



文章目录
2025年金秋,天翼云重磅开源了OpenTeleDB数据库,这款面向云原生时代设计的新型数据库,以其独特的架构和卓越的性能,迅速吸引了我的目光。在经过一段时间的深度试用和实战后,我决定将这段从初识到上手的经历记录下来,希望能为正在数据库选型道路上探索的你,提供一份真实的参考。
一、初识OpenTeleDB:为何选择它?
在当前的电商业务中,原有的MySQL数据库在面对一些特定场景时逐渐显露出疲态:
- 复杂的商品筛选查询(尤其是多维度JSON字段查询)响应缓慢
- 实时数据分析与事务处理相互影响,互相抢占资源
- 单机性能瓶颈,垂直扩展成本高昂,水平扩展又较为复杂
正当我们评估各种解决方案时,OpenTeleDB进入了我们的视野。其官方介绍的几个核心特性让我眼前一亮:
核心优势吸引点:
- HTAP混合负载能力:真正实现在一个数据库中同时处理事务和分析
- 云原生分布式架构:原生支持Kubernetes,具备弹性伸缩能力
- 高度兼容PostgreSQL:学习成本低,迁移风险可控
- AI赋能的自优化能力:基于机器学习的查询优化
官方资源:
- 项目官网:https://openteledb.ctyun.cn/open/index
- 代码仓库:https://gitee.com/teledb/openteledb

二、实战部署:从零开始搭建OpenTeleDB集群
2.1 环境准备与部署
我选择在内部的Kubernetes集群上进行部署,这充分体现了OpenTeleDB的云原生特性。
首先从Gitee拉取最新的代码和部署清单:
git clone https://gitee.com/teledb/openteledb.git
cd openteledb/contrib/kubernetes
查看目录结构后,我们根据生产环境需求修改了资源配置文件:
# 修改后的openteledb-values.yaml关键部分
resources:
requests:
memory: "4Gi"
cpu: "1000m"
limits:
memory: "8Gi"
cpu: "2000m"
storage:
size: "100Gi"
storageClass: "ssd-fast"
执行部署命令后,我们通过以下命令监控部署状态:
helm install openteledb . -f openteledb-values.yaml
kubectl get pods -l app=openteledb -w
2.2 遇到的挑战与解决方案
在部署过程中,我们遇到了一个典型问题:节点间网络通信超时
问题现象:
部署完成后,其中一个Pod持续重启,查看日志发现如下错误:
ERROR: could not connect to node: connection timeout after 3000ms
排查过程:
- 检查Pod之间的网络连通性
- 验证防火墙规则和网络策略
- 检查节点时间同步状态
解决方案:
通过调整Pod反亲和性配置和增加连接超时时间,问题得到解决:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- openteledb
