






1.模型原理
BERTopic 是一种用于从文本数据中提取主题模型的新型方法。通过结合 BERT嵌入和传统的主题模型来生成语义丰富的主题。传统的主题模型(如LDA)主要依赖于词频矩阵,而 BERTopic 通过预训练语言模型生成高维语义嵌入来捕捉词语间的复杂关系,因此可以更好地处理上下文信息。
BERTopic模型可以看作是创建其主题表示的一系列步骤。核心原理如下:
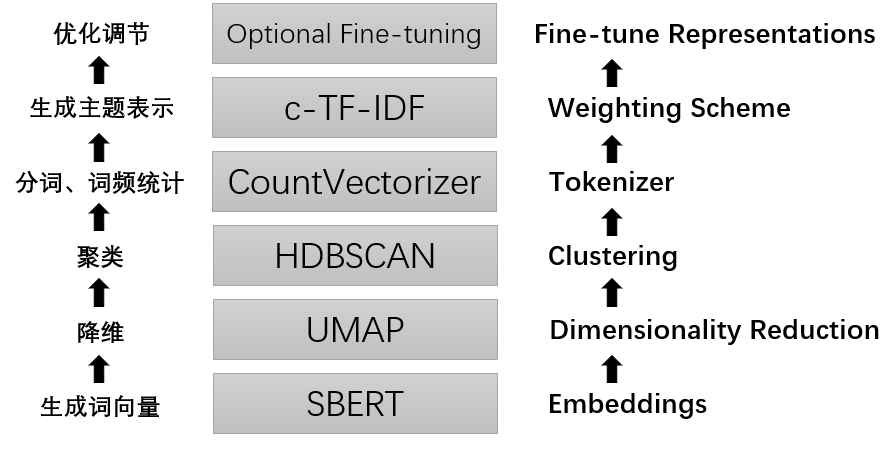
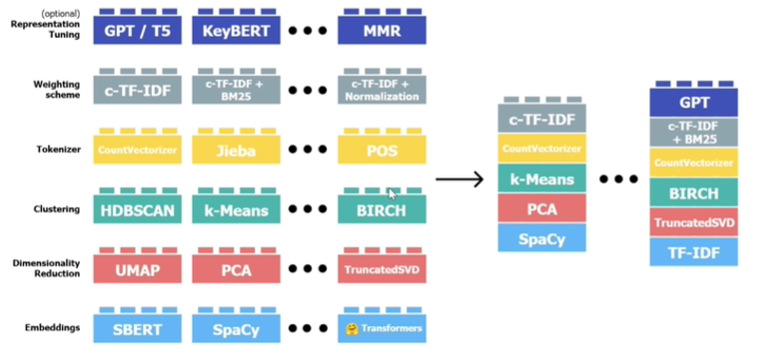
就本质而言,BERTopic就是一个拼装框架,可以把每部分都替换成其他模型,只要完成任务即可。
具体而言,BERTopic主题模型的工作原理主要分为如下步骤:
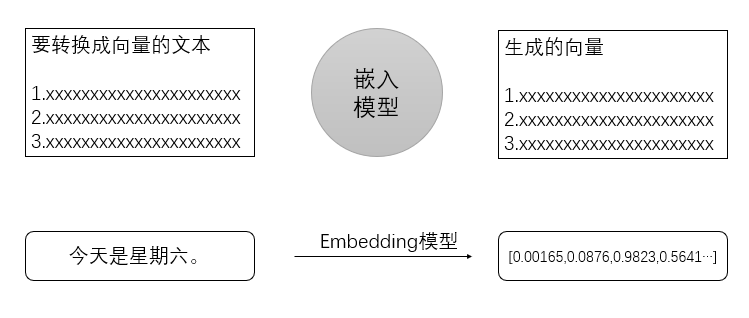
①文本嵌入(Embeddings):使用预训练的BERT模型将文本中的每个单词转换为词向量,使语义上相似的单词在向量空间中相互靠近。词向量可以简单理解为一串数值,表示高维空间的一个点。两个文本的语义相近,也就意味着两个点的位置比较近。
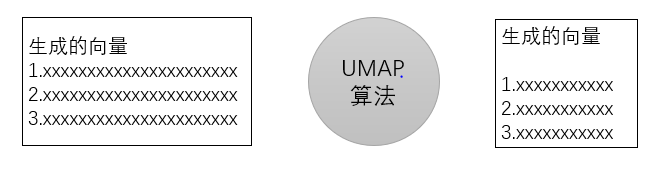
②文本降维(Dimensionality Reduction):使用UMAP(Uniform Manifold Approximation and Projection)算法对词向量进行降维,将它们映射到一个低维空间,同时保留重要的局部和全局结构信息。
③文本聚类(Clustering):在降维后的向量空间中,使用HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)算法进行聚类。HDBSCAN是一种基于密度的聚类算法,能够发现任意形状的簇,并且对于噪声和异常值具有鲁棒性,它将相似的文档(即向量)归为同一类簇,形成不同的主题。
④主题表示(Topic Representation):对每个主题簇使用c-TF-IDF方法计算主题簇中主题词的重要性,根据最大边际相关性提取主题特征词,c-TF-IDF公式如下:
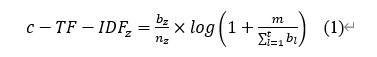
其中,z代表主题,b代表单词,bz代表每个主题z中单词b的频率,nz为单词总数,m代表每个主题z中的平均单词数,t为主题总数。
2.文本嵌入(Embedding)
嵌入是机器学习中的一个重要概念,它的主要目标是将离散的数据(如单词、图像)转换为连续的向量,从而使计算机能够更好地理解和处理这些数据。在自然语言处理中,嵌入通常指的是将单词映射为向量的过程。简单来说,词嵌入模型也就是把文本转换成向量的模型,但注意,这个部分需要实现的目标是语义相似的文本,生成的向量在空间中也相近。
2.1 代码
# 加载库
import torch
from torch.utils.data import DataLoader
from transformers import BertTokenizer, BertModel
from tqdm import tqdm
import numpy as np
# 加载数据
with open('../data/input.txt', 'r', encoding='utf-8') as file:
sentences = file.readlines()
print('文本条数: ', len(sentences))
print('预览第一条: ', sentences[0])
# 加载预训练模型和tokenizer
model_name = "bert-base-chinese" #可替换任何一个嵌入模型
model = BertModel.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
# 将模型放置在GPU上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 把模型放到cpu或gpu
model.to(device)
model.eval()
# 切分数据
batch_size = 16 # 批大小
data_loader = DataLoader(sentences, batch_size=batch_size)
for batch in data_loader:
print(len(batch), batch)
