






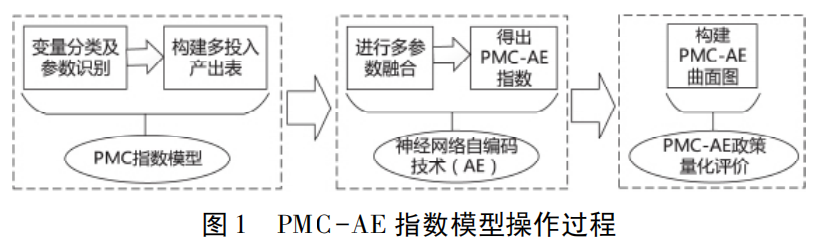
一、PMC指数模型概念
PMC(Policy Modeling Consistency)指数模型,即政策一致性指数模型,是目前国际上较为先进的政策文本评价方法之一。源于Ruiz Estrada等人基于“Omnia Mobilis”假说思想提出的一种政策建模模型,主张世界万事万物都是不断运动且相互联系的,任何一个变量都同等重要,所以不应该忽视任何一个相关变量的影响。
PMC模型不仅可以通过PMC指数从多个维度分析政策的内部异质性和优劣水平,还可以通过PMC曲面图直观展示不同维度的优劣势。该模型通常从政策文本中获取原始数据,能够有效避免政策评价的主观性,从而提高政策评价客观性。
PMC指数模型现已逐渐成为国内外政策评价领域的热点,在多个政策领域发挥着重要作用,包括公共管理、社会保障、科学研究、技术服务业以及制造业等应用领域。
PMC指数模型的优势如下:
(1)通过政策文本深度挖掘来设置参数,降低认为评价的主观性,提升量化评估的精确度;
(2)不区分指标重要性等级,不限制指标数目和各指标对应的权重,确保所有潜在影响因素得到充分考虑;
(3)能精准识别政策制定者对关键问题的共识响应,对单个政策量化评价时,能揭示政策之间的一致性,直观揭示政策优势与不足,为政策的改进路劲提供有效的参考依据;
(4)模型构建相对简单,易操作,具有较强的实用性和推广价值。
二、PMC指数模型方法步骤
1、变量分类与参数识别
采用PMC指数模型进行政策评估时,相关变量的选取需充分考量及其作用,对政策的评估尽可能全面。一般参照已有文献进行指标确定,设置好一级指标和二级指标后,需要对各个二级变量的评分标准加以规定。运用文本挖掘的办法对二级变量进行赋值,当待评价政策满足相应的二级指标变量内容时,变量赋值为1,不满足时取值为0。
2、多投入产出表编制
为了方便数据存储,需要构建多投入产出表。多投入产出表是一种可存储大量数据、对单个变量采用多维度测量的数据分析框架,由若干个一级指标变量和不受数量限制的二级变量组成。一级指标变量没有固定的排列顺序且相互独立,二级变量构成一级变量,各二级变量权重相等。
3、PMC指数测度
(1)依照政策构建变量,包括一级变量和二级变量;
(2)建立多投入产出表,并根据文本挖掘法和二进制法赋予二级变量具体数值;
(3)结合上一步二级变量的赋值进行一级变量值的计算;
其中,为一级变量;
为二级变量。
(4)将上一步得出的一级变量进行贾总,从而计算待评估的各项政策的PMC指数;
(5)按照Ruiz的观点,等级划分标准为:

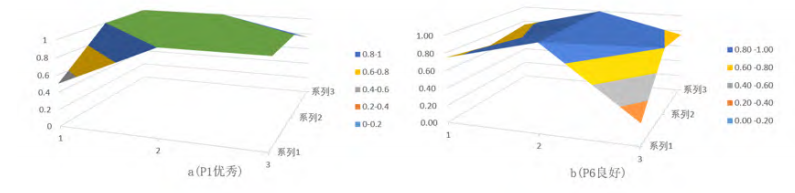
4、PMC立体曲面图构建
PMC 曲面图能立体、直观地展示 PMC 指数量化评估结果,有助于分析吉林省数字经济发展政策的优势和尚存在的不足。PMC 曲面一般为凹凸不平的三维图形,不同色块代表指标得分的不同数值,曲面凸出的部分表示该项政策对应评价指标得分较高,凹陷程度越小,政策内容一致性越好;曲面的凹陷部分则表示对应评价指标得分较低,凹陷程度越大,政策内容一致性越差。
