







将带空字符的NFA转换成DFA(用确定化算法生成状态表)&&根据DFA识别字符串类型
文章目录
前言:这里会用到之前写的文章当中的代码,例如生成的DFA类,是继承于NFA类的,在其之上增加了状态转移表等数据,用于表示DFA
说明一下文件的结构:
Github的源码地址如下https://github.com/Cheesheep/CompilingTheory-Exp2-LexicalAnalysiz
代码文件位于part03文件夹当中

程序入口:
运行createDFA的类,会去到REFIle类当中处理文件,并且在该类当中生成NFA,再继续对NFA进行处理,从而转换成DFA
因此要看懂代码的话,建议先去看之前正则式转换成NFA的文章,阅读本篇文章就会更加容易
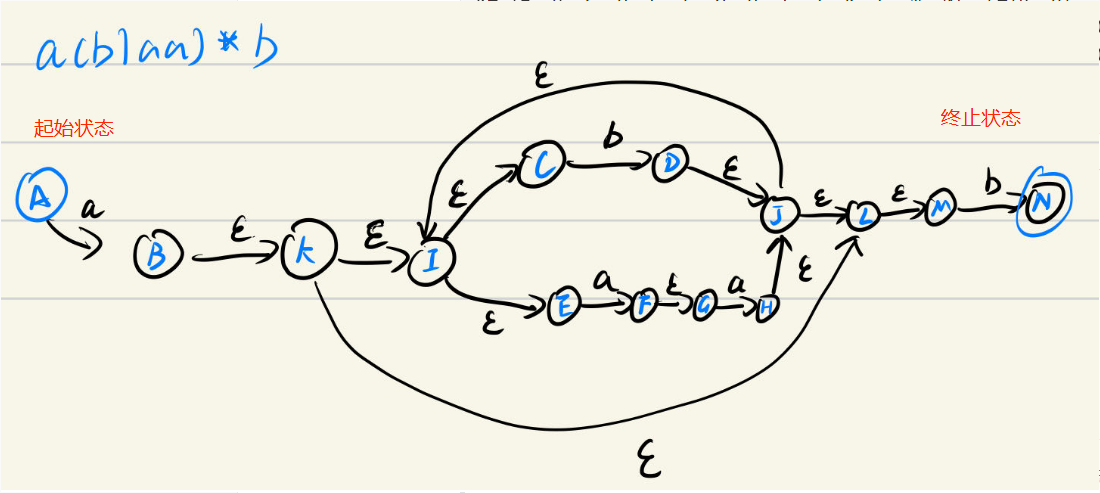
输入样例(正规式以及对应生成的NFA):
正规式:
a(b|aa)*b
对应的NFA:
K= {A, B, C, D, E, F, G, H, I, J, K, L, M, N}; Σ={a, b};
f(L, ε)= {M}, f(A, a)= {B}, f(C, b)= {D}, f(E, a)= {F}, f(G, a)= {H}, f(M, b)= {N},
f(B, ε)= {K}, f(D, ε)= {J}, f(F, ε)= {G}, f(H, ε)= {J}, f(I, ε)= {C, E}, f(J, ε)= {I, L},
f(K, ε)= {I, L}, ;
A; Z={N}
看着很多状态很复杂是吧,我们将对应的状态机画出来,看着就简单很多了
输出样例:
对应的DFA输出如下:
K= {A, B, F, N, O}; Σ={a, b};
f(O, b)= {O}, f(A, a)= {B}, f(B, a)= {F}, f(B, b)= {O}, f(F, a)= {B}, f(O, a)= {F},
;
A; Z={N, O, }
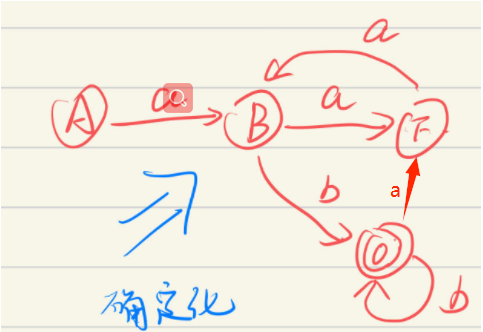
可以看到初始状态仍然是A,但是结束状态变成了O,而且N已经不见了,
这里是因为O是一个新的状态,同时可以表示到达B和F的状态,后面会讲到如何生成
实现和输出代码主要用到的函数:
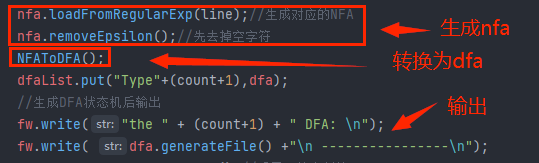
在讲解正规式生成NFA那篇文章当中已经介绍过loadFromRegularExp()的代码
因此这里只讲removeEpsilon()和NFAToDFA()的思路以及代码
NFAToDFA()的调用代码如下:
private void NFAToDFA(){
//使用确定化算法将NFA转换成DFA
dfa = new DFA(nfa);
