









Lab Week 17 实验报告
实验内容:虚拟存储管理
编写一个C程序模拟实现课件 Lecture24 中的请求页面置换算法,包括FIFO、LRU stack implementation 和 Second chance/CLOCK 置换策略。
- 固定一个页帧 (frame) 数;
- 输入一批随机页面引用序列,计算各个置换策略的平均缺页数。
- 当页帧数增加或减少时,观察上述统计结果的变化情况
- 思考:如何在随机页面引用序列中模拟局部性
I.请求页面置换算法
在操作系统中,通常使用虚拟内存来对内存进行管理,使计算机能够弥补物理内存短缺,暂时将数据从随机存取存储器(RAM)传输到磁盘存储。将内存块映射到磁盘文件使计算机能够将辅助内存视为主内存。虚拟内存使用硬件和软件进行操作。当应用程序正在使用时,来自该程序的数据将使用RAM存储在物理地址中。内存管理单元(MMU)将地址映射到 RAM,并自动转换地址。例如,MMU可以将逻辑地址空间映射到相应的物理地址。
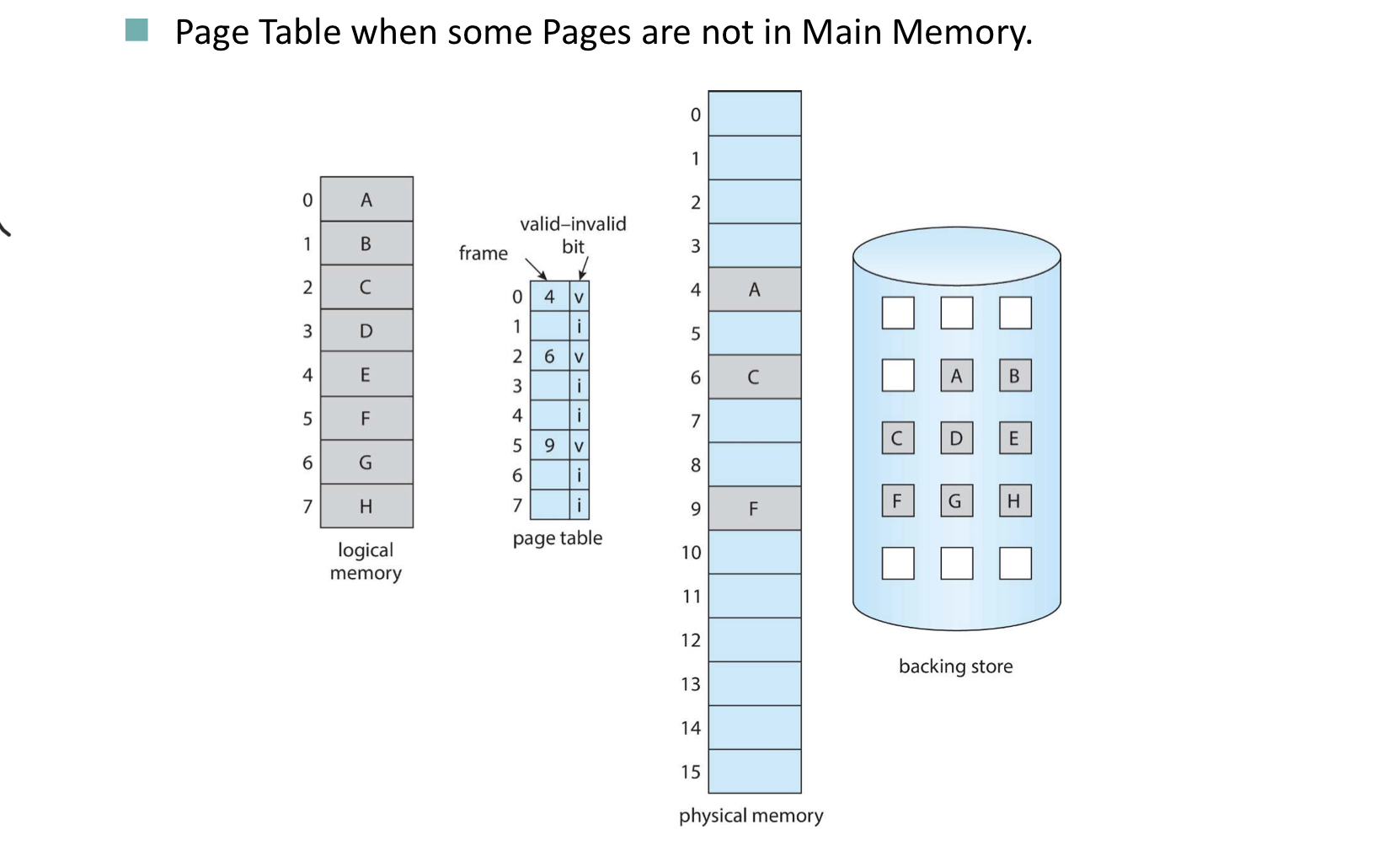
物理地址空间通常被分为多个固定大小的块叫做页框/页帧(frames),逻辑地址空间被分为与页框相同大小的块,称为页(pages),当请求的页不在内存中时,会产生缺页中断(page fault),需要把他们从外部存储设备(硬盘、磁盘等)调入内存,但内存空间不足以存储这些页,这就需要从内存中调出页(page out)

系统为每个进程在内存中建立一张页表,它记录页面在内存中对应的物理块号,页表项第一部分是页号,可以通过虚拟地址的第一部分来对应,第二部分是物理块号,而虚拟地址的第二部分是在该物理块里的偏移;通常页表还会有一个valid-invalid (present-absent) bit来表示当前对应的页是否在内存中,在内存中为valid,不在内存中为invalid,如果不在内存中,则需要到外部存储设备中找;
1.FIFO置换策略
FIFO页面置换算法优先淘汰最早进入内存的页面,即在内存中驻留时间最久的页面;
实现代码:
#include<stdio.h>
#include<stdlib.h>
#define STRING_SIZE 30
int frame_num, ref_num;
//判断引用地址addr是否在内存frame中
int find_exist(int* frame, int n, int addr){
for(int i = 0; i < n; i++){
if(frame[i] == addr)
return i;
}
return -1;
}
// 打印页框
void Print_Frame(int* frame, int n)
{
printf("\t\t");
for(int i = 0; i < n; i++){
printf("%d|", frame[i]);
}
printf("\n");
}
//更新在滞留在fifo queue中的时间
void update_time(int* time_cnt, int size, int set_zero_idx){
for(int i=0; i < size; i++){
time_cnt[i]++;
}
if(set_zero_idx != -1){ //如果set_zero_idx不为-1,则将set_zero_idx对应的页框的驻留时间清0
time_cnt[set_zero_idx] = 0;//用在替换后的页框上
}
}
void fifo(int *req_str){
int addr, hit = 0, miss = 0, iter = 0, in_queue_num = 0;
int* fifo_queue;
int* time_cnt; //计算滞留在fifo queue中的时间
fifo_queue = (int*)malloc(sizeof(int)*frame_num);
time_cnt = (int*)malloc(sizeof(int)*frame_num);
while(iter < ref_num){
addr = req_str[iter];
// printf("\tReferencing address: %d\n", addr);
iter++;
if(in_queue_num < frame_num){
if(find_exist(fifo_queue, in_queue_num, addr) != -1){
hit++;
update_time(time_cnt, in_queue_num, -1);
}
else{
miss++;
fifo_queue[in_queue_num++] = addr;
update_time(time_cnt, in_queue_num, in_queue_num);
}
}
else{
if(find_exist(fifo_queue, in_queue_num, addr) != -1){
hit++;
update_time(time_cnt, in_queue_num, -1);
}
else{
miss++;
int max_time = -9999;
int idx = -1;
for(int i = 0; i < in_queue_num; i++){//找到驻留时间最长的页框
if(time_cnt[i] > max_time){
max_time = time_cnt[i];
idx = i;
}
}
fifo_queue[idx] = addr;
update_time(time_cnt, in_queue_num, idx);
}
}
Print_Frame(fifo_queue, in_queue_num);
}
printf("\tnumber of [FIFO] page faults %d\n", miss);
}
int main(){
