







目录
(1)实际中很多公司都会自定义自己的异常体系进行规范的异常管理
1.C语言传统的处理错误的方式
- 终止程序,如assert。缺陷:用户难以接受。如发生内存错误,除0错误时就会终止程序。
- 返回错误码。缺陷:需要程序员自己去查找对应的错误。如系统的很多库的接口函数都是通过把错误码放到errno中,表示错误。
- C标准库中setjmp和longjmp组合。(不常用 , 不用了解)
实际中C语言基本都是使用返回错误码的方式处理错误,部分情况下使用终止程序处理非常严重的错误。
2.C++异常概念
异常是面向对象语言常用的一种处理错误的方式,当一个函数发现自己无法处理的错误时就可以抛出异常,让函数直接或间接的调用者处理这个错误。
- throw:当程序出现问题时,可以通过throw关键字抛出一个异常。
- try:try块中放置的是可能抛出异常的代码,该代码块在执行时将进行异常错误检测,try块后面通常跟着一个或多个catch块。
- catch:如果try块中发生错误,则可以在catch块中定义对应要执行的代码块。
try
{
//被保护的代码
}
catch (ExceptionName e1)
{
//catch块
}
catch (ExceptionName e2)
{
//catch块
}
catch (ExceptionName eN)
{
//catch块
}
3.异常的抛出和捕获
(1)异常的抛出和捕获的匹配原则
- 异常是通过抛出对象而引发的,该对象的类型决定了应该激活哪个catch的处理代码,如果抛出的异常对象没有捕获,或是没有匹配类型的捕获,那么程序会终止报错。
- 被选中的处理代码(catch块)是调用链中与该对象类型匹配且离抛出异常位置最近的那一个。
- 抛出异常对象后,会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个临时对象,所以会生成一个拷贝对象,这个拷贝的临时对象会在被catch以后销毁。(类似于函数的传值返回)
- catch(...)可以捕获任意类型的异常,但捕获后无法知道异常错误是什么。
- 实际异常的抛出和捕获的匹配原则有个例外,捕获和抛出的异常类型并不一定要完全匹配,可以抛出派生类对象,使用基类进行捕获,这个在实际中非常有用。(实际项目最常用)
(2)在函数调用链中异常栈展开的匹配原则
- 当异常被抛出后,首先检查throw本身是否在try块内部,如果在则查找匹配的catch语句,如果有匹配的,则跳到catch的地方进行处理。
- 如果当前函数栈没有匹配的catch则退出当前函数栈,继续在上一个调用函数栈中进行查找匹配的catch。找到匹配的catch子句并处理以后,会沿着catch子句后面继续执行,而不会跳回到原来抛异常的地方。(所以实际中我们最后都要加一个catch(...)捕获任意类型的异常,否则当有异常没捕获,程序就会直接终止 )
- 如果到达main函数的栈,依旧没有找到匹配的catch,则终止程序。
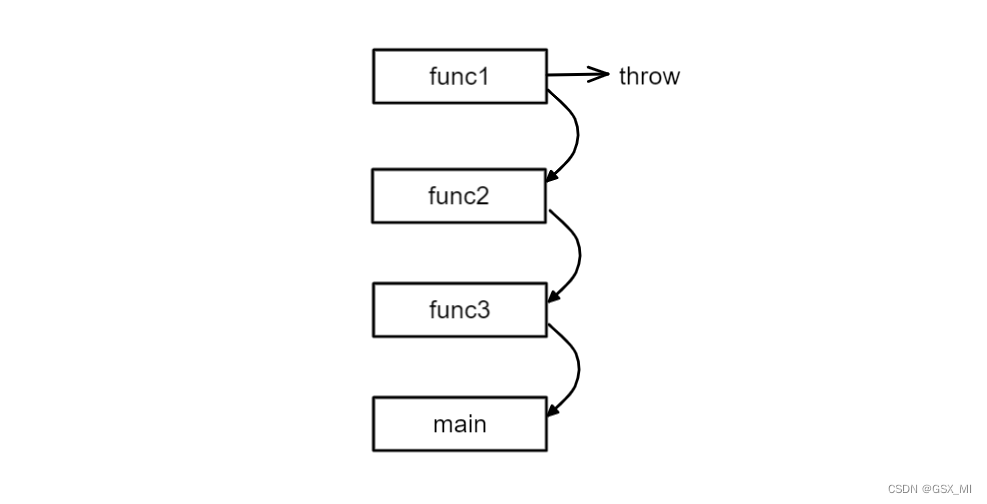
①异常栈展开测试
- main函数中调用了func3,func3中调用了func2,func2中调用了func1,在func1中抛出了一个string类型的异常对象。
void func1()
{
throw string("异常测试"); //返回一个匿名对象
}
void func2()
{
func1();
}
void func3()
{
func2();
}
int main()
{
try
{
func3();
}
catch (const string& s)
{
cout << "错误描述:" << s << endl;
}
catch (...)