dfa.generateStateFormat(nfa);//生成状态迁移表
dfa.showStateFormat();//打印到控制台
dfa.addFormatDataToDFA();
}
1. NFA去除空字符(仍可能为NFA)
为了让更好地转换成DFA,我们需要将NFA当中的 ε 转移去掉,让状态图清晰简洁一点。
注意,有的NFA去除空字符后,可能就成为DFA了,但也有的还是NFA。
例如上面给出的例子,会发现B状态输入b的时候,会回到B本身或者到达F终态。
1.1 算法思路:
思路是很简单的
两个由空字符连接起来的状态可以被简化成一个状态,如图
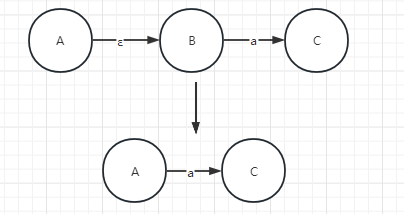
对应我们的代码,也就是将 f(A,ε) = B 当中的B替换成A
伪代码如下:
for(遍历所有状态迁移信息){
if(当前转移信息为ε){
src = 当前的出发状态;
dst = 当前目标状态;
移除这条状态信息;
for(遍历剩下的状态迁移信息){
if(当前状态==src)
当前状态=src;
if(目标状态==dst)
当前状态=dst;
}
}
}
该实现方法我们仍然放在类NFA当中,为removeEpsilon(),因为去除epsilon后可能仍然是NFA,所以就放在该类中
1.2 实现效果:
成功将空字符去除后,状态机如下:
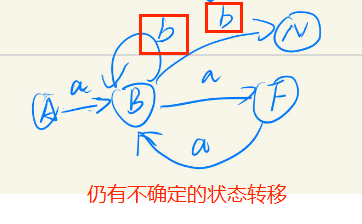
看到图片当中仍有不确定的状态转移,说明还是NFA
1.3 注意事项:
-
起始和终止状态可能发生变化:
在替代掉该带有空转移的目标状态之前,
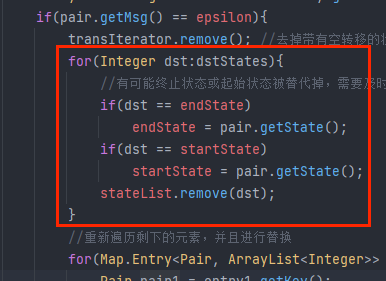
-
最后对替换后的目标状态列表进行去重
多个状态可能被替换成同一个状态
2.确定化算法
2.1 根据NFA写出状态转移表
将其去重之后就可以进行确定化算法的实现,
主要的思路就是根据当前的NFA创建一个状态表:
还是以之前的那个正规式作为例子:a(b|aa)*b
当前状态机如上图,得到如下状态表,生成思路并不难:
| 当前状态 | a | b |
|---|---|---|
| A | B | |
| B | F | B、F |
| N | ||
| F | B | |
| B、F | F | B、F |
这里看到B、F是一个叠加状态,我们可以用一个新的符号来代表这个状态。由此可以生成一个新的状态机
如上图状态机,这样每个状态的每个输出都有唯一的对应的目标状态,成功地从NFA转换成了DFA。
2.2 DFA类的实现以及代码创建状态表(最难的部分)
为了更好地面向对象,提高代码复用性以及封装性,DFA会继承于NFA类,并且新增一些属于DFA的成员函数和成员数据。