int ref_str[STRING_SIZE];
//printf("----Belady's Anomaly Test----\n");
// printf("Enter frame number:");
// scanf("%d", &frame_num);
printf("Enter Reference string size: ");
scanf("%d", &ref_num);
printf("Now, Enter Reference string: ");
for(int i = 0;i < ref_num ;i++){
scanf("%d", &ref_str[i]);
}
for(int i=1;i<=15;i++){
frame_num = i;
printf("Number of frames: %d\n", frame_num);
fifo(ref_str);
}
// fifo(ref_str);
}
代码说明:
实现FIFO调度主要在于记录页框在内存中驻留的时间,每当需要置换页面的时候,首选驻留时间最长的页面,在代码中定义了void update_time(int* time_cnt, int size, int set_zero_idx)函数,用于更新页框在内存中驻留的时间,相关的操作可见注释;
实验结果:
页框数 :3
Reference string: 7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 7 0 1


缺页数为15;
现在使用随机数,在固定页帧数的情况下,对缺页数进行测试:
固定帧数 = 3

从结果可以看到,在固定页帧数为3的前提下,缺页数随着引用序列长度的增加,缺页数随之变化,引用序列长度为6时,缺页数为5,引用序列长度为7时,缺页数为4,但总的趋势是缺页数越来越多;
固定帧数 = 4

在固定页帧数为4的前提下,也有相同的现象,总的趋势是缺页数越来越多;
测试Belady’s Anomaly
在相同的引用序列的前提下,使用不同的页框数,观察Belady’s Anomaly现象:
Reference string: 1 2 3 4 1 2 5 1 2 3 4 5
页框数从1~15:

可以发现,在页框数为3和4的时候出现了Belady’s Anomaly现象,在页框数为4的时候的缺页数为10,页框数为3时缺页数为9,这里的缺页数不降反升;
2.LRU stack implementation 置换策略
在LRU算法的实现中,采用了双向链表来存储引用页号,哈希表来存储链表索引,实现基本的思想是,对于每个引用页号,如果当前链表结点个数未满(未到限定的页帧数),则向链表头部插入该页号的结点,若引用页号已在链表中(通过哈希表查找),则将该页号的结点移动到链表头部,如果链表已满,则分成两种情况,如果引用页号在链表中,则将该页号的结点移动到链表头部,反之,则将链表尾部结点删除,将该页号的结点插入到链表头部。
实现代码:
#include<stdio.h>
#include<stdlib.h>
#include <time.h>
#define STRING_SIZE 30
int frame_num, ref_num;
struct node
{
int key;
int value;
struct node* prev;
struct node* next;
};
typedef struct DLinkList
{
struct node* head;
struct node* tail;
int size;
}DLinkList;
typedef struct HashMap
{
struct node** map;
int size;
}HashMap;
// 创建链表结点
struct node* createnode(int value){
struct node* newnode = (struct node*)malloc(sizeof(struct node));
newnode->value = value;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
//创建双向链表
void createDlinkList(DLinkList *L){
L->head = createnode(-1);
L->tail = createnode(-1);
L->head->next = L->tail;
L->tail->prev = L->head;
L->size = 0;
}
//根据页框号addr获取哈希值
struct node* getMapval(struct HashMap* HashMap, int addr){
struct node* res = NULL;
for(int i = 0; i < HashMap->size; i++){
if(HashMap->map[i] == NULL) continue;
if(HashMap->map[i]->value == addr){
res = HashMap->map[i];
break;
}
}
return res;
}
//将链表结点插入哈希表
void putHashval(struct HashMap* HashMap, struct node* newnode){
for(int i = 0; i < frame_num; i++){
if(HashMap->map[i] == NULL){
HashMap->map[i] = newnode;
break;
}
}
HashMap->size++;
}
//移除哈希表中的结点
void removeHashval(struct HashMap* HashMap, struct node* node){
for(int i = 0; i < HashMap->size; i++){
