







 本文涵盖了AI的基础数学概念,包括矩阵、张量运算、线性图像分类器、线性变换和矩阵分解。同时,介绍了概率论中的随机变量和分布,如伯努利、二项和泊松分布。文章还涉及最优化问题,特别是梯度下降法,并讨论了Python编程中的数学函数和线性代数操作。此外,文章还展示了基于MindSpore的机器学习和深度学习应用,包括机器学习算法流程和实例。
本文涵盖了AI的基础数学概念,包括矩阵、张量运算、线性图像分类器、线性变换和矩阵分解。同时,介绍了概率论中的随机变量和分布,如伯努利、二项和泊松分布。文章还涉及最优化问题,特别是梯度下降法,并讨论了Python编程中的数学函数和线性代数操作。此外,文章还展示了基于MindSpore的机器学习和深度学习应用,包括机器学习算法流程和实例。
AI数学基础
矩阵
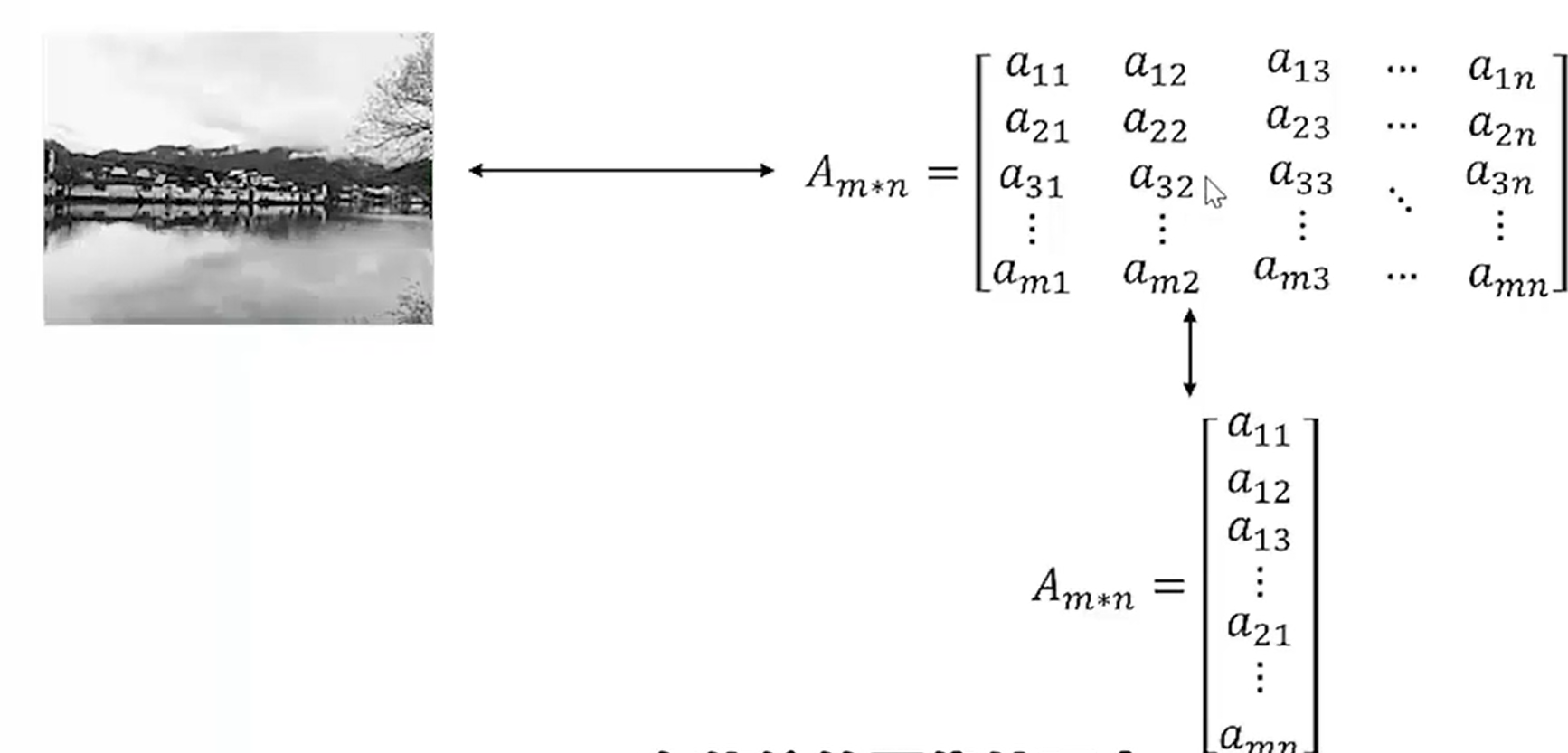
上图中,将一张图片以矩阵的形式存储,并通过按列展开成了一个列向量。
张量
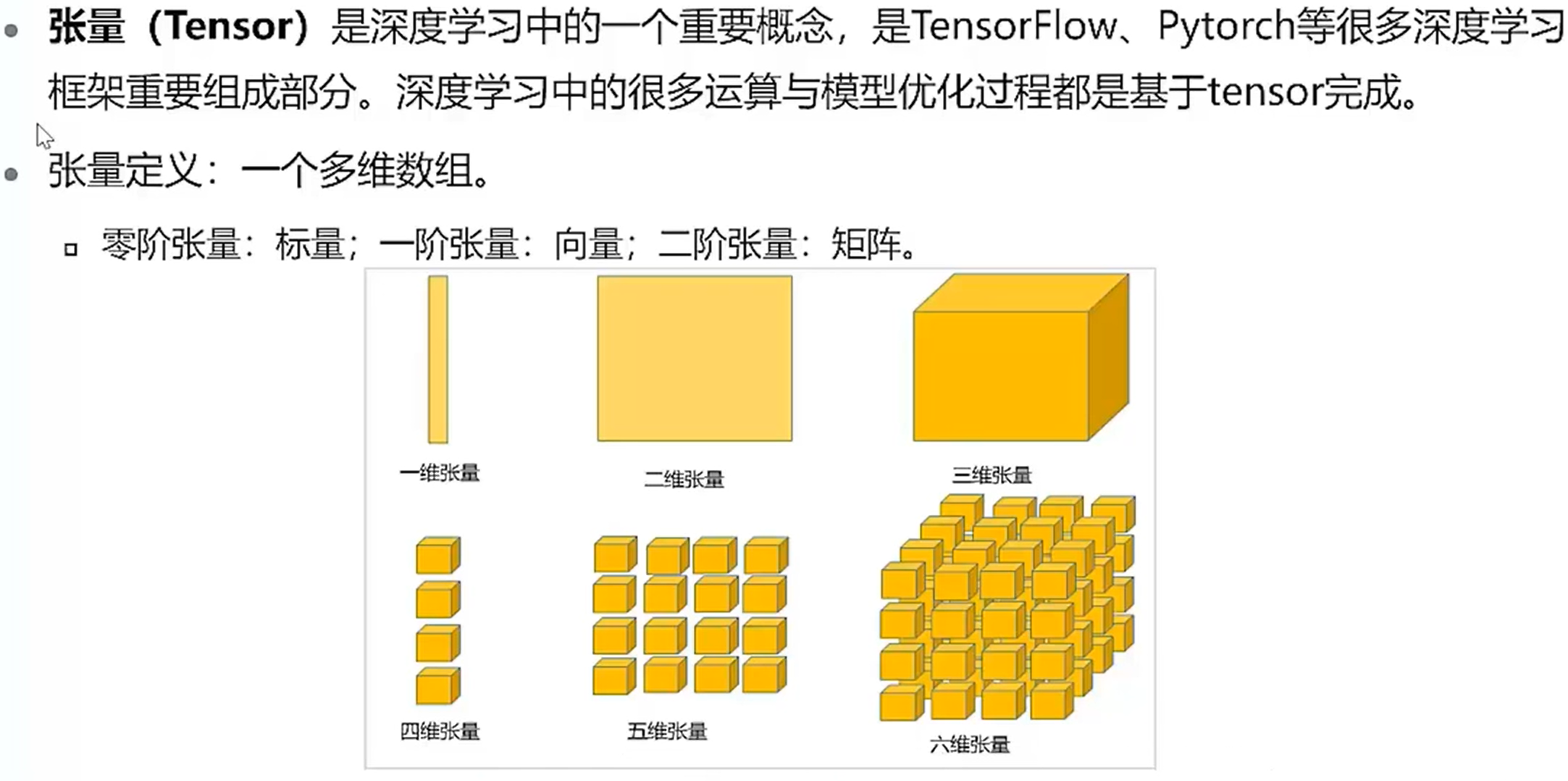
一维是线性的,二维是平面的,三维是立体的,四维是三维向量的线性排列,五维是三维的平面排列,六维是三维向量的立体排列。
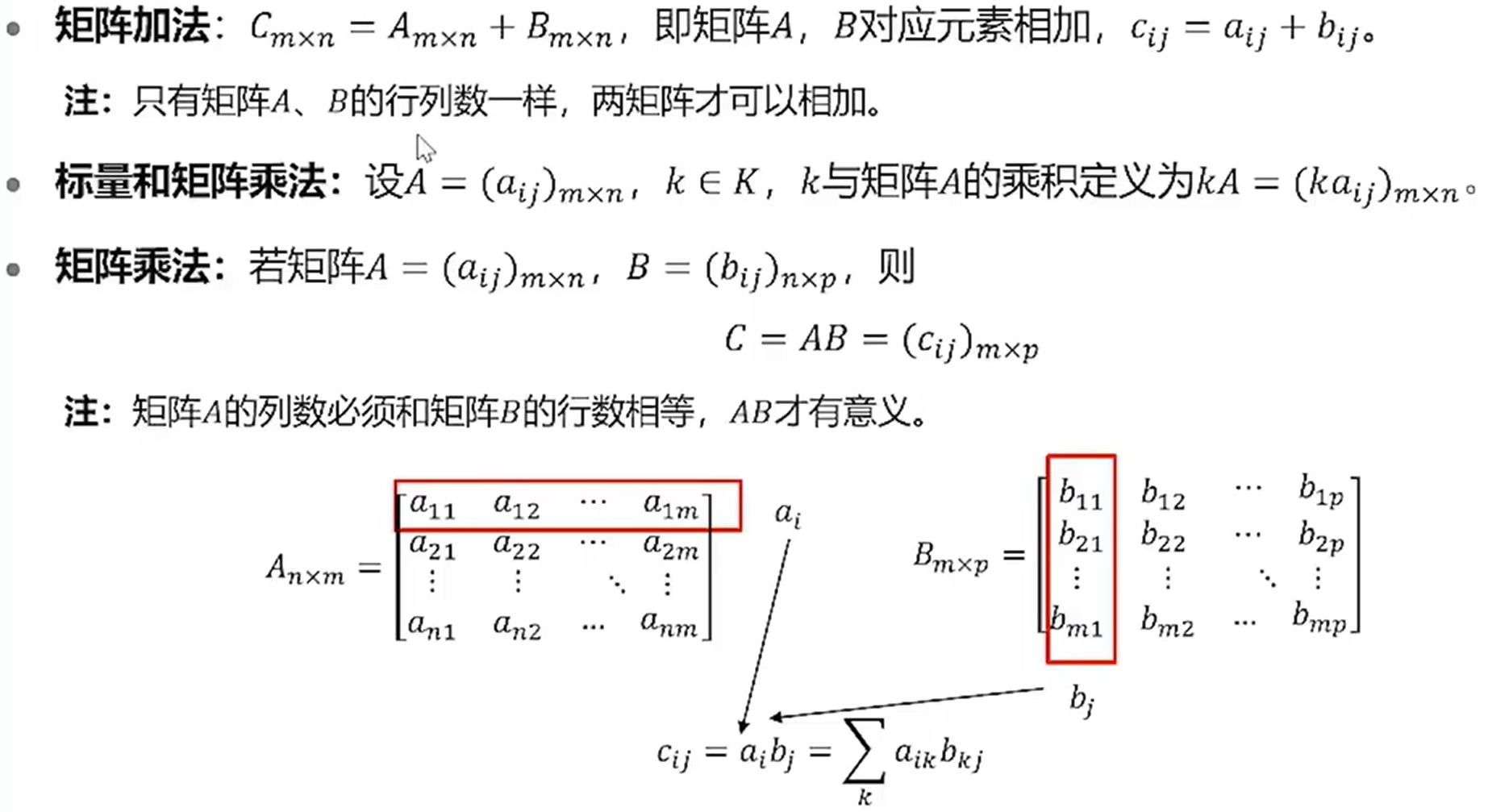
矩阵的运算
线性图像分类器
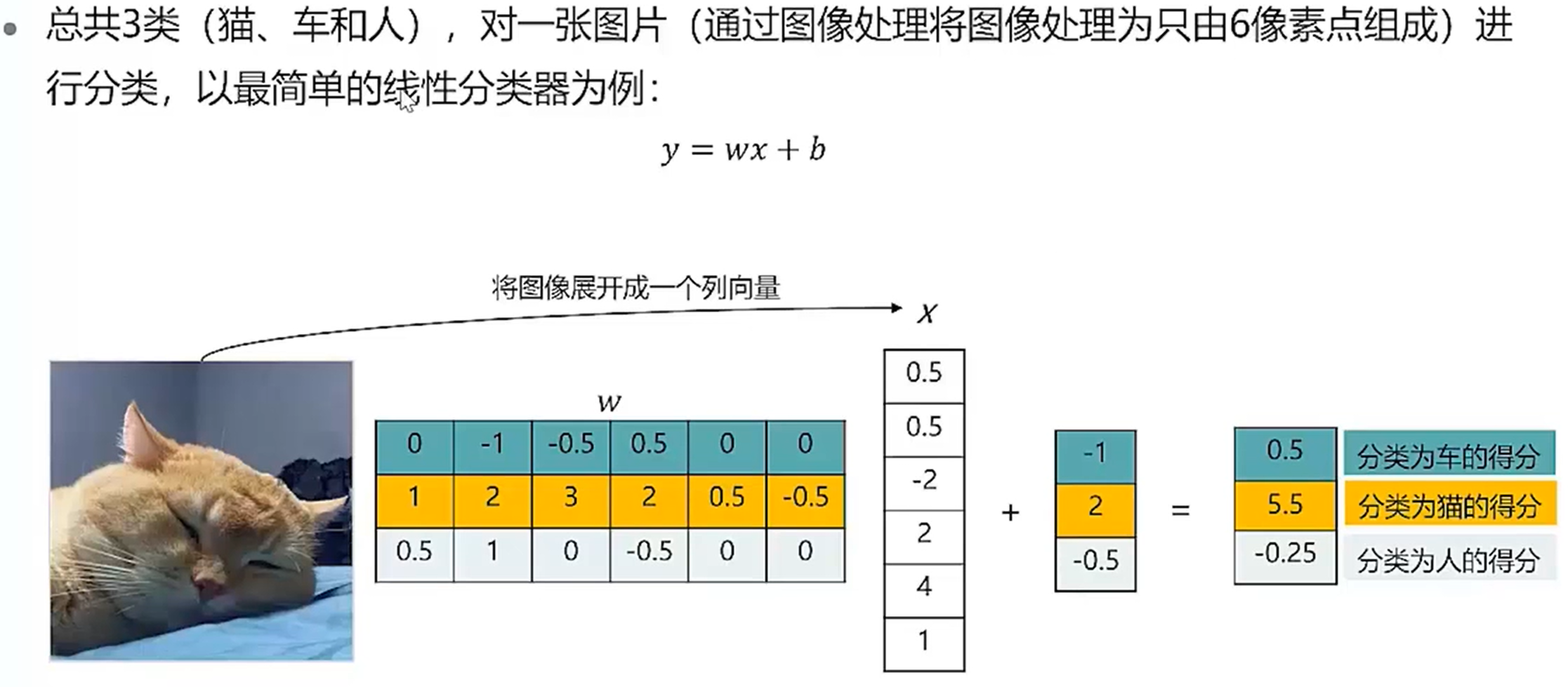
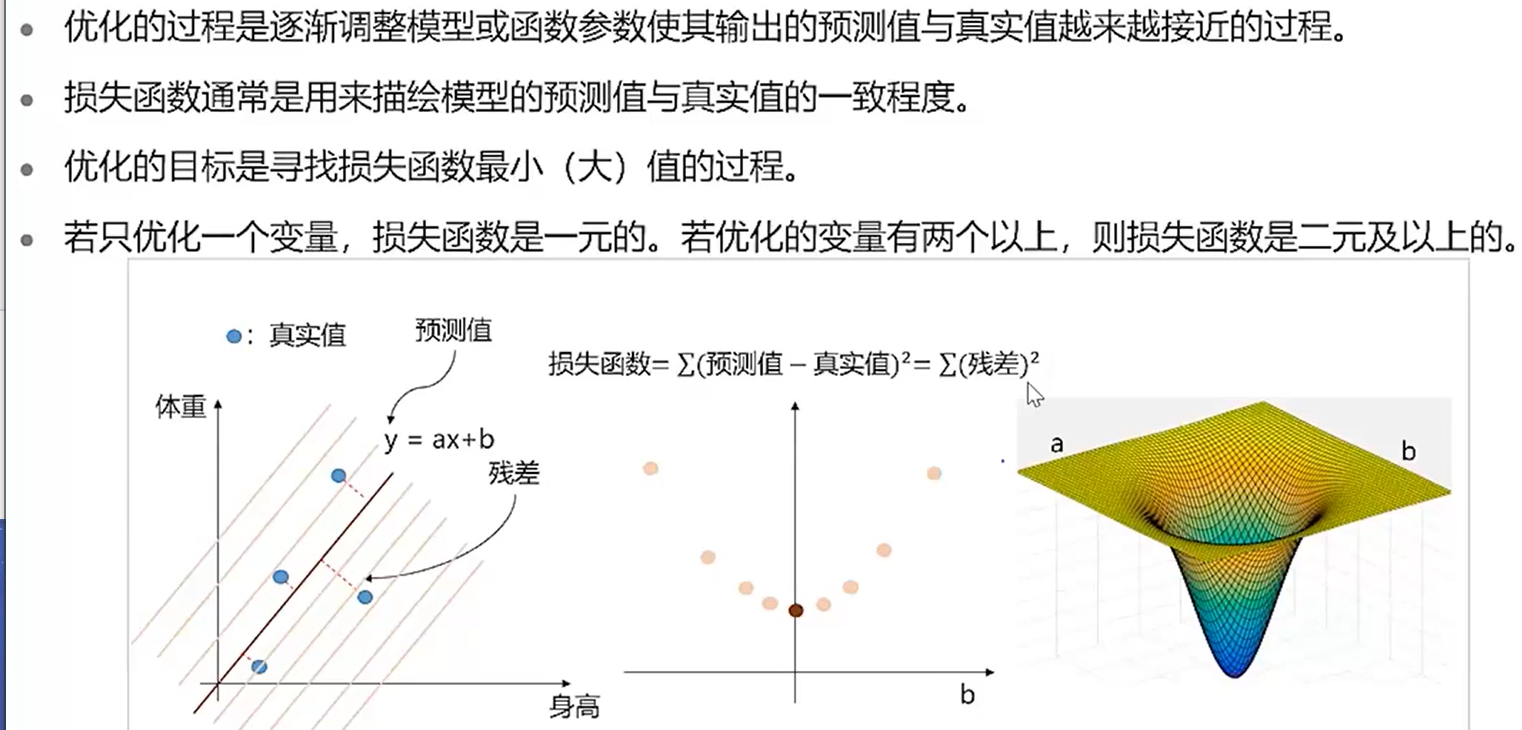
以损失函数为基准,能够找出使该损失函数的值达到最小的权重参数,即权重矩阵可以通过学习得到。神经网络中的学习是指从训练数据中自动获取最有权重参数的过程。
线性变换

