为
wage
^
=
3.73
+
0.298
exper
−
0.006
exper
2
\widehat{\text { wage }}=3.73+0.298 \text { exper }-0.006 \text { exper }^{2}
wage
=3.73+0.298 exper −0.006 exper 2
总结:如果我们在回归建模前认为某个自变量对因变量的影响不是线性的,可以尝试加入二次项,并观察二次项的显著性。如果显著,就说明两者关系确实为非线性的。
交互项
· Example11. 我们用出勤百分比atndrte,读大学前的GPA、ACT来解释一批学生期末考试标准化的成绩。有人认为对于过去成绩不同的学生,出勤率可能具有不同的影响,于是我们在模型中加入两者的交互项
s
t
n
d
f
n
l
=
β
0
+
β
1
a
t
n
d
r
t
e
+
β
2
p
r
i
G
P
A
+
β
3
A
C
T
+
β
4
p
r
i
G
P
A
2
+
β
5
A
C
T
2
+
β
6
p
r
i
G
P
A
⋅
a
t
n
d
r
t
e
+
u
\,\,\mathrm{stndfnl} =\beta _0+\beta _1\,\,\mathrm{atndrte} +\beta _2\,\,\mathrm{priGP} A+\beta _3ACT+\beta _4priGPA^2+\beta _5ACT^2+\beta _6priGPA\cdot \,\,\mathrm{atndrte} +u \\
stndfnl=β0+β1atndrte+β2priGPA+β3ACT+β4priGPA2+β5ACT2+β6priGPA⋅atndrte+u
在这里我们想提醒一下大家,在没有学习交互项、二次项的时候,我们会说自变量
x
i
x_i
xi的系数
β
i
\beta_i
βi是其对因变量
y
y
y的偏效应,这是因为在全为一次项的模型中,
Δ
y
Δ
x
i
\frac{\Delta y}{\Delta x_i}
ΔxiΔy就等于系数
β
i
\beta_i
βi。而加入了交互项、二次项后,我们对存在交互项、二次项的自变量的系数解释就不会那么简单了。我们更关注问题的本质——
x
i
x_i
xi对因变量
y
y
y的偏效应是多少,对于本例而言,出勤率对成绩的偏效应如下所示
Δ
stndfnl
Δ
a
t
n
d
r
t
e
=
β
1
+
β
6
priGPA
\frac{\Delta \text { stndfnl }}{\Delta a t n d r t e}=\beta_{1}+\beta_{6} \text { priGPA }
ΔatndrteΔ stndfnl =β1+β6 priGPA
可见,
p
r
i
G
P
A
priGPA
priGPA在不同取值下,出勤率对成绩的影响是不一样的。其实有了这个公式,我们可以计算出
p
r
i
G
P
A
priGPA
priGPA在不同取值下,出勤率对成绩偏效应的具体值,这一任务非常简单。但是涉及交互问题的假设检验就相对复杂一点,也非常有趣。通常来说,这类问题假设检验有如下两个
- 出勤率对成绩的影响是否显著?对于这一问题,假设需要设置成这样
H 0 : β 1 = β 6 = 0 ↔ H 1 : H 0 不成立 H_0: \beta _1=\beta _6=0 \leftrightarrow \,\,H_1: H_0\text{不成立} H0:β1=β6=0↔H1:H0不成立
很明显,我们用F检验即可。
# 构建有约束、无约束模型
attend_lm_ur=sm.formula.ols('stndfnl~atndrte+priGPA+ACT+I(priGPA**2)+I(ACT**2)+I(priGPA*atndrte)',data=attend).fit()
attend_lm_r=sm.formula.ols('stndfnl~priGPA+ACT+I(priGPA**2)+I(ACT**2)',data=attend).fit()
# F检验
display(anova_lm(attend_lm_r,attend_lm_ur))
print('结果显著,可以拒绝原假设')
- 当 p r i G P A priGPA priGPA为一个具体的值时,出勤率在这个值下对对成绩的影响是否显著?
这个问题非常有趣,要回答这个问题,我们需要对原模型做一些小改变。假设我们想验证
p
r
i
G
P
A
=
2.59
priGPA=2.59
priGPA=2.59时出勤率的显著性,我们需要将原来的
a
t
n
d
r
t
e
atndrte
atndrte修改为
a
t
n
d
r
t
e
−
2.59
atndrte-2.59
atndrte−2.59。模型也将变成
s
t
n
d
f
n
l
=
β
0
+
β
1
a
t
n
d
r
t
e
+
β
2
(
G
P
A
−
2.59
)
+
β
3
A
C
T
+
β
4
(
p
r
i
G
P
A
−
2.59
)
2
+
β
5
A
C
T
2
+
β
6
(
p
r
i
G
P
A
−
2.59
)
⋅
a
t
n
d
r
t
e
+
u
\,\,\mathrm{stndfnl}=\beta _0+\beta _1\,\,\mathrm{atndrte}+\beta _2\,\left( GPA-2.59 \right) +\beta _3ACT+\beta _4\left( priGPA-2.59 \right) ^2+\beta _5ACT^2+\beta _6\left( priGPA-2.59 \right) \cdot \,\,\mathrm{atndrte}+u
stndfnl=β0+β1atndrte+β2(GPA−2.59)+β3ACT+β4(priGPA−2.59)2+β5ACT2+β6(priGPA−2.59)⋅atndrte+u
我们根据这个模型求偏导会有
Δ
stndfnl
Δ
a
t
n
d
r
t
e
=
β
1
+
β
6
(priGPA-2.59)
\frac{\Delta \text { stndfnl }}{\Delta a t n d r t e}=\beta_{1}+\beta_{6} \text { (priGPA-2.59) }