if(HashMap->map[i] == node){
HashMap->map[i] = NULL;
break;
}
}
HashMap->size--;
}
//双向链表头插法
void insert_head(DLinkList *L, struct node* newnode){
newnode->next = L->head->next;
L->head->next->prev = newnode;
L->head->next = newnode;
newnode->prev = L->head;
L->size++;
}
//双向链表中移除结点
void remove_node(struct node* node){
node->prev->next = node->next;
node->next->prev = node->prev;
}
//双向链表中将结点移动到头部
void move_to_head(DLinkList *L, struct node* node){
remove_node(node);
L->size--;
insert_head(L, node);
}
//打印出双向链表中结点的值
void print(DLinkList *L){
struct node* cur = L->head->next;
for(int i=0;i<L->size;i++){
printf("%d|", cur->value);
cur = cur->next;
}
printf("\n");
}
//移除链表最后一个结点(tail前一个结点)
void removetail(DLinkList *L){
if(L->head->next == L->tail)return;
struct node* temp = L->tail->prev;
remove_node(temp);
free(temp);
L->size--;
}
// LRU Algoritum Stack Implementation
void lru(int *ref_str){
//初始化
int i, addr, miss = 0;
struct HashMap* HashMap = malloc(sizeof(HashMap));
struct DLinkList *L = malloc(sizeof(DLinkList));
L->head = createnode(-1); //通过两个dummy结点:head和tail来管理双向链表
L->tail = createnode(-1);
L->head->next = L->tail;
L->tail->prev = L->head;
L->size = 0;
HashMap->map = (struct node**)malloc(sizeof(struct node*) * frame_num);
HashMap->size = 0;
//循环获取页面引用序列
for(i = 0; i < ref_num; i++){
addr = ref_str[i];
printf("Referencing addr: %d\n", addr);
struct node* curnode = getMapval(HashMap, addr); //从哈希表中取得addr对应的结点
if(curnode){ //如果结点在链表中,将该结点移动到头部
printf("addr: %d is in list\n", curnode->value);
move_to_head(L, curnode);
}
else{ //如果结点不在链表中,考虑插入该结点
miss++;
struct node* newnode = createnode(addr);
if(L->size < frame_num){
insert_head(L, newnode);
putHashval(HashMap, newnode);
}
else{ //如果结点不在链表且空间不足,移除链表尾部的结点,将新结点插入到头部
remove_node(L->tail);
removeHashval(HashMap, L->tail);
insert_head(L, newnode);
putHashval(HashMap, newnode);
}
}
print(L);
}
//释放哈希表和链表结点
free(HashMap->map);
for(i = 0; i < L->size; i++){
struct node* cur = L->head->next;
free(L->head);
L->head = cur;
cur = cur->next;
}
printf("\tnumber of [LRU] page faults %d\n", miss);
}
int main(){
int ref_str[STRING_SIZE];
printf("Enter frame number:");
scanf("%d", &frame_num);
printf("Enter Reference string size: ");
scanf("%d", &ref_num);
printf("Now, Enter Reference string: ");
for(int i = 0;i < ref_num ;i++){
scanf("%d", &ref_str[i]);
}
lru(ref_str);
}
代码说明:
在LRU的实现中,分别为存储链表结点的哈希表和双向链表本身的插入和删除功能定义了函数,双向链表通过两个dummy结点:head和tail来管理,此外,最近使用过的页帧的结点需要移动到链表的头部,为此也定义了函数move_to_head()来实现,移除尾部结点(最近最少使用的页帧,tail的前一个结点)需要对结点进行free,因此它也另外封装了函数;
