







一、学习目标
设计模式分为三大类:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、 原型模式。
结构型模式,共七种:适配器模式、装饰者模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
其实还有两类:并发型模式和线程池模式。
设计模式的六大原则:
总原则-开闭原则
对扩展开放,对修改封闭。在程序需要进行拓展的时候,不能去修改原有的代码,而是要扩展原有代码,实现一个热插拔的效果。所以一句话概括就是:为了使程序的扩展性好,易于维护和升级。
想要达到这样的效果,我们需要使用接口和抽象类等,后面的具体设计中我们会提到这点。
1. 单一职责原则
不要存在多于一个导致类变更的原因,也就是说每个类应该实现单一的职责,否则就应该把类拆分。
2. 里氏替换原则(Liskov Substitution Principle)
任何基类可以出现的地方,子类一定可以出现。里氏替换原则是继承复用的基石,只有当衍生类可以替换基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。里氏代换原则是对“开-闭”原则的补充。实现“开闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。里氏替换原则中,子类对父类的方法尽量不要重写和重载。因为父类代表了定义好的结构,通过这个规范的接口与外界交互,子类不应该随便破坏它。
3. 依赖倒转原则(Dependence Inversion Principle)
面向接口编程,依赖于抽象而不依赖于具体。写代码时用到具体类时,不与具体类交互,而与具体类的上层接口交互。
4. 接口隔离原则(Interface Segregation Principle)
每个接口中不存在子类用不到却必须实现的方法,如果不然,就要将接口拆分。使用多个隔离的接口,比使用单个接口(多个接口方法集合到一个的接口)要好。
5. 迪米特法则(最少知道原则)(Demeter Principle)
一个类对自己依赖的类知道的越少越好。无论被依赖的类多么复杂,都应该将逻辑封装在方法的内部,通过 public 方法提供给外部。这样当被依赖的类变化时,才能最小的影响该类。
最少知道原则的另一个表达方式是:只与直接的朋友通信。类之间只要有耦合关系,就叫朋友关系。耦合分为依赖、关联、聚合、组合等。我们称出现为成员变量、方法参数、方法返回值中的类为直接朋友。局部变量、临时变量则不是直接的朋友。我们要求陌生的类不要作为局部变量出现在类中。
6. 合成复用原则(Composite Reuse Principle)
尽量首先使用合成/聚合的方式,而不是使用继承。
二、简单工厂模式
2.1 模式定义
简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式(同属于创建型模式的还有工厂方法模式,抽象工厂模式,单例模式,建造者模式)。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。
2.2 模式结构

从上图可以看出,简单工厂模式由三部分组成:具体工厂、具体产品和抽象产品。工厂类(Creator)角色:担任这个角色的是简单工厂模式的核心,含有与应用紧密相关的商业逻辑。工厂类在客户端的直接调用下创建产品对象,它往往由一个具体 Java 类实现。
抽象产品(AbstractProduct)角色:担任这个角色的类是由简单工厂模式所创建的对象的父类,或它们共同拥有的接口。抽象产品角色可以用一个 Java 接口或者 Java 抽象类实现。
具体产品(ConcreteProduct)角色:简单工厂模式所创建的任何对象都是这个角色的实例,具体产品角色由一个具体 Java 类实现。
2.3 模式动机
使用简单工厂模式可以将产品的“消费”和生产完全分开,客户端只需要知道自己需要什么产品,如何来使用产品就可以了,具体的产品生产任务由具体的工厂类来实现。工厂类根据传进来的参数生产具体的产品供消费者使用。这种模式使得更加利于扩展,当有新的产品加入时仅仅需要在工厂中加入新产品的构造就可以了。
2.4 实例分析
// 这个是Audi车的类
public class Audi {
public Audi() {
System.out.println("Create a Audi");
}
public void drive() {
System.out.println("Audi start engine");
}
}// 这个是Benz车的类
public class Benz {
public Benz() {
System.out.println("Create a Benz");
}
public void drive() {
System.out.println("Benz start engine");
}
}// 这个是Bmw车的类
public class Bmw {
public Bmw() {
System.out.println("Create a Bmw");
}
public void drive() {
System.out.println("Bmw start engine");
}
}// 主程序调用
public class Main {
public static void main(String[] args) {
Audi audi = new Audi();
audi.drive();
Benz benz = new Benz();
benz.drive();
Bmw bmw = new Bmw();
bmw.drive();
}
}
上边这段代码的结构非常的不好。不管是 Audi、Benz 还是 Bmw,大家不都是车吗,为什么不直接创建一个 Car 的父类,然后让其他的汽车的子类来继承呢?
所有针对以上的问题我们可以做如下的优化。
创建了一个新的接口类 Car,作为所有汽车的父类,定义了一个抽象的 drive 方法,具体的实现由子类来实现。
public interface ICar {
void drive();
}
// 这是改进后的Audi类实现了父类的drive方法
public class Audi extends ICar{
public Audi() {
System.out.println("Create a Audi");
}
public void drive() {
System.out.println("Audi start engine");
}
}// 这是改进后的Benz类实现了父类的drive方法
public class Benz extends ICar{
public Benz() {
System.out.println("Create a Benz");
}
public void drive() {
System.out.println("Benz start engine");
}
}// 这是改进后的Bmw类实现了父类的drive方法
public class Bmw extends ICar{
public Bmw() {
System.out.println("Create a Bmw");
}
public void drive() {
System.out.println("Bmw start engine");
}
}
// 主程序调用
public class Main {
public static void main(String[] args) {
ICar car = new Audi();
car.drive();
}
}
这个方案看似完美但其实还是存在巨大的隐患。我提供实例是比较简单的,但实际应用中创建对象时可能不是一句话就能解决的事,比如创建奥迪车时需要发动机的型号,轮胎的大小,玻璃的尺寸,并且尺寸可能是由一系列复杂的运算计算出来的,所以如果把创建对象的任务放到客户端中,就是使客户端显得非常的臃肿,所以我们可以借助简单工厂模式进行改进。
我们创建一个工厂类,这个工厂类专门负责建造各种汽车,代码如下:
// 创建一个 CarFactory 工厂类
public class CarFactory {
public ICar getCar(String type) throws Exception{
if(type.equals("Audi")) {
return new Audi();
} else if(type.equals("Benz")) {
return new Benz();
} else if(type.equals("Bmw")) {
return new Bmw();
} else {
throw new Exception();
}
}
}
// 主程序调用
public class Main {
public static void main(String[] args) throws Exception {
ICar car = new CarFactory().getCar("Audi");
car.drive();
}
}
在上面的那个例子中,Driver 类就是我们说的工厂,他用 if-else 语句来判断需要创建什么类型的对象(当然也可以使用 switch 语句),这就是我们一直说的简单工厂模式。
通过 Java 反射机制继续优化:
// 优化 CarFactory 工厂类
public class CarFactory {
public ICar getCar(Class clazz) throws Exception{
if(null != clazz) {
return (Car)clazz.newInstance();
}
return null;
}
}// 主程序调用
public class Main {
public static void main(String[] args) throws Exception {
ICar car = new CarFactory().getCar(Audi.class);
car.drive();
}
}
上边的代码更简洁了,我们还可以通过泛型限制 Car 的类型,实现单一职责。
// 通过泛型限制Car的类型,实现单一职责
public class CarFactory {
public ICar getCar(Class<? extends Car> clazz) throws Exception{
if(null != clazz) {
return clazz.newInstance();
}
return null;
}
}
// 主程序调用
public class Main {
public static void main(String[] args) throws Exception {
ICar car = new CarFactory().getCar(Audi.class);
car.drive();
}
}
2.5 模式优点
- 工厂类含有必要的判断逻辑,可以决定在什么时候创建哪一个产品类的实例,客户端可以免除直接创建产品对象的责任,而仅仅“消费”产品;简单工厂模式通过这种做法实现了对责任的分割,它提供了专门的工厂类用于创建对象。
- 客户端无须知道所创建的具体产品类的类名,只需要知道具体产品类所对应的参数即可,对于一些复杂的类名,通过简单工厂模式可以减少使用者的记忆量。
- 通过引入配置文件,可以在不修改任何客户端代码的情况下更换和增加新的具体产品类,在一定程度上提高了系统的灵活性。
- 当需要引入新的产品是不需要修改客户端的代码,只需要添加相应的产品类并修改工厂类就可以了,所以说从产品的角度上简单工厂模式是符合“开-闭”原则的。
2.6 模式缺点
- 由于工厂类集中了所有产品创建逻辑,工厂类一般被我们称作“全能类”或者“上帝类”,因为所有的产品创建他都能完成,这看似是好事,但仔细想想是有问题的。比如全国上下所有的事情都有国家主义一个人干会不会有问题,当然有!一旦不能正常工作,整个系统都要受到影响。
- 使用简单工厂模式将会增加系统中类的个数,在一定程序上增加了系统的复杂度和理解难度。
- 系统扩展困难,一旦添加新产品就不得不修改工厂逻辑,在产品类型较多时,有可能造成工厂逻辑过于复杂,不利于系统的扩展和维护。所以说从工厂的角度来说简单工厂模式是不符合“开-闭”原则的。
- 简单工厂模式由于使用了静态工厂方法,造成工厂角色无法形成基于继承的等级结构。
2.7 适用场景
在以下情况下可以使用简单工厂模式:
- 工厂类负责创建的对象比较少:由于创建的对象较少,不会造成工厂方法中的业务逻辑太过复杂。
- 客户端只知道传入工厂类的参数,对于如何创建对象不关心:客户端既不需要关心创建细节,甚至连类名都不需要记住,只需要知道类型所对应的参数。
2.8 JDK 中的应用
JDK 类库中广泛使用了简单工厂模式,如工具类`java.text.DateFormat`,它用于格式化一个本地日期或者时间。
public final static DateFormat getDateInstance();
public final static DateFormat getDateInstance(int style);
public final static DateFormat getDateInstance(int style, Locale locale);
三、工厂方法模式
3.1 概念介绍
“工厂方法模式”是对简单工厂模式的进一步抽象化,其好处是可以使系统在不修改原来代码的情况下引进新的产品,即满足开闭原则(对扩展开放,对修改封闭)。
(把创建对象的过程交给了工厂,我们只需要把你要创建的是什么对象的类,传递过去,工厂就会自动创建对象返回)
3.1.1 优点:
1. 用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程。
2. 灵活性增强,对于新产品的创建,只需多写一个相应的工厂类。
3. 典型的解耦框架。高层模块只需要知道产品的抽象类,无须关心其他实现类,满足迪米特法则(最少知识原则:就是有关联的类越少越好)、依赖倒置原则和里氏替换原则。
3.1.2 缺点 :
1. 类的个数容易过多,增加复杂度。
2. 增加了系统的抽象性和理解难度。
3. 抽象产品只能生产一种产品,此弊端可使用抽象工厂模式解决。
3.2 示例分析
东汉《风俗通》记录了一则神话故事:“开天辟辟,未有人民,女娲搏,黄土作人……”,讲述的内容就是大家非常熟悉的女娲造人的故事。开天辟地之初,大地上并没有生物,只有苍茫大地,纯粹而洁净的自然环境,寂静而又寂寞,于是女娲决定创造一个新物种(即人类)来增加世界的繁荣,怎么制造呢?
1. 别忘了女娲是神仙,没有办不到的事情,造人的过程是这样的:首先,女娲采集黄土捏成人的形状,然后放到八卦炉中烧制,最后放置到大地上生长,工艺过程是没有错的,但是意外随时都会发生:
2. 第一次烤泥人,兹兹兹兹,感觉应该熟了,往大地上一放,哇,没烤熟!于是一个白人诞生了!(这也是缺乏经验的最好证明)
3. 第二次烤泥人,兹兹兹兹兹兹兹兹,上一次没烤熟,这次多烤一会儿,放到世间一看,嘿,熟过头了,于是黑人诞生了!
4. 第三次烤泥人,兹兹兹~~,一边烧制一边察看,直到表皮微黄,嘿,真正好,于是黄色人种出现了!
5. 这个造人过程是比较有意思的,是不是可以通过软件开发来实现这个过程呢?
在面向对象的思维中,万物皆对象,是对象我们就可以通过软件设计来实现。首先对造人过程进行分析,该过程涉及三个对象:女娲、八卦炉、三种不同肤色的人,女娲可以使用场景类 Client 来表示,八卦炉类似于一个工厂,负责制造生产产品(即人类):
三种不同肤色的人,他们都是同一个接口下的不同实现类,都是人嘛,只是肤色、语言不同,对于八卦炉来说都是它生产出的产品。
分析完毕,我们就可以画出如图所示类图。
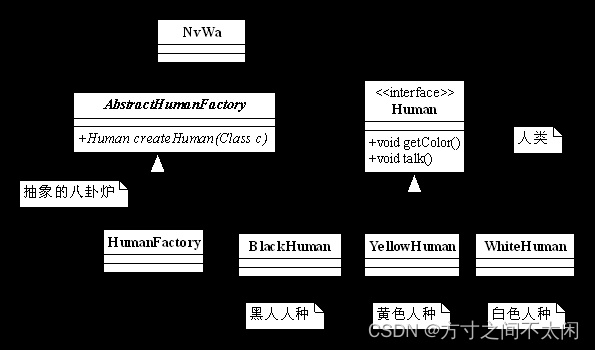
类图比较简单,AbstractHumanFactory 是一个抽象类,定义了一个八卦炉都具有的整体功能,HumanFactory 为实现类,完成具体的任务:创建人类;
Human 接口是人类的总称,其三个实现类分别为三类人种;
NvWa 类是一个场景类,负责模拟这个场景,执行相关的任务。
我们定义的每个人种都有两个方法:getColor(获得人的皮肤颜色)和 talk(交谈)
人类总称:
public interface Human {
// 每个人种的皮肤都有相应的颜色
public void getColor();
// 人类会说话
public void talk();
}
接口 Human 是对人类的总称,每个人种都至少具有两个方法,黑色人种、黄色人种、白色人种的代码分别如下:
public class BlackHuman implements Human {
public void getColor() {
System.out.println("黑色人种的皮肤颜色是黑色的!");
}
public void talk() {
System.out.println("黑人会说话,一般人听不懂。");
}
}
public class YellowHuman implements Human {
public void getColor() {
System.out.println("黄色人种的皮肤颜色是黄色的!");
}
public void talk() {
System.out.println("黄色人种会说话,一般说的都是双字节。");
}
}
public class WhiteHuman implements Human {
public void getColor() {
System.out.println("白色人种的皮肤颜色是白色的!");
}
public void talk() {
System.out.println("白色人种会说话,一般都是但是单字节。");
}
}
所有的人种定义完毕,下一步就是定义一个八卦炉,然后烧制人类。我们想象一下,女娲最可能给八卦炉下达什么样的生产命令呢?
应该是 “ 给我生产出一个黄色人种(`YellowHuman`类) ” ,而不会是“给我生产一个会走、会跑、会说话、皮肤是黄色的人种”,因为这样的命令增加了交流的成本,作为一个生产的管理者,只要知道生产什么就可以了,而不需要事物的具体信息。
通过分析,我们发现八卦炉生产人类的方法输入参数类型应该是 Human 接口的实现类,这也解释了为什么类图上的 AbstractHumanFactory 抽象类中 createHuman 方法的参数为 Class 类型。
//抽象人类创建工厂
public abstract class AbstractHumanFactory {
public abstract Human createHuman(Class<? extends Human> c);
}
注意,我们在这里采用了 JDK 1.5 的新特性:泛型(Generic),通过定义泛型对 createHuman 的输入参数产生两层限制:
- 必须是 Class 类型;
- 必须是 Human 的实现类;
其中的 “ ? ” 表示的是,只要实现了 Human 接口的类都可以作为参数,泛型是 JDK 1.5 中的一个非常重要的新特性,它减少了对象间的转换,约束其输入参数类型,对 Collection 集合下的实现类都可以定义泛型。
目前女娲只有一个八卦炉,其实现了生产人类的方法,
// 完整写法
public static <T extends Human> T createHuman(Class<T> c){
}
public class HumanFactory extends AbstractHumanFactory {
public Human createHuman(Class<? extends Human> c) {
// 定义一个生产的人种
Human human = null;
try {
// 产生一个人种
human = (Human) Class.forName(c.getName()).newInstance();
} catch (Exception e) {
System.out.println("人种生成错误!");
}
return human;
}
}
Class.forName(c.getName()).newInstance();获取输入的对象的类名,并通过其产生相应的对象人种有了,八卦炉也有了,剩下的工作就是女娲采集黄土,然后命令八卦炉开始生产。
public class NvWa {
public static void main(String[] args) {
// 声明阴阳八卦炉
AbstractHumanFactory YinYangLu = new HumanFactory();
// 女娲第一次造人,火候不足,缺陷产品
System.out.println("--造出的第一批人是白色人种--");
Human whiteHuman = YinYangLu.createHuman(WhiteHuman.class);
whiteHuman.getColor();
whiteHuman.talk();
// 女娲第二次造人,火候过足,又是次品,
System.out.println("\n--造出的第二批人是黑色人种--");
Human blackHuman = YinYangLu.createHuman(BlackHuman.class);
blackHuman.getColor();
blackHuman.talk();
// 第三次造人,火候刚刚好,优品!黄色人种
System.out.println("\n--造出的第三批人是黄色人种--");
Human yellowHuman = YinYangLu.createHuman(YellowHuman.class);
yellowHuman.getColor();
yellowHuman.talk();
}
}
运行结果:
--造出的第一批人是白色人种--
白色人种的皮肤颜色是白色的!
白色人种会说话,一般都是但是单字节。
--造出的第二批人是黑色人种--
黑色人种的皮肤颜色是黑色的!
黑人会说话,一般人听不懂。
--造出的第三批人是黄色人种--
黄色人种的皮肤颜色是黄色的!
黄色人种会说话,一般说的都是双字节。
哇,人类的生产过程就展现出来了!这个世界就热闹起来了,黑人、白人、黄人都开始活动了,这也正是我们现在的真实世界。以上就是工厂方法模式。
3.3 模式定义
1. 工厂方法模式使用的频率非常高,在我们日常的开发中总能见到它的身影。其定义为:
2. Define an interface for creating an object, but let subclasses decide which class to instantiate. Factory Method lets a class defer instantiation to subclasses。定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
工厂方法模式的通用类图