ΔatndrteΔ stndfnl =β1+β6 (priGPA-2.59)
当
a
t
n
d
r
t
e
=
2.59
atndrte=2.59
atndrte=2.59时,偏效应正好就是
β
1
\beta_1
β1!我们只需要查看这个模型的
β
1
\beta_1
β1显著性就可以回答这一假设检验问题了。
attend['priGPA2']=attend['priGPA']-2.59
attend_lm2=sm.formula.ols('stndfnl~atndrte+priGPA2+ACT+I(priGPA2**2)+I(ACT**2)+I(priGPA2*atndrte)',data=attend).fit()
print(attend_lm2.summary())
print('结果显著,可以拒绝原假设')
5. CLM假设误差分析
5.1 OLS估计另一种更为常用的求解方法
5.1.1 解法步骤
该部分仅作了解即可。
我们以求回归模型
y
=
β
0
+
β
1
x
1
+
⋯
+
β
k
x
k
+
u
y=\beta_{0}+\beta_{1} x_{1}+\cdots+\beta_{k} x_{k}+u
y=β0+β1x1+⋯+βkxk+u
中
β
1
\beta_1
β1为例,大体上可分为两步
· step 1,以
x
1
x_1
x1做因变量,对其他自变量做回归
x
1
=
α
0
+
α
2
x
2
+
⋯
+
α
k
x
k
+
r
1
x_{1}=\alpha_{0}+\alpha_{2} x_{2}+\cdots+\alpha_{k} x_{k}+r_{1}
x1=α0+α2x2+⋯+αkxk+r1
记残差为
r
^
1
=
(
r
^
11
,
r
^
21
,
⋯
,
r
^
n
1
)
′
\hat{r}_{1}=\left(\hat{r}_{11}, \hat{r}_{21}, \cdots, \hat{r}_{n 1}\right)^{\prime}
r^1=(r^11,r^21,⋯,r^n1)′
· step 2,
y
y
y对残差
r
^
1
\hat{r}_{1}
r^1做过原点(无截距)的回归
y
=
γ
r
^
1
+
u
y=\gamma \hat{r}_{1}+u
y=γr^1+u
可以证明,
β
1
\beta_1
β1的估计就是
y
^
\hat{y}
y^
γ
^
=
β
^
1
=
∑
i
=
1
n
r
^
i
1
y
i
∑
i
=
1
n
r
^
i
1
2
\hat{\gamma}=\hat{\beta}_1=\frac{\sum_{i=1}^n{\hat{r}_{i1}}y_i}{\sum_{i=1}^n{\hat{r}_{i1}^{2}}}
γ^=β^1=∑i=1nr^i12∑i=1nr^i1yi
我们仔细品味一下
β
1
\beta_1
β1的求解过程,会发现它非常符合我们对回归模型系数的理解——在第一步的自变量回归中,残差
r
^
1
\hat{r}_{1}
r^1相当于是在
x
1
x_1
x1中排除了
x
2
x_2
x2,……,
x
n
x_n
xn影响后的剩余部分,因此
β
^
1
\hat{\beta}_1
β^1相当于在度量排除了其余自变量影响后,
x
1
x_1
x1对
y
y
y的影响。而我们回想一下之前我们对
β
1
\beta_1
β1的解释有一个重要的前置语:“在其他自变量不变的前提下”,这恰恰就是排除其他变量的影响的含义。
看看这种求解方法的结果和之前的求解方法是否一致。
# 以gpa_lm2的ACT系数为例
# 常规解法的结果
print('常规解法的结果:')
display(c2)
print('-------------------------------------------')
# 新求解法
gpa_lm2_pre=sm.formula.ols('ACT~hsGPA',data=gpa1).fit()
gpa1['resid']=gpa_lm2_pre.resid
gpa_lm2_pre2=sm.formula.ols('colGPA~resid-1',data=gpa1).fit()
print('新解法的效果')
print(gpa_lm2_pre2.params[0])
5.1.2 估计系数的方差构成与多重共线性
在MLR.1~MLR.5下,
Var
(
β
^
1
)
\operatorname{Var}\left(\hat{\beta}_{1}\right)
Var(β^1)可计算为
Var
(
β
^
1
)
=
σ
2
∑
i
=
1
n
r
^
i
1
2
=
σ
2
S
S
T
1
(
1
−
R
1
2
)
\operatorname{Var}\left(\hat{\beta}_{1}\right)=\frac{\sigma^{2}}{\sum_{i=1}^{n} \hat{r}_{i 1}^{2}}=\frac{\sigma^{2}}{S S T_{1}\left(1-R_{1}^{2}\right)}
Var(β^1)=∑i=1nr^i12σ2=SST1(1−R12)σ2
中, S S T 1 = ∑ i = 1 n ( x i 1 − x ˉ 1 ) 2 S S T_{1}=\sum_{i=1}^{n}\left(x_{i 1}-\bar{x}_{1}\right)^{2} SST1=∑i=1n(xi1−xˉ1)2为 x 1 x_1 x1变量本身的完全平方和, R 1 2 R_{1}^{2} R12是 x 1 x_1 x1对其他解释变量所作回归的拟合优度判决系数, σ 2 \sigma^{2} σ2则是之前提及的随机误差的方差。至此,回归系数估计方差的构成就结构完毕了,它依赖于三个因素:
· 误差方差 σ 2 \sigma^{2} σ2,随机误差的方差可以理解为数据集的噪声信息,噪声信息越多,估计的不确定性就越大,方差就越大,这点很顺理成章!但是一般来说,对于给定的数据集,误差方差也是随之确定的,我们一般不会在这个因素上下文章。
· 自变量 x 1 x_1 x1本身的总变异 S S T 1 SST_1 SST1,自变量总变异越大,表明自变量散步程度越高,估计越牢靠。关于这个指标,我们会发现:对于一个分析任务来说,样本量越大,总变异也就越大,进而估计方差会变小,这告诉我们更多的随机样本有利于提高估计的精度!