{
cout << "未知异常" << endl;
}
return 0;
}
②func1中的异常抛出后的执行过程
- 首先会检查throw本身是否在try块内部,这里由于throw不在try块内部,因此会退出func1所在的函数栈,继续在上一个调用函数栈中进行查找,即func2所在的函数栈。
- 由于func2中也没有匹配的catch,因此会继续在上一个调用函数栈中进行查找,即func3所在的函数栈。
- func3中也没有匹配的catch,于是就会在main所在的函数栈中进行查找,最终在main函数栈中找到了匹配的catch。
- 这时就会跳到main函数中对应的catch块中执行对应的代码块,执行完后继续执行该代码块后续的代码。
- 这个沿着调用链查找匹配的catch子句的过程称为栈展开
4.异常的重新抛出
①有时候单个的catch可能不能完全处理一个异常,在进行一些校正处理以后,希望再交给更外层的调用链函数来处理,比如最外层可能需要拿到异常进行日志信息的记录,这时就需要通过重新抛出将异常传递给更上层的函数进行处理
②如果直接让最外层捕获异常进行处理可能会引发一些问题
- 其中func2中通过new操作符申请了一块内存空间,并且在func2最后通过delete对该空间进行了释放,但func2中途调用的func1内部抛出了一个异常,这时会直接跳转到main函数中的catch块执行对应的异常处理程序,并且在处理完后继续沿着catch块往后执行。
- 这时就导致func2中申请的内存块没有得到释放,造成了内存泄露。
void func1()
{
throw string("异常测试");
}
void func2()
{
int* array = new int[10];
func1();
//do something...
delete[] array;
}
int main()
{
try
{
func2();
}
catch (const string& s)
{
cout << s << endl;
}
catch (...)
{
cout << "未知异常" << endl;
}
return 0;
}
③可以在func2中先对func1抛出的异常进行捕获,捕获后先将申请到的内存释放再将异常重新抛出,这时就避免了内存泄露
- 重新抛出异常对象时,throw后面可以不用指明要抛出的异常对象(不知道以 catch(...) 的方式捕获到的具体是什么异常对象)
- catch (...) //拦截异常,不是要处理异常 ; 捕获任意类型的异常,捕什么,抛什么
void func2()
{
int* array = new int[10];
try
{
func1();
//do something...