同时这里的代码量比较大,变量也很多,有很多要注意的操作细节,个人认为由于能力问题写的太过复杂了,导致越写越难,如果有更好更简单地思路是非常正常的。
以下为DFA的成员属性:
public class DFA extends NFA{
//msgList作为行头,
// stateFormat 的 key 对应的状态作为列头
Map< Integer,ArrayList<HashSet<Integer>>> stateFormat = new HashMap<>();
//该表用来映射由于多状态而新产生的状态
Map<Integer,HashSet<Integer>> newStateMap = new HashMap<>();
//用于存放在新状态当中产生的更新的状态
Map<Integer,HashSet<Integer>> newerStateMap = new HashMap<>();
//用于存放所有已经产存在的状态
Map<Integer,HashSet<Integer>> saveAllStateMap = new HashMap<>();
//主要作为一个变量名称方便使用
ArrayList<HashSet<Integer>> theFormat;//DFA会有多个终止状态
ArrayList<Integer> endState = new ArrayList<>();
}
- stateFormat:这里就是存放的二维表格,用Map是为了方便映射状态,key存放的实际就是状态表的行头。
- newStateMap:用于存放新的状态,例如{ B、F }生成的新状态存放在key当中,B、F一起存放在该map的Value当中.
- newerStateMap:在生成新的状态的数据的时候,可能会进一步又产生一个新的状态,因此用多一个Map来存放,方便区分,这个概念可能没那么好懂,后面讲解具体实现的时候会再次展开来讲。
- endState:这里覆盖了NFA当中对应的endState,是因为DFA的结束状态往往不止一个。
主要成员方法介绍:
generateStateFormat(NFA nfa);
changeOldStates();
generateNewStateFormat();
addFormatDataTODFA();//将表的数据放入DFA的迁移状态当中,例如那些f(A,a) = B
- changeOldStates:将多状态改成对应的新状态,如{B,F} 改成 O
- generateNewStateFormat():如果有新的状态,则需要增加表的内容。
生成状态表流程图如下:

流程来说是比较简单的,但是具体的代码实现起来有较多需要注意的点。
2.2.1 generateStateFormat():增加现有状态迁移信息到表当中。
具体代码如下:
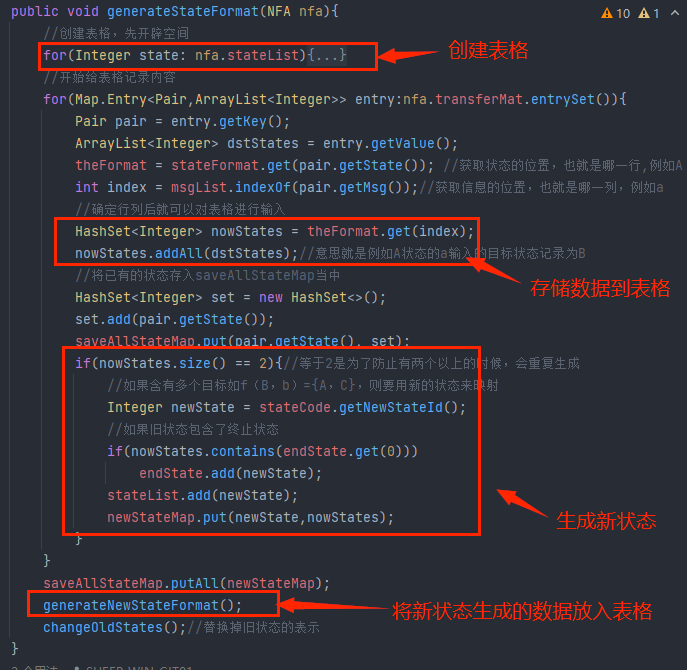
