






DPCM原理
-
DPCM系统框图
-
DPCM难点分析
DPCM设计的总体目标为在给定的码率下,使失真尽量小。由DPCM的系统框图可以知道,设计过程中需要主要关注量化器的设计以及预测器的设计,但由于编码器本身的反馈机制,使得量化器和预测器的输出互为对方的输入,难以进一步分析设计,也成为DPCM算法设计的一大难点。
-
量化器与预测器的分离
当量化器采用高码率的均匀量化时,量化误差小,而样本的重建值与样本的真值之间的差值小。因此,在高码率均匀量化的前提下,可以将上一个样本的真值作为当前样本的预测值,此时预测器的输入不再依赖于量化器的输出,量化器的输入也不再依赖于预测器的输出,从而实现量化器与预测器的分离。
分离量化器与预测器之后,只需要将其设计为各自最优状态即可实现DPCM编码系统的整体最优。
DPCM代码实现
本次实验中选择的规则如下:
量化:均匀量化
预测:左向预测,并将上一个样本的重建值作为当前样本的预测值
重建:将当前样本反量化后的预测误差与当前样本预测值之和作为当前样本的重建值
DPCM具体实现
void DPCM(unsigned char* y_buffer, unsigned char* y_Pred, unsigned char* y_Re, int N, int w, int h)
{
//预测误差
char* pred_error;
pred_error = (char*)malloc(sizeof(char) * (w * h));
//量化区间数
double Q_num = pow(2, N);
//量化间隔,此处采用均匀量化
double step = pow(2, (double)(9 - N));
//预测与量化过程;
//预测机制:采用左向预测,当前样本的预测值为上一个样本的重建值
//重构:样本的重构值等于反量化后预测误差与样本预测值之和
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
if (j == 0)
{
//第一列的预测特殊处理,以128作为预测值进行预测
pred_error[i * w + j] = (char)(y_buffer[i * w + j] - 128); //需要做类型转换以免溢出
y_Pred[i * w + j] = (unsigned char)((pred_error[i * w + j] + 255) / step);
if (y_Pred[i * w + j] > Q_num - 1)
y_Pred[i * w + j] = (unsigned char)(Q_num - 1);
else if (y_Pred[i * w + j] < 0)
y_Pred[i * w + j] = 0;
y_Re[i * w + j] = (y_Pred[i * w + j] * step - 255) +128;
}
else
{
//非第一列
pred_error[i * w + j] = (char)(y_buffer[i * w + j] - y_Re[i * w + j - 1]);
y_Pred[i * w + j] = (unsigned char)((pred_error[i * w + j] + 255) / step);
if (y_Pred[i * w + j] > Q_num - 1)
y_Pred[i * w + j] = (unsigned char)(Q_num - 1);
else if (y_Pred[i * w + j] < 0)
y_Pred[i * w + j] = 0;
y_Re[i * w + j] = (y_Pred[i * w + j] * step - 255) + y_Re[i * w + j - 1];
if (y_Re[i * w + j] > 255)
y_Re[i * w + j] = 255;
else if (y_Re[i * w + j] < 0)
y_Re[i * w + j] = 0;
}
}
}
}main
int main(int argc, char* argv[])
{
int w = 256; //图像宽
int h = 256; //图像高
int N = 8; //量化比特数
//文件读入
FILE* FileOpen = fopen("文件路径", "rb");
if (FileOpen == NULL) {
printf("open file fail!");
}
//打开预测输出文件
FILE* PredictedFile = fopen("文件路径", "wb");
if (PredictedFile == NULL)
{
printf("open PredictedFile fail!");
}
//打开重建输出文件
FILE* RebuildFile = fopen("文件路径", "wb");
if (RebuildFile == NULL)
{
printf("open RebuildFile fail!");
}
//建立缓冲区
unsigned char* y_buffer, * u_buffer, * v_buffer, * y_Pred, * y_Re;
y_buffer = (unsigned char*)malloc(sizeof(char) * (w * h));
y_Pred = (unsigned char*)malloc(sizeof(char) * (w * h));
y_Re = (unsigned char*)malloc(sizeof(char) * (w * h));