}
catch (...) //拦截异常,不是要处理异常 ; 捕获任意类型的异常,补什么,抛什么
{
delete[] array;
throw; //将捕获到的异常再次重新抛出
}
delete[] array;
}
5.异常安全
将抛异常导致的安全问题叫做异常安全问题,对于异常安全问题给出建议:
- ①构造函数完成对象的构造和初始化,最好不要在构造函数中抛出异常,否则可能导致对象不完整或没有完全初始化。
- ②析构函数主要完成对象资源的清理,最好不要在析构函数中抛出异常,否则可能导致资源泄露(内存泄露、句柄未关闭等)。
- ③C++中异常经常会导致资源泄露的问题,比如在new和delete中抛出异常,导致内存泄露,在lock和unlock之间抛出异常导致死锁,C++经常使用RAII的方式来解决以上问题。
6.异常规范
为了让函数使用者知道某个函数可能抛出哪些类型的异常,C++标准规定:
- 在函数的后面接throw(type1, type2, ...),列出这个函数可能抛掷的所有异常类型。
- 在函数的后面接throw() (C++98) 或 noexcept(C++11),表示该函数不抛异常。
- 若无异常接口声明,则此函数可以抛掷任何类型的异常。(异常接口声明不是强制的)
//表示func函数可能会抛出A/B/C/D类型的异常
void func() throw(A, B, C, D);
//表示这个函数只会抛出bad_alloc的异常
void* operator new(std::size_t size) throw(std::bad_alloc);
//表示这个函数不会抛出异常
void* operator new(std::size_t size, void* ptr) throw();
7.自定义异常体系(多态)
(1)实际中很多公司都会自定义自己的异常体系进行规范的异常管理
- 正常规范的代码是不会抛整形,字符串的类型,而是自定义类型,会有很多描述字段
- 公司中的项目一般会进行模块划分,让不同的程序员或小组完成不同的模块,如果不对抛异常这件事进行规范,那么负责最外层捕获异常的程序员就非常难受了,因为他需要捕获大家抛出的各种类型的异常对象。
- 因此实际中都会定义一套继承的规范体系,先定义一个最基础的异常类,所有人抛出的异常对象都必须是继承于该异常类的派生类对象,因为异常语法规定可以用基类捕获抛出的派生类对象,因此最外层就只需捕获基类就行了。
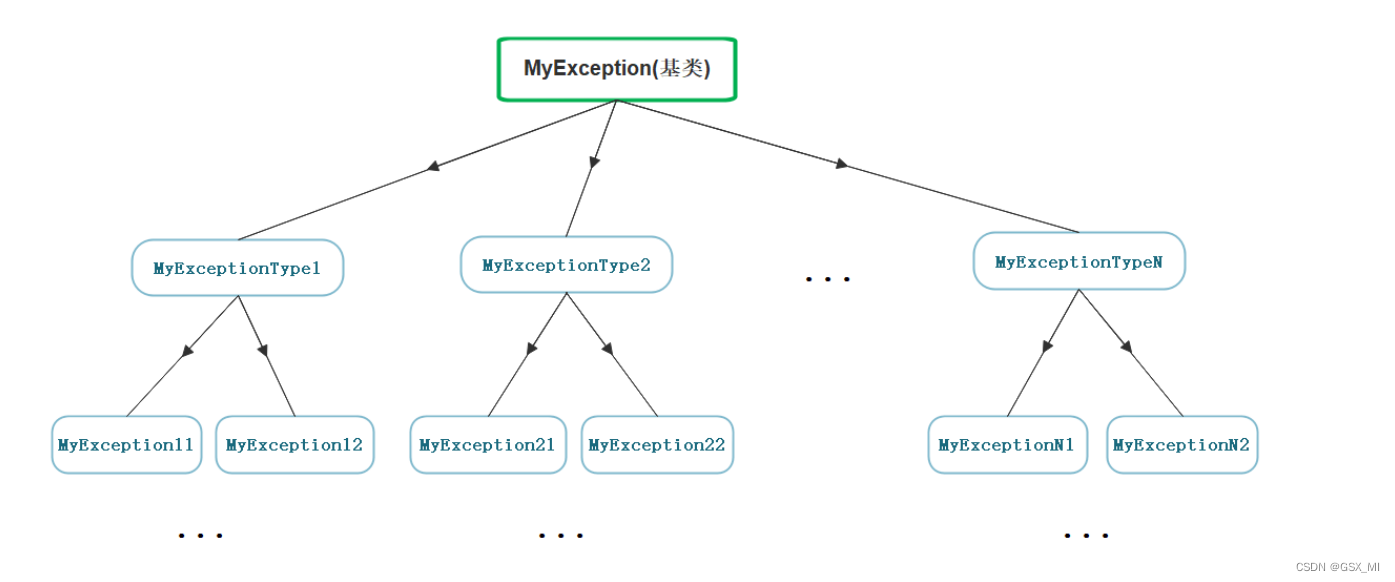
(2)模拟实现自定义异常体系
- 最基础的异常类至少需要包含错误编号和错误描述两个成员变量,甚至还可以包含当前函数栈帧的调用链等信息。该异常类中一般还会提供两个成员函数,分别用来获取错误编号和错误描述
- 其他模块如果要对这个异常类进行扩展,必须继承这个基础的异常类,可以在继承后的异常类中按需添加某些成员变量,或是对继承下来的虚函数what进行重写,使其能告知程序员更多的异常信息
- 异常类的成员变量不能设置为私有,因为私有成员在子类中是不可见的。
- 基类Exception中的what成员函数最好定义为虚函数,方便子类对其进行重写,从而达到多态的效果。
#include<iostream>
#include<string>
#include<time.h>
#include <thread>
#include <vector>
using namespace std;
// 服务器开发中通常使用的异常继承体系
