







 本文探讨了Target Encoding这一有监督特征工程方法,用于类别特征转为数值。尽管存在未知类别、空值处理和长尾类别等问题,但通过平滑处理能有效缓解。Target Encoding适用于高维数据和领域经验特征。文章提到了Beta Target Encoding,一种在Avito Demand Prediction Challenge中表现出色的编码方式,它可以提取更多特征,并且在时间效率和模型效果上优于传统方法。
本文探讨了Target Encoding这一有监督特征工程方法,用于类别特征转为数值。尽管存在未知类别、空值处理和长尾类别等问题,但通过平滑处理能有效缓解。Target Encoding适用于高维数据和领域经验特征。文章提到了Beta Target Encoding,一种在Avito Demand Prediction Challenge中表现出色的编码方式,它可以提取更多特征,并且在时间效率和模型效果上优于传统方法。
目前看到的大多数特征工程方法都是针对数值特征的。本文介绍的Target Encoding是用于类别特征的。这是一种将类别编码为数字的方法,就像One-hot或Label-encoding一样,但和这种两种方法不同的地方在于target encoding还使用目标来创建编码,这就是我们所说的有监督特征工程方法。

Target Encoding是任何一种可以从目标中派生出数字替换特征类别的编码方式。这种目标编码有时被称为平均编码。应用于二进制目标时,也被称为bin counting。(可能会遇到的其他名称包括:likelihood encoding, impact encoding, and leave-one-out encoding。)
每种方法都有其缺点,target encoding的缺点主要有:
- 未知类别,会产生过拟合风险;
- 空值,采用填充的方法不能很好的进行评估;
- 长尾类别,对长尾类别这种少量数据的编码会导致过拟合;
鉴于以上缺点的存在,一般会加入平滑来进行处理。
encoding = weight * in_category + (1 - weight) * overall
weight = n / (n + m)
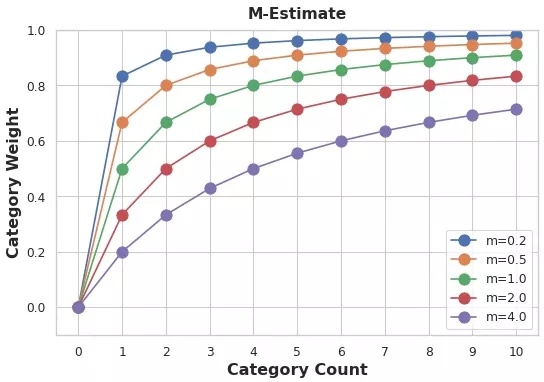
说了半天它的缺点和如何解决这些缺点,该方式的优点有哪些呢?
- 高维数据特征:具有大量类别的可能很难编码:One-hot会生成太多维度,而替代方案(如标签编码)可能不适合该类型。Target encoding在此处就很好的解决了这个问题;
- 领域经验特征:根据之前的经验,即使某项数据它在特征度量方面得分很低,你也可能会觉得一个分类特征应该很重要。Target encoding有助于揭示特征的真实信息。

在kaggle竞赛宝典中,有一篇《Kaggle Master分享编码神技-Beta Target Encoding》,很好的介绍了Beta Target Encoding,该编码方案来源于kaggle曾经的竞赛Avito Demand Prediction Challenge 第14名solution。从作者开源出来的代码,我们发现该编码和传统Target Encoding不一样。
- Beta Target Encoding可以提取更多的特征,不仅仅是均值,还可以是方差等等;
- 从作者的开源中,是没有进行N Fold提取特征的,所以可能在时间上提取会更快一些;
从作者的对比上我们可以看到,使用Beta Target Encoding相较于直接使用LightGBM建模的效果可以得到大幅提升。

class BetaTargetEncoder(object):
def __init__(self, group):
self.group = group
self.stats = None
self.whoami = "DOTA"
# get counts from df
def fit(self, df, target_col):
# 先验均值
self.prior_mean = np.mean(df[target_col])
stats = df[[target_col, self.group]]< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