# ---- 文本转向量 ----
# 生成的向量存放在这里
cls_embeddings = []
# 使用tqdm显示处理进度
for batch_sentences in tqdm(data_loader):
inputs = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt", max_length=512)
inputs.to(device)
with torch.no_grad():
outputs = model(**inputs)
print('numpy格式', type(outputs.last_hidden_state[:, 0].cpu().numpy()), outputs.last_hidden_state[:, 0].cpu().numpy().shape)
# 合并句子向量
print('batch个数:', len(cls_embeddings))
cls_embeddings_np = np.vstack(cls_embeddings)
print('最终生成的词向量', type(cls_embeddings_np), cls_embeddings_np.shape)
# ---- 保存词嵌入向量 ----
output_file = "emb_bert.npy"
np.save(output_file, cls_embeddings_np)
print("词向量存储于: ", output_file)
embeddings = np.load(output_file)
print("加载回来,验证一下:", type(embeddings), embeddings.shape)2.2 One-Hot编码
One-Hot 编码是分类变量作为二进制向量的表示。
(1) 将分类值映射到整数值。
(2) 然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
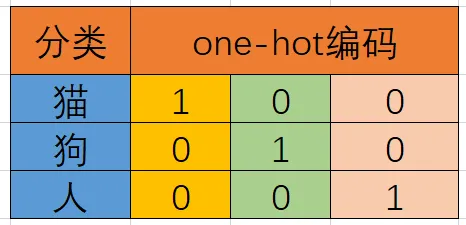
上表竖着看,黄色的代表是猫的编码 [1, 0, 0],浅绿色代表的是狗的编码 [0, 1, 0]。如果一个类别标签是猫,那么猫对应的位置就是1,狗和人对应的位置就是0,得到一个编码[1, 0, 0]。这样得到的编码都是独立的。
缺点:具有稀疏性,没办法将语义相近的词表示成相近的向量。
2.3 Word2vec模型
Word2vec 是一种有效创建词嵌入的方法,自 2013 年以来一直广泛使用。针对One-hot的缺点,Word2vec算法的核心原理一是向量短些,二是向量直接表示语义关系。

l第一个ike是用One-hot的编码表示,多且无意义。相较而言,用Word2vec表示的第二个like就比较短,且有语义表示,更能实现语义相近的文本向量距离更近。
Word2vec的思想——“一个词能被它周围的词代表。”(英国语言学家 John Rupert Firth)
举例而言:
我“喜欢”自然语言处理。
我“喜欢”吃苹果。
我“喜欢”你。
上面三句话中的“喜欢”都可以替换成“爱”,所以相同的上下文可以填入语义相近的词语。
也就是说,一个词语的语义被它周围的上下文的词语所代表。
缺点:①无法捕获全文语义。②无法处理一词多义。
2.4 Bert模型
Bert是由Google在2018年提出的一种预训练语言模型。核心思想是利用Transformer架构,通过大量的文本数据进行预训练,从而学习丰富的语言表示。Bert最大的特点是“双向”,也就是说,它在处理文本时,可以同时考虑上下文的信息,而不是像传统的模型那样只能单向地处理文本,可以有效处理一词多义的情况。进一步弥补了Word2vec的缺陷。
Transformer架构中的Self-Attention的核心是:用文本的其他词来增强目标词的语义表示。
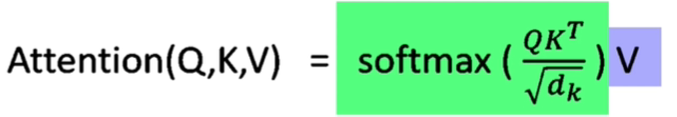
输入一个句子,模型能够通过注意力机制,把整个句子的信息有重点地融入到每个单词的向量表示中,从而得出每个单词良好的语义表示。
2.4.1 Bert-base-chinese模型
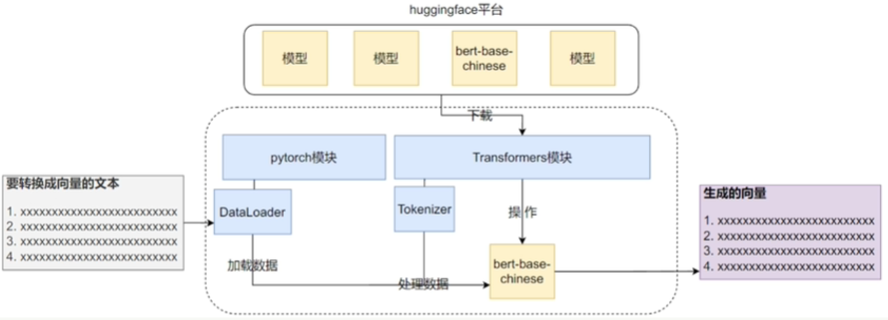
Hugging Face:模型的托管平台,自然语言处理的强大社区。(可下载各种别人的模型。)
Data Loader:将数据分批加载。
Tokenizer:分词操作。(将句子拆成字词,并加入一些特殊符号,如cls。)
