







实验原理
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
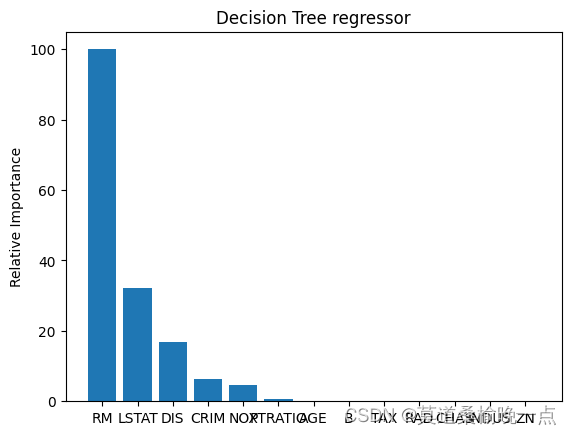
波士顿房价影响因素分析
使用决策树来对房价的因素进行分析发现哪个属性最重要。波士顿房价这个数据集由13个属性,以及一个价格所组成。房子的属性影响价格的走势,但是每一个属性的重要程度是不一样的,可以使用决策树帮我们判别出特征属性的重要程度。
提示:使用决策树回归器DecisionTreeRegressor的feature_importances_ 方法。
# 导包
import numpy as np
# 回归树
from sklearn.tree import DecisionTreeRegressor
# 数据集
from sklearn import datasets
from sklearn.metrics import mean_squared_error, explained_variance_score
from sklearn.utils import shuffle
import matplotlib.pyplot as plt
if __name__=='__main__':
housing_data = datasets.load_boston()
#print( housing_data)
#print( housing_data.data)
#print( housing_data.target)
# 'feature_names': array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
X,y = shuffle(housing_data.data,housing_data.target,random_state=7)
num_training = int(0.8*len(X))
X_train,y_train = X[:num_training],y[:num_training]
X_test,y_test = X[num_training:],y[num_training:]
dt_regressor = DecisionTreeRegressor(max_depth=4)
dt_regressor.fit(X_train,y_train)
y_pred_dt = dt_regressor.predict(X_test)
mse = mean_squared_error(y_test,y_pred_dt)
print("Mean squared error =",round(mse,2))
#Mean squared error = 14.79
#画图准备
feature_importances = 100.0*(dt_regressor.feature_importances_/max(dt_regressor.feature_importances_))
index_sorted = np.flipud(np.argsort(feature_importances))
pos = np.arange(index_sorted.shape[0])+0.5
#画图
plt.figure()
plt.bar(pos,feature_importances[index_sorted],align='center')
plt.xticks(pos,housing_data.feature_names[index_sorted])
plt.ylabel('Relative Importance')
plt.title('Decision Tree regressor')
plt.show()
随机森林准确率
使用sklearn自带数据集digits进行练习,请将数据集划分为训练与测试集,分别使用决策树和随机森林算法对数据digits的训练集进行分类,比较决策树算法和随机森林算法的表现,并思考是否可以继续提升随机森林算法的表现?该如何实现呢?
# 随机森林
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
dig = datasets.load_digits()
X_train,X_test,y_train,y_test = train_test_split(dig.data,dig.target,test_size=0.6,random_state=0)
c1 = DecisionTreeClassifier()
c2 = RandomForestClassifier()
c3 = RandomForestClassifier(n_estimators=200,max_features=8)
p1 = c1.fit(X_train,y_train).predict(X_test)
p2 = c2.fit(X_train,y_train).predict(X_test)
p3 = c3.fit(X_train,y_train).predict(X_test)
print(metrics.accuracy_score(y_test,p1))
print(metrics.accuracy_score(y_test,p2))
print(metrics.accuracy_score(y_test,p3))
# 0.7803521779425394
# 0.9657089898053753
# 0.9731232622798888
根据结果可以得出:带参数的随机森林准确率更高。
















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









