






Go语言实现常见的负载均衡算法
简介
负载均衡建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。
负载均衡*(Load Balance)*其意思就是分摊到多个操作单元上进行执行,例如Web服务器、FTP服务器、企业关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。
负载均衡的常见算法有
- 随机负载均衡
- 加权随机负载均衡
- 轮询负载均衡
- 加权负载均衡
- 加权平滑轮询负载均衡
- 一致性hash负载均衡
随机负载均衡
概述
在客户端发送请求到路由服务器时随机选取后台服务器进行响应
package banlance
import (
"errors"
"math/rand"
)
type RandomBanlance struct {
curIndex int
macList []string
}
var randomtest RandomBanlance
// 添加后台机器
func (r *RandomBanlance) Add(params ...string) error {
if len(params) == 0 {
return errors.New("params len 1 at least")
}
//可以在赋值之前加一个输入参数正确性判断
r.macList = append(r.macList, params...)
return nil
}
// 随机化负载均衡
func (r *RandomBanlance) Next() string {
if len(r.macList) == 0 {
return ""
}
r.curIndex = rand.Intn(len(r.macList))
return r.macList[r.curIndex]
}
// 提供随机化接口
func (r *RandomBanlance) Get() (res string, error error) {
mac := r.Next()
if mac == "" {
return "", errors.New("no machine backend")
}
return mac, nil
}
加权随机负载均衡
概述
在随机负载均衡的基础上为每个节点赋予权重,让不同负载能力的节点响应请求的概率呈现处差异。
加权随机负载均衡
实现方法有两种:
- 简单加权随机:将所有的节点放入一个List中,根据权重来选择装入几次节点信息,比如"121.0.0.1"这个节点的权重是2,那么就装入两次该IP。这个方法的问题在于当节点数量和权重值相对大的时候List会非常大,耗费很大的空间。
- 优化简单加权随机:为了解决简单加权随机的问题,我们可以采用坐标映射。假设A,B,C分别代表3个IP,权重分别为2,3,5,映射到坐标轴为:0—2—5—10 ,我们随意取在区间内的一个整数7,那么对应的就是C这台服务器,具体代码如下。
package banlance
import (
"errors"
"math/rand"
"sort"
)
type WeightRandomBanlance struct {
addrs []WeightRandomNode
weights []int //记录排序后的权重前缀和
max int //记录权重的总和
}
type WeightRandomNode struct {
addr string
weight int
}
func NewWeightRandomBanlance(w ...WeightRandomNode) WeightRandomBanlance {
//将节点按权重从小到大排序
sort.Slice(w, func(i, j int) bool {
return w[i].weight < w[j].weight
})
weights := make([]int, 0)
total := 0
for i := 0; i < len(w); i++ {
total += w[i].weight
weights = append(weights, total)
}
return WeightRandomBanlance{
addrs: w,
weights: weights,
max: total,
}
}
func NewWeightRandomNode(addr string, weight int) WeightRandomNode {
return WeightRandomNode{
addr: addr,
weight: weight,
}
}
// 添加节点
func (w *WeightRandomBanlance) Add(wn ...WeightRandomNode) {
nodes := append(w.addrs, wn...)
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].weight < nodes[j].weight
})
weights := make([]int, 0)
total := 0
for i := 0; i < len(nodes); i++ {
total += nodes[i].weight
weights = append(weights, total)
}
w.addrs = nodes
w.max = total
w.weights = weights
}
func (w *WeightRandomBanlance) Next() string {
if len(w.weights) == 0 {
return ""
}
r := rand.Intn(w.max) + 1 //从1开始计数
index := sort.SearchInts(w.weights, r)
return w.addrs[index].addr
}
func (w *WeightRandomBanlance) Get() (string, error) {
mac := w.Next()
if mac == "" {
return mac, errors.New("no node backend")
}
return mac, nil
}
轮询负载均衡
概述
在client发送请求到路由服务器时轮询后台服务器进行响应
package banlance
import "errors"
//轮询负载均衡
type PollingBanlance struct {
curIndex int
macList []string
}
func (p *PollingBanlance) Add(params ...string) error {
if len(params) == 0 {
return errors.New("params len 1 at least")
}
p.macList = append(p.macList, params...)