构建PMC曲面的前提是计算PMC矩阵,建立一个3*3的矩阵,由9个一级变量数值组成。绘制PMC曲面需要借助PMC矩阵,构造正方形矩阵可以保持PMC曲面完美的对称性。
三、拓展:PMC-AE模型
1、PMC指数模型的缺点
PMC指数模型的求取方法知识进行简单的加权求平均,这是一种线性的数据融合方法,而政策不同评价指标之间的关系无法衡量。因此,PMC方法并不能很好地对各政策评价指标信息进行融合。
2、自编码技术原理介绍
自编码技术(Auto Encoder,AE)是一个3层或大于3层的神经网络,隶属于非监督学习。与BP(Back Propagation)神经网络等监督学习不同的是,自编码技术通过参数自学习的方式不需要大量数据集进行训练便可以实现数据的融合,达到高维数据降维的目的。
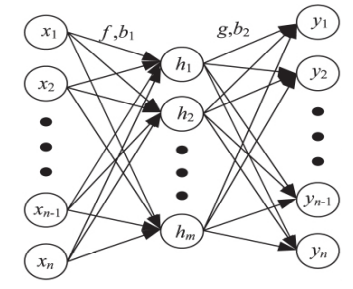
学习过程以输入节点和输出节点相差最小为目的,步骤如下:
(1)利用非线性方法对原始数据进行编码得到隐藏层节点;
(2)对得到的隐藏层节点进行解码得到输出层节点;
(3)多次循环以学习到最佳的权值和常数项使输入输出相差最小。
式中为建立的政策评价体系,
则为对应的输出层结点值;
,
分别为隐藏层和输出层的激活函数,常用的又Sigmoid、Tanh、Softplus函数等,
,
可以相同也可以不同;
为隐藏层结点值;
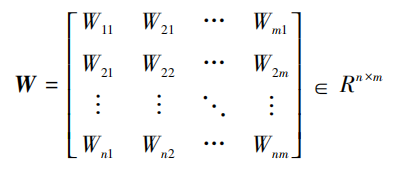
和
fe分别为输入层和隐藏层之间的权值矩阵、隐藏层和输出端之间的权值矩阵,通常权值矩阵的行数等于上一层的神经元结点数,列数等于下一层的神经元结点数;
和
则分别为输入层到隐藏层、隐藏层到输出层的常熟项,维数分别为对应的下一层神经元的结点数。
自编码技术的训练目的就是为了使和
尽量相同。
当原始数据维数过高或需要得到更低维数的数据时,可以适当增加神经网络的层数,并令神经元结点数则逐层递减。因此,经过训练后, 通过非线性结合构成
,
又通过非线性结合构成
,且
=
。所以
是
经过非线性融合得到的,而
又是
通过解码得到的,从而可以认为
是
和
的非线性表达,所以
可以作为各项指标融合后的政策文本得分。
也就是说,对输入的数据利用非线性方法压缩到隐藏层的神经元,然后将隐藏神经元解压得到输出层数据,最后通过多次循环即可使模型自动学习到可以使输入与输出数据之间差异最小的权值和常数项。
3、PMC-AE指数模型概念
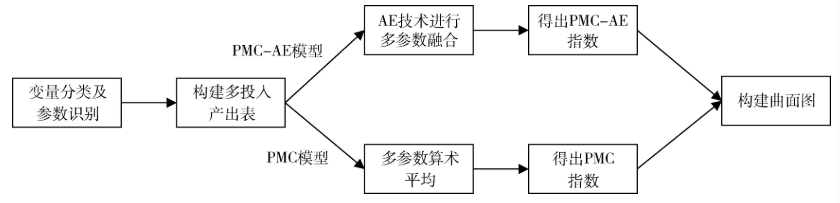
PMC-AE指数模型是将PMC指数模型的改进,与神经网络自编码技术相结合,从政策本身的合理性和可行性角度对政策文本进行评价。PMC-AE指数模型与PMC指数模型的区别在于计算指数时所采取的方法,前者利用AE技术对参数进行融合,比后者的线性融合更具有优越性,模型对比如图所示:
4、PMC-AE指数模型步骤
(1)首先利用PMC指数模型进行变量分类及参数识别;
(2)构建政策多投入产出表,利用文本挖掘技术进行赋值;
(3)利用神经网络中的自编码技术对多参数进行融合,得到PMC-AE指数,即各政策得分;