2.4.2 SentenceTransformers框架
这个模型的主要目的就是将句子转换为向量。
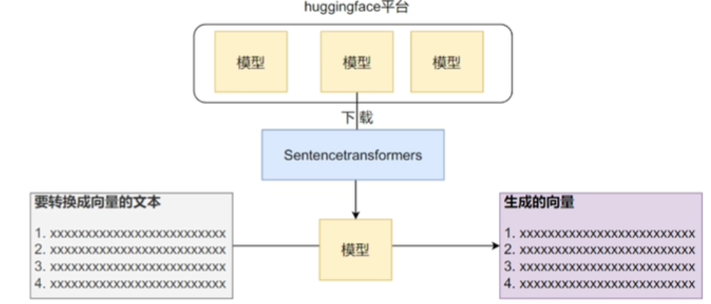
2.5 如何选择文本嵌入模型
1.选择文本嵌入模型时,要注意看模型的参数,尤其是要注意token的长度,长文本和短文本的区别很大。
2.可以参考MTEB榜单上的不同模型的参数。
3.Max Sequence Length:表示最长容纳的字词数量。
4.Dimensions:表示生成多少维的语义向量。
以使用Sentencetransformers模型为例,代码如下:
# 1. 词向量模型,同时加载本地训练好的词向量
embedding_model = embedding_model = SentenceTransformer(
'paraphrase-multilingual-mpnet-base-v2',
) # 使用Sentencetransformers模型
embeddings = np.load('../../data/embedding_sen.npy') # 使用sentence-transformers向量
print(embeddings.shape)
# 2. 创建分词模型
vectorizer_model = CountVectorizer() # 因为已经分好词了,所以这里不需要传入分词函数了
# 3. 创建UMAP降维模型
umap_model = UMAP(
n_neighbors=15,
n_components=5,
min_dist=0.0,
metric='cosine',
random_state=42
)
# 4. 创建HDBSCAN聚类模型
# 如果要建设离群值,可以减小下面两个参数
hdbscan_model = HDBSCAN(
min_cluster_size=40,
min_samples=40,
)
# 5. 创建CountVectorizer模型
vectorizer_model = CountVectorizer( )
# 正式创建BERTopic模型
topic_model = BERTopic(
embedding_model=embedding_model,
vectorizer_model=vectorizer_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
)
# 查看主题
topics, probs = topic_model.fit_transform(docs, embeddings=embeddings) #传入训练好的词向量
topic_model.get_topic_info()
# UMAP可视化
reduced_embeddings = UMAP(n_neighbors=10, n_components=2, min_dist=0.0, metric='cosine',).fit_transform(embeddings)
topic_model.visualize_documents(docs, reduced_embeddings=reduced_embeddings, hide_document_hover=True, hide_annotations=False)3.文本降维(Dimensionality Reduction)
UMAP 通过以下步骤实现降维:
-
构建邻域图:在原始高维空间中,为每个点找到
n_neighbors个最近邻点,构建局部邻域图。 -
优化低维布局:在低维空间中随机初始化点的位置,通过优化目标函数,使得低维空间中的邻域关系尽可能与高维空间一致。
-
调整点间距离:通过
min_dist参数控制低维空间中点与点之间的距离。
3.1 代码
# 创建UMAP降维模型,模型的原始参数如下:
umap_model = UMAP(
n_neighbors=15, # 控制局部邻域的大小
n_components=5, # 降维后的维度
min_dist=0.0, # 控制点与点之间的最小距离
metric='cosine', # 距离度量方式
random_state=42 # 随机种子,确保结果可复现
)3.2 参数调节
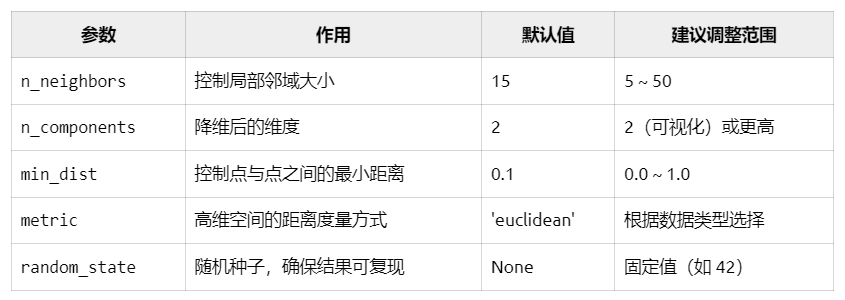
1.n_neighbors=15:UMAP模型做降维处理时,应该参考周围15个点。
-