线性变换在深度学习中最直观的应用为通过矩阵乘法对图像或语音数据集进行增强,比如将图像沿着某个方向平移、进行旋转或缩放等以产生新的图像。
矩阵的运动

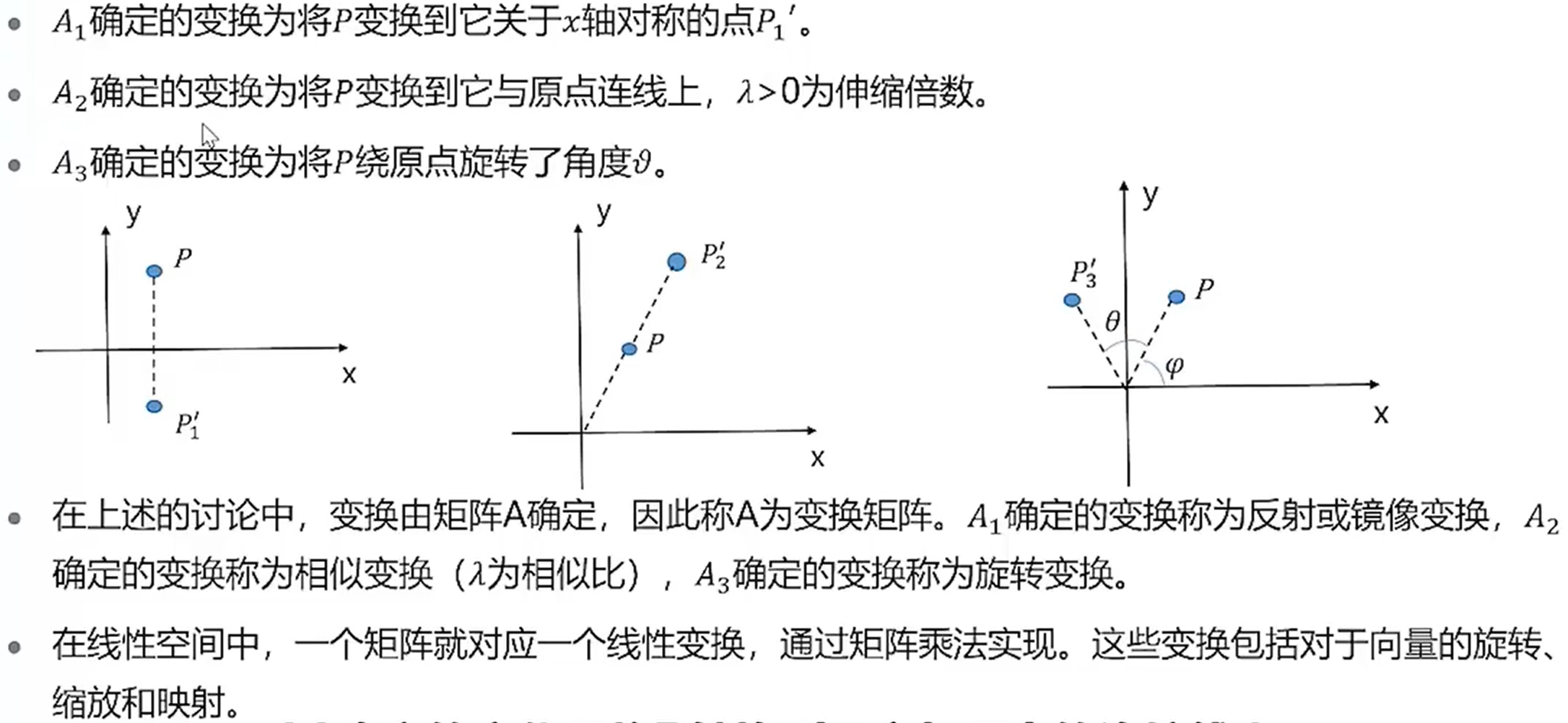
矩阵分解
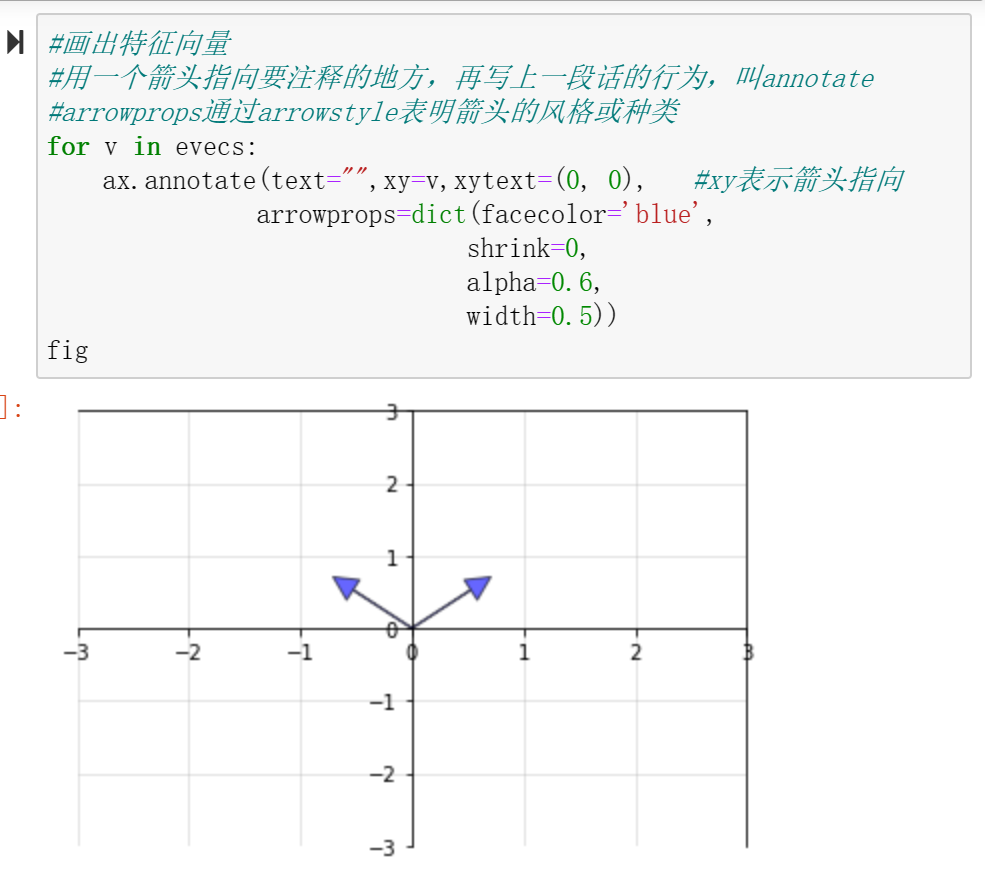
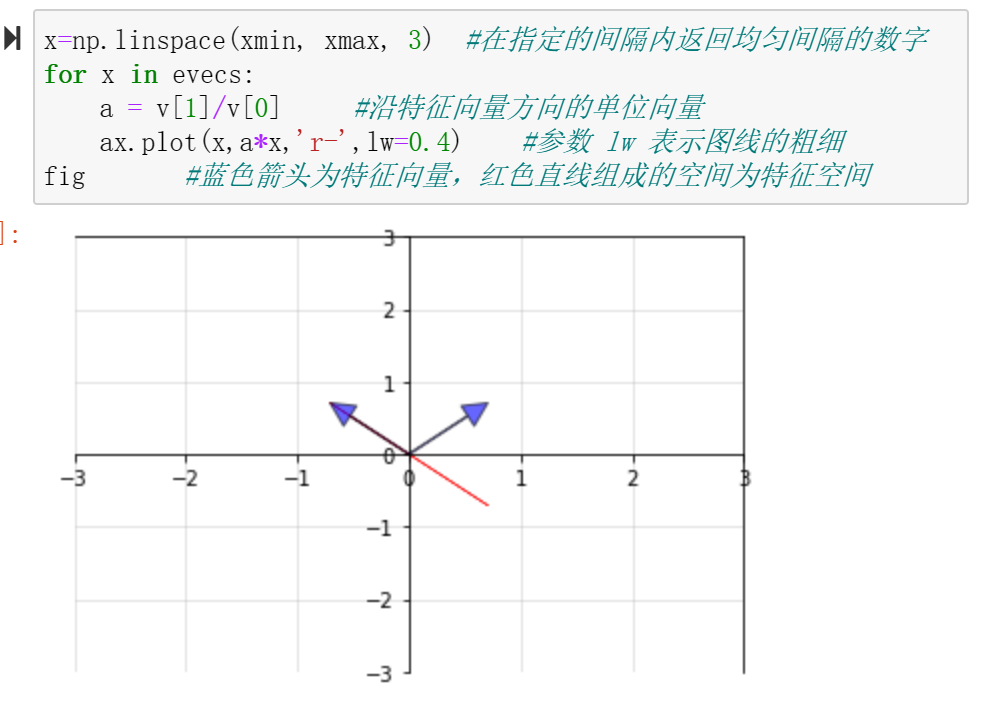
特征值和特征向量
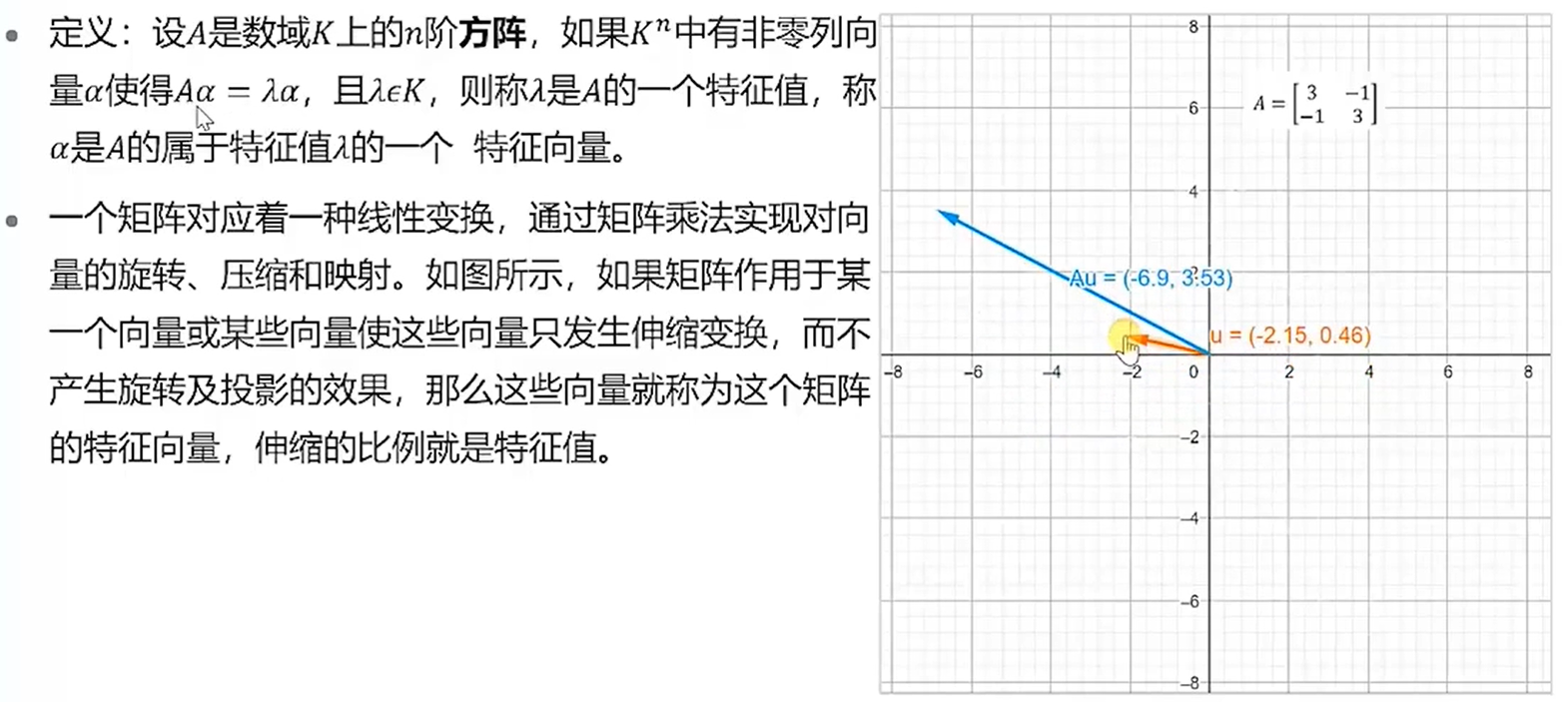
特征值和特征向量是矩阵分解中最基本的组成元素。

特征分解

奇异值分解

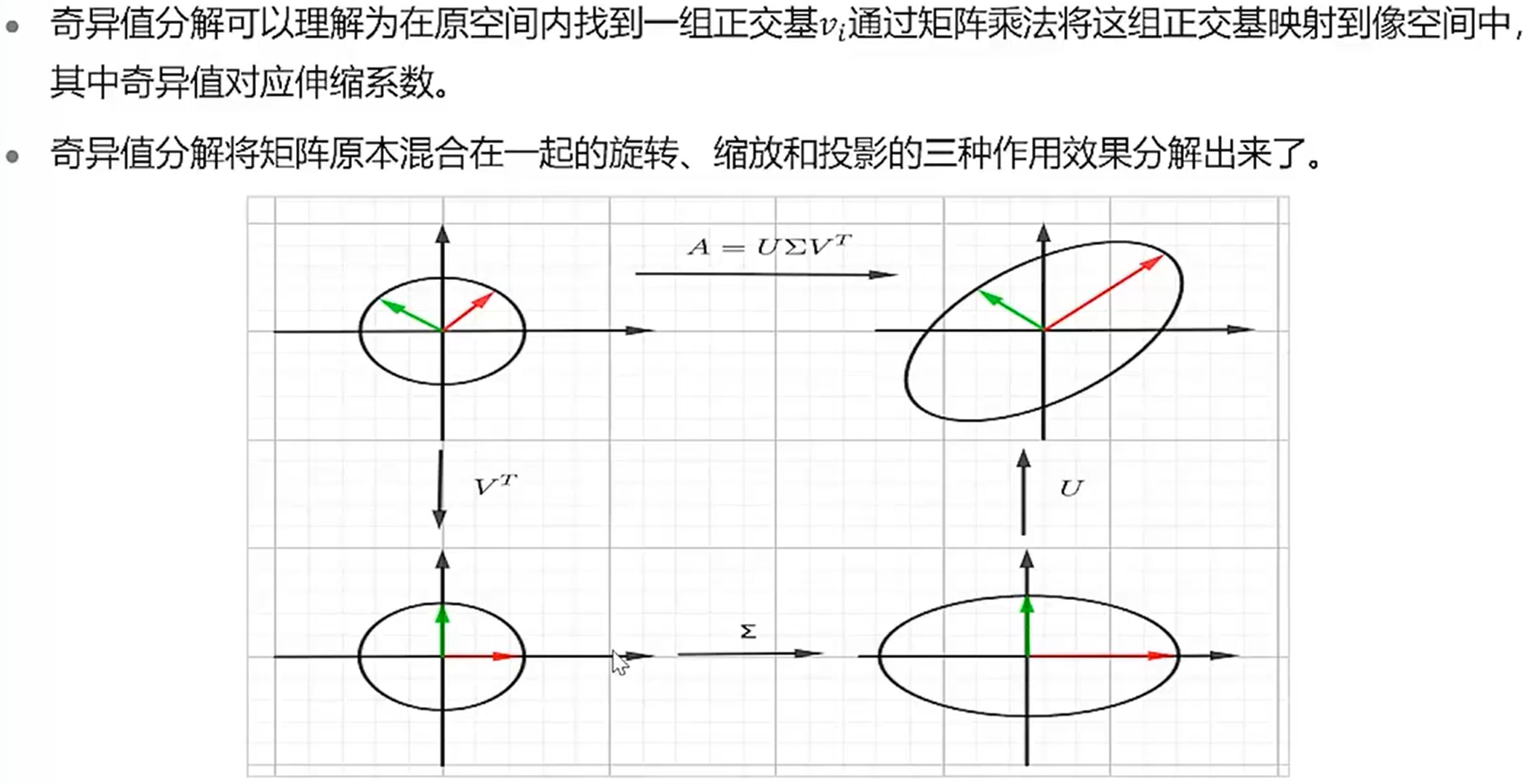


随着奇异向量值k的增加,图像也越来越保真,即越来越接近原图,但当奇异向量值为30时已经基本上能够保留图像的信息了,故取图像前30个分量即可表示图像,以达到图像压缩的目的。
概率论
随机变量及其分布
随机变量
本质上是一个函数,是从样本空间的子集到实数的映射,将事件转换成一个数值。一些随机试验的结果可能不是数,难以进行描述或研究,如S={正面,反面}。因此引入了随机变量的概念,将随机实验的一个结果与实数对应起来。

