






日志收集平台项目nginx、kafka、zookeeper、filebeat、redis搭建的基本配置
文章目录
1、环境准备
1.1 准备好三台虚拟机搭建nginx和kafka集群。
1.2 配置好静态ip地址(尽量使用NAT模式)
为了统一,我的使用的是桥接模式。
1、先准备三台虚拟机:

2、然后修改为桥接模式(三台要统一修改)。
 在箭头处点击设置:
在箭头处点击设置:
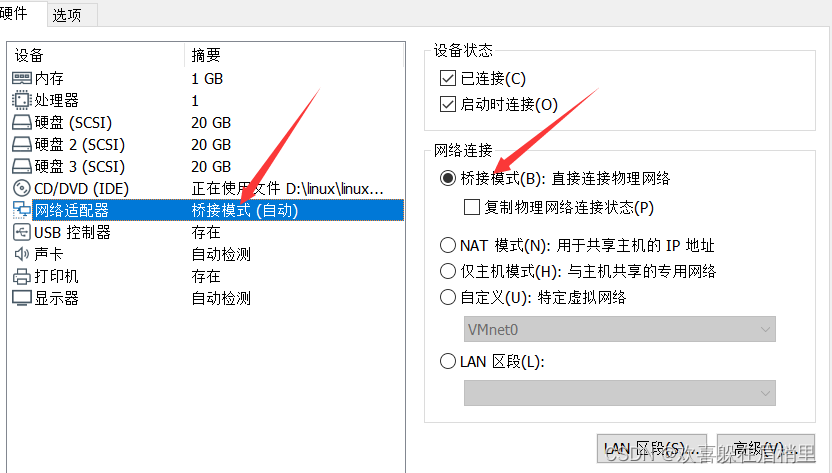
3、现在要进行静态ip地址的设置:
①先查看ip地址:ip a
②然后查看网关是多少:ip r
[root@nginx-kafka01 ~]# ip a
[root@nginx-kafka01 ~]# ip r

③配置好dns:
[root@nginx-kafka03 ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 114.114.114.114
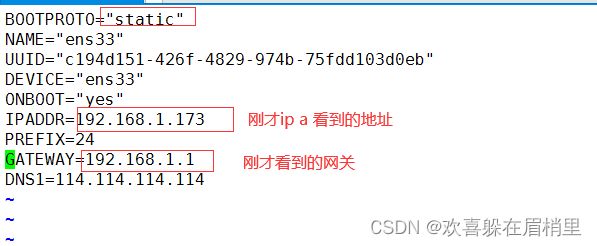
④编辑网卡配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
dns解析:
1、浏览器的缓存
2、本地hosts文件—Linux(/etc/hosts)
3、找本地域名服务器—Linux(/etc/resolv.conf)
1.3 修改主机名:三台都需要修改,然后进行序号01、02、03
第一台虚拟机
[root@nginx-kafka01 etc]# vim hostname
[root@nginx-kafka01 etc]# cat hostname
nginx-kafka01
第二台虚拟机
[root@nginx-kafka02 etc]# vim hostname
[root@nginx-kafka02 etc]# cat hostname
nginx-kafka02
第三台虚拟机
[root@nginx-kafka03 etc]# vim hostname
[root@nginx-kafka03 etc]# cat hostname
nginx-kafka03
1.4 每一台机器上都写好域名解析
ip地址根据自己的进行添加,比如我的是:192.168.0.94、192.168.0.95 、 192.168.0.96
vim /etc/hostname
192.168.0.94 nginx-kafka01
192.168.0.95 nginx-kafka02
192.168.0.96 nginx-kafka03
1.5 安装基本软件
yum install wget lsof vim -y
1.6 安装时间同步服务
yum -y install chrony
systemctl enable chronyd 设置为开机自启
扩展知识:disable:为开机不自启、关闭开机自启。
设置时区:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
1.7 关闭防火墙
[root@nginx-kafka01 ~]# systemctl stop firewalld
[root@nginx-kafka01 ~]# systemctl disable firewalld
关闭selinux服务
将/etc/selinux/config文件里的SELINUX设置为disabled
vim /etc/selinux/config
SELINUX=disabled
selinux关闭之后,需要重启机器。
selinux是什么呢?
selinux是Linux内核里一个跟安全相关的子系统,一般日常工作里都是关闭的。
2 、nginx搭建
2.1 安装好epel源:
yum install epel-release -y
2.2 安装nginx
yum install nginx -y
2.3 启动nginx
systemctl start nginx
2.4 设置为开机自启
[root@nginx-kafka01 system]# systemctl enable nginx
Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service.