在工厂方法模式中,抽象产品类 Product 负责定义产品的共性,实现对事物最抽象定义;Creator 为抽象创建类,也就是抽象工厂,具体如何创建产品类是由具体的实现工厂 ConcreteCreator 完成的。工厂方法模式的变种较多,我们来看一个比较实用的通用源码。
抽象产品类代码
public abstract class Product {
// 产品类的公共方法
public void method1() {
// 业务逻辑处理
}
// 抽象方法
public abstract void method2();
}
具体的产品类可以有多个,都继承于抽象产品类。
public class ConcreteProduct1 extends Product {
public void method2() {
// 业务逻辑处理
}
}
public class ConcreteProduct2 extends Product {
public void method2() {
// 业务逻辑处理
}
}
抽象工厂类负责定义产品对象的产生。
public abstract class Creator {
/*
* 创建一个产品对象,其输入参数类型可以自行设置
* 通常为String、Enum、Class等,当然也可以为空
*/
public abstract Product createProduct(Class<? extends Product> c);
}
具体如何产生一个产品的对象,是由具体的工厂类实现的。
public class ConcreteCreator extends Creator {
public Product createProduct(Class<? extends Product> c) {
Product product = null;
try {
product = (Product) Class.forName(c.getName()).newInstance();
} catch (Exception e) {
// 异常处理
}
return product;
}
}
场景类的调用方法。
public class Client {
public static void main(String[] args) {
Creator creator = new ConcreteCreator();
Product product = creator.createProduct(ConcreteProduct1.class);
/*
* 继续业务处理
*/
}
}
该通用代码是一个比较实用、易扩展的框架,可以根据实际项目需要进行扩展。
3.4 模式应用
3.4.1 优点
1. 良好的封装性,代码结构清晰。一个对象创建是有条件约束的,如一个调用者需要一个具体的产品对象,只要知道这个产品的类名(或约束字符串)就可以了,不用知道创建对象的艰辛过程,减少模块间的耦合。
2. 工厂方法模式的扩展性非常优秀。在增加产品类的情况下,只要适当地修改具体的工厂类或扩展一个工厂类,就可以完成“拥抱变化”。例如在我们的例子中,需要增加一个棕色人种,则只需要增加一个 BrownHuman 类,工厂类不用任何修改就可完成系统扩展。
3. 屏蔽产品类。这一特点非常重要,产品类的实现如何变化,调用者都不需要关心,它只需要关心产品的接口,只要接口保持不表,系统中的上层模块就不要发生变化,因为产品类的实例化工作是由工厂类负责,一个产品对象具体由哪一个产品生成是由工厂类决定的。在数据库开发中,大家应该能够深刻体会到工厂方法模式的好处:如果使用 JDBC 连接数据库,数据库从 MySql 切换到 Oracle,需要改动地方就是切换一下驱动名称(前提条件是 SQL 语句是标准语句),其他的都不需要修改,这是工厂方法模式灵活性的一个直接案例。
4. 工厂方法模式是典型的解耦框架。高层模块值需要知道产品的抽象类,其他的实现类都不用关心。
5. 符合迪米特原则,我不需要的就不要去交流;
6. 符合依赖倒转原则,只依赖产品类的抽象;
7. 符合里氏替换原则,使用产品子类替换产品父类。
3.4.2 使用场景
1. 工厂方法模式是 new 一个对象的替代品,所以在所有需要生成对象的地方都可以使用,但是需要慎重地考虑是否要增加一个工厂类进行管理,增加代码的复杂度。
2. 需要灵活的、可扩展的框架时,可以考虑采用工厂方法模式。万物皆对象,那万物也就皆产品类。例如需要设计一个连接邮件服务器的框架,有三种网络协议可供选择:POP3、IMAP、HTTP,我们就可以把这三种连接方法作为产品类,定义一个接口如 IConnectMail,然后定义对邮件的操作方法,三个具体的产品类(也就是连接方式)进行不同的实现,再定义一个工厂方法,按照不同的传入条件,选择不同的连接方式。如此设计,可以做到完美的扩展,如某些邮件服务器提供了 WebService 接口,很好,我们只要增加一个产品类就可以了。
3. 工厂方法模式可以用在异构项目中,例如通过 WebService 与一个非 Java 的项目交互,虽然 WebService 号称是可以做到异构系统的同构化,但是在实际的开发中,还是会碰到很多问题,如类型问题、WSDL 文件的支持问题,等等,从 WSDL 中产生的对象都认为是一个产品,然后由一个具体的工厂类进行管理,减少与外围系统的耦合。
4. 可以使用在测试驱动开发的框架下,例如,测试一个类 A,就需要把与类 A 有关联关系的类B也同时产生出来,我们可以使用工厂方法模式把类B虚拟出来,避免类 A 与类 B 的耦合。目前由于 JMock 和 EasyMock 的诞生,该使用场景已经弱化了,读者可以在遇到此种情况时直接考虑使用 JMock 或 EasyMock。
3.5 模式扩展
工厂方法模式有很多扩展,而且与其他模式结合使用威力更大,下面将介绍四种扩展。
3.5.1 缩小为简单工厂模式
我们这样考虑一个问题:一个模块仅需要一个工厂类,没有必要把它产生出来,使用静态的方法就可以了,根据这一要求,我们把上例中的 AbstarctHumanFactory修改一下。