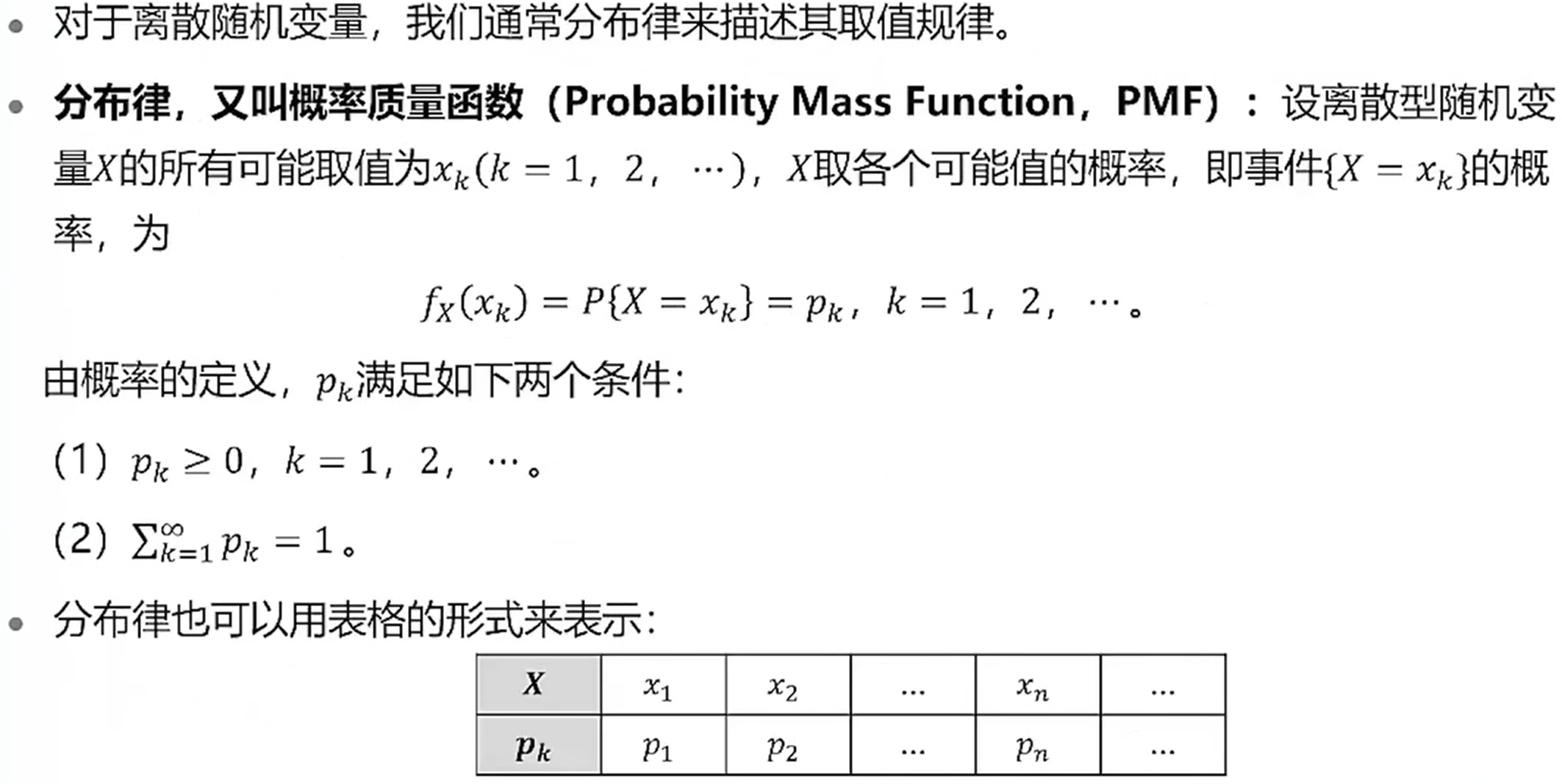
分布律
特殊离散分布
伯努利分布

二项分布

泊松分布

分布函数
研究分布函数可以取到某一区间的概率。

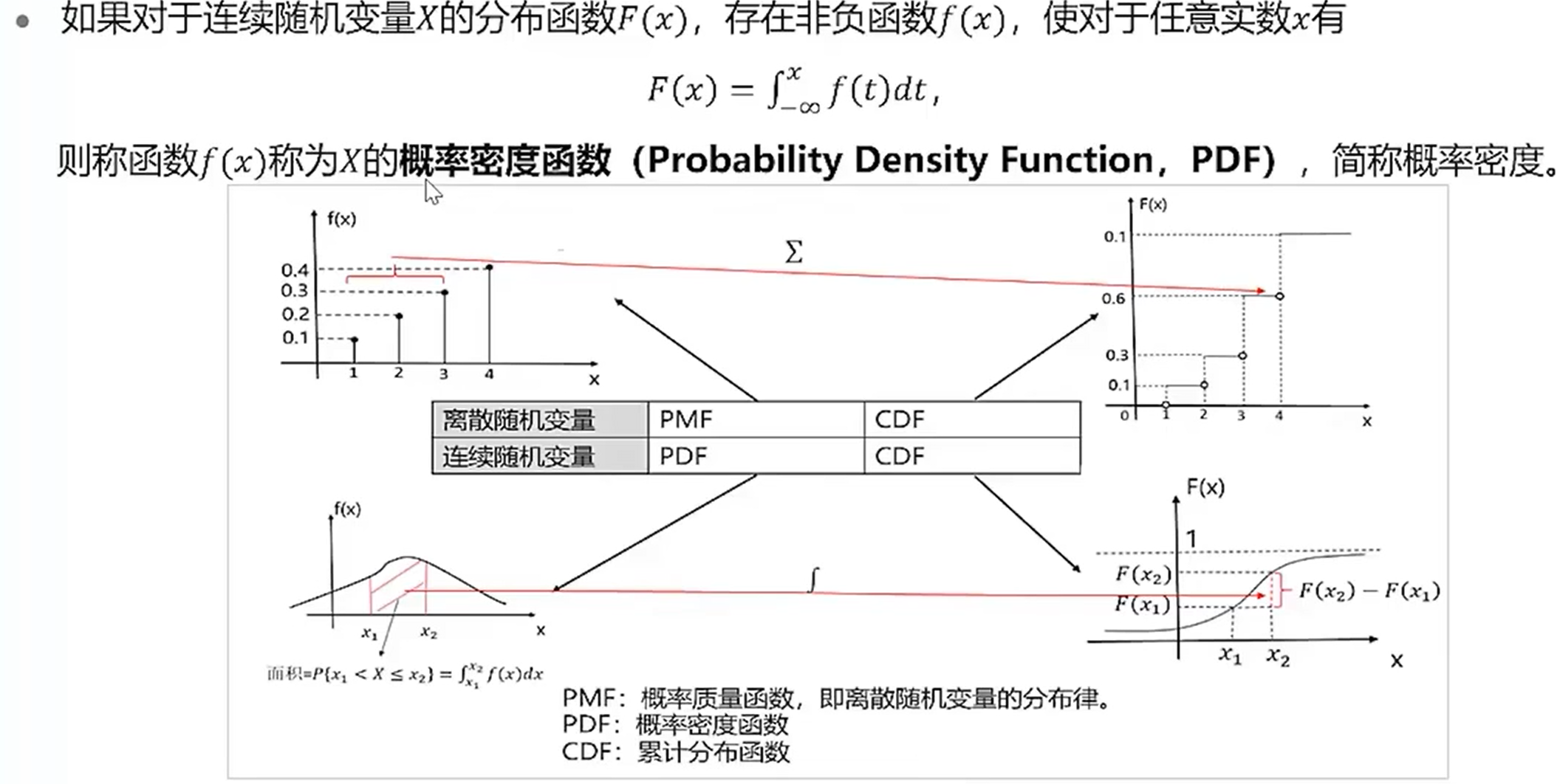
连续分布
正态分布


随机向量及其分布
随机向量

如果X(w)是一个人,那么X_1(w),X_2(w),… ,X_n(w)可能就是他身体的某一些特征。
联合分布函数
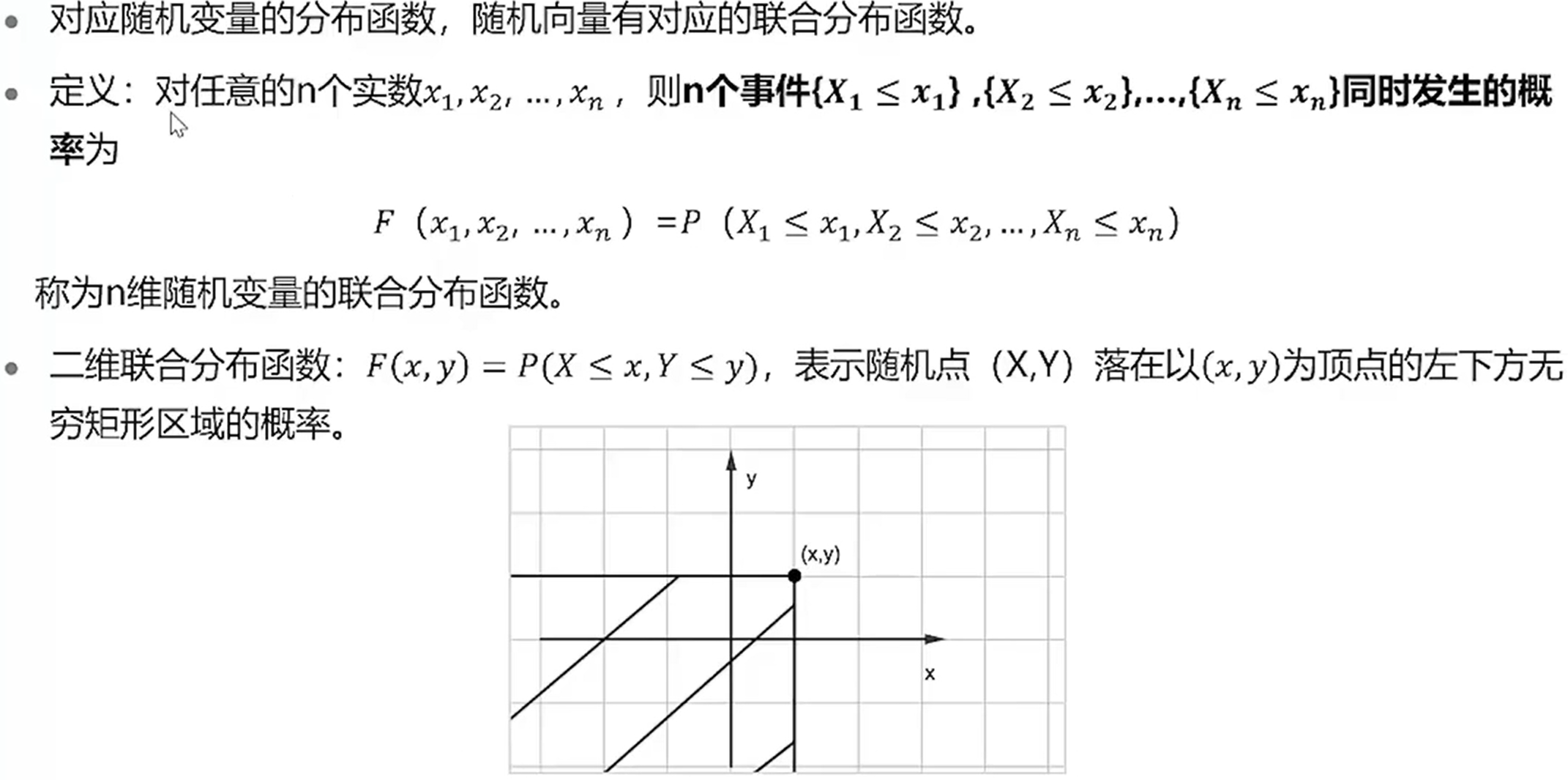
联合概率密度

