







作者:一元
公众号:炼丹笔记 Deep Feedback Network for Recommendation(IJCAI20)
背景
做数据挖掘相关的朋友,大多数都听说过特征工程这个艺术的词汇,却鲜有人知道标签工程这个伟大的词汇,诶,为什么很少有人知道呢?因为这个是我们自己造出来的,轻喷......但是这个词却真的非常契合本篇文章的核心思路,大家都知道标签脏或者模糊的问题,这个是所有数据里面不可避免的,那么如何解决或者缓解此类的问题呢?让标签更加置信,这个就是本文探讨的一个重点。具体细节,大家可以阅读下文慢慢品味.......
无论是显性反馈还是隐性反馈都能反映用户对商品的意见,这对于学习推荐中的用户偏好至关重要。然而,目前大多数推荐算法只关注隐式的正反馈(如点击),而忽略了其他信息丰富的用户行为。在这篇文章中,我们的目的是联合考虑显式/隐式和正/负反馈,以了解用户的无偏偏好。具体地说,我们提出了一种新的深度反馈网络(DFN)来建模点击、未点击和不喜欢行为。DFN有一个内部反馈交互组件,该组件捕获单个行为之间的细粒度交互,以及一个外部反馈交互组件,该组件使用精确但相对较少的反馈(单击/不喜欢)从丰富但非常嘈杂(unclick)的反馈中提取有用的信息。
基础概念
显示和隐式反馈
在推荐系统中,显式和隐式的反馈都是有价值的,许多工作使用特征mapping以及迁移学习的方式来构建显示和隐式反馈的关系,目前大多数算法使用多任务学习方式将显式和隐式反馈结合来联合处理ranking和rating的任务。在DFN中,我们使用高质量的但是相对稀有的显式反馈来指导学习。
负反馈
在平时,我们将缺失的或者未点击的样本作为负反馈,但是这么做会引入大量的噪音,因为未点击并不代表不喜欢,为了提取隐式反馈中的真实负信号,一些模型使用曝光变量或popularity。Zhao等人以点击和取消点击序列作为特征进行强化学习。相比之下,明确的负面反馈可以直接反映用户的负面意见,而其稀缺性限制了其在深层次模型中的使用。据我们所知,我们是第一个将点击、不点击、不喜欢的行为及其相互作用编码到深层神经推荐中,同时考虑到隐性和显性反馈中的负面信号的。
方法
三种反馈
DFN希望可以同时考虑大量的明显的和隐性的以及正负反馈来学习用户的无偏喜好,此处有三种不同的反馈:
- 隐式正反馈:隐式正反馈在数量和质量上面是最容易满足的,在大多数传统模型,我们考虑点击行为序列{C1,...,Cn}作为隐式的正反馈;
- 显式负反馈:显式反馈是高质量的,但是在现实世界中确是稀有的。此处我们在每个商品后面附加dislike按钮来收集现实的负反馈序列{d1,...,dn};
- 隐式负反馈:我们将impressed但是没有点击的行为序列作为隐式负反馈,未点击的序列是所有反馈中最多的,但是它需要和大量的噪音以及false-negative信号斗争。
整体框架
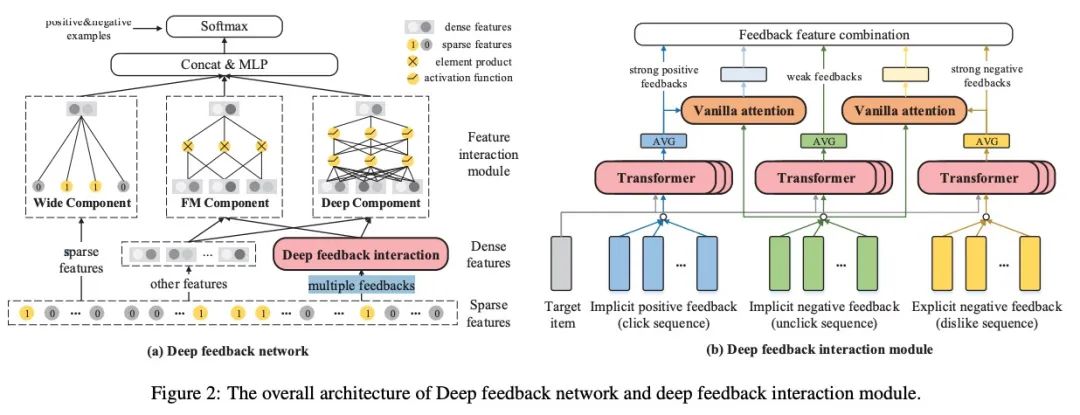
1. 深度反馈交互模块
内部反馈交互组件:该模块关注目标商品和特定类型反馈中个人行为之间的交互作用。我们在item embedding和position embedding上进行multi-head self-attention,并投射到一个联合语义空间,形成行为嵌入。以点击行为为例,将目标商品t与点击序列的行为embedding相结合,形成输入矩阵,

我们还在特定type的超参数上使用相同的Transformer来生成明显的负反馈embedding, 以及从dislike和unclick的隐式反馈embedding,内部反馈交互成份很好地捕获了目标商品和每种反馈序列中行为之间的交互。它可以为用户提供与目标商品相关的积极和消极偏好。
外部反馈交互组件: 隐式的负反馈是充分的但也是noisy的,未点击的行为看上去是负的信号,但是曝光给用户的商品是被特定策略筛选过的,所以也可能包含粗粒度方面的用户兴趣。外部反馈交互组件旨在根据点击和不喜欢行为中的强烈反馈,区分用户在不点击行为中真正喜欢和不喜欢什么。