设置开机自启之后,会在/etc/systemd/system/multi-user.target.wants下创建一个nginx.service文件。
2.5 编辑配置文件
[root@nginx-kafka01 ~]# cd /etc/nginx/
[root@nginx-kafka01 nginx]# ls
conf.d fastcgi.conf.default koi-utf mime.types.default scgi_params uwsgi_params.default
default.d fastcgi_params koi-win nginx.conf scgi_params.default win-utf
fastcgi.conf fastcgi_params.default mime.types nginx.conf.default uwsgi_params
其中nginx的主配置文件为:nginx.conf
vim nginx.conf :
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
# 全局块
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
#events块
events {
worker_connections 1024;
}
#http块
http { #http全局块
#log_format 日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
#日志存放文件
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 4096;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
#serevr块
server { #server全局块
listen 80;
listen [::]:80;
server_name _;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
error_page 404 /404.html;
location = /404.html { # location块
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
# Settings for a TLS enabled server.
#
# server {
# listen 443 ssl http2;
# listen [::]:443 ssl http2;
# server_name _;
# root /usr/share/nginx/html;
# #http全局块
# ssl_certificate "/etc/pki/nginx/server.crt";
# ssl_certificate_key "/etc/pki/nginx/private/server.key";
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 10m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
#
# # Load configuration files for the default server block.
# include /etc/nginx/default.d/*.conf;
#
# error_page 404 /404.html;
# location = /40x.html {
# }
#
# error_page 500 502 503 504 /50x.html;
# location = /50x.html {
# }
# }
}
1、全局块:配置影响nginx全局的指令。一般有运行nginx服务器的用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process数等。
2、event块:配置影响nginx服务器与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。
3、http块:可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type定义,日志自定义,是否使用sendfile传输文件,连接超时时间,单连接请求数等。
4、server块:配置虚拟主机的相关参数,一个http中可以有多个server。
5、location:配置请求的路由,以及各种页面的处理情况。
2.6 修改配置文件
vim nginx.conf
将 :
listen 80 default_server;
修改成:
listen 80;
虚拟主机的配置:
vim /etc/nginx/conf.d/sc.conf
server {
listen 80 default_server; #监听的端口
server_name www.sc.com;
#使用域名访问,使用www.sc.com进行访问,就往下执行。
#但是如果使用ip地址访问的话,会去执行绑定的server下的default
root /usr/share/nginx/html; #存放网页的根目录
access_log /var/log/nginx/sc/access.log main; #日志存放路径
location / {
}
}
#可以添加多个
server {
listen 80 default_server; #监听的端口
server_name www.sc2.com; #使用域名访问
root /usr/share/nginx/html;
access_log /var/log/nginx/sc/access.log main;
location / {
}
}
修改文件之后需要重新加载或者重启服务器。
2.7 语法检测
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: [emerg] open() “/var/log/nginx/sc/access.log” failed (2: No such file or directory)
nginx: configuration file /etc/nginx/nginx.conf test failed
如果出现说创建失败,需要先新建sc文件夹:
[root@nginx-kafka01 html]# mkdir /var/log/nginx/sc
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
重新加载nginx
nginx -s reload
nginx做web网站的话,它只能支持静态网页,所以nginx用于做反向代理和负载均衡。
然后查看nginx服务是否启动,可以去网站上输入自己的ip地址:
就会出现以下页面,表示启动成功:

或者直接在命令行输入:curl + 同一网段的其他ip地址:
root@nginx-kafka01 nginx]# curl 192.168.2.33
this is sc
welcome
hlhdlfhsdlkjhsdkjhfsdjk
访问成功之后,nginx的日志文件之中就会多一条访问记录:可以看到最后一行多了一条访问记录:
[root@nginx-kafka01 etc]# cat /var/log/nginx/access.log
192.168.2.123 - - [15/Jul/2022:11:49:28 +0800] "GET / HTTP/1.1" 200 615 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49" "-"
192.168.2.123 - - [15/Jul/2022:11:49:28 +0800] "GET /favicon.ico HTTP/1.1" 404 555 "http://192.168.2.152/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49" "-"
192.168.2.123 - - [15/Jul/2022:11:51:21 +0800] "GET /sc.html HTTP/1.1" 200 16 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49" "-"
192.168.2.33 - - [15/Jul/2022:11:56:36 +0800] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
192.168.2.123 - - [15/Jul/2022:12:02:38 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49" "-"
192.168.2.123 - - [15/Jul/2022:12:04:15 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49" "-"
192.168.2.33 - - [15/Jul/2022:12:17:08 +0800] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
curl是什么?