关注细节:
-
for循环的是transferMat,是NFA当中已经构建好的状态迁移信息
-
saveAllStateMap的作用是用于存放所有的状态以及映射的旧状态
-
当size==2的时候,说明当前状态迁移产生的不止一个状态,因此要用
新的状态来表示这个多状态。
-
当需要增添新的行的时候,就进入到generateNewStateFormat()
2.3 generateNewStateFormat()生成新状态
代码流程如下:
由于代码较长,分几步来讲解该函数
-
遍历所有的新状态,然后新增行

-
填写行数据内容
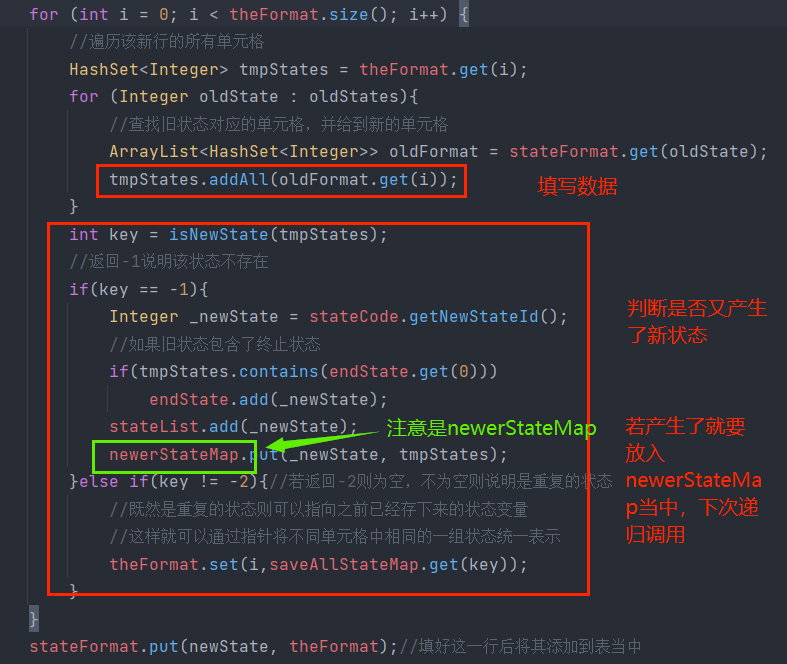
-
判断是否需要递归
最后判断newerStateMap里面的数据是否为空,否说明这次新增表格数据的时候又产生了新的目标状态组合,
因此需要递归,再次增加表的数据。

该函数与generateStateFormat还是会有比较大的区别,要注意的细节也更加多。
注意事项:
- 在该函数当中,产生新的状态时要存放到
newerStateMap当中,而不是newStateMap,注意区分 - 该函数是可以进行递归调用的,因为可能不断产生新的状态。
最终结果示例如下:
输入:
a(b|aa)*b
a*b
0(1|00)
a*b(b|(ab)*c)ca
输出:
the 1 DFA:
K= {A, B, F, N, O}; Σ={a, b};
f(O, b)= {O}, f(A, a)= {B}, f(B, a)= {F}, f(B, b)= {O}, f(F, a)= {B}, f(O, a)= {F},
;
A; Z={N, O, }
----------------
the 2 DFA:
K= {C, F}; Σ={a, b};
f(C, a)= {C}, f(C, b)= {F}, ;
C; Z={F, }
----------------
the 3 DFA:
K= {A, B, F, H}; Σ={0, 1};
f(A, 0)= {B}, f(B, 0)= {F}, f(B, 1)= {H}, f(F, 0)= {H}, ;
A; Z={H, }
----------------
the 4 DFA:
K= {C, F, H, J, T, V}; Σ={a, b, c};
f(C, a)= {C}, f(C, b)= {F}, f(T, a)= {V}, f(F, a)= {J}, f(F, b)= {H}, f(F, c)= {H},
f(H, c)= {T}, f(J, b)= {F}, ;
C; Z={V, }
----------------
3. 根据正则式生成的DFA识别字符串
输入:一个正规式文件和一个字符串文件
输出:判断字符串文件中的每个字符串,能否被正规式对应的DFA所识别