class Exception //基类
{
public:
Exception(const string& errmsg, int id)
:_errmsg(errmsg)
, _id(id)
{}
virtual string what() const //实现多态
{
return _errmsg;
}
protected:
string _errmsg; //错误描述
int _id; //错误编号 -- 针对某种错误进行特殊处理(也很重要)
};
class SqlException : public Exception
{
public:
SqlException(const string& errmsg, int id, const string& sql)
:Exception(errmsg, id)
, _sql(sql)
{}
virtual string what() const
{
string str = "SqlException:";
str += _errmsg;
str += "->";
str += _sql;
return str;
}
private:
const string _sql;
};
class CacheException : public Exception
{
public:
CacheException(const string& errmsg, int id)
:Exception(errmsg, id)
{}
virtual string what() const
{
string str = "CacheException:";
str += _errmsg;
return str;
}
};
class HttpServerException : public Exception
{
public:
HttpServerException(const string& errmsg, int id, const string& type)
:Exception(errmsg, id)
, _type(type)
{}
virtual string what() const
{
string str = "HttpServerException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};
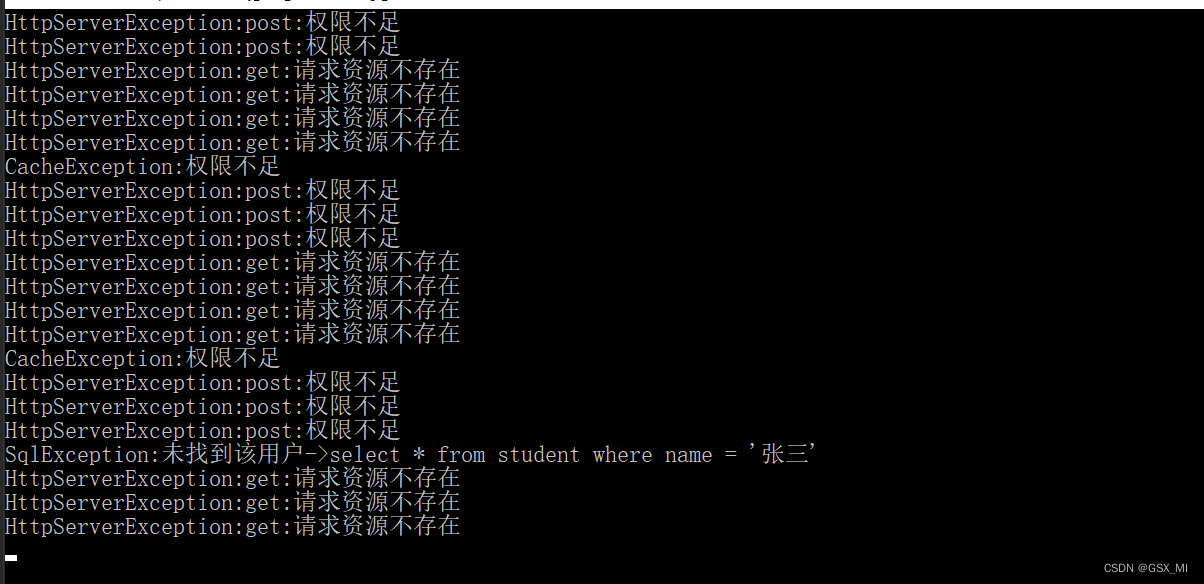
void SQLMgr()
{
srand(time(0));
if (rand() % 7 == 0)
{
throw SqlException("未找到该用户", 100, "select * from student where name = '张三'");
}
else if (rand() % 8 == 0)
{
throw SqlException("sql语句错误", 101, "select * from age = 21");
}
}
void CacheMgr()
{
srand(time(0));
if (rand() % 5 == 0)
{
throw CacheException("权限不足", 100);
}
else if (rand() % 6 == 0)
{
throw CacheException("数据不存在", 101);
}
SQLMgr();
}
void HttpServer()
{
// ...
