






一、词法分析部分关于正则表达式的相关知识
1,a(a|b)*a
(1)含义:由a开头和结尾的由a和b构成的所有串的集合
(2)化成NFA:(用thompson算法)

(3)化成DFA:(子集构造法)
①过程

②结果
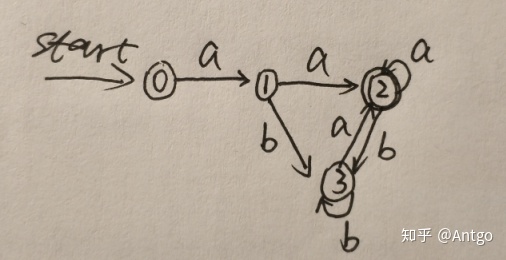
(4)DFA最小化(转态转换图):(hopcroft算法)
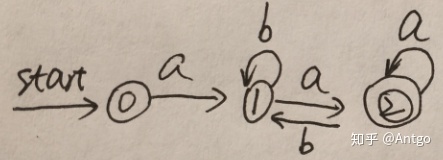
2,((ε|a)b*)*
(1)含义:由a和b构成的所有串的集合
(2)化成NFA:(用thompson算法)
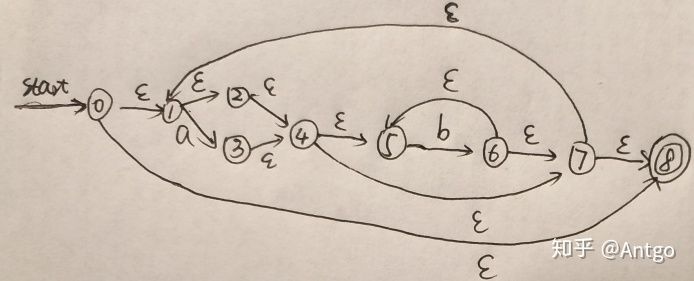
(3)化成DFA:(子集构造法)
①过程

②结果

(4)DFA最小化(转态转换图):(hopcroft算法)
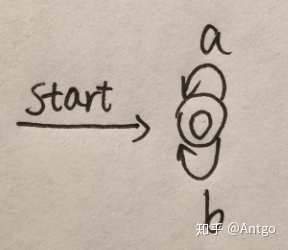
3,(a|b)*a(a|b)(a|b)
(1)含义:倒数第三位为a的由a和b构成的所有串的集合
(2)化成NFA:(用thompson算法)
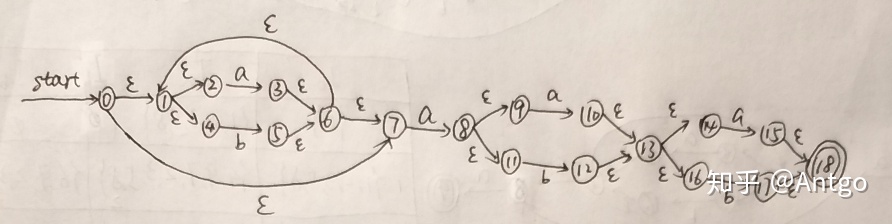
(3)化成DFA:(子集构造法)
①过程

②结果

(4)DFA最小化(转态转换图):(hopcroft算法)
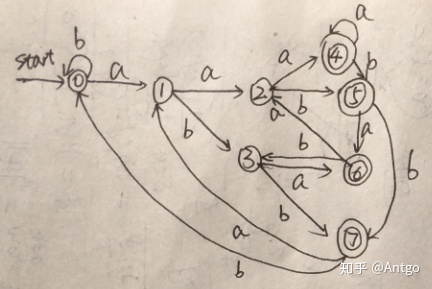
4,a*ba*ba*ba*
含义:仅含3个b的由a和b构成的字符串
二、语法分析部分
1,终结符

2,二义性
二义性文法就是对同一个句子有多个最左推导或多个最右推导的文法。
3,消除左递归
将左递归产生式A->Aα|β替换成非左递归的产生式:
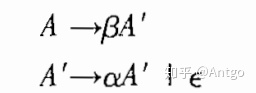
4,提取左公因式
①适用于预测分析技术或自顶向下分析技术的文法
②对产生式A->αβ1|αβ2,提取左公因式后变成

5,自顶向下的语法分析(最左推导过程)
(1)LL(k)文法类:向前看k个输入符号的预测分析器。
(2)由FIRST集和FOLLOW集构造“预测分析表”
(3)FIRST集:FIRST(α)被定义为可从α推导得到的串的首符号的集合。
FOLLOW集:FOLLOW(A)被定义为可能在某些句型中紧跟在A右边的终结符的集合。
(4)计算FOLLOW(A)集合时,运用以下规则不断更新直到不变为止:

(5)LL(1)文法:第一个“L”表示从左向右扫描输入,第二个“L”表示产生最左推导。
①左递归的文法和二义性的文法都不可能是LL(1)的。
②一个文法时LL(1)的,当且仅当文法任意两个不同的产生式A->α|β满足下面的条件:

6,自底向上的语法分析(最右推导过程)
(1)句柄剪枝

句柄总是出现在栈的顶端,句柄右边的串一定只包含终结符号。
(2)LR(k)中的k表示在输入中向前看k个符号,一个二义性文法不可能是LR的
(3)LR(k)中“L”表示对输入进行从左到右的扫描,“R”表示反向构造出一个最右推导序列
(4)LR(0)自动机:规范LR(0)项集族的一组项集提供了构建一个确定有穷自动机的基础。















 1889
1889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