return nil
}
func (p *PollingBanlance) Next() string {
if len(p.macList) == 0 {
return ""
}
lens := len(p.macList)
if p.curIndex >= lens {
p.curIndex = 0
}
mac := p.macList[p.curIndex]
p.curIndex = (p.curIndex + 1) % lens
return mac
}
func (p *PollingBanlance) Get() (string, error) {
mac := p.Next()
if mac == "" {
return mac, errors.New("no machine backend")
}
return mac, nil
}
加权平滑轮询负载均衡
概述
在轮询负载均衡的基础上为每个服务器节点加入了权重,client的请求会根据权重平滑的分散在不同的服务器节点。
加权轮询
实现方法有两种
- 加权轮询:加权轮询在轮询的基础上赋予了每个节点权重,算法的思想和优化可以参照加权随机负载均衡,只不过加权轮询在转发下一个请求的时候是curindex+1而不是随机的获取
- 加权平滑轮询:平滑轮询有一个缺点就是在某一时刻连续的几个client请求会被发送大同一个服务器上就行处理,而其它机器则处于空闲状态,加权平滑轮询在加权轮询的基础上提高的请求发往服务器的离散型。算法举例:假设由A,B,C三台机器,权重分别是2,3,5
| 轮次 | (A,B,C)当前权重 | 选择当前权重最大的节点 | 修改权重 |
|---|---|---|---|
| 0(初始化) | (0,0,0) | ||
| 1 | (2,3,5) | C | (2,3,-5) |
| 2 | (4,6,0) | B | (4,-4,0) |
| 3 | (6,-1,5) | A | (-4,-1,5) |
| 4 | (-2,2,10) | C | (-2,2,0) |
| 5 | (0,5,5) | B | (0,-5,5) |
| 6 | (2,-2,10) | C | (2,-2,0) |
| 7 | (4,1,5) | C | (4,1,-5) |
| 8 | (6,4,0) | A | (-4,4,0) |
| 9 | (-2,7,5) | B | (-2,-3,5) |
| 10 | (0,0,10) | C | (0,0,0) |
上述表格描述了A,B,C三个节点在一轮下来当前权重的变化过程,代码如下
package banlance
import (
"errors"
"strconv"
)
type WeightPollingBanlance struct {
curIndex int
macList []*weightNode
}
type weightNode struct {
addr string
weight int //初始化的权重
curWeight int //更新的临时权重
effectiveWeight int //节点有效权重
}
func (r *WeightPollingBanlance) Add(params ...string) error {
if len(params) != 2 {
return errors.New("params len need 2")
}
weight, err := strconv.ParseInt(params[1], 10, 64)
if err != nil {
return err
}
node := &weightNode{
addr: params[0],
weight: int(weight),
}
node.effectiveWeight = node.weight
r.macList = append(r.macList, node)
return nil
}
func (r *WeightPollingBanlance) Next() string {
if len(r.macList) == 0 {
return ""
}
var best *weightNode
total := 0
for i := 0; i < len(r.macList); i++ {
w := r.macList[i]
//1,获取权重总和
total += w.effectiveWeight
//2,更新curWeight
w.curWeight += w.effectiveWeight
//3,
if w.effectiveWeight < w.weight {
w.effectiveWeight++
}
//4,选中临时权重最大的节点
if best == nil || best.curWeight < w.curWeight {
best = w
r.curIndex = i
}
}
if best == nil {
return ""
}
//5,修改临时权重为临时权重-total
best.curWeight = best.curWeight - total
return best.addr
}
func (r *WeightPollingBanlance) Get() (string, error) {
mac := r.Next()
if mac == "" {
return mac, errors.New("no machine backend")
}
return mac, nil
}
一致性hash算法(consistent hash)
概述
当一个缓存服务由多个服务器共同提供时,存在一个key应该路由到哪一个服务器的问题。如果采用最通用的方式key%N(服务器的数量),当服务器发生增加或者减少时,分配则变为key%(N+1)或者key%(N-1) ,这时候会有大量的key失效迁移,如果后端的key对应的是有状态的存储数据, 那么这种做法就会导致服务器间大量的数据迁移,从而造成服务器的不稳定,而使用槽映射的方式有一个缺点就是所有节点都需要知道槽与节点对应关系,如果client端不保存槽与节点对应的关系,client就需要实现重定向的逻辑。这时候使用一致性hash算法就很适合。
一致性hash算法的特点
一致性hash算法在1997年由麻省理工学院 karger等人在解决分布式Cache中提出。一个好的hash算法应该满足四个条件:均衡性(Balance)、单调性(Monotonicity)、分散性(Spread)和负载(Load)。
