






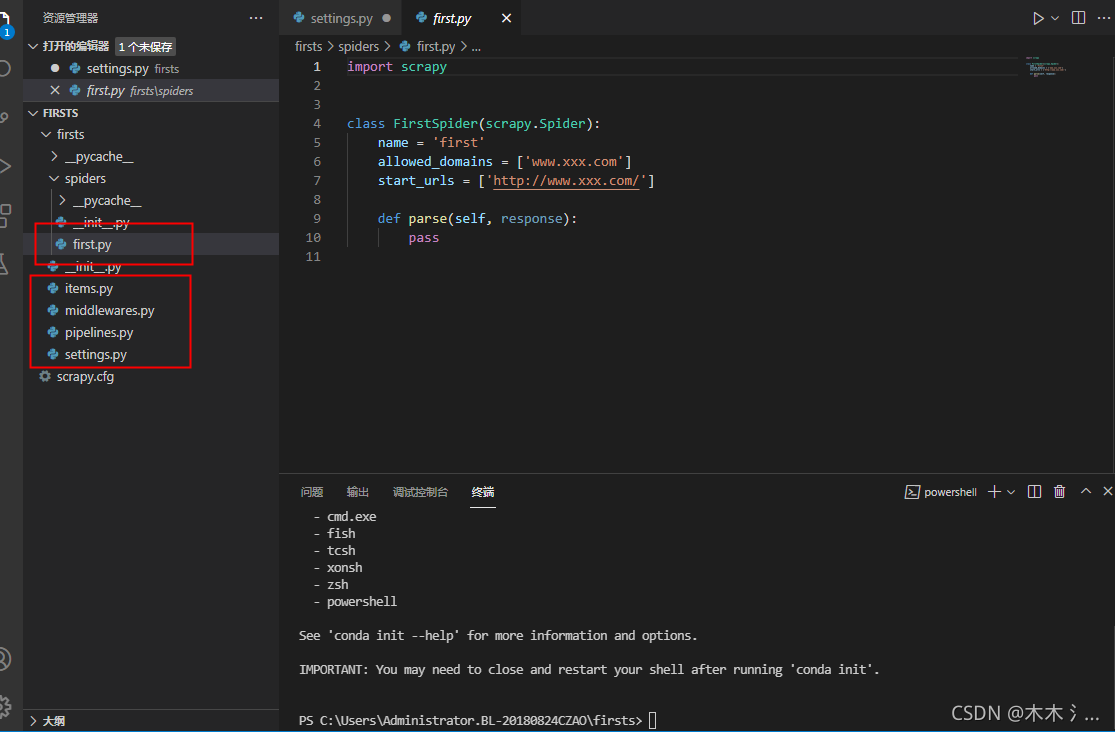
vs code的安装就不多说了,网上搜一大堆;
打开vs code -在终端位置pip install wheel,pip install pywin32,pip install scrapy,解析器选择Anaconda,pip就更换一下,具体百度也是一大堆;
1.搭建scrapy:
在终端输入 scrapy startproject 项目名(例如:scrapy startproject firsts)
如成功,在终端会输出‘cd firsts’,按着提示输入;
2.scrapy genspider 爬虫名 域名(例如:scrapy genspider first www.xxx.com)
完成以上两步,就完成搭建;
但是跟其它(pycharm/spyder)的IDE不一样,不会在资源管理器直接看到,如上图的界面,需要手动在vs code中--文件--打开文件夹(Ctrl+O)--找到刚才创建的firsts文件位置--打开,就可以愉快的爬取你喜爱的电影啦!
小白一枚,因为刚玩,花了些时间才明白vs code搭建scrapy,网上很多都是pycharm教程,所以就分享下这个方法,错误的地方大佬们指导修改!!!!

















 6919
6919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