简单工厂模式中的工厂类
public class HumanFactory {
public static Human createHuman(Class<? extends Human> c) {
// 定义一个生产出的人种
Human human = null;
try {
// 产生一个人种
human = (Human) Class.forName(c.getName()).newInstance();
} catch (Exception e) {
System.out.println("人种生成错误!");
}
return human;
}
}
HumanFactory 类仅有两个地方变化:去掉继承抽象类,并在 createHuman 前增加 static 关键字。工厂类发生变化,也同时引起了调用者 NvWa 的变化。
public class NvWa {
public static void main(String[] args) {
// 女娲第一次造人,火候不足,缺陷产品
System.out.println("--造出的第一批人是白色人种--");
Human whiteHuman = HumanFactory.createHuman(WhiteHuman.class);
whiteHuman.getColor();
whiteHuman.talk();
// 女娲第二次造人,火候过足,又是次品,
System.out.println("\n--造出的第二批人是黑色人种--");
Human blackHuman = HumanFactory.createHuman(BlackHuman.class);
blackHuman.getColor();
blackHuman.talk();
// 第三次造人,火候正正好,优品!黄色人种
System.out.println("\n--造出的第三批人是黄色人种--");
Human yellowHuman = HumanFactory.createHuman(YellowHuman.class);
yellowHuman.getColor();
yellowHuman.talk();
}
}
运行结果没有发生变化,但是我们的类图变简单了,而且调用者也比较简单,该模式是工厂方法模式的弱化,因为简单,所以被称为简单工厂模式(Simple Factory Pattern),也叫做静态工厂模式。在实际项目中,采用该方法的案例还是比较多的,其缺点是工厂类的扩展比较困难,不符合开闭原则,但它仍然是一个非常实用的设计模式。
3.5.2 升级为多个工厂类
当我们在做一个比较复杂的项目时,经常会遇到初始化一个对象很耗费精力的情况,所有的产品类都放到一个工厂方法中进行初始化会使代码结构不清晰。例如,一个产品类有 5 个具体实现,每个实现类的初始化(不仅仅是 new,初始化包括 new 一个对象,并对对象设置一定的初始值)方法都不相同,如果写在一个工厂方法中,势必会导致该方法巨大无比,那怎么办?
考虑到需要结构清晰,我们就为每个产品定义一个创造者,然后由调用者自己去选择与哪个工厂方法关联。我们还是以女娲造人为例,每个人种都有一个固定的八卦炉,分别造出黑色人种、白色人种、黄色人种,修改后的类图如下:
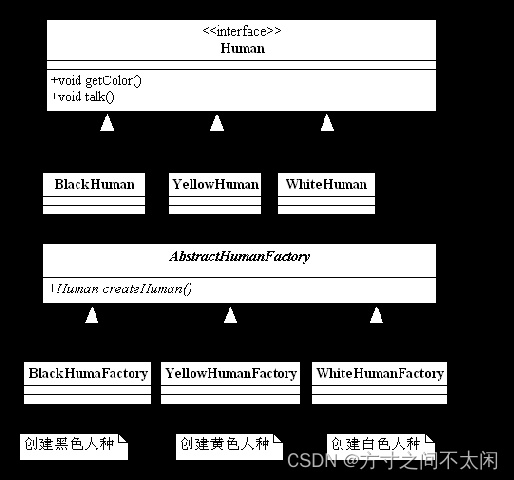
多个工厂类的类图
1. 每个人种(具体的产品类)都对应了一个创建者,每个创建者都独立负责创建对应的产品对象,非常符合单一职责原则,按照这种模式我们来看代码变化。
public abstract class AbstractHumanFactory {
public abstract Human createHuman();
}
2. 抽象方法中已经不再需要传递相关参数了,因为每一个具体的工厂都已经非常明确自己的职责:创建自己负责的产品类对象。
黑色人种的创建类(创建工厂)
public class BlackHumanFactory extends AbstractHumanFactory {
public Human createHuman() {
return new BlackHuman();
}
}
黄色人种的创建类(创建工厂)
public class YellowHumanFactory extends AbstractHumanFactory {
public Human createHuman() {
return new YellowHuman();
}
}
白色人种的创建类(创建工厂)
public class YellowHumanFactory extends AbstractHumanFactory {
public Human createHuman() {
return new WhiteHuman();
}
}
3. 三个具体的创建工厂都非常简单,但是,如果一个系统比较复杂时工厂类也会相应变复杂。场景类 NvWa 修改后的代码如下:
public class NvWa {
public static void main(String[] args) {
// 女娲第一次造人,火候不足,缺陷产品
System.out.println("--造出的第一批人是白色人种--");
Human whiteHuman = (new WhiteHumanFactory()).createHuman();
whiteHuman.getColor();
whiteHuman.talk();
// 女娲第二次造人,火候过足,又是次品,
System.out.println("\n--造出的第二批人是黑色人种--");
Human blackHuman = (new BlackHumanFactory()).createHuman();
blackHuman.getColor();
blackHuman.talk();
// 第三次造人,火候正正好,优品!黄色人种
System.out.println("\n--造出的第三批人是黄色人种--");
Human yellowHuman = (new YellowHumanFactory()).createHuman();
yellowHuman.getColor();
yellowHuman.talk();
}
}运行结果还是相同。我们回顾一下,每一个产品类都对应了一个创建类,好处就是创建类的职责清晰,而且结构简单,但是给扩展性和维护性带来了一定的影响。
为什么这么说呢?
如果要扩展一个产品类,就需要建立一个相应的工厂类,这样就增加了扩展的难度。因为工厂类和产品类的数量相同,维护时需要考虑两个对象之间的关系。当然,在复杂的应用中一般采用多工厂的方法,然后再增加一个协调类,避免调用者与各个子工厂交流,协调类的作用是封装子工厂类,对高层模块提供统一的访问接口。
3.5.3 替代单例模式
单例模式的核心要求就是在内存中只有一个对象,通过工厂方法模式也可以只在内存中生产一个对象。
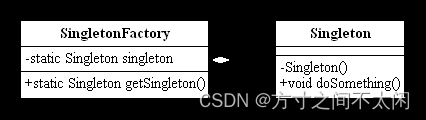
工厂方法模式替代单例模式类图
非常简单的类图,Singleton 定义了一个 private 的无参构造函数,目的是不允许通过 new 的方式创建一个对象。
单例类:
public class Singleton {
// 不允许通过new产生一个对象
private Singleton() {
}
public void doSomething() {
// 业务处理
}
}
Singleton 保证不能通过正常的渠道建立一个对象,那 SingletonFactory 如何建立一个单例对象呢?
答案是通过反射方式创建。
import java.lang.reflect.Constructor;
public class SingletonFactory {
private static Singleton singleton;
static {
try {
Class cl = Class.forName(Singleton.class.getName());
// 获得无参构造
Constructor constructor = cl.getDeclaredConstructor();
// 设置无参构造是可访问的
constructor.setAccessible(true);
// 产生一个实例对象
singleton = (Singleton) constructor.newInstance();
} catch (Exception e) {
// 异常处理
}
}
public static Singleton getSingleton() {
return singleton;
}
}
- 通过获得类构造器,然后设置访问权限,生成一个对象,然后提供外部访问,保证内存中的对象唯一。当然,其他类也可以通过反射的方式建立一个单例对象,确实如此,但是一个项目或团队是有章程和规范的,何况已经提供了一个获得单例对象的方法,为什么还要重新创建一个新对象呢?除非是有人作恶。
- 以上通过工厂方法模式创建了一个单例对象,该框架可以继续扩展,在一个项目中可以产生一个单例构造器,所有需要产生单例的类都遵循一定的规则(构造方法是 private),然后通过扩展该框架,只要输入一个类型就可以获得唯一的一个实例。
3.5.4 延迟初始化
何为延迟初始化(Lazy initialization)?
一个对象被消费完毕后,并不立刻释放,工厂类保持其初始状态,等待再次被使用。延迟初始化是工厂方法模式的一个扩展应用。
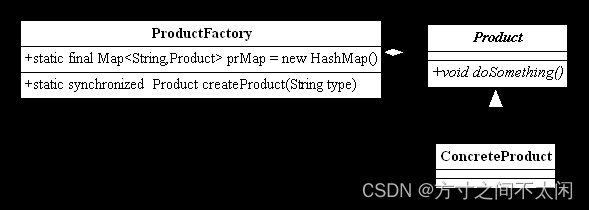
延迟初始化通用类图
- ProductFactory 负责产品类对象的创建工作,并且通过 prMap 变量产生一个缓存,对需要再次被重用的对象保留,Product 和 ConcreteProduct 是一个示例代码。
ProductFactory 代码
import java.util.HashMap;
import java.util.Map;
public class ProductFactory {
private static final Map<String, Product> prMap = new HashMap();
public static synchronized Product createProduct(String type) throws Exception {
Product product = null;
// 如果Map中已经有这个对象
if (prMap.containsKey(type)) {
product = prMap.get(type);
} else {
if (type.equals("Product1")) {
product = new ConcreteProduct1();
} else {
product = new ConcreteProduct2();
}
// 同时把对象放到缓存容器中
prMap.put(type, product);
}
return product;
}
}
1. 代码还比较简单,通过定义一个 Map 容器,容纳所有产生的对象,如果在 Map 容器中已经有的对象,则直接取出返回,如果没有,则根据需要的类型产生一个对象并放入到 Map 容器中,以方便下次调用。
2. 延迟加载框架是可以扩展的,例如限制某一个产品类的最大实例化数量,可以通过判断 Map 中已有的对象数量来实现,这样的处理是非常有意义的,例如 JDBC 连接数据库,都会要求设置一个 MaxConnections 最大连接数量,该数量就是内存中最大实例化的数量。
3. 延迟加载还可以使用在一个对象初始化比较复杂的情况,例如硬件访问,涉及多方面的交互,则可以通过延迟加载降低对象的产生和销毁带来的复杂性。
三、抽象工厂模式
首先需要了解下工厂模式和抽象工厂的区别:
- 工厂方法模式是生产单个同类型的不同产品,例如戴尔电脑,苹果电脑。
- 而抽象工厂模式生产的是多个不同类型的不同产品,所以必须将共同点抽象出来,例如戴尔 CPU,苹果 CPU,抽象的接口就是 CPU 。(再比如:戴尔 GPU,苹果 GPU,抽象的接口就是 GPU)。
这是为了遵守面向对象的原则之一,面向接口编程而不是内容编程。
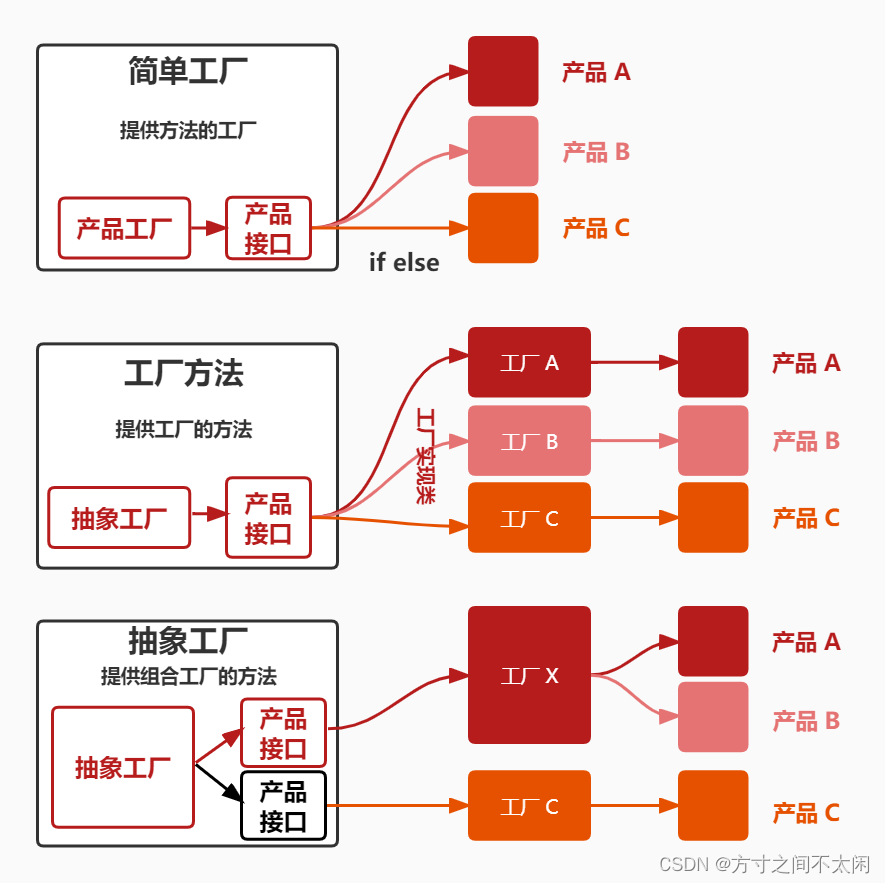
简单工厂:提供方法的工厂,比如排队去买面,只有一个窗口,具体什么面交由窗口内打饭阿姨决定,通过 if-else 判断得到。
工厂方法:提供工厂的方法,比如买面,买什么面去什么窗口,选择权交由用户决定。
组合窗口:提供组合工厂的方法,将不同类型的不同方法的共同点抽取出来进行划分。
3.1 抽象工厂
抽象工厂也可以称作其他工厂的工厂,它可以在抽象工厂中创建出其他工厂,与工厂模式一样,都是用来解决接口选择的问题,同样都属于创建型模式,比如,五菱公司既可以生产汽车也可以生产口罩。
3.2 问题背景
很多初创团队的蛮荒期,并没有完整的底层服务。
团队在初建时业务体量不大,在预估的系统服务 QPS 较低、系统压力较小、并发访问量少、近一年没有大动作等条件下,结合快速起步、时间紧迫、成本投入的因素,并不会投入特别多的研发资源构建出非常完善的系统架构。
就像对 Redis 的使用,可能最开始只需要一个单机就可以满足现状。但随着业务超预期的快速发展,系统的负载能力也要随之跟上,原有的单机 Redis 已经无法满足系统的需要。
这时就需要建设或者更换更为健壮的 Redis 集群服务,在这个升级的过程中是不能停系统的,并且需要平滑过渡。
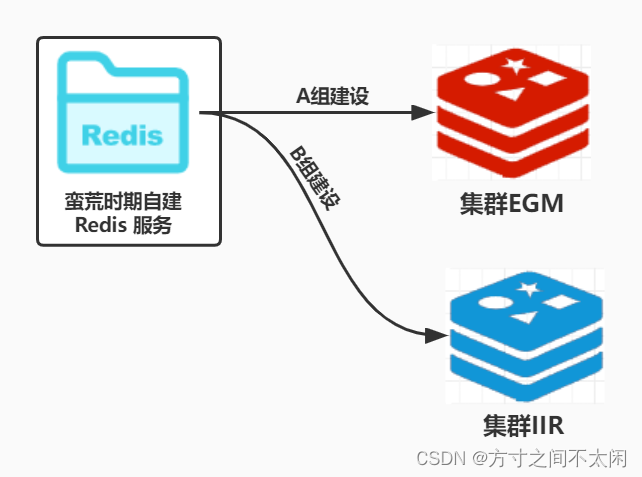
随着系统的升级,可以预见的问题有如下几种:
- 很多服务用到了 `Redis` ,需要一起升级到集群。
- 需要兼容集群 A 和集群 B,便于后续的灾备,并及时切换集群。
- 两套集群提供的接口和方法各有差异,需要进行适配。
- 不能影响目前正常运行的系统。
- 虽然升级是必须要做的,但怎样执行却显得非常重要。
该场景工程包含如下信息:

在业务初期,单机 Redis 服务工具类 RedisUtils 主要负责的是提供早期Redis 的使用。
在业务初期,单机 Redis 服务功能类 CacheService 接口以及它对应的实现类 CacheServiceImpl。
随着后续业务的发展,新增加两套 Redis 集群 EGM、IIR ,作为互备使用。
Redis 单机服务 RedisUtils:
/**
* 模拟最开始使用的Redis服务,单机的。
*/
public class RedisUtils {
private Logger logger = LoggerFactory.getLogger(RedisUtils.class);
private Map<String, String> dataMap = new ConcurrentHashMap<String, String>();
public String get(String key) {
logger.info("Redis获取数据 key:{}", key);
return dataMap.get(key);
}
public void set(String key, String value) {
logger.info("Redis写入数据 key:{} val:{}", key, value);
dataMap.put(key, value);
}
public void set(String key, String value, long timeout, TimeUnit timeUnit) {
logger.info("Redis写入数据 key:{} val:{} timeout:{} timeUnit:{}", key, value, timeout, timeUnit.toString());
dataMap.put(key, value);
}
public void del(String key) {
logger.info("Redis删除数据 key:{}", key);
dataMap.remove(key);
}
}
Redis 集群服务 EGM:
/**
* 模拟Redis缓存服务,EGM
*/
public class EGM {
private Logger logger = LoggerFactory.getLogger(EGM.class);
private Map<String, String> dataMap = new ConcurrentHashMap<String, String>();
public String gain(String key) {
logger.info("EGM获取数据 key:{}", key);
return dataMap.get(key);
}
public void set(String key, String value) {
logger.info("EGM写入数据 key:{} val:{}", key, value);
dataMap.put(key, value);
}
public void setEx(String key, String value, long timeout, TimeUnit timeUnit) {
logger.info("EGM写入数据 key:{} val:{} timeout:{} timeUnit:{}", key, value, timeout, timeUnit.toString());
dataMap.put(key, value);
}
public void delete(String key) {
logger.info("EGM删除数据 key:{}", key);
dataMap.remove(key);
}
}
这里模拟第一个 Redis 集群服务,需要注意观察这里的方法名称及入参信息,与使用单体 Redis 服务时是不同的。有点像 A 用 mac 系统,B 用 Windows 系统,虽然可以做一样的事,但操作方法不同。
Redis 集群服务 IIR:
/**
* 模拟Redis缓存服务,IIR
*/
public class IIR {
private Logger logger = LoggerFactory.getLogger(IIR.class);
private Map<String, String> dataMap = new ConcurrentHashMap<String, String>();
public String get(String key) {
logger.info("IIR获取数据 key:{}", key);
return dataMap.get(key);
}
public void set(String key, String value) {
logger.info("IIR写入数据 key:{} val:{}", key, value);
dataMap.put(key, value);
}
public void setExpire(String key, String value, long timeout, TimeUnit timeUnit) {
logger.info("IIR写入数据 key:{} val:{} timeout:{} timeUnit:{}", key, value, timeout, timeUnit.toString());
dataMap.put(key, value);
}
public void del(String key) {
logger.info("IIR删除数据 key:{}", key);
dataMap.remove(key);
}
}
这是另一套 Redis 集群服务,有时在企业开发中可能有两套服务做互相备份。这里也是为了模拟,所以添加两套实现同样功能的不同服务,主要体现抽象工厂模式在这里发挥的作用。
综上可以看到,目前的系统中已经在大量地使用 Redis 服务,但是因为系统不能满足业务的快速发展,因此需要迁移到集群服务中。而这时有两套集群服务需要兼容使用,又要满足所有的业务系统改造且不能影响线上使用。
接下来介绍在模拟的案例中,对单体 Redis 服务的使用方式。后续会通过两种方式将这部分代码扩展为使用 Redis 集群服务。
定义 Redis 使用接口:
public interface CacheService {
String get(final String key);
void set(String key, String value);
void set(String key, String value, long timeout, TimeUnit timeUnit);
void del(String key);
}
实现 Redis 的使用接口:
public class CacheServiceImpl implements CacheService {
private RedisUtils redisUtils = new RedisUtils();
public String get(String key) {
return redisUtils.get(key);
}
public void set(String key, String value) {
redisUtils.set(key, value);
}
public void set(String key, String value, long timeout, TimeUnit timeUnit) {
redisUtils.set(key, value, timeout, timeUnit);
}
public void del(String key) {
redisUtils.del(key);
}
}3.3 违背设计模式实现
如果不从全局的升级改造考虑,仅仅是升级自己的系统,那么最快的方式是添加 if…else,把 Redis 集群的使用添加进去。
再通过在接口中添加一个使用的 Redis 集群类型,判断当下调用 Redis 时应该 使用哪个集群。
可以说这样的改造非常不好,因为这样会需要所有的研发人员改动代码升级。不仅工作量非常大,而且可能存在非常高的风险。这里为了对比代码结构,会先用这种方式升级 Redis 集群服务。

在这个工程结构中只有两个类,一个是定义缓存使用的接口 CacheService,另一个是它的实现类 CacheServiceImpl。
因为这里选择的是在接口中添加集群类型,判断使用哪个集群,所以需要重新定义接口,并实现新的集群服务类。
if…else 实现需求
/**
* 升级后,使用多套Redis集群服务,同时兼容以前单体Redis服务
*/
public class CacheClusterServiceImpl implements CacheService {
private RedisUtils redisUtils = new RedisUtils();
private EGM egm = new EGM();
private IIR iir = new IIR();
public String get(String key, int redisType) {
if (1 == redisType) {
return egm.gain(key);
}
if (2 == redisType) {
return iir.get(key);
}
return redisUtils.get(key);
}
public void set(String key, String value, int redisType) {
if (1 == redisType) {
egm.set(key, value);
return;
}
if (2 == redisType) {
iir.set(key, value);
return;
}
redisUtils.set(key, value);
}
public void set(String key, String value, long timeout, TimeUnit timeUnit, int redisType) {
if (1 == redisType) {
egm.setEx(key, value, timeout, timeUnit);
return;
}
if (2 == redisType) {
iir.setExpire(key, value, timeout, timeUnit);
return;
}
redisUtils.set(key, value, timeout, timeUnit);
}
public void del(String key, int redisType) {
if (1 == redisType) {
egm.delete(key);
return;
}
if (2 == redisType) {
iir.del(key);
return;
}
redisUtils.del(key);
}
}
这种方式的代码升级并不复杂,看上去也比较简单。
主要包括如下内容:
- 给接口添加 `Redis` 集群使用类型,以控制使用哪套集群服务。
- 如果类型是 1,则使用 EGM 集群;如果类型是 2,则使用 IIR 集群,这在各方法中都有所体现。
- 因为要体现出 Redis 集群升级的过程,所以这里保留了单体 Redis 的使用方式。如果用户传递的 redisType 是不存在的,则会使用 RedisUtils 的方式调用 Redis 服务。这也是一种兼容逻辑,兼容升级过程。
测试验证:
public class ApiTest {
private Logger logger = LoggerFactory.getLogger(ApiTest.class);
@Test
public void test_CacheServiceAfterImpl() {
CacheService cacheService = new CacheClusterServiceImpl();
cacheService.set("user_name_01", "Yolo", 1);
String val01 = cacheService.get("user_name_01", 1);
logger.info("缓存集群升级,测试结果:{}", val01);
}
}
==这样的方式需要整个研发组一起硬编码,不易于维护,也增加了测试难度和未知风险==
3.4 抽象工厂模式重构代码
接下来使用抽象工厂模式优化代码,也是一次代码重构。
在前文介绍过,抽象工厂的实质就是用于创建工厂的工厂。
可以理解为有三个物料加工车间,其中任意两个都可以组合出一个新的生产工厂,用于装备汽车或缝纫机。
另外,这里会使用代理类的方式实现抽象工厂的创建过程。
而两个 Redis 集群服务相当于两个车间,两个车间可以构成两个工厂。
通过代理类的实现方式,可以非常方便地实现 Redis 服务的升级,并且可以在真实的业务场景中做成一个引入的中间件,给各个需要升级的系统使用。
这里还有非常重要的一点,集群 EGM 和集群 IIR 在部分方法提供上略有不同,如方法名和参数,因此需要增加一个适配接口。
最终使用这个适配接口承接两套集群服务,做到统一的服务输出。

抽象工厂代码类关系图:

结合以上抽象工厂的工程结构和类关系,简要介绍这部分代码包括的核心内容。整个工程包结构分为三块:工厂包(factory)、工具包(util)和车间包(workshop)。
- 工厂包:JDKProxyFactory、JDKInvocationHandler 两个类是代理类的定义和实现,这部分代码主要通过代理类和反射调用的方式获取工厂及方法调用。
- 工具包:ClassLoaderUtils 类主要用于支撑反射方法调用中参数的处理。
- 车间包:EGMCacheAdapter、IIRCacheAdapter 两个类主要是通过适配器的方式使用两个集群服务。把两个集群服务作为不同的车间,再通过抽象的代理工厂服务把每个车间转换为对应的工厂。
这里需要强调一点,抽象工厂并不一定必须使用目前的方式实现。这种使用代理和反射的方式是为了实现一个中间件服务,给所有需要升级 Redis 集群的系统使用。在不同的场景下,会有很多不同的变种方式实现抽象工厂。
定义集群适配器接口:
/**
* 车间适配器
*/
public interface ICacheAdapter {
String get(String key);
void set(String key, String value);
void set(String key, String value, long timeout, TimeUnit timeUnit);
void del(String key);
}
适配器接口的作用是包装两个集群服务,在前面已经提到这两个集群服务在一些接口名称和入参方面各不相同,所以需要进行适配。同时在引入适配器后,也可以非常方便地扩展。
实现集群适配器接口:
public class EGMCacheAdapter implements ICacheAdapter {
private EGM egm = new EGM();
public String get(String key) {
return egm.gain(key);
}
public void set(String key, String value) {
egm.set(key, value);
}
public void set(String key, String value, long timeout, TimeUnit timeUnit) {
egm.setEx(key, value, timeout, timeUnit);
}
public void del(String key) {
egm.delete(key);
}
}public class IIRCacheAdapter implements ICacheAdapter {
private IIR iir = new IIR();
public String get(String key) {
return iir.get(key);
}
public void set(String key, String value) {
iir.set(key, value);
}
public void set(String key, String value, long timeout, TimeUnit timeUnit) {
iir.setExpire(key, value, timeout, timeUnit);
}
public void del(String key) {
iir.del(key);
}
}
如果是两个集群服务的统一包装,可以看到这些方法名称或入参都已经统一。例如,IIR 集群的 iir.setExpire 和 EGM 集群的 egm.setEx 都被适配成一个方法名称——set 方法。
代理抽象工厂 JDKProxyFactory:
public class JDKProxyFactory {
public static <T> T getProxy(Class<T> cacheClazz, Class<? extends ICacheAdapter> cacheAdapter) throws Exception {
InvocationHandler handler = new JDKInvocationHandler(cacheAdapter.newInstance());
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
return (T) Proxy.newProxyInstance(classLoader, new Class[]{cacheClazz}, handler);
}
}
这里有一点非常重要,就是为什么选择代理方式实现抽象工厂。因为要把原单体 Redis 服务升级为两套 Redis 集群服务,在不破坏原有单体 Redis 服 务 和 实 现 类 的 情 况 下 , 也 就 是 cn-bugstack-design-5.0-0 的 CacheServiceImpl,通过一个代理类的方式实现一个集群服务处理类,就可以非常方便地在 Spring、SpringBoot 等框架中通过注 入的方式替换原有的 CacheServiceImpl 实现。
这样中间件设计思路的实现方式具备了良好的插拔性,并可以达到多组集群同时使用和平滑切换的目的。
getProxy 方法的两个入参的作用如下:
- Class cacheClazz:在模拟的场景中,不同的系统使用的 Redis 服务类名可能有所不同,通过这样的方式便于实例化后的注入操作。
- Class<?extendsICacheAdapter>cacheAdapter:这个参数用于决定实例化哪套集群服务使用 Redis 功能。
反射调用方法 JDKInvocationHandler:
public class JDKInvocationHandler implements InvocationHandler {
private ICacheAdapter cacheAdapter;
public JDKInvocationHandler(ICacheAdapter cacheAdapter) {
this.cacheAdapter = cacheAdapter;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return ICacheAdapter.class.getMethod(method.getName(), ClassLoaderUtils.getClazzByArgs(args)).invoke(cacheAdapter, args);
}
}
这部分是工厂被代理实现后的核心处理类,主要包括如下功能:
- 相同适配器接口 ICacheAdapter 的不同 Redis 集群服务实现,其具体调用会在这里体现。
- 在反射调用过程中,通过入参获取需要调用的方法名称和参数,可以调用对应 Redis 集群中的方法。
抽象工厂搭建完成了,这部分抽象工厂属于从中间件设计中抽取出来的最核心的内容,如果需要在实际的业务中使用,则需要扩充相应的代码,如注入的设计、配置的读取、相关监控和缓存使用开关等。
测试验证:
public class ApiTest {
private Logger logger = LoggerFactory.getLogger(ApiTest.class);
@Test
public void test_CacheService() throws Exception {
CacheService proxy_EGM = JDKProxyFactory.getProxy(CacheService.class, EGMCacheAdapter.class);
proxy_EGM.set("user_name_01", "Yolo");
String val01 = proxy_EGM.get("user_name_01");
logger.info("缓存服务 EGM 测试,proxy_EGM.get 测试结果:{}", val01);
CacheService proxy_IIR = JDKProxyFactory.getProxy(CacheService.class, IIRCacheAdapter.class);
proxy_IIR.set("user_name_01", "Yolo");
String val02 = proxy_IIR.get("user_name_01");
logger.info("缓存服务 IIR 测试,proxy_IIR.get 测试结果:{}", val02);
}
}
> 单元测试这里传入的是 CacheService.class,原代码里被代理的接口是 CacheService , 不 是 ICacheAdapter。这个案例目的是把单机使用的 CacheService 接口,用代理的方式,无感地替换成 ICacheAdapter 的集群方式,
所以被代理的接口是 CacheService(被替换者),ICacheAdapter 的实现类是真正干活的人(顶替者);
> 单元测试中 test_CacheService 里面可以把 CacheService 类替换成 ICacheAdapter,照样可以运行:替换后被代理的接口变成了 ICacheAdapter,
也就是 ICacheAdapter 的每个接口方法,都被 ICacheAdapter 的实现类 (getProxy()方法的第二个入参)顶替干活了,实现类去干接口的活当然可以跑通啦。
在测试方法中提供了两套集群的工厂获取及相应方法的使用。
通 过 代 理 的 方 式
JDKProxyFactory.getProxy ( CacheService.class ,IIRCacheAdapter.class);获取相应的工厂。
这里获取的过程相当于从车间中组合出新的工厂。
最终在实际的使用中交给Spring进行Bean注入,通过这样的方式升级服务集群,就不需要所有的研发人员硬编码了。
即使有任何问题,也可以回退到原有的实现方式里。这种可插拔服务的优点是易于维护和可扩展。
3.5 总结
抽象工厂模式要解决的是在一个产品族存在多个不同类型的产品(Redis 集群、操作系统)的情况下选择接口的问题。
而这种场景在业务开发中也非常多见,只不过可能有时候没有将它们抽象出来。如果知道在什么场景下可以通过抽象工程优化代码,那么在代码层级结构以及满足业务需求方面,可以得到很好的完成功能实现并提升扩展性和优雅度。
设计模式的使用满足了单一职责、开闭原则和解耦等要求。
如果说有什么缺点,那就是随着业务的场景功能不断拓展,可能会加大类实现上的复杂度。
但随着其他设计方式的引入,以及代理类和自动生成加载的方式,这种设计上的欠缺也可以解决。
四、单例模式
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
注意:
1. 单例类只能有一个实例。
2. 单例类必须自己创建自己的唯一实例。
3. 单例类必须给所有其他对象提供这一实例。
主要解决:一个全局使用的类频繁地创建与销毁。
何时使用:当您想控制实例数目,节省系统资源的时候。
如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
关键代码:构造函数是私有的。
4.1 优点
1. 在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
2. 避免对资源的多重占用(比如写文件操作)。
4.2 缺点
没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
单例模式的应用场景:
1. 在应用场景中,某类只要求生成一个对象的时候,如一个班中的班长、每个人的身份证号等。
2. 当对象需要被共享的场合。由于单例模式只允许创建一个对象,共享该对象可以节省内存,并加快对象访问速度。如 Web 中的配置对象、数据库的连接池等。
3. 当某类需要频繁实例化,而创建的对象又频繁被销毁的时候,如多线程的线程池、网络连接池等。
实现:
4.3 懒汉式单例
//懒汉式单例类.在第一次调用的时候实例化自己
public class Singleton {
private Singleton() {}
private static Singleton single=null;
//静态工厂方法
public static Singleton getInstance() {
if (single == null) {
single = new Singleton();
}
return single;
}
}
Singleton 通过将构造方法限定为 private 避免了类在外部被实例化,在同一个虚拟机范围内,Singleton 的唯一实例只能通过 getInstance()方法访问。
(事实上,通过 Java 反射机制是能够实例化构造方法为 private 的类的,那基本上会使所有的 Java 单例实现失效。此问题在此处不做讨论,姑且掩耳盗铃地认为反射机制不存在。)
但是以上懒汉式单例的实现没有考虑线程安全问题,它是线程不安全的,并发环境下很可能出现多个 Singleton 实例,要实现线程安全,有以下三种方式,都是对 getInstance 这个方法改造,保证了懒汉式单例的线程安全,如果你第一次接触单例模式,对线程安全不是很了解,可以先跳过下面这三小条,去看饿汉式单例,等看完后面再回头考虑线程安全的问题:
- 在 getInstance 方法上加同步
public static synchronized Singleton getInstance() {
if (single == null) {
single = new Singleton();
}
return single;
}
- 双重检查锁定
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
- 静态内部类
public class Singleton {
private static class LazyHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
这种比上面 1、2 都好一些,既实现了线程安全,又避免了同步带来的性能影响。
4.4 饿汉式单例
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
private Singleton1() {}
private static final Singleton1 single = new Singleton1();
//静态工厂方法
public static Singleton1 getInstance() {
return single;
}
}
饿汉式在类创建的同时就已经创建好一个静态的对象供系统使用,以后不再改变,所以天生是线程安全的。
4.5 登记式单例(可忽略)
//类似Spring里面的方法,将类名注册,下次从里面直接获取。
public class Singleton3 {
private static Map<String,Singleton3> map = new HashMap<String,Singleton3>();
static{
Singleton3 single = new Singleton3();
map.put(single.getClass().getName(), single);
}
//保护的默认构造子
protected Singleton3(){}
//静态工厂方法,返还此类惟一的实例
public static Singleton3 getInstance(String name) {
if(name == null) {
name = Singleton3.class.getName();
System.out.println("name == null"+"--->name="+name);
}
if(map.get(name) == null) {
try {
map.put(name, (Singleton3) Class.forName(name).newInstance());
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
return map.get(name);
}
//一个示意性的商业方法
public String about() {
return "Hello, I am RegSingleton.";
}
public static void main(String[] args) {
Singleton3 single3 = Singleton3.getInstance(null);
System.out.println(single3.about());
}
}
登记式单例实际上维护了一组单例类的实例,将这些实例存放在一个 Map(登记薄)中,对于已经登记过的实例,则从 Map 直接返回,对于没有登记的,则先登记,然后返回。
这里我对登记式单例标记了可忽略,我的理解来说,首先它用的比较少,另外其实内部实现还是用的饿汉式单例,因为其中的 static 方法块,它的单例在类被装载的时候就被实例化了。
4.6 饿汉式和懒汉式区别
从名字上来说,饿汉和懒汉,饿汉就是类一旦加载,就把单例初始化完成,保证 getInstance 的时候,单例是已经存在的了,而懒汉比较懒,只有当调用 getInstance 的时候,才回去初始化这个单例。
另外从以下两点再区分以下这两种方式:
1. 线程安全:
饿汉式天生就是线程安全的,可以直接用于多线程而不会出现问题,懒汉式本身是非线程安全的,为了实现线程安全有几种写法,分别是上面的 1、2、3,这三种实现在资源加载和性能方面有些区别。
2. 资源加载和性能:
饿汉式在类创建的同时就实例化一个静态对象出来,不管之后会不会使用这个单例,都会占据一定的内存,但是相应的,在第一次调用时速度也会更快,因为其资源已经初始化完成,而懒汉式顾名思义,会延迟加载,在第一次使用该单例的时候才会实例化对象出来,第一次调用时要做初始化,如果要做的工作比较多,性能上会有些延迟,之后就和饿汉式一样了。
至于 1、2、3 这三种实现又有些区别:
第 1 种,在方法调用上加了同步,虽然线程安全了,但是每次都要同步,会影响性能,毕竟 99%的情况下是不需要同步的。
第 2 种,在 getInstance 中做了两次 null 检查,确保了只有第一次调用单例的时候才会做同步,这样也是线程安全的,同时避免了每次都同步的性能损耗。
第 3 种,利用了 classloader 的机制来保证初始化 instance 时只有一个线程,所以也是线程安全的,同时没有性能损耗,所以一般我倾向于使用这一种。
什么是线程安全?
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
或者说:一个类或者程序所提供的接口对于线程来说是原子操作,或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题,那就是线程安全的。
应用
以下是一个单例类使用的例子,以懒汉式为例,这里为了保证线程安全,使用了双重检查锁定的方式:
public class TestSingleton {
String name = null;
private TestSingleton() {
}
private static volatile TestSingleton instance = null;
public static TestSingleton getInstance() {
if (instance == null) {
synchronized (TestSingleton.class) {
if (instance == null) {
instance = new TestSingleton();
}
}
}
return instance;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void printInfo() {
System.out.println("the name is " + name);
}
}public class TMain {
public static void main(String[] args){
TestStream ts1 = TestSingleton.getInstance();
ts1.setName("jason");
TestStream ts2 = TestSingleton.getInstance();
ts2.setName("0539");
ts1.printInfo();
ts2.printInfo();
if(ts1 == ts2){
System.out.println("创建的是同一个实例");
}else{
System.out.println("创建的不是同一个实例");
}
}
}
结论:
由结果可以得知单例模式为一个面向对象的应用程序提供了对象惟一的访问点,不管它实现何种功能,整个应用程序都会同享一个实例对象。
对于单例模式的几种实现方式,知道饿汉式和懒汉式的区别,线程安全,资源加载的时机,还有懒汉式为了实现线程安全的 3 种方式的细微差别。
五、原型模式
5.1 定义:
给出一个原型对象实例来指定创建对象的类型,并通过拷贝这些原型的方式来创建新的对象。
原型模式是简单程度仅次于单例模式的简单模式,它的定义可以简单理解为对象的拷贝,通过拷贝的方式创建一个已有对象的新对象,这就是原型模式。
在原型模式中主要的任务是实现一个接口,这个接口具有一个 clone 方法可以实现拷贝对象的功能,也就是上图中的 ProtoType 接口。由于在 Java 语言中,JDK 已经默认给我们提供了一个 Coneable 接口,所以我们不需要手动去创建 ProtoType 接口类了。Coneable 接口在 java 中是一个标记接口,它并没有任何方法,只有实现了 Coneable 接口的类在 JVM 当中才有可能被拷贝。既然 Coneable 接口没有任何方法,那 clone 方法从哪里来呢?由于在 java 中所有的类都是 Object 类的子类,所以我们只需要重写来自 Object 类的 clone 方法就可以了。
示例代码如下:
public class ProtoTypeClass implements Cloneable {
@Override
protected ProtoTypeClass clone() throws CloneNotSupportedException {
return (ProtoTypeClass)super.clone();
}
}public class Client {
public static void main(String[] args) {
ProtoTypeClass protoType = new ProtoTypeClass();
try {
//通过clone生成一个ProtoTypeClass类型的新对象
ProtoTypeClass cloneObject = protoType.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
原型模式的代码很简单,只需要实现 Cloneable 接口,然后覆写 clone 方法,调用 super.clone 就可以实现简单的对象复制了。
值得注意的是,使用 clone 方法创建的新对象的构造函数是不会被执行的,也就是说会绕过任何构造函数(有参和无参),因为 clone 方法的原理是从堆内存中以二进制流的方式进行拷贝,直接分配一块新内存。
5.2 深拷贝和浅拷贝
5.2.1 浅拷贝
浅拷贝只会拷贝对象本身相关的基本类型数据,直接看示例代码:
public class EasyCopyExample implements Cloneable {
private List<String> nameList = new ArrayList<>();
@Override
protected EasyCopyExample clone() throws CloneNotSupportedException {
return (EasyCopyExample) super.clone();
}
public void addName(String name) {
nameList.add(name);
}
public void printNames() {
for (String name : nameList) {
System.out.println(name);
}
}
}public class Client {
public static void main(String[] args) {
try {
//创建一个原始对象并添加一个名字
EasyCopyExample originalObject = new EasyCopyExample();
originalObject.addName("test1");
//克隆一个新对象并添加一个名字
EasyCopyExample cloneObject = originalObject.clone();
cloneObject.addName("test2");
//打印原始对象和新对象的name
originalObject.printNames();
System.out.println();
cloneObject.printNames();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
可以看到通过 clone()创建的新对象与之前的对象都打印出了相同的 name, 这说明新对象与原始对象是共用 nameList 的这个成员变量的,这就是浅拷贝,拷贝之后的对象会和原始对象共用一部分数据,这样会给使用上带来困扰,因为一个变量不是静态的但却可以多个对象同时修改它的值。在 java 中除了基本数据类型(int long 等)和 String 类型,数组引用和对象引用的成员变量都不会被拷贝。
5.2.2 深拷贝
为了避免上面的情况,我们就需要对具有 clone 方法不支持拷贝的数据的对象自行处理,将上述示例代码修改如下:
public class DeepCopyExample implements Serializable {
private List<String> nameList = new ArrayList<>();
private String name = "张三";
private int age = 23;
public DeepCopyExample deepClone() throws IOException, ClassNotFoundException {
//将对象写到流里
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
//从流里读回来
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (DeepCopyExample) ois.readObject();
}
public void addName(String name) {
nameList.add(name);
}
public void printNames() {
for (String name : nameList) {
System.out.println(name);
}
System.out.println(name);
System.out.println(age);
}
}public class Client {
public static void main(String[] args) {
try {
//创建一个原始对象并添加一个名字
DeepCopyExample originalObject = new DeepCopyExample();
originalObject.addName("test1");
//克隆一个新对象并添加一个名字
DeepCopyExample cloneObject = originalObject.deepClone();
cloneObject.addName("test2");
//打印原始对象和新对象的name
originalObject.printNames();
System.out.println("-----------");
cloneObject.printNames();
} catch (Exception e) {
e.printStackTrace();
}
}
}
上面的代码是通过序列化和反序列化的方式实现对象的拷贝的,通过实现 Serializable 接口,对象可以写到一个流里(序列化),再从流里读回来(反序列化),便可以重建对象。可以看到输出结果中新对象保留了原始对象的基本类型数据(name 和 age),同时针对新对象操作 List 数据不会影响原始对象,这说明跟原始对象是完全隔离开了,是两个完全独立的对象。
能够使用这种方式做的前提是,对象以及对象内部所有引用到的对象都是可序列化的,否则,就需要仔细考察那些不可序列化的对象可否设成 transient,从而将之排除在复制过程之外。
有一些对象,比如线程(Thread)对象或 Socket 对象,是不能简单复制或共享的。不管是使用浅度克隆还是深度克隆,只要涉及这样的间接对象,就必须把间接对象设成 transient 而不予复制;或者由程序自行创建出相当的同种对象。
5.3 原型模式的优缺点
优点很明显就是可以绕过繁琐的构造函数,快速创建对象,且比直接 new 一个对象性能优良,因为是直接内存二进制流拷贝。原型模式非常适合于你想要向客户隐藏实例创建的创建过程的场景,提供客户创建未知类型对象的选择。
原型模式最主要的缺点是每一个类都必须配备一个克隆方法。配备克隆方法需要对类的功能进行通盘考虑,这对于全新的类来说不是很难,而对于已经有的类不一定很容易,特别是当一个类引用不支持序列化的间接对象,或者引用含有循环结构的时候。
六、建造者模式
6.1 定义
将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
6.2 实用范围
1. 当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时。
2. 当构造过程必须允许被构造的对象有不同表示时。
在这样的设计模式中,有以下几个角色:
1. Builder:为创建一个产品对象的各个部件指定抽象接口。
2. ConcreteBuilder:实现 Builder 的接口以构造和装配该产品的各个部件,定义并明确它所创建的表示,并提供一个检索产品的接口。
3. Director:构造一个使用 Builder 接口的对象,指导构建过程。
4. Product:表示被构造的复杂对象。ConcreteBuilder 创建该产品的内部表示并定义它的装配过程,包含定义组成部件的类,包括将这些部件装配成最终产品的接口。
角色 Builder:
public interface PersonBuilder {
void buildHead();
void buildBody();
void buildFoot();
Person buildPerson();
}
角色 ConcreteBuilder:
public class WomanBuilder implements PersonBuilder {
Person person;
public WomanBuilder() {
person = new Woman();
}
public void buildbody() {
person.setBody(“建造女人的身体");
}
public void buildFoot() {
person.setFoot(“建造女人的脚");
}
public void buildHead() {
person.setHead(“建造女人的头");
}
public Person buildPerson() {
return person;
}
}
角色 Director:
public class PersonDirector {
public Person constructPerson(PersonBuilder pb) {
pb.buildHead();
pb.buildBody();
pb.buildFoot();
return pb.buildPerson();
}
}
角色 Product:
public class Person {
private String head;
private String body;
private String foot;
public String getHead() {
return head;
}
public void setHead(String head) {
this.head = head;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
public String getFoot() {
return foot;
}
public void setFoot(String foot) {
this.foot = foot;
}
}
public class Man extends Person {
public Man(){
System.out.println("开始建造男人");
}
}
public class Woman extends Person {
public Woman(){
System.out.println("开始建造女人");
}
}
测试:
public class Test{
public static void main(String[] args) {
PersonDirector pd = new PersonDirector();
Person womanPerson = pd.constructPerson(new ManBuilder());
Person manPerson = pd.constructPerson(new WomanBuilder());
}
}
建造者模式在使用过程中可以演化出多种形式:
如果具体的被建造对象只有一个的话,可以省略抽象的 Builder 和 Director , 让 ConcreteBuilder 自 己 扮 演 指 导 者 和 建 造 者 双 重 角 色 , 甚 至 ConcreteBuilder 也可以放到 Product 里面实现。
在《Effective Java》书中第二条,就提到“遇到多个构造器参数时要考虑用构建器”,其实这里的构建器就属于建造者模式,只是里面把四个角色都放到具体产品里面了。
上面例子如果只制造男人,演化后如下:
public class Man {
private String head;
private String body;
private String foot;
public String getHead() {
return head;
}
public void setHead(String head) {
this.head = head;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
public String getFoot() {
return foot;
}
public void setFoot(String foot) {
this.foot = foot;
}
}
测试:
public class Test{
public static void main(String[] args) {
ManBuilder builder = new ManBuilder();
Man man = builder.builderMan();
}
}七、代理模式
代理模式:
为一个对象提供一个替身,以控制对这个对象的访问。
即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。
被代理的对象可以是远程对象、创建开销大的对象或需要安全控制的对象。
代理模式有不同的形式主要有三种
- 静态代理
- 动态代理 (JDK 代理、接口代理)
- Cglib 代理
可以在内存动态的创建对象,而不需要实现接口,他是属于动态代理的范畴。
7.1 静态代理
静态代理在使用时需要定义接口或者父类。
被代理对象(即目标对象)与代理对象一起实现相同的接口或者是继承相同父类。
静态代理应用示例

