






ABSTRACT
1. 背景
协同过滤推荐系统存在稀疏性和冷启动问题。为了解决这些问题,研究人员和工程师通常会收集用户和项目的属性,并设计精细的算法来利用这些额外信息。
2. 知识图谱卷积网络(KGCN)
一般来说,属性不是孤立的,而是相互连接的,形成知识图谱(KG)。
文中提出了知识图谱卷积网络(KGCN),这是一种端到端的框架,通过挖掘知识图谱上的关联属性来有效地捕捉项目间的关系。
3. KGCN 的工作原理
为了自动发现知识图谱的高阶结构信息和语义信息,对知识图谱中的每个实体从其邻居中采样作为其感受野。
在计算给定实体的表示时,将邻域信息与偏差相结合。感受野可以扩展到多跳之外,以建模高阶邻近信息并捕捉用户潜在的长距离兴趣。
4. 实现与应用
以小批量方式实现了所提出的 KGCN,使其能够在大型数据集和知识图谱上运行。
将该模型应用于电影、书籍和音乐推荐的三个数据集,实验结果表明该方法优于强大的推荐基准。
KEYWORDS
Recommender systems; Knowledge graph; Graph convolutional network
1 INTRODUCTION
1.背景
随着互联网技术的发展,在线平台上的内容数量庞大,给用户带来了信息过载的问题。推荐系统(RS)被提出用于为用户推荐符合其个性化兴趣的内容。
传统的推荐技术是协同过滤(CF),但 CF 方法存在稀疏性和冷启动问题。为了解决这些问题,研究人员转向了属性丰富的场景,利用知识图谱(KG)来改善推荐性能。
知识图谱是一种有向异构图,其中节点对应实体(项目或项目属性),边对应关系。将 KG 融入推荐系统有三个好处:
可以探索项目之间的潜在联系,提高推荐结果的精度。
有助于合理扩展用户的兴趣,增加推荐项目的多样性。
可以为推荐系统带来可解释性。
2.挑战与现有方法
利用 KG 在 RS 中存在挑战,因为 KG 具有高维度和异质性。
一种可行的方法是通过知识图谱嵌入(KGE)方法对 KG 进行预处理,但常用的 KGE 方法更适合图内应用,如 KG 补全和链接预测,而不是推荐。
另一种更自然和直观的方法是直接设计图算法来利用 KG 结构,例如 PER、FMG 和 RippleNet,但这些方法存在手动设计元路径 / 元图的问题,并且在 RippleNet 中关系的重要性表征较弱,计算成本随着 KG 规模的增加而增加。
3.知识图谱卷积网络(KGCN)
提出了知识图谱卷积网络(KGCN),这是一种端到端的框架,用于推荐系统中探索用户在知识图谱上的偏好。
KGCN 的关键思想是在计算给定实体的表示时,将邻域信息与偏差相结合,通过扩展每个实体在 KG 中的感受野来捕捉高阶结构信息和语义信息。
以小批量方式实现了 KGCN,使其能够在大型数据集和知识图谱上运行。
4.实验与结果
将 KGCN 应用于三个数据集:MovieLens - 20M(电影)、Book - Crossing(书籍)和 Last.FM(音乐)。
实验结果表明,与推荐的现有最佳基准相比,KGCN 在电影、书籍和音乐推荐中分别实现了 4.4%、8.1% 和 6.2% 的平均 AUC 增益。
我们在本文中的贡献总结如下:
提出知识图谱卷积网络(KGCN):这是一个端到端的框架,用于在推荐系统中探索用户对知识图谱的偏好。通过扩展知识图谱中每个实体的感受野,KGCN 能够捕捉用户的高阶个性化兴趣。
进行实验:在三个真实世界的推荐场景中进行了实验。结果表明 KGCN - LS 比现有最佳基准更有效。
数据和代码发布:向研究人员发布了 KGCN 的代码和数据集(知识图谱),用于验证报告的结果和进行进一步研究。代码和数据可在https://github.com/hwwang55/KGCN获取。
2 RELATED WORK
这种方法在概念上受到图卷积网络(GCN)的启发,并对相关方法进行了分类和对比。
图卷积网络(GCN)的分类
GCN 可分为谱方法(spectral methods)和非谱方法(non - spectral methods)。
谱方法在傅里叶域(Fourier domain)中表示图并进行卷积,例如 Bruna 等人在傅里叶域中定义卷积并计算图拉普拉斯算子(graph Laplacian)的特征分解,Defferrard 等人通过切比雪夫展开(Chebyshev expansion)近似图拉普拉斯算子的卷积滤波器,Kipf 等人提出了一种基于局部一阶近似的谱图卷积架构。
非谱方法直接在原始图上操作并为节点组定义卷积,为了处理不同大小的邻域并保持卷积神经网络(CNN)的权重共享特性,研究人员提出了一些方法,如为每个节点度学习一个权重矩阵、从图中提取局部连接区域或对固定大小的邻居集进行采样。
文中所提到的方法可被视为针对一种特殊类型图(即知识图谱)的非谱方法。
与其他方法的联系
文中方法与 PinSage 和 GAT 相关,但 PinSage 和 GAT 是为同构图(homogeneous graphs)设计的,而文中方法借助异构知识图谱(heterogeneous knowledge graph)为推荐系统提供了新视角。
3 KNOWLEDGE GRAPH CONVOLUTIONAL NETWORKS
在本节中,我们将介绍所提出的 KGCN 模型。我们首先阐述知识图谱感知推荐问题。然后我们展示了单层 KGCN 的设计。最后,我们介绍了 KGCN 的完整学习算法及其小批量实现。
3.1 Problem Formulation
阐述了知识图谱感知推荐问题的公式化表述。
3.2 KGCN Layer