· 自变量间的线性关联程度
R
1
2
R_{1}^{2}
R12,
R
1
2
R_{1}^{2}
R12约接近1,
x
1
x_1
x1与其他自变量之间的线性关系就越强烈,估计方差也越大。这种近似的共线性关系被称为多重共线性(multicolinearity),它不同于完全共线性(事实上
R
1
2
=
1
R_{1}^{2}=1
R12=1时就是完全共线性),这种现象在数据分析中普遍存在,只是程度有所区别。那么如何衡量共线性的严重程度呢?我们一般用方差膨胀因子(VIF,Variance Inflation Factor)来评判
V
I
F
x
1
=
1
1
−
R
1
2
VIF_{x1}=\frac{1}{1-R_{1}^{2}}
VIFx1=1−R121
若
V
I
R
>
10
VIR>10
VIR>10,意味着共线性很严重,需要采取措施降低共线性。
一种方法是使变量之间尽可能的不相关,关于这点我们可以查看变量之间的皮尔逊相关系数
二种方法是减少自变量的个数。一般而言,模型中自变量个数越多,R方会越大。而
R
1
2
R_{1}^{2}
R12正是
x
1
x_1
x1对其他自变量做回归的判决系数,显然,其他自变量越多,
R
1
2
R_{1}^{2}
R12就越大。这个方法告诉我们,模型的自变量绝非越多越好
总结一下降低估计方差,提高估计精度的方法
- 采取更合理的数据采样方法,降低数据噪声。
- 增大数据样本量
- 根据线性相关程度筛选纳入模型的变量,且切忌纳入过多变量。
5.2 模型误设的误差分析——违反MLR.1的后果是什么
5.2.1 如何理解模型误设
在MLR.1中,我们假设自己设置的模型是“正确的”,即对
y
=
β
0
+
β
1
x
1
+
β
2
x
2
+
⋯
+
β
k
x
k
+
u
y=\beta_{0}+\beta_{1} x_{1}+\beta_{2} x_{2}+\cdots+\beta_{k} x_{k}+u
y=β0+β1x1+β2x2+⋯+βkxk+u
的假设上,我们正确地纳入了所有关键的自变量,且没有纳入多余的自变量。而多纳入一个无关的变量,以及少纳入一个关键的变量,都能算是违反MLR.1,我们可以看看误设模型对模型中变量系数的估计会有怎样子的影响。
5.2.2 模型误设的后果
· 遗漏相关变量
假设真模型为
y
∼
x
1
+
x
2
+
⋯
+
x
k
−
1
+
x
k
y \sim x_{1}+x_{2}+\cdots+x_{k-1}+x_{k}
y∼x1+x2+⋯+xk−1+xk
但我们实际拟合的模型却是
y
∼
x
1
+
x
2
+
⋯
+
x
k
−
1
y \sim x_{1}+x_{2}+\cdots+x_{k-1}
y∼x1+x2+⋯+xk−1
假设真模型的系数估计记为
β
^
i
\hat{\beta}_{i}
β^i,实际模型的系数估计为
β
~
i
\tilde{\beta}_{i}
β~i,那么有
β
~
1
=
β
^
1
+
β
^
k
δ
~
1
\tilde{\beta}_{1}=\hat{\beta}_{1}+\hat{\beta}_{k} \tilde{\delta}_{1}
β~1=β^1+β^kδ~1
其中,
δ
~
1
\tilde{\delta}_{1}
δ~1是遗漏变量对其余变量的辅助回归
x
k
∼
x
1
+
x
2
+
⋯
+
x
k
−
1
x_{k} \sim x_{1}+x_{2}+\cdots+x_{k-1}
xk∼x1+x2+⋯+xk−1中
x
1
x_1
x1对应的回归系数。我们观察一下
β
~
1
\tilde{\beta}_{1}
β~1的无偏性情况
E
(
β
~
1
∣
x
)
=
β
1
+
β
k
δ
~
1
E\left(\tilde{\beta}_{1} \mid x\right)=\beta_{1}+\beta_{k} \tilde{\delta}_{1}
E(β~1∣x)=β1+βkδ~1
发现,原本正确模型假设下的无偏性
E
(
β
^
1
)
=
β
1
E\left( \hat{\beta}_1 \right) =\beta _1
E(β^1)=β1,因漏设相关变量
x
k
x_k
xk导致多了偏差
β
k
δ
~
1
\beta_{k} \tilde{\delta}_{1}
βkδ~1。
因此,对于遗漏变量 x k x_k xk,除非 β k = 0 \beta_k=0 βk=0(即 x k x_k xk对 y y y完全不影响),或者 δ ~ 1 = 0 \tilde{\delta}_{1}=0 δ~1=0(遗漏变量 x k x_k xk与待分析自变量 x 1 x_1 x1不相关),否则遗漏变量会对我们实际估计模型的系数估计产生有偏影响,即我们的系数估计不再是平均意义上的准确!
假设真模型为
y
∼
x
1
+
x
2
+
⋯
+
x
k
−
1
y \sim x_{1}+x_{2}+\cdots+x_{k-1}
y∼x1+x2+⋯+xk−1
但实际拟合的模型是
y
∼
x
1
+
x
2
+
⋯
+
x
k
−
1
+
x
k
y \sim x_{1}+x_{2}+\cdots+x_{k-1}+x_{k}
y∼x1+x2+⋯+xk−1+xk
且:
x
k
x_k
xk与其余自变量
x
i
x_i
xi存在相关性,但与因变量
y
y
y不存在相关性(即无法对因变量变异做出解释),此时,我们实际拟合的模型相当于是
y
=
β
0
+
β
1
x
1
+
⋯
+
β
k
−
1
x
k
−
1
+
0
x
k
+
u
y=\beta _0+\beta _1x_1+\cdots +\beta _{k-1}x_{k-1}+0x_k+u
y=β0+β1x1+⋯+βk−1xk−1+0xk+u
这种过度设定其实并不违反MLR.1-MLR.4中的任意一条,因为就算将这个无关变量纳入模型,最终拟合出来的变量对应系数也会是0。因此,纳入无关变量这种情况对于建立在前四个假设上的OLS无偏性是没有影响的!即依然有
E
(
β
i
~
)
=
β
i
E\left( \widetilde{\beta _i} \right) =\beta _i
E(βi
)=βi
但是只要
x
k
x_k
xk与其它自变量存在共线性,将其纳入会使其他系数的估计方差变大。以
x
1
x_1
x1的系数为例,假设纳入
x
k
x_k
xk前它的方差是
V
a
r
(
β
^
1
)
=
σ
2
S
S
T
1
(
1
−
R
1
,
k
−
1
2
)
\mathrm{Var}\left( \hat{\beta}_1 \right) =\frac{\sigma ^2}{SST_1\left( 1-R_{1,k-1}^{2} \right)}
Var(β^1)=SST1(1−R1,k−12)σ2
而纳入
x
k
x_k
xk后它的方差就变成了
V
a
r
(
β
~
1
)
=
σ
2
S
S
T
1
(
1
−
R
1
,
k
2
)
\mathrm{Var}\left( \tilde{\beta}_1 \right) =\frac{\sigma ^2}{SST_1\left( 1-R_{1,k}^{2} \right)}
Var(β~1)=SST1(1−R1,k2)σ2
由于而多自变量的模型R方总是大于少自变量模型的R方,即
R
1
,
k
−
1
2
<
R
1
,
k
2
R_{1,k-1}^{2}<R_{1,k}^{2}
R1,k−12<R1,k2
于是最终有
V
a
r
(
β
^
1
)
<
V
a
r
(
β
~
1
)
\mathrm{Var}\left( \hat{\beta}_1 \right) <\mathrm{Var}\left( \tilde{\beta}_1 \right)
Var(β^1)<Var(β~1)
因此,对于增加一个对解释因变量无益的自变量,一旦这个无益自变量与其它自变量存在共线性,则会增大其他估计系数的估计方差!