值越大,UMAP 会更多地关注全局结构;值越小,UMAP 会更多地关注局部结构。
-
默认值为
15,适用于大多数数据集。 -
调整建议:如果数据分布较为稀疏,可以适当增大
n_neighbors。如果数据分布较为密集,可以适当减小n_neighbors。
2.n_components=5:将高维降低到5维的意思。
-
调整建议:如果目的是可视化,通常设置为
2或3。如果目的是特征提取或输入其他模型,可以根据后续任务需求调整。
3.min_dist=0.0:点和点之间可以任意接近。
-
值越小,点与点之间越紧密;值越大,点与点之间越分散。
-
调整建议:如果希望点与点之间更紧密,可以减小
min_dist。如果希望点与点之间更分散,可以增大min_dist。
4.metric='cosine':表示使用余弦相似度作为距离度量,适用于文本数据或高维稀疏数据。
-
常用选项:'
euclidean':欧氏距离,适用于连续数值数据。'manhattan':曼哈顿距离,适用于稀疏数据或离散数据。'correlation':相关系数距离,适用于时间序列或相关性强的数据。
5.random_state:看成随机数种子。可以随便设置,官方文档给的是42。
-
UMAP 算法中涉及一定的随机性(如初始化)。
random_state设置随机种子,使得每次运行的结果一致。默认值为None,即每次运行结果可能不同。
3.3 调参小结
4.文本聚类(Clustering)
HDBSCAN 是一种基于密度的聚类算法,能够处理噪声数据并自动识别簇的数量。其工作原理如下:
-
构建距离图:计算数据点之间的距离,构建邻域图。
-
密度估计:通过核心点(
min_samples)的定义,估计数据点的密度。 -
层次聚类:基于密度信息构建层次聚类树。
-
剪枝与簇提取:根据
min_cluster_size参数剪去过小的簇,最终提取出稳定的簇。
4.1 代码
hdbscan_model = HDBSCAN(
min_cluster_size=10, # 控制最小簇的大小
min_samples=5, # 控制簇的核心点数量
metric='euclidean' # 距离度量方式
)使用HDBSCAN算法会导致离群值,可以通过调节参数来降低离群值。
离群值的产生,是为了其他主题更加清晰。
如果使用K-means算法,就不会产生离群值。
4.2 参数调节
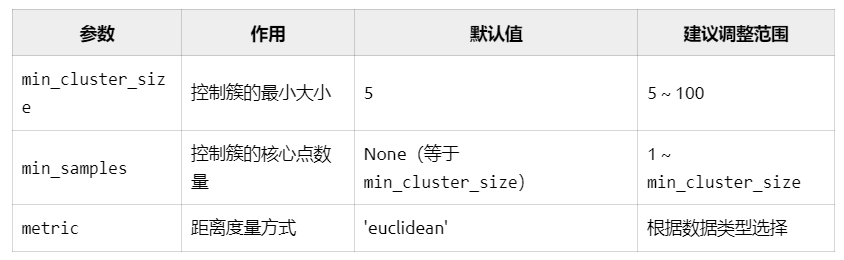
1.min_cluster_size=10:定义簇的最小大小。
-
HDBSCAN 会忽略小于
min_cluster_size的簇,将其标记为噪声点(离群点)。 -
和min_topic_size本质上一样。也就是一个主题类别中至少包含多少文档。这个参数控制簇的最小规模,值越大,生成的簇越少但越稳定。
-
调整建议:如果数据集较大且希望生成较大的簇,可以适当增大
min_cluster_size。如果数据集较小或希望生成更多小簇,可以适当减小min_cluster_size。
2.min_samples=5:定义簇的核心点所需的邻域点数量。
-
值越大,核心点的要求越严格,生成的簇越少;值越小,核心点的要求越宽松,生成的簇越多。
-
默认值为
None,表示使用与min_cluster_size相同的值,可以手动调节变小,有利于减少离群值。所以min_samples和min_cluster_size参数选择设置一个即可。 -
调整建议:如果希望生成更紧凑的簇,可以增大
min_samples。如果希望生成更多宽松的簇,可以减小min_samples。
3.metric='euclidean':定义点与点之间的距离度量方式。
-
常用选项:
'euclidean':欧氏距离(默认),适用于连续数值数据。'manhattan':曼哈顿距离,适用于稀疏数据或离散数据。'cosine':余弦相似度,适用于文本数据或高维稀疏数据。'precomputed':如果提供了预计算的距离矩阵,则使用此选项。'euclidean'表示使用欧氏距离作为度量方式,适用于连续数值数据。
当然,需要注意的是,如果强制没有离群值,那主题类别可能代表性并不好。
4.3 参数小结
4.4 K-means聚类
# 导入Kmeans库
from sklearn.cluster import KMeans
# 创建Kmeans模型
cluster_model = KMeans(n_clusters=6) # 要聚成几个类,此处为随便填写
#......