srand(time(0));
if (rand() % 3 == 0)
{
throw HttpServerException("请求资源不存在", 100, "get");
}
else if (rand() % 4 == 0)
{
throw HttpServerException("权限不足", 101, "post");
}
CacheMgr();
}
void ServerStart()
{
while (1)
{
this_thread::sleep_for(chrono::seconds(1)); //每隔1s 执行一次
try {
HttpServer();
}
catch (const Exception& e) // 这里捕获父类对象就可以
{
// 多态
cout << e.what() << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
}
}
int main()
{
ServerStart();
return 0;
}
8.标准库异常体系
(1)C++标准库当中的异常也是一个基础体系,其中exception就是各个异常类的基类,我们可以在程序中使用这些标准的异常
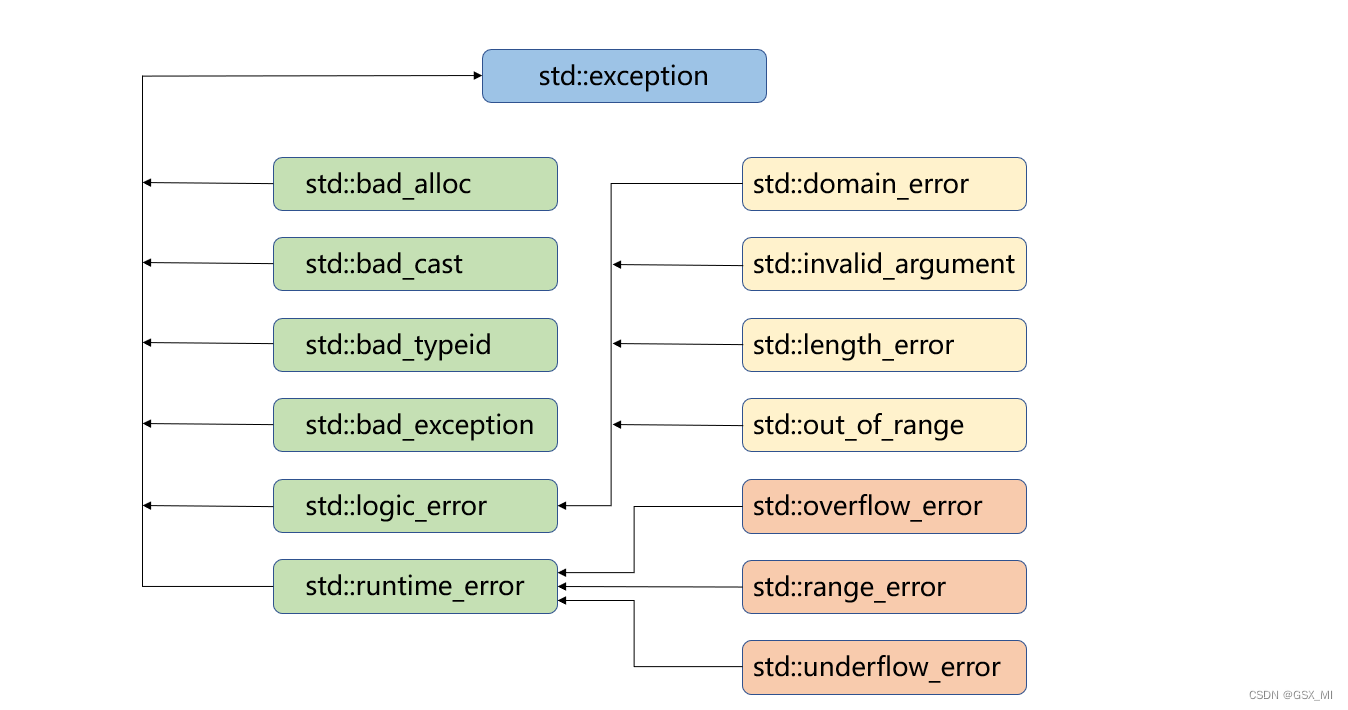
(2)对继承体系中出现的每个异常的说明
| 异常 | 描述 |
|---|---|
| std::exception | 该异常是所有标准C++异常的父类。 |
| std::bad_alloc | 该异常可以通过new抛出。 |
| std::bad_cast | 该异常可以通过dynamic_cast抛出。 |
| std::bad_exception | 这在处理C++程序中无法预期的异常时非常有用。 |
| std::bad_typeid | 该异常可以通过typeid抛出。 |
| std::logic_error | 理论上可以通过读取代码来检测到的异常。 |
| std::domain_error | 当使用了一个无效的数学域时,会抛出该异常。 |
| std::invalid_argument | 当使用了无效的参数时,会抛出该异常。 |
| std::length_error | 当创建了太长的std::string时,会抛出该异常。 |
| std::out_of_range | 该异常可以通过方法抛出,例如std::vector和std::bitset<>::operator。 |
