






1.单机多卡概述
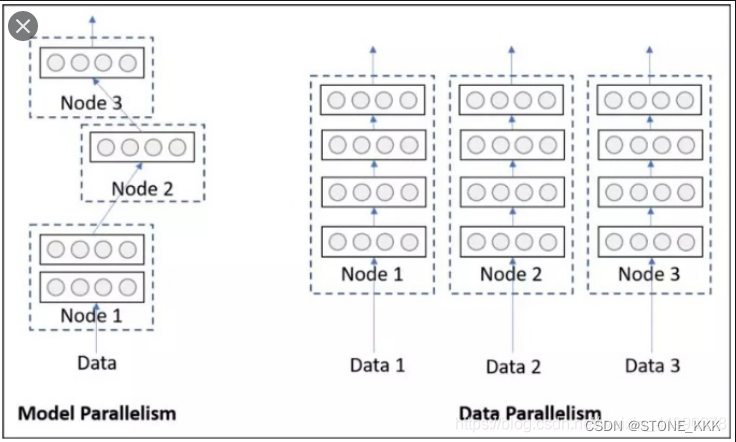
单卡多级的模型训练,即并行训练,可分为数据并行和模型并行两种.
数据并行是指,多张 GPUs 使用相同的模型副本,但采用不同 batch 的数据进行训练.
模型并行是指,多张 GPUs 使用同一 batch 的数据,分别训练模型的不同部分.
2.DataParallel源码
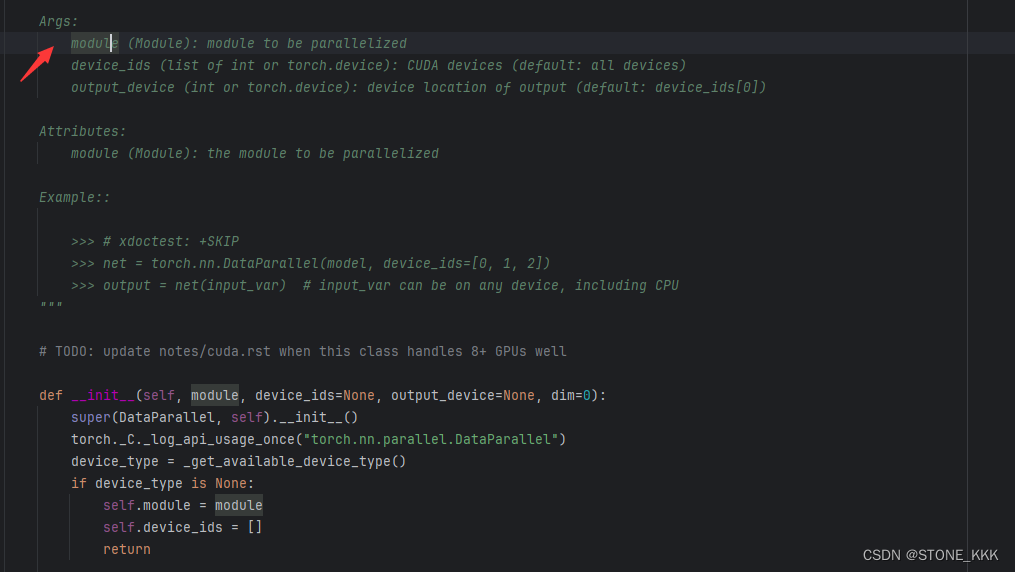
2.1 需要传入的参数
module(Module):被并行运算的模型
device_ids=None: CUDA devices
output_device=None:输出设备位置
2.2 forward
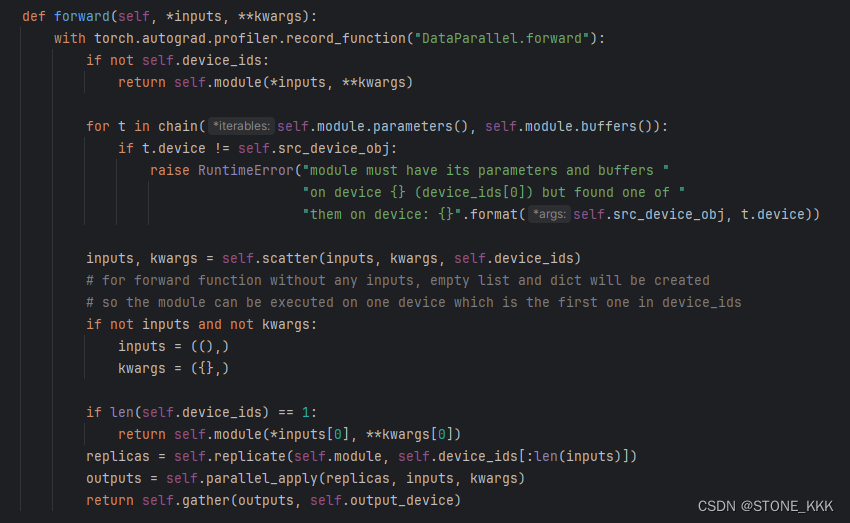
检查设备是否合理;
如果合理遍历模型参数和其缓存区, 检查参数和缓冲区的设备是否与src_device_obj相同如果不同抛RuntimeError。
源码说模型和参数必须放到device_ids[0]
将输入数据根据设备数量分发到不同的设备上。
3.DataParallel案例
通过 PyTorch 使用 GPU 非常简单。您可以将模型放在 GPU 上
device = torch.device("cuda:0")
model.to(device)
然后,您可以将所有张量复制到 GPU:
mytensor = my_tensor.to(device)
–注意:mytensor.to(device)等所有tensor操作都是copy数据然后重载,不改变原tensor
。但是,Pytorch 默认情况下仅使用一个 GPU。通过使用以下命令使模型并行运行,您可以轻松地在多个 GPU 上运行操作 DataParallel :
model = nn.DataParallel(model)
导入Pytorch模块并导入参数
import torch
from torch.utils.data import Dataset,DataLoader
import torch.nn as nn
# Parameters and DataLoaders
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
设计一个dummy数据集
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
Our model
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
创建模型和DataParallel
model = Model(input_size,output_size) #初始化参数对应,不着急进行设备关联
if torch.cuda.device_count() >1: #判别一下是否多GPU
print("可以进行数据并行训练")
model = nn.DataParallel(model) #是的话可以进行初始化操作
model = model.to(device) #pytorch一般而已都是重新赋值操作而非修改源数据
数据并行加载数据
for data in rand_loader:
input = data.to(device)
output = model(input)
print("\tIn Model: input size", input.size())
运行模型
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/linear.py:116: UserWarning:
Attempting to run cuBLAS, but there was no current CUDA context! Attempting to set the primary context… (Triggered internally at …/aten/src/ATen/cuda/CublasHandlePool.cpp:135.)
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([6, 5]) output size torch.Size([6, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([6, 5]) output size torch.Size([6, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
In Model: input size torch.Size([6, 5]) output size torch.Size([6, 2])
In Model: input size torch.Size([8, 5]) output size torch.Size([8, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([3, 5]) output size torch.Size([3, 2])
In Model: input size torch.Size([3, 5]) output size torch.Size([3, 2])
In Model: input size torch.Size([3, 5]) output size torch.Size([3, 2])
In Model: input size torch.Size([1, 5]) output size torch.Size([1, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
如果您没有 GPU 或只有一个 GPU,则当我们批量处理 30 个输入和 30 个输出时,模型将按预期获得 30 个输入和 30 个输出。但如果你有多个 GPU,那么你可以获得这样的结 果。
Let’s use 2 GPUs!
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
Let’s use 3 GPUs!
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
Let’s use 8 GPUs!
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])














 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