我们总结一下以上的内容:
- 减少模型中的变量,可能会导致模型其他系数的估计有偏,但是会使系数估计的方差减少,即:增大偏差、减小方差
- 增加模型中的变量,不会导致模型系数估计有偏,但是会使系数估计的方差增大,即:减小偏差、增大方差
而在实际情况中,我们不可能得知一个真正正确的模型,而是在摸索中慢慢找到适合纳入模型的变量。通常来说,有两种考量纳入变量的方法论:
- 从少数变量开始,一步步向模型纳入我们认为重要的变量,并通过t检验显著性来判断是否纳入该变量;如果我们认为变量存在二次项效应与交互项效应,可以将其纳入模型并通过联合F检验判断其显著性,直到模型的解释度达到一个较高的水平。
- 从多数变量开始,一步步将不显著的变量剔除出模型。
这两种方法该用哪一种,视具体情况而定。假若数据集的变量非常多,那我倾向于使用第一种方法,一步步将我们认为重要的变量纳入模型;若变量不多,则第二种方法可以考虑。
对于变量的选择,还有一些自动化的方法,如向前逐步选择、向后逐步选择等等。但我个人认为,这些自动的变量选择方法更关注模型的预测能力,而不注重变量本身对模型的意义,它们更适用于机器学习的预测任务我们总结一下以上的内容:
- 减少模型中的变量,可能会导致模型其他系数的估计有偏,但是会使系数估计的方差减少,即:增大偏差、减小方差
- 增加模型中的变量,不会导致模型系数估计有偏,但是会使系数估计的方差增大,即:减小偏差、增大方差
而在实际情况中,我们不可能得知一个真正正确的模型,而是在摸索中慢慢找到适合纳入模型的变量。通常来说,有两种考量纳入变量的方法论:
- 从少数变量开始,一步步向模型纳入我们认为重要的变量,并通过t检验显著性来判断是否纳入该变量;如果我们认为变量存在二次项效应与交互项效应,可以将其纳入模型并通过联合F检验判断其显著性,直到模型的解释度达到一个较高的水平。
- 从多数变量开始,一步步将不显著的变量剔除出模型。
这两种方法该用哪一种,视具体情况而定。假若数据集的变量非常多,那我倾向于使用第一种方法,一步步将我们认为重要的变量纳入模型;若变量不多,则第二种方法可以考虑。
对于变量的选择,还有一些自动化的方法,如向前逐步选择、向后逐步选择等等。但我个人认为,这些自动的变量选择方法更关注模型的预测能力,而不注重变量本身对模型的意义,它们更适用于机器学习的预测任务,而不适用于回归分析,因为回归分析中最重要的意义就是“解释与推断”。,而不适用于回归分析,因为回归分析中最重要的意义就是“解释与推断”。
5.3 模型不满足正态性的分析——违反MLR.6的后果是什么
如何理解与观测正态性假设
假设假定随机误差
u
u
u在任何自变量
x
x
x已知的条件下服从正态分布
u
∣
x
∼
N
(
0
,
σ
2
)
u \mid x \sim N\left(0, \sigma^{2}\right)
u∣x∼N(0,σ2)
即每个样本的误差
u
1
,
u
2
,
.
.
.
,
u
n
u_1,u_2,...,u_n
u1,u2,...,un都是来源于一个正态总体。然而,随机误差在数据集中是根本观测不到的,而由于在
x
x
x已知的条件下,
u
u
u的正态性等价于
y
y
y的正态性,因此我们只需要查看样本因变量
y
y
y的分布图就可以大致判断正态性了。
然而,因变量 y y y不为正态分布的情况是非常常见的,以下面的 n a r r 86 narr86 narr86为例,它统计了青年人在某一特定年份被拘捕的次数。很明显,绝大部分青年人都没有被拘捕过,因此该变量的分布是一个严重的偏态分布,不可能为正态分布
# 频数直方图
crime1=pd.read_stata('crime1.dta')
crime1.hist(column='narr86',figsize=(8,6))
print(crime1.narr86.value_counts())
5.3.2 违背正态性假设的后果
,因此违背正态性假设不会影响OLS系数估计的准确性与稳定性。
但是我们在进行假设检验的时候,基于t统计量与F统计量的推断是以满足MLR.6为前提的,这是否意味着对于narr86这种因变量而言,我们无法对其进行t检验与F检验呢?幸运的是,回答是否定的。得益于中心极限定理,我们有下述定理成立
· 定理: 在MLR.1-MLR.5假定下,OLS估计系数的抽样分布满足
β
^
j
−
β
j
se
(
β
^
j
)
⇒
N
(
0
,
1
)
\frac{\hat{\beta}_{j}-\beta_{j}}{\operatorname{se}\left(\hat{\beta}_{j}\right)} \Rightarrow N(0,1)
se(β^j)β^j−βj⇒N(0,1)
即,OLS的系数估计满足渐进正态性,这意味着在大样本容量下,OLS估计系数是近似正态分布的。
接下来的问题是,大样本下OLS估计是渐进正态分布的,按理来说应当使用标准正态分布作参考而不是用t分布作参考。但从实证角度来说,使用t分布进行大样本假设检验也是合理的,即以下写法是合理的
β
^
j
−
β
j
s
e
(
β
^
j
)
⇒
t
n
−
k
−
1
\frac{\hat{\beta}_j-\beta _j}{\mathrm{se}\left( \hat{\beta}_j \right)}\Rightarrow t_{n-k-1}
se(β^j)β^j−βj⇒tn−k−1
这是因为,当t分布自由度df达30以上时,就已经接近为正态分布了,而大样本下样本容量
n
n
n的大数值将让自由度
n
−
k
−
1
n-k-1
n−k−1也达到一个很大的数值,因此使用t分布进行检验实际上是没问题的!