贝叶斯定理



数字特征

对于以为随机变量而言,期望和方差是描述概率分布函数或者是分布率的数字特征。

对于一维随机向量而言,协方差、相关系数及协方差矩阵是描述概率分布或分布率的数字特征。
最优化问题
最优化问题分类



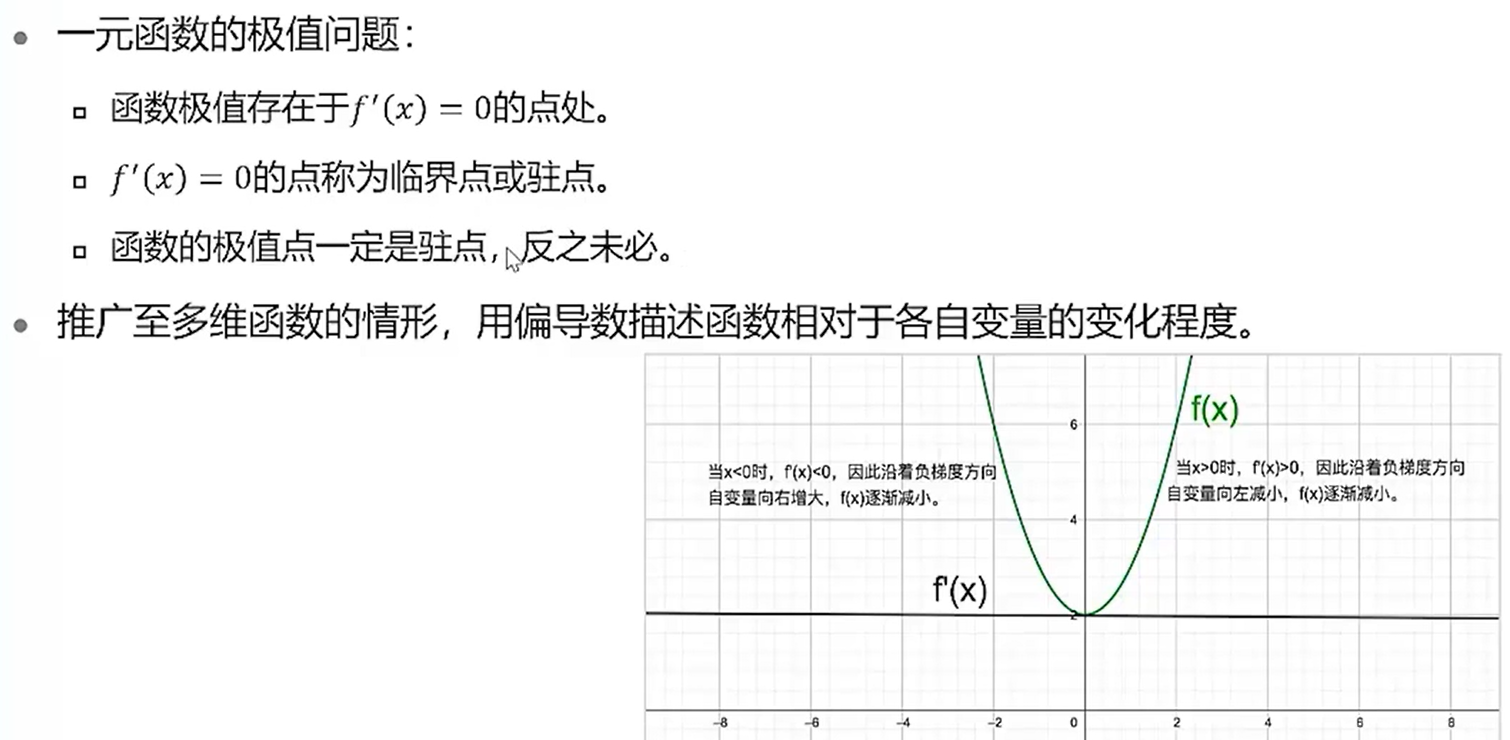
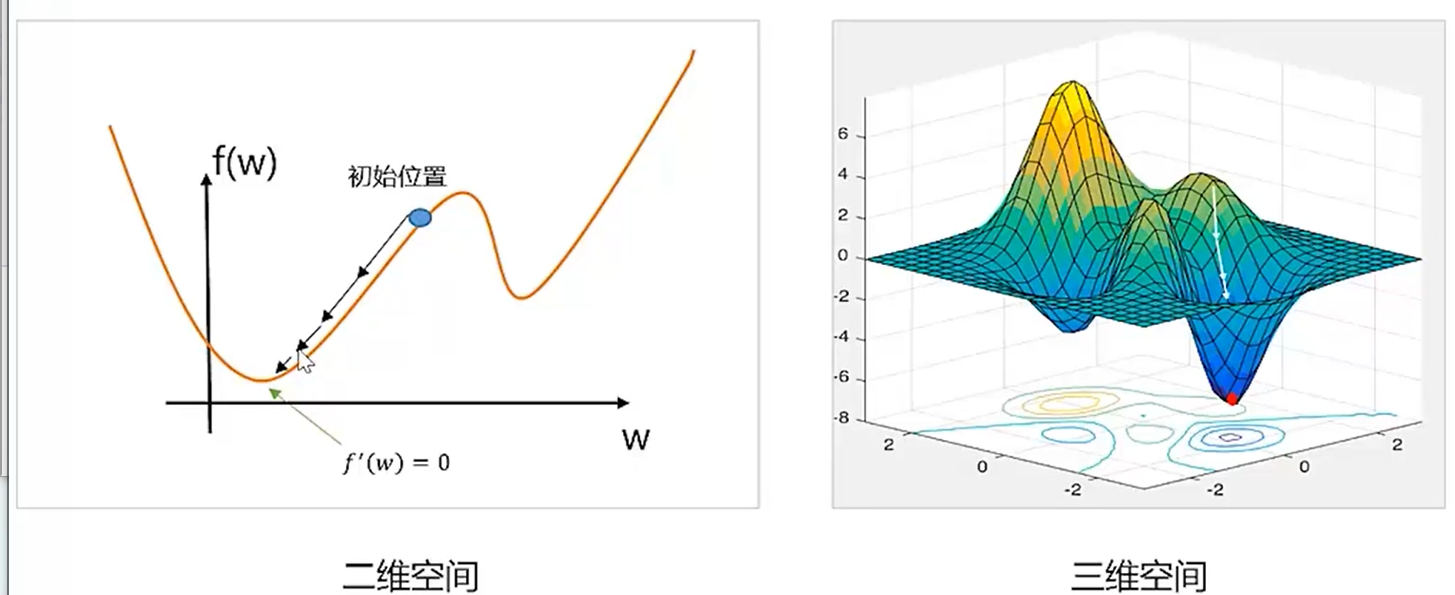
梯度下降
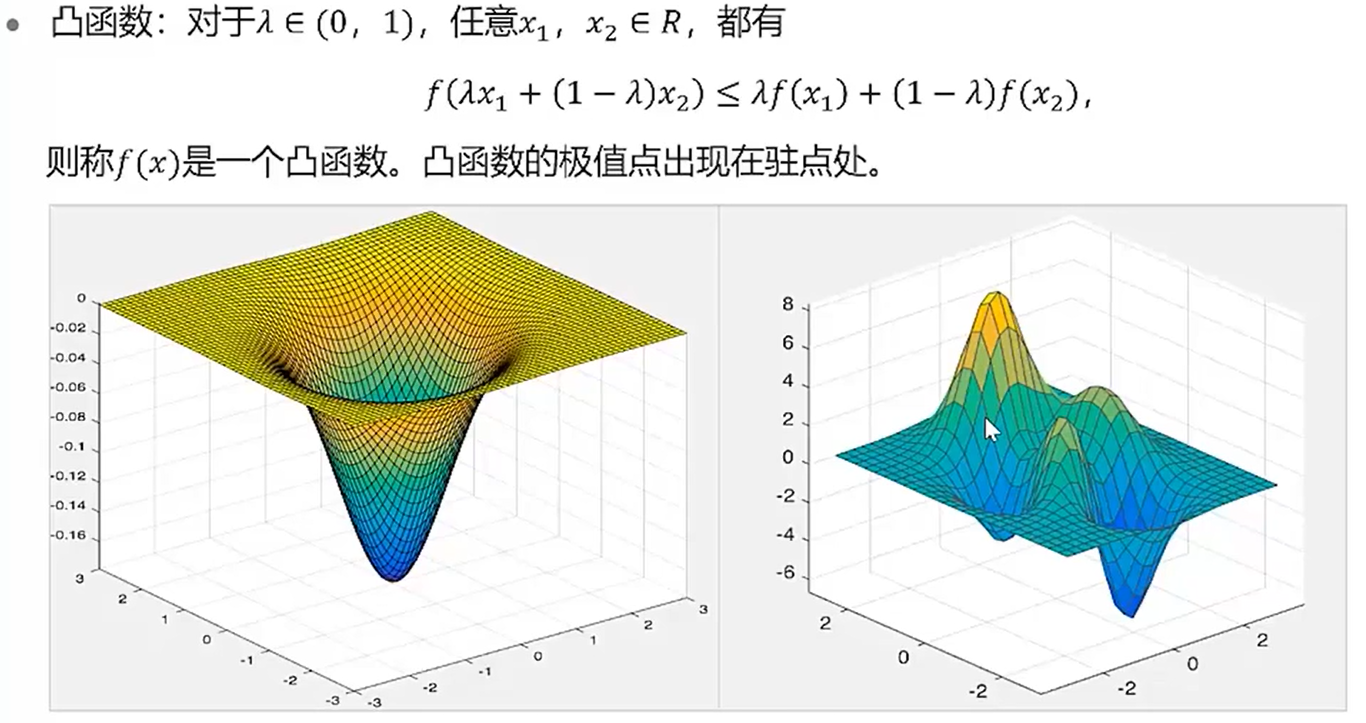
左边是凸函数,右边是非凸函数。梯度下降法用于求解凸函数的最优解。


Jupyter notebook实现
数学基础
以下例子主要使用了math库。
1、ceil(x) 取大于x的最小整数值,如果x是一个整数,则返回自身。

2、floor(x) 取小于等于x的最大的整数值,如果x是一个整数,则返回自身。

3、degree(x) 把x从弧度制转换成角度。

4、exp(x) 返回math.e,也就是2.71828的x次方。

5、fabs(x) 返回x的绝对值。

6、factorial(x) 取x的阶乘的值。

7、fsum(iterable) 对迭代器里的每个元素进行求和操作。

8、fmod(x,y) 得到x/y的余数,其值是一个浮点数。

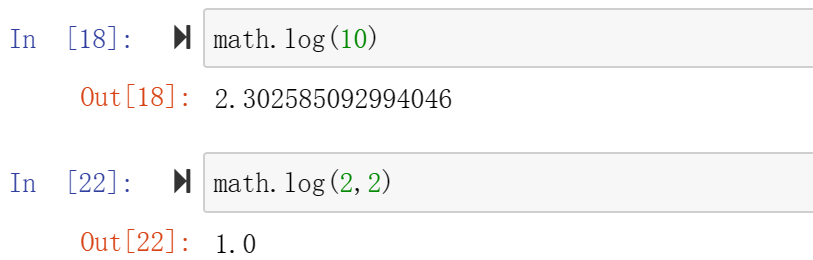
9、log(x,base) 返回x的自然对数,case为自定义底数,未设定时默认以e为底数。
10、sqrt(x) 求x的平方根。

11、pi是数字常量,圆周率。

12、**pow(x,y)**返回x的y次方,即x^y。

线性代数
主要使用numpy库以及scipy库。

1、reshape(x,y) 用于改变一个张量的维度数和每个维度的大小

2、转置实现T:向量和矩阵的转置通过交换行列顺序实现,而三位及以上张量的专职需要指定转换的维度。

3、矩阵乘法matmul(A,B):记两个矩阵依次为A、B,A矩阵的列数必须等于B矩阵的行数。

4、矩阵直接加减乘除,针对形状相同的矩阵相同位置的元素左运算。

5、linalg.inv(A) 逆矩阵实现,只有A为方阵才有逆矩阵实现。

6、linalg.det(E) 求解矩阵E的行列式。

7、求矩阵的特征值与特征向量并可视化。
使用scipy库中的linalg子库的 eig(A) 函数求特征值和特征向量
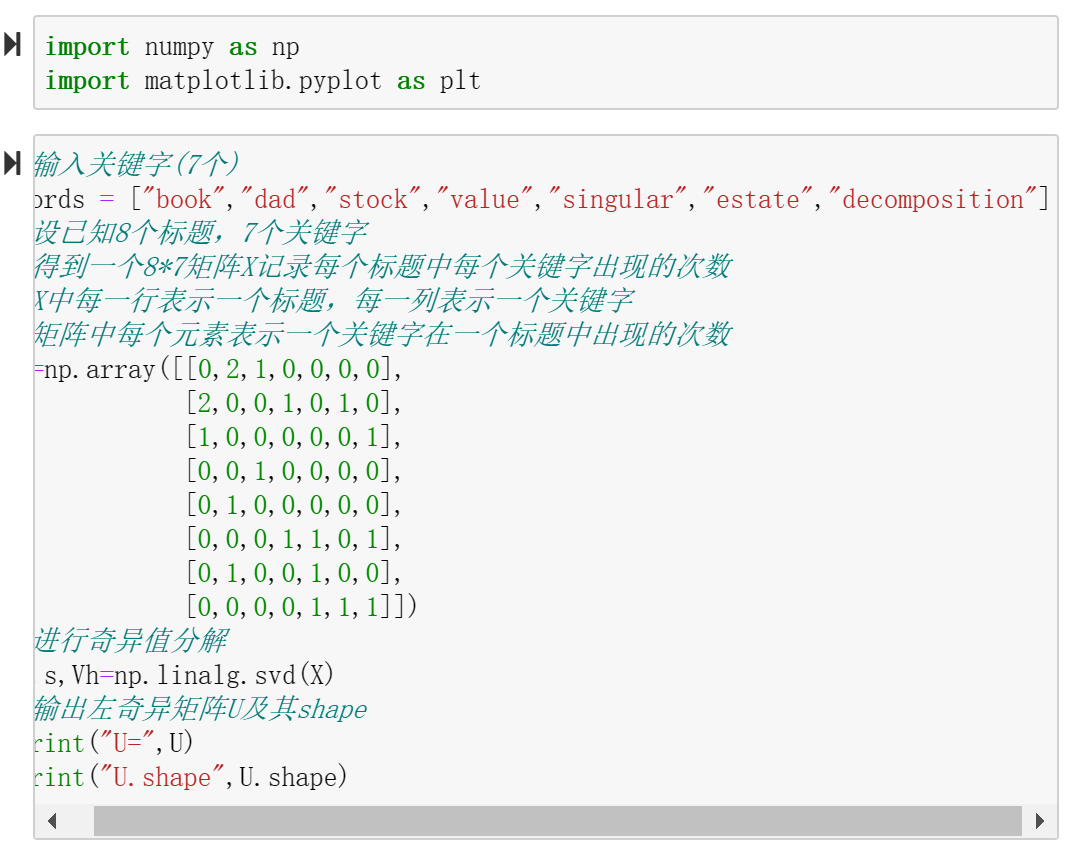
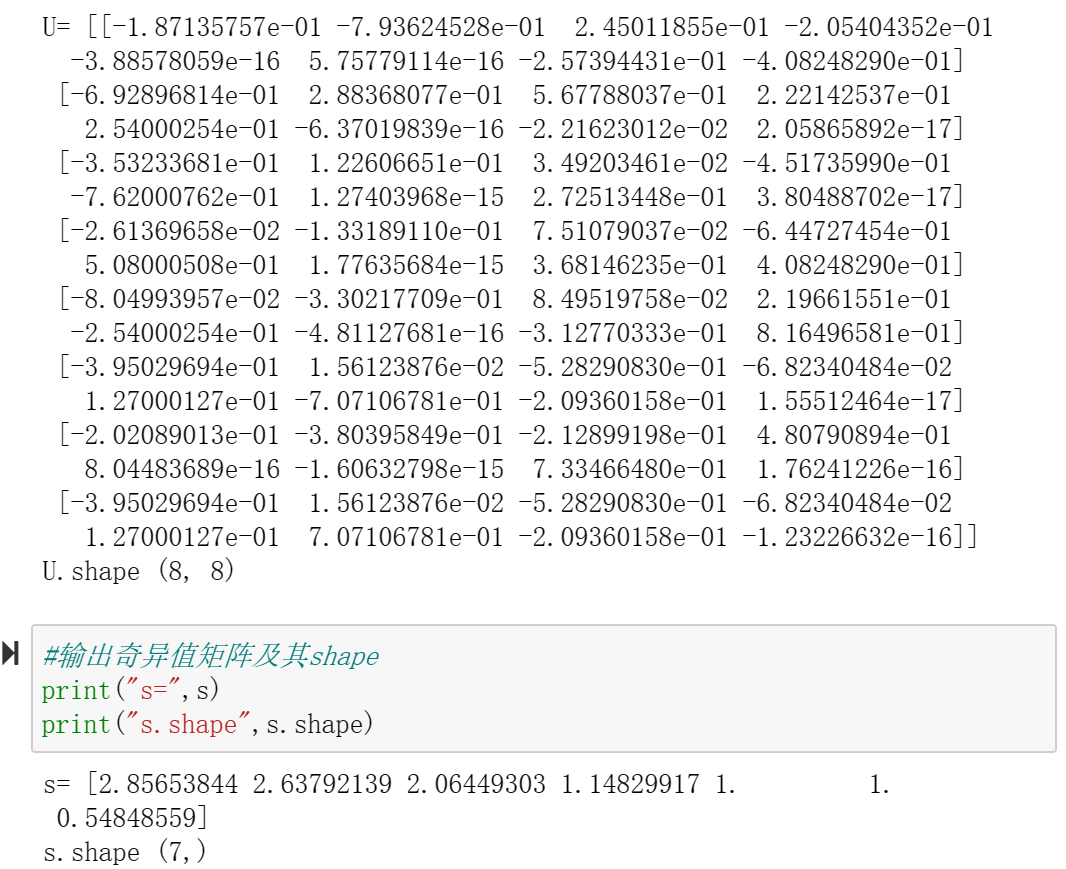
8、奇异值分解——文本聚类
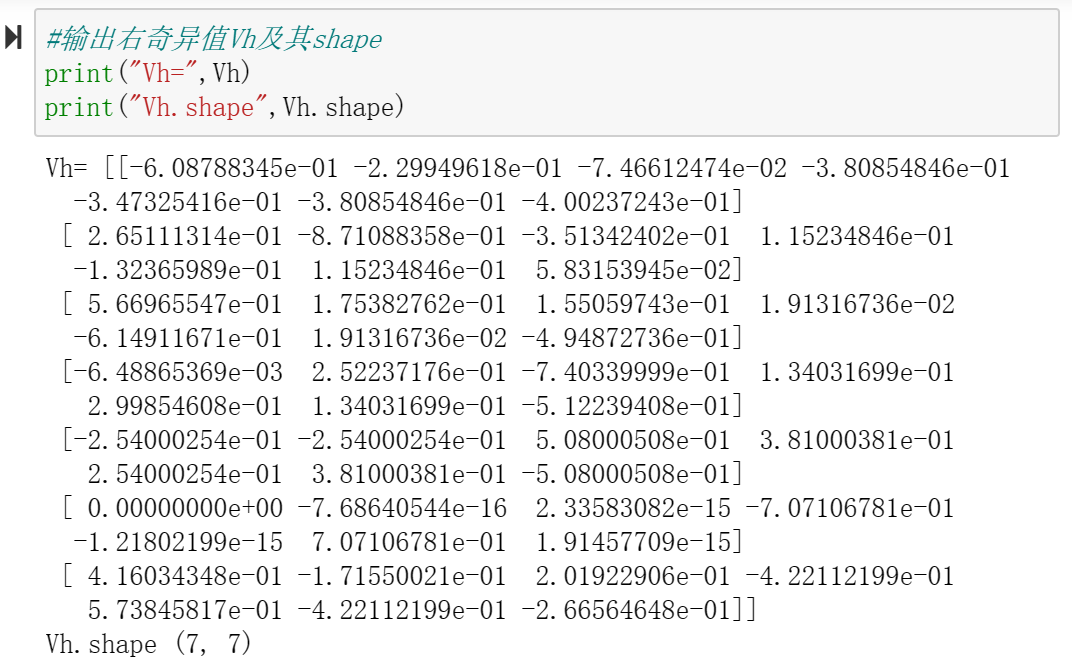
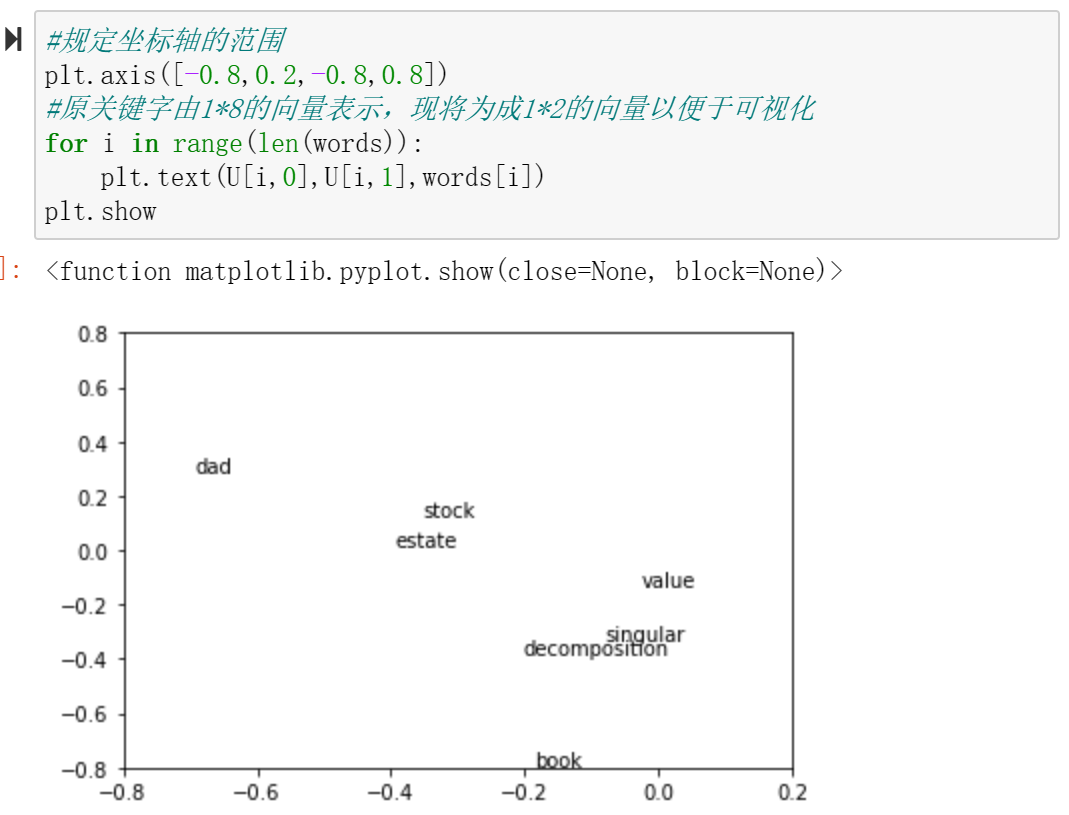
将2维可视化后,可以将关键词聚类,如singular, value和decomposition三个词举例较近可以被划分为一组,二stock和estate经常同时出现可以被划为另一组。
9、奇异值分解——图像压缩
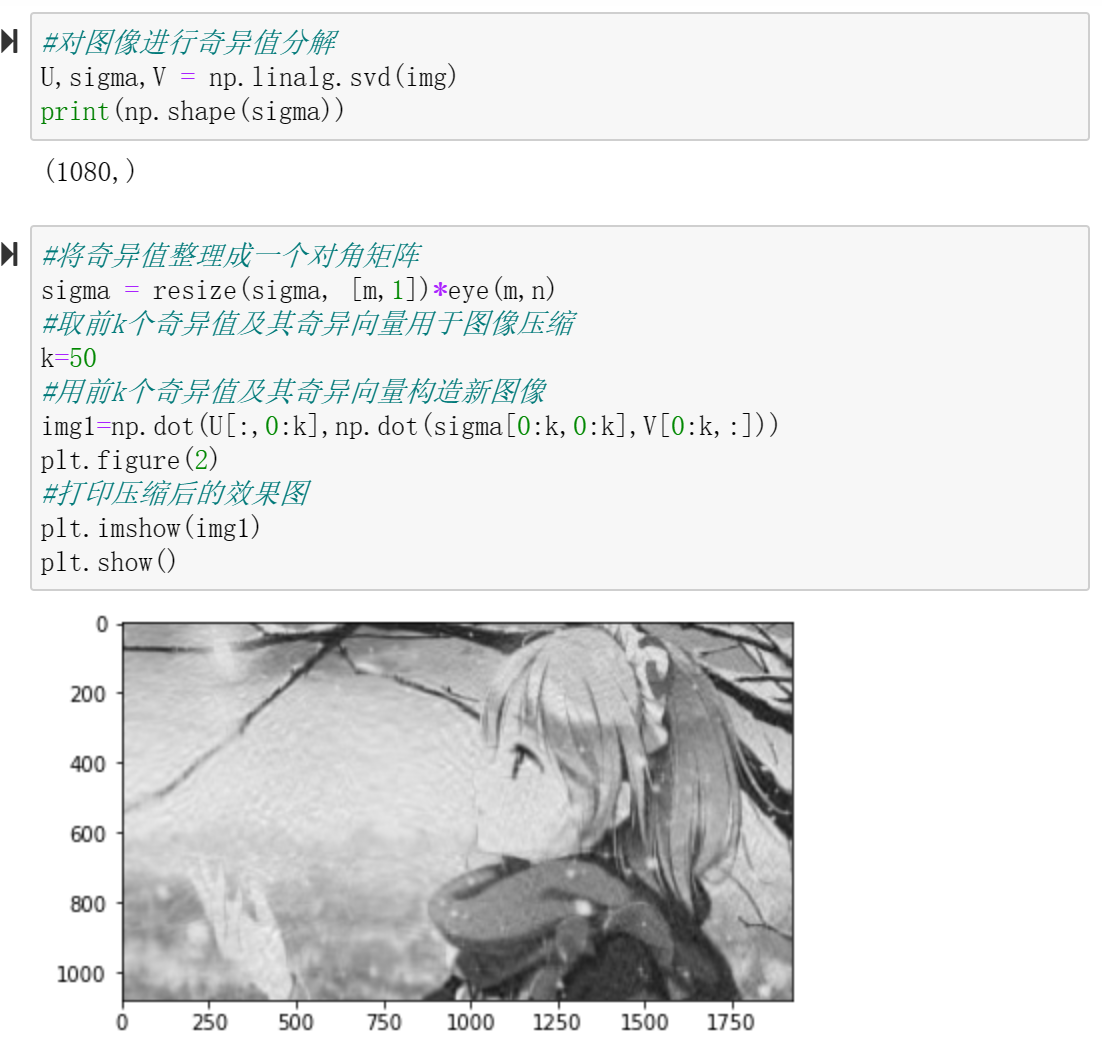
10、scipy.linalg.solve() 求解线性方程组
有以下多元方程组:
10x_1 + 2x_2 + 5x_3 = 10
4x_1 + 4x_2 + 2x_3 = 8
2x_1 + 2x_2 + 2x_3 = 5
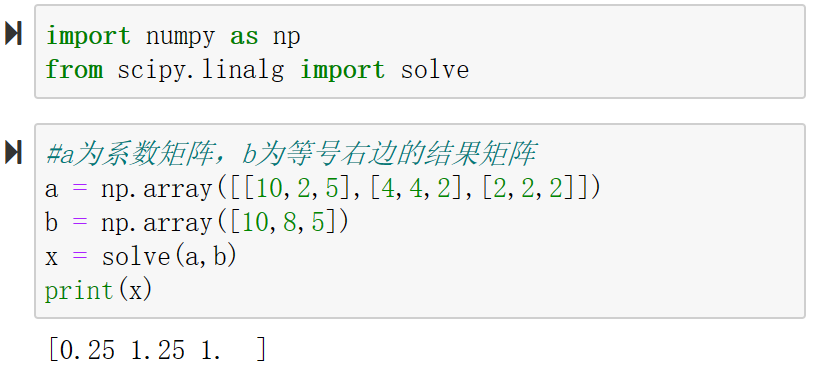
概率论
主要使用numpy库以及scipy库。

