






1、变量(Varaible)**
例子:变量实现自动求导
import torch
from torch.autograd import Variable #导入自动求导的包
#定义3个张量
x = Variable(torch.Tensor([1,2,3]),requires_grad = True)
w = Variable(torch.Tensor([2,3,4]),requires_grad = True)
b = Variable(torch.Tensor([3,4,5]),requires_grad = True)
#构建一个目标方程
y =w*x*x+b
#自动求导,计算梯度
y.backward(torch.Tensor([1,1,1]))
print(x.grad)
print(w.grad)
print(b.grad) #输出结果
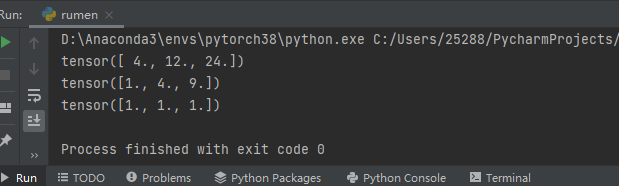
eg.对x求导,结果为2wx, tensor([4,12,24])
4 = 221 12 = 232 24 = 243 …依次类推
2、线性回归
# 导入相应的库
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
from torch.autograd import Variable
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
# 取数据,在-1 到1 之间取100个数据,维度为1
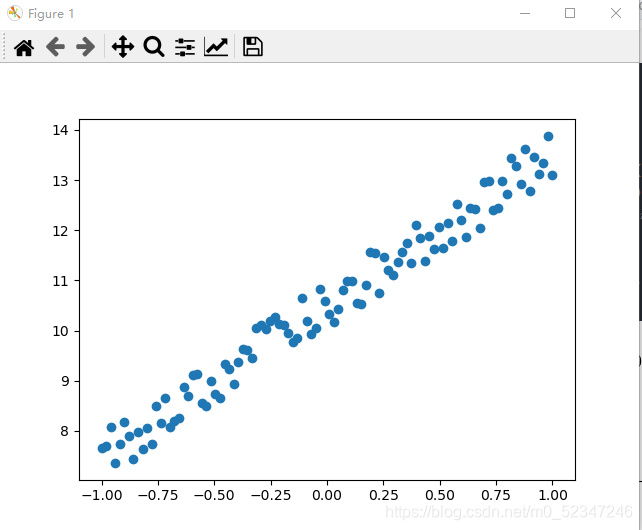
y = 3 * x + 10 + torch.rand(x.size())
# 目标函数为y = 3x+10,其中torch.rand(x.size())目的是为该函数增加噪音,使他们的初始分布在函数周围
# 作图,查看生成的随机数
plt.scatter(x.data.numpy(), y.data.numpy())
plt.show() #此两步后面分类时须注释掉
# 定义回归模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入和输出的维度都是1
def forward(self, x): #前向传播
out = self.linear(x)
return out
if torch.cuda.is_available(): #是否选用GPU
model = LinearRegression().cuda()
else:
model = LinearRegression()
criterion = nn.MSELoss() #定义损失函数,MSE为均方误差
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2) #定义优化函数,SGD(随机梯度下降法),lr学习率
num_epochs = 1000 #设定模型训练次数
for epoch in range(num_epochs):
if torch.cuda.is_available(): #是否选用GPU
inputs = Variable(x).cuda()
target = Variable(y).cuda()
else:
inputs = Variable(x)
target = Variable(y)
# 向前传播
out = model(inputs)
loss = criterion(out, target)
# 向后传播
optimizer.zero_grad() # 梯度归零
loss.backward() #反向传播得到每个参数的梯度值
optimizer.step() #通过梯度下降,更新步数
if (epoch + 1) % 20 == 0: #每间隔20,打印一次结果
print('Epoch[{}/{}], loss:{:.6f}'.format(epoch + 1, num_epochs, loss.item()))
model.eval() #模型测试,查看拟合结果
if torch.cuda.is_available():
predict = model(Variable(x).cuda())
predict = predict.data.cpu().numpy()
else:
predict = model(Variable(x))
predict = predict.data.numpy()
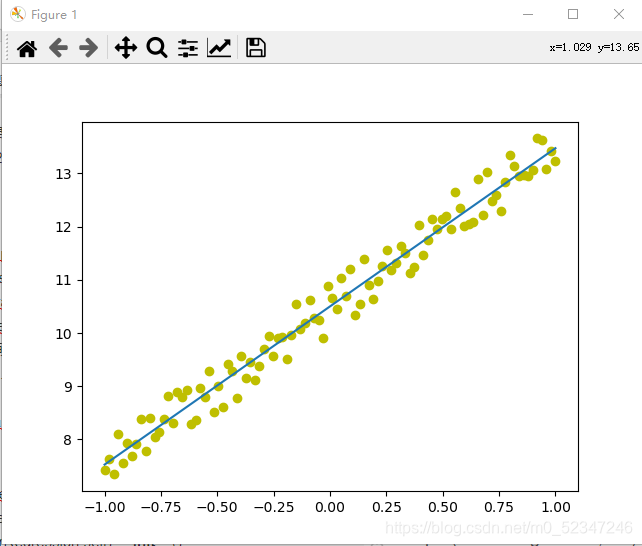
