






 GLIGEN是一种改进的文本到图像生成模型,通过结合预训练模型和门控机制,接受标题、边界框等额外输入,实现对开放世界文本的控制生成,尤其在COCO和LVIS数据集上表现出色。
GLIGEN是一种改进的文本到图像生成模型,通过结合预训练模型和门控机制,接受标题、边界框等额外输入,实现对开放世界文本的控制生成,尤其在COCO和LVIS数据集上表现出色。
GLIGEN: Open-Set Grounded Text-to-Image Generation CVPR2023
Abstract
1.文生图效果很好,但是可能会妨碍可控性,关于文本输入
解决:提出GLIGEN,它建立并扩展了现有的预先训练的文本到图像扩散模型的功能,使它们也能以接地输入为条件
我们的模型使用标题和边界框条件输入实现了基于开放世界的文本生成。在COCO和LVIS数据集效果很好。
Introduction
虽然确实存在条件扩散模型和gan,它们接受除文本以外的输入方式进行inpainting、layoutg生成等,但它们很少将这些输入结合起来进行可控的text2img生成。
基于上述,作者除了将标题和文本外,增加其他输入方式:概念边界框,接地参考图像,接地不见关键点等。也就是说,增加了额外输入。
训练过程增加门控机制将额外信息整合到预训练模型中。关于门控,参考论文Flamingo引用1
motivation:研究GLIP基于框的语言图像理解模型的缩放成功。仅在coco数据集,模型泛化能力非常强。LVIS效果也很好。
Contribution
1.提出GLIGEN一种新型的文生图的方法
2.结合门控,保留预训练的权重,并学习逐步整合新的定位层,模型实现具有边界框输入的开放世界接地文本生成。
3.效果很好。
Related Work
Large scale text-to-image generation models
点一下目前最先进的生成模型:自回归(DALL-E)和扩散。
并且点了一下,DALL-E是zeroshot能力很强。
Pariti证明了按比例扩大的自回归模型的可行性,
Muse证明了掩码建模效果。
Image generation from layouts
从布局生成图像的方式是从给定的bounding box中生成相应的图像。
介绍了一大堆模型。
Preliminaries on Latent Diffusion Models
Latent diffusion model和SD是公认最强大的模型。
LDM分两个阶段进行。
第一阶段学习双向映射网络,获得图像x的潜在表示z。
第二阶段在潜函数z上训练扩散模型。
training objective
从噪声Zt开始
逐步减噪到样本Z0
每一个t时刻,状态条件为标题c
LDM的损失函数目的在于模型学习z的去噪问题
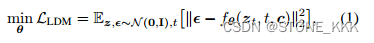
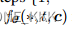
表示为t时刻c标题的状态噪音自编码器。
NetWork Architecture
核心:如何对条件进行编码;在此基础上生成一个更清晰的z
1.去噪自动编码器Denoising Autoencoder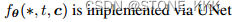
UNet由一系列ResNet和Transformer组成。
2.条件编码Condition Encoding,是接受字幕text的
LDM中的做法:从头训练一个BERT,将序列编码直接的代替损失函数中的c
标题特征是通过一个固定的CLIP[44]文本编码器在稳定扩散编码。时间t首先映射到嵌入时间的ϕ(t),然后注入到UNet中。标题特性在每个Transformer块中的交叉注意层中使用。模型学习预测噪声,遵循(1)
疑问1.我认为是标题通过CLIP编码器得到标题特征,然后将此特征放到SD中。通过时间步长t注入到UNet
通过大规模训练,模型fθ(∗,t, c)可以很好地训练到仅基于标题信息去噪z。
尽管LDM在互联网规模数据上的预训练已经显示出令人印象深刻的语言到图像生成结果,但在可以指示额外基础输入的情况下合成图像仍然具有挑战性,因此这是我们论文的重点。
Open-set Grounded Image Generation
Grounding Instruction Input
什么是接地文本到图像的生成, 理解后也就是拿额外信息作为新的输入训练模型,bounding box 和其文本标签信息.
对于接地文本到图像的生成,有多种方法可以通过附加条件接地生成过程
本文接地实体的语义信息表示为e ,对于e的特别描述为l表示。
回答上述:接地信息就好比 框框,一组关键点,边缘图等表述的接地信息.
