







 推荐系统在处理大量候选item时面临曝光偏差问题。《Contrastive Learning for Debiased Candidate Generation》论文提出使用对比学习来解决这一问题,具体通过对比损失函数优化,避免了曝光多的样本主导学习过程。CLRec是该方法的一种实现,它采用队列采样策略,有效缓解曝光偏差,提高推荐系统的多样性和准确性。
推荐系统在处理大量候选item时面临曝光偏差问题。《Contrastive Learning for Debiased Candidate Generation》论文提出使用对比学习来解决这一问题,具体通过对比损失函数优化,避免了曝光多的样本主导学习过程。CLRec是该方法的一种实现,它采用队列采样策略,有效缓解曝光偏差,提高推荐系统的多样性和准确性。
推荐系统中常常需要在亿级别的候选集中找到上百个相关的item,俗称DCG问题(Deep candidate generation)。通常处理这类问题采用的类似语言建模的方法。然而显存的推荐系统都存在着曝光偏差,在候选集多的时候这个偏差更加的严重,导致模型只学习了曝光多的样本,因此这篇论文《Contrastive Learning for Debiased Candidate Generation in Large-Scale Recommender Systems》使用了对比学习去解决曝光偏差问题,该方法已经成功部署在淘宝,并且效果有显著提升。
DCG问题中的对比学习
首先我们可以拿到这样的数据集和,D={(xu,t,yu,t): u=1,2,...,N, t=1,2,...Tu},xu,t= {yu,1:(t-1)},即我们在预估t时刻用户要点啥时,用到的是该用户t时刻前点击的所有items。在DCG问题中,我们需要学习用户的encoder和item的encoder把用户和item映射到一个空间中,并通过cos相似度找到top k的item,典型的学习方式如下,使用最大似然估计(MLE)去拟合上述数据集合:
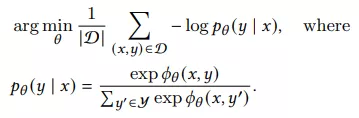
然而使用观测到的点击数据训练模型会有严重的曝光偏差问题,对有潜力但没机会曝光的item是毁灭性打击。很多高质量的item但是在训练数据集中点击较少,在MLE这种学习方式就很难再曝光。
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3035
3035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