3. KGCN 层的聚合操作

聚合操作是 KGCN 中的关键步骤,因为一个项目的表示通过聚合与其邻居绑定在一起。文中提到将在实验中评估这三种聚合器。
3.3 Learning Algorithm

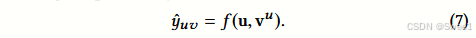

Figure 1b它说明了 KGCN 算法在一次迭代中的情况,其中给定节点的实体表示
v
[
h
]
v^{[h]}
v[h]和邻域表示(绿色节点)混合形成下一次迭代的表示(蓝色节点)。这是在直观地展示 KGCN 算法中实体表示在迭代过程中的更新机制,即当前节点的表示会和其邻居节点的表示进行混合来产生下一轮迭代的表示。
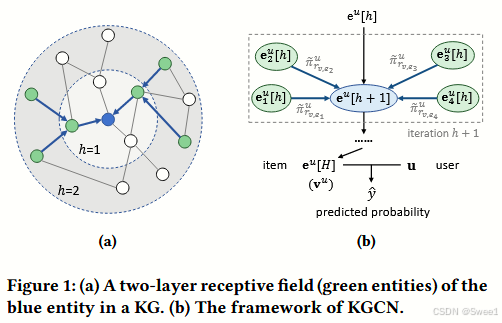
图 1:(a) 知识图谱中蓝色实体的两层感受野(绿色实体)。(b) KGCN(知识图谱卷积网络)的框架。

4 EXPERIMENTS
在本节中,我们在电影、图书和音乐推荐三个真实世界场景上对KGCN进行评估。
4.1 Datasets
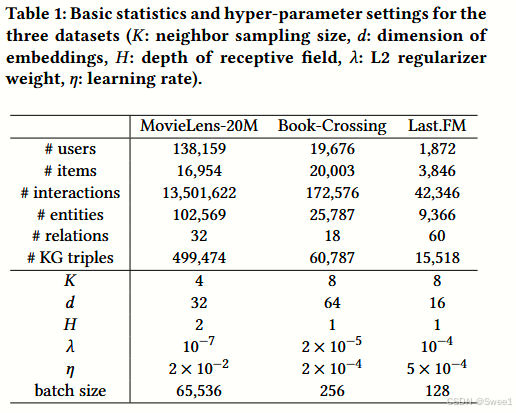
表1:三个数据集的基本统计数据和超参数设置(K:邻居采样大小,d:嵌入维度,H:感受野深度,λ:L2正则化权重,η:学习率)。
在本节中,我们在电影、图书和音乐推荐三个真实世界场景上对KGCN进行评估。
1. 数据集
MovieLens - 20M⁴
这是一个在电影推荐中广泛使用的基准数据集。
包含约 2000 万条在 MovieLens 网站上的显式评分(评分范围从 1 到 5)。
Book - Crossing⁵
包含 100 万条在 Book - Crossing 社区中书籍的评分(评分范围从 0 到 10)。
Last.FM⁶
包含来自 Last.fm 在线音乐系统中 2000 名用户的音乐收听信息。
2. 数据处理
由于这三个数据集都是显式反馈,将它们转换为隐式反馈。对每个用户,将用户正面评分的项目标记为 1(对于 MovieLens - 20M,正面评分的阈值为 4;对于 Book - Crossing 和 Last.FM,由于数据稀疏性,未设置阈值),未观看 / 未评分的项目标记为 0。
3. 知识图谱构建
使用 Microsoft Satori⁷构建知识图谱。
首先从整个知识图谱(KG)中选择置信水平大于 0.9 的三元组子集。
对于子知识图谱,通过将电影 / 书籍 / 音乐的名称与三元组的尾部(如 (head, film.film.name, tail)、(head, book.book.title, tail) 或 (head, type.object.name, tail))进行匹配,收集所有有效电影 / 书籍 / 音乐的 Satori ID。
为了简单起见,排除具有多个匹配或无匹配实体的项目。
然后将项目 ID 与所有三元组的头部进行匹配,并从子知识图谱中选择所有匹配良好的三元组。
4.2 Baselines
将提出的 KGCN(知识图谱卷积网络)与一些基准模型进行比较,这些基准模型包括:
SVD [11]:这是一种基于经典 CF(协同过滤)的模型,使用内积来对用户 - 项目交互进行建模。
LibFM [14]:这是 CTR(点击率预测)场景中的基于特征的分解模型。在使用时将用户 ID 和项目 ID 连接作为 LibFM 的输入。
LibFM + TransE:这种方法通过将 TransE [1] 学习到的实体表示附加到每个用户 - 项目对来扩展 LibFM。
PER [22]:该方法将知识图谱(KG)视为异构信息网络,并提取基于元路径的特征来表示用户和项目之间的连通性。
CKE [23]:这种方法在统一框架中结合了协同过滤(CF)与结构、文本和视觉知识用于推荐。文中将 CKE 实现为 CF 加上一个结构知识模块。
RippleNet [18]:这是一种类似记忆网络的方法,它在知识图谱上传播用户的偏好用于推荐。
4.3 Experiments Setup


