







遗传算法详解
前记
遗传算法真的很神奇,写着写着,忽然从中品出点哲学意味来。
注:本文摘自我的 博客园。
什么是遗传算法
就不从百度上往下搬了。
遗传算法,又称为 Genetic algorithm(GA) \text{Genetic algorithm(GA)} Genetic algorithm(GA)。其主要思想就是模拟生物的遗传与变异。它的用途非常广泛,可以用于加速某些求最大或者最小值的算法。
特别提醒,遗传算法是一个随机算法,会有一定的错误概率。
遗传算法前置知识
首先先来补充一些生物知识:
每个生物都有许许多多的染色体,这些染色体呈棒状。每个染色体都由双螺旋状的 DNA \text{DNA} DNA 构成。每条 D N A DNA DNA 上都有许多基因。放个图来理解一下。
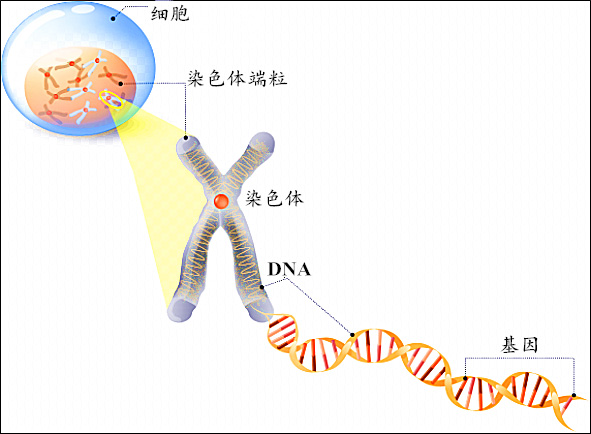
大概不需要过多解释,中学生物都学过。将 个体,染色体,基因 范围由大到小排序为 :
个体(Individual) > 染色体(chromosome) > 基因(gene)
遗传算法模拟了自然选择的过程。那些适应环境的个体能够存活下来并且繁殖后代。那些不适应环境的个体将被淘汰。换言之,如果我们对每个个体都有一个适应度评分(用来评价其是否适应环境),那么对于适应度高的物体来说,将具有更高的繁殖和生存的机会。
另外,为了保持种族的稳定性,我们会将父代的基因传递下去。
遗传算法基础
遗传算法基于一些不证自明的理论依据:
- 种群中的个体争夺资源和交配。
- 那些成功的(最适合的)个体交配以创造比其他人更多的后代。
- 来自 “最适” 父母的基因在整个世代中传播,即有时父母创造的后代比父母任何一方都好。
- 因此,每一代人都更适合他们的环境。
遗传算法基础概念
拿古代人类来举例子:
- 个体( Individual \text{Individual} Individual):每个生物。即每个古人类个体。
- 种群( population \text{population} population):一个系统里所有个体的总称。比如一个部落。
- 种群个体数( POPULATION \text{POPULATION} POPULATION):一个系统里个体的数量。比如一个部落里的人数。
- 染色体( chromosom \text{chromosom} chromosom):每个个体均携带,用来承载基因。比如一条人类染色体。
- 基因( Gene \text{Gene} Gene):用来控制生物的性状(表现)。
- 适应度( fitness \text{fitness} fitness):对某个生物是否适应环境的定量评分。比如对某个古人类是否强壮进行 [ 1 , 100 ] [1, 100] [1,100] 的评分。
- 迭代次数( TIMES \text{TIMES} TIMES):该生物种群繁衍的次数。比如古人类繁殖了 100 100 100 万年。
一定要记住这些英文名字!!!,后面会经常用到
配图表示:
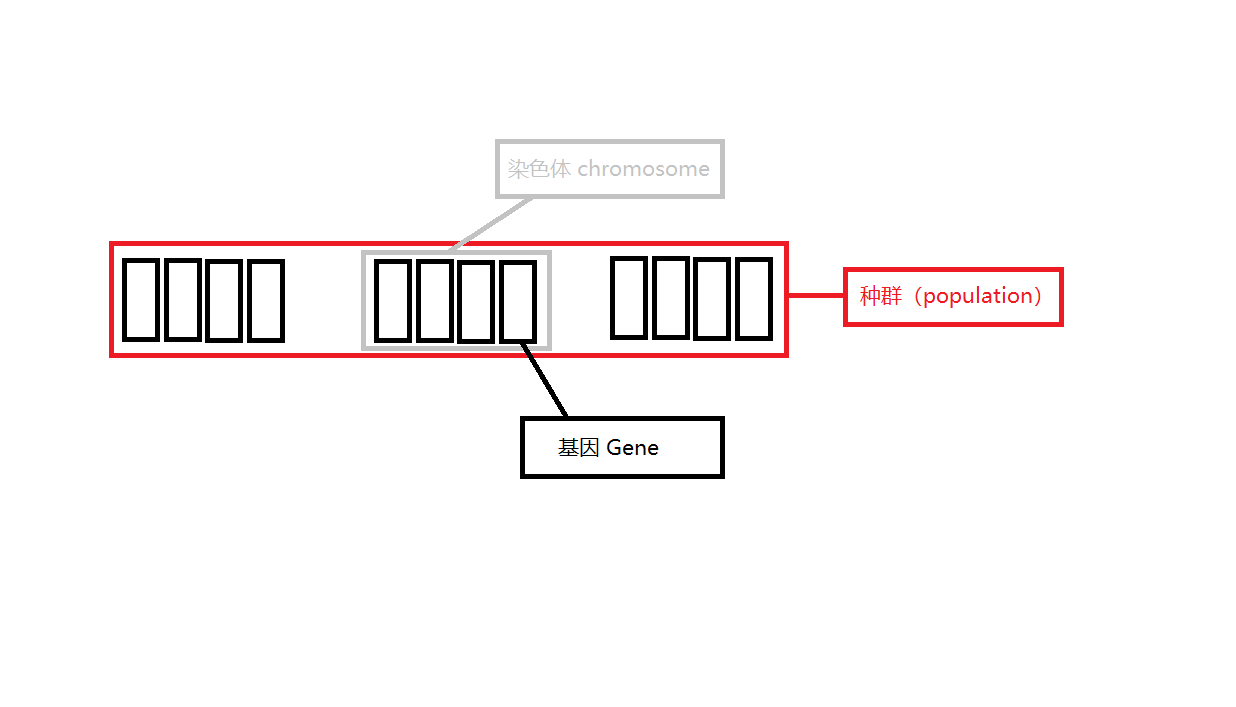
图中,种群、染色体、基因都已经标注上了。种群个体数量为 3 3 3,每个个体都是染色体 + + + 对应的适应度。
在算法中,我们对每个个体计算其染色体的适应度( fitness \text{fitness} fitness)来决定它是否优秀。
小试牛刀
尝试构建一个名字叫做 Individual \text{Individual} Individual 的结构体,里面存储一个个体的信息。可以自己尝试先写一下。
参考答案:
struct Individual {
string chromosome; // 染色体
int fitness; // 个体的适应度
Individual(string chromosome); // 初始化
int calc_fitness(); // 计算适应度
Individual mate() // 即交叉算子(CrossOver)。后面会讲到。
Individual mutation() // 即变异算子(Mutation)。后面会讲到。
};
Individual(string chromosome) {
this -> chromosome = chromosome;
this -> fitness = calc_fitness();
}
遗传算法算子
- 交叉算子( CrossOver \text{CrossOver} CrossOver)
也有将该算子称为 m a t e mate mate 的。我更倾向于第二种叫法,因为第二种字数更少。
交叉算子就是模拟父母双方交配过程。想一想人类交配时,每个基因会随机的来自父亲或者母亲。我们可以模拟这个过程。假设我们的染色体用 string \text{string} string 存储,可以实现下面的交配代码:
// par 代表母亲,chromosome 代表父亲(即本身)的染色体,par.chromosome 则代表母亲染色体。
Individual Individual::mate(Individual par) {
// 交叉
string child = ""; // 子代染色体
int len = chromosome.size();
for (int i = 0; i < len; i ++ ) {
double p = random(0, 100) / 100; // 计算来自父母的概率
if (p <= 0.5) child += chromosome[i]; // 一半概率来自父亲
else child += par.chromosome[i]; // 另一半来自母亲
}
return Individual(child);
}
当然,你也可以思考一些其他的交叉思路,比如随机抽取某些段进行交换。如下图所示:

(以上图片来自Genetic Algorithms)
这种算法通常在二进制条件下更加实用。
- 变异算子( mutation \text{mutation} mutation)
即低概率地随机地改变某个基因。这样可以有效避免程序陷入局部最优或者过慢收敛。例如:

一般来说,我们可以设计一个变异概率。变异率大概在 0.01 ∼ 0.05 0.01 \sim 0.05 0.01∼0.05 之间最优。变异率太高会导致收敛过慢,变异率太低则会导致陷入局部最优。
遗传算法策略
- 精英保留策略
还是拿古人类举例。假设我们是上帝,我们想要古人类实现长久发展,最好的办法就是尽可能的将那些头脑敏捷,肢体强壮的个体保留下来,淘汰那些老弱病残的个体。
在程序中,我们将个体按照适应度排序,把适应度最好前 k % k \% k% 的保留下来,剩下的随机交配。通常, k k k 可以设成 1 ∼ 20 1 \sim 20 1∼20。设置太高则会局部最优,太低则会收敛过慢。
- 概率保留策略
学名好像是 Stoffa改进方法,这不重要。总之,就是为了避免父母生出傻孩子浪费时间,把傻孩子(适应度低的后代)直接抛弃。
假设我们要求收敛到最低适应度,后代适应度为 y y y,父代适应度为 x x x,有 Δ = y −
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