topic_model = BERTopic(
embedding_model=embedding_model,
vectorizer_model=vectorizer_model,
umap_model=umap_model,
hdbscan_model=cluster_model, # 传入kmeans模型
)
topics, probs = topic_model.fit_transform(docs, embeddings=embeddings) #传入训练好的词向量
topic_info = topic_model.get_topic_info()
topic_info将HDBSCAN算法换成Keans聚类模型。
应用Kmeans模型,主题生成结果没有离群值。
5.BERTopic模型
5.1 代码
import numpy as np
from bertopic import BERTopic
from transformers.pipelines import pipeline
from sentence_transformers import SentenceTransformer
from umap import UMAP
from hdbscan import HDBSCAN
from sklearn.feature_extraction.text import CountVectorizer
with open('./data/切词.txt', 'r', encoding='utf-8') as file:
docs = file.readlines()
print('条数: ', len(docs))
print('预览第一条: ', docs[0])
vectorizer_model = None
# 1. 词向量模型,同时加载本地训练好的词向量
embedding_model = pipeline("feature-extraction", model="bert-base-chinese") # 使用bert-base-chinese
embeddings = np.load('./data/emb_bert.npy') # 使用bert-base-chinese向量
print('向量shape:', embeddings.shape)
# 2. 创建UMAP降维模型
umap_model = UMAP(
n_neighbors=15,
n_components=5,
min_dist=0.0,
metric='cosine',
random_state=42
)
# 3. 创建HDBSCAN聚类模型
hdbscan_model = HDBSCAN(
min_cluster_size=10,
min_samples=5,
metric='euclidean'
)
# 5. 创建CountVectorizer模型
vectorizer_model = CountVectorizer( ) #因为已经分好词,所以不需要传入分词函数。
# 6. 正式创建BERTopic模型
topic_model = BERTopic(
embedding_model=embedding_model,
