









 本文介绍了一个使用BP神经网络进行分类任务的实际案例。通过定义激活函数、前向传播、损失函数及两种误差逆传播算法(标准BP与累计BP),实现了对好瓜与坏瓜的数据分类。在训练过程中观察到累计BP算法的误差下降较慢的现象。
本文介绍了一个使用BP神经网络进行分类任务的实际案例。通过定义激活函数、前向传播、损失函数及两种误差逆传播算法(标准BP与累计BP),实现了对好瓜与坏瓜的数据分类。在训练过程中观察到累计BP算法的误差下降较慢的现象。
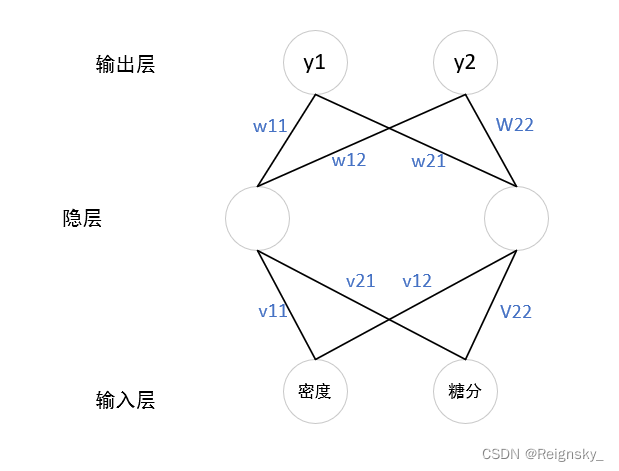
算法流程:

python代码实现:
import numpy as np
np.set_printoptions(suppress=True) #取消使用科学计数法
def Sigmoid(x): # 激活函数
function = 1.0 / (1.0 + np.exp(-x))
return function
def forward(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4): # 前向传播
y_hat1 = []
y_hat2 = []
for i in range(X.shape[0]): # X.shape表示有几个样本
x = X[i]
# 隐层的两个神经元的输入值
h1 = np.dot(x, v1)
h2 = np.dot(x, v2)
# 隐层的两个神经元的输出值 也就是 输出层的输入
h1_out = Sigmoid(h1 - yz1)
h2_out = Sigmoid(h2 - yz2)
h_out = np.array([h1_out, h2_out])
# 输出层的两个神经元的输出层
out1 = np.dot(h_out, w1)
out2 = np.dot(h_out, w2)
# 预测值的输出
y_hat1.append(Sigmoid(out1 - yz3))
y_hat2.append(Sigmoid(out2 - yz4))
Y_hat = np.array(list(zip(y_hat1, y_hat2))) # 训练集对应的预测值
return Y_hat
def loss(y, y_hat): # 误差函数
out = np.sum((y - y_hat) ** 2) / 2 * y.shape[0] # y.shape[0]指神经元的个数
return out
# 误差逆传播(标准bp算法)
def BackPropagation(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4, Y, learnrate):
Y_hat = forward(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4)
Ek_sum = 0
for i in range(X.shape[0]):
x = X[i]
# 隐层的两个神经元的输入值
h1 = np.dot(x, v1)
h2 = np.dot(x, v2)
# 隐层的两个神经元的输出值 也就是 输出层的输入
h1_out = Sigmoid(h1 - yz1)
h2_out = Sigmoid(h2 - yz2)
y1 = Y_hat[i][0]
y2 = Y_hat[i][1]
Ek = loss(Y[i], Y_hat[i])
Ek_sum = Ek_sum + Ek
# 输出层神经元的梯度项
g1 = y1 * (1 - y1) * (Y[i][0] - y1)
g2 = y2 * (1 - y2) * (Y[i][1] - y2)
# 隐层神经元的梯度项
e1 = h1_out * (1 - h1_out) * (w1[0] * g1 + w1[1] * g2)
e2 = h2_out * (1 - h2_out) * (w2[0] * g1 + w2[1] * g2)
# 更新连接权和阈值
v1[0] = v1[0] + (learnrate * e1 * x[0])
v1[1] = v1[1] + (learnrate * e2 * x[0])
v2[0] = v2[0] + (learnrate * e1 * x[1])
v2[1] = v2[1] + (learnrate * e2 * x[1])
w1[0] = w1[0] + (learnrate * g1 * h1_out)
w1[1] = w1[1] + (learnrate * g2 * h1_out)
w2[0] = w2[0] + (learnrate * g1 * h2_out)
w2[1] = w2[1] + (learnrate * g2 * h2_out)
yz1 = yz1 + (-learnrate * e1)
yz2 = yz2 + (-learnrate * e2)
yz3 = yz3 + (-learnrate * g1)
yz4 = yz4 + (-learnrate * g2)
print(Ek_sum)
return v1, v2, w1, w2, yz1, yz2, yz3, yz4
# 误差逆传播(累计bp算法)
def BackPropagation_accumulate(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4, Y, learnrate):
Y_hat = forward(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4)
Ek_sum = 0
g1 = []
g2 = []
e1 = []
e2 = []
for i in range(X.shape[0]):
x = X[i]
# 隐层的两个神经元的输入值
h1 = np.dot(x, v1)
h2 = np.dot(x, v2)
# 隐层的两个神经元的输出值 也就是 输出层的输入
h1_out = Sigmoid(h1 - yz1)
h2_out = Sigmoid(h2 - yz2)
y1 = Y_hat[i][0]
y2 = Y_hat[i][1]
Ek = loss(Y[i], Y_hat[i])
Ek_sum = Ek_sum + Ek
# 输出层神经元的梯度项
g1.append(y1 * (1 - y1) * (Y[i][0] - y1))
g2.append(y2 * (1 - y2) * (Y[i][1] - y2))
# 隐层神经元的梯度项
e1.append(h1_out * (1 - h1_out) * (w1[0] * g1[i] + w1[1] * g2[i]))
e2.append(h2_out * (1 - h2_out) * (w2[0] * g1[i] + w2[1] * g2[i]))
# 更新连接权和阈值
g1_aver = np.mean(g1)
g2_aver = np.mean(g2)
e1_aver = np.mean(e1)
e2_aver = np.mean(e2)
v1[0] = v1[0] + (learnrate * e1_aver * x[0])
v1[1] = v1[1] + (learnrate * e2_aver * x[0])
v2[0] = v2[0] + (learnrate * e1_aver * x[1])
v2[1] = v2[1] + (learnrate * e2_aver * x[1])
w1[0] = w1[0] + (learnrate * g1_aver * h1_out)
w1[1] = w1[1] + (learnrate * g2_aver * h1_out)
w2[0] = w2[0] + (learnrate * g1_aver * h2_out)
w2[1] = w2[1] + (learnrate * g2_aver * h2_out)
yz1 = yz1 + (-learnrate * e1_aver)
yz2 = yz2 + (-learnrate * e2_aver)
yz3 = yz3 + (-learnrate * g1_aver)
yz4 = yz4 + (-learnrate * g2_aver)
print(Ek_sum)
return v1, v2, w1, w2, yz1, yz2, yz3, yz4
# ---------------------main-------------------
# 对于输出层神经元,假设好瓜应为10,坏瓜为01
# 在(0,1)范围内随机初始化网络中所有连接权和阈值
v11, v12, v21, v22, w11, w12, w21, w22, yz1, yz2, yz3, yz4 = np.random.random(12)
v1 = np.array([v11, v12])
v2 = np.array([v21, v22])
w1 = np.array([w11, w12])
w2 = np.array([w21, w22])
# 学习率
learnrate = 0.1
p = [0.634, 0.608, 0.556, 0.403, 0.481, 0.437,
0.666, 0.639, 0.657, 0.593,0.719] # 密度
sug = [0.264, 0.318, 0.215, 0.237, 0.149, 0.211,
0.091, 0.161, 0.198, 0.042,0.103] # 糖分
Y = np.array([[1, 0], [1, 0], [1, 0], [1, 0], [1, 0], [1, 0],
[0, 1], [0, 1], [0, 1], [0, 1], [0, 1]]) # y值
X = np.array(list(zip(p, sug)))
a = forward(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4) # 初始的权值和阈值 算出来的预测值
print(a)
for i in range(10000):
v1, v2, w1, w2, yz1, yz2, yz3, yz4 = BackPropagation_accumulate(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4, Y, learnrate) # 训练
b = forward(X, v1, v2, w1, w2, yz1, yz2, yz3, yz4) # 训练的权值和阈值 算出来的预测值
print(b)本次实验中,使用一个隐层,且一个隐层只包含2个神经元,在输出层我使用【0,1】表示坏瓜,【1,0】表示好瓜
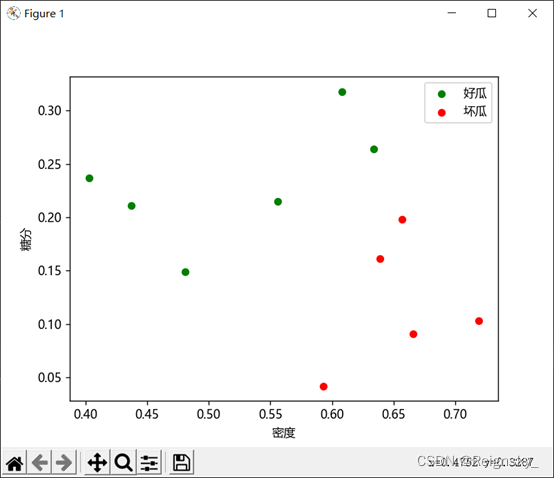
训练集:
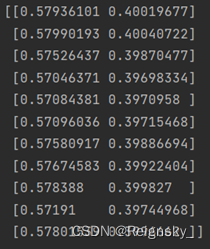
训练之前根据初始的权值和阈值 算出来的预测值:
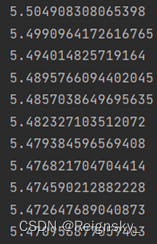
训练时:误差函数不断下降
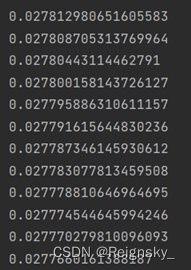
训练10000次后 输出的预测值: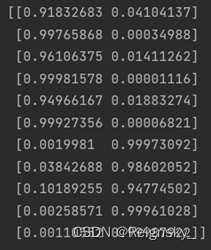
累计BP:误差函数下降的很慢(我认为可能是分类编码的原因)
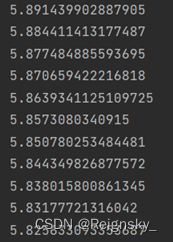
训练了一万次:
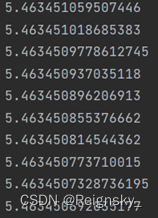
下降的非常慢,以我目前的水平还不知道为啥。

















 6354
6354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