最后的问题是,样本容量究竟要有多大才算是大样本呢?这没有一个固定的答案,部分学者认为大于等于30就可以了,当然样本量越多越好这是毋庸置疑的。
5.4 异方差的分析——违反MLR.5的后果是什么
同方差假设MLR.5:随机误差
u
u
u的条件方差恒为一个常数,即
Var
(
u
∣
x
1
,
⋯
,
x
k
)
=
σ
2
\operatorname{Var}\left(u \mid x_{1}, \cdots, x_{k}\right)=\sigma^{2}
Var(u∣x1,⋯,xk)=σ2
这个假设还可以拓展成因变量
y
y
y的同方差性
Var
(
y
∣
x
1
,
⋯
,
x
k
)
=
σ
2
\operatorname{Var}\left(y \mid x_{1}, \cdots, x_{k}\right)=\sigma^{2}
Var(y∣x1,⋯,xk)=σ2
于给定样本的 y 1 , y 2 , … , y n y_1,y_2,…,y_n y1,y2,…,yn,在每一个自变量 x j x_j xj测度下,它们的方差都应当是恒定的。这句话可以理解成,因变量/随机误差的方差在每一个自变量 x j x_j xj下都不随自变量的变化而变化;而只要其在某一个自变量 x j x_j xj下的方差是不稳定的,则同方差假设就不成立!
Example12
我们研究住房价格price的影响因素,并初步确定模型为
price
=
β
0
+
β
1
lotsize
+
β
2
sqrft
+
β
3
b
d
r
m
s
+
u
\text { price }=\beta_{0}+\beta_{1} \text { lotsize }+\beta_{2} \text { sqrft }+\beta_{3} b d r m s+u
price =β0+β1 lotsize +β2 sqrft +β3bdrms+u
即,我们纳入了三个自变量:lotsize,sqrft,bdrms。要想观测样本是否存在异方差性,
- 第一种方法就是直接查看因变量 y y y分别在三个自变量下的散点分布图,看看因变量在自变量值变化时的散布特征是否不变。
- .另一种观测异方差的方法是先进行OLS拟合,并以0为参考基准,观测残差在三个自变量上的表现
# 使用数据集hprice1,前面已经加载过
fig=plt.figure(figsize=(13,6))
ax1=fig.add_subplot(1,3,1)
hprice2=hprice1[hprice1['lotsize']<80000] #去掉了一个极端点,方便观察
plt.scatter(hprice2.lotsize,hprice2.price,axes=ax1)
ax1.set_xlabel('lotsize')
ax1.set_ylabel('price')
ax2=fig.add_subplot(1,3,2)
plt.scatter(hprice1.sqrft,hprice1.price,axes=ax2)
ax2.set_xlabel('sqrft')
ax2.set_ylabel('price')
ax3=fig.add_subplot(1,3,3)
plt.scatter(hprice1.bdrms,hprice1.price,axes=ax3)
ax3.set_xlabel('bdrms')
ax3.set_ylabel('price')
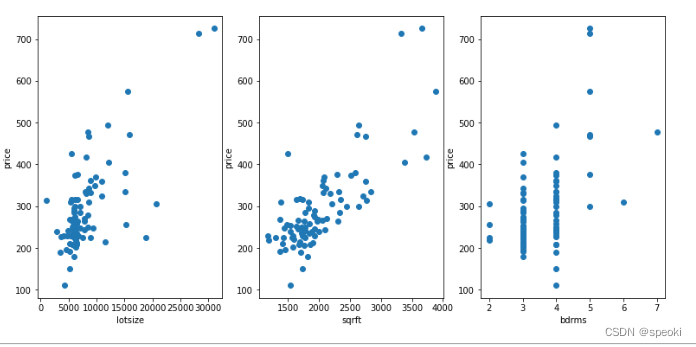
lotsize与sqrft的散布情况相对稳定,异方差的情况并不明显;而bdrms就不一样了,当bdrms=3时,因变量值分布呈现出往较小值偏移的特征,表现为上面稀疏,下面稠密。而bdrms=4时,因变量值的分布则相对对称,这说明price在bdrms上存在异方差的现象
5.4.2 违背同方差假设的后果
- 模型形式误设(导致违背MLR.1)以及随机误差的非正态性对模型的影响并不明显
- 违反同方差假设的后果就相对严重了:
- 首先由于MLR.1-MLR.4仍然成立,因此系数估计的无偏性依然成立。
- 异方差下,OLS估计不再是最优线性无偏估计。
- 异方差下,估计系数的方差计算不再准确,从而影响到标准误的计算,进而影响到t检验与F检验的有效性。
6. 异方差下的回归分析
- OLS不再最优、
- t检验与F检验不再稳健。
在这一节我们就要针对这两个问题提出解决的方法。
在这一章节我们将学习:
- 在异方差下如何重新估计标准差/标准误,并进行稳健的推断(假设检验)
- 如何用假设检验检测数据的异方差性
- 如何修正OLS估计方法达到最优(广义OLS法-GLS)
6.1 异方差稳健的t检验与F检验
稳健方法,就是这种方法不论是在异方差还是同方差下都可以进行使用。
6.1.1 重新估计方差
同方差假设下
β
j
^
\hat{\beta_j}
βj^的方差估计:
Var
(
β
^
j
)
=
σ
2
∑
i
=
j
n
r
^
i
j
2
=
σ
2
S
S
T
j
(
j
−
R
j
2
)
\operatorname{Var}\left(\hat{\beta}_{j}\right)=\frac{\sigma^{2}}{\sum_{i=j}^{n} \hat{r}_{i j}^{2}}=\frac{\sigma^{2}}{S S T_{j}\left(j-R_{j}^{2}\right)}
Var(β^j)=∑i=jnr^ij2σ2=SSTj(j−Rj2)σ2
事实上,这个方差估计有一个更广义的表达
Var
(
β
^
j
)
=
∑
r
^
i
j
2
σ
i
2
R
S
S
j
2
\operatorname{Var}\left(\hat{\beta}_{j}\right)=\frac{\sum \hat{r}_{i j}^{2} \sigma_{i}^{2}}{R S S_{j}^{2}}
Var(β^j)=RSSj2∑r^ij2σi2
在同方差假设下,由于
σ
i
=
σ
\sigma_{i}=\sigma
σi=σ,才有了上面化简了的表达式。
在异方差下,用残差
u
i
^
\hat{u_i}
ui^代替,即
σ
i
^
=
u
i
^
\hat{\sigma _i}=\hat{u_i}
σi^=ui^,系数重新估计的方差就变为了
Var
(
β
^
j
)
^
=
∑
r
^
i
j
2
u
^
i
2
R
S
S
j
2
\widehat{\operatorname{Var}\left(\hat{\beta}_{j}\right)}=\frac{\sum \hat{r}_{i j}^{2} \hat{u}_{i}^{2}}{R S S_{j}^{2}}
Var(β^j)
=RSSj2∑r^ij2u^i2