vectorizer_model=vectorizer_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
)
# 7.查看主题
topics, probs = topic_model.fit_transform(docs, embeddings=embeddings) #传入训练好的词向量
topic_info = topic_model.get_topic_info()
topic_info5.2 参数调节
1.nr_topics:指定合并为几个主题。当nr_topics="auto”时,意味着自动决定合并为几个主题。还可以设置为几个主题,比如nr_topics=5,那就是5个主题。但是当我们设置数值的时候,面临的是这个数值的解释性,为什么选择这个数值。
6.min_topic_size:设置一个主题类别中最少需要包含多少文档。如果想得到更多的主题,将该值设置的小一些,如果只想要得到几个大的主题,就可以将该值设置得大一些。
min_cluster_size和nr_topics都可以调节主题数量。
模型作者表示,相较于nr_topics的参数调节,调节min_cluster_size参数的结果往往会更满意。
5.3 合并主题
topic_model.merge_topics(docs, [1, 4])
topic_model.get_topic_info()5.4主题优化
该模型会将冗余的词进行替换,生成更具有多样性的主题词。
from bertopic.representation import MaximalMarginalRelevance # 导入
representation_model = MaximalMarginalRelevance(diversity=0.3) # 创建mmr模型
topic_model = BERTopic(
embedding_model=embedding_model,
vectorizer_model=vectorizer_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
representation_model=representation_model # 传入模型
)
topics, probs = topic_model.fit_transform(docs, embeddings=embeddings)
topic_info = topic_model.get_topic_info()
topic_info5.5 主题保存
# 打印主题信息
topic_docs = topic_model.get_document_info(docs)
topic_docs.to_csv('./聚类结果_sen.csv')6.可视化
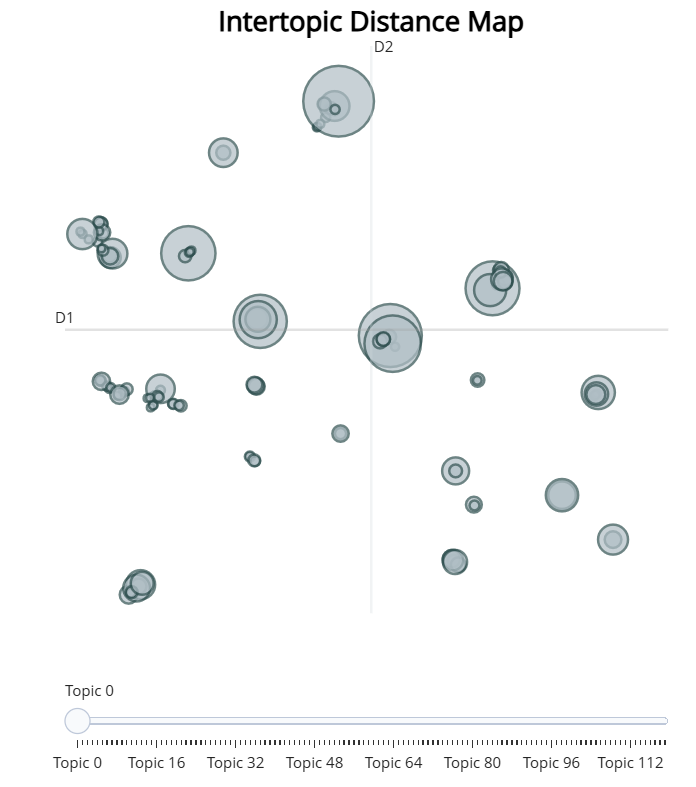
6.1 主题分布可视化
#主题分布
topic_model.visualize_topics()
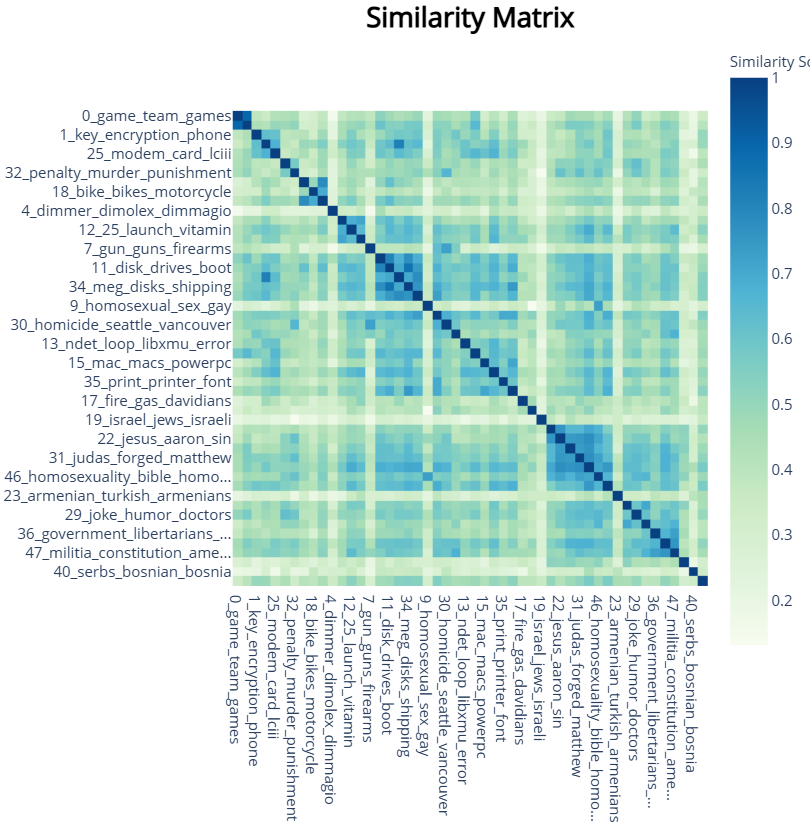
6.2 主题相似度可视化
# 主题相似度
topic_model.visualize_heatmap()