u_buffer = (unsigned char*)malloc(sizeof(char) * (w * h) / 4);
v_buffer = (unsigned char*)malloc(sizeof(char) * (w * h) / 4);
//读取yuv数据到缓冲区中
fread(y_buffer, 1, w * h, FileOpen);
fread(u_buffer, 1, w * h / 4, FileOpen);
fread(v_buffer, 1, w * h / 4, FileOpen);
//DPCM
DPCM(y_buffer, y_Pred, y_Re, N, w, h);
//计算PSNR
int max = 255;
double mse = 0;
for (int i = 0; i < h; i++)
for (int j = 0; j < w; j++)
{
mse += (y_buffer[i * w + j] - y_Re[i * w + j]) * (y_buffer[i * w + j] - y_Re[i * w + j]);
}
mse = (double)mse / (double)(w * h);
double psnr = 10 * log10((double)(max * max) / mse);
printf("PSNR = %f\n", psnr);
//写入预测误差图像
fwrite(y_Pred, 1, w * h, PredictedFile);
fwrite(u_buffer, 1, w * h / 4, PredictedFile);
fwrite(v_buffer, 1, w * h / 4, PredictedFile);
//写入重建图像
fwrite(y_Re, 1, w * h, RebuildFile);
fwrite(u_buffer, 1, w * h / 4, RebuildFile);
fwrite(v_buffer, 1, w * h / 4, RebuildFile);
fclose(FileOpen);
fclose(PredictedFile);
fclose(RebuildFile);
free(y_buffer);
free(u_buffer);
free(v_buffer);
free(y_Pred);
free(y_Re);
return 0;
}实验结果
| 量化比特数 | 原图像 | 预测误差图像 | 重建图像 | PSNR(dB) |
|---|---|---|---|---|
| 8bit |  | 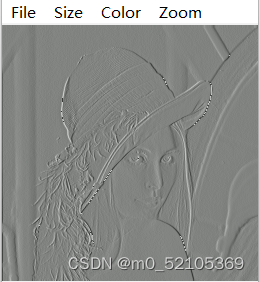 |  | 51.133820 |
| 4bit |  |  |  | 14.81887 |
| 2bit |  |  |  | 7.649990 |
熵编码 vs DPCM+熵编码
计算概率分布并写入文件
void Frequence(FILE* file, unsigned char* buffer, int w, int h) {
double fre[256] = { 0 };
for (int i = 0; i < 256; i++)
{
for (int j = 0; j < w * h; j++)
{
if (buffer[j] == i)
fre[i]++;
}
fre[i] = fre[i] / (w * h);
fprintf(file, "%lf\n", fre[i]);
}
}
FILE* y_Freq = fopen("文件路径", "wb");
if (y_Freq == NULL) {
printf("file open fail!\n");
}
Frequence(y_Freq, y_buffer, w, h);
FILE* y_Pre_Freq = fopen("文件路径", "wb");
if (y_Pre_Freq == NULL) {
printf("file open fail!\n");
}
Frequence(y_Pre_Freq, y_Pred, w, h);使用Visual Studio对huffman.bat进行编辑
huff_run.exe -i Lena256B.yuv -o lena.huff -c -t lena.txt
huff_run.exe -i PredictedFile.yuv -o PredictedFile.huff -c -t PredictedFile.txt结果对比
| 原始图像 | 8bit量化后的预测误差图像 | |
|---|---|---|
| 编码前文件大小 | 96KB | 96KB |
| 编码后文件大小 | 69KB | 45KB |
| 压缩比 | 139.13% | 213.33% |
| 重建图像PSNR | ~ | 51.133820 |
| 分布概率图 | 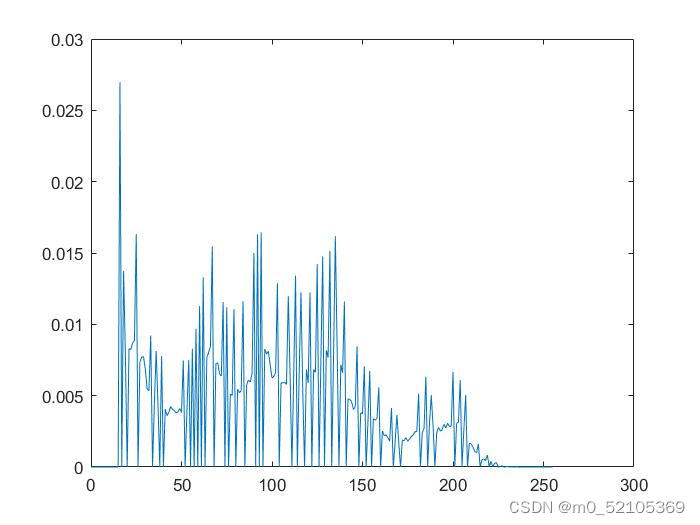 | 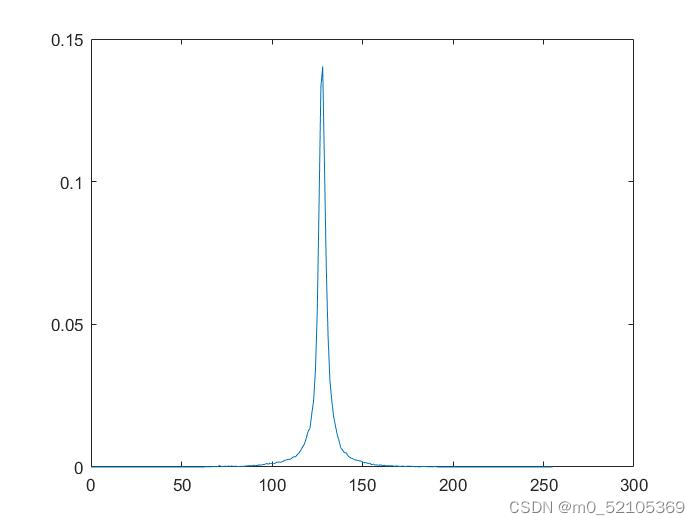 |
可以看到,与直接对未经处理的图像进行熵编码相比,对8bit量化后的预测误差图像进行熵编码的压缩比更大,可以得出结论,从压缩数据角度而言,DPCM+熵编码的系统更优。
在选用8bit量化时,重建图像的PSNR在50以上,就人眼观察而言与原图相差并不大,在选用足够比特的量化情况下,DPCM+熵编码可以实现对于人眼而言“无失真”的,压缩比更高的数据压缩。















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