curl 是常用的命令行工具,用来请求 Web 服务器。它的名字就是客户端(client)的 URL 工具的意思。
3、kafka搭建
使用kafka来收集日志的原因:收集nginx的日志,将nginx日志提取关键字段进行分析,将日志分析清洗后的数据再存入mysql数据库。可以方便业务解耦,流量。
3.1 安装(三台都需要安装)
1、安装java:
yum install java wget -y
2、安装kakfa:(安装在/opt目录下面)
wget https://mirrors.bfsu.edu.cn/apache/kafka/2.8.1/kafka_2.12-2.8.1.tgz
3、解包:
[root@nginx-kafka01 opt] tar xf kafka_2.12-2.8.1.tgz
使用自带的zookeeper集群配置:kafka_2.12-2.8.1这个版本需要zookeeper。
4、安装zookeeper:
wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
安装成功之后同样的进行解包操作:
[root@nginx-kafka01 opt] tar xf apache-zookeeper-3.6.3-bin.tar.gz
[root@nginx-kafka01 opt]# ls
apache-zookeeper-3.6.3-bin containerd kafka_2.12-2.8.1 rh
apache-zookeeper-3.6.3-bin.tar.gz flask_proj kafka_2.12-2.8.1.tgz
3.2 配置kafka
进入kafka_2.12-2.8.1/config修改sercer.properties文件:
vim kafka_2.12-2.8.1/config/server.properties
broker.id=0 # 三台都一样
###映射关系;三台机器都需要,填写主机名
listeners=PLAINTEXT://nginx-kafka01:9092 #第一台
listeners=PLAINTEXT://nginx-kafka02:9092 # 第二台
listeners=PLAINTEXT://nginx-kafka03:9092 #第三台
##zookeeper.connect连接的ip:三台机器的ip:
zookeeper.connect=192.168.2.152:2181,192.168.2.132:2181,192.168.2.137:2181
生产者:
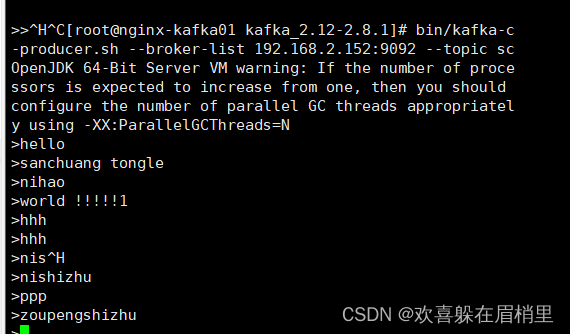
消费者:在生产者中输入的信息在消费者中都可以实时查看到。

4、 zookeeper配置
进入/opt/apache-zookeeper-3.6.3-bin/confs
[root@nginx-kafka01 opt]# cd apache-zookeeper-3.6.3-bin
[root@nginx-kafka01 apache-zookeeper-3.6.3-bin]# ls
bin conf docs lib LICENSE.txt logs NOTICE.txt README.md README_packaging.md
[root@nginx-kafka01 apache-zookeeper-3.6.3-bin]# cd conf
[root@nginx-kafka01 conf]# cp zoo_sample.cfg zoo.cfg
修改zoo.cfg, 添加如下三行:分别为三台虚拟机的ip地址:
server.1=192.168.2.152:3888:4888
server.2=192.168.2.132:3888:4888
server.3=192.168.2.137:3888:4888
其中3888和4888都是端口 一个用于数据传输,一个用于检验存活性和选举。
创建/tmp/zookeeper目录 ,在目录中添加myid文件,文件内容就是本机指定的zookeeper id内容
如:
在192.168.2.152机器上:
echo 1 > /tmp/zookeeper/myid
在192.168.2.132机器上:
echo 2 > /tmp/zookeeper/myid
在192.168.2.137机器上:
echo 3 > /tmp/zookeeper/myid
4.1 启动zookeeper
cd /opt/zookeeper/bin #进入bin目录下
./zkServer.sh start #启动命令
可以使用ps -ef|grep zookeeper查看zookeeper进程是否启动。
[root@nginx-kafka01 conf]# ps -ef|grep zookeeper
启动kafka要基于zookeeper,zookeeper帮助管理kafka,是一个配置管理服务。
开启zk和kafka的时候,一定是先启动zk,再启动kafka。
关闭服务的时候,kafka先关闭,再关闭zk。
4.2 查看zookeeper的状态
查看状态的时候也是要保证三台机器都是启动zookeeper的。