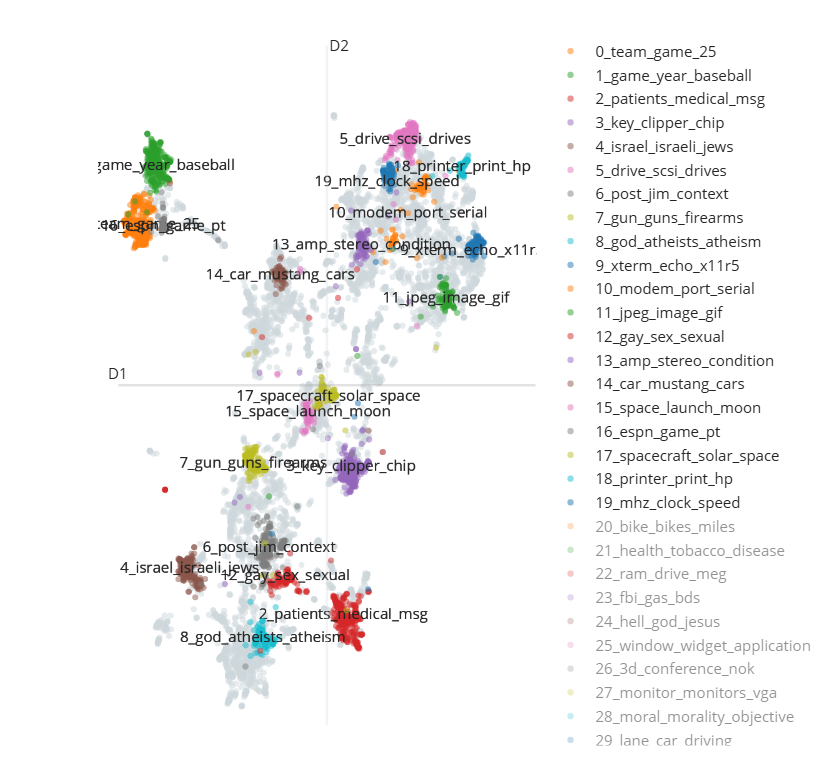
6.3 文档散点图可视化
# 文档散点图的可视化
from sklearn.datasets import fetch_20newsgroups
from sentence_transformers import SentenceTransformer
from bertopic import BERTopic
from umap import UMAP
# Prepare embeddings
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
sentence_model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = sentence_model.encode(docs, show_progress_bar=False)
# Train BERTopic
topic_model = BERTopic().fit(docs, embeddings)
# Run the visualization with the original embeddings
topic_model.visualize_documents(docs, embeddings=embeddings)
# Reduce dimensionality of embeddings, this step is optional but much faster to perform iteratively:
reduced_embeddings = UMAP(n_neighbors=10, n_components=2, min_dist=0.0, metric='cosine').fit_transform(embeddings)
topic_model.visualize_documents(docs, reduced_embeddings=reduced_embeddings)
6.4 主题关键词可视化
# 主题关键词的可视化
topic_model.visualize_barchart()
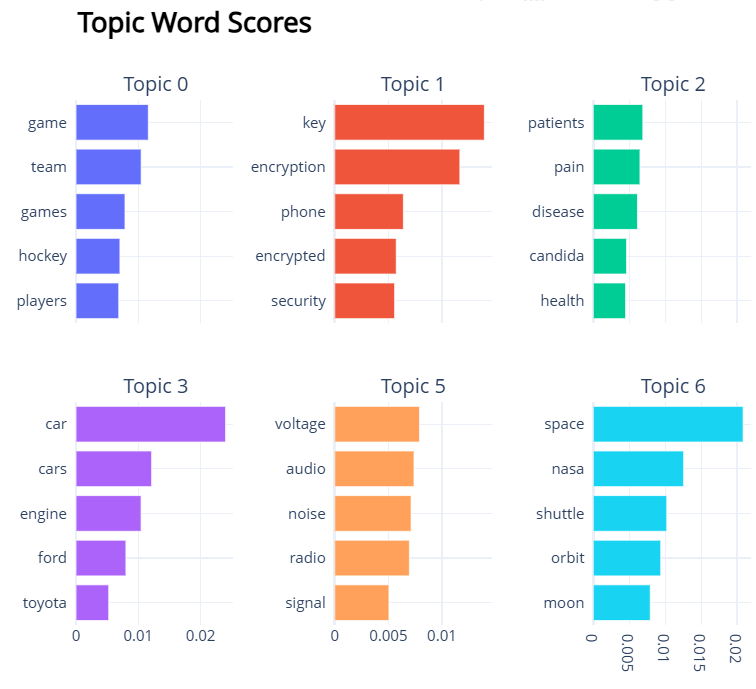
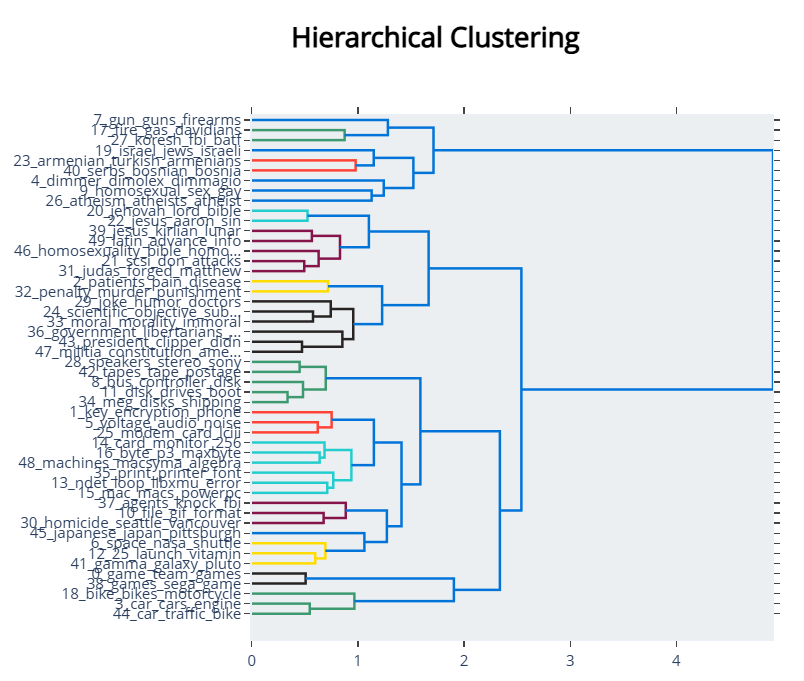
6.5 层级可视化
topic_model.visualize_hierarchy()
6.6 UMAP可视化
reduced_embeddings = UMAP(n_neighbors=10, n_components=2, min_dist=0.0, metric='cosine').fit_transform(embeddings)
topic_model.visualize_documents(docs, reduced_embeddings=reduced_embeddings)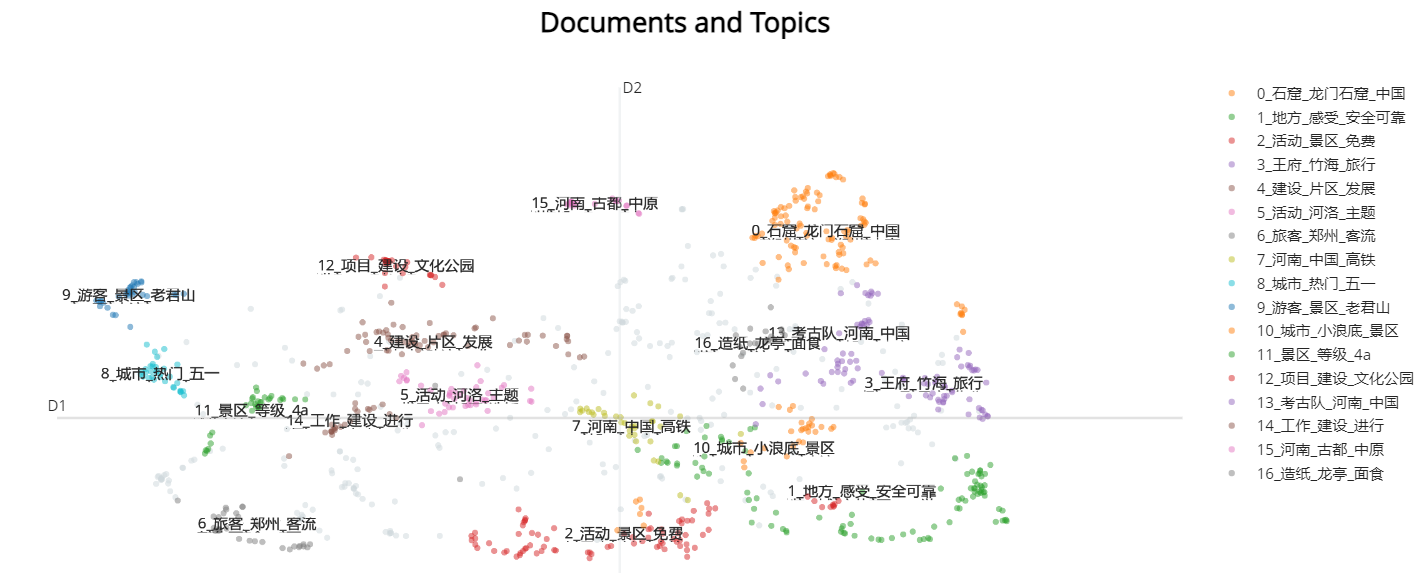
7.层次主题模型
寻找到主题之间的层次结构,自动化分主题层次,适用于主题较多,需要对主题分类的场景。
hierarchical_topics = topic_model.hierarchical_topics(docs)
