






前言
通过使用积分图技术,可以让原本繁琐的卷积运算被转化成了几个积分图像数值的直接相加或相减操作,这一转变有效加速了计算过程,提升了运算效率。
一、计算积分图像
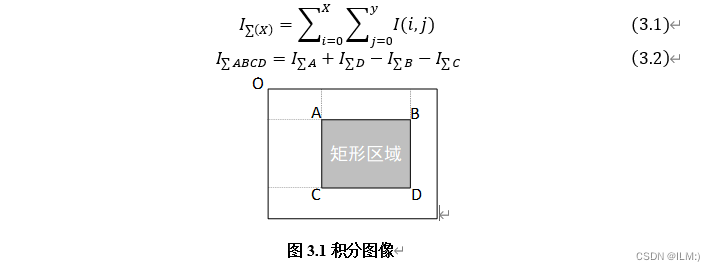
在灰度图像下,设像素X位置位于(x, y),定义该点处的累积灰度图像为:从图像原点延伸到该点(x, y)所界定的矩形区域内部所有像素灰度值的累计总和,如式3.1所示。参照图3.1,对于任意选定的矩形区域ABCD而言,其对应的积分图像可被看作是该矩形四个顶点各自所属区域积分值的直接算术叠加,如式3.2。
二、CUDA优化
1.基于Blelloch扫描前缀加法和的积分图像计算优化
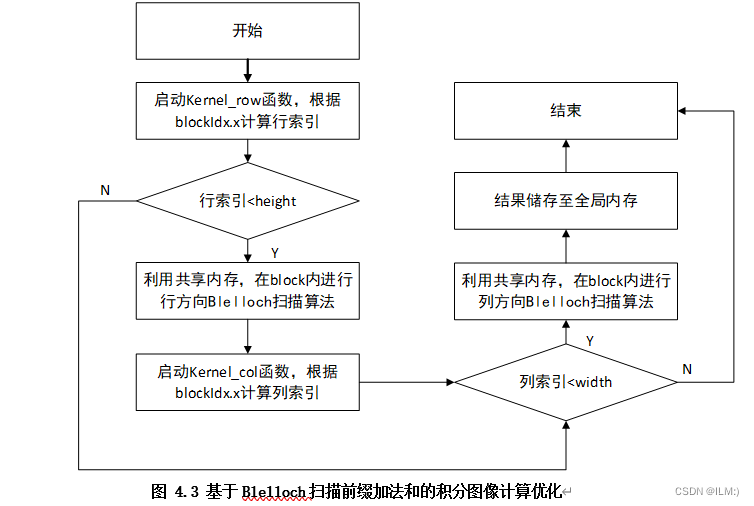
代码如下(示例):
__global__ void gScanRow(unsigned char* src, int* dst, int w1, int h1, int p1, int p2, int n)
{
extern __shared__ int temp[];
int bid = blockIdx.x;
int tdx = threadIdx.x;
int offset = 1;
int tdx2 = tdx + tdx;
int tdx2p = tdx2 + 1;
int systart = bid * p1;
int dystart = (bid + 1) * p2;
temp[tdx2] = tdx2 < w1 ? (int)src[systart + tdx2] : 0;
temp[tdx2p] = tdx2p < w1 ? (int)src[systart + tdx2p] : 0;
for (int d = n >> 1; d > 0; d >>= 1)
{
__syncthreads();
if (tdx < d)
{
int ai = offset * tdx2p - 1;
int bi = offset * (tdx2p + 1) - 1;
temp[bi] += temp[ai];
}
offset <<= 1;
}
if (tdx == 0)
{
temp[n - 1] = 0;
}
for (int d = 1; d < n; d <<= 1)
{
offset >>= 1;
__syncthreads();
if (tdx < d)
{
int ai = offset * tdx2p - 1;
int bi = offset * (tdx2p + 1) - 1;
int t = temp[ai];
temp[ai] = temp[bi];
temp[bi] += t;
}
}
__syncthreads();
if (tdx2 < w1)
{
dst[dystart + tdx2] = temp[tdx2];
}
if (tdx2p < w1)
{
dst[dystart + tdx2p] = temp[tdx2p];
}
if (tdx2 == w1 - 1 || tdx2p == w1 - 1)
{
dst[dystart + w1] = temp[w1 - 1] + (int)src[systart + w1 - 1];
}
}
__global__ void gScanCol(int* data, int w, int h, int p, int n)
{
extern __shared__ int temp[];
int bid = blockIdx.x;