4.4 Results
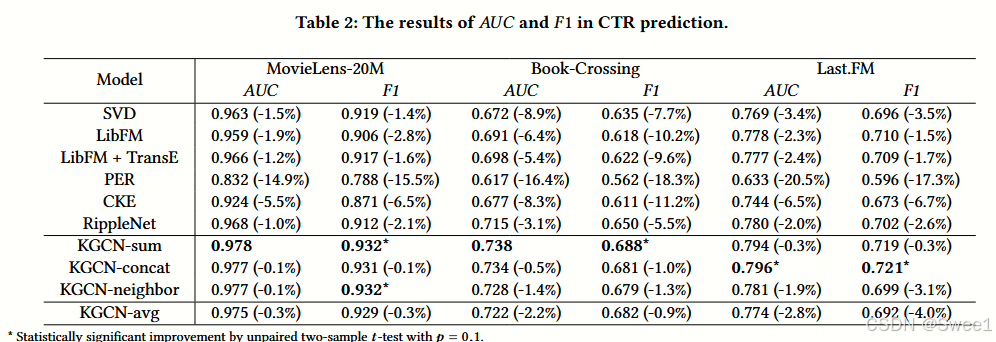
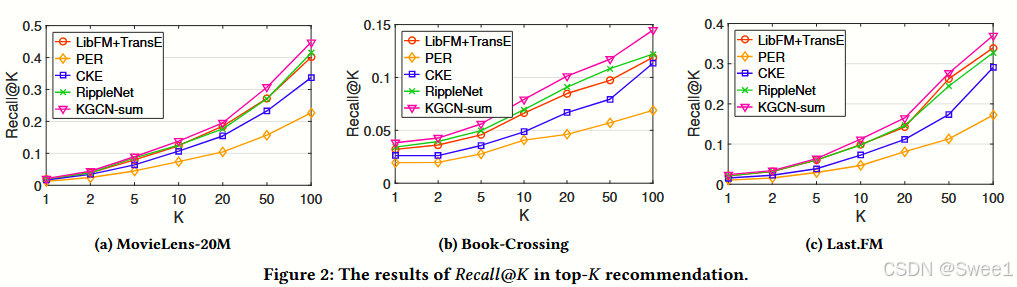
1.总体结果
CT R 预测和 top - K 推荐的结果分别在表 2 和图 2 中呈现。
文中提到为了清晰起见,图 2 中没有绘制 SVD、LibFM 和其他 KGCN 变体的结果。
2.观察结果
KGCN 在书籍和音乐上的改进更显著:
一般来说,KGCN 在书籍(Book - Crossing)和音乐(Last.FM)上的改进比在电影加粗样式(MovieLens - 20M)上更高。
这表明 KGCN 可以很好地处理稀疏场景,因为 Book - Crossing 和 Last.FM 比 MovieLens - 20M 更稀疏。
KG - free 和 KG - aware 基线模型的比较:
KG - free 基线模型(SVD 和 LibFM)的性能优于两个 KG - aware 基线模型(PER 和 CKE)。
这表明 PER 和 CKE 不能充分利用手动设计的元路径和类似 TransR 的正则化来利用知识图谱。
LibFM + TransE 的效果:
LibFM + TransE 在大多数情况下比 LibFM 更好,这表明知识图谱(KG)的引入对推荐通常是有帮助的。
PER 的表现:
PER 在所有基线模型中表现最差,因为在现实中很难定义最优的元路径。
RippleNet 的表现:
RippleNet 与其他基线模型相比表现出色。
值得注意的是,RippleNet 也使用多跳邻居结构,这有趣地表明在知识图谱中捕获邻近信息对推荐是必不可少的。
一、KGCN 变体的相关背景
KGCN 变体的定义
表 2 中的最后四行对 KGCN 变体的性能进行了总结。
其中前三个变体(sum、concat、neighbor)分别对应于前文所介绍的不同聚合器。
最后一个变体 KGCN - avg 是 KGCN - sum 的简化情况。
二、KGCN - avg 的特殊计算方式
在 KGCN - avg 中,邻域表示(neighborhood representations)是在不考虑用户关系得分(user - relation scores)的情况下直接求平均的。具体的计算公式为,
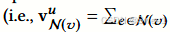
而不是按照公式 (2) 所规定的方式进行计算。这里引入 KGCN - avg 的目的是用于检验 “注意力机制”(attention mechanism)的有效性。
三、KGCN 及其变体的性能分析
KGCN 与基准模型比较
KGCN 的性能远远优于所有的基准模型。
不过,KGCN 的不同变体之间的性能存在一些差异。总体而言,KGCN - sum 的表现最佳。而 KGCN - neighbor 在 Book - Crossing(图书漂流数据集)和 Last.FM 数据集上的表现与其他数据集相比存在明显差距。这可能是因为邻居聚合器(neighbor aggregator)只使用了邻域表示,从而丢失了实体本身所包含的有用信息。
KGCN - avg 与 KGCN - sum 比较
KGCN - avg 的性能比 KGCN - sum 更差,特别是在 Book - Crossing 和 Last.FM 这两个交互数据较为稀疏的数据集上。这表明捕捉用户的个性化偏好以及知识图谱的语义信息对于推荐是有帮助的。
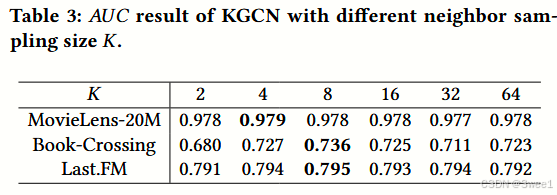
4.4.1 Impact of neighbor sampling size.