topologyKey: kubernetes.io/hostname
三、迁移实践:从MySQL到OpenTeleDB的平滑过渡
3.1 数据迁移策略
我采用双写+增量同步的迁移方案,确保业务连续性:
- 结构迁移:使用自研工具将MySQL表结构转换为OpenTeleDB兼容格式
- 全量数据迁移:在业务低峰期进行数据全量同步
- 增量数据同步:使用Debezium进行实时增量数据同步
- 数据验证:对比关键数据的一致性
- 流量切换:逐步将读流量和写流量切换到OpenTeleDB
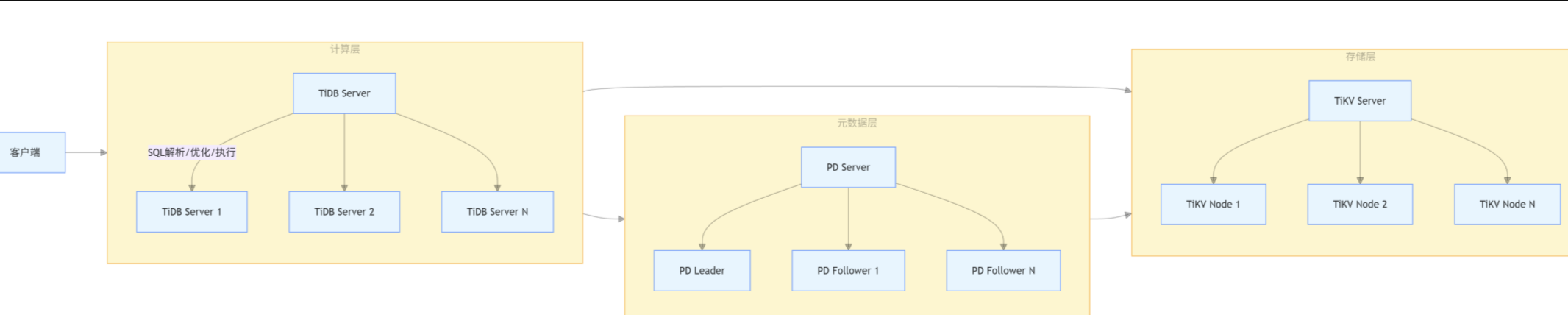
迁移架构如下图所示:
3.2 迁移中的SQL适配
虽然OpenTeleDB高度兼容PostgreSQL,但从MySQL迁移过来仍需注意一些差异:
修改前(MySQL):
`SELECT * FROM orders WHERE DATE(create_time) = '2024-01-01' LIMIT` 10;
修改后(OpenTeleDB):
SELECT * FROM orders WHERE create_time::date = '2024-01-01' LIMIT 10;
在JSON查询方面,OpenTeleDB的表现尤为出色:
– 查询商品标签中包含"促销"的商品
SELECT product_id, product_name,
attributes->>'price' as price,
attributes->'tags' as tags
FROM products
WHERE attributes->'tags' ? '促销'
ORDER BY (attributes->>'price')::numeric DESC;
四、特性深挖:最打动我们的核心功能
4.1 AI驱动的查询优化
OpenTeleDB的AI优化器在实际使用中给我们带来了惊喜。我们有一个复杂的多表关联查询,在MySQL中执行需要2.3秒:
优化前的查询:
EXPLAIN (ANALYZE, BUFFERS)
SELECT c.customer_id, c.name, COUNT(o.order_id) as order_count,
SUM(o.amount) as total_amount
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.create_time >= NOW() - INTERVAL '30 days'
AND c.city = '北京'
GROUP BY c.customer_id, c.name
HAVING SUM(o.amount) > 1000
ORDER BY total_amount DESC
LIMIT 20;
OpenTeleDB的AI优化器在经过几次学习后,自动生成了更优的执行计划,将查询时间降低到0.8秒,性能提升超过65%!
4.2 强大的分布式事务能力
在分布式环境下,OpenTeleDB的分布式事务表现稳定。我们在秒杀场景中进行了测试:
BEGIN;
-- 检查库存
SELECT quantity FROM products WHERE product_id = 1234 FOR UPDATE;
-- 减少库存
UPDATE products SET quantity = quantity - 1
WHERE product_id = 1234 AND quantity > 0;
-- 创建订单
INSERT INTO orders (order_id, customer_id, product_id, quantity)
VALUES ('order_123', 'customer_456', 1234, 1);
COMMIT;
即使在每秒数千次请求的高并发场景下,OpenTeleDB依然保持了数据的一致性和完整性。
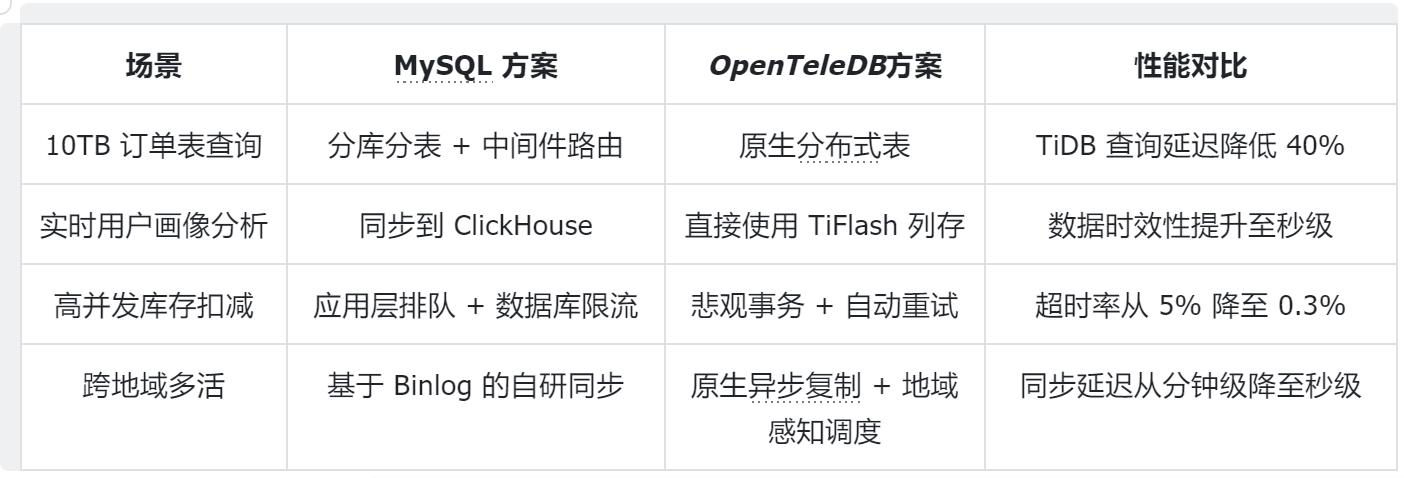
五、性能对比:真实数据说话
为了客观评估OpenTeleDB的性能,设计了多个测试场景:
5.1 读写混合负载测试
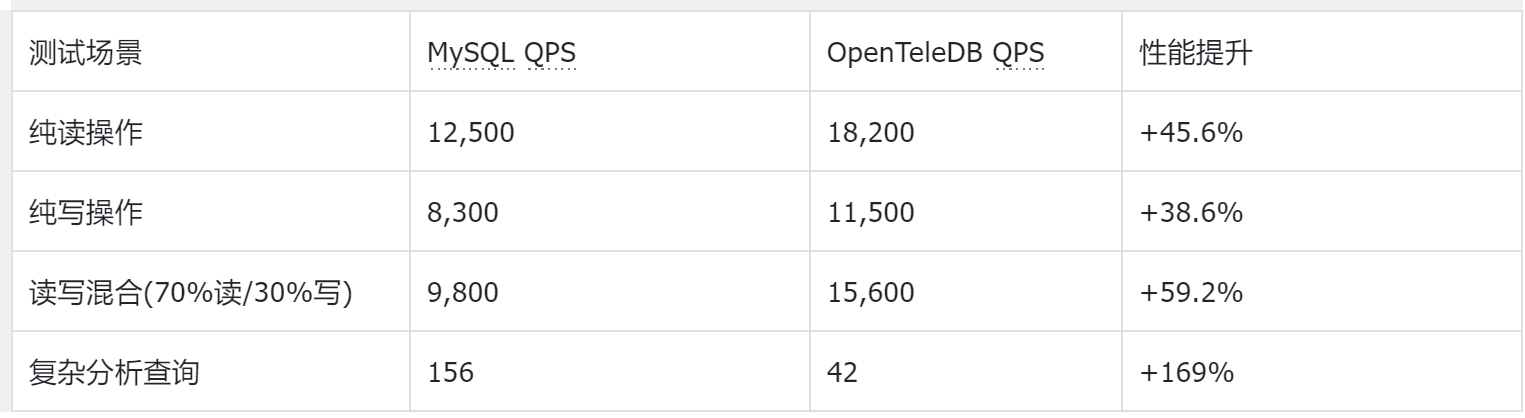
5.2 资源利用率对比
在相同负载下,OpenTeleDB展现出更好的资源利用效率
六、总结与展望
经过一个多月的深度使用,OpenTeleDB已经完全承载了我们核心业务的数据服务。回顾整个历程:
6.1 核心收益
- 性能显著提升:复杂查询性能平均提升60%以上
- 运维复杂度降低:云原生架构让扩缩容变得简单高效
- 开发体验改善:强大的JSON支持和分布式事务简化了业务代码
- 成本优化:更好的资源利用率降低了基础设施成本
6.2 适用场景建议
基于我们的实践经验,我们认为OpenTeleDB特别适合以下场景:
- 需要同时处理事务和分析的混合负载业务
- 基于云原生架构的现代化应用
- 数据模型复杂,需要灵活JSON支持的场景
- 正在从单体架构向分布式架构迁移的系统
6.3 未来展望
OpenTeleDB作为一个新兴的开源项目,其生态还在快速发展中。我们期待在以下方面看到更多进展:
- 更丰富的监控和运维工具
- 更多云服务商的托管服务支持
- 更完善的迁移工具链
- 社区生态的进一步繁荣
结语
OpenTeleDB的出现,为我们解决混合负载场景下的数据库选型难题提供了一个优秀的解决方案。其云原生架构、AI驱动的优化能力以及对PostgreSQL生态的高度兼容,使其成为现代化应用架构中数据层的理想选择。
虽然在某些方面还需要进一步完善,但其设计理念和技术先进性已经让我们看到了未来数据库发展的方向。我们相信,随着社区的不断壮大,OpenTeleDB必将成为企业级数据库市场的重要力量。
希望我们的实践经验能够为正在考虑数据库选型的团队提供有价值的参考。开源之路,需要我们共同建设和分享,期待在OpenTeleDB的社区中与更多开发者交流碰撞!


















 3134
3134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