int tdx = threadIdx.x;
int offset = 1;
int tdx2 = tdx + tdx;
int tdx2p = tdx2 + 1;
int xo = bid + 1;
temp[tdx2] = tdx2 < h ? data[tdx2p * p + xo] : 0;
temp[tdx2p] = tdx2p < h ? data[(tdx2p + 1) * p + xo] : 0;
for (int d = n >> 1; d > 0; d >>= 1)
{
__syncthreads();
if (tdx < d)
{
int ai = offset * tdx2p - 1;
int bi = offset * (tdx2p + 1) - 1;
temp[bi] += temp[ai];
}
offset <<= 1;
}
if (tdx == 0)
{
temp[n - 1] = 0;
}
for (int d = 1; d < n; d <<= 1)
{
offset >>= 1;
__syncthreads();
if (tdx < d)
{
int ai = offset * tdx2p - 1;
int bi = offset * (tdx2p + 1) - 1;
int t = temp[ai];
temp[ai] = temp[bi];
temp[bi] += t;
}
}
__syncthreads();
if (tdx2 < h)
{
data[tdx2 * p + xo] = temp[tdx2];
}
if (tdx2p < h)
{
data[tdx2p * p + xo] = temp[tdx2p];
}
if (tdx2 == h - 1 || tdx2p == h - 1)
{
data[h * p + xo] += temp[h - 1];
}
}
2.基于分块前缀和的积分图像计算优化
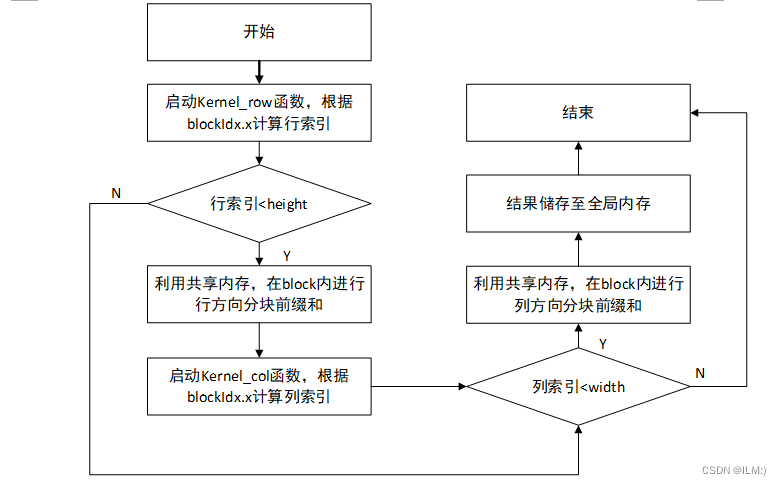
其中的分块前缀和:
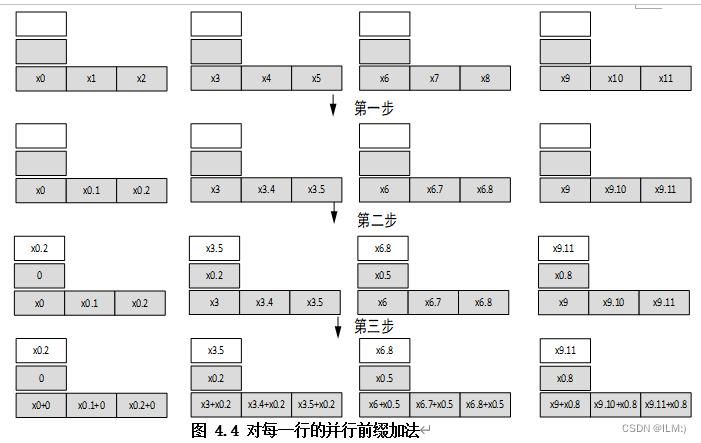
以一行的处理为例(一行对应一个线程块),在分块前缀和算法中一行会被分成多个子段,如图4.4,此过程可详细划分为三个关键阶段:
(1)各个线程负责对其分配的子段执行前缀和计算,并将计算结果临时存储在L2个寄存器里;
(2)各个线程将会把它们各自计算出的部分前缀和数据,存储到共用的关系内存中;
(3)各个线程将步骤(1)中自己计算出的结果与步骤(2)中所有编号小于当前线程号的子段和累加起来。
在图4.4中,L_1为12(代表列数),L_2为3;白色矩形代表共享内存们,它们是多线程间协作与数据交换的中枢地带,灰色矩形代表线程的专属寄存器,构成线程计算过程中的基本存储单元; x0.2代表x0+x1+x2;x0.8代表x0到x8的累加和;在各线程将其负责的子段的输入数据读入寄存器后,执行按照上文所述的三个步骤后,可得最终的前缀加法结果。在步骤(1)和(3)操作期间,线程展现出完全的独立性,仅在步骤(2)中涉及线程间必要的数据交换,这一调整显著减少了数据依赖性,优化了内存的利用效率,从而大幅度提升了整体运算速度。
代码如下(示例):
__global__ void integral_image_x(int* dst, const unsigned char* src, int row, int col)
{
int y = blockIdx.x; // row