1、mean() 函数求均值

2、var() 函数求方差

3、std( ) 函数求标准差

4、cov() 函数求协方差

5、corrcoef() 函数求相关系数

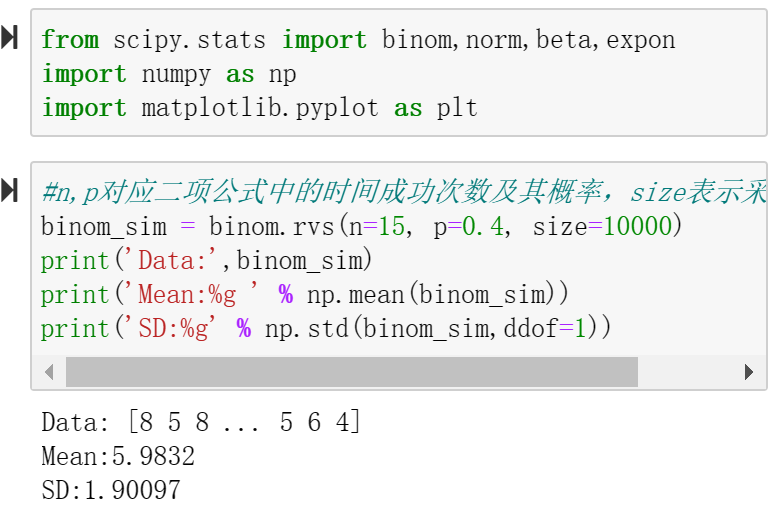
6、rvs(n,p,size) 实现二项分布,n、p对应二项公式中的时间成功次数及其概率,size表示采样的次数。
7、poisson(lambda, size) 实现泊松分布
8、norm.pdf(x,miu,sigma) 实现正态分布
9、在图像中加入噪声形成新的图像数据
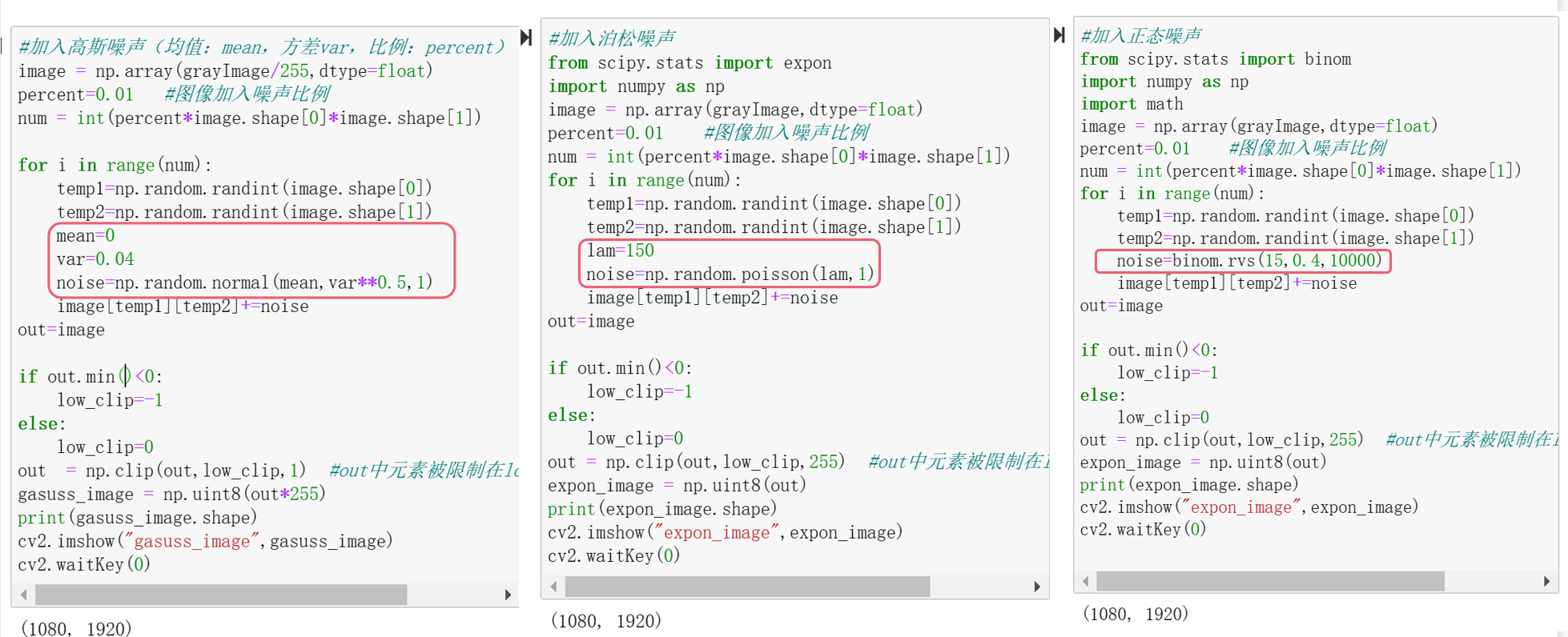

最优化
1、leastsq(func,x0,args) 实现最小二乘法
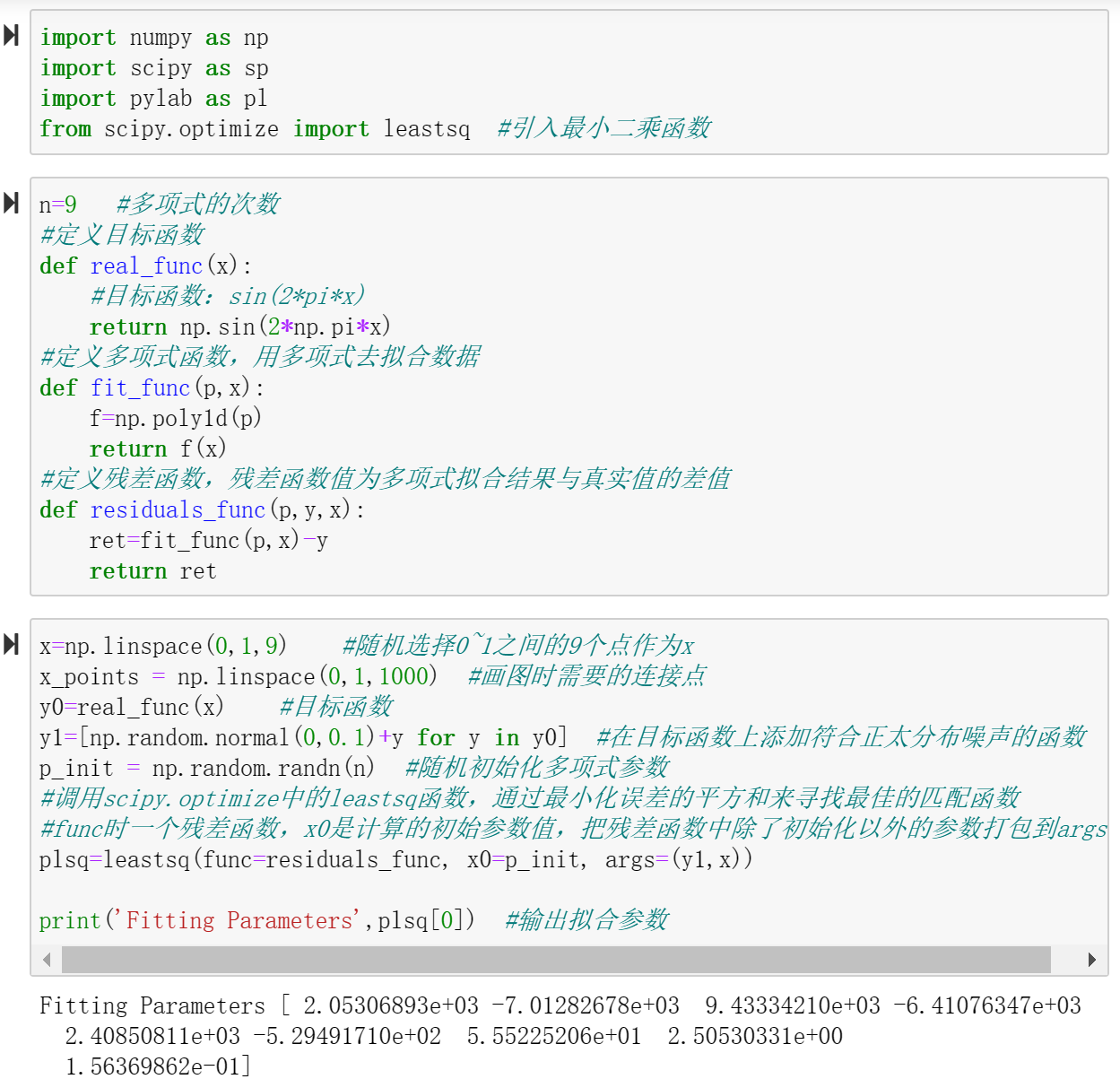
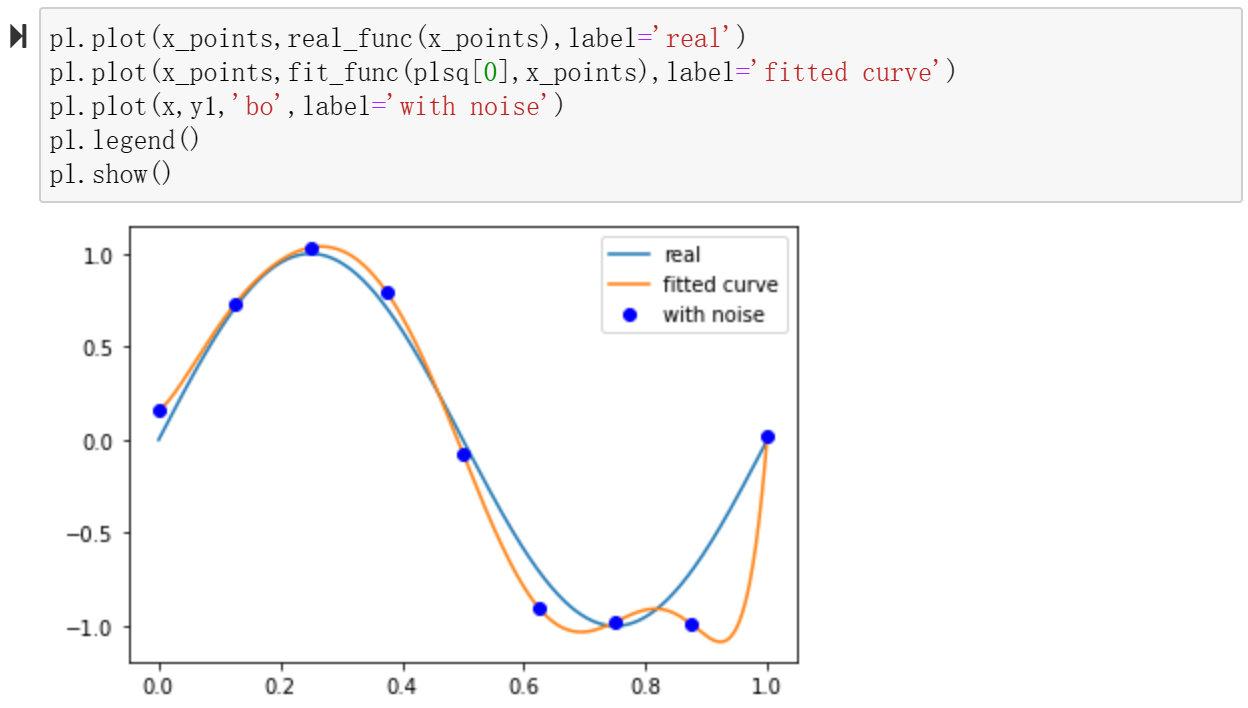
2、梯度下降