[root@nginx-kafka03 apache-zookeeper-3.6.3-bin]# bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
以下三台机器都要执行。
启动kafka:以daemon的形式去启动kafka,在config文件下面
bin/kafka-server-start.sh -daemon config/server.properties
4.3 zookeeper的使用
运行 bin/zkCli.sh
使用进入:
[root@nginx-kafka02 kafka_2.12-2.8.1]# cd /opt/apache-zookeeper-3.6.3-bin/bin
[root@nginx-kafka02 bin]# ./zkCli.sh
/usr/bin/java
Connecting to localhost:2181
2022-07-16 11:52:13,360 [myid:] - INFO [main:Environment@98] - Client environment:zookeeper.ver
.......
[zk: localhost:2181(CONNECTED) 0] ls
ls [-s] [-w] [-R] path
[zk: localhost:2181(CONNECTED) 1] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 2] ls brokers/
Path must start with / character
[zk: localhost:2181(CONNECTED) 3] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 4] ls /brokers/ids
[1, 2, 3] #要保证三台机器都起来
[zk: localhost:2181(CONNECTED) 10] create /sc/xx 5 #创建节点、文件夹
Created /sc/xx
[zk: localhost:2181(CONNECTED) 11] set /sc/xx 5 #设置
[zk: localhost:2181(CONNECTED) 12] ls /sc/xx
[]
[zk: localhost:2181(CONNECTED) 13] get /sc/xx
5
[zk: localhost:2181(CONNECTED) 15] set /sc/xx yy 10
[zk: localhost:2181(CONNECTED) 16] get /sc/xx
yy
[zk: localhost:2181(CONNECTED) 17] ls /sc #查看当前文件夹里面的内容
[xx]
[zk: localhost:2181(CONNECTED) 18] create /sc/page #创建page
Created /sc/page
[zk: localhost:2181(CONNECTED) 19] set /sc/page 10
[zk: localhost:2181(CONNECTED) 20] get /sc/page
10
[zk: localhost:2181(CONNECTED) 21] ls /brokers/ids #查看集群id
[1, 2, 3]
4.4 启动kafka和zookeeper的连接
启动kafka和zookeeper的连接,随便在一个机器上面输入:
[root@nginx-kafka02 kafka_2.12-2.8.1]# cd /opt/apache-zookeeper-3.6.3-bin/bin
[root@nginx-kafka02 bin]# ./zkCli.sh
/usr/bin/java
Connecting to localhost:2181
2022-07-16 11:52:13,360 [myid:] - INFO [main:Environment@98] - Client environment:zookeeper.version=3.6.3--6401e4ad2087061bc6b9f80dec2d69f2e3c8660a, built on 04/08/2021 16:35 GMT
2022-07-16 11:52:13,364 [myid:] - INFO [main:Environment@98] - Client environment:host.n
....
5、 kafka的使用
测试:
5.1 创建topic:nginxlog
进入kafka中:三台机器是一个集群,使用哪个地址都可以的。
root@nginx-kafka01 opt]# cd kafka_2.12-2.8.1
[root@nginx-kafka01 kafka_2.12-2.8.1]# bin/kafka-topics.sh --create --zookeeper 192.168.2.152:2181 --replication-factor 3 --partitions 3 --topic nginxlog
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Created topic nginxlog.