topic_model.visualize_hierarchy(hierarchical_topics=hierarchical_topics)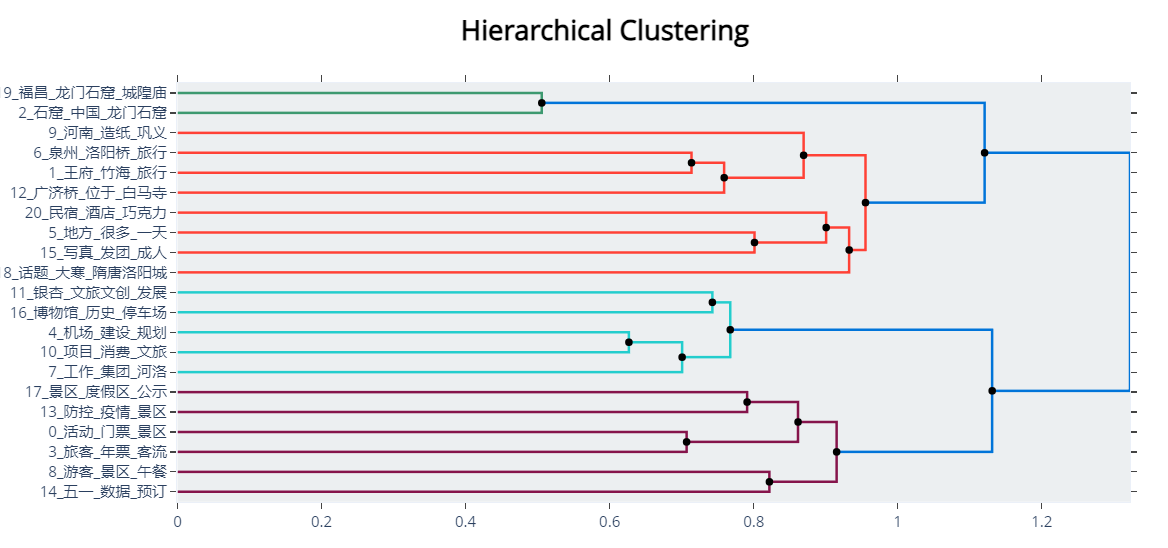
8.动态主题模型
动态主题模型主要是用来分析各类主题随时间的演变。
# 读取时间戳
with open('./data/时间.txt', "r", encoding='utf-8') as file:
lines = file.readlines()
timestamps = [int(line.strip()) for line in lines]
print(len(timestamps), timestamps[:10])
topics_over_time = topic_model.topics_over_time(docs, timestamps, global_tuning=False, evolution_tuning=False)
topic_model.visualize_topics_over_time(topics_over_time)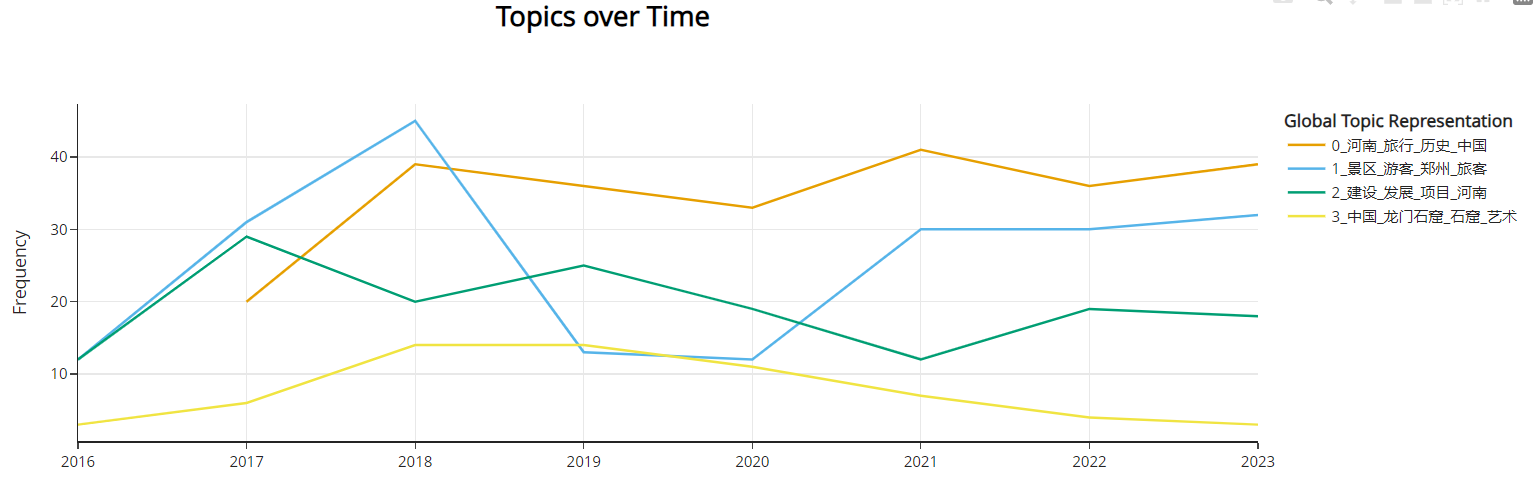
9.BERTopic代码编写及论文写作经验
9.1 如何减少离群值
9.1.1 reduce outliers函数
# 调用函数
new_topics = topic_model.reduce_outliers(docs, topics, probabilities=probs, strategy="probabilities", threshold=0.5)
# 应用更新
topic_model.update_topics(docs, topics=new_topics, vectorizer_model=vectorizer_model)docs:文档
topics:主题分布
probabilities=probs:前文计算的概率
strategy="probabilities":策略就是用概率的方式来减少离群值
9.1.2 小结
1. HDBSCAN的min_sanmples、min_cluster_size
2.UMAP的min_dist、random_state
3. reduce outlier
4.清理数据
9.2 其他注意事项
1.官方文档说明:不建议一开始就先进行停用词处理,会影响整体的语义表示,所以BERTopic模型的停用词可以等文本嵌入和聚类完成之后,再进行停用词的处理。
2.注意,使用不同嵌入模型时,要根据不同模型的参数,同时调整切词的文本处理。比如paraphrase-multilingual-mpnet-base-v2模型的最大长度为128,那么在相应生成embedding模型时,本身的切词处理就应该也设置为128。
3.分析结果的时候,一定要回到原文档,多看,多理解,多领会,才能分析得更准确。
4.一定要提前清理数据,提供高质量的原数据。
本文参考了b站视频,十分感谢原作者。
原视频链接贴在这里~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