Python编程基础
1、一对三引号不仅可以做多行注释,还可以将多行的字符串赋值给一个变量
2、只有一个元素的元组,记得在元素后再加一个逗号
3、设x是一个字典,用x.get( 键名 )获取字典x中键对应的值比较方便,获取的值不存在也不会报错。
4、浅拷贝无法拷贝嵌套结构的数据,需要导入copy库中的deepcopy()函数进行拷贝。
例:a=[1,2,3,[4,5]]中的[4,5]是嵌套在列表a中的列表,属于引用类型,使用浅拷贝后拷贝列表a,改变列表a[4,5]中的值,新拷贝出的列表b中的[4,5]也会改变;或者说,改变列表a的副本列表b中的[4,5],列表a中的[4,5]也会改变。但使用了深拷贝拷贝列表a,其余副本中的嵌套结构[4,5]就成了两个,改变b的[4,5],a的[4,5]不会变。
5、break只会跳出它所在的那一层循环。
6、使用lambda来创建匿名函数,相比于普通函数而言,匿名函数知识一个表达式。
例: a = lambda x, y: x+y #x,y是传入的参数,x+y是函数中的一个表达式
a(1,2) #传入1,2作为参数调用函数a
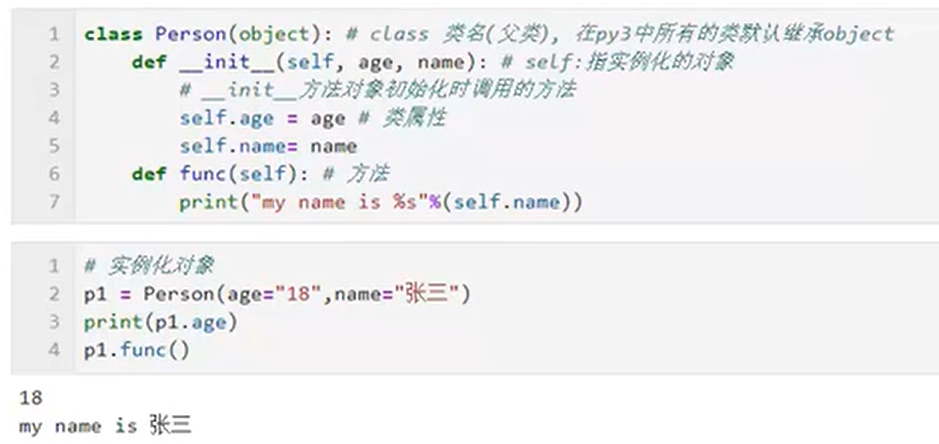
7、定义一个类对象,并调用其中的属性和方法。
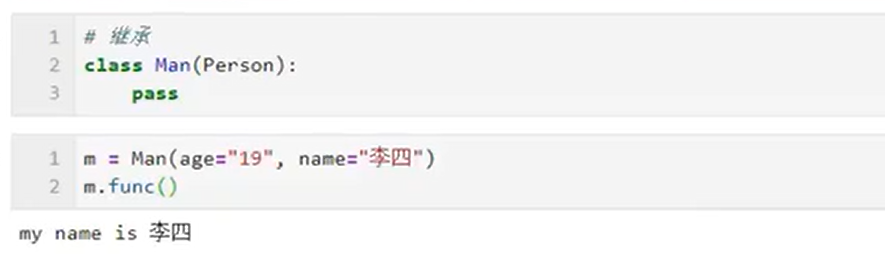
8、局部私有化和完全私有化
如果类中的某些属性不想被外界访问或继承,可以对其私有化。
–在属性或方法前加上一个下划线。可以防止模块的属性用“from mymodule import”来加载,它只可以在本模块中使用
–在方法或属性前加双下划线,可以实现完全私有化。
例,Person类中的age前加了单下划线,实现了局部私有化。
9、os库和time库的使用

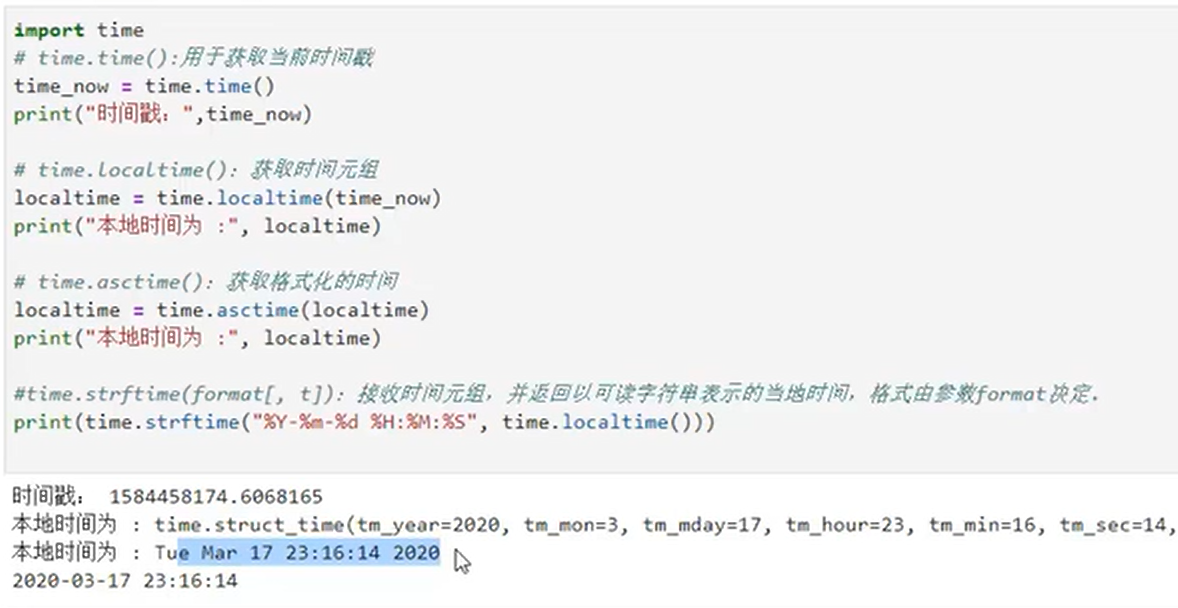
基于MindSpore的深度学习和机器学习
机器学习
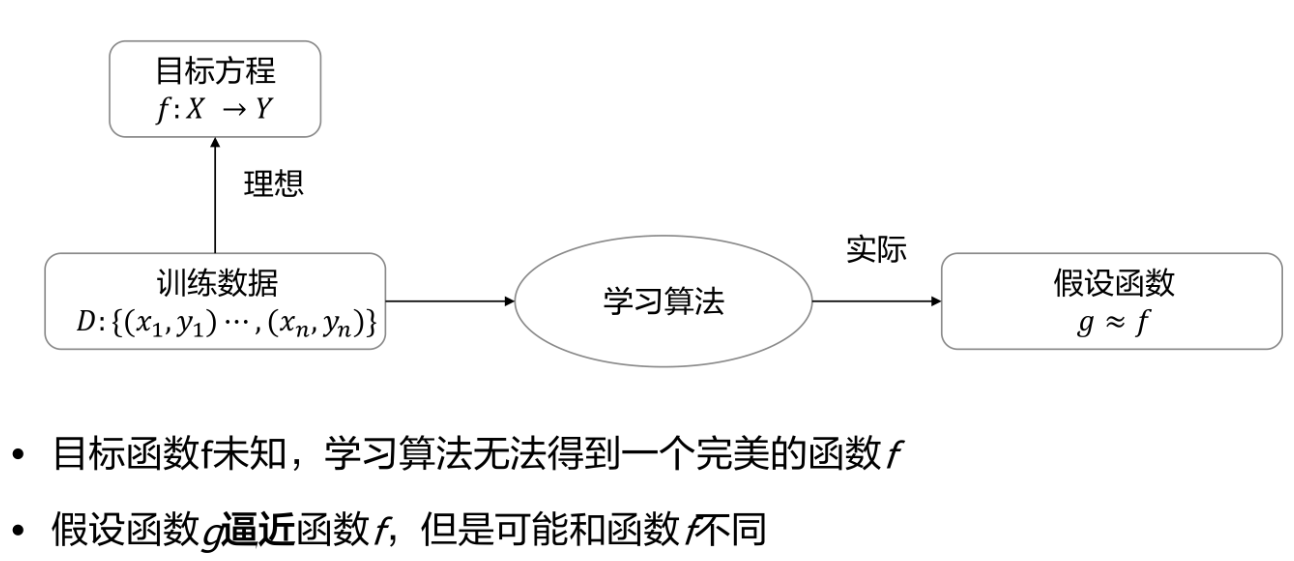
1、机器学习是研究“学习算法”的一门学问。所谓“学习”,即对于某类任务T和性能度量P,一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么这个计算机程序在从经验E中学习,是一个自我完善的过程。
2、机器学习主要解决三类问题:分类,回归,聚类。
3、机器学习分为四类:监督学习,无监督学习,半监督学习,强化学习
机器学习算法的整体流程
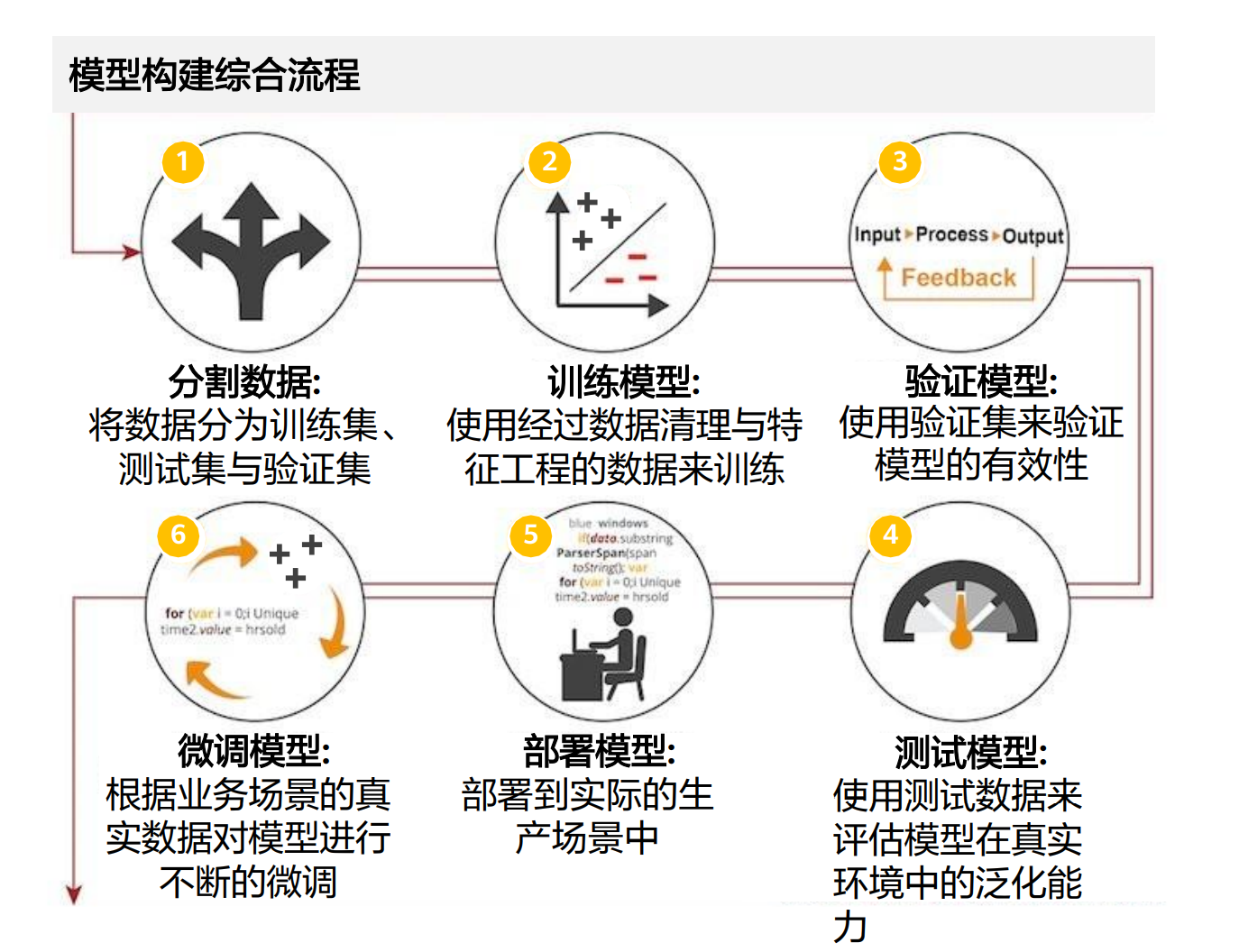
1、训练集和测试集不能有交集
2、欠拟合——学习特征不充分,过拟合——学习特征过于充分
3、误差是过拟合的原因
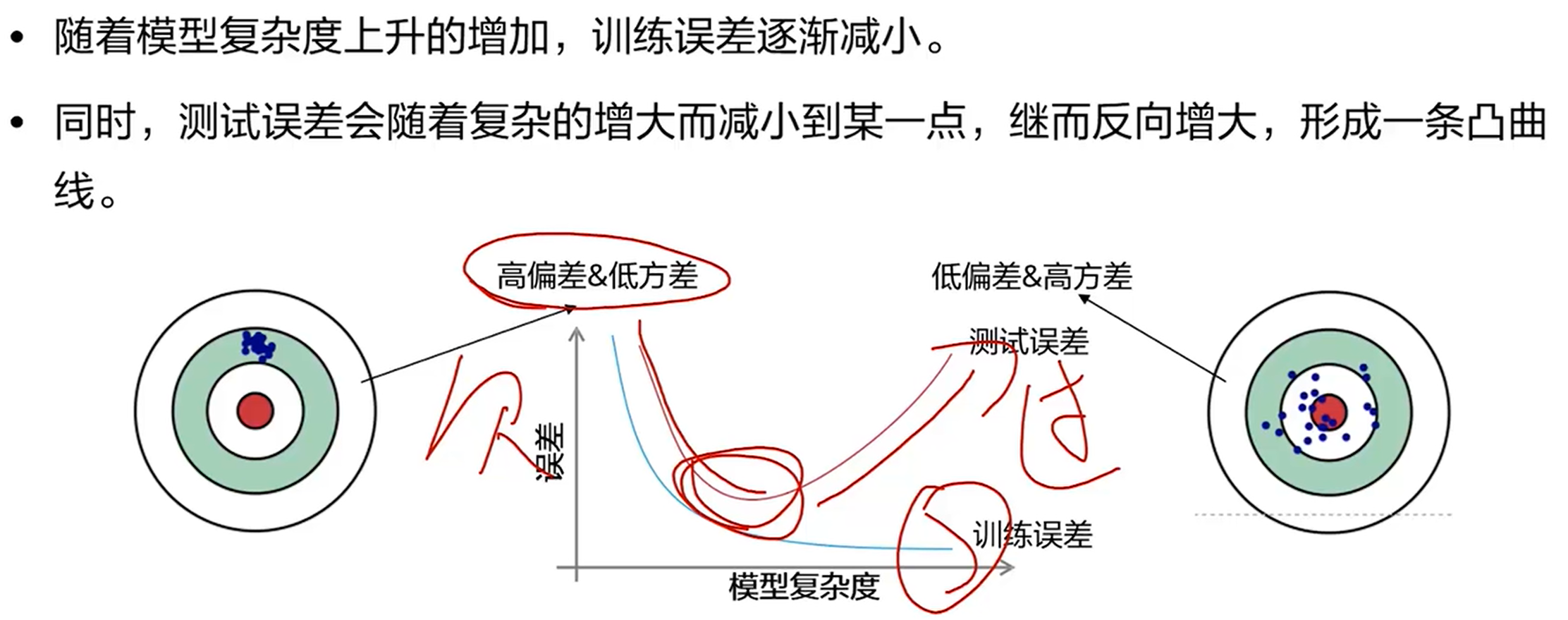
最终预测的总误差=偏差²+方差+不可消解的误差
方差:
·模型的预测结果在均值附近的偏移幅度
·来源于模型在训练集上对小波动的敏感性的误差
偏差:
·模型的预期(或平均)预测值与我们试图预测的正确值之间的差异
4、低偏差&低方差 才是好模型
5、机器学习的性能评估
回归——MAE、MSE、R²
分类——混淆矩阵