实验结果:
Reference string: 4 7 0 7 1 0 1 2 1 2 7 1 2
Reference string size: 13
页框数:5
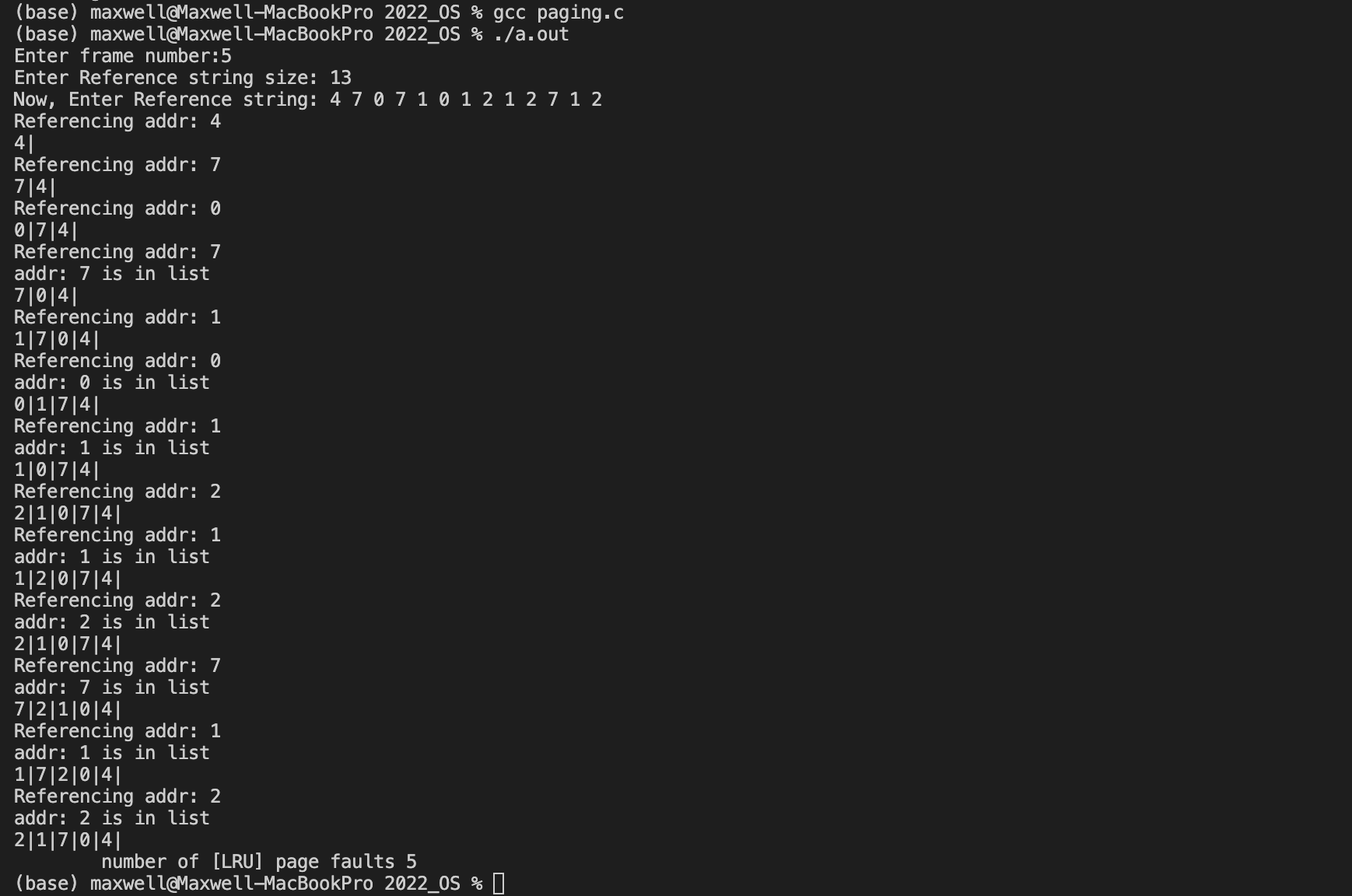
现在使用随机数,在固定页帧数的情况下,对缺页数进行测试:
固定帧数 = 5
引用序列:
1 2 1
2 2 8 6
2 7 1 9 1
7 8 0 1 5 1
9 8 1 2 6 2 9
8 7 2 1 6 2 8 9

随着随机页面引用序列的个数增大,在固定页帧数的情况下,缺页数随之上升;
固定帧数 = 4

减少固定帧数后,同样随着随机页面引用序列的个数增加,缺页数增加;
固定帧数 = 6

增加固定帧数后,同样随着随机页面引用序列的个数增加,缺页数增加;
3.Second chance/CLOCK置换策略
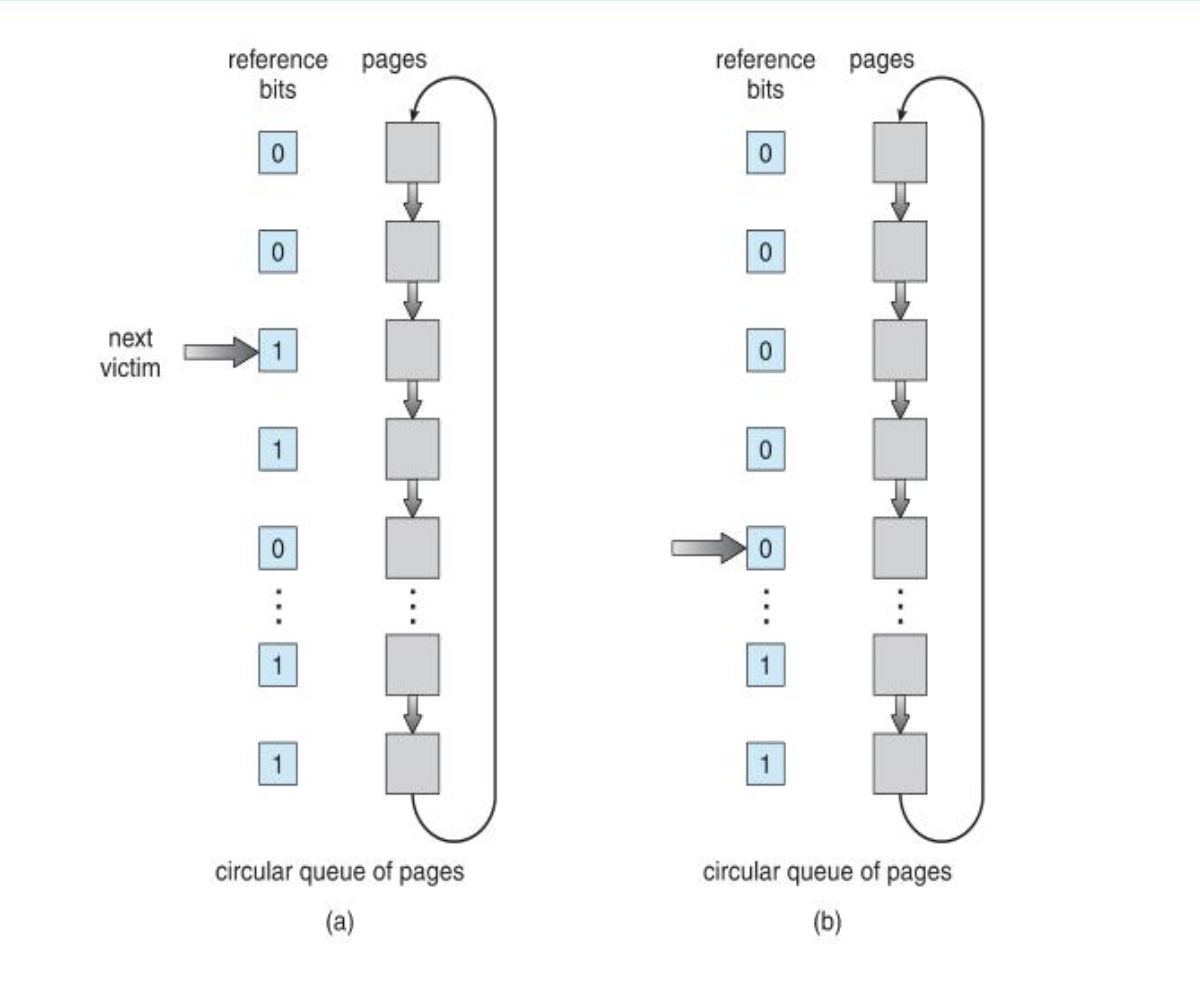
在CLOCK算法中,每帧都关联一个附加位,称为使用位,当某页首次装入主存时,该帧的使用位被设置为1,当改页随后再次被访问到时,其使用位也被置为1,对于置换算法,用于替换的候选帧集合可以视为一个循环缓冲区,并有一个指针与其相关联,当需要进行页帧替换时,通过在循环缓冲区上扫描,当遇到一个使用位为0的帧时就替换改帧,并将使用位置为1,如果遇到使用位为1的帧,则将该位置为0(如果缓冲区中所有帧都为1,那么最后则会选择第一个帧进行替换),替换后指针指向替换帧的下一个位置。
实现代码:
#include<stdio.h>
#include<stdlib.h>
#include <time.h>
#include<string.h>
#define STRING_SIZE 30
#define MAX_REF
int frame_num, ref_num;
struct node
{
int key;
int value;
struct node* prev;
struct node* next;
};
typedef struct DLinkList
{
struct node* head;
struct node* tail;
int size;
}DLinkList;
typedef struct HashMap
{
struct node** map;
int size;
}HashMap;
struct clock_node{
int used;
int page;
};
typedef struct c_clock
{
struct clock_node* clock_list;
int ptr;
int size;
}c_clock;
int random_code(unsigned int code_len)
{
int code_val;
long int modulus = 1;
for (int i = 0; i < code_len; i++) {
modulus = modulus * 10;
}
srand(time(NULL));
while (1) {
code_val = rand() % modulus;
if(code_val > modulus / 10 - 1) {
break;
}
}
return code_val;
}
int find_exist(struct clock_node* clock_node, int n, int addr){
for(int i = 0; i < n; i++){
if(clock_node[i].page == addr)
return i;
}
return -1;
}
//struct clock_node* clock_list
void second_chance(int *ref_str){
int i, addr, cur, miss = 0;
struct c_clock* c_clock = (struct c_clock*)malloc(sizeof(c_clock));
c_clock->clock_list = (struct clock_node*)malloc(sizeof(struct clock_node)*frame_num);
for(i = 0; i < frame_num; i++) c_clock->clock_list[i].page = -1;
c_clock->size = 0;
c_clock->ptr = 0;
for(i = 0; i<ref_num; i++){
int flag = 0;
addr = ref_str[i];
printf("Referencing %d\n", addr);
if(c_clock->size < frame_num){
if(find_exist(c_clock->clock_list, c_clock->size, addr) == -1){
c_clock->clock_list[c_clock->ptr].page = addr;
c_clock->clock_list[c_clock->ptr].used = 1;
//printf("PRE: %d\n",c_clock->ptr);
c_clock->ptr = (c_clock->ptr + 1) % frame_num;
//printf("AFTER: %d\n",c_clock->ptr);
c_clock->size++;
}
}
else{
for(cur = c_clock->ptr;(cur + 1) % frame_num != c_clock->ptr; cur = (cur + 1) % frame_num){
if(c_clock->clock_list[cur].page == addr){
c_clock->clock_list[cur].used = 1;