- 均衡性: 均衡性主要是通过算法分配,集群中各节点应该要尽可能均衡。
- 单调性: 单调性主要是指当集群发生变化时,已经分配到老节点的key,尽可能的继续分配到之前的节点,防止大量数据迁移。
- 分散性: 分散性主要针对同一个key,当在不同的客户端操作时候,可能存在客户端获取到的缓存集群的数量不一致,从而导致将key映射到不同节点的问题,这会引起数据的不一致性。
- 负载: 负载主要针对一个缓存而言,同一缓存有可能会被用户映射到不同的key上,从而导致该缓存的状态不一致。
一致性hash算法
一致性hash的核心思想是将key做hash运算,然后通常的做法是按照一定的算法得出一个 0 ~ 2^32-1之间的值,环的大小为 2^23,key计算出的整数为key在hash环上的位置。
所以就是两步:
- 将代表服务器的key做hash,得到服务器节点在hash环上的位置。
- 将缓存的key,用同样的方法计算出hash环上的位置,按顺时针方向,找到第一个大于等于hash环位置的服务器的ServerNodeKey,从而得到该key需要分配的服务器。
如果只使用实际节点,一般都会出现hash出来的范围分配不均的情况,这时候就需要加上虚拟节点。(即在hash环中加入某一结点的多个副本,还可以根据节点的负载能力更改节点的副本数量)
package banlance
import (
"errors"
"fmt"
"sort"
"strconv"
"sync"
"github.com/spaolacci/murmur3"
)
const (
TopWeight = 100 //最大的权重
minReplicas = 10 //最小的副本数量
prime = 16777619
)
type UInt64Slice []uint64
// 默认的hash函数
func Hash(data []byte) uint64 {
return murmur3.Sum64(data)
}
func (s UInt64Slice) Len() int {
return len(s)
}
func (s UInt64Slice) Less(i, j int) bool {
return s[i] < s[j]
}
func (s UInt64Slice) Swap(i, j int) {
s[i], s[j] = s[j], s[i]
}
type (
//定义hash函数的形式
Func func(data []byte) uint64
ConsistentHash struct {
hashFunc Func //使用的hash函数
replicas int //每一个新增节点的副本数量
keys []uint64 //存放hash后的节点
hashMap map[uint64]string //存放节点的hash值与节点的对应信息
mux sync.RWMutex
}
)
// 新建一个一致性hash环
func NewConsistentHashBanlance(replicas int, fn Func) *ConsistentHash {
if replicas < minReplicas {
replicas = minReplicas //限制最小的节点副本数量
}
if fn == nil {
fn = Hash
}
return &ConsistentHash{
replicas: replicas,
hashFunc: fn,
hashMap: make(map[uint64]string),
}
}
// 向环中添加节点
func (c *ConsistentHash) Add(params ...string) error {
if len(params) == 0 {
return errors.New("params len 1 at least")
}
addr := params[0]
//加锁进行操作
c.mux.Lock()
defer c.mux.Unlock()
for i := 0; i < c.replicas; i++ {
hash := c.hashFunc([]byte(addr + strconv.Itoa(i)))
c.keys = append(c.keys, hash)
c.hashMap[hash] = addr
}
sort.Slice(c.keys, func(i, j int) bool {
return c.keys[i] < c.keys[j]
})
return nil
}
func (c *ConsistentHash) IsEmpty() bool {
return len(c.keys) == 0
}
// 获取请求改发往的服务器
func (c *ConsistentHash) Get(key string) (string, error) {
if c.IsEmpty() {
return "", errors.New("no node backend")
}
c.mux.RLock()
defer c.mux.RUnlock()
hash := c.hashFunc([]byte(key))
//用二分查找找到第一个hash值大于key的节点
index := sort.Search(len(c.keys), func(i int) bool { return c.keys[i] >= hash }) % (len(c.keys))
return c.hashMap[c.keys[index]], nil
}
// 从consistenthash中删除节点
func (c *ConsistentHash) Remove(key string) error {
c.mux.Lock()
defer c.mux.Unlock()
if c.IsEmpty() {
return errors.New("no node bakend")
}
for i := 0; i < c.replicas; i++ {
hash := c.hashFunc([]byte(key + strconv.Itoa(i)))
index := sort.Search(len(c.keys), func(i int) bool {
return c.keys[i] >= hash
})
if index < len(c.keys) && c.keys[index] == hash {
c.keys = append(c.keys[:index], c.keys[index+1:]...)