机器学习算法实例
1、引入相关依赖的包
#防止不必要的警告
import warnings
warnings.filterwarnings("ignore")
#引入数据科学基础包
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import scipy.stats as st
import seaborn as sns
##设置属性防止画图中文乱码
mpl.rcParams['font.sans-serif']=[u'SimHer']
mpl.rcParams['axes.unicode_minus']=False
#引入机器学习,预处理,模型选择,评估指标
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import r2_score
#引入本次所使用的波士顿数据集
from sklearn.datasets import load_boston
#引入算法
from sklearn.linear_model import RidgeCV,LassoCV,LinearRegression,ElasticNet
#对比SVC,是svm的回归形式
from sklearn.svm import SVR
#集成算法
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from xgboost import XGBRegressor
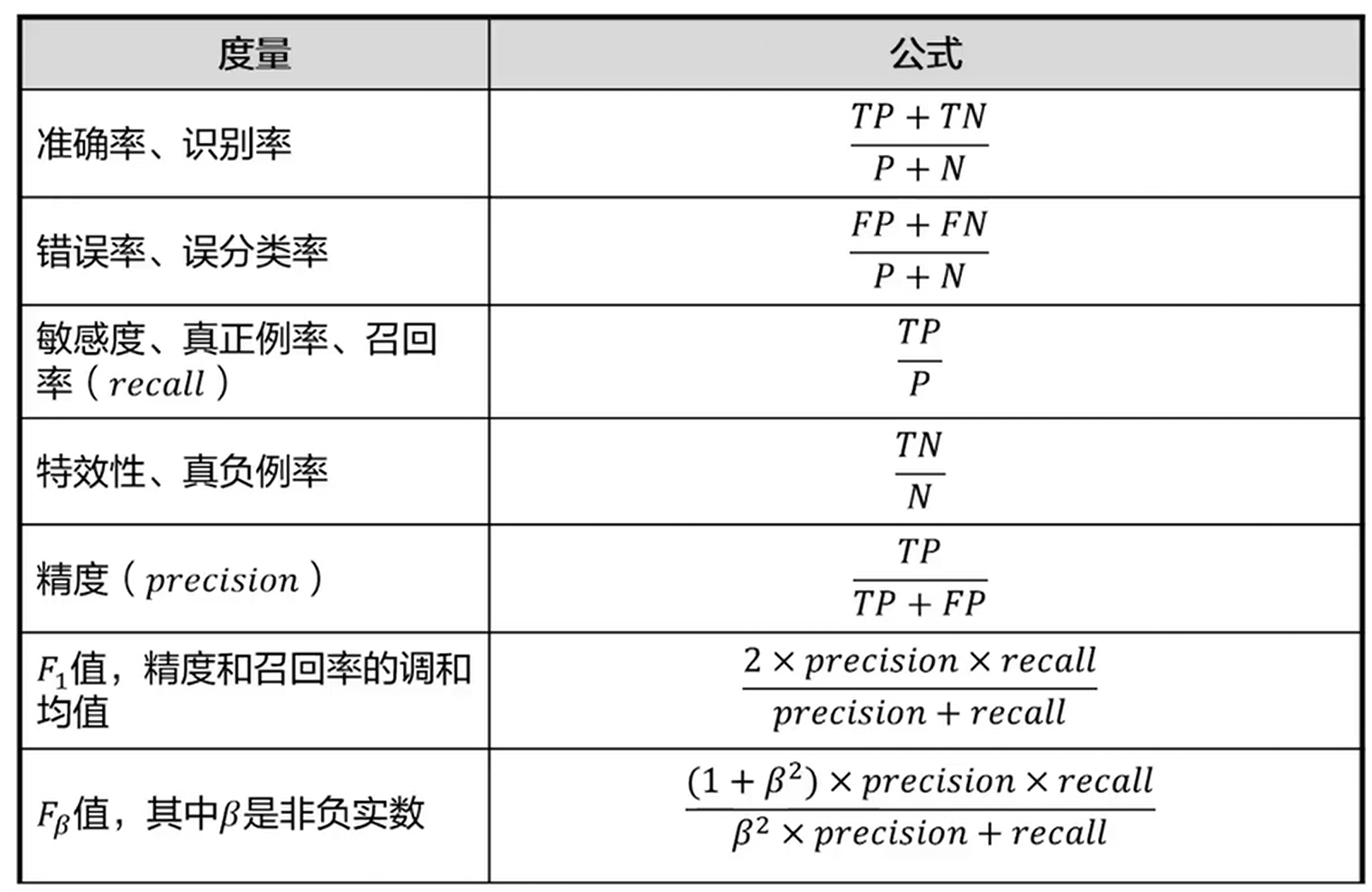
2、载入数据集,查看数据属性,可视化
#载入波士顿房价数据集
boston = load_boston()
#x是特征,y是标签
x = boston.data
y = boston.target
#查看相关属性
print('特征的列名')
print(boston.feature_names)
print("样本数据量%d,特征个数:%d" % x.shape)
print("target样本数据量%d" % y.shape[0])

#转化为dataframe形式
x = pd.DataFrame(boston.data,columns=boston.feature_names)
x.head()
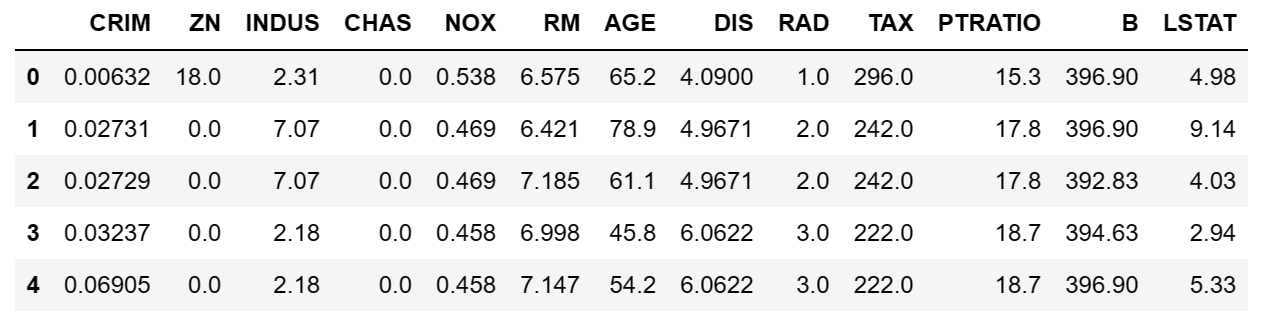
#对标签的分布进行可视化
sns.distplot(tuple(y),kde=False,fit=st.norm)
3、分割数据集,并对数据集进行预处理
#数据分割
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=28)
#标准化数据集
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)
x_train[0:100]

4、利用各类回归模型,对数据集进行建模
#模型的名字
names = ['LineRegression',
'Ridge',
'Lasso',
'Random Forrest',
'GBDT',
'Support Vector Regression',
'ElasticNet',
'XgBoost']
#定义模型
#cv在这里是交叉验证的思想
models = [LinearRegression(),
RidgeCV(alphas=(0.001,0.1,1),cv=3),
LassoCV(alphas=(0.001,0.1,1),cv=5),
RandomForestRegressor(n_estimators=10),
GradientBoostingRegressor(n_estimators=30),
SVR(),
ElasticNet(alpha=0.001,max_iter=10000),
XGBRegressor()]
#输出所有回归模型的R2评分
#定义R2评分的函数
def R2(model,x_train,x_test,y_train,y_test):
model_fitted = model.fit(x_train,y_train)
y_pred = model_fitted.predict(x_test)
score = r2_score(y_test,y_pred)
return score
#遍历所有模型进行评分
for name,model in zip(names,models):
score = R2(model,x_train,x_test,y_train,y_test)
print("{}:{:.6f},{:.4f}".format(name,score.mean(),score.std()))

5、利用网格搜索对超参数进行调节
#模型构建
'''
'kernel':核函数
'C':SVR的正则化因子
'gamma':'rbf','poly' and 'sigmoid'核函数的系数,影响模型性能
'''
parameters={
'kernel':['linear','rbf'],
'C':[0.1,0.5,0.9,1,5],
'gamma':[0.001,0.01,0.1,1]
}
#使用网格搜索,以及交叉验证
model = GridSearchCV(SVR(),param_grid=parameters,cv=3)
model.fit(x_train,y_train)

##获取最优参数
print("最优参数列表:",model.best_params_)
print("最优模型:",model.best_estimator_)
print("最优R2值:",model.best_score_)

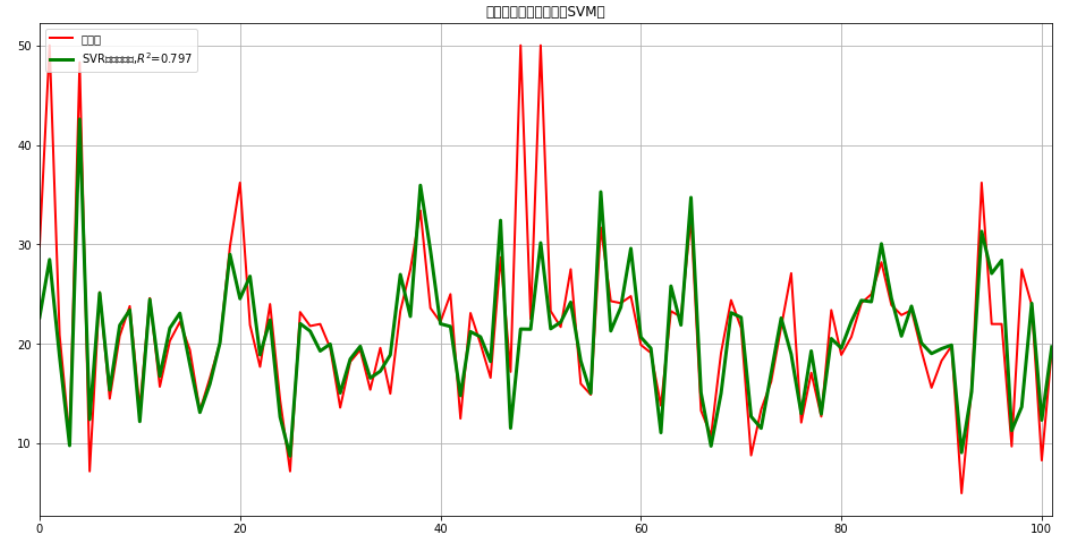
##可视化
In_x_test = range(len(x_test))
y_predict = model.predict(x_test)
#设置画布
plt.figure(figsize=(16,8),facecolor='w')
#用红实线画图
plt.plot(In_x_test,y_test,'r-',lw=2,label=u'真实值')
#用绿实线画图
plt.plot(In_x_test,y_predict,'g-',lw=3,label=u'SVR算法估计值,$R^2$=%.3f' % (model.best_score_))
#图形显示
plt.legend(loc='upper left')
plt.grid(True)
plt.title(u"波士顿房屋价格预测(SVM)")
plt.xlim(0,101)
plt.show()
深度学习
训练法则
1、梯度下降与损失函数

权重向量w是神经网络里面最重要的一个参数。

均方误差的弊端:梯度饱和现象。如sigmod函数做梯度下降的时候容易产生饱和现象,那么梯度下降算法就会很慢,导致参数更新特别慢,找到损失函数的最小值的速度也会很慢。此时可用交叉熵误差函数代替均方误差函数。
2、梯度下降算法
全局梯度算法(BGD)