int x = threadIdx.x * L2;
extern __shared__ int sharedMem[];
int s0 = 0;
int startX = x;
int endX = (((startX + L2) < (col)) ? (startX + L2) : (col));
int data[L2];
//读数据
for (int i = startX; i < endX; ++i) {
data[i-x] = src[y * col + i];
}
//计算块内前缀和
for (int i = 1; i < L2; i++)
{
data[i] += data[i - 1];
}
sharedMem[threadIdx.x] = data[L2-1]; // 存储到共享内存
__syncthreads();
for (int i = 0; i < threadIdx.x; i++)
{
s0 += sharedMem[i];
}
for (int i = 0; i < L2; i++)
{
data[i] += s0;
}
//写结果
for (int i = startX; i < endX; ++i) {
dst[(y + 1) * (col + 1) + i + 1] = data[i - x];
}
//if (threadIdx.x == 0)dst[index - 1] = 0;
}
__global__ void integral_image_y(int* dst, int row, int col)
{
int x = blockIdx.x; // block对应列
int y = threadIdx.x * L2;
extern __shared__ int sharedMem[];
int s0 = 0;
int startY = y;
int endY = (((startY + L2) < (row)) ? (startY + L2) : (row));
int data[L2];
//读数据
for (int i = startY; i < endY; ++i) {
data[i - y] = dst[(i + 1) * (col+1) + x + 1];
}
for (int i = 1; i < L2; i++)
{
data[i] += data[i - 1];
}
sharedMem[threadIdx.x] = data[L2 - 1]; // 存储到共享内存
__syncthreads();
for (int i = 0; i < threadIdx.x; i++)
{
s0 += sharedMem[i];
}
for (int i = 0; i < L2; i++)
{
data[i] += s0;
}
//写结果
for (int i = startY; i < endY; ++i) {
dst[(i + 1) * (col + 1) + x + 1] = data[i - y];
}
}
该处使用的url网络请求的数据。
时间测试
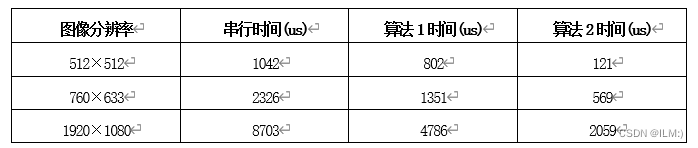 如表所示,算法2效果较好,加速比达4-9倍。
如表所示,算法2效果较好,加速比达4-9倍。
总结
对积分图像计算进行了CUDA优化,实现了一定的加速。















 2395
2395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