5.2 查看topic:
tmp/kafka_2.12-2.8.1/ bin/kafka-topics.sh --list --zookeeper 192.168.2.152:2181
5.3 创建生产者:
root@localhost kafka_2.12-2.8.0]# bin/kafka-console-producer.sh --broker-list 192.168.2.152:9092 --topic nginxlog
>hello
>sanchuang tongle
>nihao
>world !!!!!!1
进入生产者机器测试:
[root@nginx-kafka01 kafka_2.12-2.8.1]# bin/kafka-c-producer.sh --broker-list 192.168.2.152:9092 --topic nginxlog
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
>hello
>sanchuang tongle
>nihao
>world !!!!!1
>hhh
>hhh
>nis
>nishizhu
>ppp
>zoupengshizhu
在生产者中输入的信息在消费者的可以实时查看到。
5.3 创建消费者
一台虚拟机做消费者,ip地址可以设置一样。
[root@localhost kafka_2.12-2.8.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.2.152:9092 --topic nginxlog --from-beginning
消费者机器测试:
[root@nginx-kafka02 kafka_2.12-2.8.1]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.2.152:9092 --topic nginxlog --from-beginning #from-beginning 表示从头开始
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
hello
nihao
sanchuang tongle
world !!!!!1
hhh
sanchuang tongle
hello
nihao
hhh
ni
nishizhu
ppp
zoupengshizhu
5.4 连接zk
bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/ids
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 3] get /brokers/ids
null
[zk: localhost:2181(CONNECTED) 4] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://nginx-kafka02:9092"],"jmx_port":9999,"features":{},"host":"nginx-kafka02","timestamp":"1642300427923","port":9092,"version":5}
[zk: localhost:2181(CONNECTED) 5] ls /brokers/ids/0
[]
[zk: localhost:2181(CONNECTED) 6] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://nginx-kafka02:9092"],"jmx_port":9999,"features":{},"host":"nginx-kafka02","timestamp":"1642300427923","port":9092,"version":5}
6、filebeat部署
6.1 安装
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch #导入它的key
6.2 编辑/etc/yum.repos.d/nginx.repo文件
可以先进行备份一份
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
6.3 yum安装
yum install filebeat -y
rpm -qa |grep filebeat #可以查看filebeat有没有安装 rpm -qa 是查看机器上安装的所有软件包
rpm -ql filebeat 查看filebeat安装到哪里去了,牵扯的文件有哪些
6.4 设置开机自启
systemctl enable filebeat
6.5 修改配置文件
vim /etc/filebeat/filebeat.yml (可以先备份一份)
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/sc/access.log
#==========------------------------------kafka-----------------------------------
output.kafka:
hosts: ["192.168.2.152:9092","192.168.2.132:9092","192.168.2.137:9092"]
topic: nginxlog
keep_alive: 10s
6.6 启动服务
systemctl start filebea
6.7 查看数据文件
[root@nginx-kafka01 filebeat]# pwd
/var/lib/filebeat/registry/filebeat
[root@nginx-kafka01 filebeat]# less log.json
7、安装redis
yum install epel-release -y
yum install redis -y
修改监听ip
vim /etc/redis.conf
bind 0.0.0.0
启动redis:
[root@nginx-kafka01 ~]systemctl start redis
[root@nginx-kafka01 ~]# ps -aux|grep redis
redis 10847 0.1 0.5 143056 5788 ? Ssl 15:08 0:00 /usr/bin/redis-server 0.0.0.0:6379
root 10851 0.0 0.0 112824 984 pts/1 S+ 15:08 0:00 grep --color=auto redis
[root@nginx-kafka01 ~]# lsof -i:6379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 10847 redis 4u IPv4 329707 0t0 TCP *:6379 (LISTEN)
[root@nginx-kafka01 ~]# netstat -anplut|grep redis