定义一个接口:ITeacherDao
目标对象 TeacherDAO 实现接口 ITeacherDAO
使用静态代理方式就需要在代理对象 TeacherDAOProxy 中也实现 ITeacherDAO
调用的时候通过调用代理对象的方法来调用目标对象。
特别提醒:代理对象与目标对象要实现相同的接口,然后通过调用相同的方法来调用目标对象的方法。
1. 首先根据思路创建一个接口
//接口
interface ITeacherDao {
void teach(); // 授课的方法
}
接下来我们有一个对象实现这个接口,进行具体的授课。
class TeacherDao implements ITeacherDao {
@Override
public void teach() {
System.out.println(" 老师授课中 。。。。。");
}
}
我们不直接调用,而是通过代理调用这个老师的方法,创建一个代理。
//代理对象,静态代理
class TeacherDaoProxy implements ITeacherDao {
// 目标对象,通过接口来聚合
private ITeacherDao target;
//构造器
public TeacherDaoProxy(ITeacherDao target) {
this.target = target;
}
@Override
public void teach() {
System.out.println("开始代理 完成某些操作。。。。。 ");//方法
target.teach();
}
}
接下来让我们使用 demo 体会一下静态代理的使用方式。
public static void main(String[] args) {
// TODO Auto-generated method stub
//创建目标对象(被代理对象)
TeacherDao teacherDao = new TeacherDao();
//创建代理对象, 同时将被代理对象传递给代理对象
TeacherDaoProxy teacherDaoProxy = new TeacherDaoProxy(teacherDao);
//通过代理对象,调用到被代理对象的方法
//即:执行的是代理对象的方法,代理对象再去调用目标对象的方法
teacherDaoProxy.teach();
}
运行结果:
运行结果如下:
开始代理
完成某些操作。。。。。
老师授课中
。。。。。
看起来是使用代理对象的方法,但本质上还是使用目标对象的方法。
静态代理优缺点
优点:在不修改目标对象的功能前提下, 能通过代理对象对目标功能扩展。
缺点:因为代理对象需要与目标对象实现一样的接口,所以会有很多代理类。
一旦接口增加方法,目标对象与代理对象都要维护。
7.2 动态代理
代理对象,不需要实现接口,但是目标对象要实现接口,否则不能用动态代理。
代理对象的生成,是利用 JDK 的 API,动态的在内存中构建代理对象。
动态代理也叫做:JDK 代理、接口代理。
JDK 中生成代理对象的 API。
代理类所在包:java.lang.reflect.Proxy
JDK 实现代理只需要使用 newProxyInstance 方法,但是该方法需要接收三个参数,完整的写法是:
static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces,InvocationHandler h ){}
动态代理应用案例
我们将将前面的静态代理改进成动态代理模式(即:JDK 代理模式)

接下来我们就根据思路创建授课接口:ITeacherDao
//接口
interface ITeacherDao {
void teach(); // 授课的方法
}
接下来我们有一个对象实现这个接口,进行具体的授课。
class TeacherDao implements ITeacherDao {
@Override
public void teach() {
System.out.println(" 老师授课中 。。。。。");
}
}
我们通过 API 传入目标对象,返回代理对象调用这个老师的方法。
class ProxyFactory {
//维护一个目标对象 , Object
private Object target;
//构造器 对 target 进行初始化
public ProxyFactory(Object target) {
this.target = target;
}
//给目标对象 生成一个代理对象
public Object getProxyInstance() {
//说明
/*
* public static Object newProxyInstance(ClassLoader loader,Class<?>[] interfaces, InvocationHandler h)
* //1. ClassLoader loader : 指定当前目标对象使用的类加载器, 获取加载器的方法固定
* //2. Class<?>[] interfaces: 目标对象实现的接口类型,使用泛型方法确认类型
* //3. InvocationHandler h : 事情处理,执行目标对象的方法时,会触发事情处理器方法, 会把当前执行的目标对象方法作为参数传入
*/
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(),new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("JDK 代理开始~~");
//反射机制调用目标对象的方法
Object returnVal = method.invoke(target, args);
System.out.println("JDK 代理提交");
return returnVal;
}
});
}
}
接下来让我们使用 demo 体会一下动态代理的使用方式。
public static void main(String[] args) {
//创建目标对象
ITeacherDao target = new TeacherDao();
//给目标对象,创建代理对象, 可以转成 ITeacherDao
ITeacherDao proxyInstance = (ITeacherDao)new ProxyFactory(target).getProxyInstance();
// proxyInstance=class com.sun.proxy.$Proxy0 内存中动态生成了代理对象
System.out.println("proxyInstance=" + proxyInstance.getClass());
//通过代理对象,调用目标对象的方法
proxyInstance.teach();
}
运行结果:
proxyInstance=class com.bdqn.it.algorithm.$Proxy0
JDK 代理开始~~
老师授课中
。。。。。
JDK 代理提交
7.3 Cglib 代理
静态代理 和 JDK 代理模式都要求目标对象是实现一个接口。
但是有时候目标对象只是一个单独的对象,并没有实现任何的接口。
这个时候可使用目标对象子类来实现代理这就是 Cglib 代理。
它是在内存中构建一个子类对象从而实现对目标对象功能扩展, 有些书也将 Cglib 代理归属到动态代理。
它一个强大的高性能的代码生成包,它可以在运行期扩展 java 类与实现 java 接口。
它广泛的被许多 AOP 的框架使用,例如 Spring AOP,实现方法拦截。
它是通过底层使用字节码处理框架 ASM 来转换字节码并生成新的类。
在 AOP 编程中如何选择代理模式:
- 目标对象需要实现接口,用 JDK 代理
- 目标对象不需要实现接口,用 Cglib 代理
Cglib 代理模式实现步骤
- asm,jar
- asm-commons.jar
- asm-treejar
- cglib-2.2.jar
需要引入以上 cglib 的 jar 文件。
Cgib 代理模式注意细节
在内存中动态构建子类,注意被代理的类不能为final,否则报错 java.lang.IllegalArgumentException:
目标对象的方法如果为 final/static,那么就不会被拦截与不会执行目标对象的业务方法。
Cgib 代理应用示例
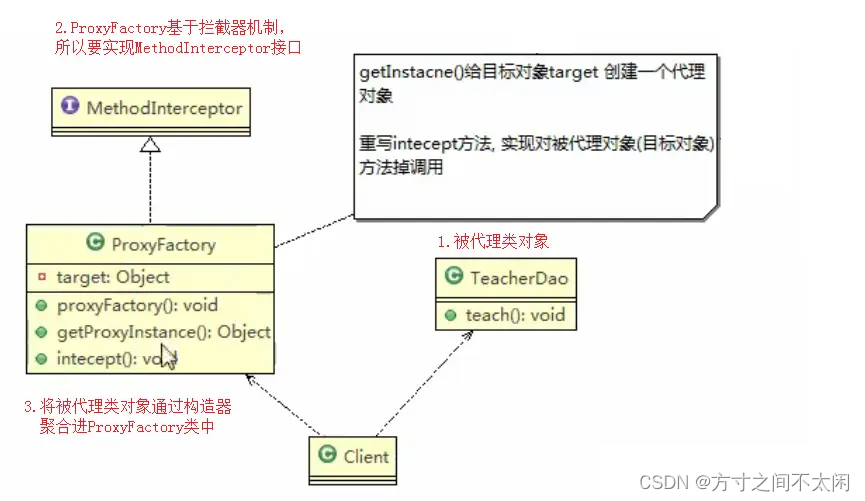
接下来根据我们的思路,创建一个类它无需实现接口。
class TeacherDao{
public void teach() {
System.out.println("老师授课中。。。。 我是Cglib 代理,不需要实现接口");
}
}
我们再创建一个类实现方法拦截器,进行与被代理类的连接聚合。
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
class ProxyFactory implements MethodInterceptor{
//维护一个目标对象
private Object target;
//构造器,传入一个被代理的对象
public ProxyFactory(Object target) {
this.target = target;
}
//返回一个代理对象: 是 target 对象的代理对象
public Object getProxyInstance() {
//1. 创建一个工具类
Enhancer enhancer = new Enhancer();
//2. 设置父类
enhancer.setSuperclass(target.getClass());
//3. 设置回调函数
enhancer.setCallback(this);
//4. 创建子类对象,即代理对象
return enhancer.create();
}
//重写 intercept 方法,会调用目标对象的方法
@Override
public Object intercept(Object arg0, Method method, Object[] args, MethodProxy arg3) throws Throwable {
System.out.println("Cglib 代理模式 ~~ 开始");
Object returnVal = method.invoke(target, args);
System.out.println("Cglib 代理模式 ~~ 提交");
return returnVal;
}
}
接下来让我们使用 demo 体会一下 Cglib 代理的使用方式。
public static void main(String[] args) {
//创建目标对象
TeacherDao target = new TeacherDao();
//获取到代理对象,并且将目标对象传递给代理对象
TeacherDao proxyInstance = (TeacherDao)new ProxyFactory(target).getProxyInstance();
//执行代理对象的方法,触发 intecept 方法,从而实现 对目标对象的调用
String res = proxyInstance.teach();
System.out.println("res=" + res);
}
运行结果:
Cglib 代理开始~~
老师授课中
。。。。 我是 Cglib 代理,不需要实现接口
Cglib 代理提交
7.4 常见代理的变体
- 防火墙代理
内网通过代理穿透防火墙,实现对公网的访问。
- 缓存代理
比如:当请求图片文件等资源时,先到缓存代理取,如果取到资源则 ok,如果取不到资源,再到公网或者数据库取,然后缓存。
- 远程代理
远程对象的本地代表,通过它可以把远程对象当本地对象来调用。远程代理通过网络和真正的远程对象沟通信息。
- 同步代理
主要使用在多线程编程中,完成多线程间同步工作。
八、门面模式
医院的例子
现代的软件系统都是比较复杂的,设计师处理复杂系统的一个常见方法便是将其“分而治之”,把一个系统划分为几个较小的子系统。如果把医院作为一个子系统,按照部门职能,这个系统可以划分为挂号、门诊、划价、化验、收费、取药等。看病的病人要与这些部门打交道,就如同一个子系统的客户端与一个子系统的各个类打交道一样,不是一件容易的事情。
首先病人必须先挂号,然后门诊。如果医生要求化验,病人必须首先划价,然后缴费,才可以到化验部门做化验。化验后再回到门诊室。

上图描述的是病人在医院里的体验,图中的方框代表医院。
解决这种不便的方法便是引进门面模式,医院可以设置一个接待员的位置,由接待员负责代为挂号、划价、缴费、取药等。这个接待员就是门面模式的体现,病人只接触接待员,由接待员与各个部门打交道。