delete(c.hashMap, hash)
} else {
return errors.New("node not exsts")
}
}
return nil
}
func (c *ConsistentHash) Out() {
for i := 0; i < len(c.keys); i++ {
fmt.Println(c.keys[i])
}
for k, v := range c.hashMap {
fmt.Println("hash", k, "value", v)
}
}
以一致性hash算法测试一下负载均衡
服务器端
package main
import (
"fmt"
"net/http"
)
func sayHelloHander(w http.ResponseWriter, r *http.Request) {
_, _ = fmt.Fprint(w, "Hello World port 8080")
}
func main() {
http.HandleFunc("/hello", sayHelloHander)
err := http.ListenAndServe(":8080", nil)
if err != nil {
fmt.Println("http server error!", err)
return
}
}
多开几个端口模拟服务器
模拟负载均衡
package main
import (
"fmt"
"io/ioutil"
"log"
"math/rand"
"net/http"
banlance "test/src/Banlance"
"time"
)
var hashring *banlance.ConsistentHash
// 初始化一致性hash环
func initHashRing() {
hashring = banlance.NewConsistentHashBanlance(10000, banlance.MyHash)
hashring.Add("127.0.0.1:8080")
hashring.Add("127.0.0.1:8081")
hashring.Add("127.0.0.1:8082")
hashring.Add("127.0.0.1:8083")
hashring.Add("127.0.0.1:8084")
}
func query(str string) string {
client := &http.Client{}
mac, _ := hashring.Get(str)
req, err := http.NewRequest("GET", "http://"+mac+"/hello", nil)
if err != nil {
log.Fatal(err)
}
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
if resp.StatusCode != 200 {
log.Fatal("bad StatusCode", resp.StatusCode, "body", string(body))
}
return string(body)
}
func main() {
rand.Seed(time.Now().Unix())
initHashRing()
tic := time.Now().UnixNano()
res := map[string]int{}
for i := 0; i < 100000; i++ {
req := fmt.Sprintf("%d.%d.%d.%d:80", rand.Intn(192)+1, rand.Intn(255)+1, rand.Intn(255)+1, rand.Intn(255)+1)
response := query(req)
if _, ok := res[response]; !ok {
res[response] = 1
} else {
res[response]++
}
}
toc := time.Now().UnixNano()
fmt.Printf("spend time : %d\n", (toc-tic)/1000)
for k := range res {
fmt.Printf("%s count:%d\n", k, res[k])
}
}
我在这里开了五个进程分别占用本地的8080~8084五个端口进行测试,测试效果如下:
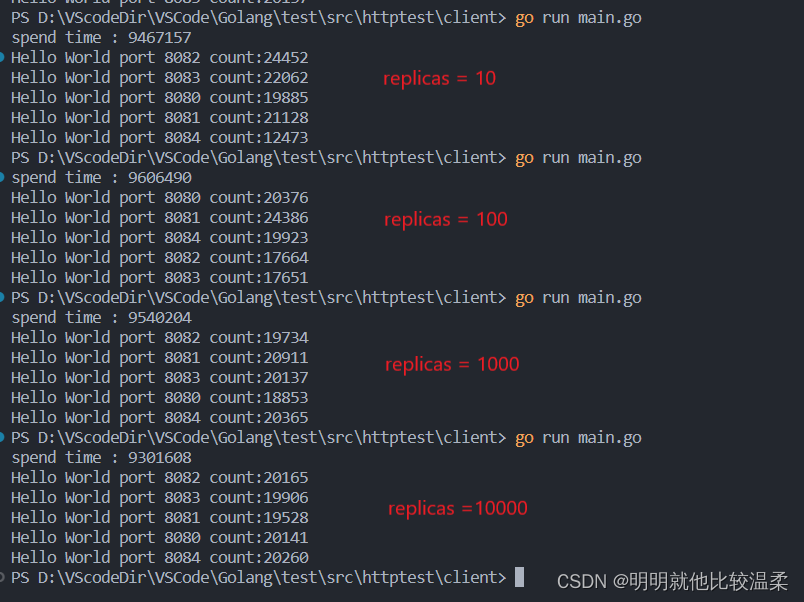
由上图可以看出当replicas越大时负载均衡的效果越好















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