(4)绘制PMC-AE曲面图,对政策展开评价。
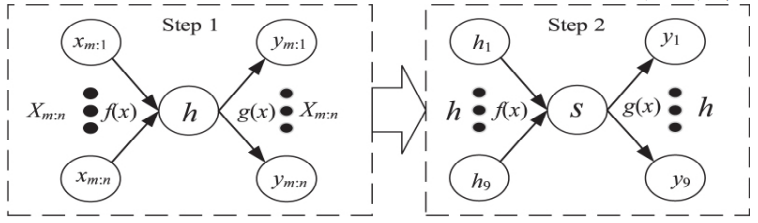
5、PMC-AE数据融合过程
假设选取了 项政策作为样本,利用文本挖掘技术求取出每项政策的各二级指标得分并用
表示,其中上标
代表第
项政策,
代表一级指标,
为第
个一级指标下属的第
个二级指标。
(1)分别将各二级指标进行融合得到各政策的所有一级指标的融合得分;
(2)将第一阶段得到的进行融合,得到各项政策的PMC-AE指数
。
如下图所示,其中和
分别为经过AE融合后重构得到的各自的输入量。
6、构建PMC-AE曲面
为了更加清晰、直观地展现各项政策的得分情况,需要构建PMC-AE曲面。PMC-AE曲面可以通过图像方式将政策最终得分立体地表现出来,从而更加直观具体地展现政策评价的结果。步骤如下:
(1)将政策一级变量的得分转化为三阶方阵;
(2)计算PMC-AE矩阵值。
7、文献中常用的参数设置
神经网络为3层,隐藏层结点为1,输入层到隐藏层的激活函数选取Softplus函数,隐藏层到输出层的函数选取Sigmoid函数。
四、拓展:关于政策评价
政策评价是公共政策的制定和管理过程中最重要的纽带,通过使用不同的理论、量化模型和技术手段来对特定的政策进行综合性分析,不仅可以对政策本身做出科学的评判了还可以检验政策制定和执行的实际效果。政策评价在公共政策分析的过程中充当了重要角色,也是政策资源合理分配的基础,有效地检验政策效果。
政策评价是通过科学的评价标准或评价模型来对政策进行系统性分析。较为常用的评价方法有政策工具分析法、扎根理论、熵权TOPSIS法和双重差分模型。这些政策评价方法在政策适用性、理论阐释力和实证检验效度等方面有各自的优势,但也有一定的研究局限。政策工具分析法分析视角相对单一,难以实现政策的整体性、系统性评价;扎根理论可用于理论构建但不适用于政策量化评价;熵权TOPSIS法指标权重敏感性较高且模型构建过程复杂;双重差分模型能有效评估政策影响但需严格严格验证假设。
五、参考文献
[1]王进富,杨青云,张颖颖.基于PMC-AE指数模型的军民融合政策量化评价[J].情报杂志,2019,38(04):66-73.
[2]蔡冬松,柴艺琳,田志雄.基于PMC指数模型的吉林省数字经济政策文本量化评价[J].情报科学,2021,39(12):139-145.
[3]王雪,范丽伟,王文雅,等.基于PMC指数模型的可再生能源技术创新政策量化评价研究[J].中国石油大学学报(社会科学版),2024,40(02):29-38.
[4]朱晓峰,吴婧娴,许发见.基于改进PMC指数的国内政府数据治理政策评价:体系构建与优化[J].情报理论与实践,2025,48(03):81-91.
[5]吴卫红,盛丽莹,唐方成,等.基于特征分析的制造业创新政策量化评价[J].科学学研究,2020,38(12):2246-2257.

















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