8.1 门面模式的结构
门面模式没有一个一般化的类图描述,最好的描述方法实际上就是以一个例子说明。
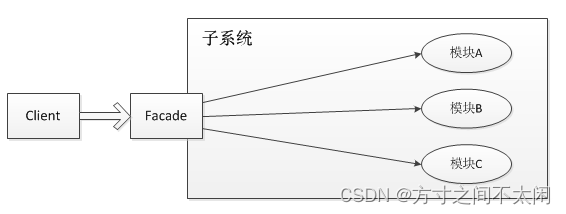
由于门面模式的结构图过于抽象,因此把它稍稍具体点。假设子系统内有三个模块,分别是 ModuleA、ModuleB 和 ModuleC,它们分别有一个示例方法,那么此时示例的整体结构图如下:

在这个对象图中,出现了两个角色:
- 门面(Facade)角色 :客户端可以调用这个角色的方法。此角色知晓相关的(一个或者多个)子系统的功能和责任。在正常情况下,本角色会将所有从客户端发来的请求委派到相应的子系统去。
- 子系统(SubSystem)角色 :可以同时有一个或者多个子系统。每个子系统都不是一个单独的类,而是一个类的集合(如上面的子系统就是由 ModuleA、ModuleB、ModuleC 三个类组合而成)。每个子系统都可以被客户端直接调用,或者被门面角色调用。子系统并不知道门面的存在,对于子系统而言,门面仅仅是另外一个客户端而已。
源代码
子系统角色中的类:
public class ModuleA {
//示意方法
public void testA(){
System.out.println("调用ModuleA中的testA方法");
}
}public class ModuleB {
//示意方法
public void testB(){
System.out.println("调用ModuleB中的testB方法");
}
}public class ModuleC {
//示意方法
public void testC(){
System.out.println("调用ModuleC中的testC方法");
}
}
门面角色类:
public class Facade {
//示意方法,满足客户端需要的功能
public void test(){
ModuleA a = new ModuleA();
a.testA();
ModuleB b = new ModuleB();
b.testB();
ModuleC c = new ModuleC();
c.testC();
}
}
客户端角色类:
public class Client {
public static void main(String[] args) {
Facade facade = new Facade();
facade.test();
}
}
Facade 类其实相当于 A、B、C 模块的外观界面,有了这个 Facade 类,那么客户端就不需要亲自调用子系统中的 A、B、C 模块了,也不需要知道系统内部的实现细节,甚至都不需要知道 A、B、C 模块的存在,客户端只需要跟 Facade 类交互就好了,从而更好地实现了客户端和子系统中 A、B、C 模块的解耦,让客户端更容易地使用系统。
8.2 门面模式的实现
使用门面模式还有一个附带的好处,就是能够有选择性地暴露方法。一个模块中定义的方法可以分成两部分,一部分是给子系统外部使用的,一部分是子系统内部模块之间相互调用时使用的。有了 Facade 类,那么用于子系统内部模块之间相互调用的方法就不用暴露给子系统外部了。
比如,定义如下 A、B、C 模块。
public class Module {
/**
* 提供给子系统外部使用的方法
*/
public void a1(){};
/**
* 子系统内部模块之间相互调用时使用的方法
*/
private void a2(){};
private void a3(){};
}public class ModuleB {
/**
* 提供给子系统外部使用的方法
*/
public void b1(){};
/**
* 子系统内部模块之间相互调用时使用的方法
*/
private void b2(){};
private void b3(){};
}public class ModuleC {
/**
* 提供给子系统外部使用的方法
*/
public void c1(){};
/**
* 子系统内部模块之间相互调用时使用的方法
*/
private void c2(){};
private void c3(){};
}public class ModuleFacade {
ModuleA a = new ModuleA();
ModuleB b = new ModuleB();
ModuleC c = new ModuleC();
/**
* 下面这些是A、B、C模块对子系统外部提供的方法
*/
public void a1(){
a.a1();
}
public void b1(){
b.b1();
}
public void c1(){
c.c1();
}
}
这样定义一个 ModuleFacade 类可以有效地屏蔽内部的细节,免得客户端去调用 Module 类时,发现一些不需要它知道的方法。比如 a2()和 a3()方法就不需要让客户端知道,否则既暴露了内部的细节,又让客户端迷惑。对客户端来说,他可能还要去思考 a2()、a3()方法用来干什么呢?其实 a2()和 a3()方法是内部模块之间交互的,原本就不是对子系统外部的,所以干脆就不要让客户端知道。
一个系统可以有几个门面类
在门面模式中,通常只需要一个门面类,并且此门面类只有一个实例,换言之它是一个单例类。当然这并不意味着在整个系统里只有一个门面类,而仅仅是说对每一个子系统只有一个门面类。或者说,如果一个系统有好几个子系统的话,每一个子系统都有一个门面类,整个系统可以有数个门面类。
为子系统增加新行为
初学者往往以为通过继承一个门面类便可在子系统中加入新的行为,这是错误的。门面模式的用意是为子系统提供一个集中化和简化的沟通管道,而不能向子系统加入新的行为。比如医院中的接待员并不是医护人员,接待员并不能为病人提供医疗服务。
8.3 门面模式的优点
门面模式的优点:
- 松散耦合
门面模式松散了客户端与子系统的耦合关系,让子系统内部的模块能更容易扩展和维护。
- 简单易用
门面模式让子系统更加易用,客户端不再需要了解子系统内部的实现,也不需要跟众多子系统内部的模块进行交互,只需要跟门面类交互就可以了。
- 更好的划分访问层次
通过合理使用 Facade,可以帮助我们更好地划分访问的层次。有些方法是对系统外的,有些方法是系统内部使用的。把需要暴露给外部的功能集中到门面中,这样既方便客户端使用,也很好地隐藏了内部的细节。
九、装饰器模式
装饰器模式(Decorator)是一种结构型模式,顾名思义,就是对已经存在的某些类进行装饰,以此来扩展一些功能。
9.1 应用场景
在不想更改已存在类的核心功能的情况下,想要扩展该类的功能。
模式特征
| 角色 | 说明 | 举栗 |
| ----------------- | ------------------------------------------------------------ | -------------------------------- |
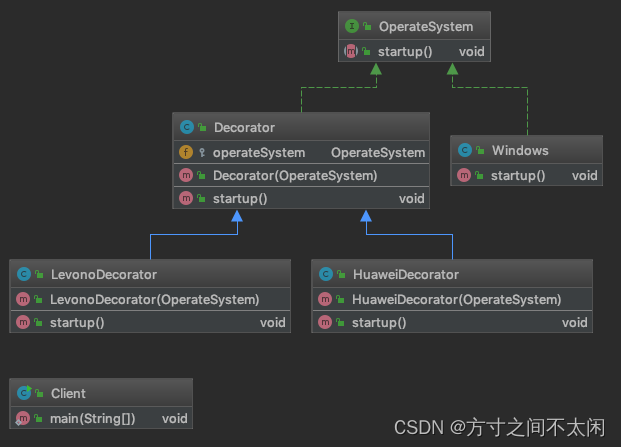
| Component | 统一接口,也是装饰类和被装饰类的基本类型 | OperateSystem |
| ConcreteComponent | 具体实现类,也是被装饰类,他本身是个具有一些功能的完整的类 | Windows |
| Decorator | 装饰类,实现了Component接口的同时还在内部维护了一个ConcreteComponent的实例,并可以通过构造函数初始化。而Decorator本身,通常采用默认实现,他的存在仅仅是一个声明:我要生产出一些用于装饰的子类了。而其子类才是赋有具体装饰效果的装饰产品类 | Decorator |
| ConcreteDecorator | 具体的装饰产品类,每一种装饰产品都具有特定的装饰效果。可以通过构造器声明装饰哪种类型的ConcreteComponent,从而对其进行装饰 | HuaweiDecorator、LevonoDecorator |
UML
9.2 代码实现
- OperateSystem 操作系统
public interface OperateSystem {
void startup();
}
- Windows 具体系统
public class Windows implements OperateSystem {
@Override
public void startup() {
System.out.println("Windows系统启动中...");
}
}
- Decorator 装饰器
public class Decorator implements OperateSystem{
protected OperateSystem operateSystem;
public Decorator(OperateSystem operateSystem) {
this.operateSystem = operateSystem;
}
public void startup(){
operateSystem.startup();
}
}
- HuaweiDecorator 具体装饰器一
public class HuaweiDecorator extends Decorator {
public HuaweiDecorator(OperateSystem operateSystem) {
super(operateSystem);
}
@Override
public void startup() {
System.out.println("华为电脑");
super.startup();
}
}
- LevonoDecorator 具体装饰器二
public class LevonoDecorator extends Decorator {
public LevonoDecorator(OperateSystem operateSystem) {
super(operateSystem);
}
@Override
public void startup() {
System.out.println("联想电脑");
super.startup();
}
}
- 客户端测试代码
public class Client {
public static void main(String[] args) {
//华为装饰器
Decorator decorator = new HuaweiDecorator(new Windows());
decorator.startup();
//联想装饰器
Decorator decorator1 = new LevonoDecorator(new Windows());
decorator1.startup();
}
}
- 结果
华为电脑
Windows 系统启动中...
联想电脑
Windows 系统启动中...
9.2 模式对比
很多刚刚接触设计模式的同学,很容易将装饰器模式和静态代理模式混淆,下面简单说说他们之间的区别,需要用心体会。
对装饰器模式来说,装饰者和被装饰者都实现一个接口。对代理模式来说,代理类和真实处理的类也都实现同一个接口。此外,不论我们使用哪一个模式,都可以很容易地在真实对象的方法前面或者后面加上自定义的方法。
装饰器模式关注于在一个对象上动态地添加方法,而代理模式关注于控制对对象的访问。换句话说,用代理模式,代理类可以对它的客户隐藏一个对象的具体信息。因此当使用代理模式的时候,我们常常在一个代理类中创建一个对象的实例;当使用装饰器模式的时候,我们通常的做法是将原始对象作为一个参数传给装饰器的构造器,简单的说,就是调用者主动将一个对象传入装饰器的构造器,来主动装饰它,调用者知道原始对象的存在。
十、享元模式
10.1 概念
也就是说在一个系统中如果有多个相同的对象,那么只共享一份就可以了,不必每个都去实例化一个对象。比如说一个文本系统,每个字母定一个对象,那么大小写字母一共就是 52 个,那么就要定义 52 个对象。如果有一个 1M 的文本,那么字母是何其的多,如果每个字母都定义一个对象那么内存早就爆了。那么如果要是每个字母都共享一个对象,那么就大大节约了资源。
在 Flyweight 模式中,由于要产生各种各样的对象,所以在 Flyweight(享元)模式中常出现 Factory 模式。Flyweight 的内部状态是用来共享的,Flyweight factory 负责维护一个对象存储池(Flyweight Pool)来存放内部状态的对象。Flyweight 模式是一个提高程序效率和性能的模式,会大大加快程序的运行速度。
应用场合很多,下面举个
10.2 示例
先定义一个抽象的 Flyweight 类:
package Flyweight;
public abstract class Flyweight{
public abstract void operation();
}
实现一个具体类:
package Flyweight;
public class ConcreteFlyweight extends Flyweight{
private String string;
public ConcreteFlyweight(String str){
string = str;
}
public void operation()
{
System.out.println("Concrete---Flyweight : " + string);
}
}
实现一个工厂方法类:
package Flyweight;
import java.util.Hashtable;
public class FlyweightFactory{
private Hashtable flyweights = new Hashtable();//----------------------------1
public FlyweightFactory(){}
public Flyweight getFlyWeight(Object obj){
Flyweight flyweight = (Flyweight) flyweights.get(obj);//----------------2
if(flyweight == null){//---------------------------------------------------3
//产生新的ConcreteFlyweight
flyweight = new ConcreteFlyweight((String)obj);
flyweights.put(obj, flyweight);//--------------------------------------5
}
return flyweight;//---------------------------------------------------------6
}
public int getFlyweightSize(){
return flyweights.size();
}
}
这个工厂方法类非常关键,这里详细解释一下:
在 1 处定义了一个 Hashtable 用来存储各个对象;在 2 处选出要实例化的对象,在 6 处将该对象返回,如果在 Hashtable 中没有要选择的对象,此时变量 flyweight 为 null,产生一个新的 flyweight 存储在 Hashtable 中,并将该对象返回。
最后看看 Flyweight 的调用:
package Flyweight;
import java.util.Hashtable;
public class FlyweightPattern{
FlyweightFactory factory = new FlyweightFactory();
Flyweight fly1;
Flyweight fly2;
Flyweight fly3;
Flyweight fly4;
Flyweight fly5;
Flyweight fly6;
/** *//** Creates a new instance of FlyweightPattern */
public FlyweightPattern(){
fly1 = factory.getFlyWeight("Google");
fly2 = factory.getFlyWeight("Qutr");
fly3 = factory.getFlyWeight("Google");
fly4 = factory.getFlyWeight("Google");
fly5 = factory.getFlyWeight("Google");
fly6 = factory.getFlyWeight("Google");
}
public void showFlyweight(){
fly1.operation();
fly2.operation();
fly3.operation();
fly4.operation();
fly5.operation();
fly6.operation();
int objSize = factory.getFlyweightSize();
System.out.println("objSize = " + objSize);
}
public static void main(String[] args){
System.out.println("The FlyWeight Pattern!");
FlyweightPattern fp = new FlyweightPattern();
fp.showFlyweight();
}
}
运行结果:
Concrete---Flyweight : Google
Concrete---Flyweight : Qutr
Concrete---Flyweight : Google
Concrete---Flyweight : Google
Concrete---Flyweight : Google
Concrete---Flyweight : Google
objSize = 2
我们定义了 6 个对象,其中有 5 个是相同的,按照 Flyweight 模式的定义“Google”应该共享一个对象,在实际的对象数中我们可以看出实际的对象却是只有 2 个。
10.3 总结
Flyweight(享元)模式是如此的重要,因为它能帮你在一个复杂的系统中大量的节省内存空间。在 JAVA 语言中,String 类型就是使用了享元模式。String 对象是 final 类型,对象一旦创建就不可改变。在 JAVA 中字符串常量都是存在常量池中的,JAVA 会确保一个字符串常量在常量池中只有一个拷贝。String a="abc",其中"abc"就是一个字符串常量。
熟悉 java 的应该知道下面这个例子:
String a = "hello";
String b = "hello";
if(a == b)
System.out.println("OK");
else
System.out.println("Error");
输出结果是:OK。可以看出 if 条件比较的是两 a 和 b 的地址,也可以说是内存空间。
核心总结,可以共享的对象,也就是说返回的同一类型的对象其实是同一实例,当客户端要求生成一个对象时,工厂会检测是否存在此对象的实例,如果存在那么直接返回此对象实例,如果不存在就创建一个并保存起来,这点有些单例模式的意思。通常工厂类会有一个集合类型的成员变量来用以保存对象,如 hashtable,vector 等。在 java 中,数据库连接池,线程池等即是用享元模式的应用。
十一、组合模式
11.1 定义
将对象组合成树形结构以表示‘部分-整体’的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
就拿剪发办卡的事情来分析一下吧。
首先,一张卡可以在总部,分店,加盟店使用,那么总部可以刷卡,分店也可以刷卡,加盟店也可以刷卡,这个属性结构的店面层级关系就明确啦。
那么,总店刷卡消费与分店刷卡消费是一样的道理,那么总店与分店对会员卡的使用也具有一致性。
11.2 组合模式的例子
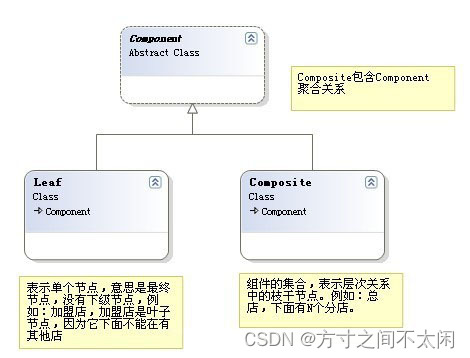
组合模式的实例如下:
import java.util.ArrayList;
import java.util.List;
public class ComponentDemo {
public abstract class Component {
String name;
public abstract void add(Component c);
public abstract void remove(Component c);
public abstract void eachChild();
}
// 组合部件类
public class Leaf extends Component {
// 叶子节点不具备添加的能力,所以不实现
@Override
public void add(Component c) {
// TODO Auto-generated method stub
System.out.println("");
}
// 叶子节点不具备添加的能力必然也不能删除
@Override
public void remove(Component c) {
// TODO Auto-generated method stub
System.out.println("");
}
// 叶子节点没有子节点所以显示自己的执行结果
@Override
public void eachChild() {
// TODO Auto-generated method stub
System.out.println(name + "执行了");
}
}
// 组合类
public class Composite extends Component {
// 用来保存节点的子节点
List<Component> list = new ArrayList<Component>();
// 添加节点 添加部件
@Override
public void add(Component c) {
// TODO Auto-generated method stub
list.add(c);
}
// 删除节点 删除部件
@Override
public void remove(Component c) {
// TODO Auto-generated method stub
list.remove(c);
}
// 遍历子节点
@Override
public void eachChild() {
// TODO Auto-generated method stub
System.out.println(name + "执行了");
for (Component c : list) {
c.eachChild();
}
}
}
public static void main(String[] args) {
ComponentDemo demo = new ComponentDemo();
// 构造根节点
Composite rootComposite = demo.new Composite();
rootComposite.name = "根节点";
// 左节点
Composite compositeLeft = demo.new Composite();
compositeLeft.name = "左节点";
// 构建右节点,添加两个叶子几点,也就是子部件
Composite compositeRight = demo.new Composite();
compositeRight.name = "右节点";
Leaf leaf1 = demo.new Leaf();
leaf1.name = "右-子节点1";
Leaf leaf2 = demo.new Leaf();
leaf2.name = "右-子节点2";
compositeRight.add(leaf1);
compositeRight.add(leaf2);
// 左右节点加入 根节点
rootComposite.add(compositeRight);
rootComposite.add(compositeLeft);
// 遍历组合部件
rootComposite.eachChild();
}
}
运行结果:
根节点执行了
右节点执行了
右-子节点 1 执行了
右-子节点 2 执行了
左节点执行了
11.3 应用组合模式的会员卡消费
那么我们就根据我们会员卡的消费,来模拟一下组合模式的实现吧!
首先:
1. 我们的部件有,总店,分店,加盟店!
2. 我们的部件共有的行为是:刷会员卡
3. 部件之间的层次关系,也就是店面的层次关系是,总店下有分店、分店下可以拥有加盟店。
有了我们这几个必要条件后,我的要求就是目前店面搞活动当我在总店刷卡后,就可以累积相当于在所有下级店面刷卡的积分总额,设计的代码如下:
import java.util.ArrayList;
import java.util.List;
public class PayDemo {
public abstract class Market {
String name;
public abstract void add(Market m);
public abstract void remove(Market m);
public abstract void PayByCard();
}
// 分店 下面可以有加盟店
public class MarketBranch extends Market {
// 加盟店列表
List<Market> list = new ArrayList<PayDemo.Market>();
public MarketBranch(String s) {
this.name = s;
}
@Override
public void add(Market m) {
// TODO Auto-generated method stub
list.add(m);
}
@Override
public void remove(Market m) {
// TODO Auto-generated method stub
list.remove(m);
}
// 消费之后,该分店下的加盟店自动累加积分
@Override
public void PayByCard() {
// TODO Auto-generated method stub
System.out.println(name + "消费,积分已累加入该会员卡");
for (Market m : list) {
m.PayByCard();
}
}
}
// 加盟店 下面不在有分店和加盟店,最底层
public class MarketJoin extends Market {
public MarketJoin(String s) {
this.name = s;
}
@Override
public void add(Market m) {
// TODO Auto-generated method stub
}
@Override
public void remove(Market m) {
// TODO Auto-generated method stub
}
@Override
public void PayByCard() {
// TODO Auto-generated method stub
System.out.println(name + "消费,积分已累加入该会员卡");
}
}
public static void main(String[] args) {
PayDemo demo = new PayDemo();
MarketBranch rootBranch = demo.new MarketBranch("总店");
MarketBranch qhdBranch = demo.new MarketBranch("长沙分店");
MarketJoin hgqJoin = demo.new MarketJoin("长沙岳麓加盟店");
MarketJoin btlJoin = demo.new MarketJoin("长沙星沙加盟店");
qhdBranch.add(hgqJoin);
qhdBranch.add(btlJoin);
rootBranch.add(qhdBranch);
rootBranch.PayByCard();
}
}
运行结果:
总店消费,积分已累加入该会员卡
长沙分店消费,积分已累加入该会员卡
长沙岳麓加盟店消费,积分已累加入该会员卡
长沙星沙加盟店消费,积分已累加入该会员卡
这样在累积所有子店面积分的时候,就不需要去关心子店面的个数了,也不用关系是否是叶子节点还是组合节点了,也就是说不管是总店刷卡,还是加盟店刷卡,都可以正确有效的计算出活动积分。
11.4 什么情况下使用组合模式
引用大话设计模式的片段:“当发现需求中是体现部分与整体层次结构时,以及你希望用户可以忽略组合对象与单个对象的不同,统一地使用组合结构中的所有对象时,就应该考虑组合模式了。”
十二、适配器模式
12.1 概述
将一个类的接口转换成客户希望的另外一个接口。Adapter 模式使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作。
12.2 解决的问题
即 Adapter 模式使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作。
下面是两个非常形象的例子
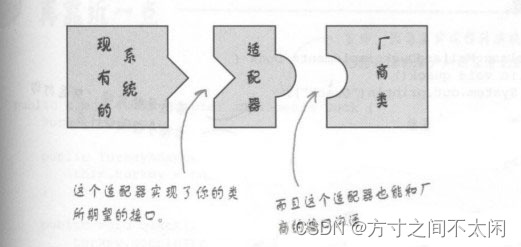
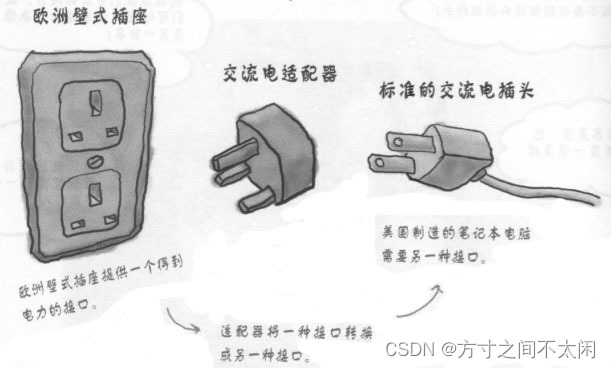
12.3 模式中的角色
1. 目标接口(Target):客户所期待的接口。目标可以是具体的或抽象的类,也可以是接口。
2. 需要适配的类(Adaptee):需要适配的类或适配者类。
3. 适配器(Adapter):通过包装一个需要适配的对象,把原接口转换成目标接口。
12.4 实现方式
1. 类的适配器模式(采用继承实现)
2. 对象适配器(采用对象组合方式实现)
适配器模式的类图