| std::runtime_error | 理论上不可以通过读取代码来检测到的异常。 |
| std::overflow_error | 当发生数学上溢时,会抛出该异常。 |
| std::range_error | 当尝试存储超出范围的值时,会抛出该异常。 |
| std::underflow_error | 当发生数学下溢时,会抛出该异常。 |
(3)补充
- exception类的what成员函数和析构函数都定义成了虚函数,方便子类对其进行重写,从而达到多态的效果。
- 实际中我们也可以去继承exception类来实现自己的异常类,但实际中很多公司都会自己定义一套异常继承体系。
9.异常的优缺点
(1)异常的优点:
- 异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息,甚至可以包含堆栈调用等信息,这样可以帮助更好的定位程序的bug。
- 返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们得层层返回错误码,最终最外层才能拿到错误。
- 很多的第三方库都会使用异常,比如boost、gtest、gmock等等常用的库,如果我们不用异常就不能很好的发挥这些库的作用。
- 很多测试框架也都使用异常,因此使用异常能更好的使用单元测试等进行白盒的测试。
- 部分函数使用异常更好处理,比如T& operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误。
(2)异常的缺点:
- 异常会导致程序的执行流乱跳,并且非常的混乱,这会导致我们跟踪调试以及分析程序时比较困难。
- 异常会有一些性能的开销,当然在现代硬件速度很快的情况下,这个影响基本忽略不计。
- C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄露、死锁等异常安全问题。这个需要使用RAII来处理资源的管理问题,学习成本比较高。
- C++标准库的异常体系定义得不够好,导致大家各自定义自己的异常体系,非常的混乱。
- 异常尽量规范使用,否则后果不堪设想,随意抛异常,也会让外层捕获的用户苦不堪言。
- 异常接口声明不是强制的,对于没有声明异常类型的函数,无法预知该函数是否会抛出异常。
(3) 但总体而言,异常的利大于弊,所以工程中我们还是鼓励使用异常的















 2933
2933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









