






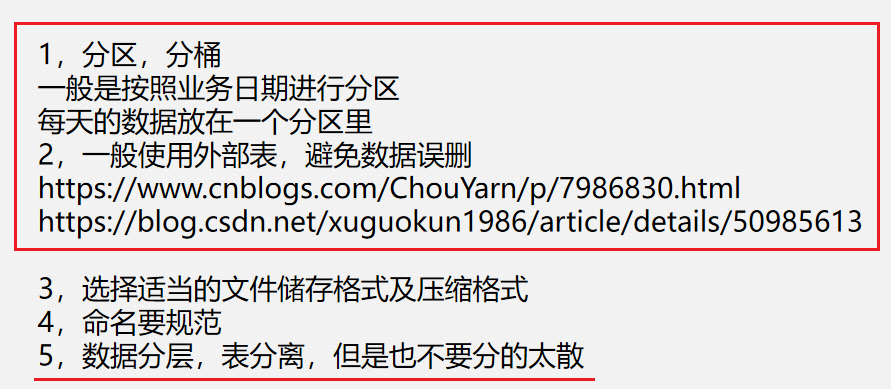
Hive调优-建表注意事项
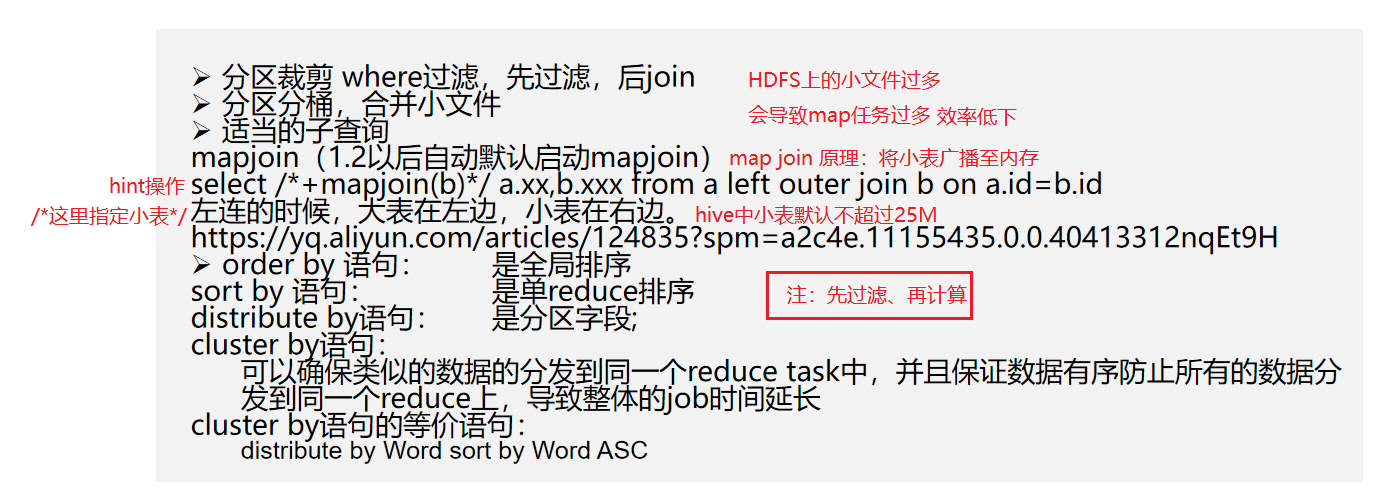
Hive调优-查询优化
Hive With as 用法
用法
后面的表可以用到前面的表
// 之前的写法
select t.id
,t.name
,t.clazz
,t.score_id
,t.score
,c.subject_name
from(
select a.id
,a.name
,a.clazz
,b.score_id
,b.score
from (
select id
,name
,clazz
from
students
) a left join (
select id
,score_id
,score
from score
) b
on a.id = b.id
) t left join (
select subject_id
,subject_name
from subject
) c on t.score_id = c.subject_id
limit 10;
// with as 可以把子查询拿出来,让代码逻辑更加清晰,提高效率
// 必须跟着sql一起使用
with tmp1 as (
select id
,name
,clazz
from students
), tmp2 as (
select score_id
,id
,score
from
score
), tmp1Jointmp2 as (
select a.id
,a.name
,a.clazz
,b.score_id
,b.score
from tmp1 a
left join tmp2 b
on a.id = b.id
), tmp3 as (
select subject_id
,subject_name
from subject
)select t.id
,t.name
,t.clazz
,t.score_id
,t.score
,c.subject_name
from tmp1Jointmp2 t left join tmp3 c
on t.score_id = c.subject_id
limit 10;Hive数据倾斜
在hive的shell中可以通过
set mapred.reduce.tasks = num ; (num--reduce 的数量)命令设置reduce的数量

原因:
key 分布不均匀,数据重复
有shuffle的过程
表现:
长尾效应:任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
解决方案:
- 1、从数据源头,业务层面进行优化
- 2、找到key重复的具体值,进行拆分,hash。异步求和。
// 数据
key col 数据量
84401,a --*982128
84402,c --*400
84403,d --*200
84404,e --*300
84405,f --*100
null,b --*16872
// 建表语句
create table data_skew(
key string
,col string
) row format delimited fields terminated by ',';
// 可以通过随机的抽样检查发现 分布不均的key 的具体值
// 随机分区(这里的分区是shuffle过程中的分区)
select * from data_skew distribute by rand() limit 1000;
// 为了模拟数据倾斜的问题,设置reduce任务数为6
set mapred.reduce.tasks = 6;
// 直接分组求count
select key,count(*) from data_skew group by key;
// 使用异步求和
// if(key='84401' or key == 'null',ceil(rand()*6),0)
// 将 84401 或 null 这两个 key 进一步的细分成6份
// group by key,if(key='84401' or key == 'null',ceil(rand()*6),0)
select t1.key
,sum(cnt) as sum_snt
from(
select key
,if(key='84401' or key == 'null',ceil(rand()*6),0) as hash_key
,count(*) as cnt
from data_skew
group by key,if(key='84401' or key == 'null',ceil(rand()*6),0)
) t1
group by t1.keyHive读写模式
Hive在加载数据的时候,能不能查询?
Hive 是 读时模式 的:hive在加载数据的时候,并不会检查我们的数据是不是符合规范,只有在读的时候才会根据schema(表结构)去解析数据
MYSQL是 写时模式 的 -- 写数据的时候 检查数据的合法性
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