flag = 1;
break;
}
}
if(!flag){ //CLOCK中没有该addr
miss++;
for(cur = c_clock->ptr;;cur = (cur + 1) % frame_num){
if(!c_clock->clock_list[cur].used){
c_clock->clock_list[cur].page = addr;
c_clock->clock_list[cur].used = 1;
c_clock->ptr = (cur + 1) % frame_num;
break;
}
else{
c_clock->clock_list[cur].used = 0;
}
}
}
}
for(int k = 0; k < c_clock->size; k++){
printf("%d|", c_clock->clock_list[k].page);
}
printf("\n");
}
printf("\tnumber of [CLOCK] page faults %d\n", miss);
}
int main(){
int ref_str[STRING_SIZE];
//printf("----Belady's Anomaly Test----\n");
printf("Enter frame number:");
scanf("%d", &frame_num);
printf("Enter Reference string size: ");
scanf("%d", &ref_num);
printf("Now, Enter Reference string: ");
for(int i = 0;i < ref_num ;i++){
scanf("%d", &ref_str[i]);
}
//随机数测试
// for(int i = 3; i<=20; i++){
// ref_num = i;
// printf("Reference string size: %d\n", ref_num);
// printf("Random generated reference string: ");
// int code = random_code(ref_num);
// for(int j=0;j<ref_num;j++){
// ref_str[j] = code % 10;
// code /= 10;
// }
// for(int j=0;j<ref_num;j++){
// printf("%d", ref_str[j]);
// }
// printf("\n");
// second_chance(ref_str);
// }
second_chance(ref_str);
}
实验结果:
Reference string: 2 3 2 1 5 2 4 5 3 2 5 2

现在使用随机数,在固定页帧数的情况下,对缺页数进行测试:
固定帧数 = 3
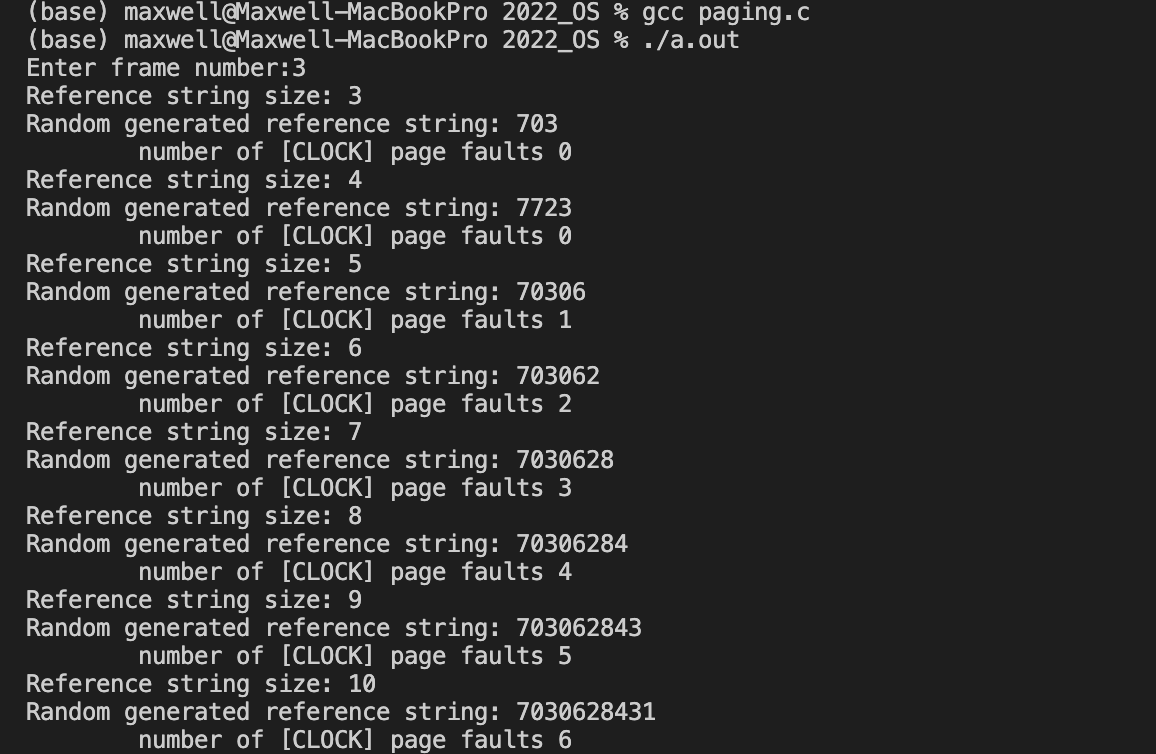
可以看到,随着引用序列长度的增加,缺页数随着增大;
固定帧数 = 4
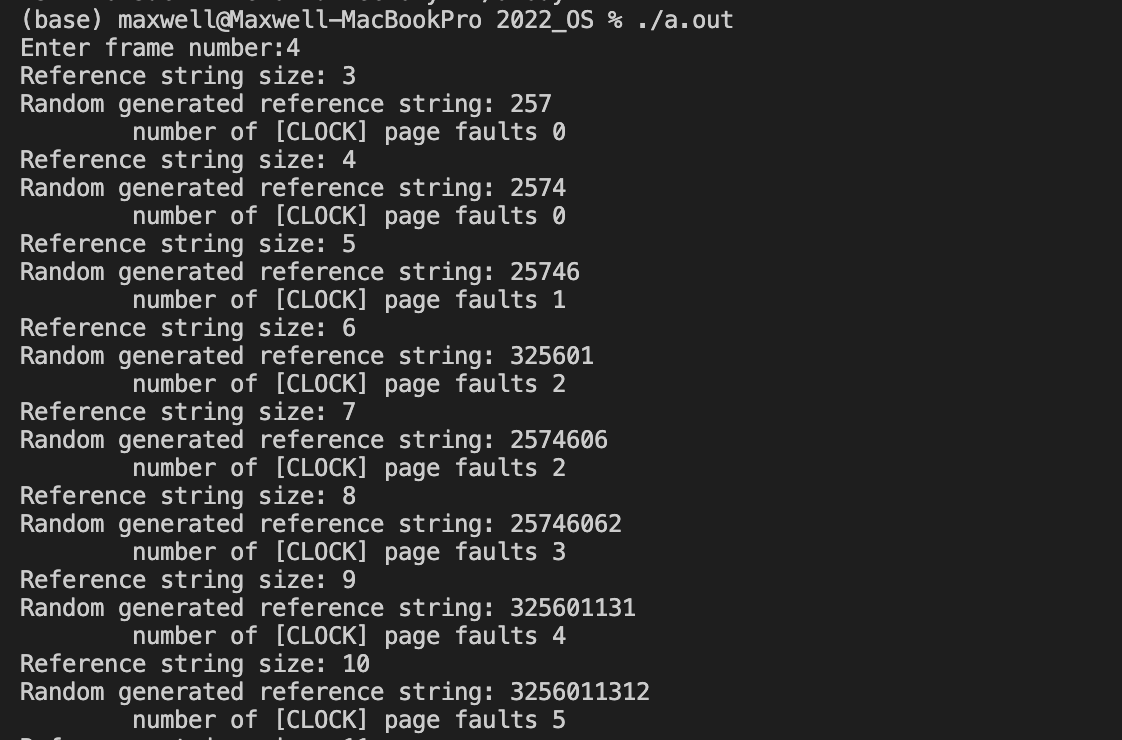
同样的,随着引用序列长度的增加,缺页数随着增大;
现在采用同一页面引用序列,对以上三种不同的页面置换算法的缺页数进行测试:
页框数 :3
Reference string: 7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 7 0 1
【FIFO】
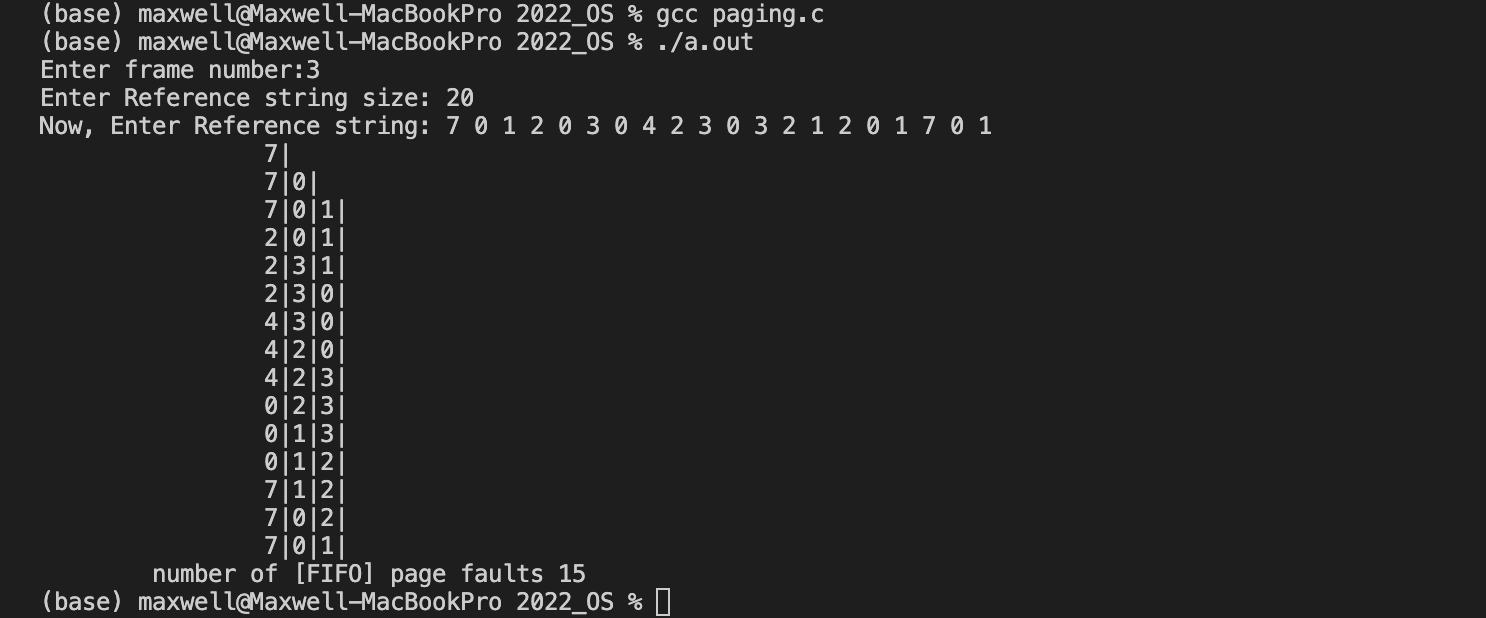
缺页数=15
【LRU】
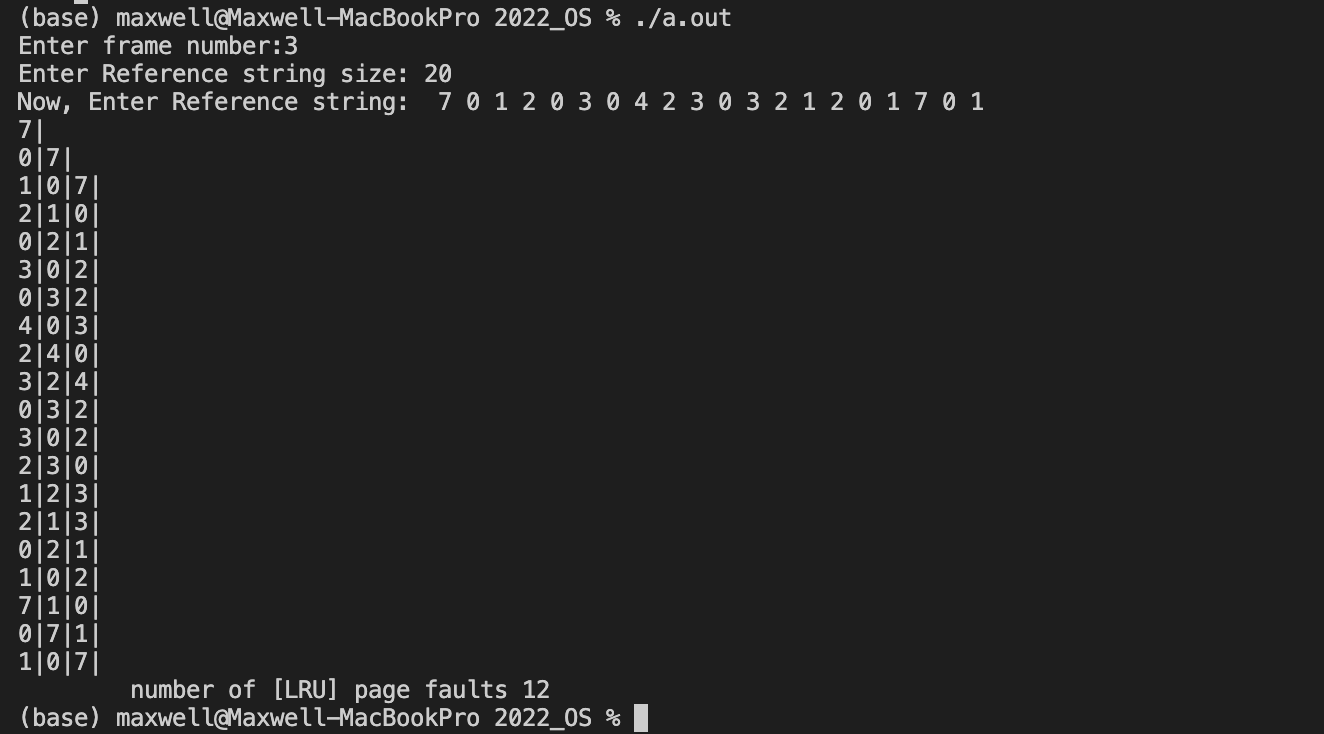
缺页数=12
【CLOCK】

缺页数=11
可以看到,上面三种页面置换算法,CLOCK在当前引用序列下的缺页数最少,其次是LRU,最多是FIFO;
完整代码:
#include<stdio.h>
#include<stdlib.h>
#include <time.h>
#include<string.h>
#define STRING_SIZE 30
#define MAX_REF
int frame_num, ref_num;
struct node
{
int key;
int value;
struct node* prev;
struct node* next;
};
typedef struct DLinkList
{
struct node* head;
struct node* tail;
int size;
}DLinkList;
typedef struct HashMap
{
struct node** map;
int size;
}HashMap;
struct clock_node{
int used;
int page;
};
typedef struct c_clock
{
struct clock_node* clock_list;
int ptr;
int size;
}c_clock;
int random_code(unsigned int code_len)
{
int code_val;
long int modulus = 1;
for (int i = 0; i < code_len; i++) {
modulus = modulus * 10;
}
srand(time(NULL));
while (1) {
code_val = rand() % modulus;
if(code_val > modulus / 10 - 1) {
break;
}
}
return code_val;
}
int find_exist(int* frame, int n, int addr){