其次,再给每个正规式增加一个类别,识别到给定字符串符合某个特定正规式时,输出该类别。
示例:如果输入
a* Type1
b Type2
那么对字符串aaa输出:aaa,Type1
在前面的实验当中,我们已经成功根据正规式生成了对应的DFA了,因此现在可以直接读入字符串进行识别。
在这里就不去讲述如何读写文件了,直接讲解需要的功能:根据DFA识别字符串
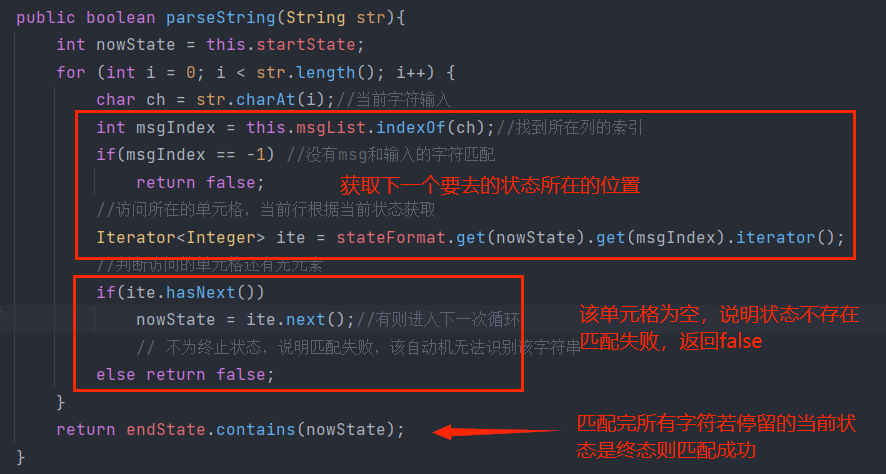
用到的思路是根据生成的状态转移表stateFormat,就可以很容易的完成字符串识别了。
| 当前状态 | a | b |
|---|---|---|
| A | B | |
| B | F | B、F |
| N | ||
| F | B | |
| B、F | F | B、F |
又是这个例子,每次循环当中读入一个字符,根据当前字符可以获取下一个要到达的状态。
例如从A开始,读入aaab,第一个字符是a,则下一个状态为B
第二个字符还是a,则下一个状态是F,以此类推…
逻辑代码如下:
最终结果示例如下:
正则式:
Type2: a*b
Type3: 0(1|00)
Type4: a*b(b|(ab)*c)ca
Type5: a*b(b|(ab)*c)*ca
Type6: a*b(b|(ab)*c)|ca
Type7: a*b(b|(ab)*c|ca)
Type8: a*b(b|(db)*c|css*e)
Type9: ((0|1)(010|11)*) | ((0|101)*)*
Type1: a(b|aa)*b
----------
字符串 类别 :
aaab Type2 Type1
aab Type2
abaabb Type1
aaabababcbca Type5
000 Type3 Type9
00 Type9
0101000 Type9
:
正则式:
Type2: a*b
Type3: 0(1|00)
Type4: a*b(b|(ab)*c)ca
Type5: a*b(b|(ab)*c)*ca
Type6: a*b(b|(ab)*c)|ca
Type7: a*b(b|(ab)*c|ca)
Type8: a*b(b|(db)*c|css*e)
Type9: ((0|1)(010|11)*) | ((0|101)*)*
Type1: a(b|aa)*b
----------
字符串 类别 :
aaab Type2 Type1
aab Type2
abaabb Type1
aaabababcbca Type5
000 Type3 Type9
00 Type9
0101000 Type9















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