至此,我们就可以利用新的估计方差进行稳健t检验与F检验了。
6.1.2 稳健t检验
对于单参数检验问题,我们使用稳健t检验。
先看单参数检验问题
H
0
:
β
j
=
β
j
0
↔
H
1
:
β
j
≠
β
j
0
H_{0}: \beta_{j}=\beta_{j0} \leftrightarrow H_{1}: \beta_{j} \neq \beta_{j 0}
H0:βj=βj0↔H1:βj=βj0
定义t统计量
t
=
β
^
j
−
β
j
0
s
e
(
β
^
j
)
≈
N
(
0
,
1
)
t=\frac{\hat{\beta}_j-\beta _{j0}}{\mathrm{se}\left( \hat{\beta}_j \right)}\approx N\left( 0,1 \right)
t=se(β^j)β^j−βj0≈N(0,1)
注意,此时t统计量不再服从t分布,而是服从标准正态分布
# 以前面的price1_lm为例
# hprice1_lm=sm.formula.ols('price~lotsize+sqrft+bdrms',data=hprice1).fit()
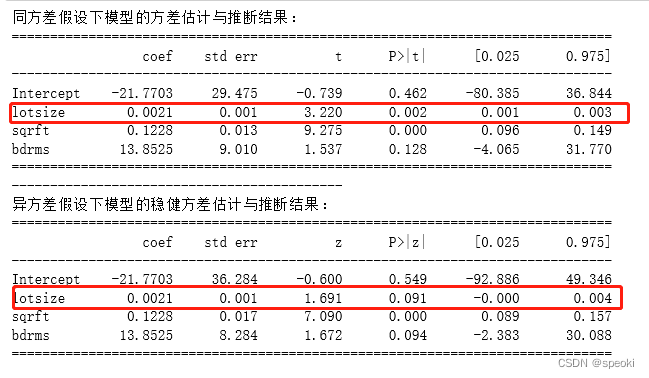
print('同方差假设下模型的方差估计与推断结果:')
print(hprice1_lm.summary().tables[1])
print('-------------------------------------------')
hprice1_lm_1=sm.formula.ols('price~lotsize+sqrft+bdrms',data=hprice1).fit(cov_type='HC0', use_t=False)
# use_t:稳健t检验是否使用t分布进行推断,False表示拒绝使用t分布,改用标准正态分布
print('异方差假设下模型的稳健方差估计与推断结果:')
print(hprice1_lm_1.summary().tables[1])
异方差稳健t检验的结果与普通t检验的结果的不同:
lotsize在普通t检验下是显著的,但在稳健t检验中是不显著的。
6.1.3 稳健F检验
多参数的联合检验,我们使用稳健F检验
稳健F检验的问题设置与原来的F检验一样,且它们的F检验统计量也完全一样,即
F
=
(
R
S
S
r
−
R
S
S
u
r
)
/
q
R
S
S
u
r
/
(
n
−
k
−
1
)
F=\frac{\left(R S S_{r}-R S S_{u r}\right) / q}{R S S_{u r} /(n-k-1)}
F=RSSur/(n−k−1)(RSSr−RSSur)/q
在稳健检验下,F统计量并不严格服从F分布,而是渐进服从自由度为
q
q
q的卡方分布。
我们考虑下述模型
c
u
m
g
p
a
=
β
0
+
β
1
s
a
t
+
β
2
h
s
p
e
r
c
+
β
3
t
o
t
h
r
s
+
β
4
f
e
m
a
l
e
+
β
5
b
l
a
c
k
+
β
6
w
h
i
t
e
+
u
cumgpa=\beta _0+\beta _1sat+\beta _2hsperc+\beta _3tothrs+\beta _4female+\beta _5black+\beta _6white+u
cumgpa=β0+β1sat+β2hsperc+β3tothrs+β4female+β5black+β6white+u
并做假设检验
H
0
:
β
5
=
β
6
=
0
↔
H
1
:
H
0
不成立
H_0: \beta _5=\beta _6=0 \leftrightarrow \,\,H_1: H_0\text{不成立}
H0:β5=β6=0↔H1:H0不成立
#载入数据
gpa3=pd.read_stata('gpa3.dta')
gpa3=gpa3[gpa3['term']==2]
# 直接训练无约束模型,并采用稳健估计训练
gpa3_lm=sm.formula.ols('cumgpa~sat+hsperc+tothrs+female+black+white',data=gpa3).fit(cov_type='HC0')
hypotheses='(black=0),(white=0)' # 另一种做联合检验的形式,直接将原假设写出来
gpa3_lm.wald_test(hypotheses,use_f=True,scalar=False)
6.2 异方差的诊断
关于检验方差是否与自变量无关的方法,最常用的便是BP异方差检验与White异方差检验。
6.2.1 BP异方差检验
· 检验思想
我们取原假设为:假定同方差假设正确,即
Var
(
u
∣
x
1
,
⋯
,
x
k
)
=
σ
2
\operatorname{Var}\left(u \mid x_{1}, \cdots, x_{k}\right)=\sigma^{2}
Var(u∣x1,⋯,xk)=σ2
由于MLR.2假设:
E
(
u
∣
x
1
,
⋯
,
x
k
)
=
0
E\left(u \mid x_{1}, \cdots, x_{k}\right)=0
E(u∣x1,⋯,xk)=0的成立,则同方差假设等价为
E
(
u
2
∣
x
1
,
⋯
,
x
k
)
=
σ
2
E\left( u^2\mid x_1,\cdots ,x_k \right) =\sigma ^2
E(u2∣x1,⋯,xk)=σ2
BP检验的实质是检验异方差与所有自变量的一次项无关,这就等价于对一个以
u
2
u^2
u2为因变量,以
x
j
x_j
xj为自变量的线性回归模型
u
2
=
δ
0
+
δ
1
x
1
+
δ
2
x
2
+
⋯
+
δ
k
x
k
+
v
u^{2}=\delta_{0}+\delta_{1} x_{1}+\delta_{2} x_{2}+\cdots+\delta_{k} x_{k}+v
u2=δ0+δ1x1+δ2x2+⋯+δkxk+v
做全部变量系数的联合显著性检验,于是原假设变为
H
0
:
δ
1
=
δ
2
=
⋯
=
δ
k
=
0
\mathrm{H}_{0}: \delta_{1}=\delta_{2}=\cdots=\delta_{k}=0
H0:δ1=δ2=⋯=δk=0
如果原假设被拒绝,就意味着存在一种与某自变量一次项相关的异方差。
BP检验的步骤
-
使用OLS法估计模型
y ∼ x 1 + x 2 + ⋯ + x k − 1 + x k y \sim x_{1}+x_{2}+\cdots+x_{k-1}+x_{k} y∼x1+x2+⋯+xk−1+xk
获得残差的平方 u ^ 2 \hat{u}^2 u^2 -