某些情况下,语义信息和空间信息都可以用 l 单独使用(例如,边缘映射),其中单个映射可以表示图像中可能存在的对象和位置。
其中,单个边缘图可以表示图像中可能出现的对象及其位置。
我们将对基于文本到图像模型的指令定义为标题和基于实体的组合:
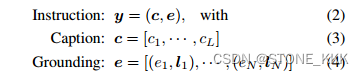
其中L为标题长度,N为落地实体数。在这项工作中,我们主要研究使用边界框作为接地空间配置,因为它具有较大的可用性和易于用户注释的特点。对于接地实体e,由于简单,我们主要使用文本作为其表示。我们处理标题和接地实体作为扩散模型的输入令牌,如下文详细描述。
Caption Tokens
标题c的处理方式与LDM相同。具体来说,我们使用hc = [h c 1,···,hc L] = ftext©获得标题特征序列(图2中的黄色标记),其中 最后一个单词hc L就是caption的上下文特种(类比BERT的CLS)
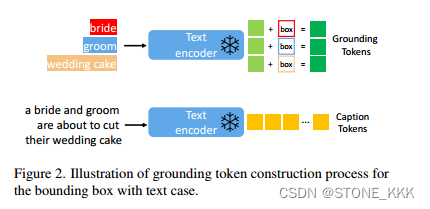
Grounding Tokens
对于每一个接地文本实体用一个bounding box来表示,表示为l = [αmin, βmin, αmax, βmax]
坐标分别表示左上右下
关于文本实体e,使用相同的pretraining model获取其文本特征 浅绿色.
最终,文本实体特征e + box 生成接地token
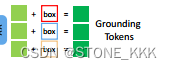
解决上述疑惑,文本实体e也就是关于bounding box的信息描述.
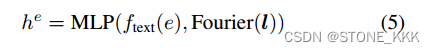
Fourier表示傅里叶嵌入,l表示实体信息bounding box,e表示文本实体.这些信息统统送入MLP
From Closed-set to Open-set
请注意,现有的layout2img只能处理闭集设置(例如,COCO类别),因为它们通常学习每个实体的向量嵌入u,以替换(5)中的ftext(e)。
疑问3:到底啥是闭集开集的?还需要通过字典查询…
GLIGEN 的灵活性,展现之一就是Grounding的使用场景
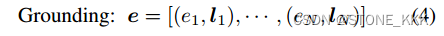
Continual Learning for Grounded Generation
motivation:为现有的大模型赋予新的空间基础能力.大型扩散模型已经在网络规模的imagettext上进行了预训练,以获得基于各种复杂语言指令合成逼真图像所需的知识。由于预训练成本高且性能优异,在扩展新能力的同时,将这些知识保留在模型权值中非常重要。
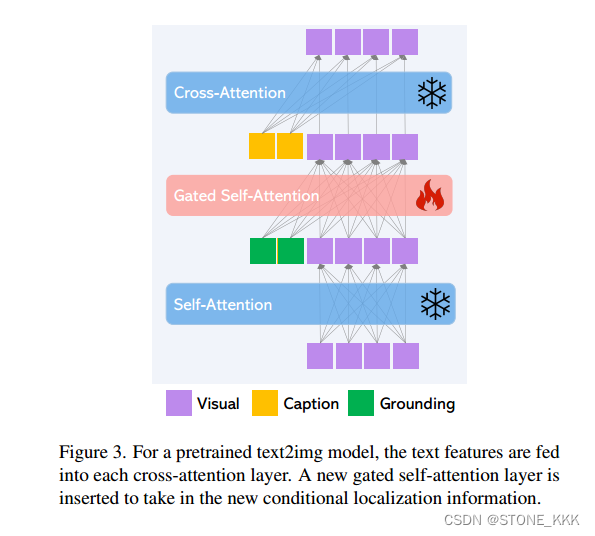
作者冻结了子注意力机制层和交叉注意力机制层.添加了一个新的门控子注意力机制层.
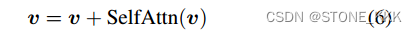
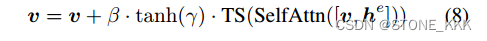
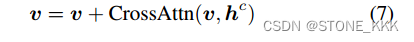
7是门控注意力机制.
直观地说,(8)中的门控自注意允许视觉特征利用边界框信息,并且由此产生的接地特征被视为残差,其门初始设置为0(由于γ被初始化为0)。这也使训练更加稳定。请注意,在Flamingo中使用了类似的想法[1];然而,它使用门控交叉注意,这导致在我们的消融研究中表现较差。
Experiments
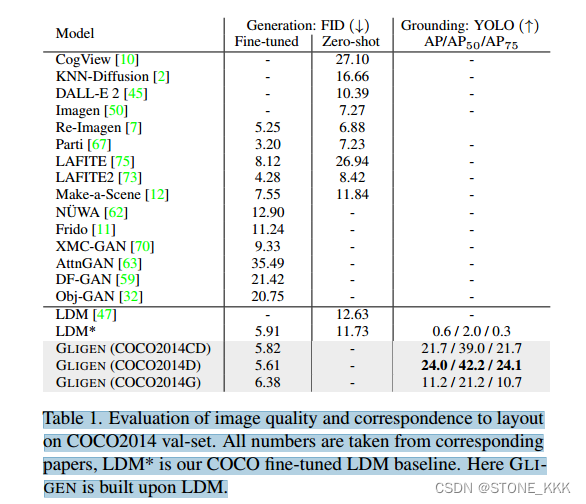















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