类的适配器模式
// 已存在的、具有特殊功能、但不符合我们既有的标准接口的类
class Adaptee {
public void specificRequest() {
System.out.println("被适配类具有 特殊功能...");
}
}
// 目标接口,或称为标准接口
interface Target {
public void request();
}
// 具体目标类,只提供普通功能
class ConcreteTarget implements Target {
public void request() {
System.out.println("普通类 具有 普通功能...");
}
}
// 适配器类,继承了被适配类,同时实现标准接口
class Adapter extends Adaptee implements Target{
public void request() {
super.specificRequest();
}
}
// 测试类public class Client {
public static void main(String[] args) {
// 使用普通功能类
Target concreteTarget = new ConcreteTarget();
concreteTarget.request();
// 使用特殊功能类,即适配类
Target adapter = new Adapter();
adapter.request();
}
}
运行结果:
普通类 具有 普通功能...
被适配类具有 特殊功能...
上面这种实现的适配器称为类适配器,因为 Adapter 类既继承了 Adaptee (被适配类),也实现了 Target 接口(因为 Java 不支持多继承,所以这样来实现),在 Client 类中我们可以根据需要选择并创建任一种符合需求的子类,来实现具体功能。另外一种适配器模式是对象适配器,它不是使用多继承或继承再实现的方式,而是使用直接关联,或者称为委托的方式,类图如下:
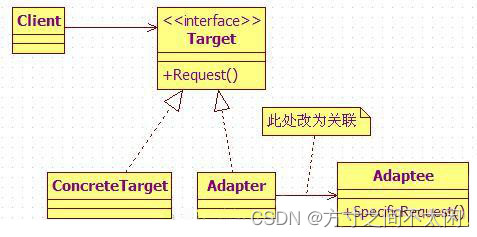
代码如下:
// 适配器类,直接关联被适配类,同时实现标准接口
class Adapter implements Target{
// 直接关联被适配类
private Adaptee adaptee;
// 可以通过构造函数传入具体需要适配的被适配类对象
public Adapter (Adaptee adaptee) {
this.adaptee = adaptee;
}
public void request() {
// 这里是使用委托的方式完成特殊功能
this.adaptee.specificRequest();
}
}
// 测试类
public class Client {
public static void main(String[] args) {
// 使用普通功能类
Target concreteTarget = new ConcreteTarget();
concreteTarget.request();
// 使用特殊功能类,即适配类,
// 需要先创建一个被适配类的对象作为参数
Target adapter = new Adapter(new Adaptee());
adapter.request();
}
}
执行结果与上面的一致。从类图中我们也知道需要修改的只不过就是 Adapter 类的内部结构,即 Adapter 自身必须先拥有一个被适配类的对象,再把具体的特殊功能委托给这个对象来实现。使用对象适配器模式,可以使得 Adapter 类(适配类)根据传入的 Adaptee 对象达到适配多个不同被适配类的功能,当然,此时我们可以为多个被适配类提取出一个接口或抽象类。这样看起来的话,似乎对象适配器模式更加灵活一点。
12.5 模式总结
优点
- 通过适配器,客户端可以调用同一接口,因而对客户端来说是透明的。这样做更简单、更直接、更紧凑。
- 复用了现存的类,解决了现存类和复用环境要求不一致的问题。
- 将目标类和适配者类解耦,通过引入一个适配器类重用现有的适配者类,而无需修改原有代码。
- 一个对象适配器可以把多个不同的适配者类适配到同一个目标,也就是说,同一个适配器可以把适配者类和它的子类都适配到目标接口。
缺点
对于对象适配器来说,更换适配器的实现过程比较复杂。
适用场景
- 系统需要使用现有的类,而这些类的接口不符合系统的接口。
- 想要建立一个可以重用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作。
- 两个类所做的事情相同或相似,但是具有不同接口的时候。
- 旧的系统开发的类已经实现了一些功能,但是客户端却只能以另外接口的形式访问,但我们不希望手动更改原有类的时候。
- 使用第三方组件,组件接口定义和自己定义的不同,不希望修改自己的接口,但是要使用第三方组件接口的功能。
12.6 适配器应用举例
- 使用过 ADO.NET 的开发人员应该都用过 DataAdapter,它就是用作 DataSet 和数据源之间的适配器。DataAdapter 通过映射 Fill 和 Update 来提供这一适配器。
- 手机电源适配器。















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