plt.plot(x.numpy(), y.numpy(), 'yo', label='Original Data') #作图
plt.plot(x.numpy(), predict, label='Fitting Line')
plt.show()
损失结果:
3、二分类逻辑回归
import torch
import matplotlib.pyplot as plt #导入相应的包
n_data= torch.ones(100,2) #生成100行,2列的全为1的矩阵
x0 = torch.normal(2*n_data,1) #利用100行两列的全1矩阵产生一个正态分布的矩阵均值和方差分别是(2*n_data,1)
y0 = torch.zeros(100) #给x0定标签,其标签为0
x1 = torch.normal(-2*n_data,1) #利用100行两列的全1矩阵产生一个正态分布的矩阵均值和方差分别是(-2*n_data,1)
y1 = torch.ones(100) #给x1定标签,其标签为1
x= torch.cat((x0,x1),0).type(torch.FloatTensor)
y = torch.cat((y0,y1),0).type(torch.FloatTensor) #cat方法是将两个数据样本聚合在一起(x0,x1),0这个属性是在行维度进行聚合,1是列维度聚合
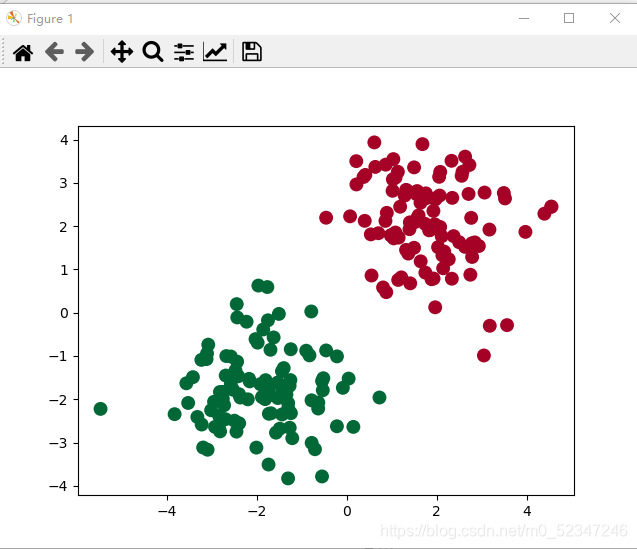
#作出相应的数据图
plt.scatter(x.data.numpy()[:, 0],x.data.numpy()[:,1],c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.show() #此处后面需要注释掉
class LogisticRegression(nn.Module): #定义模型
def __init__(self): #初始化
super(LogisticRegression,self).__init__()
self.lr = nn.Linear(2,1) #相当于通过线性变换y=x*T(A)+b可以得到对应的各个系数
self.sm = nn.Sigmoid() #相当于通过激活函数Sigmoid的变换
def forward(self,x): #前向传播
x = self.lr(x)
x = self.sm(x)
return x
model = LogisticRegression()
criterion = torch.nn.BCELoss() #BCE损失函数
optimizer = torch.optim.SGD(model.parameters(),lr = 1e-2,momentum=0.9)
#优化器(随机梯度下降法),学习率
loss_list=[]
for epoch in range(100): #迭代,1000次
inputs = Variable(x)
target = Variable(y)
out = model(x)
out1 = out.squeeze(-1)
loss = criterion(out1,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
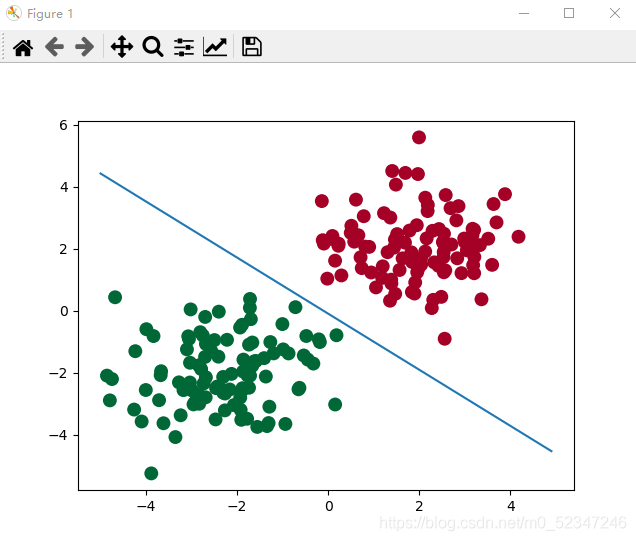
mask = out.ge(0.5).float #以0.5为阈值进行分类
#作图
w0, w1 = model.lr.weight[0]
w0 = float(w0.item())
w1 = float(w1.item())
b = float(model.lr.bias.item())
plot_x = np.arange(-5, 5, 0.1)
plot_y = (-w0 * plot_x - b) / w1
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.plot(plot_x, plot_y)
plt.show()
注意:第三个二分类逻辑回归直接粘贴我的代码可能会报错。记得加上相应的库就行。
完整的库是:
import torch
import matplotlib.pyplot as plt #作图
from torch.autograd import Variable #变量
import torch.nn as nn
import numpy as np















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