2. 特征交互模块
我们将稀疏的特征分为m个域,{x1,x2,...,xm} ,里面也包含连续域,例如年龄等,所有的field被表示为one-hot的embedding,lookup table被用来生成所有filed的dense特征{f1,...,fn},此处我们实现了Wide,FM以及Deep的成份来做特征交叉。
2.1 Wide部分
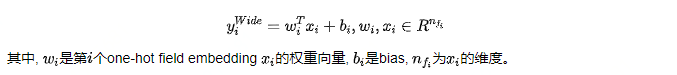
2.2 FM部分
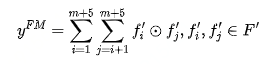
2.3 深度部分
此处,我们使用一个二层的MLP来学习高阶的特征交叉,输入是dense特征和反馈特征的拼接形式,

3. 目标优化
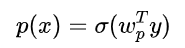
最终我们的损失函数为:
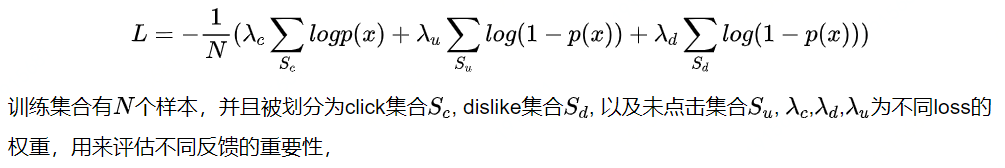
实验
1. 效果比较

- DFN在所有的baseline上的效果远超过了Baseline;
- DFN的又是主要来源于它的深度反馈交叉模块。内部反馈交互组件通过transformer成功地捕获了目标项和个体行为之间的细粒度交互。它可以从不同类型反馈中的行为层交互中提取用户偏好。第二,外部反馈交互组件使用精确但相对较少的反馈来消除丰富但嘈杂的不点击的行为。因此,DFN可以解决数量与质量的两难问题。
2. Dislike预测
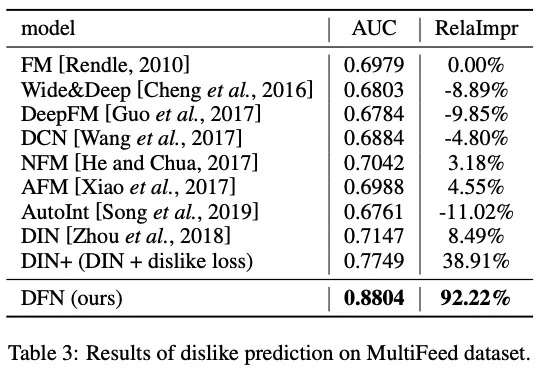
- DFN取得了最好的效果;
- 主要的改进来自两点:(1)DFN在损失函数中考虑了显式的负反馈,直接优化了不喜欢预测。(二)深度反馈交互模块引入了内部和外部反馈交互,更好地提取了信息丰富的用户无偏见的推荐偏好;
- 对于公平模型的比较,我们进一步将DFN中的不喜欢损失添加到一些强基线中(DIN+);它的结果和DFN相比还是差了很远。
3. 解耦分析
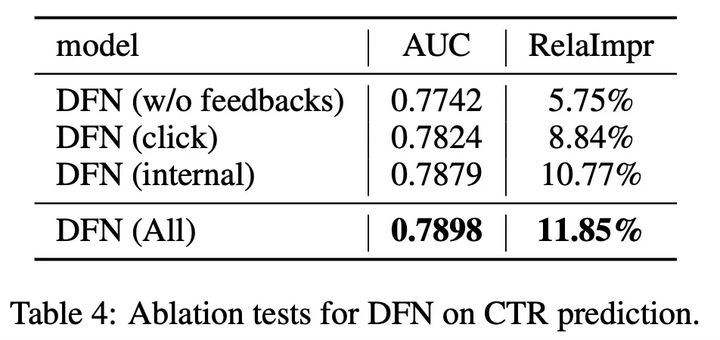
- DFN(click)效果优于DFN(w/o feedbacks),这证实了单击行为的重要性。
- 从DFN(click)到DFN(internal)的显著改进也验证了unclick和dislike行为可以提供补充信息,帮助学习用户无偏见的偏好。
- 与DFN(内部)和DFN(All)相比,外部反馈交互仍然有显著的改进,这证实了外部反馈交互组件在DFN中是有益的;
4. 在线效果
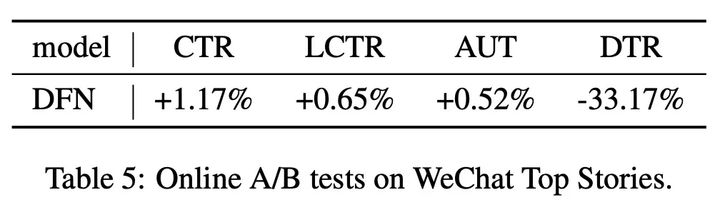
- 与DIN相比,DFN在CTR和LCTR指标上实现了一致的改进,这证实了DFN在实际CTR预测中表现良好。
- AUT的改进也意味着用户愿意花更多的时间使用我们的系统,因为DFN可以提供更好的推荐商品。
- DTR的显著改进表明,DFN能够对推荐中的用户负偏好进行建模,这对于提高用户的实际体验至关重要。
结论
在本文中,我们提出一个深度反馈网路(DFN),它同时考虑显式/隐式和正/负回馈来学习使用者的无偏喜好。DFN在多个反馈中使用内部行为和外部反馈交互。离线和在线的显著改进验证了DFN的有效性和鲁棒性。在未来,我们将使用更复杂的排名模型进行功能交互。
参考文献
- Deep Feedback Network for Recommendation:https://www.ijcai.org/Proceedings/2020/0349.pdf















 5677
5677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