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 10847/redis-server
进入redis:
[root@nginx-kafka01 ~]# redis-cli
选择0 1 2 3号库
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> select 2
OK
127.0.0.1:6379[2]> select 3
OK
127.0.0.1:6379[3]> set a 123
OK
127.0.0.1:6379[3]> get a 设置key
"123"
127.0.0.1:6379[3]> keys a* 获取以a开头的key
1) "a"
127.0.0.1:6379[3]> set abc 444 设置key
OK
127.0.0.1:6379[3]> set aaa 555
OK
127.0.0.1:6379[3]> set ddd 666
OK
127.0.0.1:6379[3]> keys a*
1) "abc"
2) "a"
3) "aaa"
redis通常被称为数据库结构服务器,Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
不同的类型执行不同的指令:list:lpush
列表:使用lpush:
127.0.0.1:6379[3]> lpush sanchuang call
(integer) 1
127.0.0.1:6379[3]> lpush sanchuang 1
(integer) 2
127.0.0.1:6379[3]> lpush sanchuang nnn
(integer) 3
127.0.0.1:6379[3]> lpush sanchuang yyy
(integer) 4
127.0.0.1:6379[3]> lrange sanchuang 0 10
1) "yyy"
2) "nnn"
3) "1"
4) "call"
127.0.0.1:6379[3]> rpop sanchuang #移除并获取列表的第一个元素。
"call"
127.0.0.1:6379[3]> lrange sanchuang 0 10 #获取列表指定范围内的元素:获取列表0到10内的元素。
1) "yyy"
2) "nnn"
3) "1"
8、安装celery
pip install celery
pip install redis
编辑celery 参照flask_log/celery_app。
执行的是定时任务。
config.py:celery 的配置文件
from celery.schedules import crontab
#配置消息中间件的地址 #启动worker的地址
BROKER_URL = "redis://192.168.77.152:6379/1"
#配置结果存放地址
CELERY_RESULT_BACKEND = "redis://192.168.77.152:6379/2"
#启动celery时,导入任务,只要导入任务才能执行
CELERY_IMPORTS = {
'celery_tasks' #最开始时候是没有任务的,存放celery要执行的任务
}
#时区
CELERY_TIMEZONE = "Asia/Shanghai"
#设置了一个定时任务
CELERYBEAT_SCHEDULE = {
'log-every-minute': {
'task' : 'celery_tasks.scheduled_task', #是celery_tasks中的scheduled_task任务,千万不能打错
'schedule': crontab(minute='*/1')
}
}
celery_tasks.py:存放任务的文件
from app import celery_app
#加入装饰器就是一个任务,不加装饰器就是一个普通对象。
@celery_app.task
def scheduled_task(*args,**kwargs):
print("this is scheduled_task")
app.py:核心对象,生成celery的核心对象;存放celery核心对象的文件。
from celery import Celery
#实例化celery对象,传入一个名字即可
celery_app = Celery('celery_app')
#从config中获取东西
celery_app.config_from_object('config')
启动worker:启动消费者,消费任务
[root@nginx-kafka01 celery_task]# celery -A app.celery_app worker --loglevel=INFO -n node1
py` to avoid these warnings and to allow a smoother upgrade to Celery 6.0.
[2022-07-25 16:45:51,567: INFO/MainProcess] Connected to redis://192.168.2.152:6379/1
[2022-07-25 16:45:51,574: INFO/MainProcess] mingle: searching for neighbors
[2022-07-25 16:45:52,610: INFO/MainProcess] mingle: all alone
[2022-07-25 16:45:52,645: INFO/MainProcess] celery@nodel ready.
生成的任务每分钟会打印出来。
启动beat:
[root@nginx-kafka01 celery_task]# celery -A app.celery_app beat --loglevel=INFO
celery beat v5.1.2 (sun-harmonics) is starting.
__ - ... __ - _
LocalTime -> 2022-07-25 17:08:53
....
worker和beat都要执行核心对象文件.
9、kafka、zookeeper、filebeat搭建成功测试
在windows机器上的C:\Windows\System32\drivers\etc的hosts文件里面添加ip和域名:
192.168.2.152 www.sc.com
192.168.2.132 www.sc.com
192.168.2.137 www.sc.com
然后在浏览器上面输入:www.sc.com就能进行访问到页面。

如果没有成功的可以尝试更换浏览器和清除缓存:同时按ctrl+shift+del清除缓存。
输入www.sc.com解析到的先是第一个ip地址的,如果第一个ip地址里面没有数据,就会进行轮询,解析第二个ip地址。是由于客户机有重试机制,所以会影响用户的体验。
也可以通过一个脚本的方式实现一键配置部署:
脚本一键安装部署kafka、zookeeper、filebeat















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