for(int i = 0; i < n; i++){
if(frame[i] == addr)
return i;
}
return -1;
}
// 打印页框
void Print_Frame(int* frame, int n)
{
printf("\t\t");
for(int i = 0; i < n; i++){
printf("%d|", frame[i]);
}
printf("\n");
}
void update_time(int* time_cnt, int size, int set_zero_idx){
for(int i=0; i < size; i++){
time_cnt[i]++;
}
if(set_zero_idx != -1){
time_cnt[set_zero_idx] = 0;
}
}
void fifo(int *req_str){
int addr, hit = 0, miss = 0, iter = 0, in_queue_num = 0;
int* fifo_queue;
int* time_cnt; //计算滞留在fifo queue中的时间
fifo_queue = (int*)malloc(sizeof(int)*frame_num);
time_cnt = (int*)malloc(sizeof(int)*frame_num);
while(iter < ref_num){
addr = req_str[iter];
// printf("\tReferencing address: %d\n", addr);
iter++;
if(in_queue_num < frame_num){
if(find_exist(fifo_queue, in_queue_num, addr) != -1){
hit++;
// printf("Hitted addr: %d\n", addr);
Print_Frame(fifo_queue, in_queue_num);
update_time(time_cnt, in_queue_num, -1);
}
else{
miss++;
// printf("missed and load addr: %d\n", addr);
fifo_queue[in_queue_num++] = addr;
// in_queue_num++;
Print_Frame(fifo_queue, in_queue_num);
update_time(time_cnt, in_queue_num, in_queue_num);
//in_queue_num++;
}
}
else{
if(find_exist(fifo_queue, in_queue_num, addr) != -1){
hit++;
// printf("Hitted addr: %d\n", addr);
update_time(time_cnt, in_queue_num, -1);
}
else{
miss++;
int max_time = -9999;
int idx = -1;
for(int i = 0; i < in_queue_num; i++){
if(time_cnt[i] > max_time){
max_time = time_cnt[i];
idx = i;
}
}
// printf("Replaced addr %d to %d\n", fifo_queue[idx], addr);
fifo_queue[idx] = addr;
update_time(time_cnt, in_queue_num, idx);
Print_Frame(fifo_queue, in_queue_num);
}
}
}
printf("\tnumber of [FIFO] page faults %d\n", miss);
free(time_cnt);
free(fifo_queue);
// printf("number of [FIFO] page hit %d\n", hit);
// printf("Frames: ");
// for(int i=0;i<in_queue_num;i++){
// printf("%d|", fifo_queue[i]);
// }
// printf("\n");
}
struct node* createnode(int value){
struct node* newnode = (struct node*)malloc(sizeof(struct node));
newnode->value = value;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
void createDlinkList(DLinkList *L){
L->head = createnode(-1);
L->tail = createnode(-1);
L->head->next = L->tail;
L->tail->prev = L->head;
L->size = 0;
}
struct node* getMapval(struct HashMap* HashMap, int addr){
struct node* res = NULL;
for(int i = 0; i < frame_num; i++){
if(HashMap->map[i] == NULL) continue;
if(HashMap->map[i]->value == addr){
res = HashMap->map[i];
break;
}
}
return res;
}
void putHashval(struct HashMap* HashMap, struct node* newnode){
for(int i = 0; i < frame_num; i++){