使用OLS估计法估计模型
u ^ 2 ∼ x 1 + x 2 + ⋯ + x k − 1 + x k \hat{u}^2 \sim x_{1}+x_{2}+\cdots+x_{k-1}+x_{k} u^2∼x1+x2+⋯+xk−1+xk -
对所有变量系数做联合检验,可用F检验或大样本LM检验。
· 用python实现BP检验
from statsmodels.stats.diagnostic import het_breuschpagan
#直接输出
hprice_lm=sm.formula.ols('price~lotsize+sqrft+bdrms',data=hprice1).fit()
hprice_lm_reg=sm.formula.ols('price~lotsize+sqrft+bdrms',data=hprice1)
het_breuschpagan(hrpice1_1m_reg.exog)
# 定义一个输出bp检验的函数
def bp_test(res,X):
result_bp_test=sm.stats.diagnostic.het_breuschpagan(res,X)
bp_lm_statistic=result_bp_test[0]
bp_lm_pval = result_bp_test[1]
bp_F_statistic= result_bp_test[2]
bp_F_pval = result_bp_test[3]
bp_test_output=pd.Series(result_bp_test[0:4],index=['bp_lm_statistic','bp_lm_pval','bp_F_statistic','bp_F_pval'])
return bp_test_output
bp_test(hprice1_lm.resid,hprice1_lm_reg.exog)
6.2.2 White异方差检验
BP检验考虑的是是否存在与变量的一次项相关的异方差,而White检验则增加了对所有变量二次项以及交互项的考察。
假若模型包含三个变量,BP检验所检验的模型是
y
∼
x
1
+
x
2
+
x
3
y\sim x_1+x_2+x_3
y∼x1+x2+x3
而White检验所检验的模型是
y
∼
x
1
+
x
2
+
x
3
+
x
1
2
+
x
2
2
+
x
3
2
+
x
1
x
2
+
x
1
x
3
+
x
2
x
3
y\sim x_1+x_2+x_3+{x_1}^2+{x_2}^2+{x_3}^2+x_1x_2+x_1x_3+x_2x_3
y∼x1+x2+x3+x12+x22+x32+x1x2+x1x3+x2x3
White检验虽然考虑的问题范围更广,但是由于回归元个数指数级增长,模型自由度相比于BP检验大大降低,对于自变量较多的情况,White检验可能并不如BP检验合适。
from statsmodels.stats.diadnostic import het_white
#White检验函数在python上的使用与BP检验完全一样
def white_test(res,X):
result_bp_test = sm.stats.diagnostic.het_white(res, X)
bp_lm_statistic = result_bp_test[0]
bp_lm_pval = result_bp_test[1]
bp_F_statistic= result_bp_test[2]
bp_F_pval = result_bp_test[3]
white_test_output=pd.Series(result_bp_test[0:4],index=['white_lm_statistic','white_lm_pval','white_F_statistic','white_F_pval'])
return white_test_output
white_test(hprice1_lm.resid,hprice1_lm_reg.exog)
6.3 广义最小二乘法
——回归存在异方差的另一种解决方法
异方差可以用自变量的函数被表达出来。如果它能被我们找出来,我们就可以是加权最小二乘估计WLS;如果由于函数形式复杂而无法被判断出来,我们则使用可行的广义最小二乘估计FGLS。
6.3.1 加权最小二乘法
加权最小二乘法的原理非常简单。
假设异方差的形式除去一个常数外是已知的,即
Var
(
u
∣
x
)
=
σ
2
h
(
x
)
\operatorname{Var}(u \mid x)=\sigma^{2} h(x)
Var(u∣x)=σ2h(x)
那么如果我们在原模型两边同除以
1
h
(
x
)
\frac{1}{\sqrt{h\left( x \right)}}
h(x)1,即
y
h
(
x
)
=
β
0
∗
h
(
x
)
+
β
1
∗
x
1
h
(
x
)
+
⋯
+
β
k
∗
x
k
h
(
x
)
+
u
h
(
x
)
\frac{y}{\sqrt{h\left( x \right)}}=\frac{\beta _{0}^{*}}{\sqrt{h\left( x \right)}}+\beta _{1}^{*}\frac{x_1}{\sqrt{h\left( x \right)}}+\cdots +\beta _{k}^{*}\frac{x_k}{\sqrt{h\left( x \right)}}+\frac{u}{\sqrt{h\left( x \right)}}
h(x)y=h(x)β0∗+β1∗h(x)x1+⋯+βk∗h(x)xk+h(x)u
并将带有 1 h ( x ) \frac{1}{\sqrt{h\left( x \right)}} h(x)1的自变量与随机误差视作是新的变量与随机误差,则问题就是同方差情形了,我们可以使用OLS估计。
鉴别简单的异方差形式,并用statsmodels包中的wls函数进行wls估计。
· Example13. 我们想研究27家企业主管人数Y与工人人数X的关系。由于只有一个自变量,一开始我们可以考虑简单线性回归模型
Y
=
β
0
+
β
1
X
+
u
Y=\beta _0+\beta _1X+u
Y=β0+β1X+u
##查看散点图 Y.X
fig=plt.sigure(figsize=(13,6))
ax1=fig.add_subplot(1,2,1)
plt.scatter(data.X,data.Y,axes=ax1)
ax1.set_xlabel('X')
ax1.set_ylabel('Y')
ax1.set_title('Y|X')
##查看ols估计的残差与X的散点图
data_lm=sm.formula.ols('Y~X',data=data)