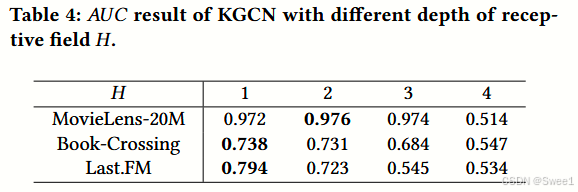
4.4.2 Impact of depth of receptive field.

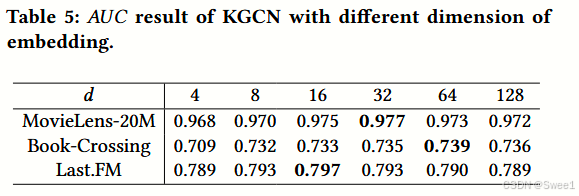
4.4.3 Impact of dimension of embedding.

5 CONCLUSIONS AND FUTURE WORK
1.KGCN 的提出和特点
论文提出了用于推荐系统的知识图谱卷积网络(KGCN)。
KGCN 通过有选择地、有偏向地聚合邻居信息,将非谱 GCN 方法扩展到知识图谱。它能够学习知识图谱的结构信息和语义信息,以及用户的个性化和潜在兴趣。
采用了小批量方式实现该方法,使其能够处理大型数据集和知识图谱。
2.实验结果
通过在真实世界数据集上进行广泛的实验,KGCN 在电影、书籍和音乐推荐方面的表现优于现有的先进基准方法。
3.未来工作方向
非均匀采样:目前工作是均匀地从实体的邻居中采样来构建感受野。探索非均匀采样器(例如重要性采样)是未来工作的一个重要方向。
用户端知识图谱:目前论文(以及所有相关文献)都侧重于对项目端知识图谱进行建模。一个有趣的未来工作方向是研究利用用户端知识图谱是否有助于提高推荐性能。
两端知识图谱结合:设计一种算法来很好地结合两端(项目端和用户端)的知识图谱也是一个有前景的方向。


















 4278
4278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