if(HashMap->map[i] == NULL){
HashMap->map[i] = newnode;
break;
}
}
HashMap->size++;
}
void removeHashval(struct HashMap* HashMap, struct node* node){
for(int i = 0; i < frame_num; i++){
if(HashMap->map[i] == node){
HashMap->map[i] = NULL;
break;
}
}
HashMap->size--;
}
void insert_head(DLinkList *L, struct node* newnode){
newnode->next = L->head->next;
L->head->next->prev = newnode;
L->head->next = newnode;
newnode->prev = L->head;
L->size++;
}
void remove_node(struct node* node){
node->prev->next = node->next;
node->next->prev = node->prev;
}
void move_to_head(DLinkList *L, struct node* node){
remove_node(node);
L->size--;
insert_head(L, node);
}
void print(DLinkList *L){
struct node* cur = L->head->next;
for(int i=0;i<L->size;i++){
printf("%d|", cur->value);
cur = cur->next;
}
printf("\n");
}
void removetail(DLinkList *L){
if(L->head->next == L->tail)return;
struct node* temp = L->tail->prev;
remove_node(temp);
free(temp);
L->size--;
}
// LRU Algoritum Stack Implementation
void lru(int *ref_str){
int i, addr, miss = 0;
struct HashMap* HashMap = malloc(sizeof(HashMap));
struct DLinkList *L = malloc(sizeof(DLinkList));
L->head = createnode(-1);
L->tail = createnode(-1);
L->head->next = L->tail;
L->tail->prev = L->head;
L->size = 0;
HashMap->map = (struct node**)malloc(sizeof(struct node*) * frame_num);
HashMap->size = 0;
for(i = 0; i < ref_num; i++){
addr = ref_str[i];
// printf("Referencing addr: %d\n", addr);
struct node* curnode = getMapval(HashMap, addr); //从哈希表中取得addr对应的结点
if(curnode){ //如果结点在链表中,将该结点移动到头部
// printf("addr: %d is in list\n", curnode->value);
move_to_head(L, curnode);
}
else{ //如果结点不在链表中,考虑插入该结点
miss++;
struct node* newnode = createnode(addr);
if(L->size < frame_num){
insert_head(L, newnode);
putHashval(HashMap, newnode);
}
else{ //如果结点不在链表且空间不足
removeHashval(HashMap, L->tail->prev);
removetail(L);
//removetail(L);
insert_head(L, newnode);
putHashval(HashMap, newnode);
}
}
print(L);
}
free(HashMap->map);
for(i = 0; i < L->size; i++){
struct node* cur = L->head->next;
free(L->head);
L->head = cur;
cur = cur->next;
}
printf("\tnumber of [LRU] page faults %d\n", miss);
}
int find_clock_exist(struct clock_node* clock_node, int n, int addr){
for(int i = 0; i < n; i++){
if(clock_node[i].page == addr)
return i;
}
return -1;
}
void second_chance(int *ref_str){
int i, addr, cur, miss = 0;
struct c_clock* c_clock = (struct c_clock*)malloc(sizeof(c_clock));
c_clock->clock_list = (struct clock_node*)malloc(sizeof(struct clock_node)*frame_num);