随机梯度下降(SGD)
下降速度比BGD块,但难以找到最小值,存在把局部极小值当成全局极小值的可能。

小批量梯度下降算法(MBGD)
综合了BGD和SGD的优点。

3、反向传播算法
信号正向传播,误差反向传播。
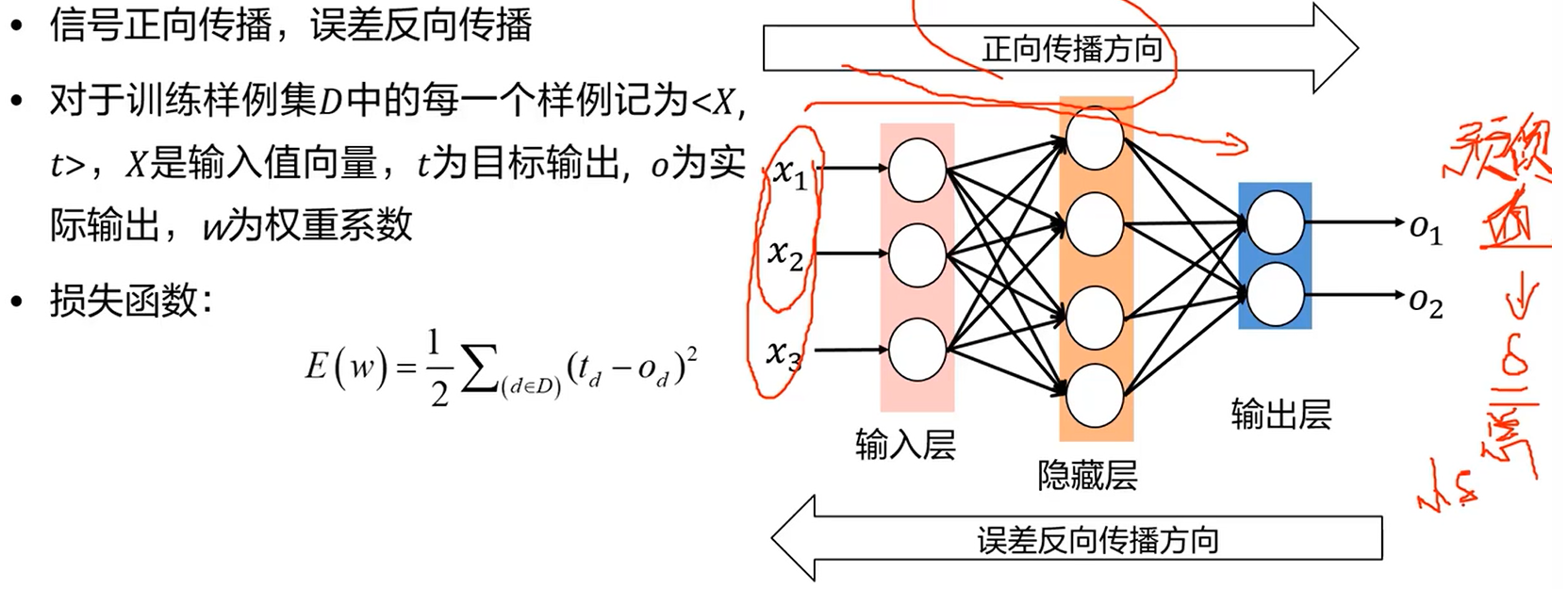



正则化
正则化是机器学习中非常重要并且有效的减少泛化误差的技术,特别是在深度学习模型中,由于其模型参数非常多容易产生过拟合。以下时常用的防止过拟合的技术:
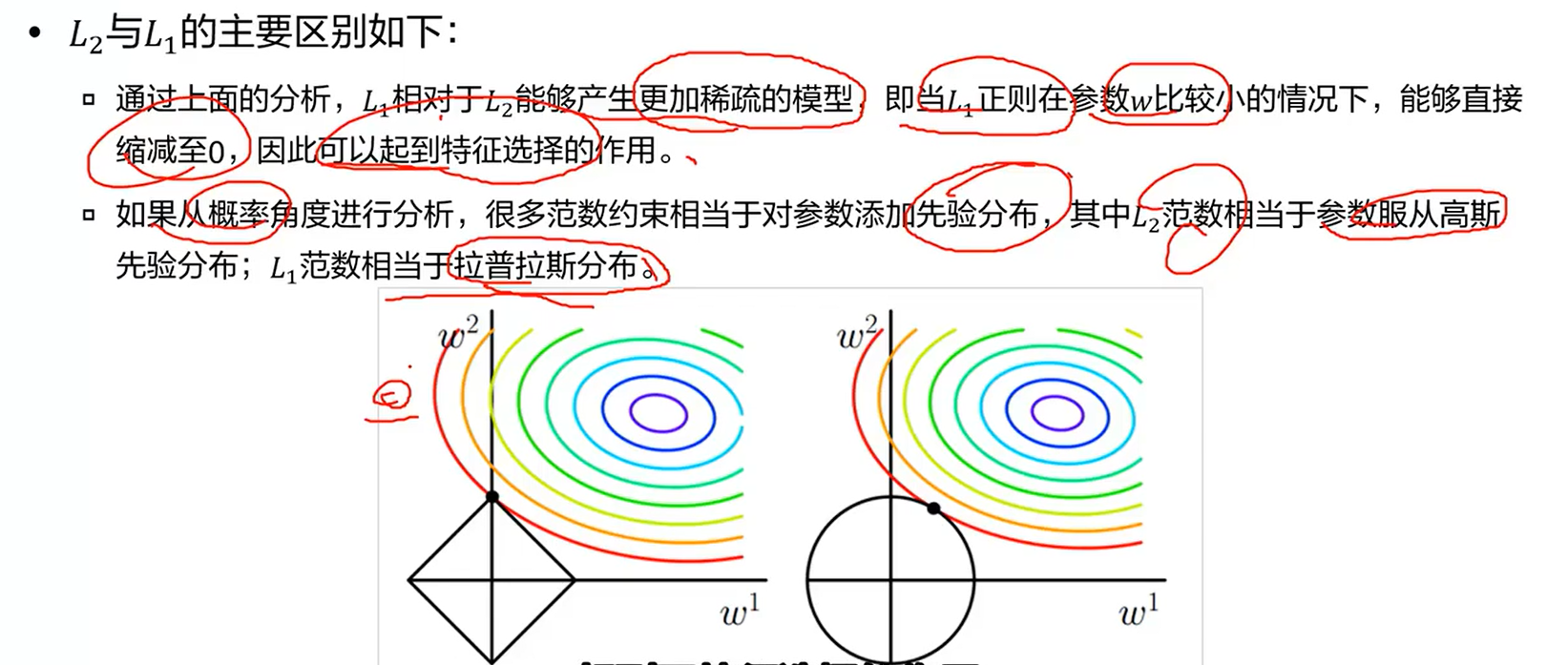
1、参数添加约束(参数惩罚项),例如L1、L2范数等。
许多正则化方法通过对目标函数J添加一个参数惩罚Ω(θ),限制模型的学习能力。
正则化后的目标函数=J(w;X,y) + α Ω(w)。
其中α∈[0,∞)是权衡范数惩罚项Ω和标准目标函数J(X;θ)相对贡献的超参数。α=0时表示没有正则化;α越大,对应正则化惩罚越大。
当Ω(w)为一个绝对值w时,为L1正则;如果通过梯度方法进行求解时,参数梯度为
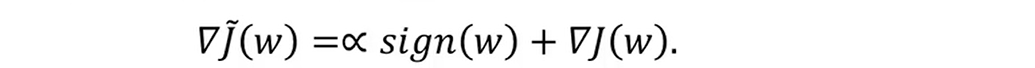
当Ω(w)为(1/2) w²时,为L2正则;通过最优化技术,例如梯度相关方法可以很快推导出,参数优化方式为:
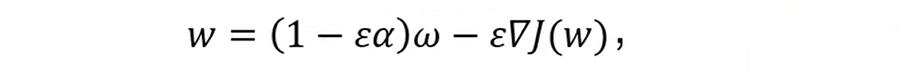
其中E为学习率,相对于正常的梯度优化公式,对参数乘上一个缩减因子。
2、训练集合扩充,例如添加噪声、数据变换。
增加训练集合时防止过拟合最有效的方法,训练集合越大过拟合概率就越小。不同领域有不同放入扩充方法:
目标识别领域——将图片进行旋转、缩放
语音识别领域——对输入数据添加随机噪声
NLP领域——进行近义词替换
噪声注入,可以对输入添加噪声,也可以对隐藏层或者输出层添加噪声。例如对于softmax可以通过Label Smoothing技术添加噪声,对于0-1添加噪声,则对应概率变成
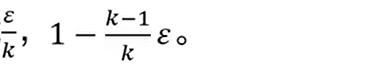
3、Dropout随机丢弃一些数据。此时,丢弃部分对应的参数不会更新。相当于Dropout是一个集成方法,将所有子网络结果进行合并,如图通过随机丢弃输入可以得到各种子网络:
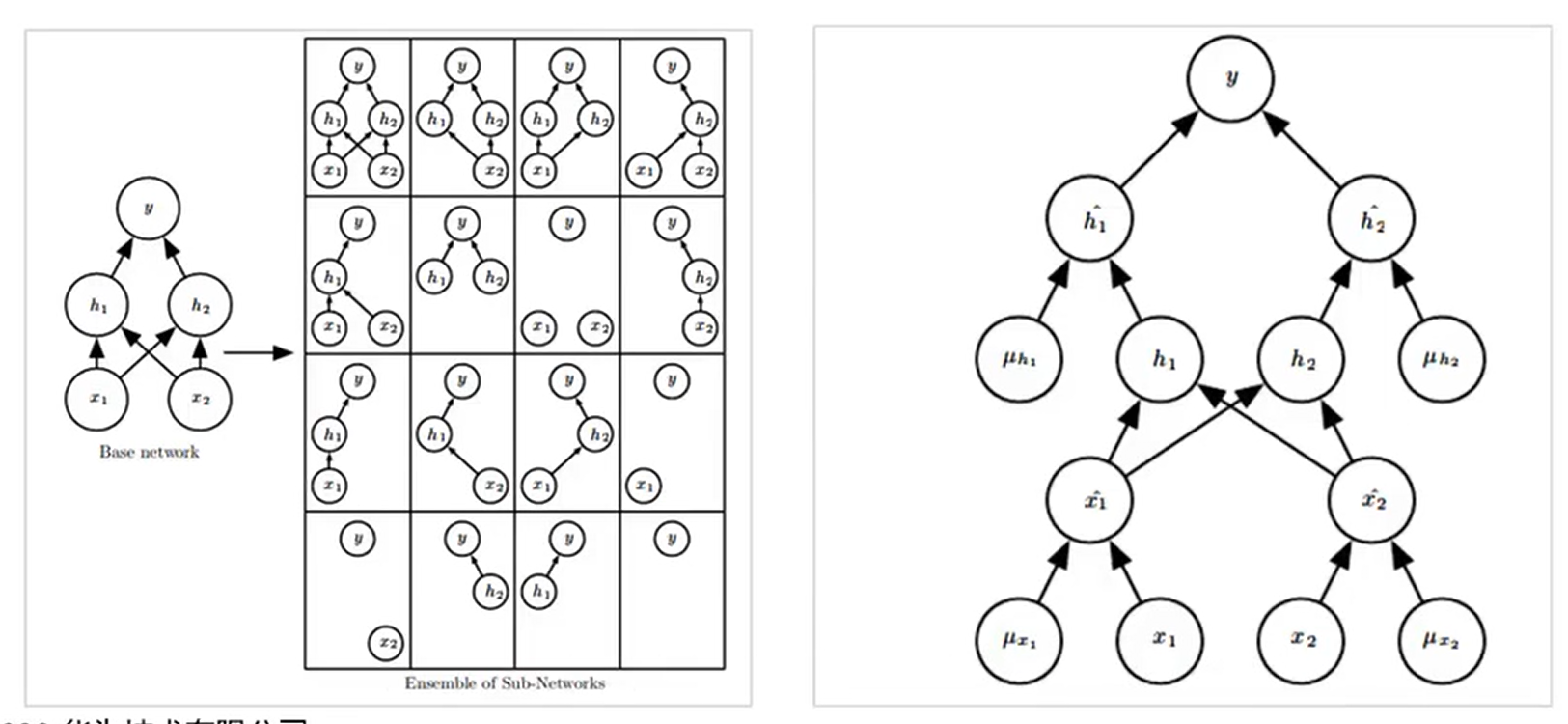
右图中是一个已经完成Dropout的一个网络图,ux1是上一时刻的输入值,和当前时刻的x1、x2以及上一时刻的ux2一直输出的结果直到y,得到最左边的一个网络。下一次做参数更新的时候,仍然是随机地去对网络进行一个删减。
Dropout防止过拟合的效果比参数惩罚和范数约束效果更好,计算复杂度也较低。但是当数据集比较小时效果不是很好。
4、提前停止训练。
当验证集数据的loss上升时,提前停止训练。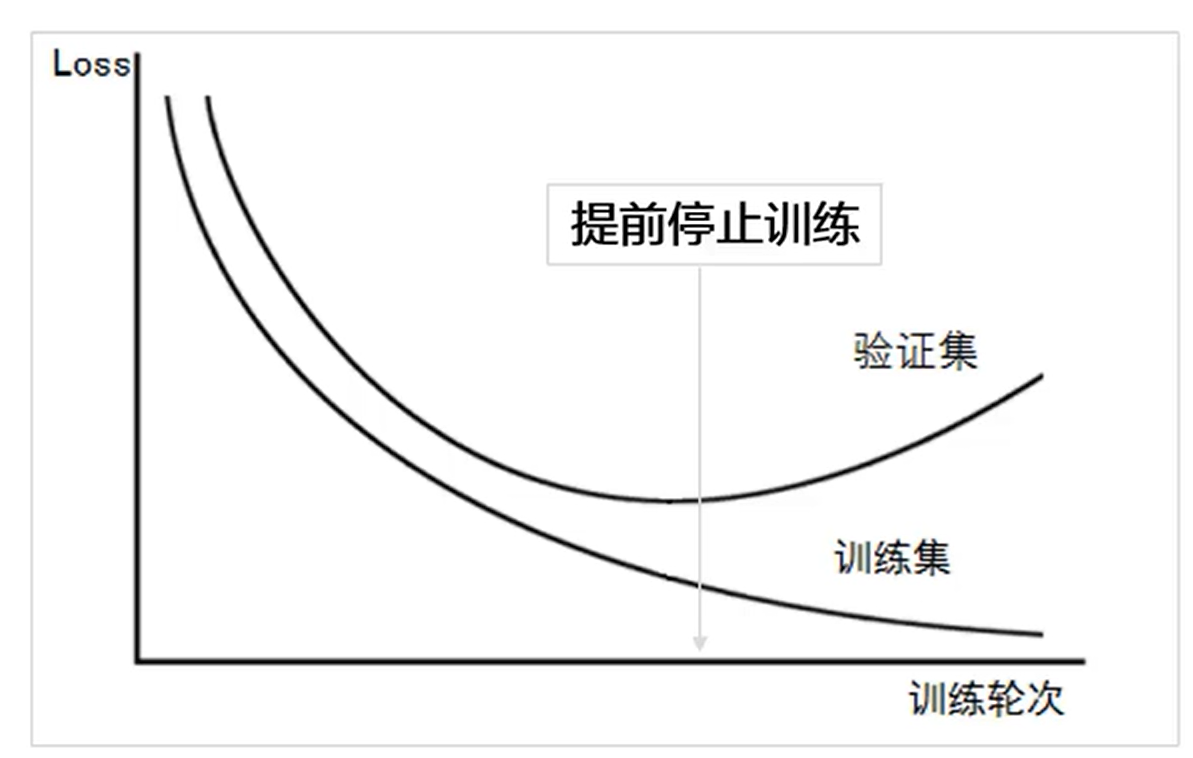
优化器
1、定义:在面向对象的语言实现中,往往把不同的梯度下降算法封装成一个对象,成为优化器。简而言之,优化器就是不同的梯度下降算法。
2、算法改进的目的:
a. 加快算法收敛速度
b. 精良避过或冲过局部极值
c. 减小手工参数的设置难度,主要是学习率(LR, Learning Rate)
3、常见的优化器:
a. 普通GD优化器
b. 动量优化器
基于反向传播算法(式子等号右边的第一个加法项),加入了一个动量项,给予一个一定的惯性或者说初速度,让它训练的时候比较快,更快的能找到最佳参数。
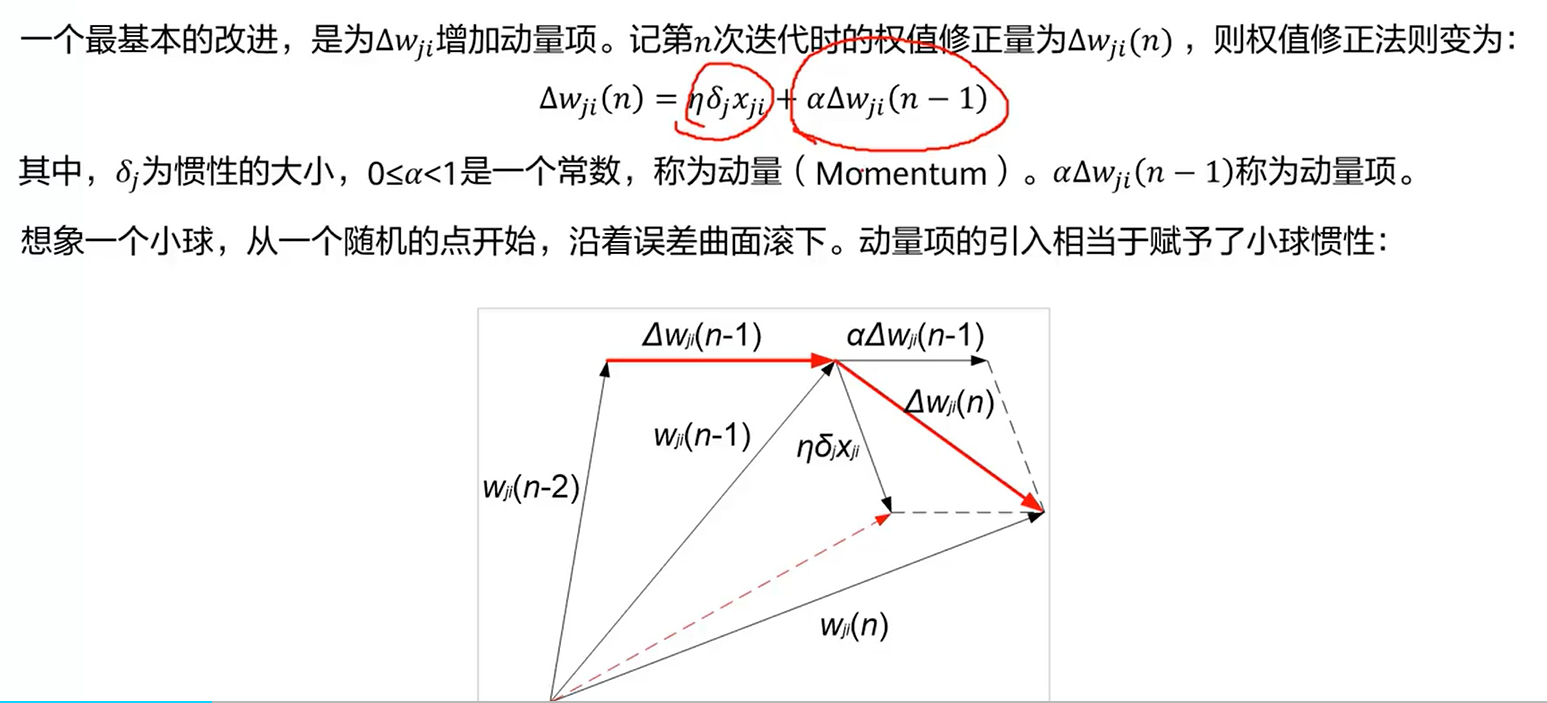
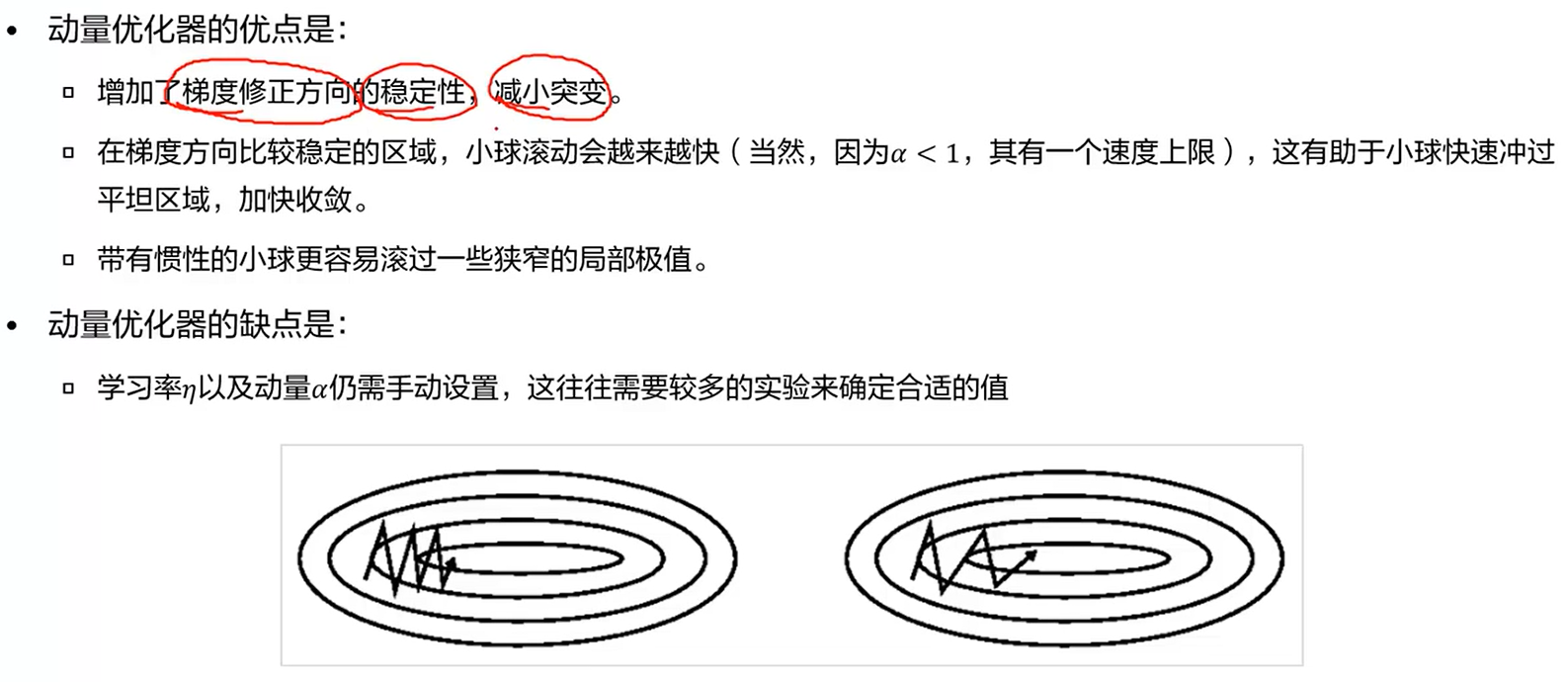
c. Nesterov
d. Adagrad


e. Adadelta
f. RMSprop

g. Adam


h. AdaMax
i. Nadam


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