print(bp_test(data_lm.resid,data_lm_reg.exog))
print("*********")
#使用whiite检验
data_lm_reg=sm.formula.ols('Y~X',data=data)
print(white_test(data_lm.resid,data_lm_reg.exog))
bp检验与White检验均表示,回归确实存在明显的异方差线性。且根据散点图,我们可以看到随着X的增大,样本的分布越来越分散,即方差越来越大。我们设想:方差可能与X的二次项成正比(一次项也有可能,言之有理即可),于是我们假定
Var
(
u
∣
x
)
=
σ
2
x
2
\operatorname{Var}(u \mid x)=\sigma^{2} x^{2}
Var(u∣x)=σ2x2
data_lm_wls=sm.formula.wls('Y~X',weights=1/data.X**2,data=data).fit()
#注意weights传入的是一个数组,不是一个表达式,如果方差函数为h(x),则要传入1/h(x)的数组
print(data_lm.summary().tables[1])
print(data_lm_wls.summary().tables[1])
6.3.2 可行的广义最小二乘法
FGLS将
h
(
x
)
h(x)
h(x)假设为
h
(
x
)
=
exp
(
δ
0
+
δ
1
x
1
+
⋯
+
δ
k
x
k
)
h(x)=\exp \left(\delta_{0}+\delta_{1} x_{1}+\cdots+\delta_{k} x_{k}\right)
h(x)=exp(δ0+δ1x1+⋯+δkxk)
则条件方差的表达式就有
V
a
r
(
u
∣
x
)
=
E
(
u
2
∣
x
)
=
σ
2
exp
(
δ
0
+
δ
1
x
1
+
⋯
+
δ
k
x
k
)
\mathrm{Var(}u\mid x)=E\left( u^2\mid x \right) =\sigma ^2\exp \left( \delta _0+\delta _1x_1+\cdots +\delta _kx_k \right)
Var(u∣x)=E(u2∣x)=σ2exp(δ0+δ1x1+⋯+δkxk)
进而有
E
(
u
2
∣
x
)
=
σ
2
exp
(
δ
0
+
δ
1
x
1
+
⋯
+
δ
k
x
k
)
⇒
log
(
u
2
)
∼
x
1
+
⋯
+
x
k
E\left( u^2\mid x \right) =\sigma ^2\exp \left( \delta _0+\delta _1x_1+\cdots +\delta _kx_k \right) \Rightarrow \log \left( u^2 \right) \sim x_1+\cdots +x_k
E(u2∣x)=σ2exp(δ0+δ1x1+⋯+δkxk)⇒log(u2)∼x1+⋯+xk
也就是说,我们先用OLS估计求解一个以
log
(
u
^
2
)
\log \left(\hat{u}^{2}\right)
log(u^2)为因变量的线性回归模型,再将该模型进行指数化处理,便可以得到
h
(
x
)
h(x)
h(x)的估计形式了。
我们总结出以下步骤:
- 做回归 y ∼ x 1 + ⋯ x k y \sim x_{1}+\cdots x_{k} y∼x1+⋯xk,得到残差 u ^ \hat{u} u^
- 做回归 log ( u ^ 2 ) ∼ x 1 + ⋯ + x k \log \left(\hat{u}^{2}\right) \sim x_{1}+\cdots+x_{k} log(u^2)∼x1+⋯+xk,得到拟合值 g ^ \hat{g} g^
- 计算函数 h ^ = exp ( g ^ ) \hat{h}=\exp (\hat{g}) h^=exp(g^)
- 以 1 / h ^ 1/\hat{h} 1/h^做权重,用wls估计模型 y ∼ x 1 + ⋯ x k y \sim x_{1}+\cdots x_{k} y∼x1+⋯xk
statsmod
els.api
statsmodels.api
statsmodels 分为
statsmodels.api横截面模型和方法
statsmodels.tsa.api时间序列模型和方法
statsmodels.formula.api使用公式字符串和dataframe指定模型的便捷接口
回归
类描述OLS(endog[, exog, missing, hasconst])普通最小二乘
WLS(endog, exog[, weights, missing, hasconst])加权最小二乘
GLS(endog, exog[, sigma, missing, hasconst])广义最小二乘
GLS##所谓自变量函数,其实就是将原自变量进行一种变换。变换后的变量一方面可能使模型对数据的拟合效果更佳;另一方面也可以满足一些我们实际的数据分析需求。在这一章节,我们简单介绍三种常见的自变量函数:对数化、二次项化、交互项化。AR(endog[, exog, rho, missing, hasconst])具有 AR 协方差结构的广义最小二乘
RecursiveLS(endog, exog[, constraints])递归最小二乘
RollingOLS(endog, exog[, window, min_nobs, …])滚动普通最小二乘法
RollingWLS(endog, exog[, window, weights, …])滚动加权最小二乘法
插值
类描述BayesGaussMI(data[, mean_prior, cov_prior, …])使用高斯模型的贝叶斯插值。
MI(imp, model[, model_args_fn, …])MI 使用提供的 imputer 对象执行多重插值。
MICE(model_formula, model_class, data[, …])链式方程的多重插值。
MICEData(data[, perturbation_method, k_pmm, …])包装数据集以允许使用 MICE 处理丢失的数据。
离散和计数模型
logit(endog,exog,[,check_rank])Logi模型
probit(endog,exog,[,check_rank])概率模型
MNLogit(endog,exog,[,check_rank])多项logit















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