for(i = 0; i < frame_num; i++) c_clock->clock_list[i].page = -1;
c_clock->size = 0;
c_clock->ptr = 0;
for(i = 0; i<ref_num; i++){
int flag = 0;
addr = ref_str[i];
// printf("Referencing %d\n", addr);
if(c_clock->size < frame_num){
if(find_clock_exist(c_clock->clock_list, c_clock->size, addr) == -1){
c_clock->clock_list[c_clock->ptr].page = addr;
c_clock->clock_list[c_clock->ptr].used = 1;
//printf("PRE: %d\n",c_clock->ptr);
c_clock->ptr = (c_clock->ptr + 1) % frame_num;
//printf("AFTER: %d\n",c_clock->ptr);
c_clock->size++;
}
}
else{
for(cur = c_clock->ptr;(cur + 1) % frame_num != c_clock->ptr; cur = (cur + 1) % frame_num){
if(c_clock->clock_list[cur].page == addr){
c_clock->clock_list[cur].used = 1;
flag = 1;
break;
}
}
if(!flag){ //CLOCK中没有该addr
miss++;
for(cur = c_clock->ptr;;cur = (cur + 1) % frame_num){
if(!c_clock->clock_list[cur].used){
c_clock->clock_list[cur].page = addr;
c_clock->clock_list[cur].used = 1;
c_clock->ptr = (cur + 1) % frame_num;
break;
}
else{
c_clock->clock_list[cur].used = 0;
}
}
}
}
for(int k = 0; k < c_clock->size; k++){
printf("%d|", c_clock->clock_list[k].page);
}
printf("\n");
}
printf("\tnumber of [CLOCK] page faults %d\n", miss);
}
int main(){
int opt;
int ref_str[STRING_SIZE];
//printf("----Belady's Anomaly Test----\n");
printf("Please choose Page Replacement Algorithm: 1:FIFO, 2:LRU, 3:CLOCK\n");
scanf("%d", &opt);
printf("Enter frame number:");
scanf("%d", &frame_num);
printf("Enter Reference string size: ");
scanf("%d", &ref_num);
printf("Now, Enter Reference string: ");
for(int i = 0;i < ref_num ;i++){
scanf("%d", &ref_str[i]);
}
switch (opt)
{
case 1:
fifo(ref_str);
break;
case 2:
lru(ref_str);
break;
case 3:
second_chance(ref_str);
default:
printf("INVALID OPTION!\n");
break;
}
// for(int i = 3; i<=11; i++){
// ref_num = i;
// printf("Reference string size: %d\n", ref_num);
// printf("Random generated reference string: ");
// int code = random_code(ref_num);
// for(int j=0;j<ref_num;j++){
// ref_str[j] = code % 10;
// code /= 10;
// }
// for(int j=0;j<ref_num;j++){
// printf("%d", ref_str[j]);
// }
// printf("\n");
// second_chance(ref_str);
// //lru(ref_str);
// }
// }
}
三种算法用switch-case,OPTION整合,运行效果如下:

- 随机页面引用序列中模拟局部性
在虚拟内存技术中,局部性原理主要表现在两个方面:
1.时间局部性:程序中的某条指令一旦执行,不久后该指令可能再次执行;
2.空间局部性:一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问;
在页面引用序列中,设定在某段时间间隔内,进程要访问的页面集合,即工作集,基于局部性原理,可以用最近访问过的页面来确定工作集;
如上图中的随机引用序列,在一段时间内不断访问的工作集 = {1, 4, 5, 9},以此能够反映进程接下来一段时间很有可能回频繁访问的页面集合,需要注意的是,分配给进程的物理页帧数需要大于工作集大小,否则会频繁缺页;
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









